目录
一、数组名的理解
二、使用指针访问数组
三、一维数组传参的本质
四、冒泡排序
五、二级指针
六、指针数组
正文开始
一、数组名的理解
在上一篇博客中我们在使用指针访问数组的内容时有这样的代码:
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int *p = &arr[0];
这里我们使用&arr[0]的方式拿到了数组第一个元素的地址,但是我们在上篇博客提到过数组名的另一种含义是首元素的地址:
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("&arr[0] = %p\n", &arr[0]);
printf("arr = %p\n", arr);
return 0;
}这里我在32位环境下运行,这样更便于我们观察结果:

由此可见&arr和&arr[0]这两个语句是等效的!
这时候有同学会有疑问,如果数组名是数组首元素的地址,那下面的代码该怎么理解呢?
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("%d\n", sizeof(arr));
return 0;
}我们在计算数组的大小时用的也是sizeof(数组名),那这里的数组名是不是首元素的地址呢?我们运行一下看看:

输出的结果是40。一个整型的大小是4个字节,十个整型的大小就是40个字节,也就是说sizeof(arr)中的arr代表的是整个数组,而不是首元素的地址。如果这里的arr是数组首元素的地址,那输出的结果应该的应该是4/8才对。
再举一个例子:
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("%p", &arr);
printf("%p", &arr[0]);
return 0;
}你觉得上述代码的结果是多少呢?&arr[0]得到的就是数组首元素的地址,那&arr呢?arr代表首元素的地址,取地址的地址,难不成是二级指针吗?实际上,这里&arr中的arr代表的是整个数组:
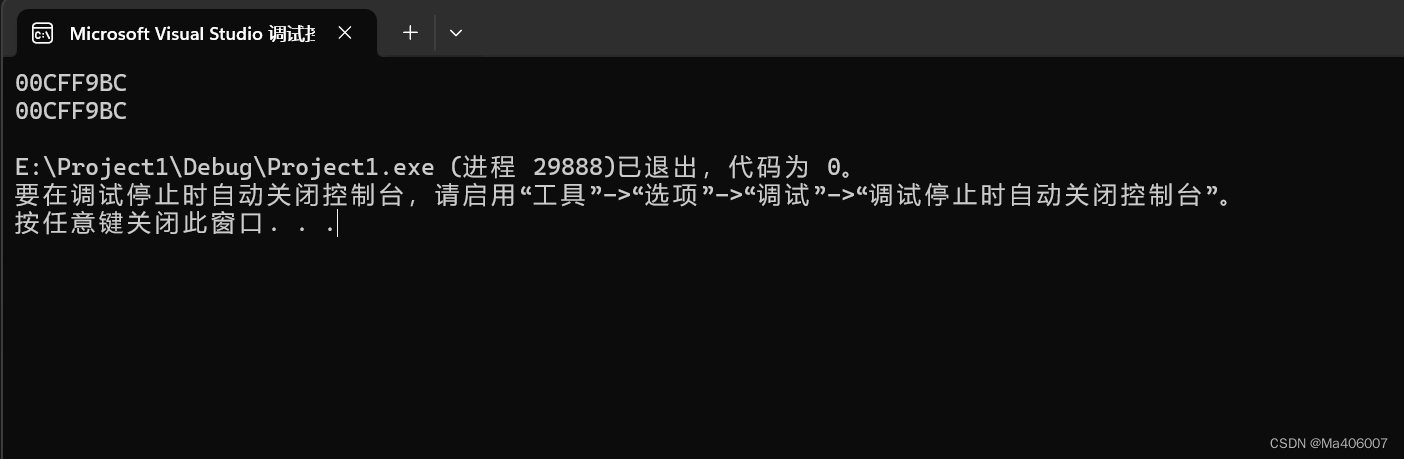
那我们就可以解读为,第一个输出的结果是整个数组的地址,而第二个输出的结果是数组首元素的地址。那为啥这两个的值是一样的呢?
如果你想要取到一个数组的地址,你就首先得找到首元素的地址。由于内存中的地址我们是无法直接看到的,但由于数组在内存中是连续存放的,只要你找到了首元素的地址,我们就可以顺藤摸瓜将后续的元素的地址表示出来。主要是由于数组在内存中是连续存放的这一特性而致使数组的地址和数组的首元素的地址是一样的。
我们来总结一下。其实数组名就是数组首元素的地址这句话是没有问题的,但是有两个例外:
①sizeof(数组名)。sizeof中单独放数组名,这里的数组名表示整个数组,计算的是整个数组的大小,单位是字节。
②&数组名。这里的数组名表示整个数组,取出的是整个数组的地址(整个数组的地址和数组首元素的地址是有区别的)
除上面两条之外,在任何地方使用数组名,都表示首元素的地址。
理解了数组名的实质,我们接下来再看一个例子:
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
printf("&arr[0] = %p\n", &arr[0]);
printf("&arr[0]+1 = %p\n", &arr[0]+1);
printf("arr = %p\n", arr);
printf("arr+1 = %p\n", arr+1);
printf("&arr = %p\n", &arr);
printf("&arr+1 = %p\n", &arr+1);
return 0;
}我们来逐个进行分析:
第一个printf()和第二个printf()都很容易理解。第一个打印出来的是首元素的地址,第二个打印出来的是第二个元素的地址。
由刚刚我们了解的数组名的本质我们也可以很轻易地得出:第三个打印出来的是首元素的地址,第四个打印出来的是第二个元素的地址。
接下来看第五个和第六个。我们已经知道&arr代表的是整个数组的地址,那么输出的结果其实和首元素的地址是相同的。那&arr+1的结果是啥呢?arr的长度是10,也就代表着一共有10个整型。一个整型占4个字节,那么十个整型就占40个字节。&arr+1代表的就是跳过整个数组,使数组的地址加上数组的长度*sizeof(数组的类型)。假设数组的地址是0x12ff40,那么输出的结果其实就是原地址加上40。
我们来看一下结果:

经过计算,010ffbf4与010ffbcc的差值正好是40。
二、使用指针访问数组
在上篇博客中我们已经写过如何用指针遍历数组:
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int* p = &arr[0];
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]);
for (i = 0; i < sz; i++)
printf("%d ", *(p + i));
return 0;
}在前面我们已经了解了数组名的含义,那我们是否还能根据数组名的含义将上述代码改成其他等效的代码呢?
数组名arr代表数组首元素地址,而这里的指针变量p也代表数组首元素地址。那也就是说我们可以这么认为:p==arr。那么我们就可以将访问数组的代码中的数组名arr替换为指针变量p(除初始化数组)。那也就代表着有以下代码语句成立:
① p + i == arr + i
② arr[i] == p[i]
③ *(p + i) == arr[i] == *(arr + i)
为了验证这些语句的成立,我们不妨敲代码进行验证:
#include <stdio.h>
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
int* p = &arr[0];
int i = 0;
int sz = sizeof(arr) / sizeof(arr[0]);
for (i = 0; i < sz; i++)
printf("%d ", *(p + i)); printf("\n");
for (i = 0; i < sz; i++)
printf("%d ", *(arr + i)); printf("\n");
for (i = 0; i < sz; i++)
printf("%d ", p[i]); printf("\n");
return 0;
}结果:
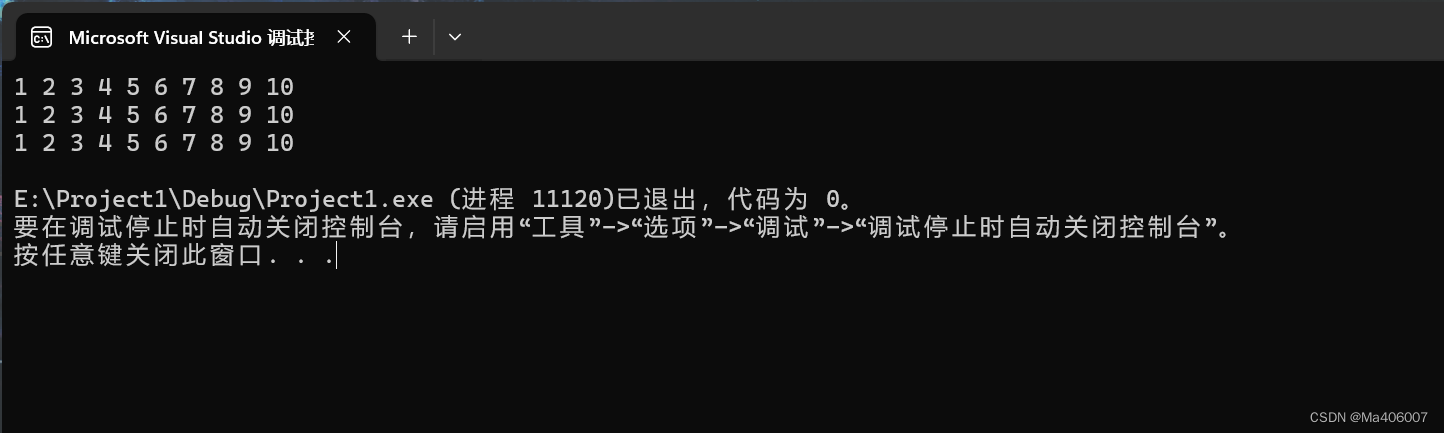
可以看到,这三个for循环打印出来的结果都是数组arr的内容。这就说明我们的猜想是正确的!编译器在处理数组元素的访问时,也是转换成首元素的地址+偏移量求出各个元素的地址,然后再通过解引用来访问的。
三、一维数组传参的本质
我们之前都是在main()函数中计算数组的元素个数。那我们可以把数组传给一个函数,然后在函数内部求数组的元素个数吗?
#include <stdio.h>
void test(int arr[])
{
int sz2 = sizeof(arr)/sizeof(arr[0]);
printf("sz2 = %d\n", sz2);
}
int main()
{
int arr[10] = {1,2,3,4,5,6,7,8,9,10};
int sz1 = sizeof(arr)/sizeof(arr[0]);
printf("sz1 = %d\n", sz1);
test(arr);
return 0;
}结果(32位环境下):
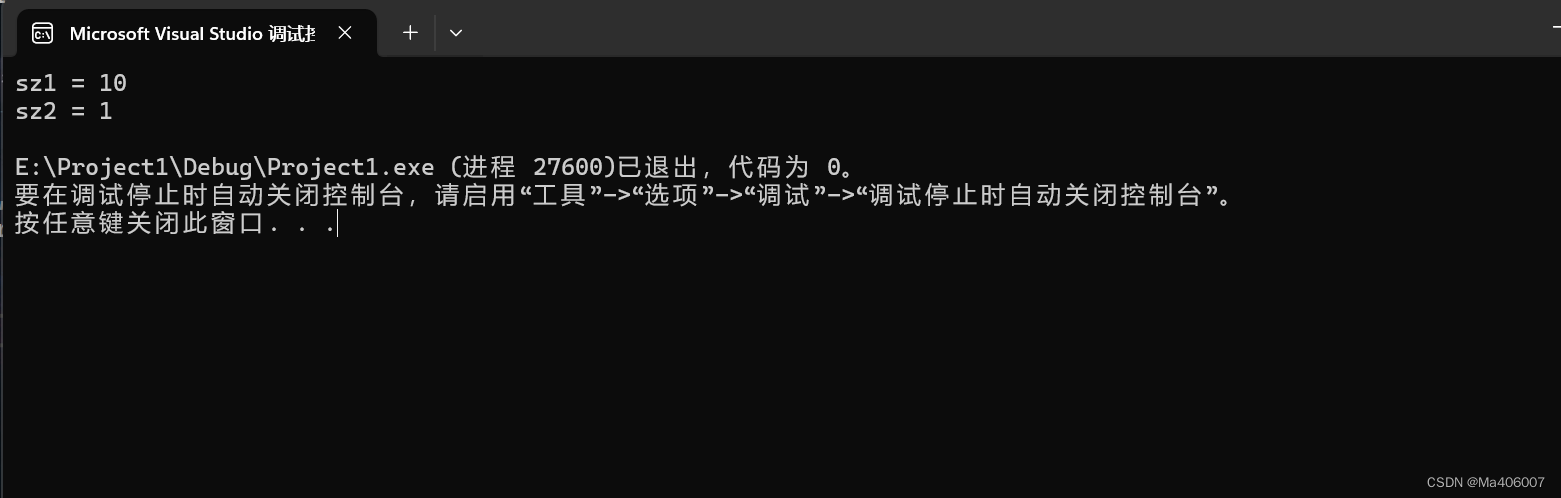
我们可以很清晰地看到sz2和sz1的结果并不相同。如果按我们的逻辑来分析的话,这里的sz2和sz1的结果应该都是10才对。
这就要学习数组传参的本质了。上个小节我们学习了:数组名是数组首元素的地址。那么在数组传参的时候传递的是数组名,也就是说数组传参本质上传递的是数组首元素的地址。
所以函数形参部分理论上应该使用指针变量接收首元素的地址。那么在函数内部我们写sizeof(arr) 计算的是一个地址的大小(单位字节)而不是数组的大小(单位字节)。
正是因为函数的参数部分是本质上是指针,所以在函数内部是没办法正确求得数组元素个数的。所以我们在进行一维数组传参时,形参的部分既可以写成数组的形式(arr[ ]),也可以写成指针的形式(*arr)。
#include <stdio.h>
void test1(int arr[])//参数写成数组形式,本质上还是指针
{
printf("%d\n", sizeof(arr));
}
void test2(int* arr)//参数写成指针形式
{
printf("%d\n", sizeof(arr));//计算⼀个指针变量的⼤⼩
}
int main()
{
int arr[10] = { 1,2,3,4,5,6,7,8,9,10 };
test1(arr);
test2(arr);
return 0;
}四、冒泡排序(整型版)
算法中举出了很多排序方法,其中最为经典的就是冒泡排序。冒泡排序的核心思想就是:将两两相邻的元素进行比较。接下来我们就一步步地来实现冒泡排序的算法~
我们不妨先写出main()函数中的代码。首先我们得先初始化一个乱序的数组,当然你也可以定义一个for循环来一个个输入数组元素。然后计算数组的长度以便作为形参传给冒泡排序的函数。随后就是让冒泡排序来对我们已经初始化好的乱序数组进行排序。最后再打印已经由冒泡排序排好的数组:
#include <stdio.h>
int main()
{
int arr[] = {3,1,7,5,8,9,0,2,4,6};
int sz = sizeof(arr)/sizeof(arr[0]);
bubble_sort(arr, sz);
for(int i=0; i<sz; i++)
printf("%d ", arr[i]);
return 0;
}接下来我们来实现bubble_sort()函数部分。
假设有以下逆序数组:
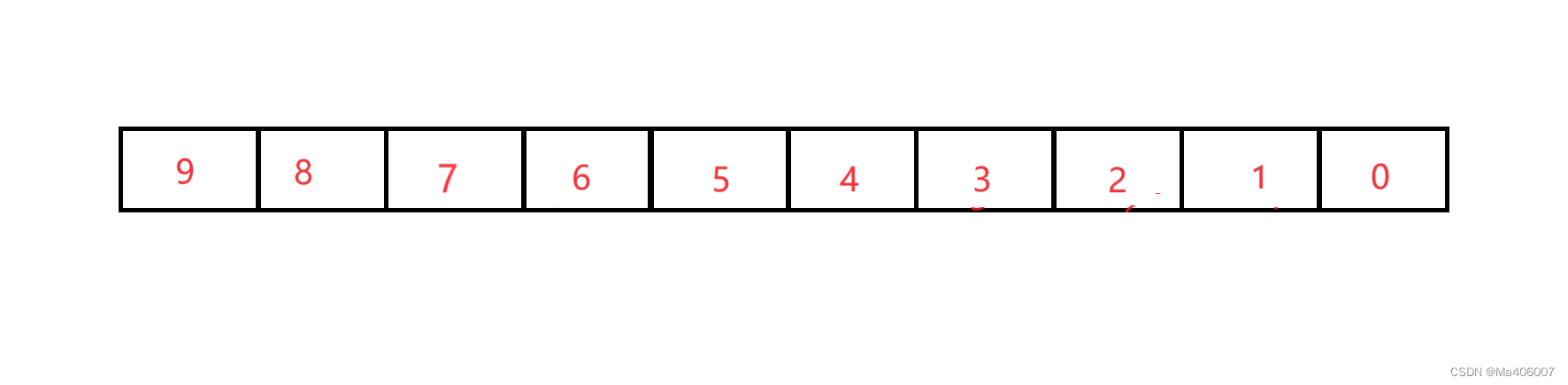
要将数组元素9移动到数组的最右端,具体方法是先让9和8比较,由于9比8大,所以9和8互换位置:

随后就是让9和7进行比较,9比7大,9和7互换位置。以此类推,直到9换到数组元素的最右端:

整个过程一共经历了9次交换。同样的,我们要将8移动到数组的右端就一共要经历8次交换:
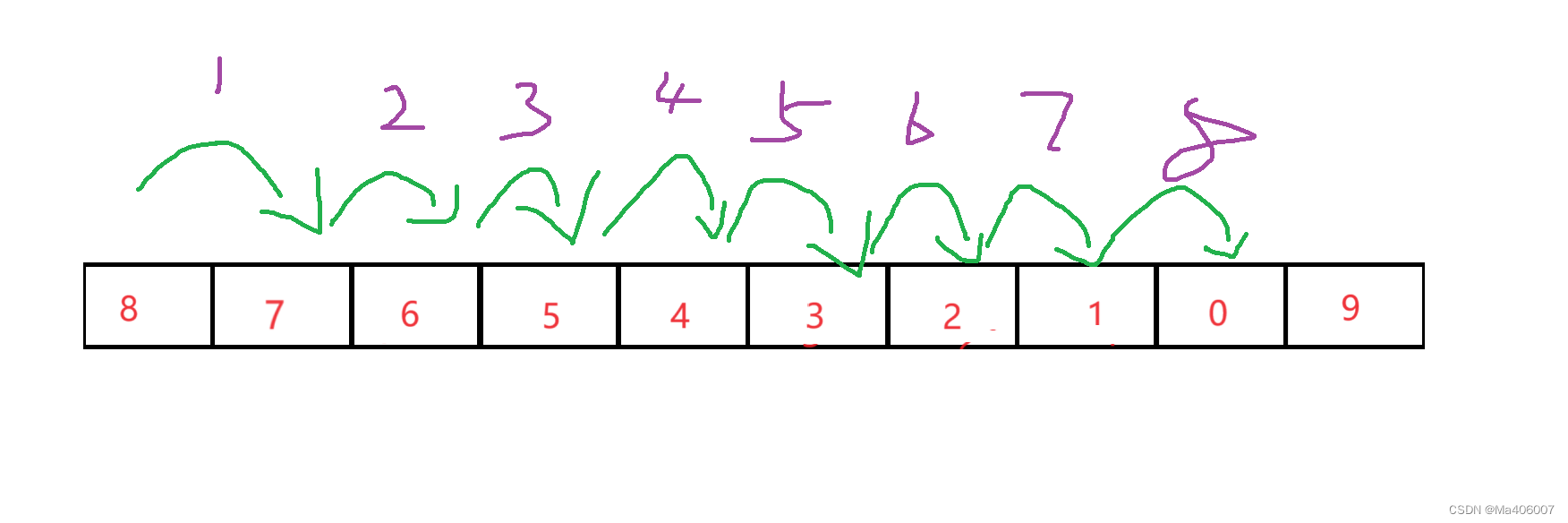
由于排序到最后只有0和1需要交换位置,0和1交换完位置后不需要再进行排序。那总的算下来一共就需要9+8+...+1次,也就是45次。最高交换次数为9,也就是数组的长度减一,所以主循环的循环次数一共有9次。然后子循环最初的循环次数与主循环相同,也就是将9移动到数组的最右端。随后子循环的循环次数递减。直到最后的子循环不循环(因为0不需要再进行排序),所以我们可以根据这个思路来写出bubble_sort()函数的代码:
void bubble_sort(int arr[], int sz)//参数接收数组元素个数
{
int i = 0;
for(i=0; i<sz-1; i++)
{
int j = 0;
for(j=0; j<sz-i-1; j++)
{
}
}接下来就是要考虑子循环内部的代码是什么样的了。冒泡排序的思想就是将两两相邻元素进行大小比较,然后再进行交换。也就是说本质上还是两个变量的数值交换。只需在加个前提条件,就是左边的元素是否大于右边的元素。如果确实是大于,那么两个数组元素就会进行数值交换;反之则不交换:
void bubble_sort(int arr[], int sz)//参数接收数组元素个数
{
int i = 0;
for(i=0; i<sz-1; i++)
{
int j = 0;
for(j=0; j<sz-i-1; j++)
{
if(arr[j] > arr[j+1])
{
int tmp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = tmp;
}
}
}
}那么整个程序就如下:
#include <stdio.h>
void bubble_sort(int arr[], int sz)//参数接收数组元素个数
{
int i = 0;
for(i=0; i<sz-1; i++)
{
int j = 0;
for(j=0; j<sz-i-1; j++)
{
if(arr[j] > arr[j+1])
{
int tmp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = tmp;
}
}
}
}
int main()
{
int arr[] = {3,1,7,5,8,9,0,2,4,6};
int sz = sizeof(arr)/sizeof(arr[0]);
bubble_sort(arr, sz);
for(int i=0; i<sz; i++)
printf("%d ", arr[i]);
return 0;
}结果:

然而实际上绝大多数时候并不会像逆序数组那样正好一共就经历45次排序,也就是排序次数≤45。为了让这个算法代码的时间复杂度尽量小一点,防止数组元素过多的时候排序次数过多导致代码运行时间过长,我们可以对代码进行优化。
我们要再引入一个变量flag,令其等于1。假设冒泡排序经历了若干次(小于等于最坏情况也就是排序次数正好是我们所设计的循环总次数)后还没有排好顺序,也就是代码还要对数组元素进行数值交换,这时flag的值就会变为0。下一次进入循环时,flag会重新变为1。假设代码刚好在这一次将数组的元素完全排好序,这时flag就不会等于0,它依然是1,这时只要再设立一个if语句让我们的代码退出循环即可。
想必大家已经知道改良后的冒泡排序算法该怎么写了吧!直接上代码:
void bubble_sort(int arr[], int sz)//参数接收数组元素个数
{
int i = 0;
for(i=0; i<sz-1; i++)
{
int flag = 1;//假设这一趟已经有序了
int j = 0;
for(j=0; j<sz-i-1; j++)
{
if(arr[j] > arr[j+1])
{
flag = 0;//发生交换就说明还需要进行排序
int tmp = arr[j];
arr[j] = arr[j+1];
arr[j+1] = tmp;
}
}
if(flag == 1)//这⼀趟没交换就说明已经有序。后续无需再进行排序,节省时间。
break;
}
}
五、二级指针
指针变量也是变量,是变量就有地址,那指针变量的地址存放在哪里呢?
没错,就是存放在存放指针变量的指针变量。
这就好比俄罗斯套娃:

我们将这个比较大的套娃拿走:

得到的就是名为int* n的较小套娃。我们再把这个较小套娃拿走:

得到的就是名为int** n的更小的套娃。这就是二级指针。


简单理解就是:一级指针pa存放的是int类型的变量a的地址,一级指针通过解引用操作后得到的就是变量a的值,同时也可以通过解引用操作来修改变量a的值;二级指针ppa存放的是int*类型的指针变量pa的地址,二级指针通过解引用操作后得到的就是指针变量pa的值(实际上就是变量a的地址),同时也可以通过解引用操作来修改指针变量pa的值,此时指针变量指向的变量就不再是变量a,而是内存中的另一个变量。以此类推。
当我们对二级指针进行两次解引用操作后,得到的就是变量a,即:
**ppa == *pa == a
六、指针数组
我们先来看一个例子:
int* ap[10];
为了弄清这个复杂的声明,我们假定它是一个表达式,并对它进行求值。
由操作符的优先级顺序我们可以知道,下标引用操作符([ ])的优先级高于解引用操作符,所以在这个表达式中,先执行下标引用操作符。因此ap是某种类型的数组。在取得一个数组元素之后,随即执行的是解引用操作符(*)。这个表达式不再有其他操作符,所以它的结果是一个整型值。
那这个ap到底是个什么东西啊?当我们对数组的某个元素执行解引用操作后,会得到一个整型值。所以ap肯定是个数组,那么它内部的元素类型就是指向整型的指针变量。所以ap就是指针数组。
指针数组,顾名思义,就是指针的数组。指针数组是一个数组,其元素都是指针。这些指针可以指向同一类型的不同变量,或者指向不同类型的变量,这取决于它们的定义。


七、指针数组模拟二维数组
接下来我们就用指针数组来模拟实现二维数组。以前我们实现二维数组是这样写的:
int arr[3][3] = { 0 };
我们在学习数组的时候就已经提到过二维数组的概念:(C语言:数组-CSDN博客)二维数组的元素是一维数组。那么在这里我们先创建三个一维数组:
int arr1[] = {1,2,3,4,5};
int arr2[] = {2,3,4,5,6};
int arr3[] = {3,4,5,6,7};
如果要将这三个一维数组囊括在一个二维数组里就是:
int arr[3][5] = { { 1,2,3,4,5 }, { 2,3,4,5,6 }, { 3,4,5,6,7 } };
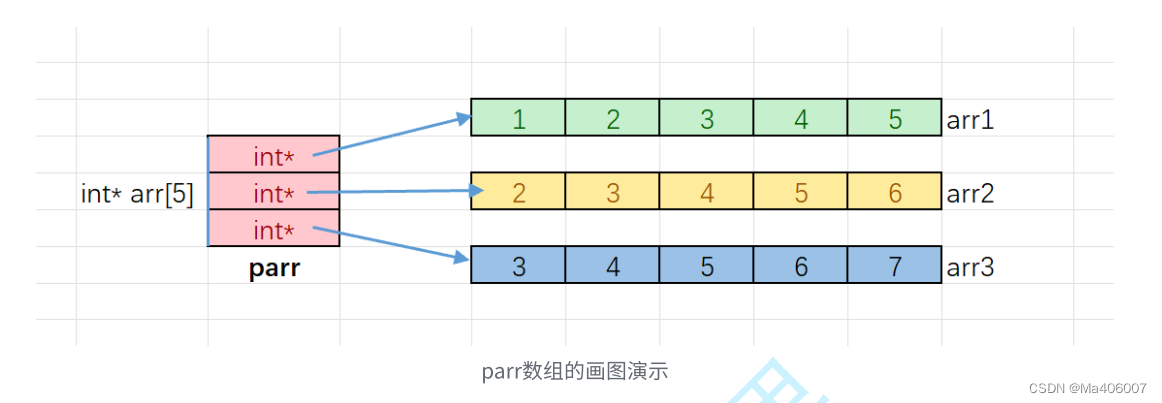
既然二维数组的元素是一维数组,而一维数组的打印又可以通过首元素地址依次遍历数组元素来完成。那我们不妨就将二维数组内部的元素分别改为arr1的首元素地址、arr2的首元素地址和arr3的首元素地址。这时数组内部的元素就变成了指针,因此,我们需要创建一个指针数组来承载这三个指针。我们不妨将其命名为parr。数组一共就有三个元素,所以:
int* parr[3] = {arr1, arr2, arr3};
既然我们的任务是打印出来类似二维数组的东西,我们肯定还是得需要构建出两层循环,也就是和打印真正的二维数组一样的流程。
接下来才是重头戏。我们在正常打印真正的二维数组的时候是这样写代码的:
#include <stdio.h>
int main()
{
int arr[3][5] = {1,2,3,4,5, 2,3,4,5,6, 3,4,5,6,7};
for(int i=0; i<3; i++)//产生行号
{
for(int j=0; j<5; j++)//产生列号
printf("%d ", arr[i][j]);//输出数据
printf("\n");
}
return 0;
}再回到我们这里写的指针数组。parr[0]是arr1,parr[1]是arr2,parr[2]是arr3。我们可以很清晰地发现:parr[i]代表的就是我们提前声明好的一维数组的首元素地址!如果我们将parr[i]看成一个整体——Arr,我们还可以很轻易地表示出三个一维数组的元素:也就是Arr[j]。所以就可以按照顺序依次打印出三个一维数组。例如如果是parr[0][3]本质上就代表着一维数组arr1中下标为3的元素。
因此,我们可以写出指针数组模拟二维数组的代码:
#include <stdio.h>
int main()
{
int arr1[] = {1,2,3,4,5};
int arr2[] = {2,3,4,5,6};
int arr3[] = {3,4,5,6,7};
//数组名是数组首元素的地址,类型是int*的,就可以存放在parr数组中
int* parr[3] = {arr1, arr2, arr3};//指针数组
for(int i=0; i<3; i++)
{
for(int j=0; j<5; j++)
printf("%d ", parr[i][j]);
printf("\n");
}
return 0;
}结果:
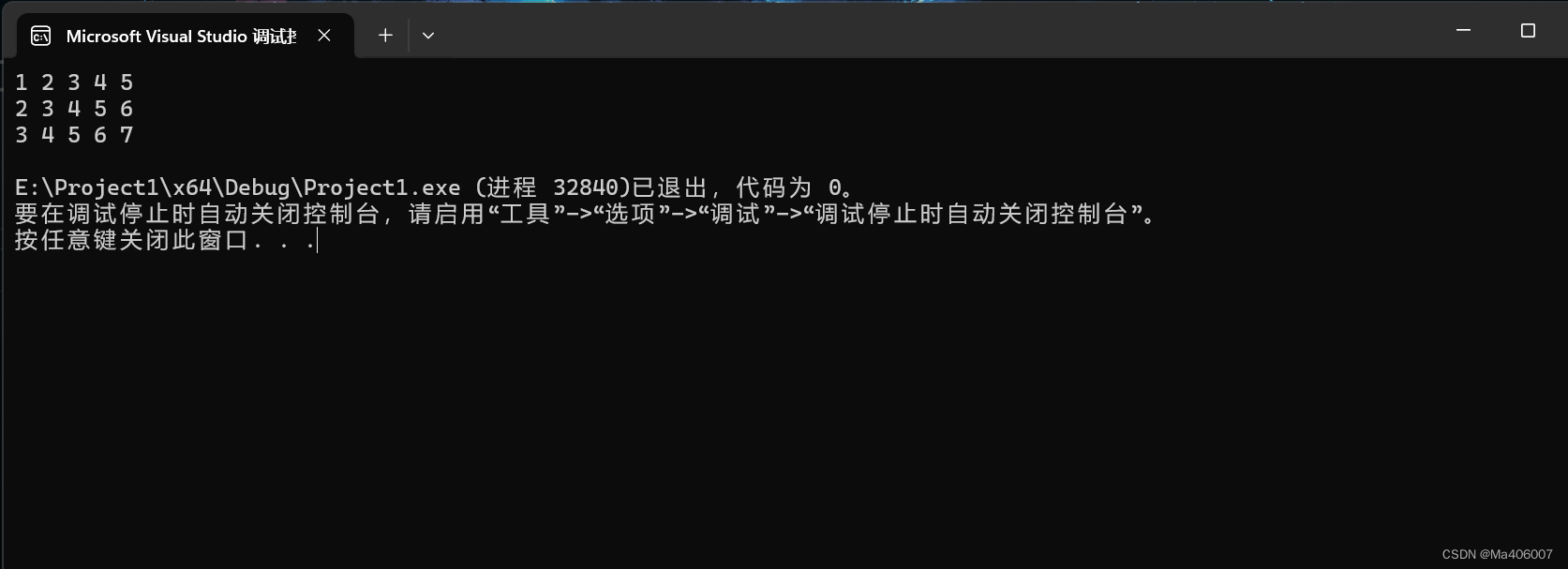
可以发现,与我们正常打印二维数组的结果一模一样。但这里我们还是要明白,这种利用指针数组打印的方式与直接打印二维数组的方式所输出的结果本质上还是不一样的!直接打印二维数组输出的结果是实打实的二维数组,而利用指针数组模拟二维数组输出的结果本质上是若干个一维数组。因为它们在内存上并不是连续的。为啥呢?假设arr1数组的地址在0x12ff40,那么arr2数组的地址可能就在0x20cc12,而arr3数组的地址可能就已经被孙悟空携着乘上筋斗云飞向十万八千里开外了!
完