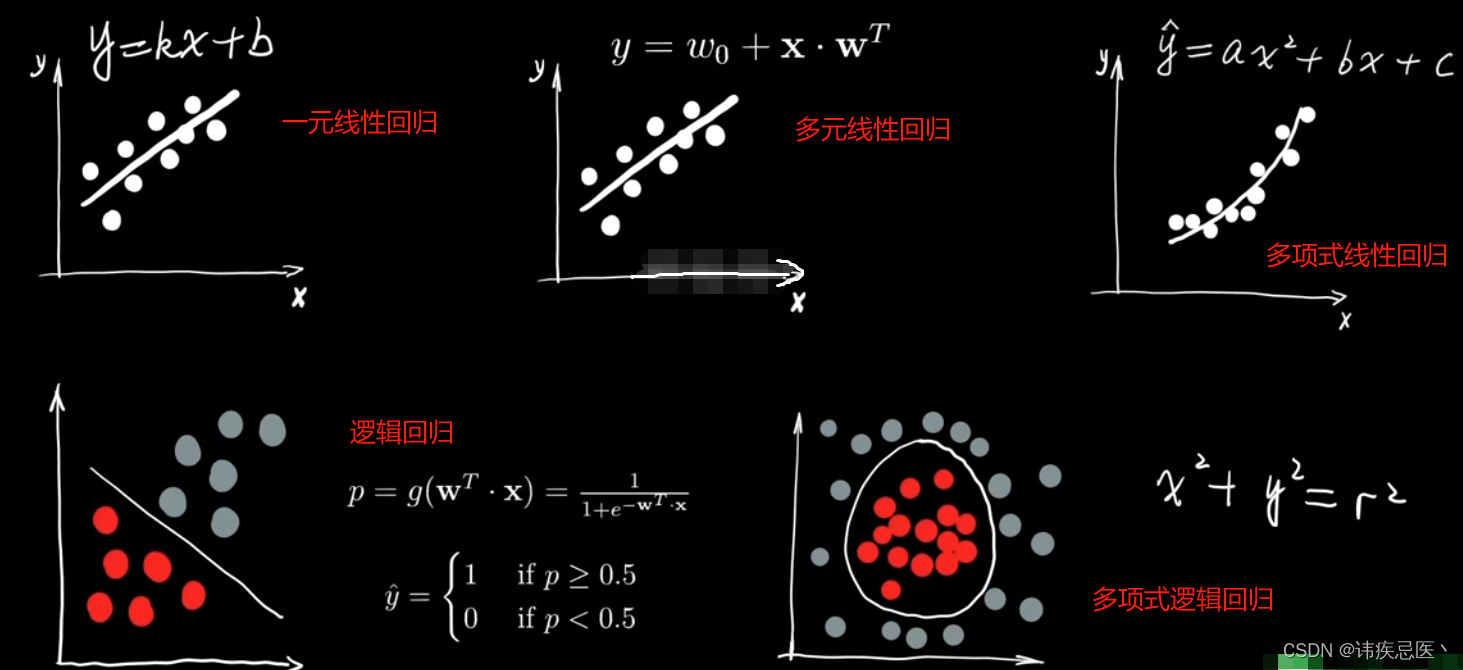
1、什么是一元线性回归
线性:两个变量之间的关系是一次函数,也是数据与数据之间的关系。
回归:人们在测试事物的时候因为客观条件所限,求的都是测试值,而不是真实值,为了无限接近真实值,无限次的进行测量,最后通过这些测量数据计算回归到真实值,这就是回归的由来。
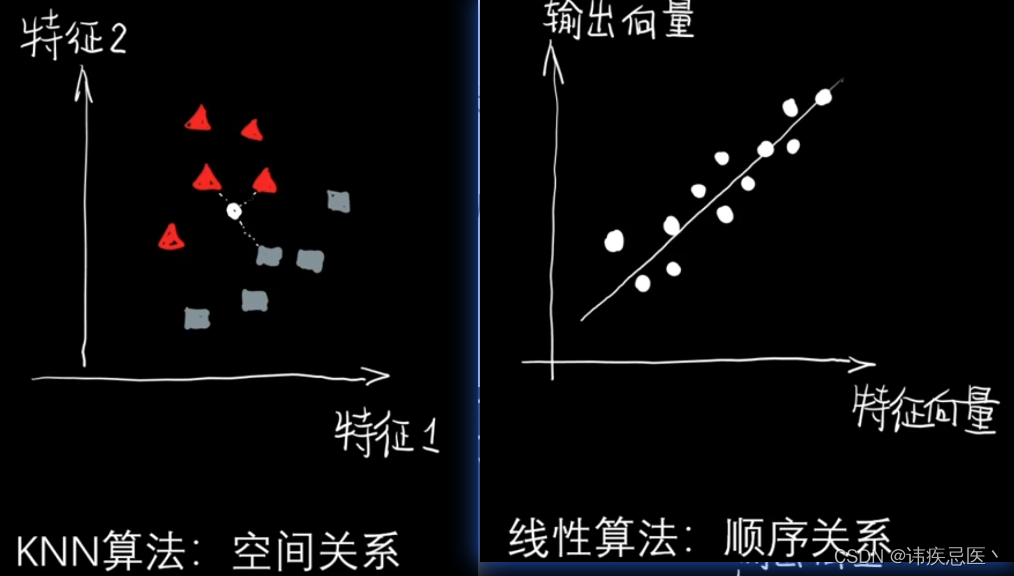
KNN最近邻值是:KNN横纵轴坐标为两个特征,比如身高体重与某种疾病关系。
一元线性回归:只有横轴是特征,纵轴是输出值,比如股价与时间的关系。
通俗的说就是用一个函数去逼近这个真实值
1.2、线性回归解决什么问题
通过大量样本数据进行处理,可以得出一个 比较符合事物内部规律的y=kx+b,从而对结果进行预测,解决的就是通过已知样本数据,预测未知数据,比如房价进行预测,电影票房预测。
计算k和b的计算公式:
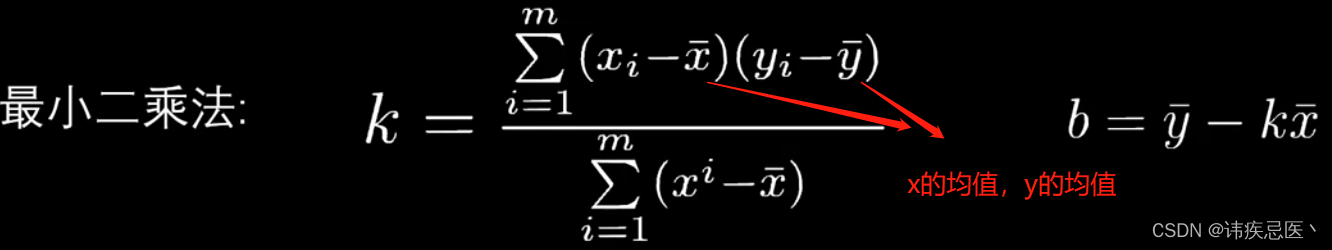
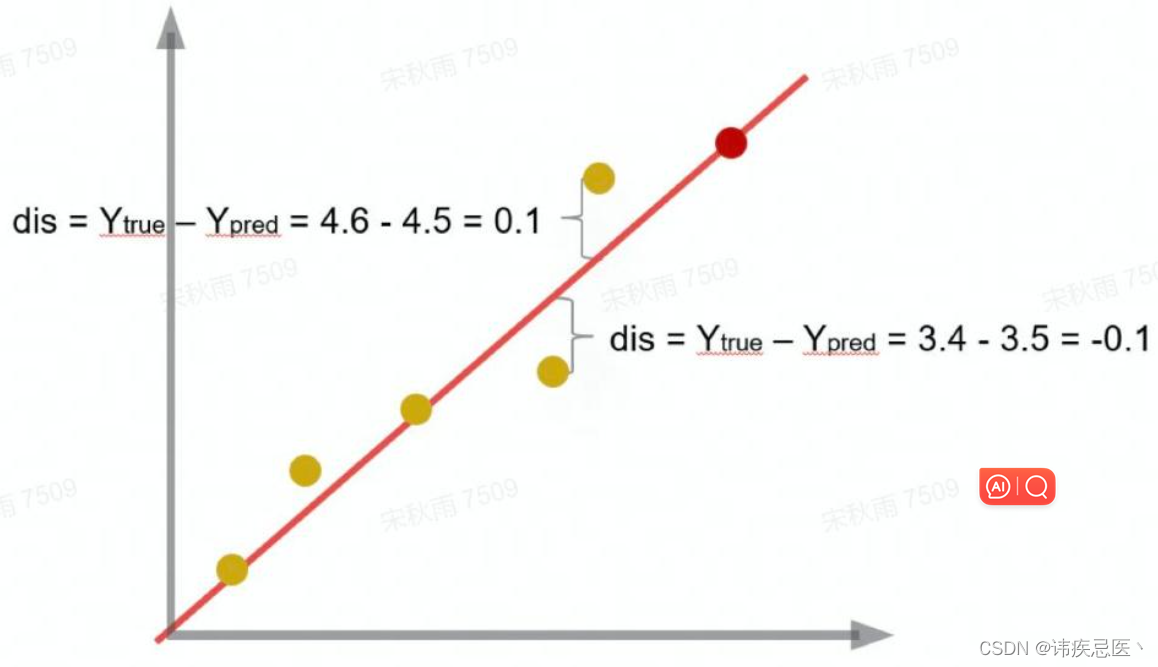
损失函数(loss function),衡量了误差大小,不断地去优化,找出最优解,平方残差和是最常用的一种方式
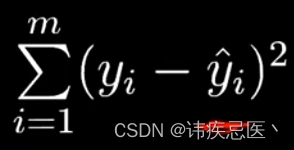
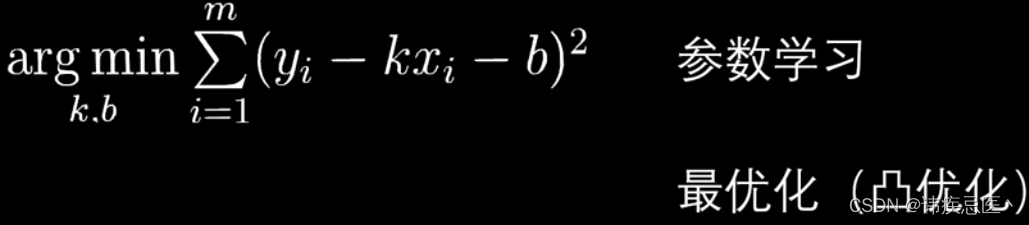
1.3、实现一元线性回归
# 使用boston数据集
import numpy as np
import matplotlib.pyplot as plt
import sklearn
from sklearn.model_selection import train_test_split
import pandas as pd
# 加载波士顿房屋数据集
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
from sklearn.model_selection import train_test_split
# 拆分数据集
x_train,x_test,y_train,y_test = train_test_split(data,target,train_size=0.7,random_state=233)
x_train[:,5].shape,y_train.shape
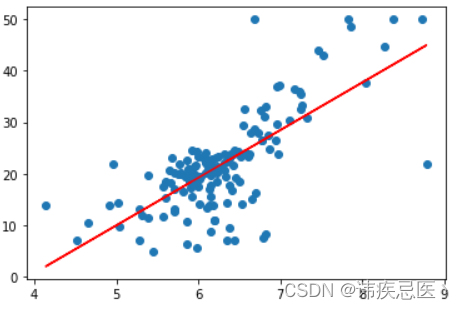
plt.scatter(x_train[:,5],y_train)
def fit(x,y):
a_up = np.sum((x-np.mean(x))*(y-np.mean(y)))
a_bottom = np.sum((x-np.mean(x))**2)
a = a_up/a_bottom
b = np.mean(y) - a *np.mean(x)
return a,b
a,b = fit(x_train[:,5],y_train)
a,b
plt.scatter(x_train[:,5],y_train)
plt.plot(x_train[:,5],a*x_train[:,5]+b,c='r')
plt.show()
1.4、使用sklearn实现一元线性回归
from sklearn.linear_model import LinearRegression
lr = LinearRegression()
lr.fit(x_train[:,5].reshape(-1,1),y_train)
y_predict = lr.predict(x_test[:,5].reshape(-1,1))
plt.scatter(x_test[:,5],y_test)
plt.plot(x_test[:,5],y_predict,c='r')
plt.show()
2、多元线性回归
参考链接
线性回归是评估自变量x和应变量y之间的一种线性关系,当只有一个自变量称为一元线性回归,多个自变量称为多元线性回归,现实生活中数据都是比较复杂的,比如影响房价的因素往往不止一个,可能还有附近地铁,房间数,层数,建筑年代等诸多因素。不过每个因素对房价影响权重不同,因此我们可以用多个权重来表示多个因素与房屋价格的关系
x:影响因素,即特征。
w:每个x的影响力度。
n:特征的个数。
y^:房屋的预测价格。
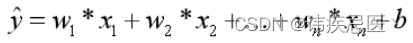

这样,就可以表示为:
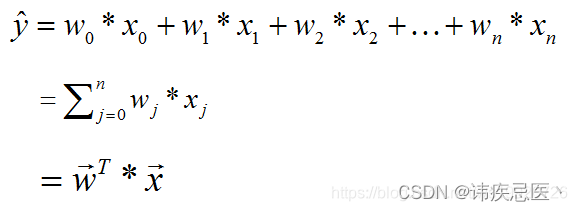
多元线性回归在空间中,可以表示为一个超平面,去拟合空间中的数据点。
我们的目的就是从现有的数据中,去学习w与b的值。一旦w与b的值确定,就能够确定拟合数据的线性方程,这样就可以对未知的数据x进行预测y(房价)
损失函数:
对于机器学习来讲,就是从已知数据去建立一个模型,使得该模型能够对未知数据进行预测。实际上,机器学习的过程就是确定模型参数的过程。
对于监督学习来说,我们可以通过建立损失函数来实现模型参数的求解,损失函数也称目标函数或代价函数,简单来说就是关于误差的一个函数。损失函数用来衡量模型预测值与真实值之间的差异。机器学习的目标,就是要建立一个损失函数,使得该函数的值最小。
也就是说,损失函数是一个关于模型参数的函数(以模型参数w作为自变量的函数),自变量可能的取值组合通常是无限的,我们的目标,就是要在众多可能的组合中,找到一组最合适的自变量组合,使得损失函数的值最小。
在线性回归中,我们使用平方损失函数(最小二乘法),定义如下:

2.2、使用sklearn实现多元线性回归
多元线性回归没办法通过画图看出效果,但是可以通过score来获取模型的评分。
注意:多元线性回归是不需要归一化的,学习的是各自维度特征
# 使用boston数据集
import numpy as np
import matplotlib.pyplot as plt
import sklearn
from sklearn.model_selection import train_test_split
import pandas as pd
# 加载波士顿房屋数据集
data_url = "http://lib.stat.cmu.edu/datasets/boston"
raw_df = pd.read_csv(data_url, sep="\s+", skiprows=22, header=None)
data = np.hstack([raw_df.values[::2, :], raw_df.values[1::2, :2]])
target = raw_df.values[1::2, 2]
x_train,x_test,y_train,y_test = train_test_split(data,target,test_size=0.3,random_state=233)
lr = LinearRegression()
lr.fit(x_train,y_train)
lr.score(x_test,y_test)
2.3、MSE
MSE(Mean Squared Error),平均平方差,为所有样本数据误差(真实值与预测值之差)的平方和,然后取均值。越接近0越好,mse越小容易出现过拟合,反之容易欠拟合。

手动实现
mse = np.sum(((y_test-y_predict)**2)/len(y_test))
mse
使用skleran实现
# 使用sklearn实现
from sklearn.metrics import mean_squared_error
mean_squared_error(y_test,y_predict)
2.4、RMSE
RMSE(Root Mean Squared Error),平均平方误差的平方根,即在MSE的基础上,取平方根。放大了较大误差之间的差距
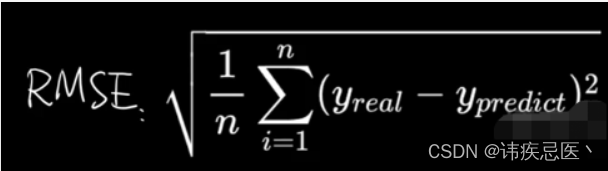
#RMSE,先对数据进行了平方然后累加在开方,放大了较大误差之间的差距
rmse = np.sqrt(mse)
# 使用skleran实现
from sklearn.metrics import mean_squared_error
mean_squared_error(y_test,y_predict,squared=False)
2.5、MAE
MAE(Mean Absolute Error),平均绝对值误差,为所有样本数据误差的绝对值和,然后去均值。真实误差
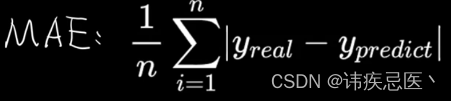
# MAE 真是误差
mae = np.sum((np.abs(y_test-y_predict))/len(y_test))
# 使用skleran实现
from sklearn.metrics import mean_absolute_error
mean_absolute_error(y_test,y_predict)
2.6、R^2
R2为决定系数,用来表示模型拟合性的分值,值越高表示模型拟合性越好,在训练集中,R2的取值范围为[0,1]。在R2的取值范围为[-∞,1]。从公式定义可知,最理想情况,所有的样本数据的预测值与真实值相同,即RSS为0,此时R2为1。
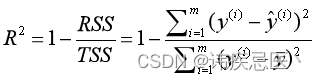
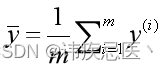
r2 = 1 - (np.sum((y_test-y_predict)**2))/(np.sum((y_test-np.mean(y_test))**2))
r2
公式二:消除样本本身取值大小的影响,实现了归一化
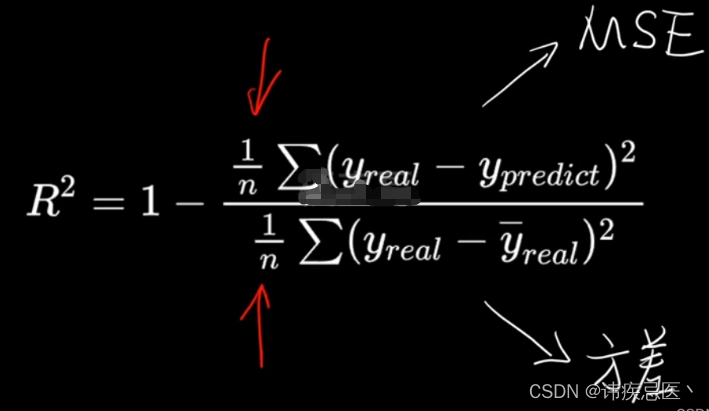
1-mse/np.var(y_test)
# skleran实现
from sklearn.metrics import r2_score
r2_score(y_test,y_predict)
2.7、模型评价方法总结
总结:MSE计算简单,RMSE和MAE保持了和样本同样的量纲,MSE和MAE适用误差相对明显的时候,大的误差就会有比较大的权重,RMSE针对误差不是很明显的时候,MAE相比MSE更能凸显异常值,在回归模型中损失函数一般使用MAE、MSE、RMSE,性能评估指标一般使用R^2。
3、多项式回归代码实现
对于非线性回归的数据,我们可以使用多项式回归拟合一条曲线。
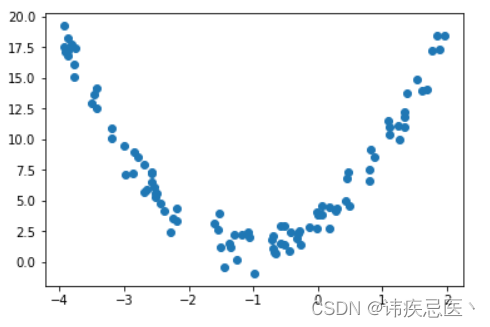
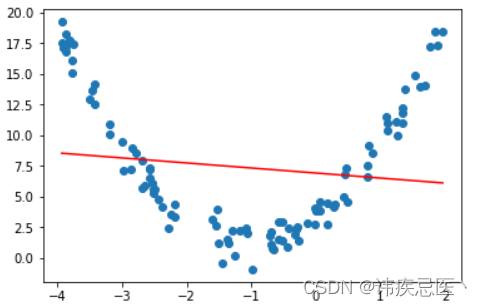
可以明显看到使用直线拟合非线性数据,效果非常不好。
# 多项式回归
x = np.random.uniform(-4,2,size=(100))
y = 2*x**2 + 4*x+3+np.random.randn(100)
X = x.reshape(-1,1)
plt.scatter(x,y)
plt.show()
lr = LinearRegression()
lr.fit(X,y)
y_predict = lr.predict(X)
plt.scatter(x,y)
plt.plot(np.sort(x),y_predict[np.argsort(x)],color='red')
plt.show()
使用多项式回归拟合
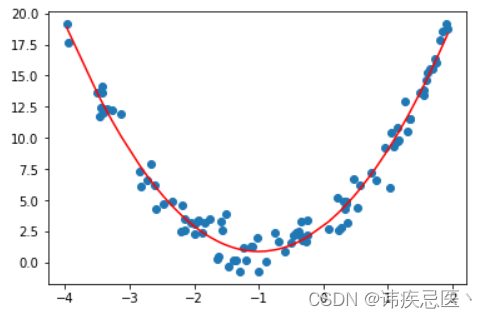
X_new = np.hstack([X,X**2])
lr = LinearRegression()
lr.fit(X_new,y)
y_predict = lr.predict(X_new)
plt.scatter(x,y)
plt.plot(np.sort(x),y_predict[np.argsort(x)],color='red')
plt.show()+# 输出函数截取
lr.intercept_
# 输出函数特征值
lr.coef_
使用sklearn实现
# 使用sklearn实现
from sklearn.preprocessing import PolynomialFeatures
# 最高2次幂
polynomial = PolynomialFeatures(degree=2)
# 转换后的特征
x_poly = polynomial.fit_transform(X)
lr = LinearRegression()
lr.fit(x_poly,y)
y_predict = lr.predict(x_poly)
plt.scatter(x,y)
plt.plot(np.sort(x),y_predict[np.argsort(x)],color='red')
plt.show()
4、逻辑回归解决分类问题
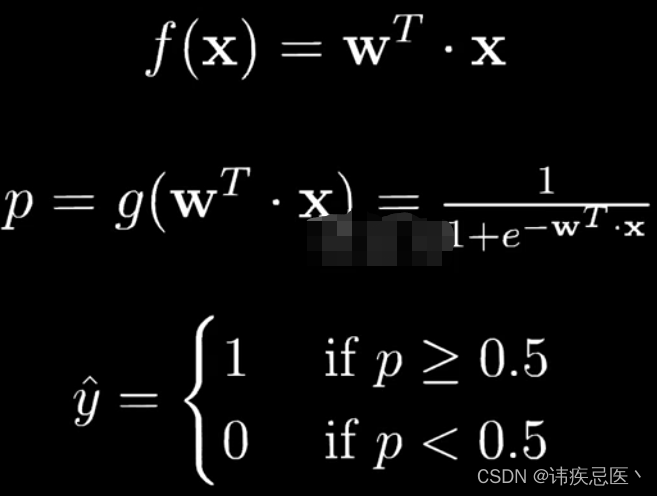
误差距离计算方式:
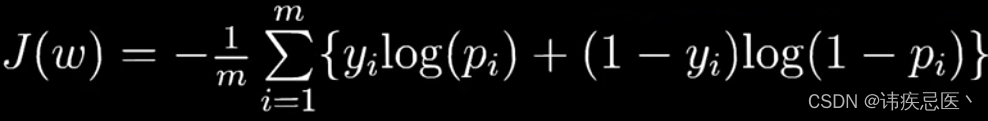

4.2、使用sklearn实现逻辑回归
# 逻辑回归
import numpy as np
import matplotlib.pyplot as plt
from sklearn.model_selection import train_test_split
from sklearn.datasets import make_classification
x,y = make_classification(
n_samples=200,# 样本数
n_features=2,# 特征数
n_redundant=0,# 冗余特指数
n_classes=2,# 类型
n_clusters_per_class=1,# 族设为1
random_state=1024
)
x.shape,y.shape
x_train,x_test,y_train,y_test = train_test_split(x,y,train_size=0.7,random_state=1024,stratify=y)
plt.scatter(x_train[:,0],x_train[:,1],c=y_train)
from sklearn.linear_model import LogisticRegression
clf = LogisticRegression()
clf.fit(x_train,y_train)
clf.score(x_test,y_test)
clf.predict(x_test)
4.3、超参数使用
# 超参数
from sklearn.model_selection import GridSearchCV
params = [{
'penalty':['l2','l1'],# 损失函数正则项
'C':[0.0001,0.001,0.01,0.1,1,10,100,1000],
'solver':['liblinear']# 优化算法
},{
'penalty':['none'],
'C':[0.0001,0.001,0.01,0.1,1,10,100,1000],
'solver':['lbfgs']
},{
'penalty':['elasticnet'],
'C':[0.0001,0.001,0.01,0.1,1,10,100,1000],
'l1_ratio':[0,0.25,0.5,0.75,1],
'solver':['saga'],
'max_iter':[200]
}]
grid = GridSearchCV(
estimator=LogisticRegression(),
param_grid=params,
n_jobs=-1
)
grid.fit(x,y)
grid.best_score_
grid.best_estimator_.score(x_test,y_test)
grid.best_params_
4.4、多项式逻辑回归
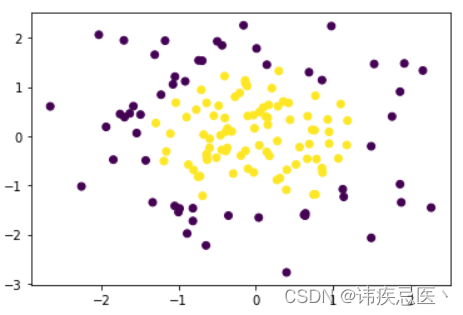
# 多项式逻辑回归
np.random.seed(0)
X = np.random.normal(0,1,size=(200,2))
y = np.array((X[:,0]**2)+(X[:,1]**2)<2,dtype='int')
x_train,x_test,y_train,y_test = train_test_split(X,y,train_size=0.7,random_state=1024,stratify=y)
plt.scatter(x_train[:,0],x_train[:,1],c=y_train)
from sklearn.preprocessing import PolynomialFeatures
poly = PolynomialFeatures(degree=2)
poly.fit(x_train)
x2 = poly.transform(x_train)
x2t = poly.transform(x_test)
clf = LogisticRegression()
clf.fit(x2,y_train)
clf.score(x2,y_train)
clf.score(x2t,y_test)
4.5、多分类问题OVR
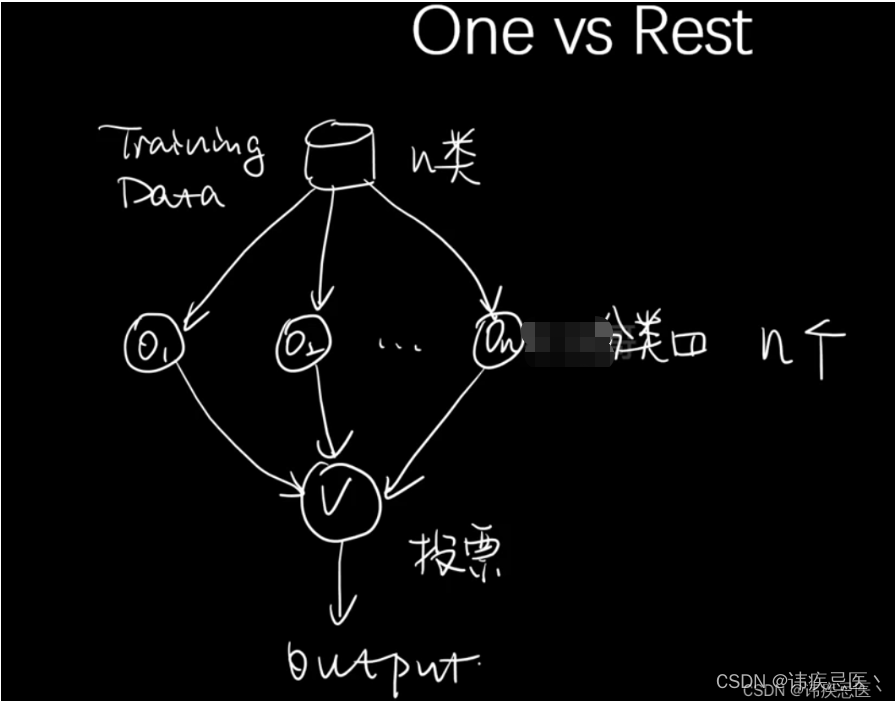
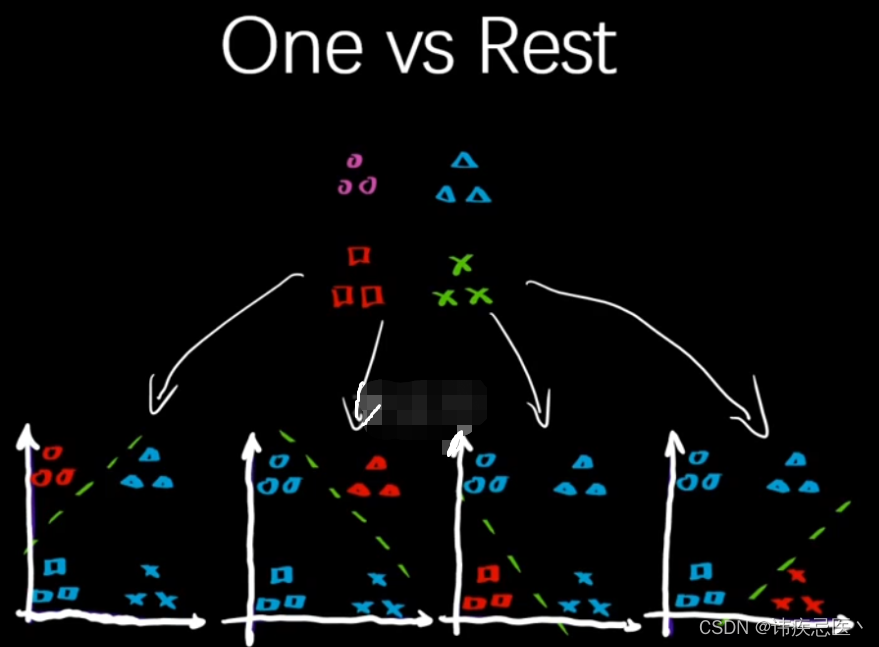
# 多分类问题,OVO和OVR
from sklearn import datasets
iris = datasets.load_iris()
x = iris.data
y = iris.target
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=666)
plt.scatter(x_train[:,0],x_train[:,1],c=y_train)
plt.show()
from sklearn.multiclass import OneVsRestClassifier
ovr = OneVsRestClassifier(clf)
ovr.fit(x_train,y_train)
ovr.score(x_test,y_test)
4.6、多分类问题OVO
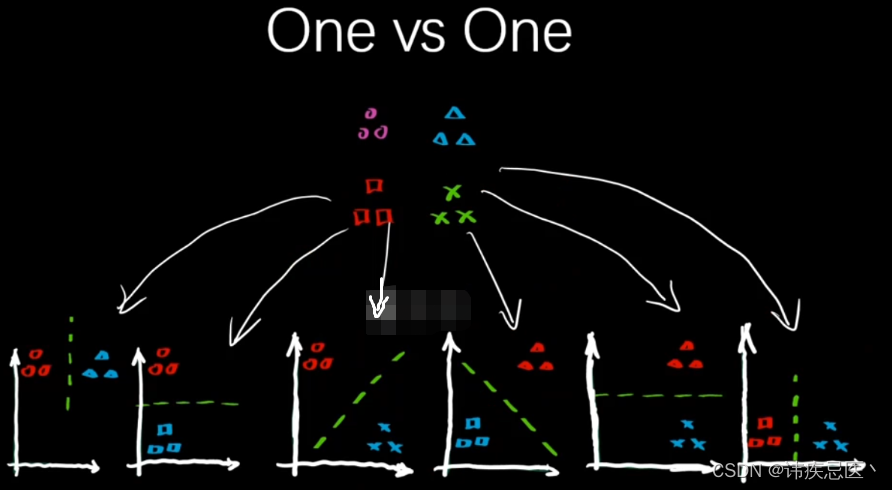
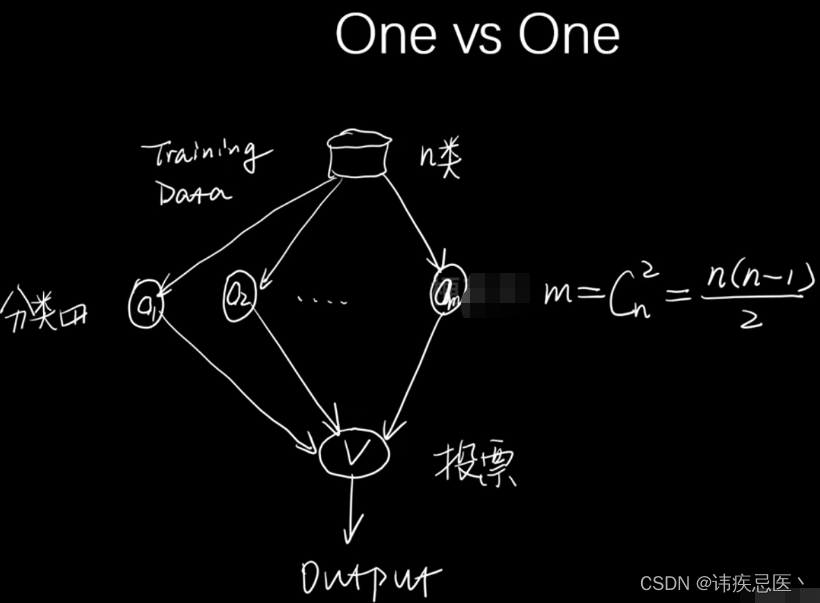
# 多分类问题,OVO和OVR
from sklearn import datasets
iris = datasets.load_iris()
x = iris.data
y = iris.target
x_train,x_test,y_train,y_test = train_test_split(x,y,random_state=666)
plt.scatter(x_train[:,0],x_train[:,1],c=y_train)
plt.show()
from sklearn.multiclass import OneVsOneClassifier
ovo = OneVsOneClassifier(clf)
ovo.fit(x_train,y_train)
ovo.score(x_test,y_test)
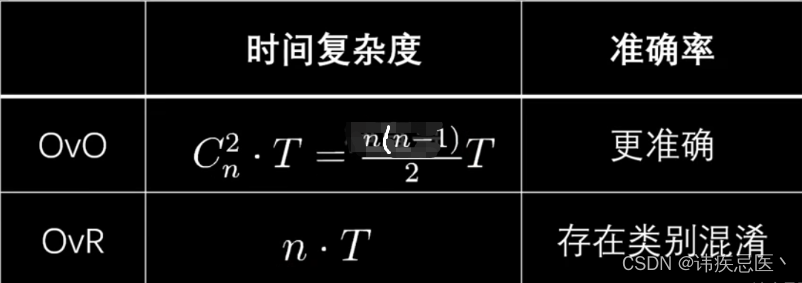
5、优缺点对比
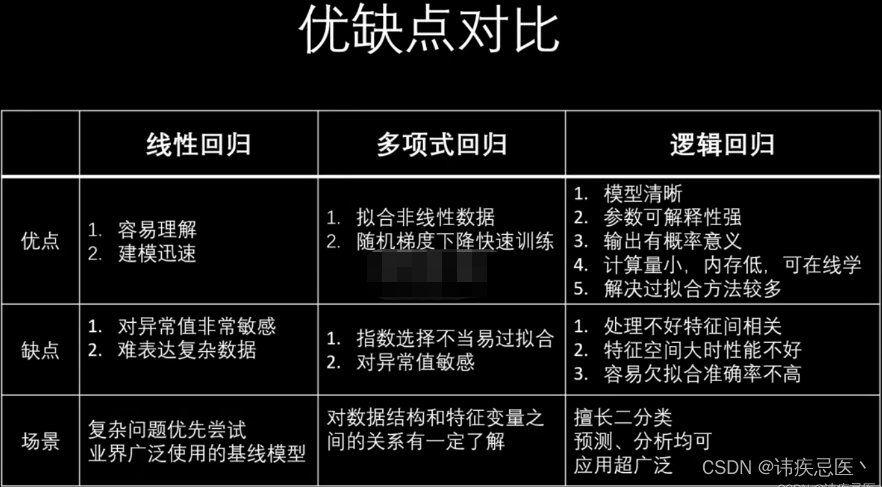
KNN对比线性算法:
KNN算法:非参数模型、计算量大、数据无假设
线性算法:可解释性好、建模迅速、线性分布