文章目录
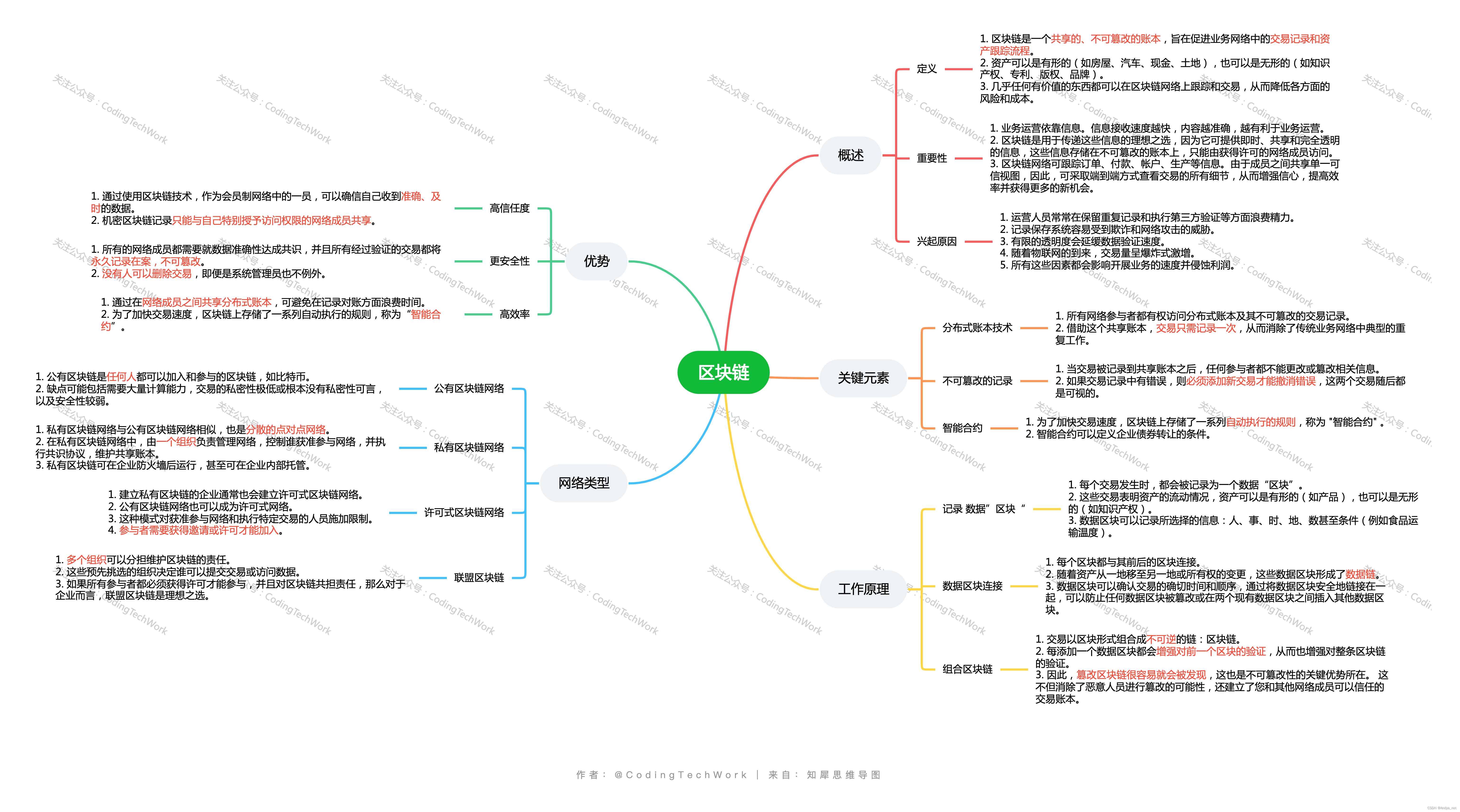
- 针对序列任务
- self-attention(注意力机制)流程
- multi-head self-attention(多头注意力机制)流程
- positional encoding(位置编码)
- Transformer
- embedding
- Add & Norm
- feed forward
- Masked
李老师官方视频传送门
李老师课程主页传送门
针对序列任务
RNN无法实现并行化操作,因为下一个节点的输入依赖于上一个节点的输出,有人提出采用CNN,每一个节点都看一个序列词,这样可以做到并行化,最后再来一个CNN将每个节点的输出汇总作为输入得到结果。而self-attention自注意力机制在并行化上可以取代RNN,而且效果也不错。
self-attention(注意力机制)流程
①:x指的序列中每个个体,x经过一层W后生成a,a再经过不同的W(Wq、Wk、Wv)会生成三个向量q、k、v
- q:query,用于匹配其他
- k:key,被匹配
- v:value,包含信息

②:拿每一个q去对每个key做注意力机制,这里的注意力机制采用的是Scaled Dot-Product Attention方法,这里的d是q和k的维度,除以根号d的原因多半是为了降低结果大小,使得点积在不同维度上变化辐度一致

③:将得到的α经过softmax转换成α‘,softmax的目的是将每个元素转换为一个介于 0 和 1 之间的数,并且使得它们的总和为 1,下面是softmax公式

④:将各自得到的α‘和对应的v相乘,最后将所有的相乘结果相加记为b,注意这里就是拿q1和所有的k、v最后得到了b1,q2、q3 …也是类似可以得到b2、b3 …
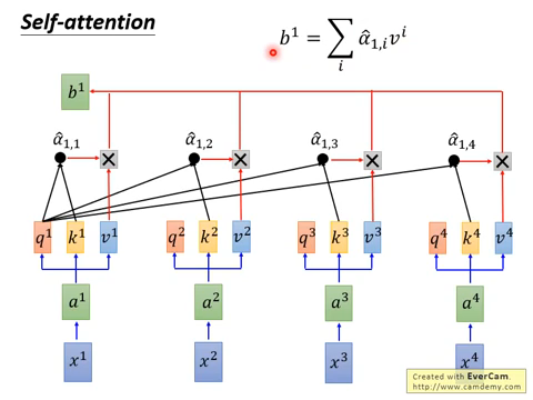
⑤:所以经过上述一系列流程x1、x2、x3、x4就被转换为了b1、b2、b3、b4
multi-head self-attention(多头注意力机制)流程
①:在得到q、k、v后,再经过W进行划分,而且后面相乘的时只允许划分后的相乘,不能跨其他划分相乘,得到b
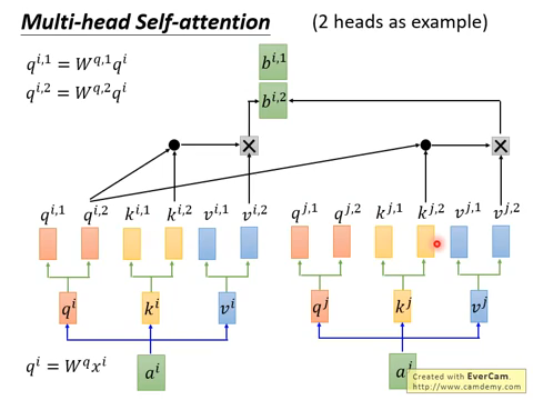
②:得到对应的b后,再利用W进行降维,将其变成和原来对应的bi。单一的头可能只学到单一的注意力表示,多头可以学习到不同的注意力表示,表示的更加丰富

positional encoding(位置编码)
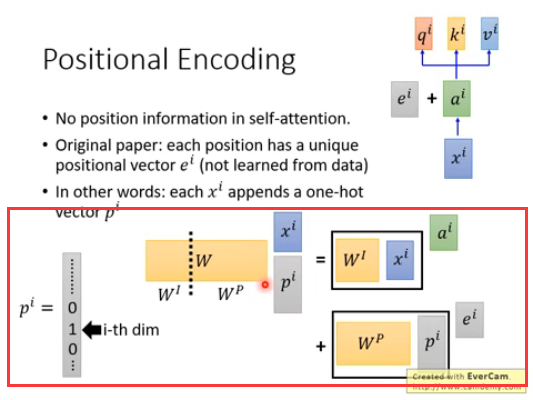
在序列任务中,序列的顺序是尤为重要的特征,需要考虑,原文是在x转换为a的时候增加了e,e里面就包含了位置信息,这里为什么不拼接而是相加呢?拼接不是更能表示位置信息嘛?
实际解释是这样的,原始假设p向量是表示位置的独热编码,和x拼接后经过w得到a,拆分后其实就是a+e,所以不需要拼接
Transformer
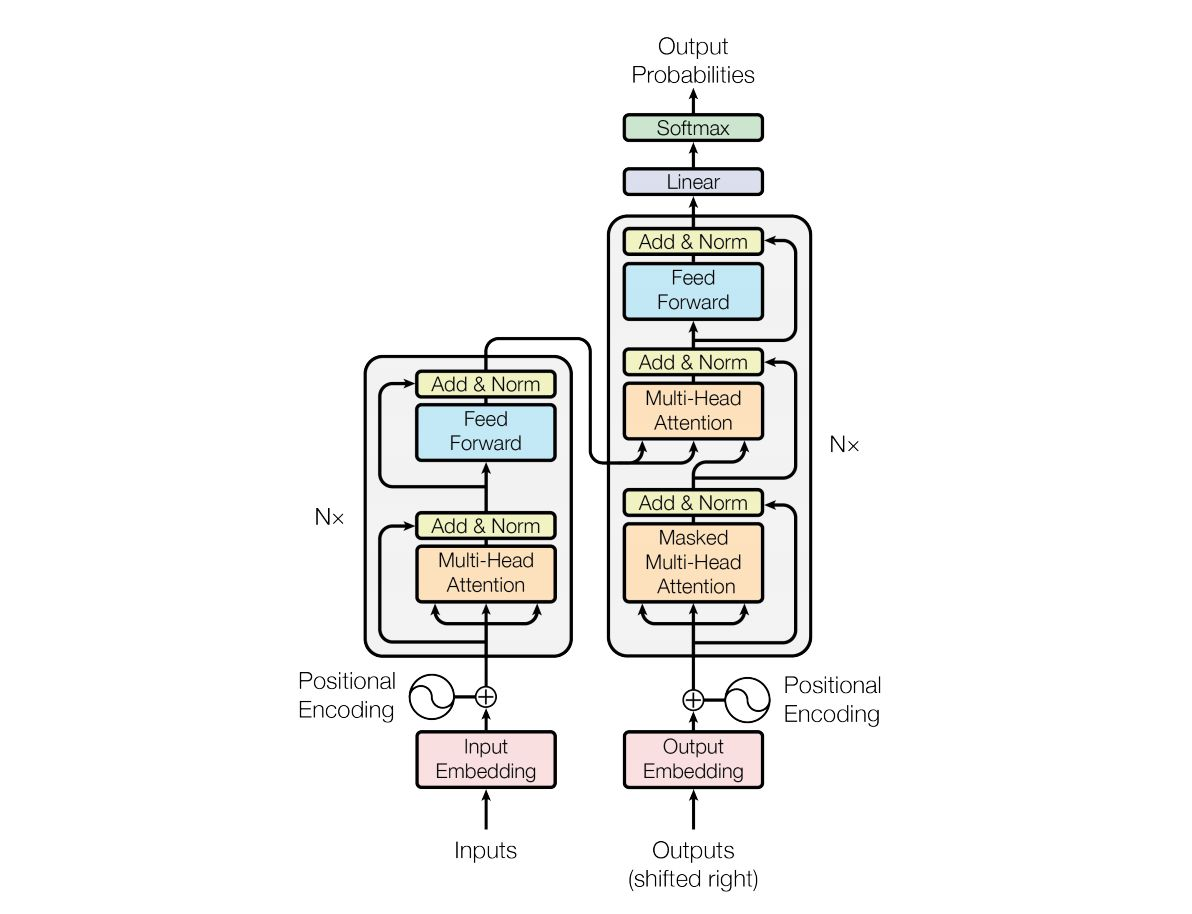
embedding
嵌入层,将每个输入符号(单词、字符等)映射为一个高维的词嵌入向量。通常情况下,词嵌入层的参数是在大规模文本语料上预训练得到的,例如使用 Word2Vec、GloVe、FastText 等预训练词嵌入模型
Add & Norm
- add:将a和a经过注意力机制后得到b相加
- norm:layer norm,对上面相加的结果做层归一化
- layer:每个数据样本所有特征特征做μ=0,σ=1。适用于序列数据或者批次大小变化较大的情况,通常应用于循环神经网络等网络的每一层输出。
- batch:每个批次同一维特征做μ=0,σ=1。适用于深度网络中的卷积层或者全连接层;
feed forward
前馈神经网络,由两个线性层(全连接层)和一个激活函数组成。用于对序列中每个位置的隐藏状态进行非线性变换和映射,从而增强模型对特定位置的特征表示的表达能力
Masked
遮蔽多头注意力机制,会遮盖当前位置之后的数据,确保不会访问到未来的信息,因为这里的是自回归的任务,需要循环预测下一个值。通常采用的掩码方式是将当前位置之后的位置的注意力分数设置为一个非常小的值(如负无穷),或者将对应位置的注意力权重设置为零,以防止模型在计算注意力权重时考虑到未来位置。