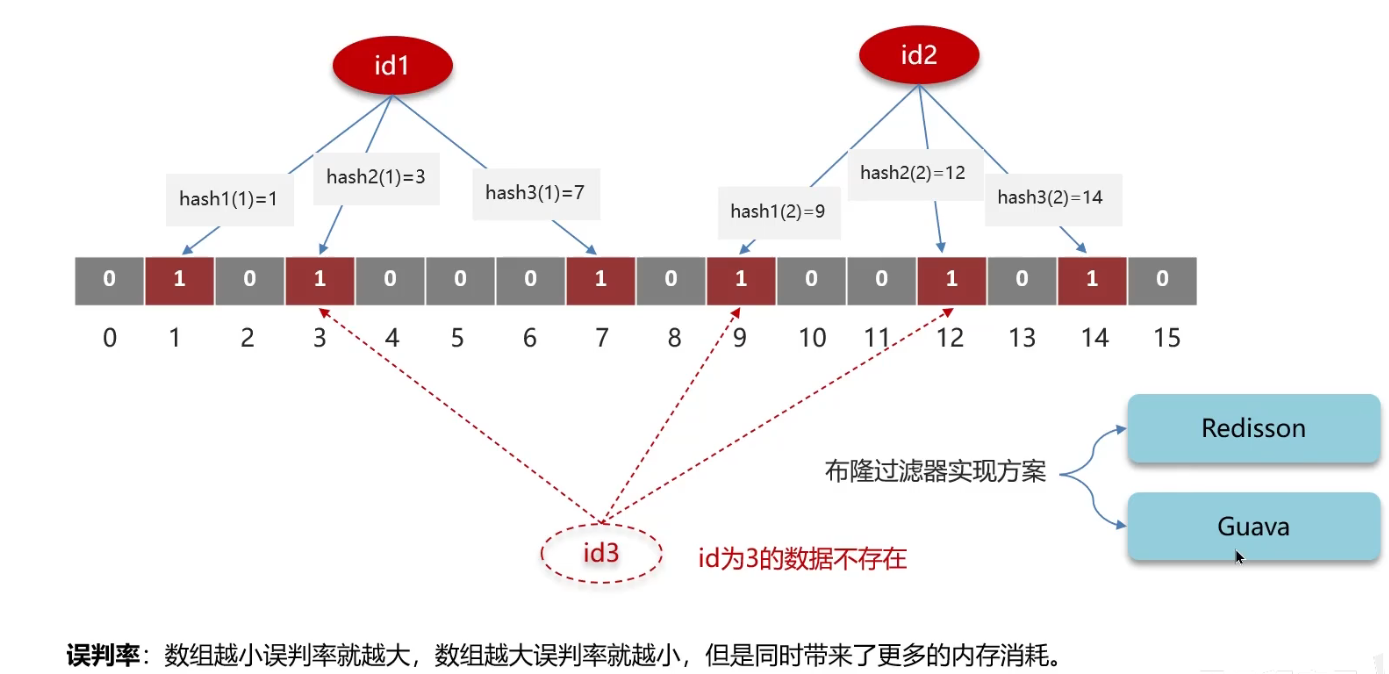
该文得到了一个反常识的结论,当无关的噪声文档放在正确的位置时,实际上有助于提高RAG的准确性。
摘要
检索增强生成(RAG)系统代表了传统大语言模型(大语言模型)的显着进步。 RAG系统通过整合通过信息检索(IR)阶段检索到的外部数据来增强其生成能力,克服了标准大语言模型受限于预训练知识和有限上下文窗口的局限性。 该领域的大多数研究主要集中在 RAG 系统内大语言模型的生成方面。 我们的研究通过彻底、批判性地分析 IR 组件对 RAG 系统的影响来填补这一空白。 本文分析了检索器应具备哪些特征才能有效制定 RAG 的提示,重点关注应检索的文档类型。 我们评估各种元素,例如文档与提示的相关性、它们的位置以及上下文中包含的数量。 除其他见解外,我们的研究结果表明,包含不相关的文档可以意外地将性能提高超过30% 的准确性,这与我们最初关于质量下降的假设相矛盾。 这些结果强调需要开发专门的策略将检索与语言生成模型相结合,从而为该领域的未来研究奠定基础。
1.介绍
大型语言模型(大语言模型)(Brown 等人,2020)在各种任务上表现出了前所未有的熟练程度,从文本生成到复杂的问答(Beeching 等人,2023),到信息检索 (IR) 任务(Kenton 和 Toutanova,2019;Yates 等人,2021)。 然而,大语言模型在处理大型上下文方面受到限制(Vaswani 等人,2017),这一限制导致对其预先训练的知识的依赖增加。 这种限制不仅限制了他们有效管理扩展话语(例如书籍或长时间对话)的能力,而且还增加了产生幻觉的可能性,即模型产生事实上不正确或无意义信息的情况(Roller等人,2021). 为了提高大语言模型生成的响应的准确性,检索增强生成(RAG)系统已成为一种有前途的解决方案(Lewis等人,2020)。 这些系统的主要目的是通过为模型提供对外部信息的访问来提高事实准确性,而不是仅仅依赖于预训练阶段注入的知识,这些知识也可能是有限的或过时的。 RAG 系统的一个关键优势是能够增加大语言模型的有效上下文大小。 他们通过合并一个 IR 组件来实现这一点,该组件在响应生成过程中动态地获取相关的外部信息。 这种方法显着扩展了模型可访问的数据范围,将其上下文窗口扩展到初始输入之外。 RAG 系统的核心由两个基本组件组成:检索器和生成器。 IR组件负责获取外部信息以丰富生成模块的输入。 相比之下,生成组件利用大语言模型的力量来生成连贯且上下文相关的文本。 本研究集中于 RAG 系统的 IR 方面,我们提出以下研究问题: “为了优化 RAG 系统的快速构造,检索器需要哪些基本特征? 目前的猎犬理想吗?”. 我们关注检索器可以获取的三种主要文档类型:相关、相关和不相关。 相关文档包含与查询直接相关的信息,提供直接回答或告知查询的黄金标准数据。 相关文档虽然不直接回答查询,但在语义或上下文上链接到该主题。 例如,如果有人询问拿破仑的马的颜色,一份表达拿破仑妻子的马的颜色的文档虽然不包含正确的信息,但会高度相关。 另一方面,不相关文档与查询无关,代表检索过程中的一种信息噪声。 我们的分析发现,RAG 系统中相关文档比不相关文档危害更大。 更令人惊讶的是,我们发现嘈杂的文档是有益的,并且可以在准确性方面提高高达35%。 这些结果与 IR 系统面向客户的标准使用形成鲜明对比,在 IR 系统中,相关文档通常被认为比不相关文档更容易被接受。 分析表明,传统的检索技术在这种新范式中可能不是最佳的,因此需要开发适合集成检索与语言生成模型的特定需求的专门方法。 这些见解凸显了该领域新颖研究的潜力,为在 RAG 系统背景下系统地重新思考和推进 IR 策略铺平了道路。 总而言之,我们的贡献是:(a)我们进行了首次全面研究,重点关注检索到的文档如何影响 RAG 框架。 我们的目标是了解检索器所需的特性,以优化 RAG 系统的快速构建; (b) 这项研究发现,在 RAG 系统中,相关文档比不相关文档的危害更大。 事实上,与传统观点相反,我们发现嘈杂(不相关)的文档在准确性方面可以将性能提高高达 35%; © 我们提出了利用这一现象的策略。 同时,我们强调需要重新考虑信息检索策略,为未来的研究工作铺平道路。
2.相关作品
2.1.生成语言模型
现代大语言模型时代的开始可以追溯到题为《Attention Is All You Need》的开创性论文(Vaswani 等人,2017)。 这项工作引入了 Transformer 架构,该框架采用注意力机制而不是循环层,使模型能够捕获数据内的全局依赖关系。 继这一创新之后,2018 年引入了 BERT(来自 Transformers 的双向编码器表示)(Kenton 和 Toutanova,2019)。 BERT 利用深度双向、无监督的语言表示,代表了文本上下文理解领域的重大进步。 随着生成式预训练 Transformer (GPT) 的发展,基于 Transformer 的模型继续发展(Radford 等人,2018)。 其后继者 GPT-2 (Radford 等人, 2019) 在此基础上进行了扩展,推出了更大规模的模型,并在无需特定任务训练的情况下在各种语言任务中展示了改进的性能。 随后的迭代 GPT-3 (Brown 等人, 2020) 代表了模型规模和能力的进一步增强,特别是在少样本学习领域。 与此同时,基于并扩展 Transformer 架构的专用模型和变体不断增多。 值得注意的是,Google 的 T5(文本到文本传输转换器)(Raffel 等人,2020) 通过将 NLP 任务重新定义为文本到文本问题,提出了一个统一的框架。 Google 和 CMU 同年开发的 XLNet (Yang 等人, 2019) 通过采用基于排列的训练方法超越了 BERT 的性能。 最后,最近大型公开语言模型的产量激增。 一些演员已经发布了他们的模型,最引人注目的是 Llama (Touvron 等人, 2023a, b)、Falcon (Almazrouei 等人, 2023)、Mosaic MPT ( Team 等人, 2023), 和 Phi (Li 等人, 2023; Javaheripi 等人, 2023)。
2.2.信息检索
IR 领域起源于基于文本的系统。 基础方法,例如向量空间模型(VSM)(Wong等人,1985)和词频-逆文档频率(TF-IDF)(Ramos等人,2003) t1>,为量化文本相似度提供了基础。 这些稀疏检索方法,其中 BM25 是其最著名的当前迭代(Robertson 等人,2009),其特点是使用高维和稀疏特征向量,对于开发早期 IR 系统至关重要。 IR 的一个重大演变是稀疏检索器和密集检索器之间的区别。 稀疏检索器(例如 VSM 和 TF-IDF)依赖于精确的关键字匹配,并且由于其可解释性和简单性,对于大规模文档检索非常有效。 然而,他们常常难以理解单词之间的语义关系(Manning 等人,2008)。 相比之下,由于深度学习的进步而出现的密集检索器利用低维密集向量进行表示。 第一个真正改进稀疏方法的是 DPR (Karpukhin 等人,2020a),随后出现了大量其他技术(Izacard 等人,2021;Khattab 和 Zaharia ,2020)。
2.3.检索和生成
RAG 代表了机器学习的重大转变,结合了基于检索的模型和生成模型的优势。 这个想法最早起源于(程等人,2021)和(张等人,2019)等作品,但RAG的概念在中得到普及(Lewis 等人,2020),引入了一种将密集通道检索器与序列到序列模型相结合的模型,展示了知识密集型任务的实质性改进。 类似的方法几乎同时出现,例如(Guu 等人, 2020; Borgeaud 等人, 2022)。 我们建议读者参考(Mialon 等人, 2023) 进行有关增强语言模型的调查。 研究人员和从业者最近开始探索这些 RAG 系统的内部工作原理。 值得注意的是,(Sauchuk 等人,2022)分析了不同类型文档对级联 IR/NLP 系统的影响。 然而,他们没有使用大语言模型,因此得出了几乎相反的结论。 其他作品试图研究 Transformer 对输入的关注程度(Sun 等人,2021;Khandelwal 等人,2018;Liu 等人,2023;Ram 等人,2023)。 在本文中,我们希望首次全面分析在 RAG 系统中使用检索器模块的影响,研究几个关键因素的影响,例如文档的位置、类型以及使用的数量。
3.RAG
RAG 提供了一个强大的框架,可以成功应用于许多问题和下游任务。 在本文中,我们探讨了 RAG 在问答领域的应用,这可以说是其最流行的应用。
3.1.开放域问答

3.2.检索器

3.3.推理器

4.实验方法
在本节中,我们详细介绍实验框架。 我们将从描述实验中使用的数据开始。 这为检查检索器可以返回并传递给大语言模型的文档类型奠定了基础,这将是本节的主要焦点。
4.1.自然问题数据集
自然问题 (NQ) 数据集(Kwiatkowski 等人,2019) 是源自 Google 搜索数据的现实世界查询的大规模集合。 数据集中的每个条目都包含用户查询和包含答案的相应维基百科页面。 该数据集旨在促进自然语言理解和开放域问答的研究,提供丰富的现实世界问题和上下文相关答案的来源。 NQ-open 数据集(Lee 等人,2019) 是 NQ 数据集的子集,其不同之处在于消除了将答案链接到特定维基百科段落的限制,从而模仿了更通用的信息检索场景,类似于网络搜索。 这种开放域的性质极大地影响了我们的实验设计,特别是在文档的选择和分类方面。 遵循 Lee 等人 (2019) 的方法,我们回答查询的主要来源是截至 2018 年 12 月 20 日的英文维基百科转储。 与密集段落检索 (DPR) 方法 (Karpukhin 等人,2020b) 一致,此转储中的每篇维基百科文章都被分割为 100 单词的非重叠段落。 开放域问答中的一个重大挑战是维基百科转储和数据集中的问答对之间潜在的时间不匹配,这可能导致转储不包含答案的情况,如 AmbigQA 研究中所强调的(敏等人,2020)。 为了缓解这个问题,我们将原始 NQ 数据集中的黄金文档集成到我们的维基百科文档集中。 鉴于我们任务的开放域性质,可能存在与查询相关的其他文档,即包含答案,但我们不会将它们视为黄金。 最终数据集包含 21,035,236训练文档,其中 72,209 查询位于集合中,2,889位于测试集中。
详情内容见https://arxiv.org/abs/2401.14887