网络爬虫:爬取假数据
文章目录
- 网络爬虫:爬取假数据
- 前言
- 一、项目介绍:
- 二、项目来源:
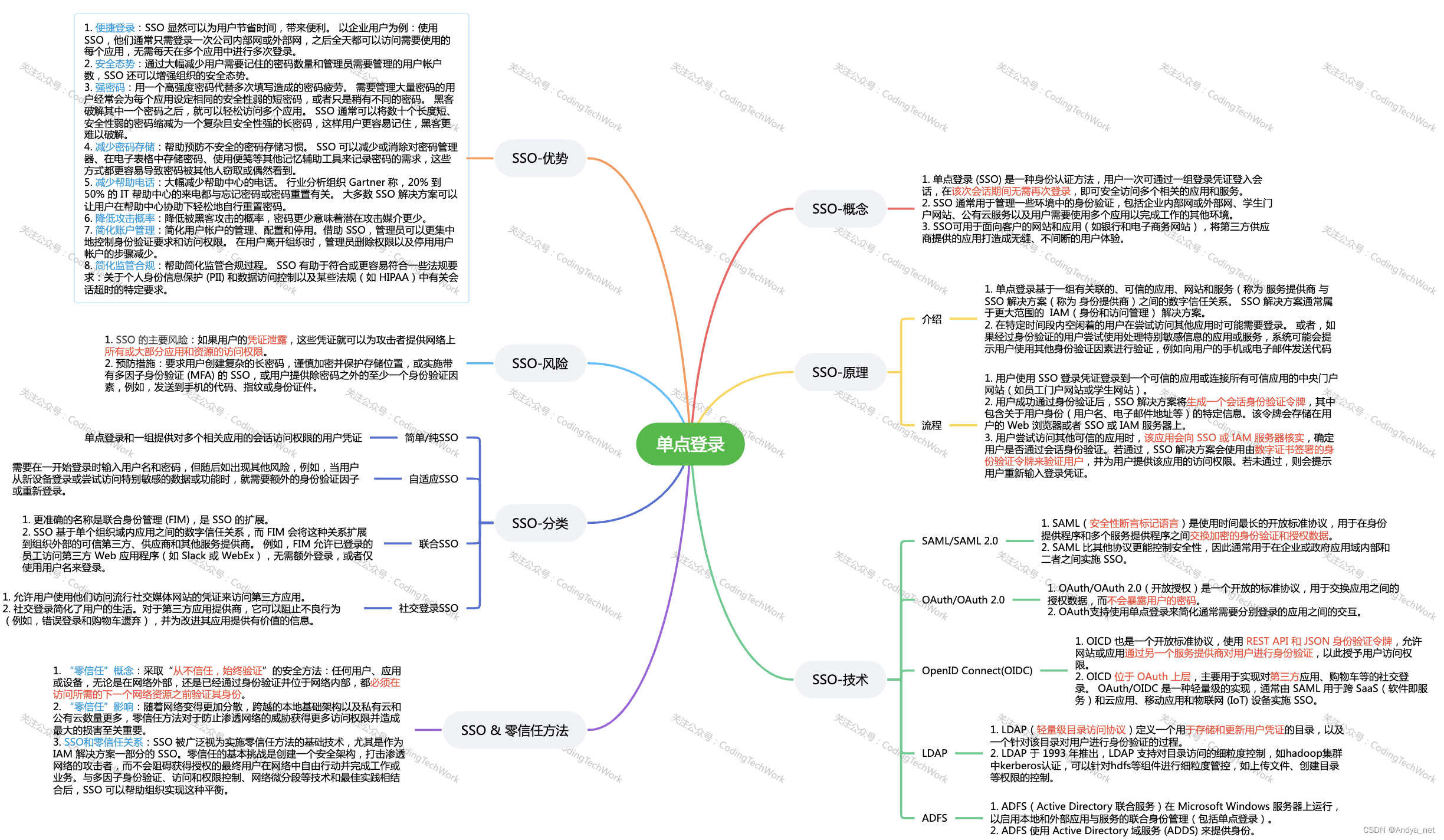
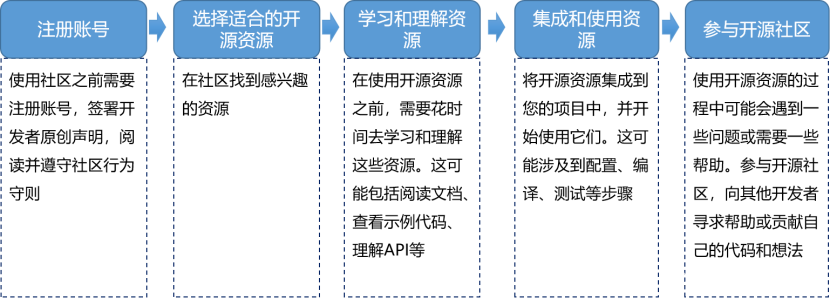
- 三、架构图:(流程图)
- 四、使用了什么技术:(知识点)
- 五、结果示意图:
- 六、具体代码与分析:
- 1.在web网页获取数据(全部数据打包为字符串)
- (1)记录网址
- (2)使用crawler方法根据网址获取web网页上的数据(未处理)
- 这是我们从web网页上爬取的“乱数据”
- 2.初步获取姓氏,名字(根据正则表达式)获取3个集合
- (1)通过正则表达式处理“从网页爬取的乱数据”并放到集合当中
- (2)将姓氏、名字彻底拆开来,再放到集合当中
- 在网页上“姓氏”,“男生名字”,“女生名字”的样式分别为:
- 姓氏:
- 男生名字:
- 女生名字:
- (1)通过正则表达式处理“从网页爬取的乱数据”并放到集合当中:
- 效果图:
- (2)将姓氏、名字彻底拆开来,再放到集合当中:
- 3.生成指定数量的男生和女生(姓名-性别-年龄)
- 七、总结:需要注意的地方 && 改进之处:
- (1)我们可以将这个“随机生成的男生,女生”保存到本地:(IO)
- (2)如果网址失效了 或 网页内容改变了,上面的正则表达式就失效了,须要我们自己去编写regex。
- 八、个人思考:
- 九、补充:使用hutool包(稀里糊涂地就写完了代码)
- 拷贝jar包,直接使用就好了
- 使用hutool的好处:我们不用自己写:crawler 和 getData方法
- 十、附录:完整代码
前言
学习java过程中,值得回忆的代码。

提示:以下是本篇文章正文内容:
一、项目介绍:
爬取web页面上的百家姓和男生,女生的名字,然后组合成一个完整的姓名。
你可以指定须要的 boyCount 和 girlCount,然后会返回一个集合(顺序是打乱的,集合元素是一个类似于“傅彬远-男-19”的字符串)
二、项目来源:
黑马阿伟java系列课程:😊链接在这里😊
三、架构图:(流程图)

四、使用了什么技术:(知识点)
1.URL对象,爬取网页上的内容
2.书写正则表达式,根据正则表达式爬取内容
3.处理,拼接字符串的方法
4.Collections.shuffle();// 打乱元素的方法
5.将数据保存到本地(IO流)
五、结果示意图:

六、具体代码与分析:
1.在web网页获取数据(全部数据打包为字符串)
(1)记录网址
(2)使用crawler方法根据网址获取web网页上的数据(未处理)
//1.定义变量记录网址:百家姓,男生名,女生名
String familyNameNet = "https://hanyu.baidu.com/shici/detail?pid=0b2f26d4c0ddb3ee
693fdb1137ee1b0d&from=kg0";
String boyNameNet = "http://www.haoming8.cn/baobao/10881.html";
String girlNameNet = "http://www.haoming8.cn/baobao/7641.html";
//2.从"网址"中爬取数据(webCrawler方法)
//注意:要去确保自己可以上网,连接了WiFi
String familyNameStr = webCrawler(familyNameNet);
String boyNameStr = webCrawler(boyNameNet);
String girlNameStr = webCrawler(girlNameNet);
// webCrawler方法:从网页爬取数据
private static String webCrawler(String net) throws IOException {
StringBuilder sb = new StringBuilder();
URL url = new URL(net);// 注意1:根据参数创建一个url对象
// 返回一个 URLConnection 对象,它表示到 URL 所引用的远程对象的连接。
URLConnection conn = url.openConnection();
// 返回从此打开的连接读取的输入流。
// conn.getInputStream()返回一个字节流,InputStreamReader是转换流,字节流转为字符流,
InputStreamReader isr = new InputStreamReader(conn.getInputStream());
int ch;//注意:为什么是int ch ?而不是char ch?
while ((ch = isr.read()) != -1) {// 每次读取一个字符,直到读完为止
sb.append((char) ch);// 拼接
}
isr.close();
return sb.toString();// 返回
}
这是我们从web网页上爬取的“乱数据”

2.初步获取姓氏,名字(根据正则表达式)获取3个集合
(1)通过正则表达式处理“从网页爬取的乱数据”并放到集合当中
(2)将姓氏、名字彻底拆开来,再放到集合当中
在网页上“姓氏”,“男生名字”,“女生名字”的样式分别为:
姓氏:

男生名字:

女生名字:

(1)通过正则表达式处理“从网页爬取的乱数据”并放到集合当中:

//3.通过正则表达式,筛选数据1(getData方法)
ArrayList<String> familyNameTempList = getData(familyNameStr, "(.{4})(,|。)", 1);
ArrayList<String> boyNameTempList = getData(boyNameStr, "([\\u4E00-\\u9FA5]{2})(、|。)", 1);
ArrayList<String> girlNameTempList = getData(girlNameStr, "(.. ){4}..", 0);
//方法2:getData:去除前端代码,返回初次筛选数据的集合:
//参数:完整字符串,正则表达,分组号
private static ArrayList<String> getData(String str, String regex, int index) {
ArrayList<String> list = new ArrayList<>();
// 注意1:按照正则表达式规则,从字符串中,取获取数据
// 1.编译规则---2.创建匹配器,绑定文本---3.寻找符合要求的数据---4.返回数据
// 将给定的正则表达式编译到模式中。
Pattern pattern = Pattern.compile(regex);
// 创建匹配给定输入与此模式的匹配器。
Matcher matcher = pattern.matcher(str);
// 尝试查找与该模式匹配的输入序列的下一个子序列。
while (matcher.find()) {
// 返回由以前匹配操作所匹配的输入子序列。------注意2:有分组
list.add(matcher.group(index));
}
return list;
}
效果图:



(2)将姓氏、名字彻底拆开来,再放到集合当中:

// 4.进一步处理数据:
// familyNameList (姓氏)
// 处理方案:将每一个姓氏拆开,并添加到一个新的集合当中
ArrayList<String> familyNameList = new ArrayList<>();
for (String familyNames : familyNameTempList) {
for (int i = 0; i < familyNames.length(); i++) {
//注意:为了统一,我们最好都用字符串表示姓氏(虽然这里的形式都是单个字符)
familyNameList.add(familyNames.charAt(i) + "");
}
}
// boyNameList(男名)
// 处理方案:去除其中的重复元素
// 法1:用hashset去重-------法2:list集合,元素不重复,才添加到集合当中。
// 这里使用第2种
ArrayList<String> boyNameList = new ArrayList<>();
for (String boyName : boyNameTempList) {
if (!boyNameList.contains(boyName)) {
boyNameList.add(boyName);
}
}
// girlNameList(女名)
// 处理方案:用split将空格切割,得到每一个女生的名字,添加的集合当中
ArrayList<String> girlNameList = new ArrayList<>();
for (String girlNames : girlNameTempList) {
// 注意:split方法:根据给定正则表达式的匹配拆分此字符串。返回值是“数组”
String[] girlNames2 = girlNames.split(" ");
for (int i = 0; i < girlNames2.length; i++) {
girlNameList.add(girlNames2[i]);
}
}
3.生成指定数量的男生和女生(姓名-性别-年龄)
// 生成想要数据集合(getInfos方法)--注意:要指定集合中男生,女生的个数
ArrayList<String> list = getInfos(familyNameList, boyNameList, girlNameList
, 70, 50);
// 打乱
Collections.shuffle(list);
// 方法3:getInfos:根据“姓氏”,“男名”,“女名”集合,返回一个集合
// 参数:3个集合,boyCount,girlCount
private static ArrayList<String> getInfos(ArrayList<String> familyNameList,
ArrayList<String> boyNameList, ArrayList<String> girlNameList,
int boyCount, int girlCount) {
ArrayList<String> list = new ArrayList<>();
Random r = new Random();// 随机生成年龄
// 获取男生名字集合:(hashset:防止出现重复的名字)
HashSet<String> boys = new HashSet<>();
while (true) {
if (boys.size() == boyCount) break;
Collections.shuffle(familyNameList);
Collections.shuffle(boyNameList);
boys.add(familyNameList.get(0) + boyNameList.get(0));
}
// 获取女生名字集合:
HashSet<String> girls = new HashSet<>();
while (true) {
if (girls.size() == girlCount) break;
Collections.shuffle(familyNameList);
Collections.shuffle(girlNameList);
girls.add(familyNameList.get(0) + girlNameList.get(0));
}
// 拼接男生信息:
for (String boy : boys) {
int age = r.nextInt(10) + 18;//18~27
list.add(boy + "-男-" + age);
}
// 拼接女生信息:
for (String girl : girls) {
int age = r.nextInt(8) + 18;//18~25
list.add(girl + "-女-" + age);
}
// 返回最后的集合:
return list;
}
七、总结:需要注意的地方 && 改进之处:
(1)我们可以将这个“随机生成的男生,女生”保存到本地:(IO)
BufferedWriter bw = new BufferedWriter(new FileWriter("myiotest1\\names.txt"));
for(String str : list) {
bw.write(str);
bw.newLine();
}
bw.close();
(2)如果网址失效了 或 网页内容改变了,上面的正则表达式就失效了,须要我们自己去编写regex。
八、个人思考:
1.通过一整个流程下来,我须要熟悉如何分析一个项目,有哪些步骤
2.这只是一个很简单的“爬虫引用”,是用java实现的,那么向python实现的爬虫又是什么样的呢?
可以通过之后的学习,进一步了解到“爬虫”有关的进阶知识。
九、补充:使用hutool包(稀里糊涂地就写完了代码)
拷贝jar包,直接使用就好了
😊hutool网址😊
使用hutool的好处:我们不用自己写:crawler 和 getData方法

// 原本的代码:
//2.爬取数据,把网址上所有的数据拼接成一个字符串
String familyNameStr = webCrawler(familyNameNet);
String boyNameStr = webCrawler(boyNameNet);
String girlNameStr = webCrawler(girlNameNet);
//3.通过正则表达式,把其中符合要求的数据获取出来
ArrayList<String> familyNameTempList = getData(familyNameStr, "(.{4})(,|。)", 1);
ArrayList<String> boyNameTempList = getData(boyNameStr, "([\\u4E00-\\u9FA5]{2})(、|。)", 1);
ArrayList<String> girlNameTempList = getData(girlNameStr, "(.. ){4}..", 0);
// 使用hutool后的代码:
String familyNameStr = HttpUtil.get(familyNameNet);
String boyNameStr = HttpUtil.get(boyNameNet);
String girlNameStr = HttpUtil.get(girlNameNet);
List<String> familyNameTempList = ReUtil.findAll("(.{4})(,|。)", familyNameStr, 1);
List<String> boyNameTempList = ReUtil.findAll("([\\u4E00-\\u9FA5]{notes})(、|。)", boyNameStr, 1);
List<String> girlNameTempList = ReUtil.findAll("(.. ){4}..", girlNameStr, 0);
十、附录:完整代码
import java.io.BufferedWriter;
import java.io.FileWriter;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
import java.net.URLConnection;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashSet;
import java.util.Random;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class Test1 {
public static void main(String[] args) throws IOException {
/*
制造假数据:
获取姓氏:https://hanyu.baidu.com/shici/detail?pid=0b2f26d4c0ddb3ee693fdb1137ee1b0d&from=kg0
获取男生名字:http://www.haoming8.cn/baobao/10881.html
获取女生名字:http://www.haoming8.cn/baobao/7641.html
*/
//1.定义变量记录网址
String familyNameNet = "https://hanyu.baidu.com/shici/detail?pid=0b2f26d4c0ddb3ee693fdb1137ee1b0d&from=kg0";
String boyNameNet = "http://www.haoming8.cn/baobao/10881.html";
String girlNameNet = "http://www.haoming8.cn/baobao/7641.html";
//2.爬取数据,把网址上所有的数据拼接成一个字符串
// 这个时候的数据是“杂乱”的
String familyNameStr = webCrawler(familyNameNet);
String boyNameStr = webCrawler(boyNameNet);
String girlNameStr = webCrawler(girlNameNet);
//3.通过正则表达式,把其中符合要求的数据获取出来
// 这个时候数据经过了处理
ArrayList<String> familyNameTempList = getData(familyNameStr, "(.{4})(,|。)", 1);
ArrayList<String> boyNameTempList = getData(boyNameStr, "([\\u4E00-\\u9FA5]{2})(、|。)", 1);
ArrayList<String> girlNameTempList = getData(girlNameStr, "(.. ){4}..", 0);
//4.处理数据
//familyNameTempList(姓氏)
//处理方案:把每一个姓氏拆开并添加到一个新的集合当中
ArrayList<String> familyNameList = new ArrayList<>();
for (String str : familyNameTempList) {
//str 赵钱孙李 周吴郑王 冯陈褚卫 蒋沈韩杨
for (int i = 0; i < str.length(); i++) {
char c = str.charAt(i);
familyNameList.add(c + "");
}
}
//boyNameTempList(男生的名字)
//处理方案:去除其中的重复元素
ArrayList<String> boyNameList = new ArrayList<>();
for (String str : boyNameTempList) {
if (!boyNameList.contains(str)) {
boyNameList.add(str);
}
}
//girlNameTempList(女生的名字)
//处理方案:把里面的每一个元素用空格进行切割,得到每一个女生的名字
ArrayList<String> girlNameList = new ArrayList<>();
for (String str : girlNameTempList) {
String[] arr = str.split(" ");
for (int i = 0; i < arr.length; i++) {
girlNameList.add(arr[i]);
}
}
//5.生成数据
//姓名(唯一)-性别-年龄
ArrayList<String> list = getInfos(familyNameList, boyNameList, girlNameList, 70, 50);
Collections.shuffle(list);
//System.out.println(list);
//
// //6.写出数据
// BufferedWriter bw = new BufferedWriter(new FileWriter("myiotest\\names.txt"));
// for (String str : list) {
// bw.write(str);
// bw.newLine();
// }
// bw.close();
}
/*
* 作用:
* 获取男生和女生的信息:张三-男-23
*
* 形参:
* 参数一:装着姓氏的集合
* 参数二:装着男生名字的集合
* 参数三:装着女生名字的集合
* 参数四:男生的个数
* 参数五:女生的个数
* */
public static ArrayList<String> getInfos(ArrayList<String> familyNameList, ArrayList<String> boyNameList, ArrayList<String> girlNameList, int boyCount, int girlCount) {
//1.生成男生不重复的名字
HashSet<String> boyhs = new HashSet<>();
while (true) {
if (boyhs.size() == boyCount) {
break;
}
//随机
Collections.shuffle(familyNameList);
Collections.shuffle(boyNameList);
boyhs.add(familyNameList.get(0) + boyNameList.get(0));
}
//2.生成女生不重复的名字
HashSet<String> girlhs = new HashSet<>();
while (true) {
if (girlhs.size() == girlCount) {
break;
}
//随机
Collections.shuffle(familyNameList);
Collections.shuffle(girlNameList);
girlhs.add(familyNameList.get(0) + girlNameList.get(0));
}
//3.生成男生的信息并添加到集合当中
ArrayList<String> list = new ArrayList<>();
Random r = new Random();
//【18 ~ 27】
for (String boyName : boyhs) {
//boyName依次表示每一个男生的名字
int age = r.nextInt(10) + 18;
list.add(boyName + "-男-" + age);
}
//4.生成女生的信息并添加到集合当中
//【18 ~ 25】
for (String girlName : girlhs) {
//girlName依次表示每一个女生的名字
int age = r.nextInt(8) + 18;
list.add(girlName + "-女-" + age);
}
return list;
}
/*
* 作用:根据正则表达式获取字符串中的数据
* 参数一:
* 完整的字符串
* 参数二:
* 正则表达式
* 参数三:
* 获取数据
* 0:获取符合正则表达式所有的内容
* 1:获取正则表达式中第一组数据
* 2:获取正则表达式中第二组数据
* ...以此类推
*
* 返回值:
* 真正想要的数据
*
* */
private static ArrayList<String> getData(String str, String regex, int index) {
//1.创建集合存放数据
ArrayList<String> list = new ArrayList<>();
//2.按照正则表达式的规则,去获取数据
Pattern pattern = Pattern.compile(regex);
//按照pattern的规则,到str当中获取数据
Matcher matcher = pattern.matcher(str);
while (matcher.find()) {
list.add(matcher.group(index));
}
return list;
}
/*(从web上爬取数据)(粗糙)(未处理)
作用:从web页面上爬取数据,把数据拼接成字符串返回
形参:网址net(string类型)
返回:所有数据组成的字符串
*/
public static String webCrawler(String net) throws IOException {
//1.定义StringBuilder拼接爬取到的数据
StringBuilder sb = new StringBuilder();
//2.创建一个URL对象
URL url = new URL(net);
//3.链接上这个网址
//细节:保证网络是畅通的,而且这个网址是可以链接上的。
URLConnection conn = url.openConnection();
//4.读取数据
InputStreamReader isr = new InputStreamReader(conn.getInputStream());
int ch;
while ((ch = isr.read()) != -1) {
sb.append((char) ch);
}
//5.释放资源
isr.close();
//6.把读取到的数据返回
return sb.toString();
}
}