目录
1. 前言
2. include常规路由分发
3. include源码解析
4. 路由分发的第二种写法
5. 路由分发的第三种写法
6. 小结
7. 有关namespace
8. 最后
1. 前言
本篇文章主要是讲解路由分发的三种方式。当然,你可能在想,一般做路由分发只需要一个include就能搞定,为什么还有另外三种方式呢。
这个就要追溯到Django的底层源码了, 通过研究Django中include的底层源码了,从而发现另外两种作路由分发的方式。
2. include常规路由分发
在了解include方法之前,我们应该了解什么是路由分发:
路由分发:传入的HTTP请求映射到相应的视图函数或处理程序的过程 。通过前缀匹配,将url分发到相应的app里面,在对相应的app里面的url路由进行再一次匹配。
通俗来讲,就是我们在app里面单独定义url,通过全局的前缀匹配之后,再去相应的app里面进行路由匹配
inlcude方法,常用于作路由分发 , 可以将剩下的路由交给app去匹配:
urls.py
urlpatterns = [
path('blog/', include('app02.urls')),
]app02.urls.py
from django.contrib import admin
from django.urls import path, re_path, include
from app02 import views
urlpatterns = [
path('', views.test, name='index'),
path('<int:post_id>/', views.test, name='detail'),
]
然后我们在进行匹配的时候,就需要先匹配前缀,再匹配后面的:
![]()
我们在访问具体url的时候,就需要先进行前缀blog匹配,然后再进入到app02里面进行匹配。
3. include源码解析
path('blog/', include('app02.urls')),
我们对当前这条代码进行解析 ,以下是inlcude的源码:
def include(arg, namespace=None):
app_name = None
if isinstance(arg, tuple):
# Callable returning a namespace hint.
try:
urlconf_module, app_name = arg
except ValueError:
if namespace:
raise ImproperlyConfigured(
"Cannot override the namespace for a dynamic module that "
"provides a namespace."
)
raise ImproperlyConfigured(
"Passing a %d-tuple to include() is not supported. Pass a "
"2-tuple containing the list of patterns and app_name, and "
"provide the namespace argument to include() instead." % len(arg)
)
else:
# No namespace hint - use manually provided namespace.
urlconf_module = arg
if isinstance(urlconf_module, str):
urlconf_module = import_module(urlconf_module)
patterns = getattr(urlconf_module, "urlpatterns", urlconf_module)
app_name = getattr(urlconf_module, "app_name", app_name)
if namespace and not app_name:
raise ImproperlyConfigured(
"Specifying a namespace in include() without providing an app_name "
"is not supported. Set the app_name attribute in the included "
"module, or pass a 2-tuple containing the list of patterns and "
"app_name instead.",
)
namespace = namespace or app_name
# Make sure the patterns can be iterated through (without this, some
# testcases will break).
if isinstance(patterns, (list, tuple)):
for url_pattern in patterns:
pattern = getattr(url_pattern, "pattern", None)
if isinstance(pattern, LocalePrefixPattern):
raise ImproperlyConfigured(
"Using i18n_patterns in an included URLconf is not allowed."
)
return (urlconf_module, app_name, namespace)
其中ags就是我们传递进来的路径字符串

这里,主要是判断是否是元组,我们传递进来的是字符串,所以可以先忽略这里

其中,最重要的就是patterns和app_name
这都是通过反射getattr从上面导入进来的模块里面拿的数据,也就是app02里面的urls里面的urlpatterns
这里,主要是跟命名空间相关的 :

定义namespace后,就需要定义好app_name
命名空间在后面聊
其实最后,总结下来,也就这些内容:
def include(arg = 'app02.urls', namespace=None):
app_name = None
urlconf_module = arg
if isinstance(urlconf_module, str):
urlconf_module = import_module(urlconf_module)
patterns = getattr(urlconf_module, "urlpatterns", urlconf_module)
app_name = getattr(urlconf_module, "app_name", app_name)
namespace = namespace or app_name
return (urlconf_module, app_name, namespace)返回的是一个元组:
-
urlconf_module:导入的模块(app02.urls)
-
app_name:app02下的app名字,与命名空间相挂钩
-
namespace:命名空间
4. 路由分发的第二种写法
所以,通过源码,我们得出了路由分发的第二种写法:
path('blog/', (importlib.import_module('app02.urls'), None, None))
其中第一个就是以上的通过动态导入的字符串路径,第二个和第三个都是与命名空间相关的
5. 路由分发的第三种写法
我们先看一下_path的源码:
def _path(route, view, kwargs=None, name=None, Pattern=None):
from django.views import View
if isinstance(view, (list, tuple)):
# For include(...) processing.
pattern = Pattern(route, is_endpoint=False)
urlconf_module, app_name, namespace = view
return URLResolver(
pattern,
urlconf_module,
kwargs,
app_name=app_name,
namespace=namespace,
)
elif callable(view):
pattern = Pattern(route, name=name, is_endpoint=True)
return URLPattern(pattern, view, kwargs, name)
elif isinstance(view, View):
view_cls_name = view.__class__.__name__
raise TypeError(
f"view must be a callable, pass {view_cls_name}.as_view(), not "
f"{view_cls_name}()."
)
else:
raise TypeError(
"view must be a callable or a list/tuple in the case of include()."
)很显然,我们第二个view参数传递的是一个元组,因此走的就是第一条路:
最后返回的就是一个URLResolver对象 , 常规的是返回一个URLPattern对象

我们稍微做一下整理:
def _path('blog/', (importlib.import_module('app02.urls'), None, None) ):
from django.views import View
pattern = RoutePattern('blog/', is_endpoint=False)
urlconf_module, app_name, namespace = importlib.import_module('app02.urls'), None, None
return URLResolver(
RoutePattern('blog/', is_endpoint=False),
importlib.import_module('app02.urls'),
None,
app_name=None,
namespace=None,
)实际上,最后就是一个URLResolver的对象。
现在,我们来看URLResolver的reslove函数(如果不清楚为什么看这个的,我们看我以前的一篇文章,就是关于路由匹配源码的解析):
def resolve(self, path):
path = str(path) # path may be a reverse_lazy object
tried = []
match = self.pattern.match(path)
if match:
new_path, args, kwargs = match
for pattern in self.url_patterns:
try:
sub_match = pattern.resolve(new_path)
except Resolver404 as e:
self._extend_tried(tried, pattern, e.args[0].get("tried"))
else:
if sub_match:
# Merge captured arguments in match with submatch
sub_match_dict = {**kwargs, **self.default_kwargs}
# Update the sub_match_dict with the kwargs from the sub_match.
sub_match_dict.update(sub_match.kwargs)
# If there are *any* named groups, ignore all non-named groups.
# Otherwise, pass all non-named arguments as positional
# arguments.
sub_match_args = sub_match.args
if not sub_match_dict:
sub_match_args = args + sub_match.args
current_route = (
""
if isinstance(pattern, URLPattern)
else str(pattern.pattern)
)
self._extend_tried(tried, pattern, sub_match.tried)
return ResolverMatch(
sub_match.func,
sub_match_args,
sub_match_dict,
sub_match.url_name,
[self.app_name] + sub_match.app_names,
[self.namespace] + sub_match.namespaces,
self._join_route(current_route, sub_match.route),
tried,
captured_kwargs=sub_match.captured_kwargs,
extra_kwargs={
**self.default_kwargs,
**sub_match.extra_kwargs,
},
)
tried.append([pattern])
raise Resolver404({"tried": tried, "path": new_path})
raise Resolver404({"path": path})我们看到这一句:

这就相当于遍历了urls里面的整个url_patterns:
这里的self.url_patterns其实是一个方法,它被赋予@cached_property装饰器,代表不需要加上括号,就能执行:
@cached_property:这个函数与property()类似,但增加了缓存,可以直接通过方法名来访问方法,不需要在方法名后添加一对“()”小括号。
重点看以下两句,返回的其实就是app02.urls下面的url_patterns
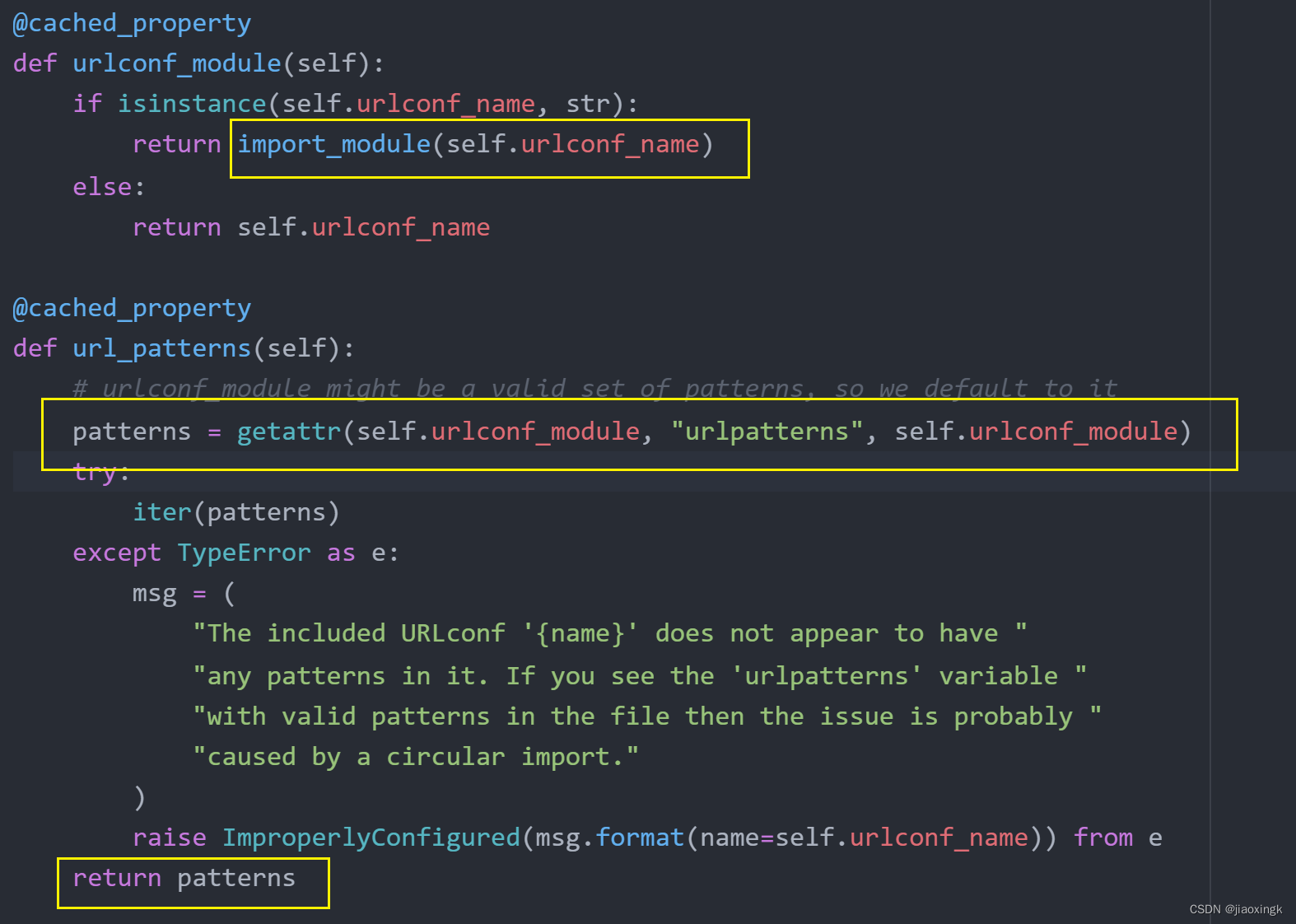
由此,我们引出来第三种编写路由分发的方法:
# 最初
path('web/', (
[
path('v1/', www_views.login, name='v1'),
path('v2/', www_views.login, name='v2'),
],
None,
None)
)
# 解析之后
URLResolver(
RoutePattern('api/',name=None,is_endpoint=False),
[
path('v1/', www_views.login, name='v1'),
path('v2/', www_views.login, name='v2'),
],
None,
app_name=None,
namespace=None
)6. 小结
对于常规的path对象,它的底层是URLPattern类,但是对于路由分发,它的底层就是URLResolver对象了。
from django.urls import path, re_path, include
from apps.www import views
from django.urls import URLPattern, ResolverMatch
from django.urls.resolvers import RoutePattern
from importlib import import_module
from apps.www import views as www_views
from django.urls.resolvers import URLResolver
urlpatterns = [
URLPattern(
RoutePattern("login/", name=None, is_endpoint=True),
views.login,
None,
None
),
URLResolver(
RoutePattern('api/', name=None, is_endpoint=False),
import_module("apps.base.urls"), # 模块对象 from app.base import urls
None,
app_name=None,
namespace=None
),
URLResolver(
RoutePattern('web/', name=None, is_endpoint=False),
[
path('v1/', www_views.login, name='v1'),
path('v2/', www_views.login, name='v2'),
],
None,
app_name=None,
namespace=None
)
]7. 有关namespace
平常做路由的时候,我们有一个参数为name , 主要就是为URL取的别名,在后续操作中更加方便引入该路径:
path('user/', views.User.as_view() , name='user')
但是在做路由分发的时候,涉及到一个命名空间,也就是涉及到相同的name,但是无法去做解析识别。
比如我现在有两个app:app01和app02
以下是两个单独的urls

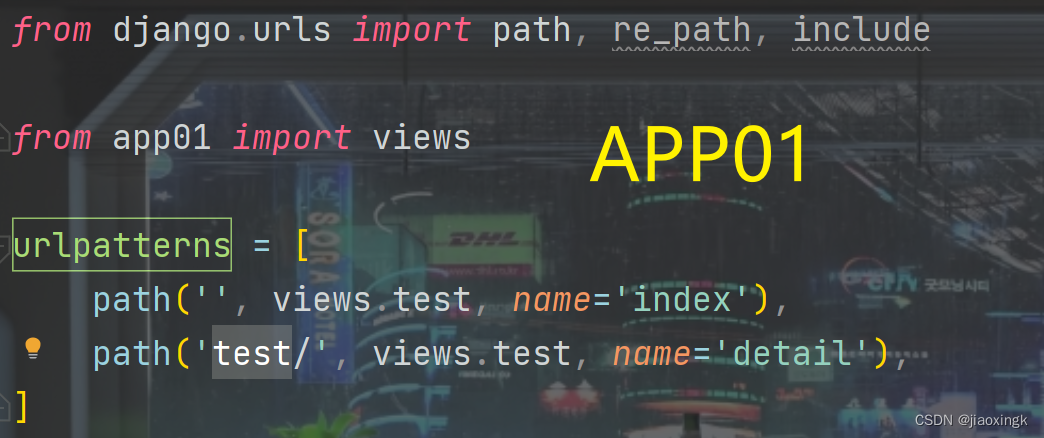
可以看到,两个里面都有name,并且name都是一样的。
如果,这个时候我要来做反向解析:通过name生成url:


可以看到,最后解析出来的是blog2 ,为什么是blog2呢, 这是因为相同的name,第二个把第一个给覆盖了。
这个时候,命名空间的作用就来了,可以很好的做分割:
- 设置namespace
path('blog/', include('app02.urls', namespace='v1')),
path('blog2/', include('app01.urls', namespace='v2'))
- 设置app_name ,使namespace能够找到对应的app


ok,设置好之后,我们再一次进行匹配:
这个时候,我们需要在解析之前加上一个命名空间:


ok,现在就能找到相应的URL啦
8. 最后
路由分发,常规用法是会比较简单的,但是要搞清楚源码的执行流程,还需要花费一定时间和精力,不懂的小伙伴,可以去看看我之前写过的路由定义和路由匹配的源码分析,本篇文章只做了一些简单的介绍。