目录
- 一、元组作为一级索引
- (一)示例1
- (二)示例2
- 二、引入多级索引
- (一)多级索引的创建
- (二)多级索引中的数学选取
首先,导入 NumPy 库和 Pandas 库。
import numpy as np
import pandas as pd
一、元组作为一级索引
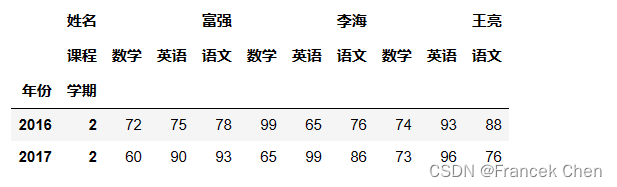
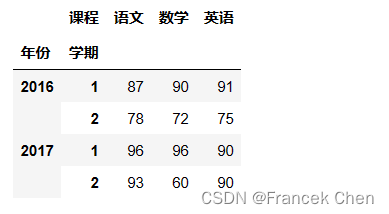
如果想产生如下图所示的学生成绩表:

因为 DataFrame 的行索引/列索引要求是不可变的,因此考虑使用元组做索引是很自然的选择。
s_index = [(2016,1),(2016,2),(2017,1),(2017,2)]
s_columns = [('王亮','语文'),('王亮','数学'),('王亮','英语'),('李海','语文'),('李海','数学'),('李海','英语'),('富强','语文'),('富强','数学'),('富强','英语')]
scores = pd.DataFrame(np.random.randint(60,100,(4,9)),index=s_index,columns=s_columns)
scores

上述由元组构成的行索引/列索引的缺点是使用不够方便,举例说明如下:
(一)示例1
使用元组索引查询时,对 Series 和 DataFrame 的操作不统一,后者需要对元组索引额外加中括号,而前者不用!
1、查询王亮的数学成绩
# 查询王亮的数学成绩
scores[('王亮','数学')]

2、查询2017年第一学期的成绩
# 查询2017年第一学期的成绩
scores.loc[(2017,1)]---出错!相当于scores.loc[2017,1],此时会把2017看成行索引,1看成列索引,而行索引没有2017
对于 DataFrame,应该在元组的外面再加一层中括号,写成:
scores.loc[[(2017,1)]]

当然用位置标签是最简单的:
scores.iloc[2,:]
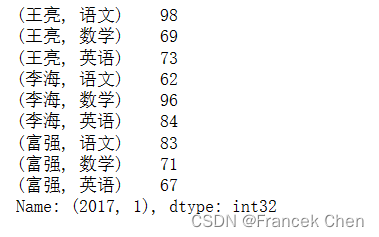
3、查询王亮2017第1学期的成绩
如果用 DataFrame 直接做查询,则表示行索引和列索引的元组外都要多加一层中括号,需要写成:
scores.loc[[(2017,1)],[('王亮','数学')]]

但是对于 Series,则无需在元组外面加一层中括号,例如,先得到 Series 再用元组索引可写成:
scores[('王亮','数学')][(2017,1)]
直接使用位置标签:
scores.iloc[2,1]
69
(二)示例2
查询语文成绩时,需要写循环,无法使用切片中的冒号(:)语法,不太方便。
for col in scores.columns:
if col[1]=='语文':
print(scores[col])

上述例子说明:把元组用作单级索引来表示多个维度的信息,不是一个很好的选择!
二、引入多级索引
(一)多级索引的创建
MultiIndex 对象是 Pandas 标准 Index 的子类,由它来表示多层索引业务。 可以将 MultiIndex 视为一个元组对数组,其中每个元组对都是唯一的。
创建主要有三个相关的函数:from_tuples、from_arrays和from_product,它们都是pd.MultiIndex类的方法
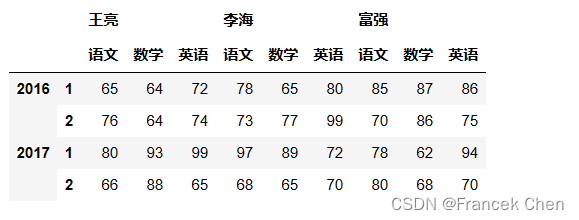
1、使用pd.MultiIndex.from_tuples创建 MultiIndex 对象和 DataFrame 对象
t1 = pd.MultiIndex.from_tuples(s_index)
t1
MultiIndex(levels=[[2016, 2017], [1, 2]],
labels=[[0, 0, 1, 1], [0, 1, 0, 1]])
t2 = pd.MultiIndex.from_tuples(s_columns)
t2
MultiIndex(levels=[['富强', '李海', '王亮'], ['数学', '英语', '语文']],
labels=[[2, 2, 2, 1, 1, 1, 0, 0, 0], [2, 0, 1, 2, 0, 1, 2, 0, 1]])
scores = pd.DataFrame(np.random.randint(60,100,(4,9)),index=t1,columns=t2)
scores
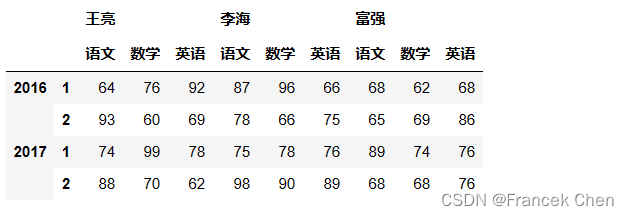
2、使用pd.MultiIndex.from_arrays创建 MultiIndex 对象和 DataFrame 对象
a1 = pd.MultiIndex.from_arrays([[2016,2016,2017,2017],[1,2,1,2]]) # 两级索引都放在列表中,属于花式索引的写法
a1
MultiIndex(levels=[[2016, 2017], [1, 2]],
labels=[[0, 0, 1, 1], [0, 1, 0, 1]])
a2 = pd.MultiIndex.from_arrays([['王亮','王亮','王亮','李海','李海','李海','富强','富强','富强'],
['语文','数学','英语','语文','数学','英语','语文','数学','英语']])
a2
MultiIndex(levels=[['富强', '李海', '王亮'], ['数学', '英语', '语文']],
labels=[[2, 2, 2, 1, 1, 1, 0, 0, 0], [2, 0, 1, 2, 0, 1, 2, 0, 1]])
scores = pd.DataFrame(np.random.randint(60,100,(4,9)),index=a1,columns=a2)
scores
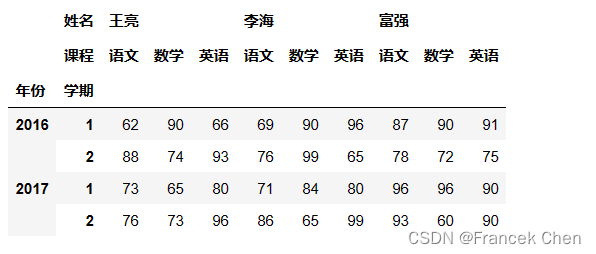
3、使用pd.MultiIndex.from_product创建 MultiIndex 对象和 DataFrame 对象(推荐!)
r_index = pd.MultiIndex.from_product([[2016,2017],[1,2]],names=['年份','学期'])
r_index
MultiIndex(levels=[[2016, 2017], [1, 2]],
labels=[[0, 0, 1, 1], [0, 1, 0, 1]],
names=['年份', '学期'])
c_index = pd.MultiIndex.from_product([['王亮','李海','富强'],['语文','数学','英语']],names=['姓名','课程'])
c_index # 下面显示的levels的内容是系统已经拍过序的
MultiIndex(levels=[['富强', '李海', '王亮'], ['数学', '英语', '语文']],
labels=[[2, 2, 2, 1, 1, 1, 0, 0, 0], [2, 0, 1, 2, 0, 1, 2, 0, 1]],
names=['姓名', '课程'])
np.random.seed(666)
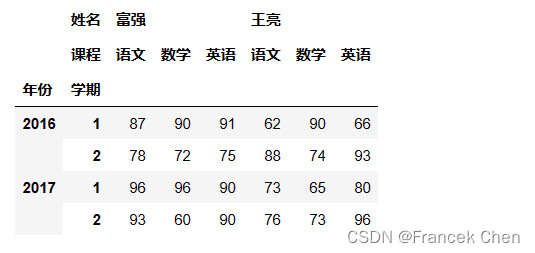
scores = pd.DataFrame(np.random.randint(60,100,(4,9)),index=r_index,columns=c_index)
scores
(二)多级索引中的数学选取
1、基于列索引选取数据
# 基于列的第1层索引选取单列
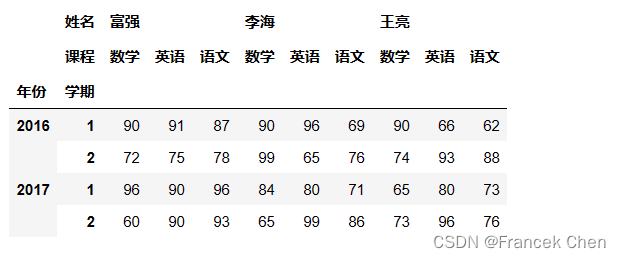
scores['富强']
# 基于列的第1层索引选取多列,需要使用花式索引
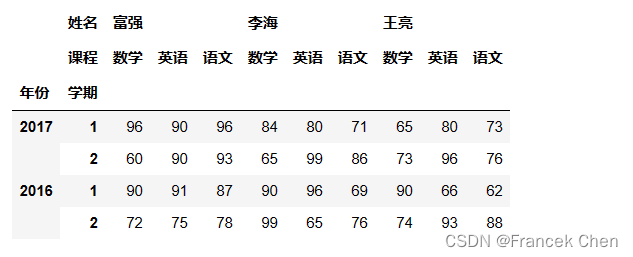
scores[['富强','王亮']]
补充说明:
排序时默认按第一个字符的 Unicode 编码顺序升序排序。
查看一个字符的十进制 Unicode 编码:ord(字符);查看一个字符的十六进制 Unicode 编码:hex(ord(字符))。
- level 0级的排序:富、李、王的十进制Unicode编码分别是23500、26446和29579
- level 1级的排序:数、英和语十进制Unicode编码分别是25968、33521和35821
sort_index()没有指明对哪个级别的列索引排序,默认对两级列索引都做了排序。如果只对level 0级的列索引排序,则应指明参数level=0;要对level 0级升序,而level 1级降序,则应该额外使用参数level=[0,1],ascending=[True,False]。
scores.sort_index(axis=1,inplace=True) # axis=1指明对列索引按升序排列,注意inplace=True后才能看到排序结果
scores
# axis=0指明对行索引排序
scores.sort_index(axis=0,inplace=True,level=[0,1],ascending=[False,True])
scores
# 基于列的第2层索引选取单独1列
scores.loc[:,(slice(None),'语文')]
其中的:表示行索引是任意的,切片slice(None)表示第 0 级列索引是任意的。
注意:元组中不允许使用:,因此用slice(None)代替。
说明:多级索引的切片操作要求必须先对索引排序,因此才有上面的sort_index()函数调用。
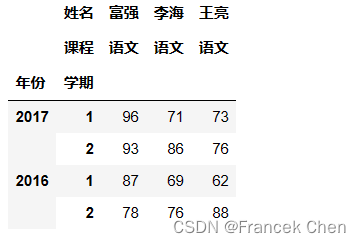
# 基于列的第2层索引选取多列
scores.loc[:,(slice(None),['语文','数学'])]
其中的花式索引['语文','数学']表示选取 level 1 级列索引是语文和数学的两列。

# 同时基于列的第1层和第2层索引选取数据
scores['李海','语文'] # 等价于scores[('李海','语文')]
注意:虽然scores[('李海','语文')]可以,但不能使用scores[(slice(None),'语文')]选取所有的语文成绩。而只能通过scores.loc[:,(slice(None),'语文')]选取所有的语文成绩。

小结:无论基于行索引还是列索引选取数据,只要没指定最高级索引,则必须使用.loc[行索引,列索引]的形式。
2、基于行索引选取数据
基于行索引选取数据,必须使用.loc[]的形式。
# 基于行的单个第1层索引值选取数据
scores.loc[2017]
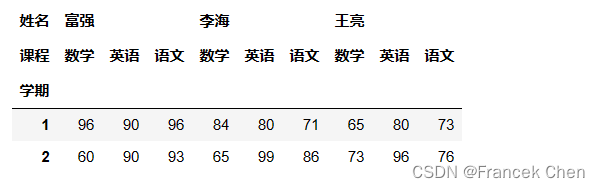
# 基于行的多个第1层索引值选取数据
scores.loc[[2017,2016]]
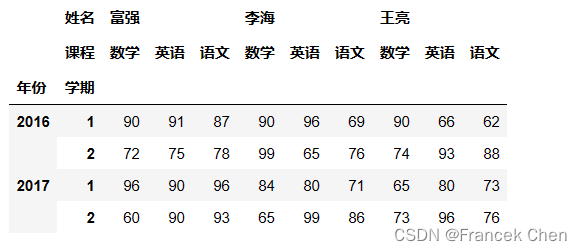
# 基于行的单个第2层索引值选取数据
scores.loc[(slice(None),2),:] # 不能写成scores.loc[(slice(None),2)]或scores.loc[slice(None),2]的形式
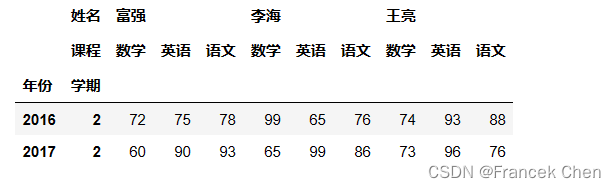
# 基于行的多个第2层索引值选取数据
scores.loc[(slice(None),[1,2]),:] # 不能写成scores.loc[(slice(None),1:2),:],元组中不支持:进行切片操作
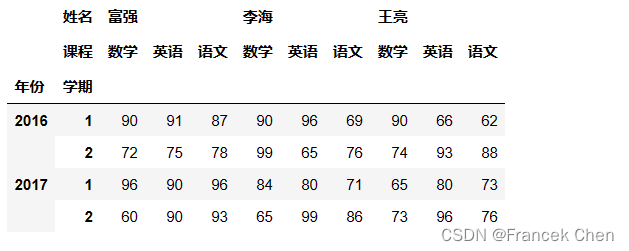
# 同时基于行的第1层和第2层索引选取数据
scores.loc[2016,2] # 等价于scores.loc[(2016,2)]或scores.loc[(2016,2),:],表示元组的括号此时可以去掉
姓名 课程
富强 数学 72
英语 75
语文 78
李海 数学 99
英语 65
语文 76
王亮 数学 74
英语 93
语文 88
Name: (2016, 2), dtype: int32
# 查看2016年所有学生的数学和英语成绩
scores.loc[2016,(slice(None),['数学','英语'])] #*1*
# 查看第2学期的全部数据
scores.loc[(slice(None),2),:] #*2* 不能写成scores.loc[(slice(None),2)]或scores.loc[slice(None),2]的形式
# 查看李海同学的语文成绩
scores['李海','语文'] #*3* 等价于scores.loc[:,('李海','语文')] 或scores[('李海','语文')]
# 查看2017年第1学期的成绩
scores.loc[2017,1] #*4* 等价于scores.loc[(2017,1),:]或scores.loc[(2017,1)]
以#1——#4的语句为例来小结多级索引下的数据选取方式:
1、选取数据的通用形式:(1)通用写法是:df.loc[(行索引),(列索引)],例如#1处;
(2)其中行/列索引分别构成元组,并且从左到右,索引级别依次下降,相邻级别间用逗号分隔;
(3)未指明的高级别行/列索引需要用slice(None)表示取任意值(例如#1处的第1级列索引);未指明的低级别索引可以不写(例如#1处的第2级行索引);如果同级别的索引有多个(例如#1处的第2级列索引),需要用花式索引而不能使用切片(元组不支持冒号:);
2、选取数据的简化形式:(1)当只涉及列索引元组并且其中不包含
slice(None)时,行索引元组可以用冒号(:)简化,写成df.loc[:,(列索引)];或者进一步简化成df[列索引](即loc行选择器和表示元组的圆括号都可以省略,例如#3处)
(2)当只涉及行索引元组并且其中不包含slice(None)时,列索引元组可以用冒号(:)简化,写成df.loc[(行索引),:];或者进一步简化成df.loc[行索引](即表示元组的圆括号也省略了,例如#4处);注意:loc行选择器不能省略,因为只要包含行索引,一定要使用行选择器loc或iloc,而选择列索引则不需要!
(3)无论行/列索引,只要有一个元组中包含slice(None),就不能使用上述简化形式,而必须使用通用形式(#1和#2处)
注意:为了在多级索引的中括号[]中可以使用切片(即使用冒号:),需要先使用sort_index()函数对索引进行排序。上面的结论可以把前面的所有例子都归纳在其中!
# 多级索引中的行/列索引使用元组表示法,不方便之处在于对于元组内部的索引无法使用切片,为此引入IndexSlice对象
idx = pd.IndexSlice
# 用idx改写上面的*1*和#*2*语句
# 查看2016年所有学生的数学和英语成绩
scores.loc[2016,idx[:,['数学','英语']]] #*1* 用:替代了slice(None)
scores.loc[2016,idx[:,'数学':'英语']] # 与上面等价,用第2级列索引上的切片('数学':'英语')替代了上面的花式索引

# 查看第2学期的全部数据
scores.loc[idx[:,2],:] #*2*