一、源码特点
java 酒店推荐推荐系统是一套完善的完整信息系统,结合java web开发和bootstrap UI框架完成本系统 采用协同过滤算法进行推荐 ,对理解JSP java编程开发语言有帮助,系统具有完整的源代码和数据库,系统主要采用B/S模式开发。
前段主要技术 css jquery bootstrap UI框架
后端主要技术 java jsp
数据库 mysql
开发工具 IDEA JDK1.8
java web基于协同过滤酒店推荐系统1
二、功能介绍
前台功能:
1)系统首页
2)公告浏览
3)酒店浏览、查看酒店详情 ,系统并记录用户浏览记录,系统采用协同过滤算法,根据用户的行为习惯进行推荐其他酒店
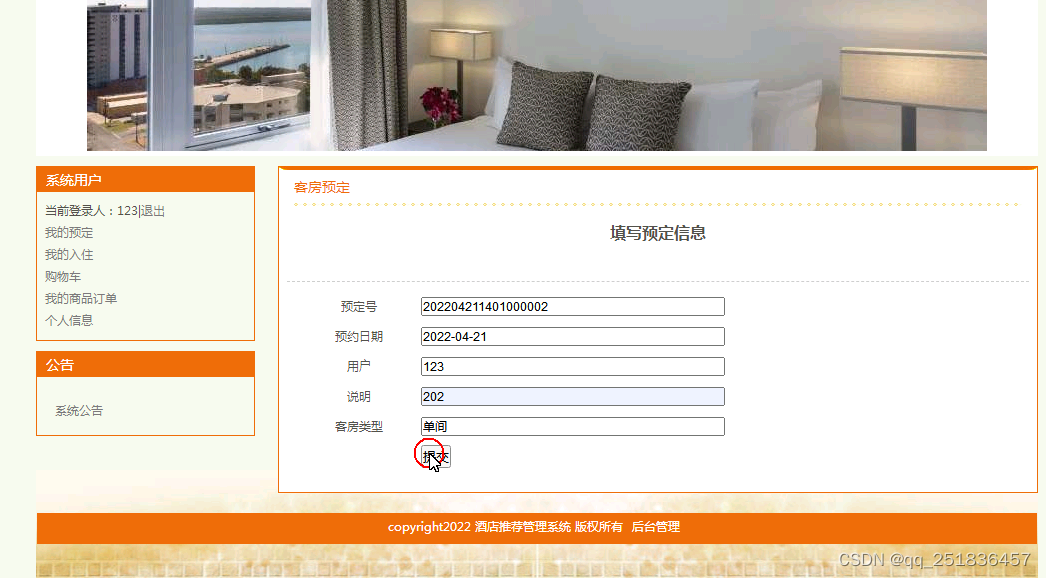
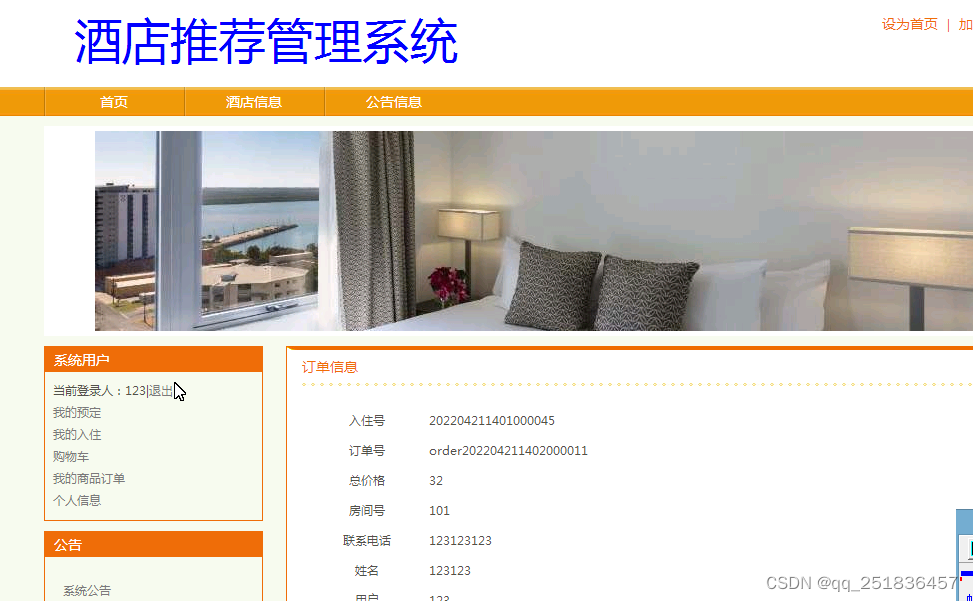
4)客房预定、入住、查看订单
5)用户注册、登录
后台功能:
(1)管理员管理:对管理员信息进行添加、删除、修改和查看
(2)用户管理:对用户信息进行添加、删除、修改和查看
(3)员工管理:对员工信息进行添加、删除、修改和查看
(4)公告管理:对公告信息进行添加、删除、修改和查看
(5)酒店管理:对酒店信息进行添加、删除、修改和查看
(6)浏览管理:对浏览信息进行添加、删除、修改和查看
(7)客房类型管理:对客房类型信息进行添加、删除、修改和查看
(8)客房管理:对客房信息进行添加、删除、修改和查看
(9)预定管理:对预定信息进行添加、删除、修改和查看
(10)入住管理:对入住信息进行添加、删除、修改和查看
(11)商品管理:对商品信息进行添加、删除、修改和查看
(12)订单管理:对订单信息进行删除、修改和查看
(13)订单明细管理:对订单明细信息进行删除、修改和查看
(14)用户登录、个人信息修改
数据库设计
CREATE TABLE `gly` (
`glyid` int(11) NOT NULL auto_increment,
`yhm` VARCHAR(40) default NULL COMMENT '用户名',
`mm` VARCHAR(40) default NULL COMMENT '密码',
`xm` VARCHAR(40) default NULL COMMENT '姓名', PRIMARY KEY (`glyid`)
) ENGINE=InnoDB DEFAULT CHARSET=gb2312;
CREATE TABLE `yonghu` (
`yhid` int(11) NOT NULL auto_increment,
`yhm` VARCHAR(40) default NULL COMMENT '用户名',
`mm` VARCHAR(40) default NULL COMMENT '密码',
`xm` VARCHAR(40) default NULL COMMENT '姓名',
`lxdh` VARCHAR(40) default NULL COMMENT '联系电话',
`lxdz` VARCHAR(40) default NULL COMMENT '联系地址', PRIMARY KEY (`yhid`)
) ENGINE=InnoDB DEFAULT CHARSET=gb2312;
CREATE TABLE `yuangong` (
`ygid` int(11) NOT NULL auto_increment,
`yhm` VARCHAR(40) default NULL COMMENT '用户名',
`mm` VARCHAR(40) default NULL COMMENT '密码',
`xm` VARCHAR(40) default NULL COMMENT '姓名',
`lxdh` VARCHAR(40) default NULL COMMENT '联系电话',
`jd` VARCHAR(40) default NULL COMMENT '酒店', PRIMARY KEY (`ygid`)
) ENGINE=InnoDB DEFAULT CHARSET=gb2312;
CREATE TABLE `gonggao` (
`ggid` int(11) NOT NULL auto_increment,
`bt` VARCHAR(40) default NULL COMMENT '标题',
`nr` VARCHAR(40) default NULL COMMENT '内容',
`fbsj` VARCHAR(40) default NULL COMMENT '发布时间', PRIMARY KEY (`ggid`)
) ENGINE=InnoDB DEFAULT CHARSET=gb2312;
CREATE TABLE `jiudian` (
`jdid` int(11) NOT NULL auto_increment,
`jdmc` VARCHAR(40) default NULL COMMENT '酒店名称',
`wz` VARCHAR(40) default NULL COMMENT '位置',
`tp` VARCHAR(40) default NULL COMMENT '图片',
`lxdh` VARCHAR(40) default NULL COMMENT '联系电话', PRIMARY KEY (`jdid`)
) ENGINE=InnoDB DEFAULT CHARSET=gb2312;
CREATE TABLE `liulan` (
`llid` int(11) NOT NULL auto_increment,
`jd` VARCHAR(40) default NULL COMMENT '酒店',
`yh` VARCHAR(40) default NULL COMMENT '用户',
`llsj` VARCHAR(40) default NULL COMMENT '浏览时间', PRIMARY KEY (`llid`)
) ENGINE=InnoDB DEFAULT CHARSET=gb2312;代码设计
int N = scanner.nextInt();
int[][] sparseMatrix = new int[N][N];//建立用户稀疏矩阵,用于用户相似度计算【相似度矩阵】
Map<String, Integer> userItemLength = new HashMap();//存储每一个用户对应的不同物品总数 eg: A 3
Map<String, Set<String>> itemUserCollection = new HashMap();//建立物品到用户的倒排表 eg: a A B
Set<String> items = new HashSet();//辅助存储物品集合
Map<String, Integer> userID = new HashMap();//辅助存储每一个用户的用户ID映射
Map<Integer, String> idUser = new HashMap();//辅助存储每一个ID对应的用户映射
System.out.println("Input user--items maping infermation:<eg:A a b d>");
scanner.nextLine();
for(int i = 0; i < N ; i++){//依次处理N个用户 输入数据 以空格间隔
String[] user_item = scanner.nextLine().split(" ");
int length = user_item.length;
userItemLength.put(user_item[0], length-1);//eg: A 3
userID.put(user_item[0], i);//用户ID与稀疏矩阵建立对应关系
idUser.put(i, user_item[0]);
//建立物品--用户倒排表
for(int j = 1; j < length; j ++){
if(items.contains(user_item[j])){//如果已经包含对应的物品--用户映射,直接添加对应的用户
itemUserCollection.get(user_item[j]).add(user_item[0]);
}else{//否则创建对应物品--用户集合映射
items.add(user_item[j]);
itemUserCollection.put(user_item[j], new HashSet<String>());//创建物品--用户倒排关系
itemUserCollection.get(user_item[j]).add(user_item[0]);
}
}
}
System.out.println(itemUserCollection.toString());
//计算相似度矩阵【稀疏】
Set<Entry<String, Set<String>>> entrySet = itemUserCollection.entrySet();
Iterator<Entry<String, Set<String>>> iterator = entrySet.iterator();
while(iterator.hasNext()){
Set<String> commonUsers = iterator.next().getValue();
for (String user_u : commonUsers) {
for (String user_v : commonUsers) {
if(user_u.equals(user_v)){
continue;
}
sparseMatrix[userID.get(user_u)][userID.get(user_v)] += 1;//计算用户u与用户v都有正反馈的物品总数
}
}
}
System.out.println(userItemLength.toString());
System.out.println("Input the user for recommendation:<eg:A>");
String recommendUser = scanner.nextLine();
System.out.println(userID.get(recommendUser));
//计算用户之间的相似度【余弦相似性】
int recommendUserId = userID.get(recommendUser);
for (int j = 0;j < sparseMatrix.length; j++) {
if(j != recommendUserId){
System.out.println(idUser.get(recommendUserId)+"--"+idUser.get(j)+"相似度:"+sparseMatrix[recommendUserId][j]/Math.sqrt(userItemLength.get(idUser.get(recommendUserId))*userItemLength.get(idUser.get(j))));
}
}
//计算指定用户recommendUser的物品推荐度
for(String item: items){//遍历每一件物品
Set<String> users = itemUserCollection.get(item);//得到购买当前物品的所有用户集合
if(!users.contains(recommendUser)){//如果被推荐用户没有购买当前物品,则进行推荐度计算
double itemRecommendDegree = 0.0;
for(String user: users){
itemRecommendDegree += sparseMatrix[userID.get(recommendUser)][userID.get(user)]/Math.sqrt(userItemLength.get(recommendUser)*userItemLength.get(user));//推荐度计算
}
System.out.println("The item "+item+" for "+recommendUser +"'s recommended degree:"+itemRecommendDegree);
}
} 三、注意事项
1、管理员账号:admin密码:admin 数据库配置文件DBO.java
2、开发环境为IDEA开发,数据库为mysql,使用java语言开发。
3、数据库文件名是jspjdtj.sql 系统名称jdtj
4、地址:qt/index.jsp
四系统实现
代码下载
https://download.csdn.net/download/qq_41221322/89064345
需要源码 其他的定制服务 下方联系卡片↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓↓