目录
一、二叉树的存储
1.1 顺序存储
1.2 链式存储
二、二叉树的顺序结构及实现
2.1堆的概念及结构
2.2堆的构建
2.3堆的插入
2.4堆顶的删除
2.5堆的完整代码
三、二叉树的链式结构及实现
3.1链式二叉树的构建
3.2链式二叉树的遍历
3.2.1前序遍历
3.2.2中序遍历
3.2.3后序遍历
3.2.4层序遍历
一、二叉树的存储
二叉树一般用顺序结构存储或链式结构存储。
1.1 顺序存储
顺序存储就是用数组来存储,但一般使用数组只适合用来表示完全二叉树,如果不是完全二叉树,就可能存在空间浪费,甚至极大的空间浪费。二叉树的顺序存储在物理结构上是数组,在逻辑上是一颗二叉树。
例:1、完全二叉树

2、非完全二叉树
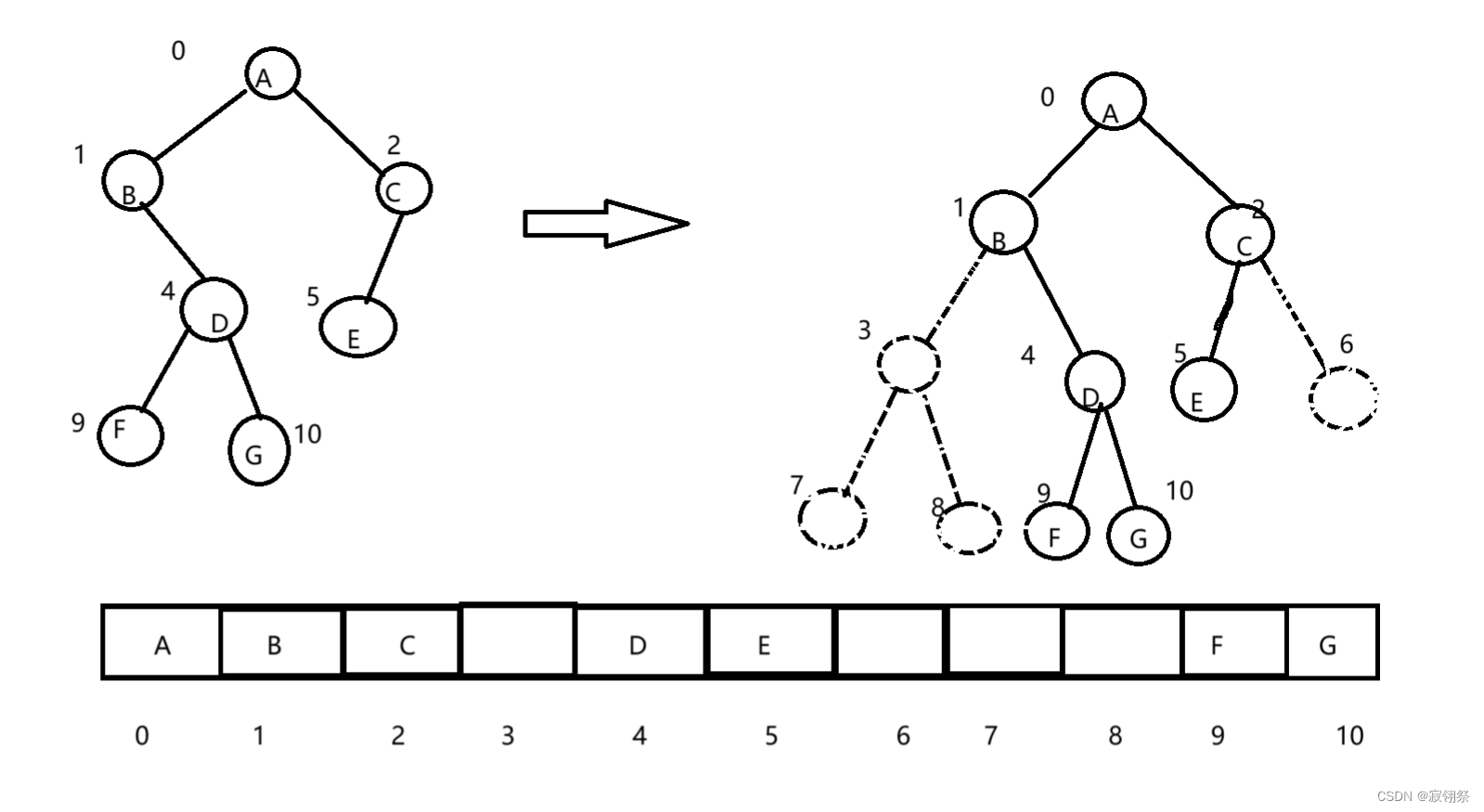
由上面两幅图可以看出,如果二叉树是非完全二叉树,则在数组中会存在很多空位,导致空间浪费。
1.2 链式存储
链式存储就是用链表来表示二叉树,一般用结构体表示每一个节点,每个节点中有三个域,数据域和左右指针域。数据域用来存储节点的数据,左指针指向左孩子,右指针指向右孩子。

二、二叉树的顺序结构及实现
在现实中,一般的二叉树用顺序存储可能会存在大量空间浪费,所以一般只用堆来用顺序结构存储。
注:这里的堆与地址空间中的堆不同,前者是数据结构,后者是操作系统中的一块内存区域分段。
2.1堆的概念及结构
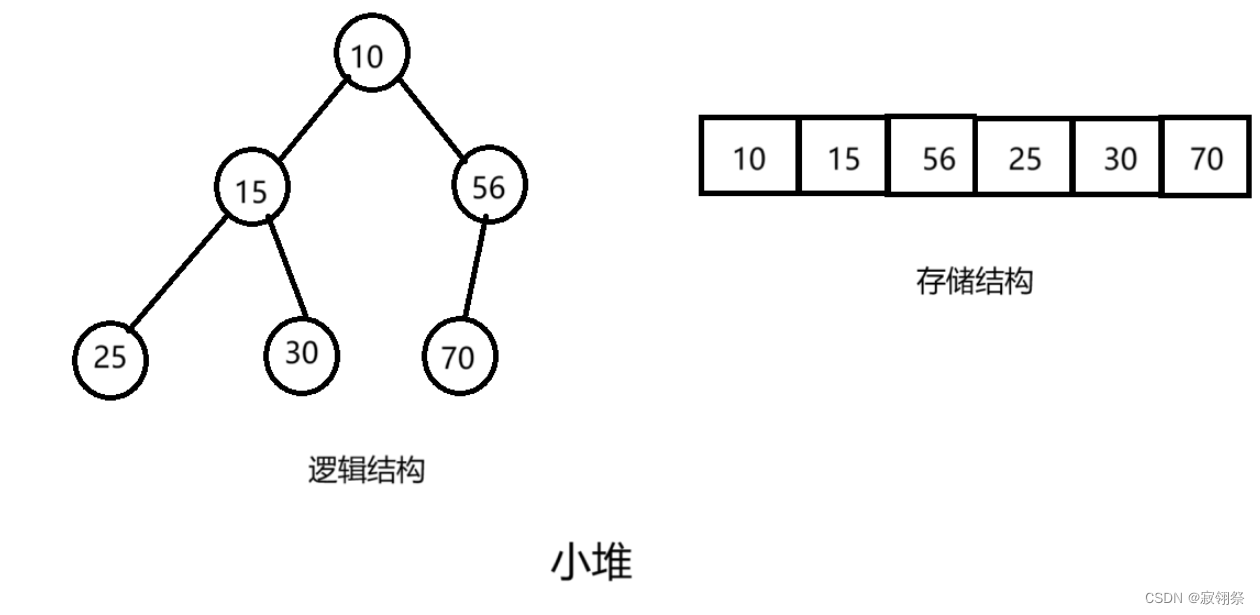
1.概念:如果有一个集合K,将它的所有元素按照完全二叉树的顺序存储方式存储在一个一维数组中,并满足K(i)<=K(2*i+1)且K(i)<=K(2*i+1),则称为小堆,如果大于等于就是大堆。将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆。
2.性质:
堆中某个节点的值总是不大于或不小于其父节点的值。
堆总是一颗完全二叉树。

2.2堆的构建
void HeapCreate(Heap* hp, HPDataType* a, int n)
{
assert(hp);//断言堆是否存在
hp->_a = NULL;//将数据置为空
hp->_capacity = 0;//将堆的容量清零
hp->_size = 0;//将堆的大小清零
}2.3堆的插入
void AdjustUp(HPDataType* a, int child)//向上调整堆
{
int parent = (child - 1) / 2;//父节点在孩子节点-1除2的位置
while (child>0)//如果孩子节点的位置不在最上面
{
if (a[child] < a[parent])//如果父节点小于孩子节点
{
swap(&a[child], &a[parent]);//交换值
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
// 堆的插入
void HeapPush(Heap* hp, HPDataType x)
{
assert(hp);//断言堆是否存在
if (hp->_size == hp->_capacity)//如果堆的大小等于容量,需扩容
{
size_t newcapacity = hp->_capacity == 0 ? 4 : hp->_capacity * 2;
HPDataType* tmp = realloc(hp->_a, sizeof(HPDataType) * newcapacity);//定义临时变量扩容
if (tmp == NULL)//判断扩容是否成功
{
perror("realloc fail");//扩容失败
return;
}
hp->_a = tmp;//将变量传给a
hp->_capacity = newcapacity;//扩容
}
hp->_a[hp->_size] = x;//将值插入堆的最后
hp->_size++;//堆的大小加1
AdjustUp(hp->_a ,hp->_size -1);//用向上调整的方法重新调整堆,防止插入后不再是大堆或小堆
}2.4堆顶的删除
void AdjustUp(HPDataType* a, int child)//向下调整堆
{
int parent = (child - 1) / 2;//父节点在孩子节点-1除2的位置
while (child>0)//如果孩子节点的位置不在最上面
{
if (a[child] < a[parent])//如果父节点小于孩子节点
{
swap(&a[child], &a[parent]);//交换值
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
// 堆的删除
void HeapPop(Heap* hp)
{
assert(hp);//断言堆是否存在
assert(hp->_size > 0);//断言堆的大小是否为0
swap(&hp->_a[0], &hp->_a[hp->_size - 1]);//交换堆顶和堆尾的值
hp->_size--;//堆的大小减1
AdjustDown(hp->_a, hp->_size, 0);//向下调整堆
}2.5堆的完整代码
// 堆的构建
void HeapCreate(Heap* hp, HPDataType* a, int n)
{
assert(hp);//断言堆是否存在
hp->_a = NULL;//将数据置为空
hp->_capacity = 0;//将堆的容量清零
hp->_size = 0;//将堆的大小清零
}
// 堆的销毁
void HeapDestory(Heap* hp)
{
assert(hp);//断言堆是否存在
free(hp->_a);//释放数据
hp->_a = NULL;//将指针置为空
hp->_capacity = 0;将堆的容量清零
hp->_size = 0;//将堆的大小清零
}
void swap(HPDataType* x, HPDataType* y)
{
HPDataType tmp = *x;
*x = *y;
*y = tmp;
}
void AdjustDown(HPDataType* a, int n, int parent)
{
int child = parent * 2 + 1;//左孩子节点是父亲节点的2倍加1
while (child < n)//如果孩子节点不在最后
{
//找到左右孩子中较小的
if (child + 1 < n && a[child + 1] < a[child])//如果左孩子大于右孩子
{
++child;
}
if (a[child] < a[parent])//如果孩子小于父亲
{
swap(&a[child], &a[parent]);//交换父节点与子节点
parent = child;
child = parent * 2 + 1;
}
else
{
break;
}
}
}
void AdjustUp(HPDataType* a, int child)//向上调整堆
{
int parent = (child - 1) / 2;//父节点在孩子节点-1除2的位置
while (child>0)//如果孩子节点的位置不在最上面
{
if (a[child] < a[parent])//如果父节点小于孩子节点
{
swap(&a[child], &a[parent]);//交换值
child = parent;
parent = (child - 1) / 2;
}
else
{
break;
}
}
}
// 堆的插入
void HeapPush(Heap* hp, HPDataType x)
{
assert(hp);//断言堆是否存在
if (hp->_size == hp->_capacity)//如果堆的大小等于容量,需扩容
{
size_t newcapacity = hp->_capacity == 0 ? 4 : hp->_capacity * 2;
HPDataType* tmp = realloc(hp->_a, sizeof(HPDataType) * newcapacity);//定义临时变量扩容
if (tmp == NULL)//判断扩容是否成功
{
perror("realloc fail");//扩容失败
return;
}
hp->_a = tmp;//将变量传给a
hp->_capacity = newcapacity;//扩容
}
hp->_a[hp->_size] = x;//将值插入堆的最后
hp->_size++;//堆的大小加1
AdjustUp(hp->_a ,hp->_size -1);//用向上调整的方法重新调整堆,防止插入后不再是大堆或小堆
}
// 取堆顶的数据
HPDataType HeapTop(Heap* hp)
{
assert(hp);//断言堆是否存在
return hp->_a[0];
}
// 堆的删除
void HeapPop(Heap* hp)
{
assert(hp);//断言堆是否存在
assert(hp->_size > 0);//断言堆的大小是否为0
swap(&hp->_a[0], &hp->_a[hp->_size - 1]);//交换堆顶和堆尾的值
hp->_size--;//堆的大小减1
AdjustDown(hp->_a, hp->_size, 0);//向下调整堆
}
// 堆的数据个数
int HeapSize(Heap* hp)
{
assert(hp);
return hp->_size;
}
// 堆的判空
int HeapEmpty(Heap* hp)
{
assert(hp);
return hp->_size == 0;
}
// 对数组进行堆排序
void HeapSort(int* a, int n)
{
for (int i = (n - 1) / 2; i >= 0; --i)
{
AdjustDown(a, n, i);
}
}三、二叉树的链式结构及实现
一颗链式二叉树一般用结构体表示,结构体中一个存储数据,一个链表指向左孩子节点,一个指向右孩子节点。
typedef int BTDataType;//方便后面改变二叉树中的数据类型
typedef struct BinaryTreeNode
{
BTDataType data;//二叉树存储数据的节点
struct BinaryTreeNode* left;//左孩子节点
struct BinaryTreeNode* right;//右孩子节点
}BTNode;//重命名3.1链式二叉树的构建
BTNode* BinaryTreeCreate(BTDataType* a, int n, int* pi)//二叉树一般需要手动扩建
{
BTNode* n1 = BuyNode('A');
BTNode* n2 = BuyNode('B');
BTNode* n3 = BuyNode('C');
BTNode* n4 = BuyNode('D');
BTNode* n5 = BuyNode('E');
BTNode* n6 = BuyNode('F');
BTNode* n7 = BuyNode('G');
BTNode* n8 = BuyNode('H');
n1->left = n2;
n1->right = n3;
n2->left = n4;
n2->right = n5;
n3->left = n6;
n3->right = n7;
n5->left = n8;
return n1;
}
3.2链式二叉树的遍历
二叉树的遍历就是按照某种特殊规则,依次对二叉树的节点进行操作,每个节点只能操作一次。
二叉树的遍历一般有4种方式。
3.2.1前序遍历
前序遍历:优先操作每个节点的自身,后操作左节点,最后操作右节点。
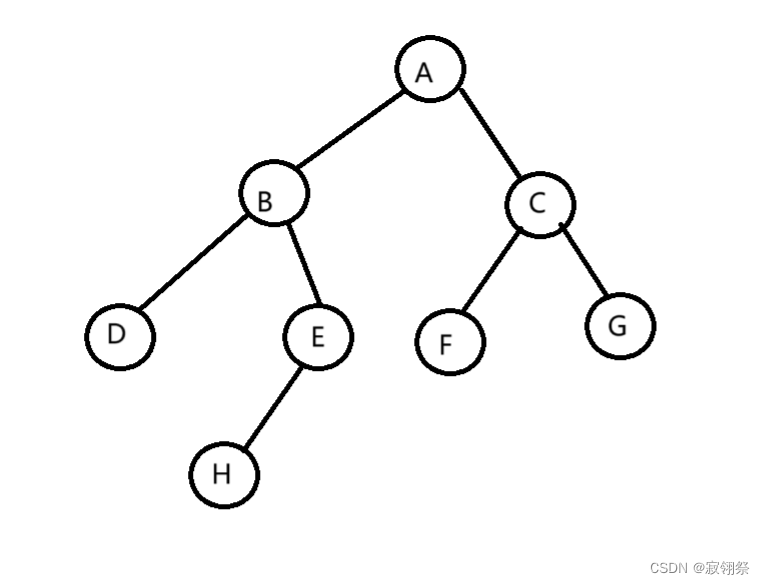
例如上图的树就是按照A-B-D-E-H-C-F-G的顺序操作。
从A开始,先操作A的自身,再访问A的左节点B。
B节点先操作自身,再访问B的左节点D。
D节点操作自身,无孩子节点则返回到B,访问B的右节点E。
E节点操作自身,再访问E的左节点H。
H节点操作自身,无孩子节点则返回到E,E无左孩子节点则返回到B,B的左右孩子都已访问则返回到A,访问A的右节点C。
C节点操作自身,再访问C的左节点F。
F节点操作自身,无孩子节点则返回C,访问C的右节点G
G节点操作自身,无孩子节点,访问结束。
// 二叉树前序遍历
void BinaryTreePrevOrder(BTNode* root)
{
if (root == NULL)
{
printf("N ");//如果节点为空打印N
return;
}
printf("%c ", root->data);//打印节点
BinaryTreePrevOrder(root->left);//访问左节点
BinaryTreePrevOrder(root->right);//访问右节点
}3.2.2中序遍历
中序遍历:优先操作每个节点的左节点,后操作自身,最后操作右节点。
上图按照D-B-H-E-A-F-C-G的顺序操作。
从A开始,先访问A的左节点B,B节点先访问D,D无左节点,操作自身。
D无右节点,则返回B,操作B的自身,再访问B的右节点E。
E节点先访问左节点H,H无左节点,操作自身,H无右节点,则返回E节点。
E节点操作自身,无右节点,返回B节点,再返回A节点。
A节点操作自身,再访问右节点C,C节点访问左节点F。
F无左节点操作自身,无右节点,返回C节点。
C节点操作自身,再访问C的右节点G。
G无左节点,操作自身,无右节点,访问结束。
// 二叉树中序遍历
void BinaryTreeInOrder(BTNode* root)
{
if (root == NULL)
{
printf("N ");//如果节点为空打印N
return;
}
BinaryTreePrevOrder(root->left);//访问左节点
printf("%c ", root->data);//打印节点
BinaryTreePrevOrder(root->right);//访问右节点
}3.2.3后序遍历
后序遍历:优先操作每个节点的左节点,后操作右节点,最后操作自身。
上图按照D-B-H-E-F-C-G-A的顺序操作。
从A开始,访问A的左节点B,再访问B的左节点D,D无左右节点,操作自身,返回B节点。
访问B节点的右节点E,再访问E的左节点H,H无左右节点, 操作自身,返回E节点。
E节点操作自身,返回B节点。
B节点操作自身,返回A节点,再访问A节点的右节点C,访问C的左节点F。
F无左右节点,操作自身,返回C节点,访问C节点的右节点G。
G无左右节点,操作自身,返回C节点。
C节点操作自身,返回A节点。
A节点操作自身,访问结束。
// 二叉树后序遍历
void BinaryTreePostOrder(BTNode* root)
{
if (root == NULL)
{
printf("N ");//如果节点为空打印N
return;
}
BinaryTreePrevOrder(root->left);//访问左节点
BinaryTreePrevOrder(root->right);//访问右节点
printf("%c ", root->data);//打印节点
}3.2.4层序遍历
层序遍历:按照二叉树的每一层,一层一层的从左向右操作。
实现二叉树的层序遍历需要用到队列的知识。
队列是一个有着先进先出原则的链表,先进的元素永远比后进的元素先出来。通过队列的规则,只要二叉树的每一个节点出队列时将其左右孩子节点入队列即可完成二叉树的层序遍历。
上图的操作顺序是A-B-C-D-E-F-G-H
A节点入队列,A节点出队列,将A的左右子节点BC入队列。
此时队列中有B-C,将B出队列,B的左右子节点DE入队列。
此时队列中有C-D-E,将C出队列,C的左右子节点FG入队列。
此时队列中有D-E-F-G,将D出队列,D无子节点。
此时队列中有E-F-G,将F出队列,F的左节点H入队列。
此时队列中有F-G-H,均无子节点,一个一个出队列即可。
队列头文件代码
#pragma once
#include<stdio.h>
#include<stdbool.h>
#include<assert.h>
#include<string.h>
#include<stdlib.h>
typedef struct BinTreeNode* QDataType;
// 链式结构:表示队列
typedef struct QueueNode
{
QDataType data;
struct QueueNode* next;
}QNode;
// 队列的结构
typedef struct Queue
{
QNode* phead;
QNode* ptail;
int size;
}Queue;
// 初始化队列
void QueueInit(Queue* q);
// 队尾入队列
void QueuePush(Queue* q, QDataType data);
// 队头出队列
void QueuePop(Queue* q);
// 获取队列头部元素
QDataType QueueFront(Queue* q);
// 获取队列队尾元素
QDataType QueueBack(Queue* q);
// 获取队列中有效元素个数
int QueueSize(Queue* q);
// 检测队列是否为空,如果为空返回非零结果,如果非空返回0
int QueueEmpty(Queue* q);
// 销毁队列
void QueueDestroy(Queue* q);
队列代码
#include"1.h"
// 初始化队列
void QueueInit(Queue* q)
{
assert(q);//断言队列是否存在
q->phead = NULL;//将头节点的置为空
q->ptail = NULL;//将尾节点置为空
q->size = 0;//将队列大小初始化为0
}
// 队尾入队列
void QueuePush(Queue* pq, QDataType x)
{
assert(pq);//断言队列是否存在
QNode* newnode = (QNode*)malloc(sizeof(QNode));//创建临时变量
if (newnode == NULL)//判断变量是否创建成功
{
perror("malloc fail");
return;
}
newnode->data = x;//将要入队列的值给临时变量
newnode->next = NULL;//将临时变量的指向下一个节点的指针置空
if (pq->ptail)//如果尾队列存在,则队列中含有数据
{
pq->ptail->next = newnode;//将原本尾队列指向下一个节点的指针指向临时变量
pq->ptail = newnode;//将临时变量设为尾节点
}
else//尾队列不存在,则队列为空
{
pq->phead = pq->ptail = newnode;//将头节点和尾节点都设为临时变量
}
pq->size++;//队列大小加1
}
// 队头出队列
void QueuePop(Queue* q)
{
assert(q);//断言队列是否存在
assert(q->phead != NULL);//断言队列的头节点是否为空
if (q->phead->next == NULL)//队列头节点的下一个节点为空,则队列中只有一个元素
{
free(q->phead);//释放头节点
q->phead = q->ptail = NULL;//将头节点和尾节点置空
}
else//队列中不止1个元素
{
QNode* next = q->phead->next;//创建临时变量指向头节点的下一个节点
free(q->phead);//是否头节点
q->phead = next;//将头节点的下一个节点设为头节点
}
q->size--;//队列大小减1
}
// 获取队列头部元素
QDataType QueueFront(Queue* q)
{
assert(q);//断言队列是否存在
assert(q->phead != NULL);//断言队列的头节点是否为空
return q->phead->data;//返回队列头节点的数据
}
// 获取队列队尾元素
QDataType QueueBack(Queue* q)
{
assert(q);//断言队列是否存在
assert(q->ptail != NULL);//断言队列的尾节点是否为空
return q->ptail->data;//返回队列尾节点的数据
}
// 获取队列中有效元素个数
int QueueSize(Queue* q)
{
assert(q);//断言队列是否存在
return q->size;//返回队列的大小
}
// 检测队列是否为空,如果为空返回非零结果,如果非空返回0
int QueueEmpty(Queue* q)
{
assert(q);//断言队列是否存在
return q->size == 0;//判断队列的大小是否为0
}
// 销毁队列
void QueueDestroy(Queue* q)
{
assert(q);//断言队列是否存在
QNode* cur = q->phead;//定义临时节点等于头节点
while (cur)//如果头节点不为空
{
QNode* next = cur->next;//定义临时节点指向头节点的下一个节点
free(cur);//释放头节点
cur = next;//将下一个节点当作头节点
}
q->phead = NULL;//将头节点指针置空
q->ptail = NULL;//将尾节点指针置空
q->size = 0;//将队列大小置为0
}二叉树头文件
#pragma once
#include<stdio.h>
#include<string.h>
#include<assert.h>
#include<stdlib.h>
typedef int BTDataType;//方便后面改变二叉树中的数据类型
typedef struct BinaryTreeNode
{
BTDataType data;//二叉树存储数据的节点
struct BinaryTreeNode* left;//左孩子节点
struct BinaryTreeNode* right;//右孩子节点
}BTNode;//重命名
#include"1.h"
// 通过前序遍历的数组"ABD##E#H##CF##G##"构建 二叉树
BTNode* BinaryTreeCreate(BTDataType* a, int n, int* pi);
// 二叉树销毁
void BinaryTreeDestory(BTNode** root);
// 二叉树节点个数
int BinaryTreeSize(BTNode* root);
// 二叉树叶子节点个数
int BinaryTreeLeafSize(BTNode* root);
// 二叉树第k层节点个数
int BinaryTreeLevelKSize(BTNode* root, int k);
// 二叉树查找值为x的节点
BTNode* BinaryTreeFind(BTNode* root, BTDataType x);
// 二叉树前序遍历
void BinaryTreePrevOrder(BTNode* root);
// 二叉树中序遍历
void BinaryTreeInOrder(BTNode* root);
// 二叉树后序遍历
void BinaryTreePostOrder(BTNode* root);
// 层序遍历
void BinaryTreeLevelOrder(BTNode* root);
// 判断二叉树是否是完全二叉树
int BinaryTreeComplete(BTNode* root);二叉树代码
#include"tree.h"
BTNode* BuyNode(BTDataType a)//a是要创建的值
{
BTNode* newnode = (BTNode*)malloc(sizeof(BTNode));//定义临时变量扩容
if (newnode == NULL)
{
printf("malloc fail");//扩容失败
return NULL;
}
newnode->data = a;
newnode->left = NULL;
newnode->right = NULL;
return newnode;
}
// 通过前序遍历的数组"ABD##E#H##CF##G##"构建二叉树
BTNode* BinaryTreeCreate(BTDataType* a, int n, int* pi)//二叉树一般需要手动扩建
{
BTNode* n1 = BuyNode('A');
BTNode* n2 = BuyNode('B');
BTNode* n3 = BuyNode('C');
BTNode* n4 = BuyNode('D');
BTNode* n5 = BuyNode('E');
BTNode* n6 = BuyNode('F');
BTNode* n7 = BuyNode('G');
BTNode* n8 = BuyNode('H');
n1->left = n2;
n1->right = n3;
n2->left = n4;
n2->right = n5;
n3->left = n6;
n3->right = n7;
n5->left = n8;
return n1;
}
// 二叉树销毁
void BinaryTreeDestory(BTNode** root)
{
assert(root);
free(root);
}
// 二叉树节点个数
int BinaryTreeSize(BTNode* root)
{
return root == NULL ? 0 :
BinaryTreeSize(root->left) + BinaryTreeSize(root->right) + 1;
}
// 二叉树叶子节点个数
int BinaryTreeLeafSize(BTNode* root)
{
if (root == NULL)
{
return 0;
}
if (root->left == NULL && root->right == NULL)
{
return 1;
}
return BinaryTreeLeafSize(root->left) + BinaryTreeLeafSize(root->right);
}
// 二叉树第k层节点个数
int BinaryTreeLevelKSize(BTNode* root, int k)
{
assert(k > 0);
if (root == NULL)
{
return 0;
}
if (k == 1)
{
return 1;
}
return BinaryTreeLevelKSize(root->left, k - 1) + BinaryTreeLevelKSize(root->right, k - 1);
}
// 二叉树查找值为x的节点
BTNode* BinaryTreeFind(BTNode* root, BTDataType x)
{
if (root == NULL)
{
return NULL;
}
if (root->data == x)
{
return root;
}
BTNode* ret1= BinaryTreeFind(root->right, x);
if (ret1)
{
return ret1;
}
BTNode* ret2=BinaryTreeFind(root->left , x);
if (ret2)
{
return ret2;
}
return NULL;
}
// 二叉树前序遍历
void BinaryTreePrevOrder(BTNode* root)
{
if (root == NULL)
{
printf("N ");//如果节点为空打印N
return;
}
printf("%c ", root->data);//打印节点
BinaryTreePrevOrder(root->left);//访问左节点
BinaryTreePrevOrder(root->right);//访问右节点
}
// 二叉树中序遍历
void BinaryTreeInOrder(BTNode* root)
{
if (root == NULL)
{
printf("N ");//如果节点为空打印N
return;
}
BinaryTreePrevOrder(root->left);//访问左节点
printf("%c ", root->data);//打印节点
BinaryTreePrevOrder(root->right);//访问右节点
}
// 二叉树后序遍历
void BinaryTreePostOrder(BTNode* root)
{
if (root == NULL)
{
printf("N ");//如果节点为空打印N
return;
}
BinaryTreePrevOrder(root->left);//访问左节点
BinaryTreePrevOrder(root->right);//访问右节点
printf("%c ", root->data);//打印节点
}
// 层序遍历
void TreeLevelOrder(BTNode* root)
{
Queue q;//定义临时节点
QueueInit(&q);//创建临时节点
if (root)//如果节点不为空
{
QueuePush(&q, root);//节点入队列
}
while (!QueueEmpty(&q))//如果队列不为空
{
BTNode* front = QueueFront(&q);//获取队头元素
QueuePop(&q);//队头元素出队列
if (front)//如果节点存在
{
printf("%d ", front->data);//打印节点数据
// 带入下一层
QueuePush(&q, front->left);//左孩子节点入队列
QueuePush(&q, front->right);//右孩子节点入队列
}
else
{
printf("N ");//不存在打印N
}
}
printf("\n");
QueueDestroy(&q);//销毁临时节点,防止空间泄露
}