参考教材截图

数据可视化第二版-03部分-06章-比较与排序
总结
本系列博客为基于《数据可视化第二版》一书的教学资源博客。本文主要是第6章,比较与排序可视化的案例相关。
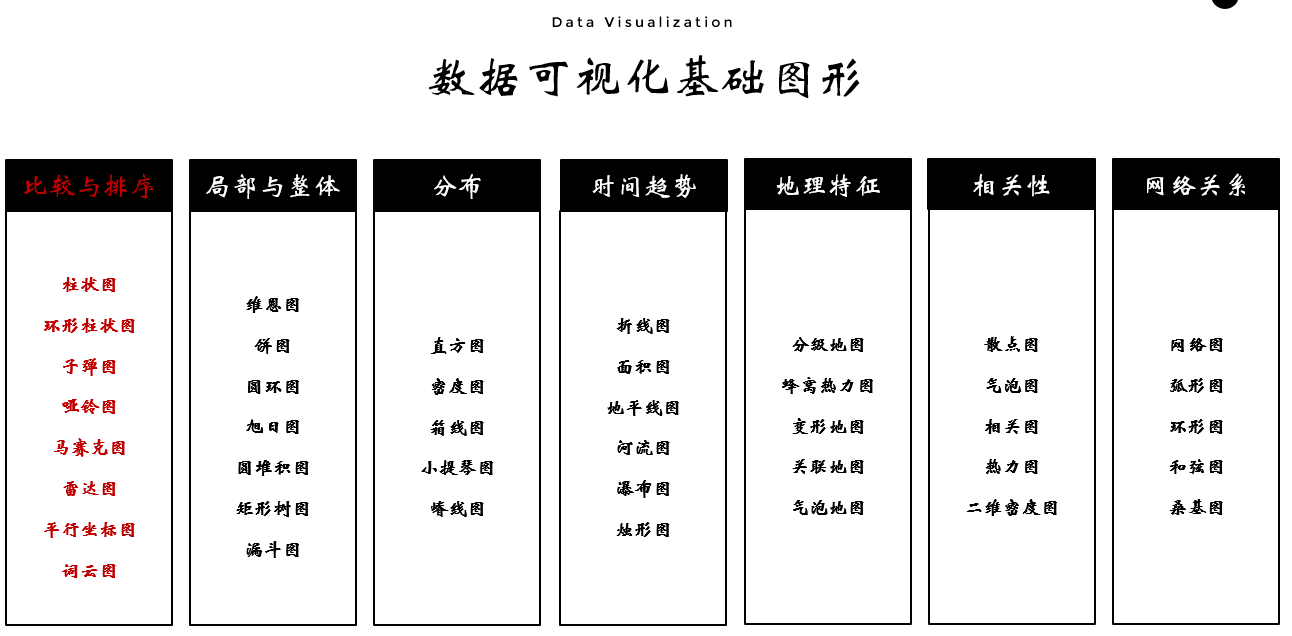
可视化视角-比较与排序
代码实现
创建虚拟环境
我的conda下有多个python环境。
1. python版本管理
创建python版本的命令为
conda create -n name python=3.10(python版本自己指定)
如:
conda create -n py10 python=3.10
查看当前的python版本
conda env list

2.切换到指定版本后安装虚拟环境
切换到指定的python版本
conda activate py10
激活虚拟环境后,安装python虚拟环境
python -m venv venv202302

然后把数据和代码拖拽到
E:\vscode\数据可视化第二版李伊配套资源
切换路径到文件当前路径
目录下即可,但很多代码拖拽后,无法执行,因为python工程中的默认路径为工程目录的根路径,如果python文件中的路径为相对于当前文件,需要切换默认路径为文件当前路径
import os
print(os.getcwd(),"-----------------")
# os.chdir("./")
os.chdir(os.path.dirname(os.path.realpath(__file__)))
print(os.getcwd(),"-----------------")
输出为:
(venv202302) E:\vscode\数据可视化第二版李伊配套资源>e:/vscode/数据可视化第二版李伊配套
资源/venv202302/Scripts/python.exe e:/vscode/数据可视化第二版李伊配套资源/各类图形示例
代码/比较类/哑铃图.py
E:\vscode\数据可视化第二版李伊配套资源 -----------------
E:\vscode\数据可视化第二版李伊配套资源\各类图形示例代码\比较类 -----------------
柱形图
plt.bar(x, height, width=0.8, bottom=None, *, align='center', data=None, **kwargs)
x:表示x坐标,数据类型为int或float类型,刻度自适应调整;也可传dataframe的object,x轴上等间距排列;
height:表示柱状图的高度,也就是y坐标值,数据类型为int或float类型;
width:表示柱状图的宽度,取值在0~1之间,默认为0.8;
bottom:柱状图的起始位置,也就是y轴的起始坐标;
align:柱状图的中心位置,默认"center"居中,可设置为"lege"边缘;
color:柱状图颜色;
edgecolor:边框颜色;
linewidth:边框宽度;
tick_label:下标标签;
log:柱状图y周使用科学计算方法,bool类型;
orientation:柱状图是竖直还是水平,竖直:“vertical”,水平条:“horizontal”;
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei'] # 设置支持中文
plt.rcParams['axes.unicode_minus']=False # 设置支持坐标轴数值为复数
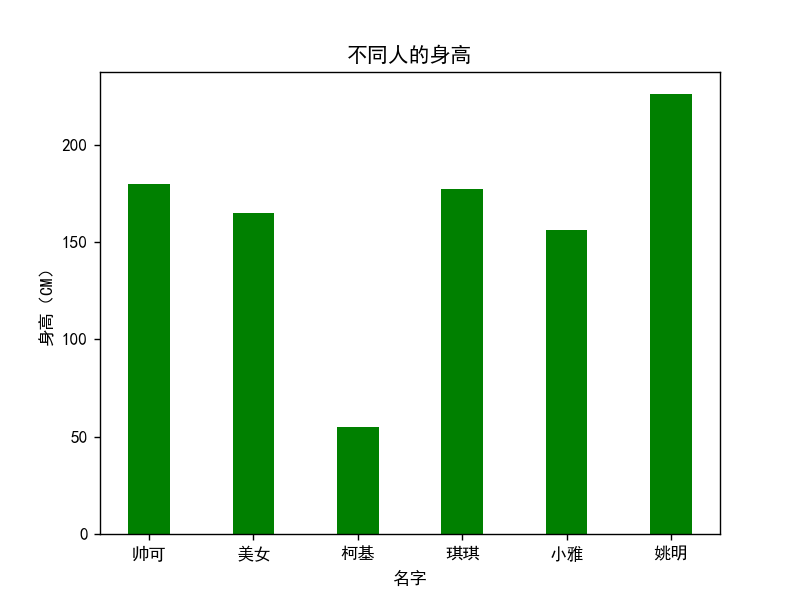
X = ["帅可", "美女", "柯基", "琪琪", "小雅", "姚明"]
Y = [180, 165, 55, 177, 156, 226]
fig = plt.figure()
plt.bar(X, Y, 0.4, color="green")
plt.xlabel("名字")
plt.ylabel("身高(CM)")
plt.title("不同人的身高")
plt.show()
输出为:
环形柱状图
plt.axes解释参考:https://www.zhihu.com/question/51745620
axes的用法和subplot是差不多的,四个参数的话,前两个指的是相对于坐标原点的位置,后两个指的是坐标轴的长/宽度,
import numpy as np
from matplotlib import pyplot as plt
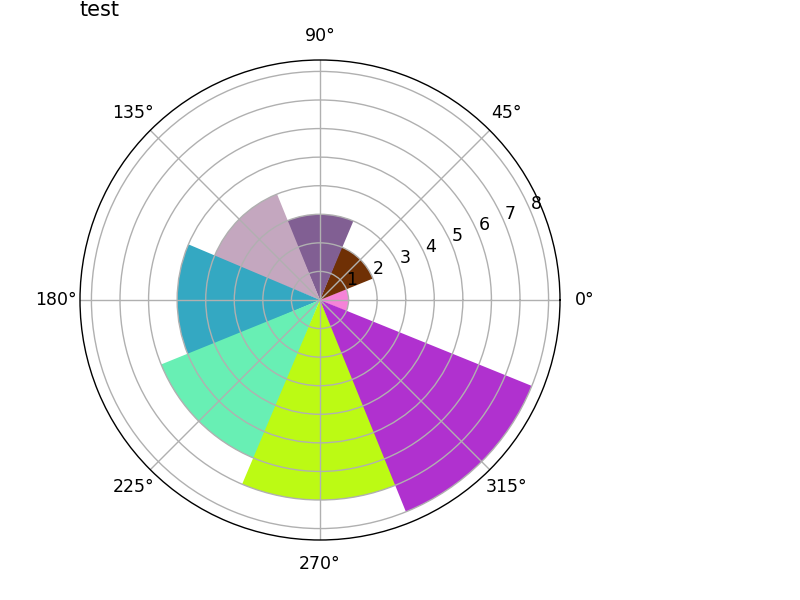
def show_rose(values, title):
n = 8
angle = np.arange(0, 2 * np.pi, 2 * np.pi / n)
print("angle--->",angle)
# angle---> [0. 0.78539816 1.57079633 2.35619449 3.14159265 3.92699082 4.71238898 5.49778714]
# 绘制的数据
radius = np.array(values)
print("radius--->",radius)
# radius---> [1 2 3 4 5 6 7 8]
# 极坐标条形图,polar为True
plt.axes([0, 0.1, 0.8, 0.8], polar=True)
color = np.random.random(size=24).reshape((8, 3))
plt.bar(angle, radius, color=color)
plt.title(title, loc='left')
plt.show()
v = [1, 2, 3, 4, 5, 6, 7, 8]
show_rose(v, 'test')
输出为:
子弹图
import plotly.graph_objects as go
fig = go.Figure()#每一个制作一条子弹图轨道
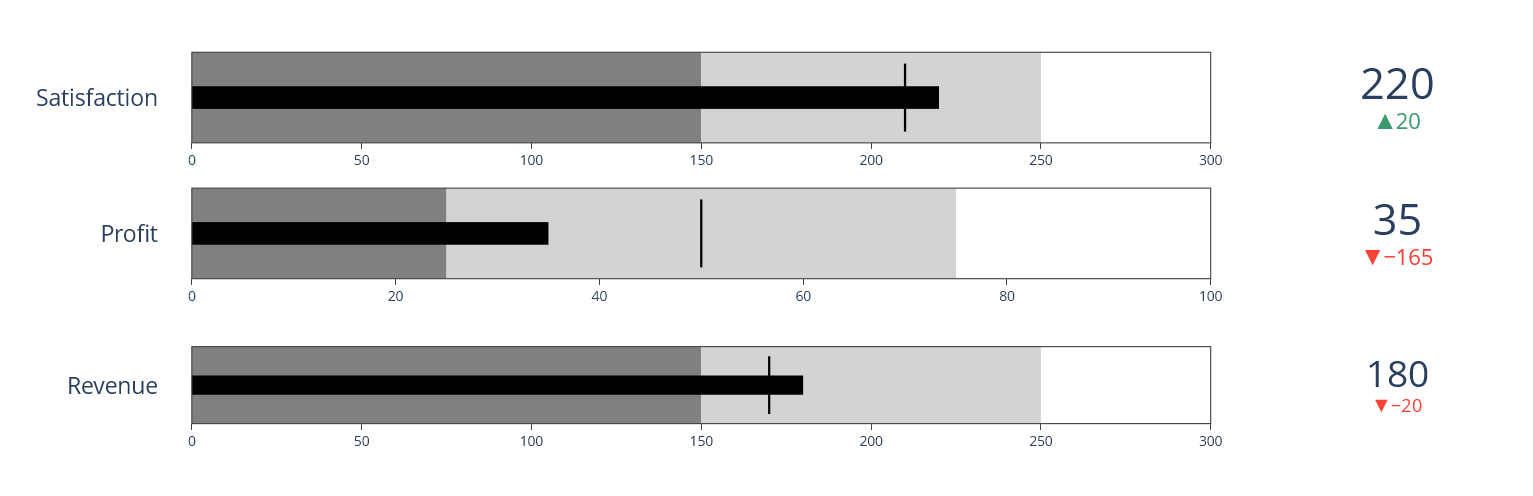
fig.add_trace(go.Indicator(
mode = "number+gauge+delta", value = 180,#调整的是显示的内容,number是最右端数字。gauge表示图表,delta表示与标准的差值,值为细条形的值
delta = {"reference": 200},#设定标准
domain = {"x": [0.25, 1], "y": [0.08, 0.25]},#这一条子弹图的位置
title = {"text": "Revenue"},
gauge = {
"shape": "bullet",
"axis": {"range": [None, 300]},
"threshold": {#细线属性
"line": {"color": "black", "width": 2},
"thickness": 0.75,
"value": 170},
"steps": [#分段填充颜色
{"range": [0, 150], "color": "gray"},
{"range": [150, 250], "color": "lightgray"}],
"bar": {"color": "black"}}))
fig.add_trace(go.Indicator(
mode = "number+gauge+delta", value = 35,
delta = {"reference": 200},
domain = {"x": [0.25, 1], "y": [0.4, 0.6]},
title = {"text": "Profit"},
gauge = {
"shape": "bullet",
"axis": {"range": [None, 100]},
"threshold": {#细线属性
"line": {"color": "black", "width": 2},
#"line": {"color": "black", "width": 2},
"thickness": 0.75,
"value": 50},
"steps": [#分段填充颜色
{"range": [0, 25], "color": "gray"},
{"range": [25, 75], "color": "lightgray"}],
"bar": {"color": "black"}}))
fig.add_trace(go.Indicator(
mode = "number+gauge+delta", value = 220,
delta = {"reference": 200},
domain = {"x": [0.25, 1], "y": [0.7, 0.9]},
title = {"text" :"Satisfaction"},
gauge = {
"shape": "bullet",
"axis": {"range": [None, 300]},
"threshold": {#准线
"line": {"color": "black", "width": 2},
# "line": {"color": "black", "width": 2},
"thickness": 0.75,
"value": 210},
"steps": [
{"range": [0, 150], "color": "gray"},
{"range": [150, 250], "color": "lightgray"}],
"bar": {"color": "black"}}))
fig.update_layout(height = 400 , margin = {"t":0, "b":0, "l":0})
fig.show()
输出为:
哑铃图
数据:美国部分地图人均GDP.csv
"Area","pct_2014","pct_2013"
"Houston",0.19,0.22
"Miami",0.19,0.24
"Dallas",0.18,0.21
"San Antonio",0.15,0.19
"Atlanta",0.15,0.18
"Los Angeles",0.14,0.2
"Tampa",0.14,0.17
"Riverside, Calif.",0.14,0.19
"Phoenix",0.13,0.17
"Charlotte",0.13,0.15
"San Diego",0.12,0.16
"All Metro Areas",0.11,0.14
"Chicago",0.11,0.14
"New York",0.1,0.12
"Denver",0.1,0.14
"Washington, D.C.",0.09,0.11
"Portland",0.09,0.13
"St. Louis",0.09,0.1
"Detroit",0.09,0.11
"Philadelphia",0.08,0.1
"Seattle",0.08,0.12
"San Francisco",0.08,0.11
"Baltimore",0.06,0.09
"Pittsburgh",0.06,0.07
"Minneapolis",0.06,0.08
"Boston",0.04,0.04
代码:
plt.gca() 参考:https://zhuanlan.zhihu.com/p/110976210
matplotlib库的axiss模块中的Axes.vlines()函数用于在从ymin到ymax的每个x处绘制垂直线。
Axes.vlines(self, x, ymin, ymax, colors=’k’, linestyles=’solid’, label=”, *, data=None, **kwargs)
参数:此方法接受以下描述的参数:
x:该参数是x-indexes绘制线条的顺序。
ymin, ymax:这些参数包含一个数组,它们代表每行的开头和结尾。
colors:此参数是可选参数。它是默认值为k的线条的颜色。
linetsyle:此参数也是可选参数。它用于表示线型{‘实线’,‘虚线’,‘虚线’,‘虚线’}。
label:该参数也是可选参数,它是图形的标签。
返回值:这将返回LineCollection。
# -*- coding:UTF-8 -*-
import matplotlib.pyplot as plt
import pandas as pd
import matplotlib.lines as mlines
import os
print(os.getcwd(),"-----------------")
# E:\vscode\数据可视化第二版李伊配套资源 -----------------
# os.chdir("./")
os.chdir(os.path.dirname(os.path.realpath(__file__)))
print(os.getcwd(),"-----------------")
# E:\vscode\数据可视化第二版李伊配套资源\各类图形示例代码\比较类 -----------------
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams["axes.unicode_minus"] = False # 用来正常显示负号
# Import Data
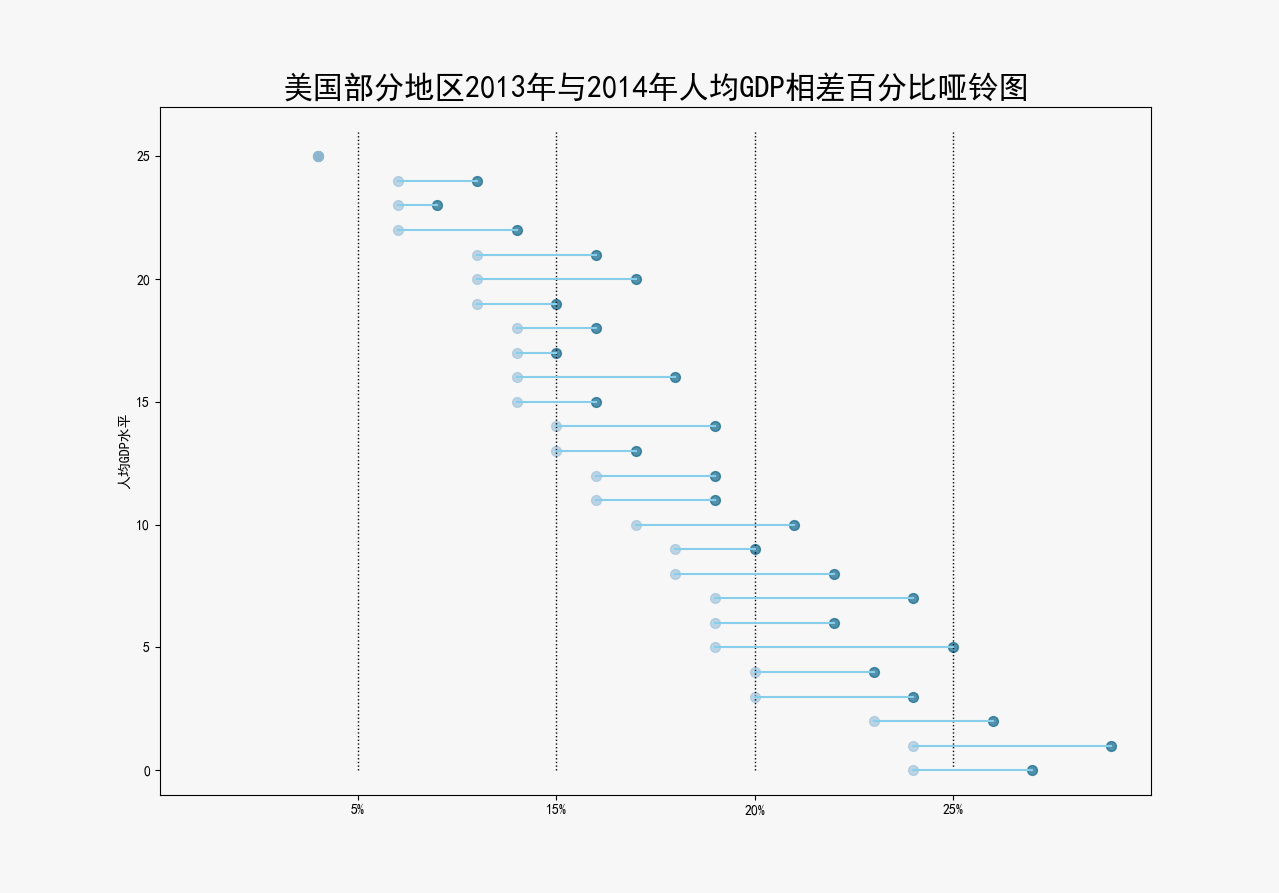
df = pd.read_csv("美国部分地图人均GDP.csv")
df.sort_values('pct_2014', inplace=True)
df.reset_index(inplace=True)
# Func to draw line segment
def newline(p1, p2, color='black'):
ax = plt.gca()
l = mlines.Line2D([p1[0], p2[0]], [p1[1], p2[1]], color='skyblue')
ax.add_line(l)
return l
# Figure and Axes
fig, ax = plt.subplots(1, 1, figsize=(14, 14), facecolor='#f7f7f7', dpi=80)
# Vertical Lines
ax.vlines(x=.05, ymin=0, ymax=26, color='black', alpha=1, linewidth=1, linestyles='dotted')
ax.vlines(x=.10, ymin=0, ymax=26, color='black', alpha=1, linewidth=1, linestyles='dotted')
ax.vlines(x=.15, ymin=0, ymax=26, color='black', alpha=1, linewidth=1, linestyles='dotted')
ax.vlines(x=.20, ymin=0, ymax=26, color='black', alpha=1, linewidth=1, linestyles='dotted')
# Points
ax.scatter(y=df['index'], x=df['pct_2013'], s=50, color='#0e668b', alpha=0.7)
ax.scatter(y=df['index'], x=df['pct_2014'], s=50, color='#a3c4dc', alpha=0.7)
# Line Segments
for i, p1, p2 in zip(df['index'], df['pct_2013'], df['pct_2014']):
newline([p1, i], [p2, i])
# Decoration
ax.set_facecolor('#f7f7f7')
ax.set_title("美国部分地区2013年与2014年人均GDP相差百分比哑铃图", fontdict={'size': 22})
ax.set(xlim=(0, .25), ylim=(-1, 27), ylabel='人均GDP水平')
ax.set_xticks([.05, .1, .15, .20])
ax.set_xticklabels(['5%', '15%', '20%', '25%'])
ax.set_xticklabels(['5%', '15%', '20%', '25%'])
plt.show()
输出为:
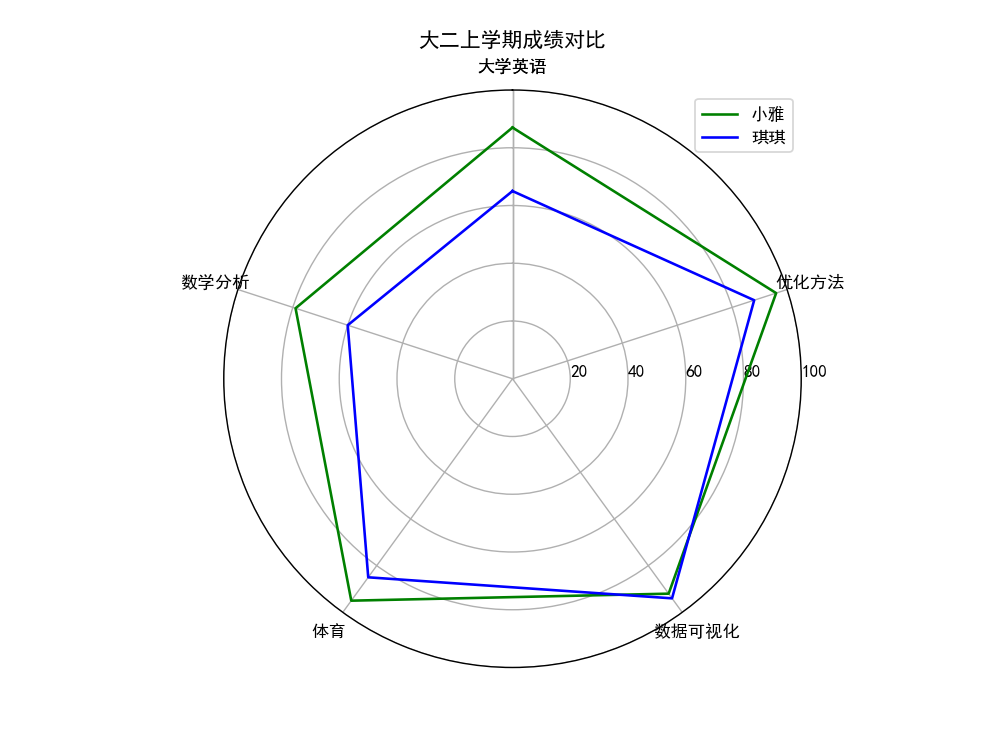
雷达图
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
results = [{"大学英语": 87, "数学分析": 79, "体育": 95, "数据可视化": 92, "优化方法": 96},
{"大学英语": 65, "数学分析": 60, "体育": 85, "数据可视化": 94, "优化方法": 88}]
data_length = len(results[0])
# 将极坐标根据数据长度进行等分
angles = np.linspace(0, 2 * np.pi, data_length, endpoint=False)
print("angles-->",angles)
# angles--> [0. 1.25663706 2.51327412 3.76991118 5.02654825]
labels = [key for key in results[0].keys()]
print("labels-->",labels)
# labels--> ['大学英语', '数学分析', '体育', '数据可视化', '优化方法']
score = [[v for v in result.values()] for result in results]
print("score-->",score)
# score--> [[87, 79, 95, 92, 96], [65, 60, 85, 94, 88]]
# 使雷达图数据封闭
score_a = np.concatenate((score[0], [score[0][0]]))
print("score_a-->",score_a)
# score_a--> [87 79 95 92 96 87]
score_b = np.concatenate((score[1], [score[1][0]]))
print("score_b-->",score_b)
# score_b--> [65 60 85 94 88 65]
angles = np.concatenate((angles, [angles[0]]))
print("angles-->",angles)
# angles--> [0. 1.25663706 2.51327412 3.76991118 5.02654825 0. ]
labels = np.concatenate((labels, [labels[0]]))
print("labels-->",labels)
# labels--> ['大学英语' '数学分析' '体育' '数据可视化' '优化方法' '大学英语']
# 设置图形的大小
fig = plt.figure(figsize=(8, 6), dpi=100)
# 新建一个子图
ax = plt.subplot(111, polar=True)
# 绘制雷达图
ax.plot(angles, score_a, color='g')
ax.plot(angles, score_b, color='b')
# 设置雷达图中每一项的标签显示
ax.set_thetagrids(angles * 180 / np.pi, labels)
# 设置雷达图的0度起始位置
ax.set_theta_zero_location('N')
# 设置雷达图的坐标刻度范围
ax.set_rlim(0, 100)
# 设置雷达图的坐标值显示角度,相对于起始角度的偏移量
ax.set_rlabel_position(270)
ax.set_title("大二上学期成绩对比")
plt.legend(["小雅", "琪琪"], loc='best')
plt.show()
输出为:
词云图
from pyecharts import options as opts
from pyecharts.charts import Page, WordCloud
from pyecharts.faker import Collector
from pyecharts.globals import SymbolType
C = Collector()
words = [
("Sam S Club", 10000),
("Macys", 6181),
("Amy Schumer", 4386),
("Jurassic World", 4055),
("Charter Communications", 2467),
("Chick Fil A", 2244),
("Planet Fitness", 1868),
("Pitch Perfect", 1484),
("Express", 1112),
("Home", 865),
("Johnny Depp", 847),
("Lena Dunham", 582),
("Lewis Hamilton", 555),
("KXAN", 550),
("Mary Ellen Mark", 462),
("Farrah Abraham", 366),
("Rita Ora", 360),
("Serena Williams", 282),
("NCAA baseball tournament", 273),
("Point Break", 265),
]
def wordcloud_diamond() -> WordCloud:
c = (
WordCloud()
.add("", words, word_size_range=[20, 100], shape=SymbolType.DIAMOND)
.set_global_opts(title_opts=opts.TitleOpts(title="WordCloud-shape-diamond"))
)
return c
wordcloud_diamond().render()
输出为:

数据可视化第二版-03部分-07章-局部与整体
光荣的三八节到了,来个充满理想年代的图片。

总结
本系列博客为基于《数据可视化第二版》一书的教学资源博客。本文主要是第07章-局部与整体可视化的案例相关。
可视化视角-局部与整体
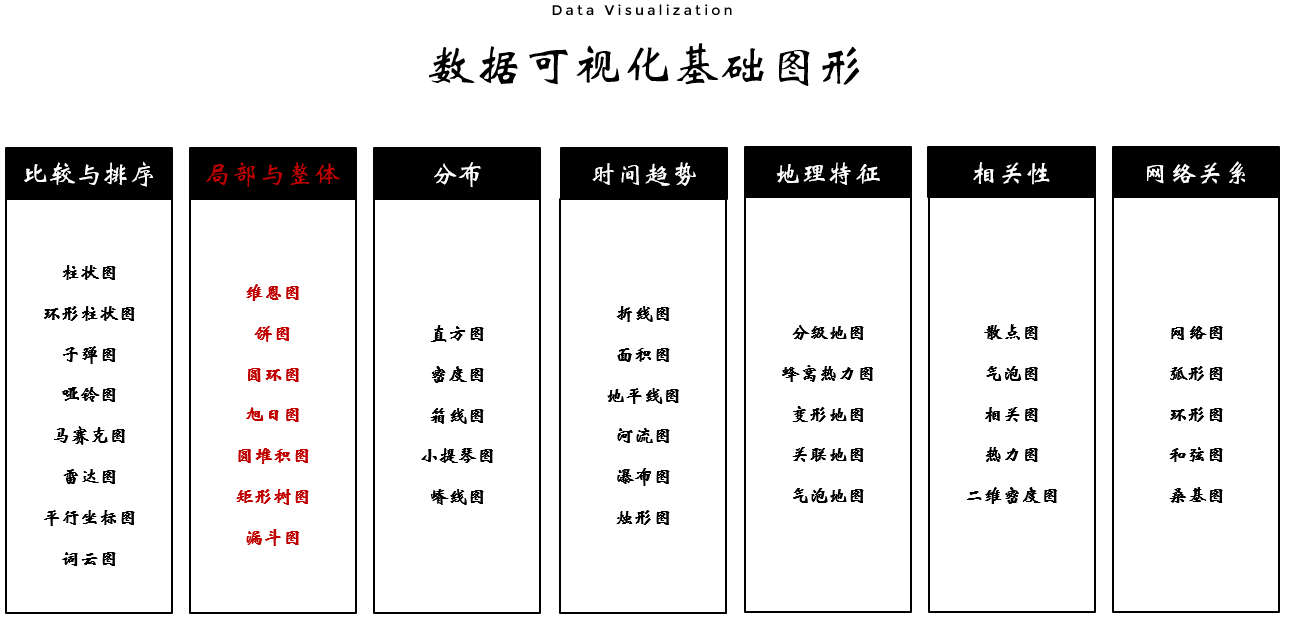
代码实现
韦恩图
可参考:https://www.jb51.net/article/238729.htm
https://pypi.org/project/matplotlib-venn/
python中Matplotlib并没有现成的函数可直接绘制venn图, 不过已经有前辈基于matplotlib.patches及matplotlib.path开发了两个轮子。
安装matplotlib_venn:
pip install matplotlib_venn -i https://pypi.tuna.tsinghua.edu.cn/simple
该包提供了四个主要函数:venn2、venn2_circles、venn3和venn3_circles。
venn3
韦恩图1
from matplotlib import pyplot as plt
from matplotlib_venn import venn3
# 1
plt.figure(figsize=(4, 4)) # 设置画布大小
plt.title("韦恩图示例")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# (Abc, aBc, ABc, abC, AbC, aBC, ABC)
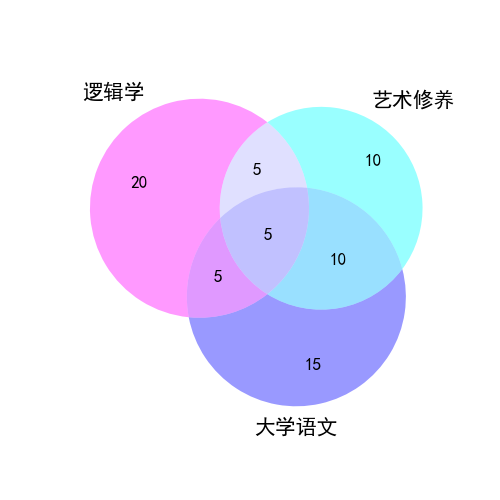
v = venn3(subsets=(20, 10, 5, 15, 5, 10, 5),
set_labels=('逻辑学', '艺术修养', '大学语文'),
set_colors=('magenta', 'cyan', 'b'))
plt.show()
输出为:

from matplotlib import pyplot as plt
from matplotlib_venn import venn3
# 2
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.figure(figsize=(4, 4)) # 设置画布大小
v = venn3(subsets=(20, 10, 5, 15, 5, 10, 5), set_labels=('逻辑学', '艺术修养', '大学语文'), set_colors=('magenta', 'cyan', 'b'))
plt.show()
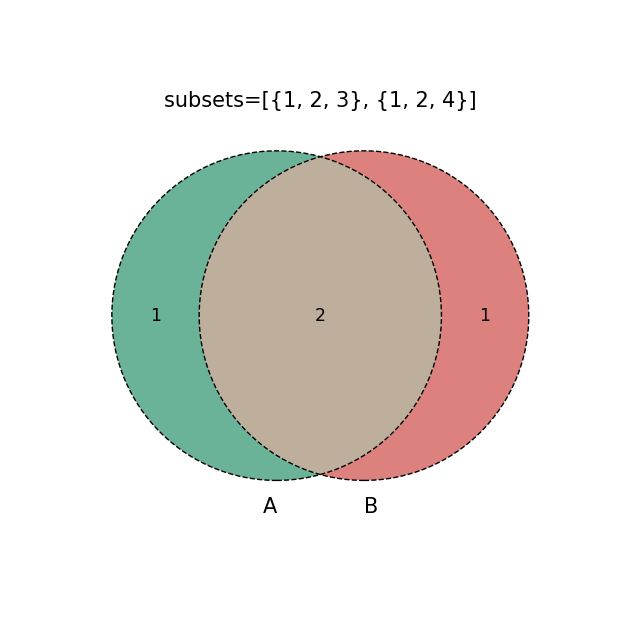
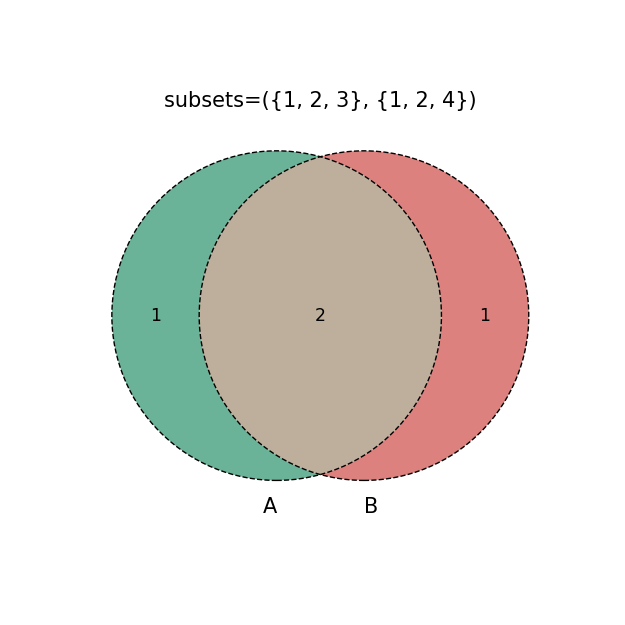
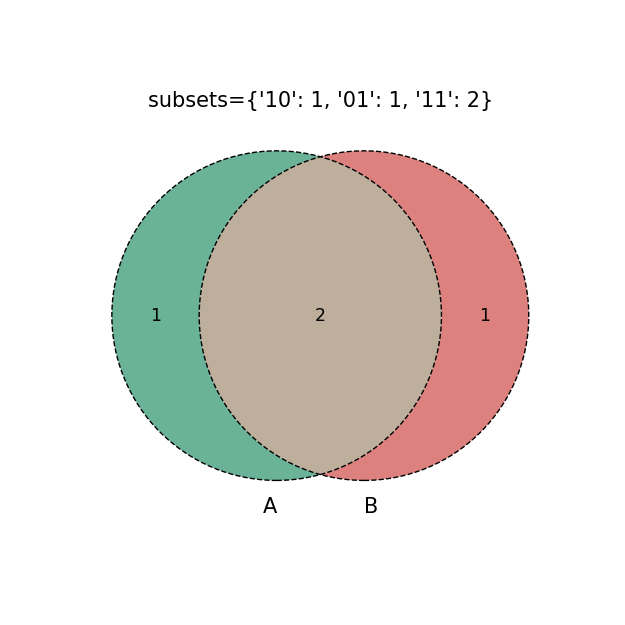
venn2
#导入依赖packages
import matplotlib.pyplot as plt
from matplotlib_venn import venn2,venn2_circles
# subsets参数
#绘图数据的格式,以下5种方式均可以,注意异同
# (Ab, aB, AB)
subset = [[{1,2,3},{1,2,4}],#列表list(集合1,集合2)
({1,2,3},{1,2,4}),#元组tuple(集合1,集合2)
{'10': 1, '01': 1, '11': 2},#字典dict(A独有,B独有,AB共有)
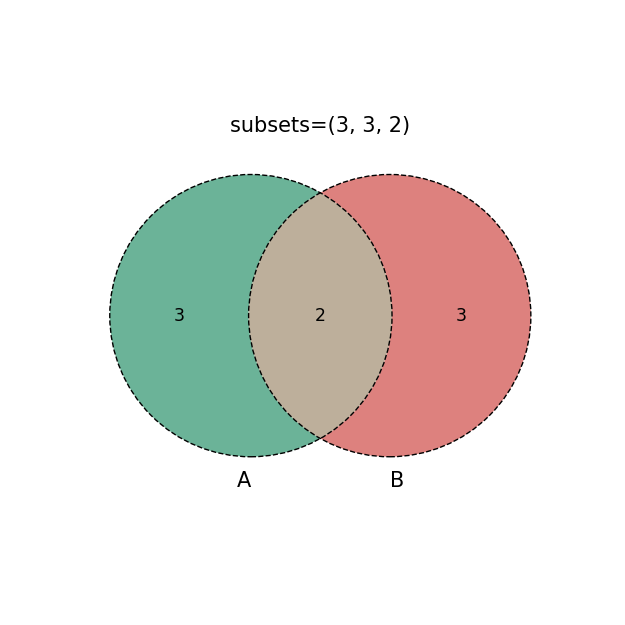
(3, 3, 2),####元组tuple(A有,B有,AB共有),注意和其它几种方式的异同点
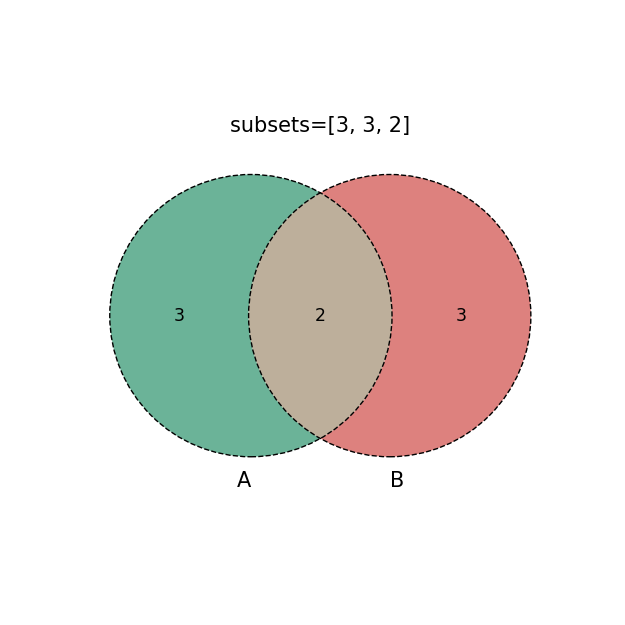
[3,3,2]#列表list(A有,B有,AB共有)
]
for i in subset:
my_dpi=100
plt.figure(figsize=(500/my_dpi, 500/my_dpi), dpi=my_dpi) # #控制图尺寸的同时,使图高分辨率(高清)显示
g=venn2(subsets=i, #默认数据绘制venn图,只需传入绘图数据
set_colors=("#098154","#c72e29"),#设置圈的颜色,中间颜色不能修改
alpha=0.6,#透明度
normalize_to=1.0,#venn图占据figure的比例,1.0为占满
)
g=venn2_circles(subsets = i,
linestyle='--', linewidth=0.8, color="black"#外框线型、线宽、颜色
)
plt.title('subsets=%s'%str(i))
plt.show()
饼图
plt.pie(x, explode=None, labels=None, colors=None, autopct=None, pctdistance=0.6, shadow=False, labeldistance=1.1,
startangle=0, radius=1, counterclock=True, wedgeprops=None, textprops=None, center=0, 0, frame=False,
rotatelabels=False, *, normalize=None, data=None)
x即每个扇形的占比的序列或数组
explode如果不是None,则是一个len(x)长度的数组,指定每一块的突出程度;突出显示,设置每一块分割出来的间隙大小
labels为每个扇形提供标签的字符串序列
colors为每个扇形提供颜色的字符串序列
autopct如果它是一个格式字符串,标签将是fmt % pct。如果它是一个函数,它将被调用。
shadow阴影
startangle从x轴逆时针旋转,饼的旋转角度
pctdistance, default: 0.6每个饼片的中心与由autopct生成的文本的开头之间距离与半径的比率,大于1的话会显示在圆外
labeldistance, default: 1.1饼状图标签绘制时的径向距离(我认为这个也与8类似是个比率)。如果设置为None,则不绘制标签,而是存储在图例()中使用。
# -*- coding:UTF-8 -*-
from matplotlib import pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams["axes.unicode_minus"] = False # 用来正常显示负号
# 1
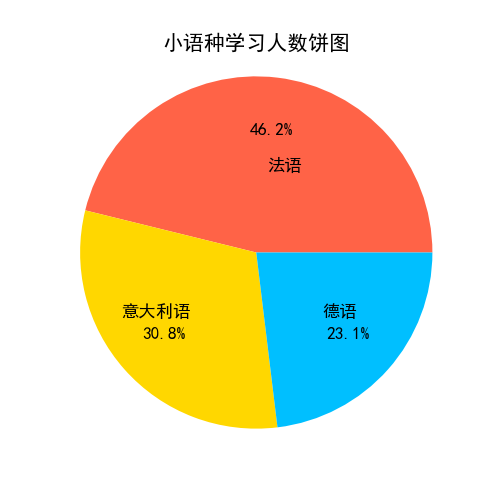
labels = '法语', '意大利语', '德语' # 建立不同类别
sizes = [60, 40, 30] # 不同类别对应的数量
fig = plt.figure(figsize=(4, 4))
ax1 = fig.add_subplot(111)
color = ['tomato', 'Gold', 'DeepSkyBlue']
ax1.pie(sizes,
labels=labels,
labeldistance=0.5,
colors=color,
textprops=dict(color='black'), # 字体颜色
autopct='%1.1f%%', # 显示数值标签
pctdistance=0.7) # 数值标签到中心点的距离
ax1.axis('equal')
plt.title('小语种学习人数饼图')
plt.show()
from matplotlib import pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams["axes.unicode_minus"] = False # 用来正常显示负号
# 2
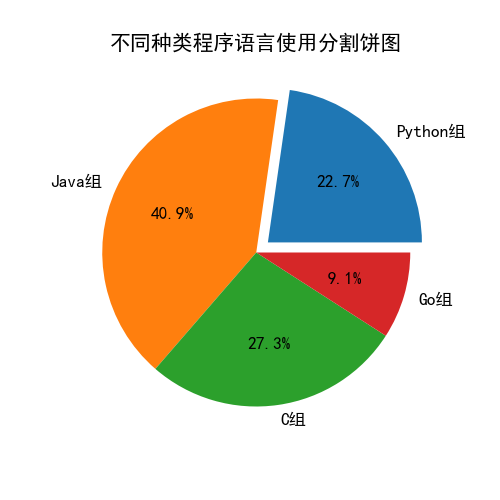
labels = 'Python组', 'Java组', 'C组', 'Go组'
sizes = [25, 45, 30, 10]
fig = plt.figure(figsize=(4, 4))
explode = (0.1, 0, 0, 0) # 分割扇形
ax2 = fig.add_subplot(111)
ax2.pie(sizes, explode=explode, # 分隔扇形
labels=labels, autopct='%1.1f%%')
plt.title('不同种类程序语言使用分割饼图')
plt.show()
from matplotlib import pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams["axes.unicode_minus"] = False # 用来正常显示负号
# 3
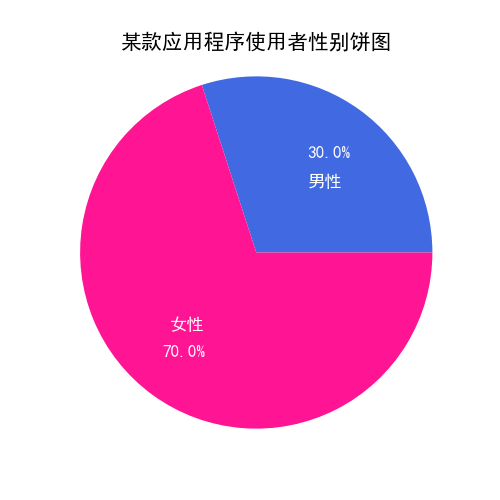
labels = '男性', '女性' # 建立不同类别
sizes = [30, 70] # 不同类别对应的数量
fig = plt.figure(figsize=(4, 4))
ax1 = fig.add_subplot(111)
color = ['RoyalBlue', 'DeepPink']
ax1.pie(sizes,
labels=labels,
labeldistance=0.5,
colors=color,
textprops=dict(color='white'), # 字体颜色
autopct='%1.1f%%', # 显示数值标签
pctdistance=0.7) # 数值标签到中心点的距离
ax1.axis('equal')
plt.title('某款应用程序使用者性别饼图')
plt.show()
环形图
参考:
[python] 基于matplotlib实现圆环图的绘制
可以重点看下这个链接。
wedgeprops中通过width参数设定内部圆的半径,edgecolor设置内部圆的颜色。
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams["axes.unicode_minus"] = False # 用来正常显示负号
# 1
labels = ['四川', '河北', '北京', '重庆', '天津'] # 设定类别
A1 = [36980.22, 35964.00, 28000.40, 19500.00, 18595.38]
color = ['yellow', 'cyan', 'lightblue', 'lightgreen', 'pink']
wedges1, texts1, autotexts1 = plt.pie(A1, autopct='%3.1f%%', radius=1, pctdistance=0.8,
colors=color, startangle=180, textprops=dict(color='black'),
wedgeprops=dict(width=0.4, edgecolor='w'))
plt.legend(wedges1, labels, fontsize=12, title='地区', loc='center right',
bbox_to_anchor=(1, 0, 0.3, 1))
plt.title('2017年四个地区生产总值')
plt.show()

import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams["axes.unicode_minus"] = False # 用来正常显示负号
# 2
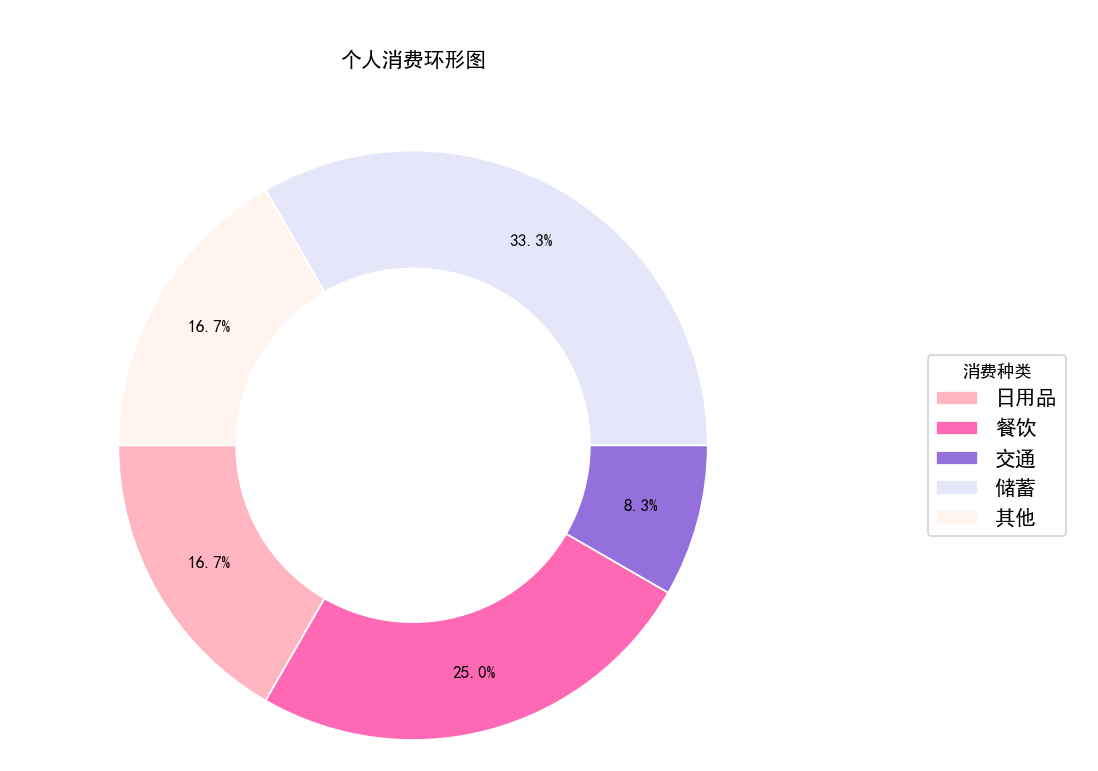
labels = ['日用品', '餐饮', '交通', '储蓄', '其他'] # 设定类别
A1 = [1000, 1500, 500, 2000, 1000]
color = ['lightpink', 'hotpink', 'MediumPurple', 'Lavender', 'seashell']
wedges1, texts1, autotexts1 = plt.pie(A1, autopct='%3.1f%%', radius=1, pctdistance=0.8,
colors=color, startangle=180, textprops=dict(color='black'),
wedgeprops=dict(width=0.4, edgecolor='w'))
plt.legend(wedges1, labels, fontsize=12, title='消费种类', loc='center right',
bbox_to_anchor=(1.1, 0, 0.3, 1))
plt.title('个人消费环形图')
plt.show()
旭日图
参考:
https://pyecharts.org/#/zh-cn/intro
https://pyecharts.org/#/zh-cn/basic_charts?id=sunburst%ef%bc%9a%e6%97%ad%e6%97%a5%e5%9b%be
from pyecharts.charts import Sunburst
from pyecharts import options as opts
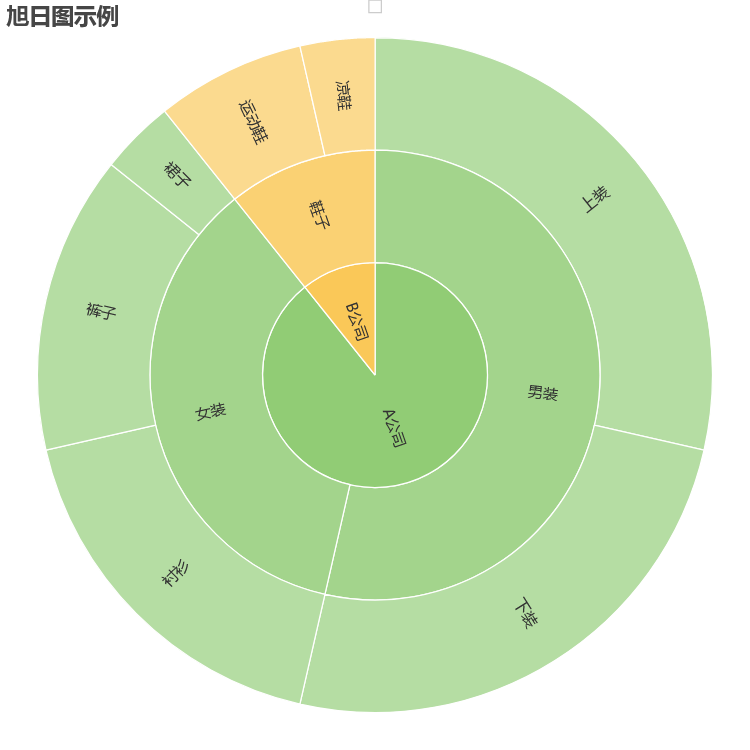
data = [
opts.SunburstItem(
name="A公司",
children=[
opts.SunburstItem(
name="男装",
value=15,
children=[
opts.SunburstItem(name="上装", value=8),
opts.SunburstItem(name="下装", value=7)]
),
opts.SunburstItem(
name="女装",
value=10,
children=[
opts.SunburstItem(name="衬衫", value=5),
opts.SunburstItem(name="裙子", value=1),
opts.SunburstItem(name="裤子", value=4),
],
),
],
),
opts.SunburstItem(
name="B公司",
children=[
opts.SunburstItem(name="鞋子",
children=[
opts.SunburstItem(name="凉鞋", value=1),
opts.SunburstItem(name="运动鞋", value=2),
],
)
],
),
]
sunburst = (
Sunburst(init_opts=opts.InitOpts(width="600px", height="600px"))
.add(series_name="", data_pair=data, radius=[0, "90%"])
.set_global_opts(title_opts=opts.TitleOpts(title="旭日图示例"))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}"))
.render("旭日图.html")
)
import os
os.system("旭日图.html")
园堆积图
参考:https://blog.csdn.net/LuohenYJ/article/details/119006870
pip install circlify==0.15.0
代码:
# 圆堆积图
import circlify
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams["axes.unicode_minus"] = False # 用来正常显示负号
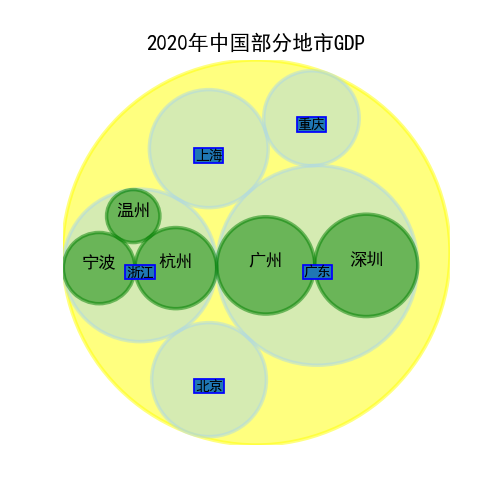
data = [{'id': '中国', 'datum': 1015986, 'children': [
{'id': "广东", 'datum': 110760.94,
'children': [
{'id': "深圳", 'datum': 27670.24},
{'id': "广州", 'datum': 25019.11}
]},
{'id': "上海", 'datum': 38700.58},
{'id': "北京", 'datum': 36102.6},
{'id': "重庆", 'datum': 25002.79},
{'id': "浙江", 'datum': 64613,
'children': [
{'id': "杭州", 'datum': 16106},
{'id': "宁波", 'datum': 12408.7},
{'id': "温州", 'datum': 6870.9}
]}
]}]
# 计算圆圈位置
circles = circlify.circlify(
data,
show_enclosure=False,
target_enclosure=circlify.Circle(x=0, y=0, r=1)
)
# 设置画布
fig, ax = plt.subplots(figsize=(4, 4))
# 设置标题
ax.set_title('2020年中国部分地市GDP')
ax.axis('off')
lim = max(
max(
abs(circle.x) + circle.r,
abs(circle.y) + circle.r,
)
for circle in circles
)
plt.xlim(-lim, lim)
plt.ylim(-lim, lim)
# 画最高级的圆圈:
for circle in circles:
if circle.level != 1:
continue
x, y, r = circle
ax.add_patch(plt.Circle((x, y), r, alpha=0.5, linewidth=2, color="yellow"))
# 画第二级的圆圈:
for circle in circles:
if circle.level != 2:
continue
x, y, r = circle
ax.add_patch(plt.Circle((x, y), r, alpha=0.5, linewidth=2, color="lightblue"))
# 画第三级的圆圈:
for circle in circles:
if circle.level != 3:
continue
x, y, r = circle
label = circle.ex["id"]
ax.add_patch(plt.Circle((x, y), r, alpha=0.5, linewidth=2, color="green"))
plt.annotate(label, (x, y), ha='center', color="black")
# 设置标签
for circle in circles:
if circle.level != 2:
continue
x, y, r = circle
label = circle.ex["id"]
plt.annotate(label, (x, y), va='top', ha='center', bbox=dict(edgecolor='blue', pad=.5),
fontsize=8)
plt.show()
输出为:
voronoi一般指泰森多边形。 泰森多边形又叫冯洛诺伊图(Voronoi diagram),得名于Georgy Voronoi,是一组由连接两邻点线段的垂直平分线组成的连续多边形。
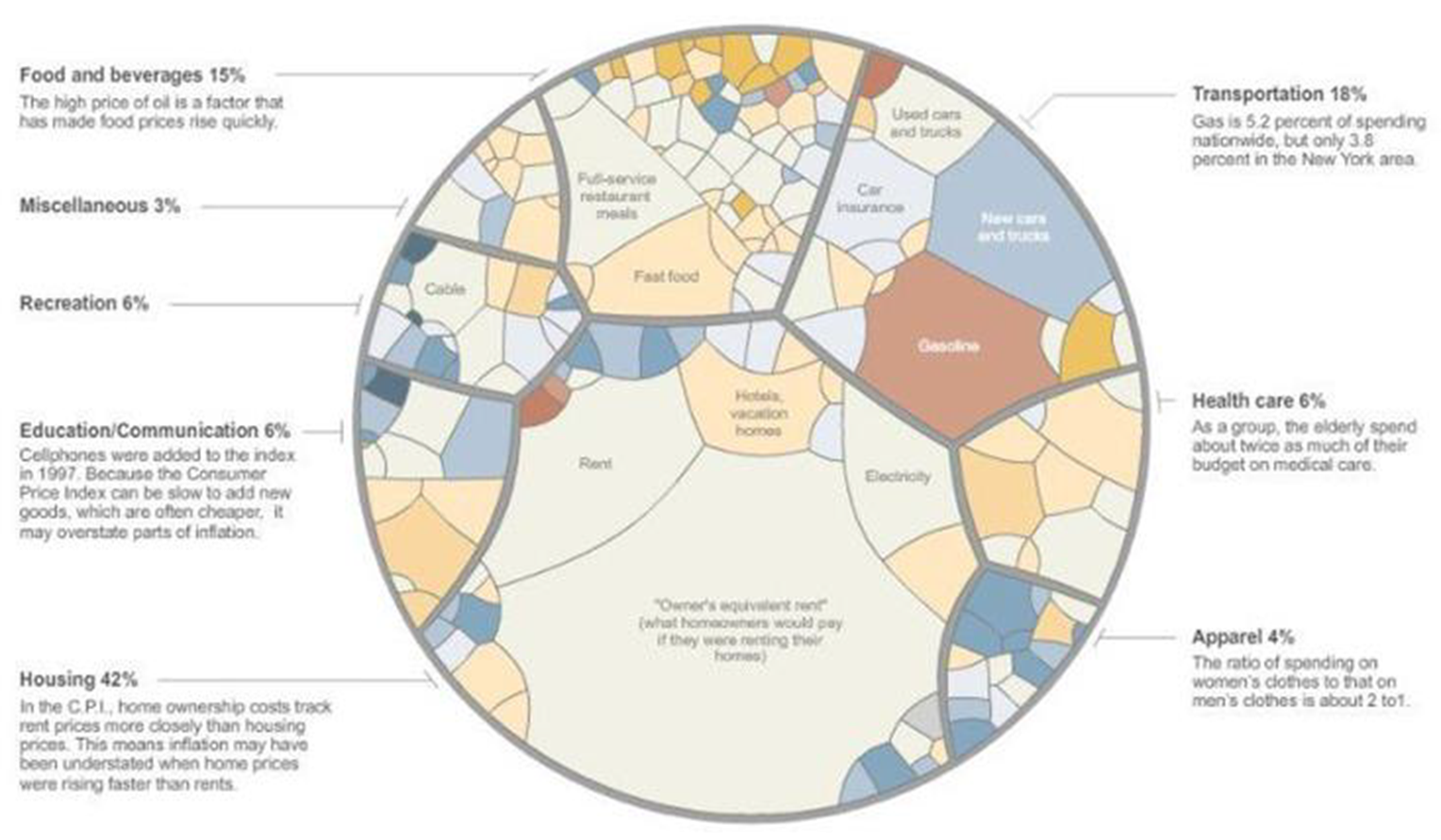
矩形树图
squarify一种坐标系,包括原点(x和y)和宽度/高度(dx和dy)的值。
从最大值到最小值排序并规范化为总面积(即dx*dy)的正值列表。
将数据生成基于matplotlib的树状图可视化
pip install squarify
# 导入第三方包
import matplotlib.pyplot as plt
import squarify
# 中文及负号处理办法
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams["axes.unicode_minus"] = False # 用来正常显示负号
# 创建数据
name = ['俄罗斯', '加拿大', '中国', '美国', '巴西', '澳大利亚',
'印度', '阿根廷', '哈萨克斯坦', '苏丹', '阿尔及利亚']
income = [1707.50, 997.1, 960.1, 936.4, 854.7, 774.1, 328.8, 278, 271.1, 250.6, 238.2]
# 绘图
colors = ['steelblue', '#9999ff', 'red', 'indianred',
'green', 'yellow', 'orange', 'lightblue', 'gold', 'lightgreen', 'pink']
plot = squarify.plot(sizes=income, # 指定绘图数据
label=name, # 指定标签
color=colors, # 指定自定义颜色
alpha=0.6, # 指定透明度
value=income, # 添加数值标签
edgecolor='white', # 设置边界框为白色
linewidth=3 # 设置边框宽度为3
)
# 设置标签大小
plt.rc('font', size=9)
# 设置标题大小
plot.set_title('世界国土面积情况(单位:万平方公里)', fontdict={'fontsize': 16})
# 去除坐标轴
plt.axis('off')
# 去除上边框和右边框刻度
plt.tick_params(top='off', right='off')
# 显示图形
plt.show()

# 导入第三方包
import matplotlib.pyplot as plt
import squarify
# 中文及负号处理办法
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams["axes.unicode_minus"] = False # 用来正常显示负号
# 2
# # 创建数据
name = ['美国', '加拿大', '中国', '德国', '意大利', '英国', '土耳其', '西班牙']
income = [529951, 23318, 83482, 126266, 152271, 79885, 52167, 163027]
# 绘图
colors = ['royalblue', 'cyan', 'red', 'violet', 'green', 'yellow', 'orange', 'lightblue']
plot = squarify.plot(sizes=income, # 指定绘图数据
label=name, # 指定标签
color=colors, # 指定自定义颜色
alpha=0.5, # 指定透明度
value=income, # 添加数值标签
linewidth=3 # 设置边框宽度为3
)
# 设置标签大小
plt.rc('font', size=9)
# 设置标题大小
plot.set_title('截止2020年4月12日的新冠肺炎感染人数', fontdict={'fontsize': 16})
# 去除坐标轴
plt.axis('off')
# 去除上边框和右边框刻度
plt.tick_params(top='off', right='off')
# 显示图形
plt.show()

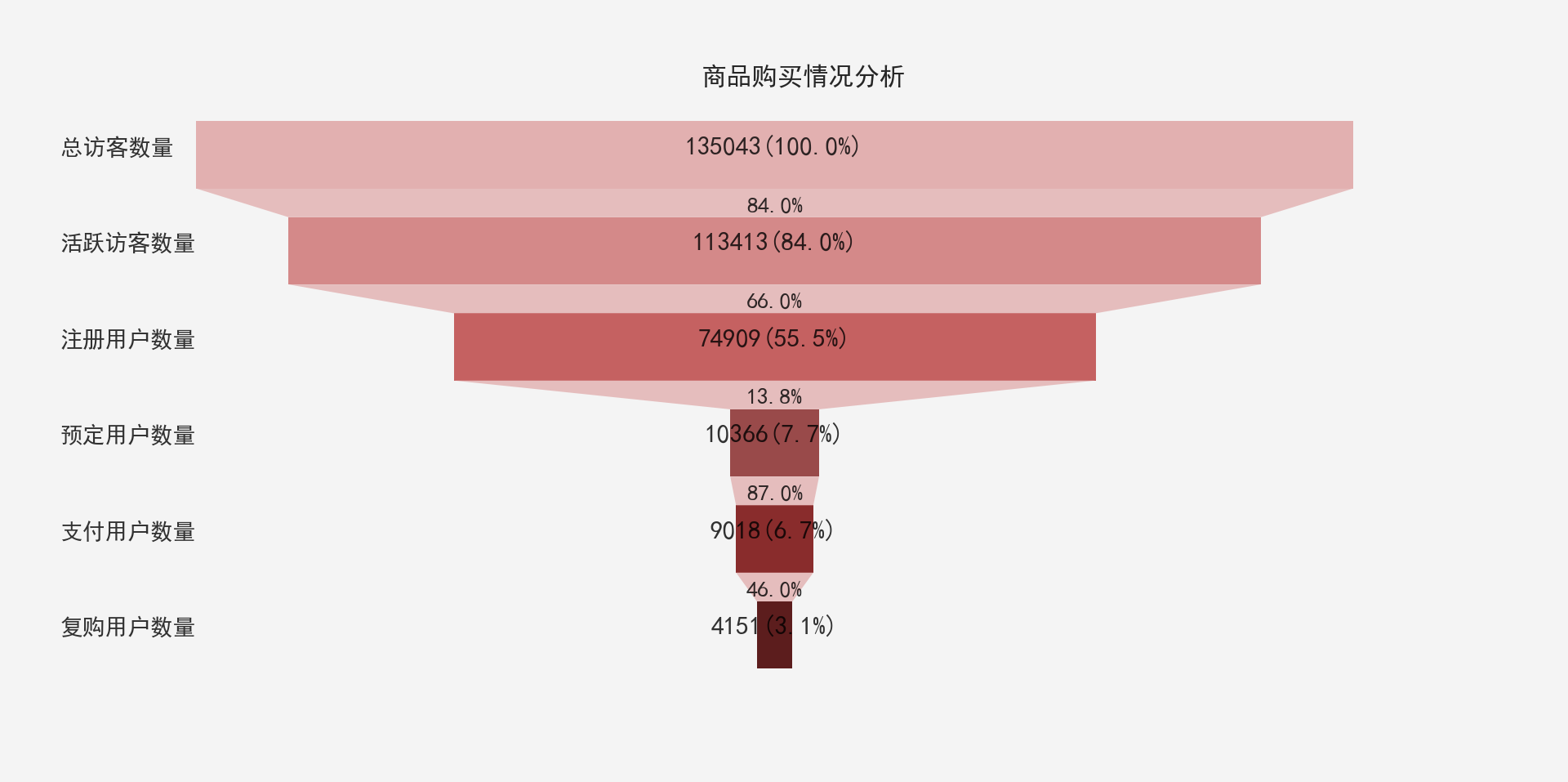
漏斗图
基于matplot’lib的漏斗图
# 漏斗图1
import numpy as np
import matplotlib.pyplot as plt
from matplotlib.patches import Polygon
# Polygon()可以用来传入按顺序组织的多边形顶点,从而生成出多边形
from matplotlib.collections import PatchCollection
plt.style.use('seaborn-dark') # 设置主题
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams["axes.unicode_minus"] = False # 用来正常显示负号
data = [135043, 113413, 74909, 10366, 9018, 4151]
phase = ['总访客数量 ', '活跃访客数量', '注册用户数量', '预定用户数量', '支付用户数量', '复购用户数量']
visitor_num = 135043
data1 = [visitor_num / 2 - i / 2 for i in data]
data2 = [i + j for i, j in zip(data, data1)]
color_list = ['#5c1d1d', '#892c2c', '#994a4a', '#c56161', '#d48989', '#e2b0b0'] # 柱子颜色
fig, ax = plt.subplots(figsize=(16, 9), facecolor='#f4f4f4')
ax.barh(phase[::-1], data2[::-1], color=color_list, height=0.7) # 柱宽设置为0.7
ax.barh(phase[::-1], data1[::-1], color='#f4f4f4', height=0.7) # 设置成背景同色
ax.axis('off')
polygons = []
for i in range(len(data)):
# 阶段
ax.text(
0, # 坐标
i, # 高度
phase[::-1][i], # 文本
color='black', alpha=0.8, size=16, ha="right")
# 数量
ax.text(
data2[0] / 2,
i,
str(data[::-1][i]) + '(' + str(round(data[::-1][i] / data[0] * 100, 1)) + '%)',
color='black', alpha=0.8, size=18, ha="center")
if i < 5:
# 比例
ax.text(
data2[0] / 2,
4.4 - i,
str(round(data[i + 1] / data[i], 3) * 100) + '%',
color='black', alpha=0.8, size=16, ha="center")
# 绘制多边形
polygons.append(Polygon(xy=np.array([(data1[i + 1], 4 + 0.35 - i),
# 因为柱状图的宽度设置成了0.7,所以一半便是0.35
(data2[i + 1], 4 + 0.35 - i),
(data2[i], 5 - 0.35 - i),
(data1[i], 5 - 0.35 - i)])))
# 使用add_collection与PatchCollection来向Axes上添加多边形
ax.add_collection(PatchCollection(polygons,
facecolor='#e2b0b0',
alpha=0.8));
plt.title("商品购买情况分析", fontsize=18)
plt.show()
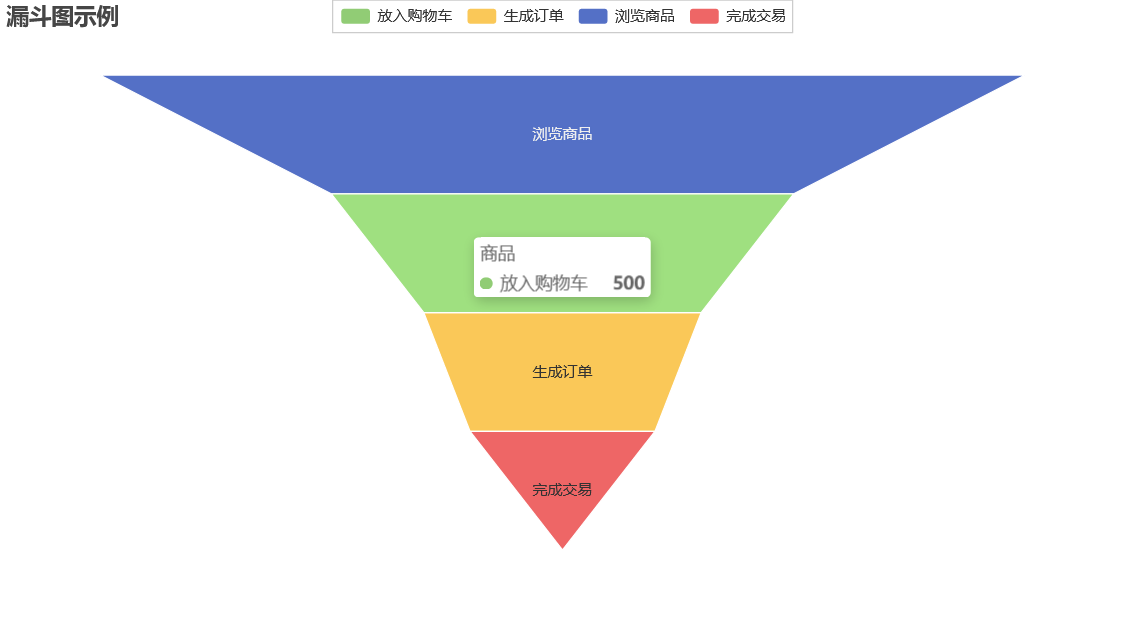
基于pyecharts的漏斗图
pip install openpyxl
# 漏斗图2
import pandas as pd
import os
os.chdir(os.path.dirname(os.path.realpath(__file__)))
data = pd.read_excel('漏斗图.xlsx', 'Sheet1')
attrs = data['环节'].tolist()
attr_value = data['人数'].tolist()
from pyecharts import options as opts
from pyecharts.charts import Funnel
c = (
Funnel()
.add("商品", [list(z) for z in zip(attrs, attr_value)],
label_opts=opts.LabelOpts(position="inside"),
)
.set_global_opts(title_opts=opts.TitleOpts(title="漏斗图示例"))
.render("漏斗图.html")
)
import os
os.system("漏斗图.html")
输出为:
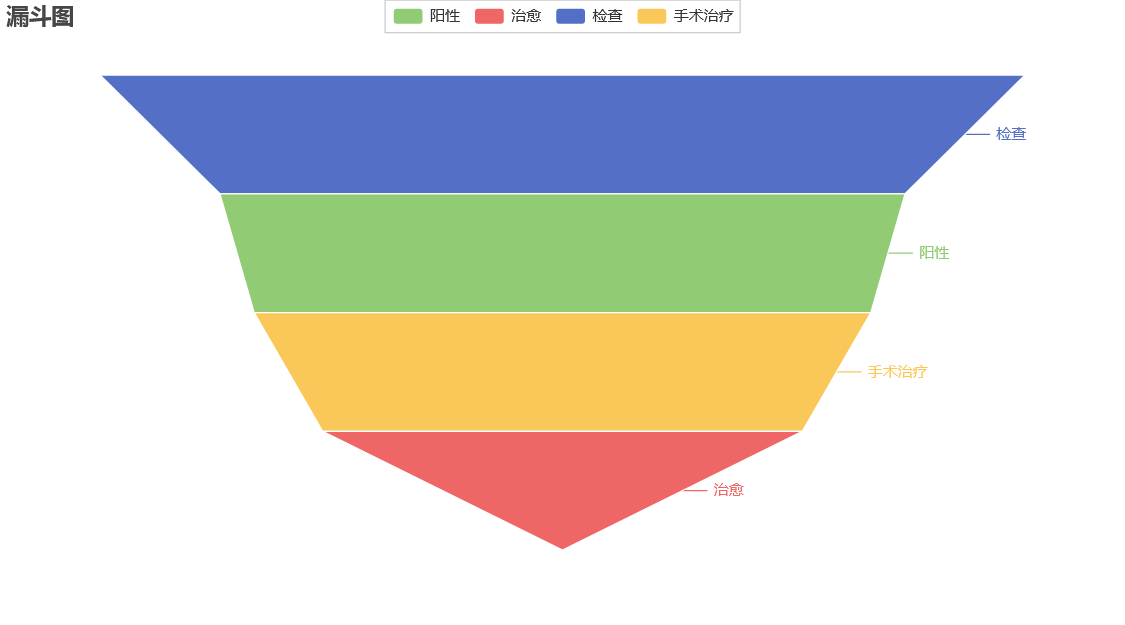
基于pyecharts的治愈率漏斗图
from pyecharts import options as opts
from pyecharts.charts import Funnel
data = [13500, 10000, 9000, 7000]
phase = ['检查', '阳性', '手术治疗', '治愈']
c = (
Funnel()
.add("阶段", [list(z) for z in zip(phase, data)])
.set_global_opts(title_opts=opts.TitleOpts(title="漏斗图"))
.render("治愈率漏斗图.html")
)
import os
os.system("治愈率漏斗图.html")
虚拟环境相关命令汇集
激活conda
d:\ProgramData\Anaconda3\Scripts\activate
创建python版本的命令
conda create -n py10 python=3.10
查看当前的python版本
conda env list
切换到指定的python版本
conda activate py10
激活虚拟环境后,安装python虚拟环境
python -m venv venv202302
切换路径到文件当前路径
import os
print(os.getcwd(),"-----------------")
# os.chdir("./")
os.chdir(os.path.dirname(os.path.realpath(__file__)))
print(os.getcwd(),"-----------------")
临时使用阿里镜像安装python包
pip install 包名 -i https://mirrors.aliyun.com/pypi/simple/
持久使用阿里镜像安装python包
pip config set global.index-url https://mirrors.aliyun.com/pypi/simple/
数据可视化第二版-03部分-08章-分布
总结
本系列博客为基于《数据可视化第二版》一书的教学资源博客。本文主要是第8章,分布可视化的案例相关。
可视化视角-分布

代码实现
安装依赖
pip install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install seaborn -i https://pypi.tuna.tsinghua.edu.cn/simple
直方图
直方图依赖
from sklearn import datasets
import matplotlib.pyplot as plt
import numpy as np
import pandas as pd
from numpy.random import randn
import matplotlib as mpl
import seaborn as sns
from scipy.stats.kde import gaussian_kde
from scipy.stats import norm
from numpy import linspace, hstack
from pylab import plot, show, hist
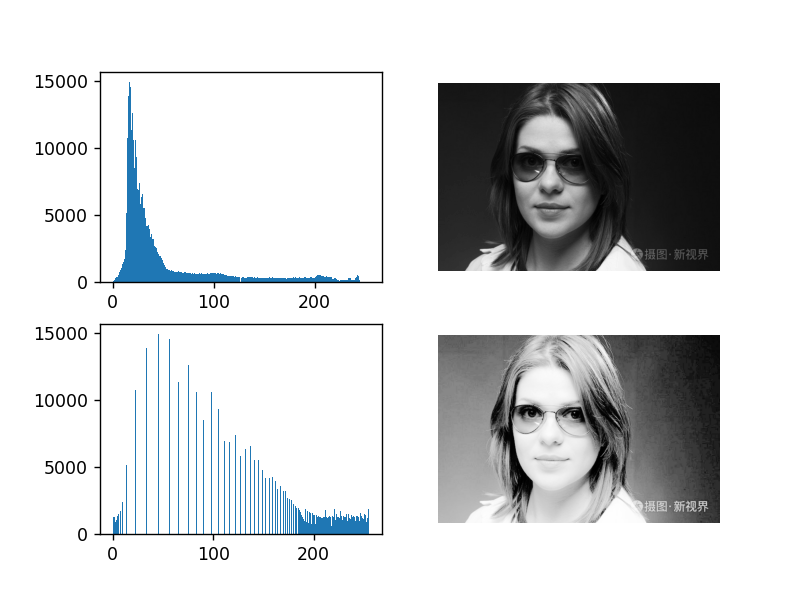
直方图在计算机视觉中的应用
参考:https://www.dandelioncloud.cn/article/details/1564611965912051714
https://www.shuzhiduo.com/A/GBJrYeBWz0/
import numpy as np
from PIL import Image
import matplotlib.pyplot as plt
import matplotlib.cm as cm
def histeq(image_array,image_bins=256):
# 将图像矩阵转化成直方图数据,返回元组(频数,直方图区间坐标)
image_array2,bins = np.histogram(image_array.flatten(),image_bins)
# 计算直方图的累积函数
cdf = image_array2.cumsum()
# 将累积函数转化到区间[0,255]
cdf = (255.0/cdf[-1])*cdf
# 原图像矩阵利用累积函数进行转化,插值过程
image2_array = np.interp(image_array.flatten(),bins[:-1],cdf)
# 返回均衡化后的图像矩阵和累积函数
return image2_array.reshape(image_array.shape),cdf
image = Image.open("pika1.jpg").convert("L")
image_array = np.array(image)
plt.subplot(2,2,1)
plt.hist(image_array.flatten(),256)
plt.subplot(2,2,2)
plt.imshow(image,cmap=cm.gray)
plt.axis("off")
a = histeq(image_array) # 利用刚定义的直方图均衡化函数对图像进行均衡化处理
plt.subplot(2,2,3)
plt.hist(a[0].flatten(),256)
plt.subplot(2,2,4)
plt.imshow(Image.fromarray(a[0]),cmap=cm.gray)
plt.axis("off")
plt.show()
pika1.jpg

输出为:
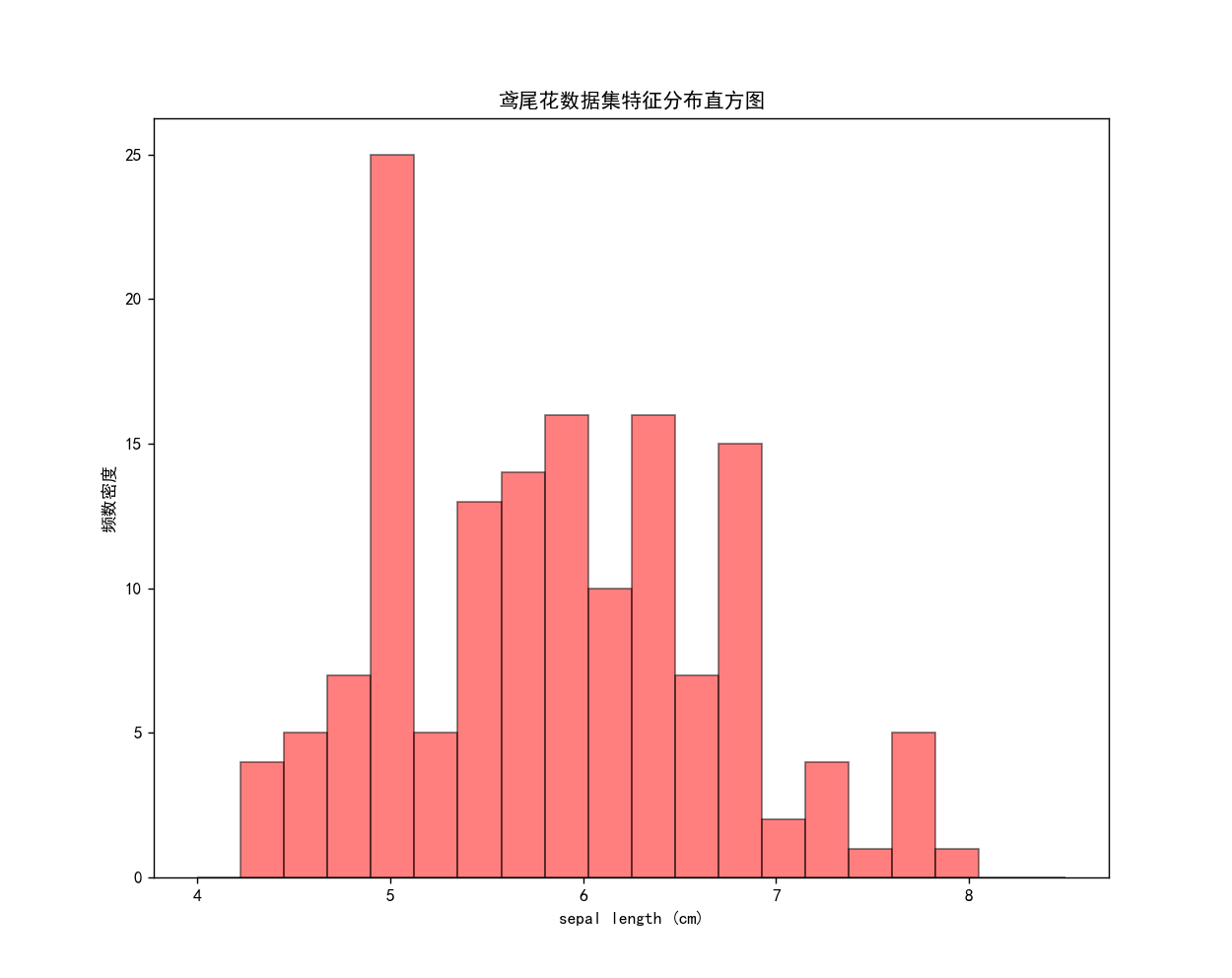
直方图案例1
# 直方图
df = datasets.load_iris()
plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加中文字体
plt.figure(figsize=(10, 8)) # 设置画布大小
plt.hist(df.data[:, 0], # 选择鸢尾花数据集的第一个特征
bins=20, # 设置分组数量
alpha=0.5, # 颜色透明度
color="r", # 直方图矩形填充颜色
edgecolor="black", # 直方图矩形边框颜色
range=(4, 8.5)) # 设置直方图边界
plt.xlabel(df.feature_names[0]) # x标签
plt.ylabel("频数密度") # y标签
plt.title("鸢尾花数据集特征分布直方图")
plt.show()
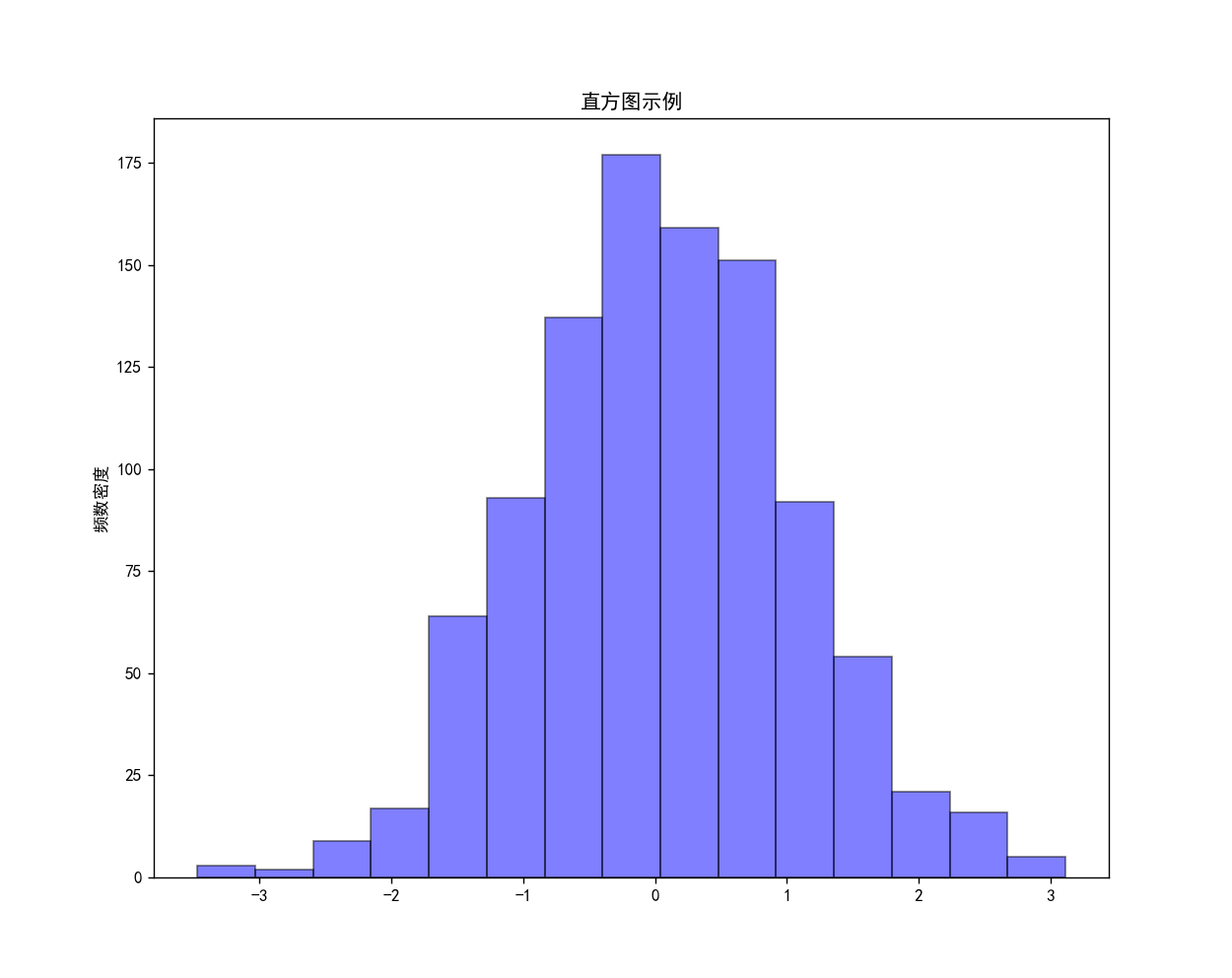
直方图示例2
# 直方图示例
data = np.random.randn(1000)
plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加中文字体
plt.rcParams['axes.unicode_minus'] = False
plt.figure(figsize=(10, 8)) # 设置画布大小
plt.hist(data,
bins=15, # 设置分组数量
alpha=0.5, # 颜色透明度
color="blue", # 直方图矩形填充颜色
edgecolor="black") # 直方图矩形边框颜色
plt.xlabel("") # x标签
plt.ylabel("频数密度") # y标签
plt.title("直方图示例")
plt.show()
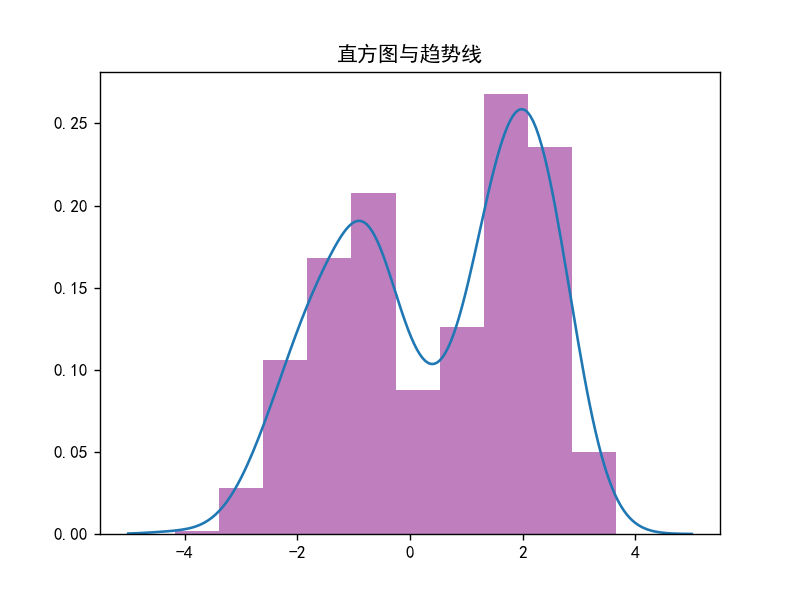
直方图与趋势线
# 直方图与趋势线
plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加中文字体
plt.rcParams['axes.unicode_minus'] = False
sample1 = norm.rvs(loc=-1.0, scale=1, size=320)
sample2 = norm.rvs(loc=2.0, scale=0.6, size=320)
sample = hstack([sample1, sample2])
probDensityFun = gaussian_kde(sample)
x = linspace(-5, 5, 200)
plot(x, probDensityFun(x))
hist(sample, density=True, alpha=0.5, color="purple")
plt.title("直方图与趋势线")
show()
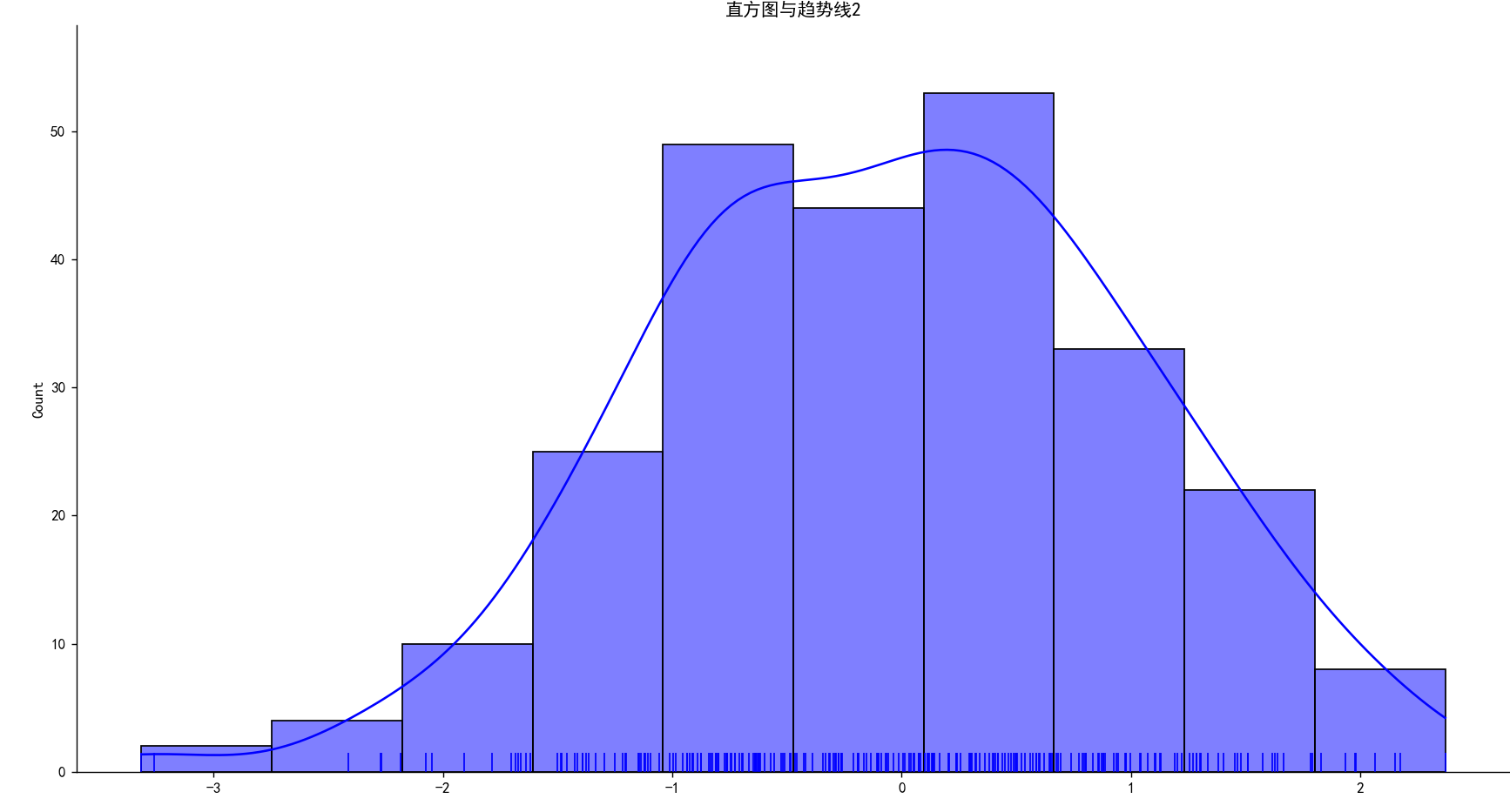
直方图与趋势线2
# 直方图与趋势线2
data = randn(250)
sns.set_palette("hls")
plt.rcParams['axes.unicode_minus'] = False
mpl.rc("figure", figsize=(10, 6))
sns.displot(data, bins=10, kde=True,
rug=True,
color='b')
plt.title("直方图与趋势线2")
plt.show()
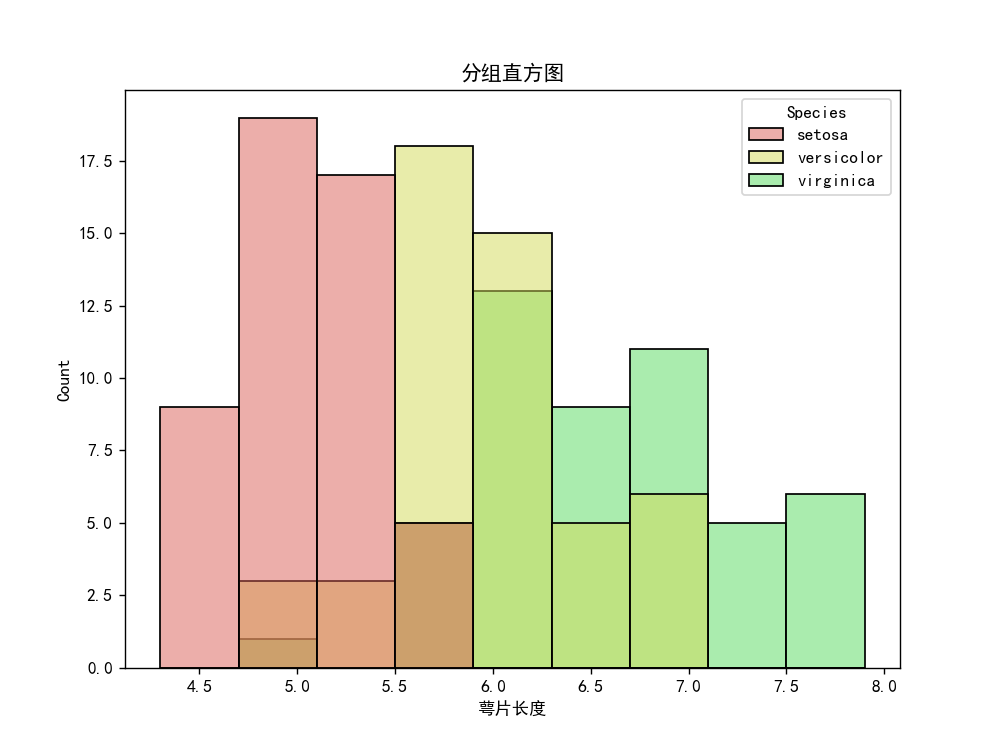
分组直方图
import os
os.chdir(os.path.dirname(__file__))
iris = pd.read_csv("鸢尾花.csv")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加中文字体
plt.figure(figsize=(8, 6)) # 设置画布大小
sns.histplot(data=iris, x="Sepal.Length", hue="Species", alpha=0.5)
plt.title("分组直方图")
plt.xlabel("萼片长度")
plt.show()
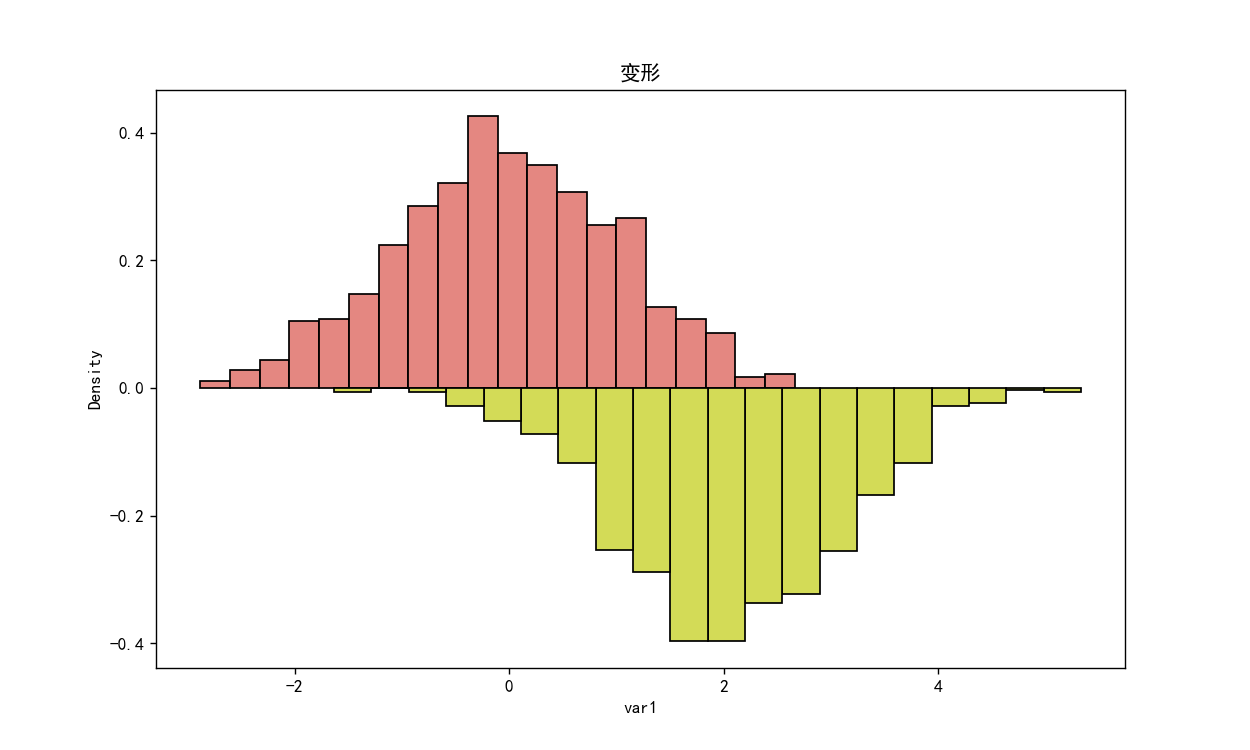
变形
# 变形
# 创建数据集
df = pd.DataFrame({
'var1': np.random.normal(size=1000),
'var2': np.random.normal(loc=2, size=1000) * -1
})
# 画布大小
plt.rcParams["figure.figsize"] = 10, 6
plt.rcParams['axes.unicode_minus'] = False
# 画变量1的频率分布直方图
sns.histplot(x=df.var1, stat="density", bins=20)
# 画变量2的频率分布直方图
n_bins = 20
# 获得变量2的分组
heights, bins = np.histogram(df.var2, density=True, bins=n_bins)
# 给变量2的高度乘以1
heights *= -1
bin_width = np.diff(bins)[0]
bin_pos = (bins[:-1] + bin_width / 2) * -1
plt.bar(bin_pos, heights, width=bin_width, edgecolor='black')
plt.title("变形")
plt.show()
密度图
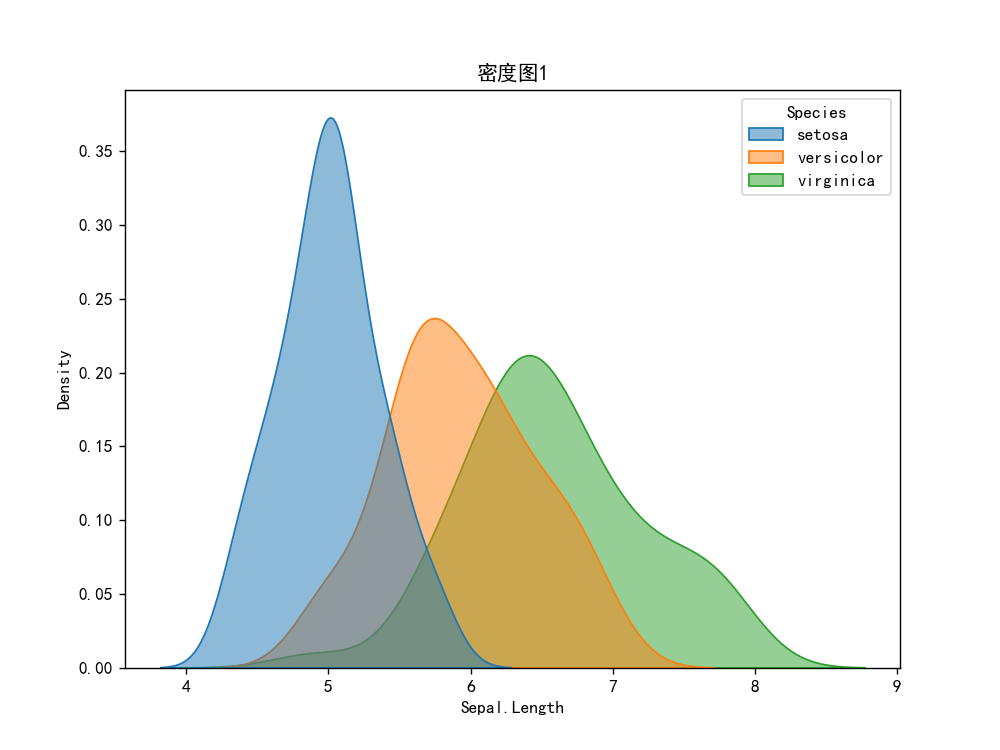
密度图1
# 密度图1
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import os
os.chdir(os.path.dirname(__file__))
iris = pd.read_csv("鸢尾花.csv")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加中文字体
plt.figure(figsize=(8, 6)) # 设置画布大小
sns.kdeplot(data=iris, x="Sepal.Length", hue="Species", alpha=0.5, fill="Species")
plt.title("密度图1")
plt.show()
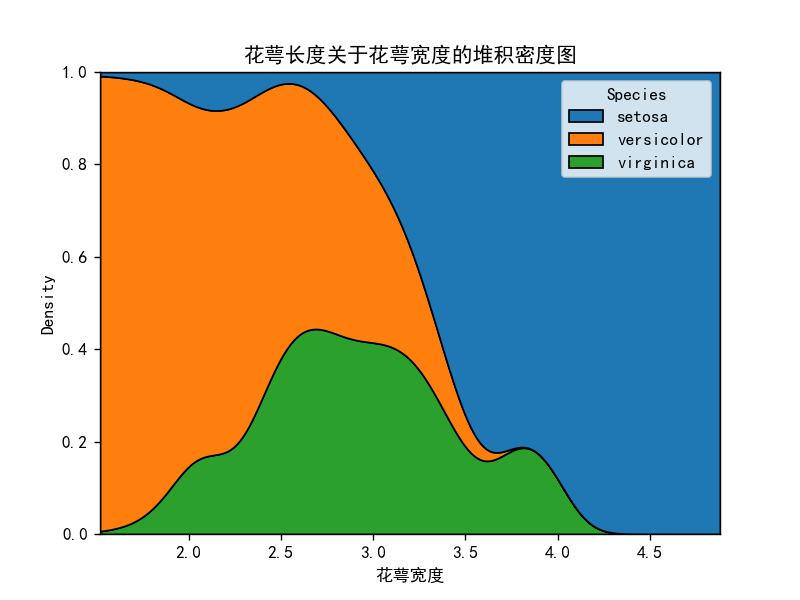
密度图2-堆积密度图
# 密度图2
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import os
os.chdir(os.path.dirname(__file__))
iris = pd.read_csv("鸢尾花.csv")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加中文字体
sns.kdeplot(data=iris.iloc[:, [1, 2, 5]], x="Sepal.Width", hue="Species", common_norm=False, multiple="fill", alpha=1)
plt.title("花萼长度关于花萼宽度的堆积密度图")
plt.xlabel("花萼宽度")
plt.show()
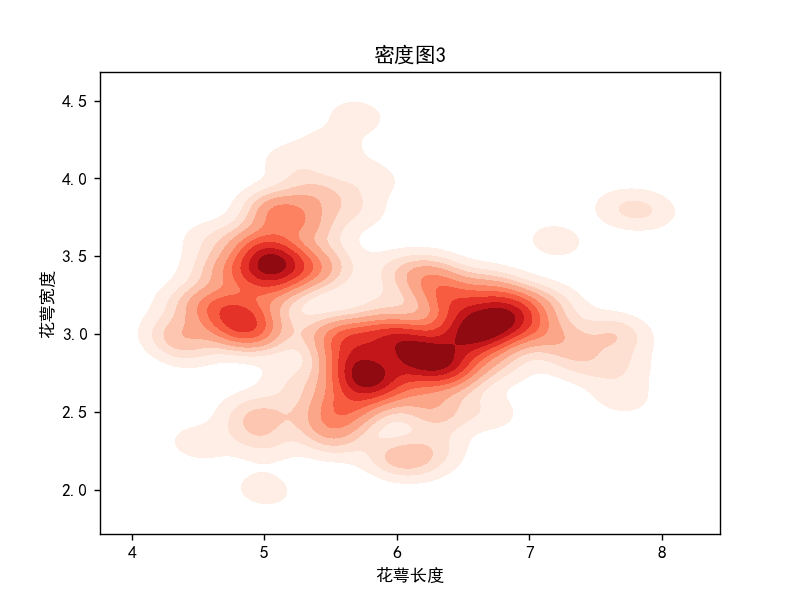
密度图3-二维密度图
# 密度图3
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import os
os.chdir(os.path.dirname(__file__))
iris = pd.read_csv("鸢尾花.csv")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加中文字体
sns.kdeplot(x=iris.iloc[:, 1], y=iris.iloc[:, 2], cmap="Reds", fill=True, bw_adjust=.5)
plt.xlabel("花萼长度")
plt.ylabel("花萼宽度")
plt.title("密度图3")
plt.show()
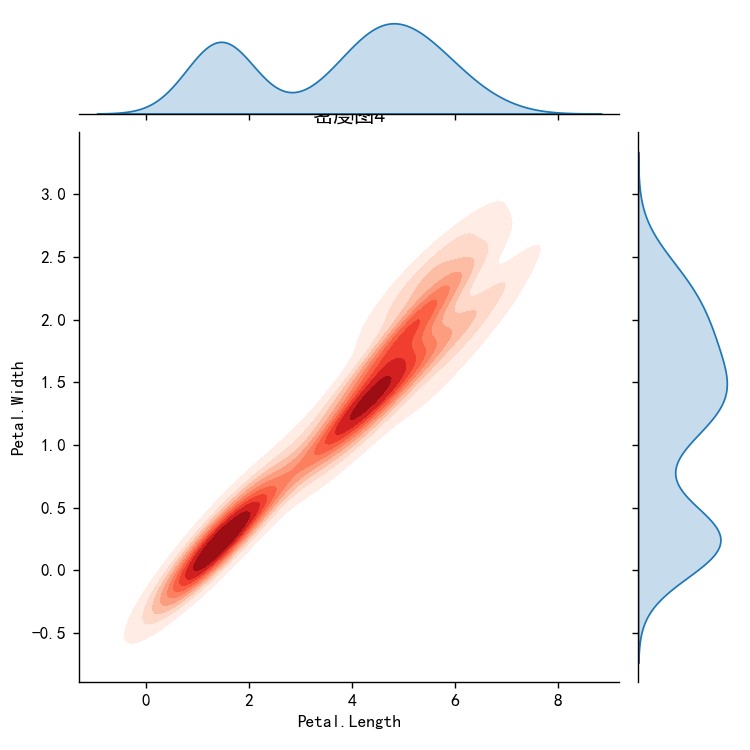
密度图4-边际密度图
# 密度图4
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
iris = pd.read_csv("鸢尾花.csv")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加中文字体
plt.rcParams['axes.unicode_minus'] = False
sns.jointplot(x=iris["Petal.Length"], y=iris["Petal.Width"], kind='kde', cmap="Reds", fill=True)
plt.title("密度图4")
plt.show()
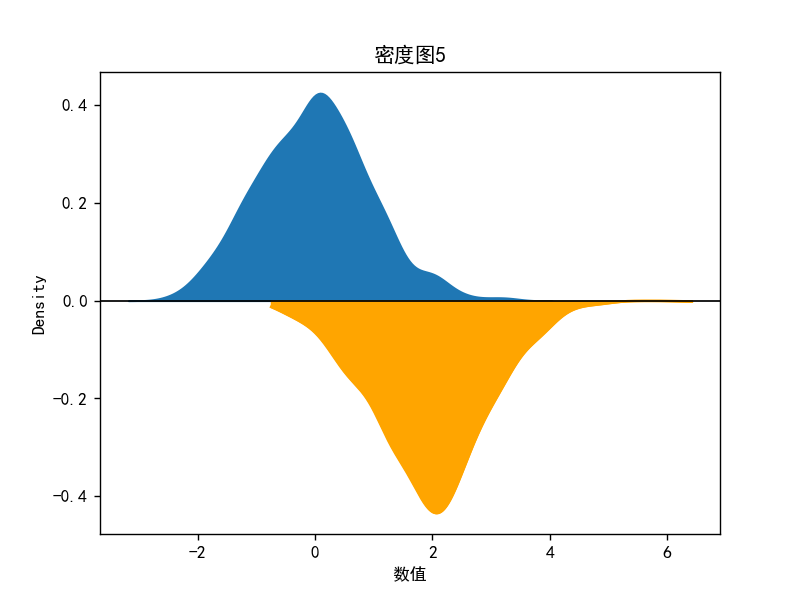
密度图5-镜像密度图
# 密度图5
import numpy as np
from numpy import linspace
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from scipy.stats import gaussian_kde
# 创建数据
df = pd.DataFrame({
'var1': np.random.normal(size=1000),
'var2': np.random.normal(loc=2, size=1000) * -1
})
plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加中文字体
plt.rcParams['axes.unicode_minus'] = False
# 画变量1的核密度图
sns.kdeplot(data=df, x="var1", fill=True, alpha=1)
# 画变量2的密度图
kde = gaussian_kde(df.var2)
x_range = linspace(min(df.var2), max(df.var2), len(df.var2))
sns.lineplot(x=x_range * -1, y=kde(x_range) * -1, color='orange')
plt.fill_between(x_range * -1, kde(x_range) * -1, color='orange')
plt.xlabel("数值")
plt.axhline(y=0, linestyle='-', linewidth=1, color='black')
plt.title("密度图5")
# show the graph
plt.show()
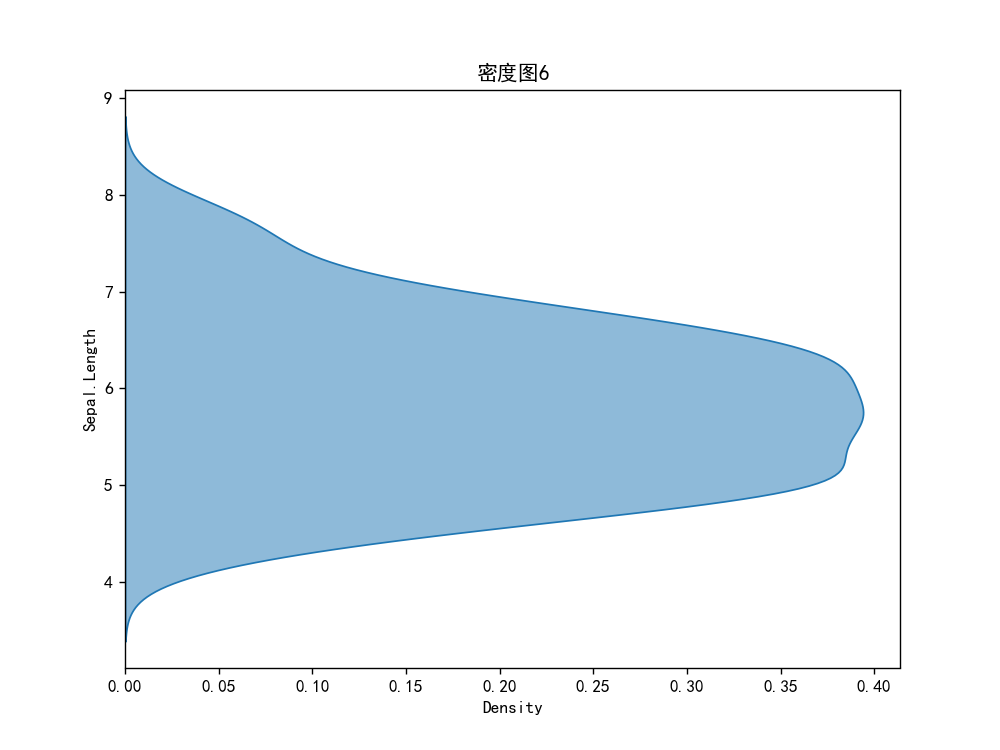
密度图6-横向密度图
# 密度图6
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
import warnings
warnings.filterwarnings("ignore")
iris = pd.read_csv("鸢尾花.csv")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加中文字体
plt.figure(figsize=(8, 6)) # 设置画布大小
sns.kdeplot(data=iris, x="Sepal.Length", alpha=0.5, fill="red", vertical=True)
plt.title("密度图6")
plt.show()
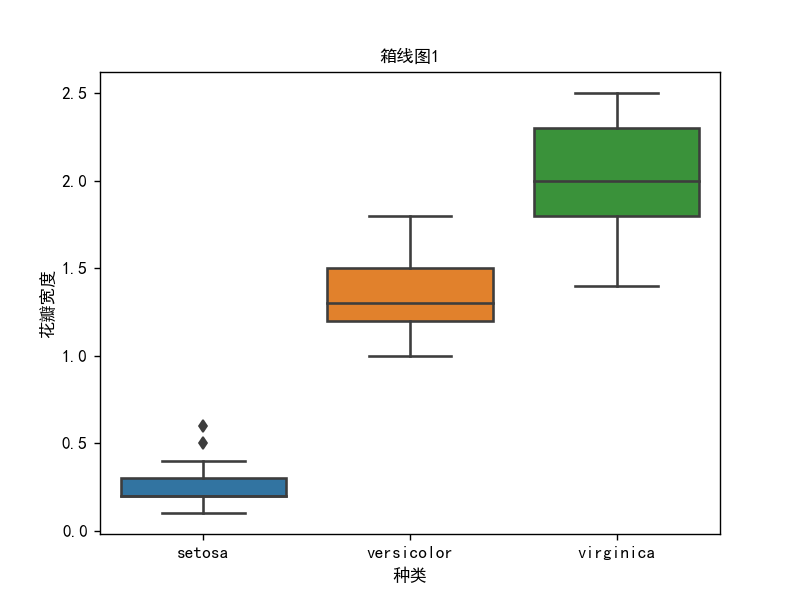
箱线图
箱线图1
# 箱线图1
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import os
os.chdir(os.path.dirname(__file__))
iris = pd.read_csv("鸢尾花.csv")
df = iris
plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加中文字体
sns.boxplot(x=df["Species"], y=df["Petal.Width"])
plt.xlabel("种类")
plt.ylabel("花瓣宽度")
plt.title("箱线图1", fontsize=10)
plt.show()
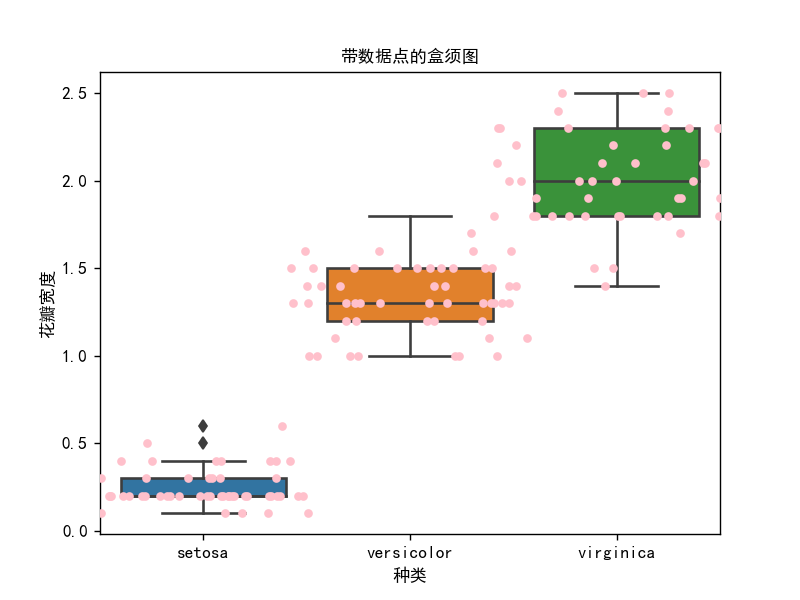
箱线图2-带数据点的盒须图
# 箱线图2
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import os
os.chdir(os.path.dirname(__file__))
iris = pd.read_csv("鸢尾花.csv")
df = iris
plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加中文字体
sns.boxplot(x=df["Species"], y=df["Petal.Width"])
sns.stripplot(x="Species", y="Petal.Width", data=df, jitter=0.6, color="pink")
plt.xlabel("种类")
plt.ylabel("花瓣宽度")
plt.title("带数据点的盒须图", fontsize=10)
plt.show()
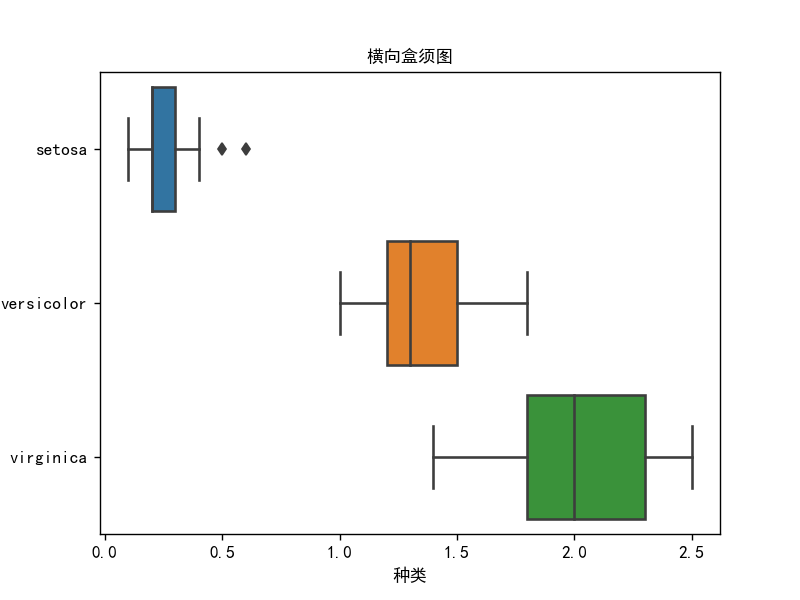
箱线图3-横向合须图
# 箱线图3
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import os
os.chdir(os.path.dirname(__file__))
iris = pd.read_csv("鸢尾花.csv")
df = iris
sns.boxplot(y=df["Species"], x=df["Petal.Width"], )
plt.xlabel("种类")
plt.ylabel("花瓣宽度")
plt.title("横向盒须图", fontsize=10)
plt.show()
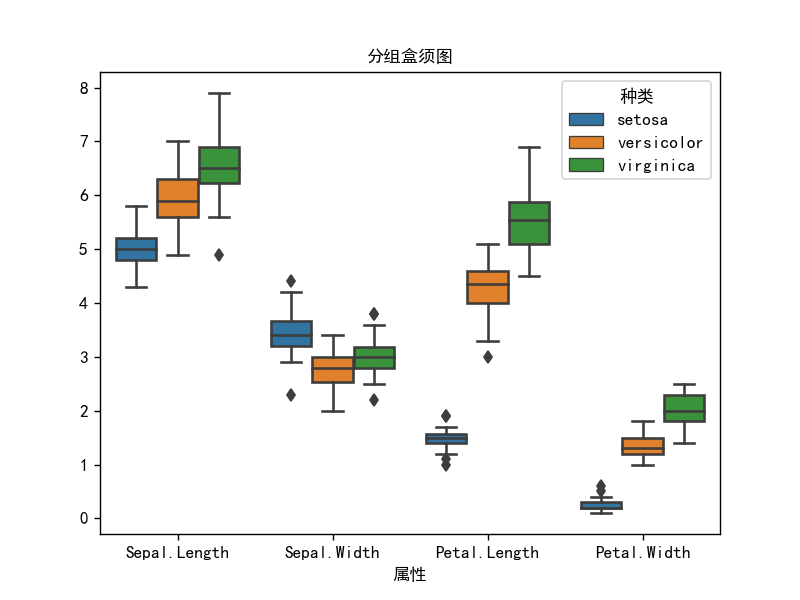
箱线图4-分组合须图
# 箱线图4
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import os
os.chdir(os.path.dirname(__file__))
plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加中文字体
iris = pd.read_csv("鸢尾花2.csv")
df = iris
sns.boxplot(x=df["属性"], y=df["指标值"], hue=(df["种类"]), )
plt.xlabel("属性")
plt.ylabel("")
plt.title("分组盒须图", fontsize=10)
plt.show()
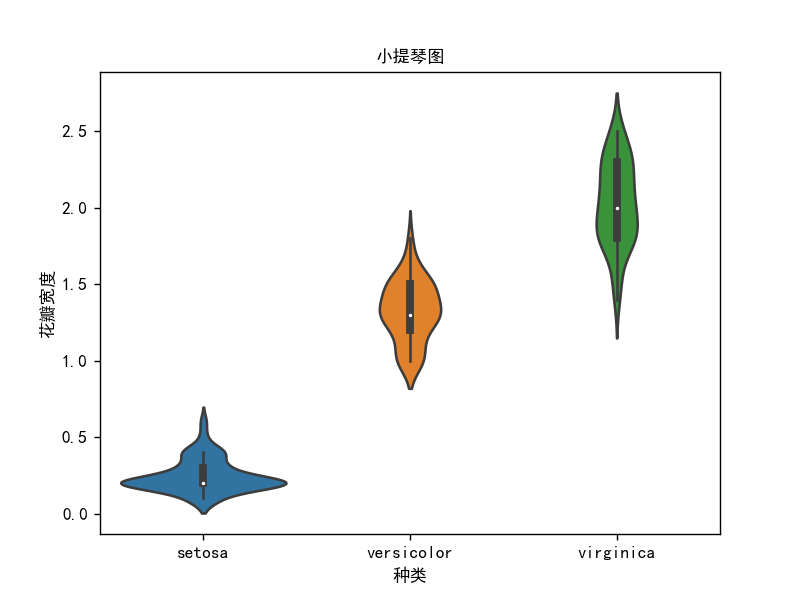
小提琴图
小提琴图-
# 小提琴图1
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import os
os.chdir(os.path.dirname(__file__))
iris = pd.read_csv("鸢尾花.csv")
df = iris
plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加中文字体
sns.violinplot(x=df["Species"], y=df["Petal.Width"])
plt.xlabel("种类")
plt.ylabel("花瓣宽度")
plt.title("小提琴图", fontsize=10)
plt.show()
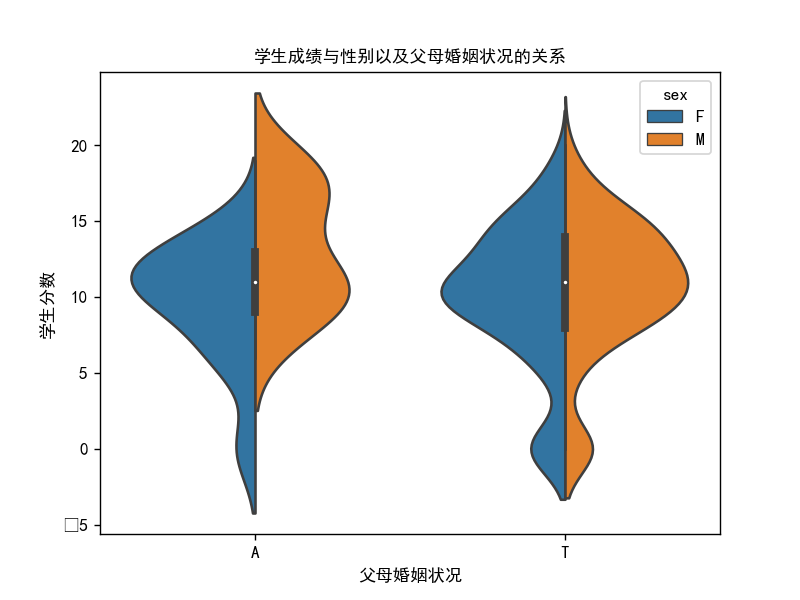
小提琴图-学生成绩与性别以及父母婚姻状况的关系
# 小提琴图2
import seaborn as sns
import matplotlib.pyplot as plt
import pandas as pd
import warnings
import os
os.chdir(os.path.dirname(__file__))
warnings.filterwarnings("ignore")
score = pd.read_csv("student/student-mat.csv", sep=";")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加中文字体
df = score
sns.violinplot(y=df["G3"], x=df["Pstatus"], hue=(df["sex"]), split=True)
plt.xlabel("父母婚姻状况")
plt.ylabel("学生分数")
plt.title("学生成绩与性别以及父母婚姻状况的关系", fontsize=10)
plt.show()
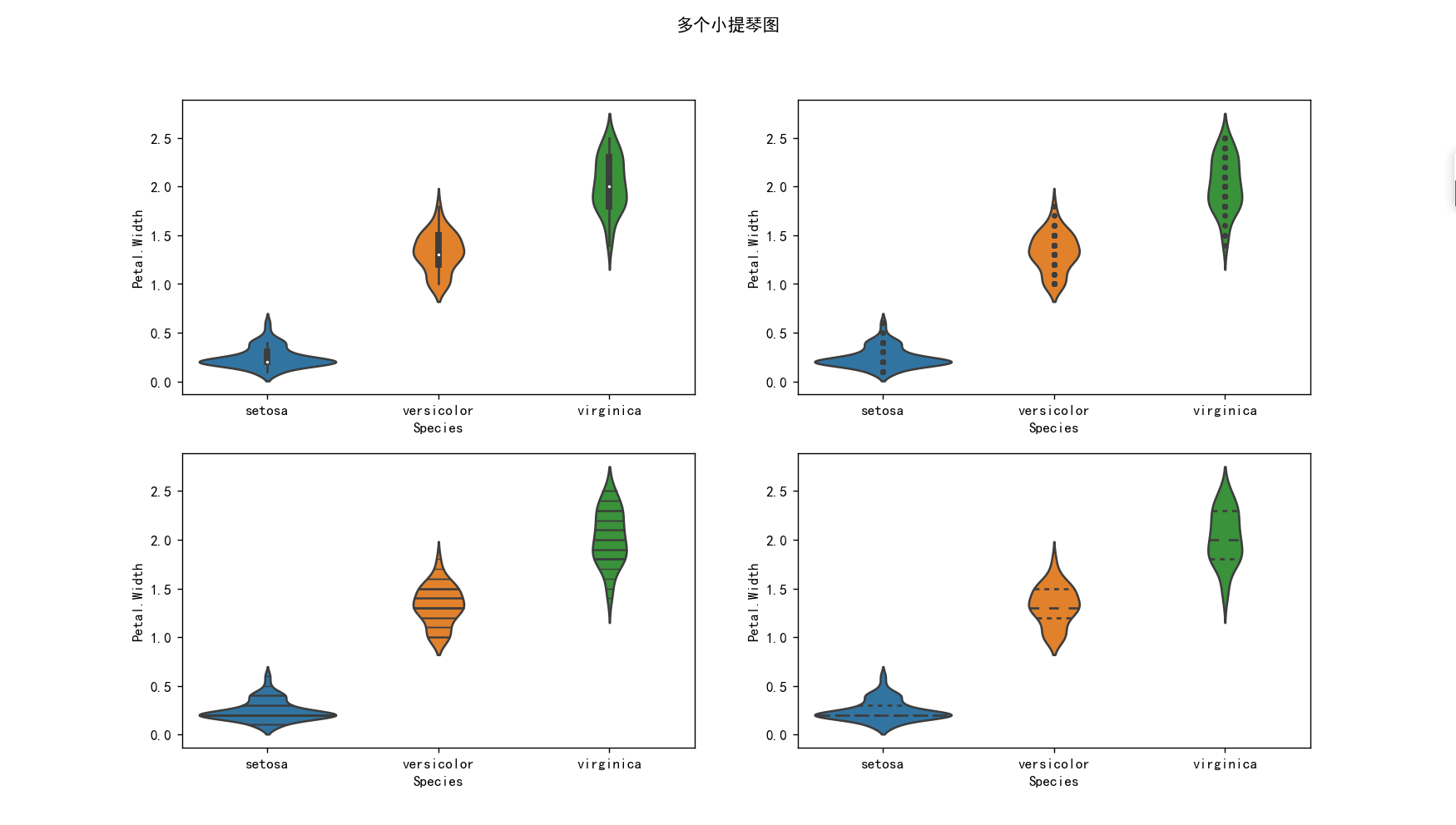
小提琴图-多个小提提琴图
# 小提琴图3
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import os
os.chdir(os.path.dirname(__file__))
iris = pd.read_csv("鸢尾花.csv")
df = iris
plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加中文字体
fig = plt.figure(figsize=(14, 14))
fig.suptitle("多个小提琴图")
plt.subplot(2, 2, 1)
sns.violinplot(x=df["Species"], y=df["Petal.Width"], inner="box")
plt.subplot(2, 2, 2)
sns.violinplot(x=df["Species"], y=df["Petal.Width"], inner="point")
plt.subplot(2, 2, 3)
sns.violinplot(x=df["Species"], y=df["Petal.Width"], inner="stick")
plt.subplot(2, 2, 4)
sns.violinplot(x=df["Species"], y=df["Petal.Width"], inner="quartile")
plt.show()
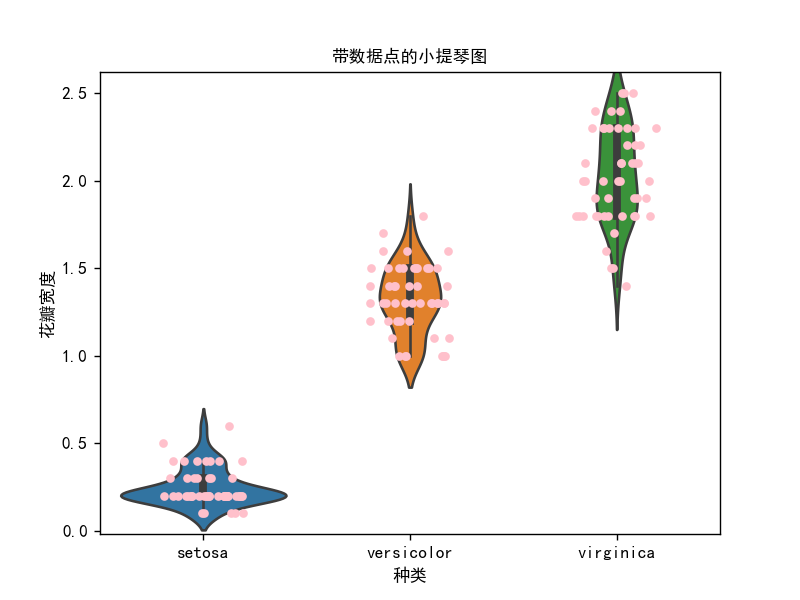
小提琴图-带数据点的小提琴图
# 小提琴图4
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import os
os.chdir(os.path.dirname(__file__))
iris = pd.read_csv("鸢尾花.csv")
df = iris
plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加中文字体
sns.violinplot(x=df["Species"], y=df["Petal.Width"])
sns.stripplot(x="Species", y="Petal.Width", data=df, jitter=0.2, color="pink")
plt.xlabel("种类")
plt.ylabel("花瓣宽度")
plt.title("带数据点的小提琴图", fontsize=10)
plt.show()
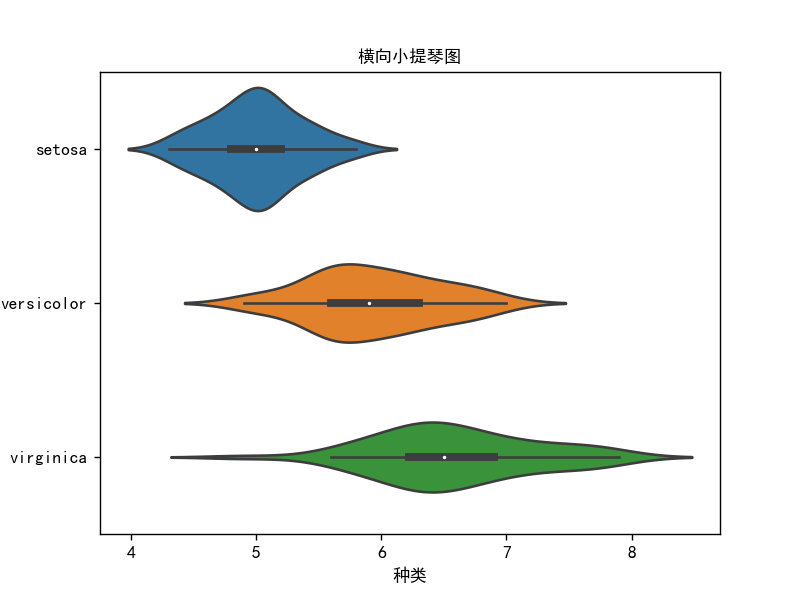
小提琴图-横向小提琴图
# 小提琴图5
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
import os
os.chdir(os.path.dirname(__file__))
iris = pd.read_csv("鸢尾花.csv")
df = iris
sns.violinplot(y=df["Species"], x=df["Sepal.Length"], )
plt.xlabel("种类")
plt.ylabel("花瓣宽度")
plt.title("横向小提琴图", fontsize=10)
plt.show()
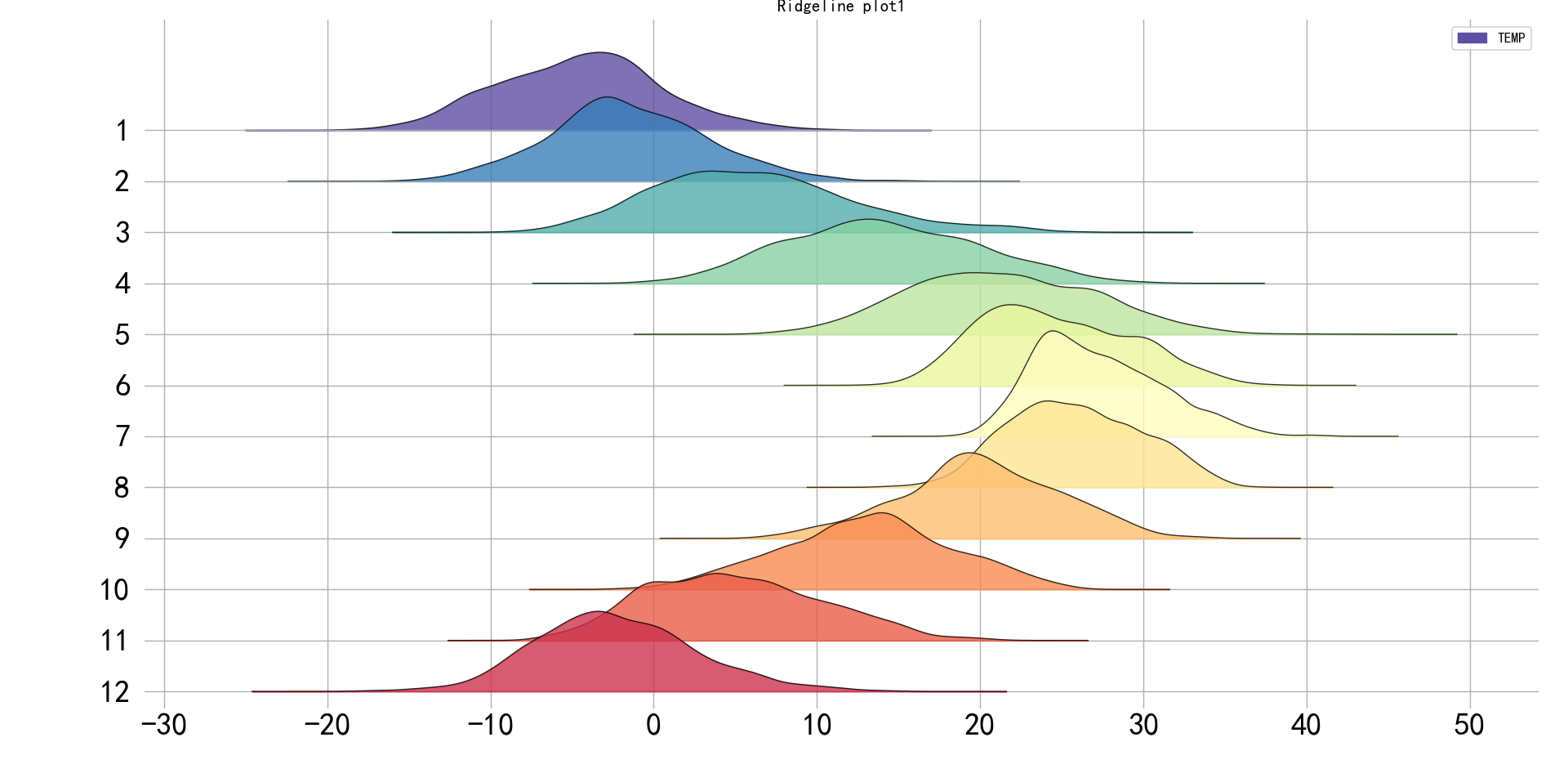
嵴线图
嵴线图-
# 脊线图1
import pandas as pd
import matplotlib.pyplot as plt
from matplotlib import cm # 色谱
import joypy
import os
os.chdir(os.path.dirname(__file__))
tm1 = pd.read_csv("北京pm2.5数据.csv", sep=",")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加中文字体
plt.rcParams['axes.unicode_minus'] = False
tm2 = tm1.iloc[:, [2, 7]]
tm2 = tm2.dropna()
fig, axs = joypy.joyplot(tm2, by="month", fill=True, legend=True, alpha=.8,
range_style='own', xlabelsize=22, ylabelsize=22,
grid='both', linewidth=.8, linecolor='k', figsize=(8, 6), colormap=(cm.Spectral_r))
plt.title("Ridgeline plot1")
plt.show()
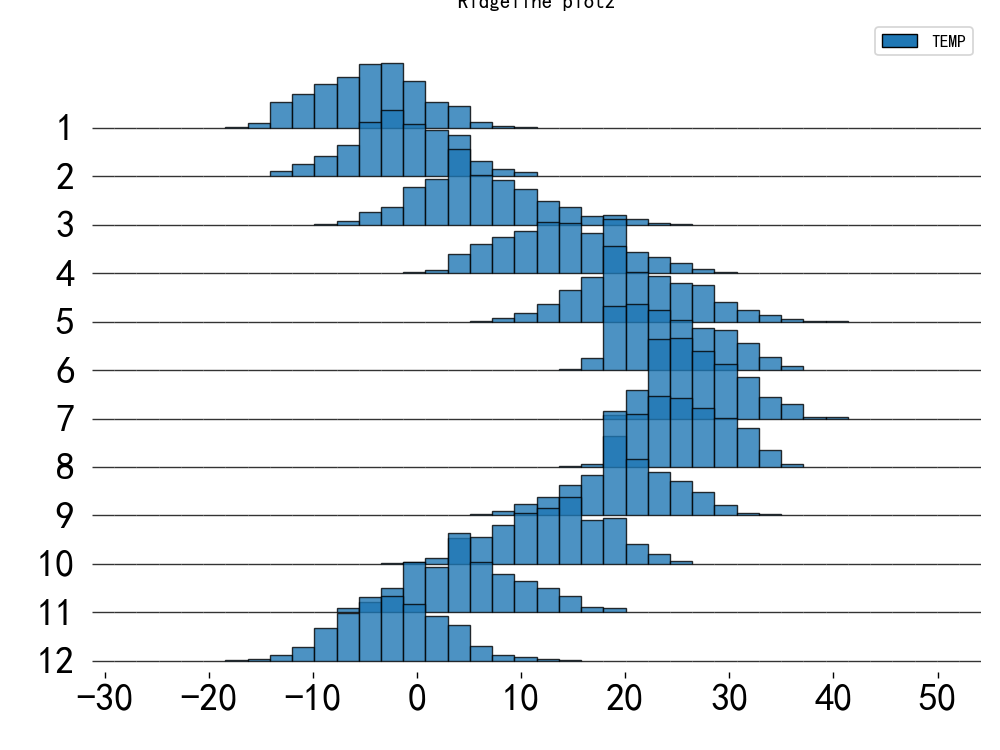
嵴线图-
# 脊线图2
import pandas as pd
import matplotlib.pyplot as plt
import joypy
import os
os.chdir(os.path.dirname(__file__))
tm1 = pd.read_csv("北京pm2.5数据.csv", sep=",")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加中文字体
plt.rcParams['axes.unicode_minus'] = False
tm2 = tm1.iloc[:, [2, 7]]
tm2 = tm2.dropna()
fig, axs = joypy.joyplot(tm2, by="month", fill=True, legend=True, alpha=.8, hist=True, bins=40,
range_style='own', xlabelsize=22, ylabelsize=22,
linewidth=.8, linecolor='k', figsize=(8, 6))
plt.title("Ridgeline plot2")
plt.show()
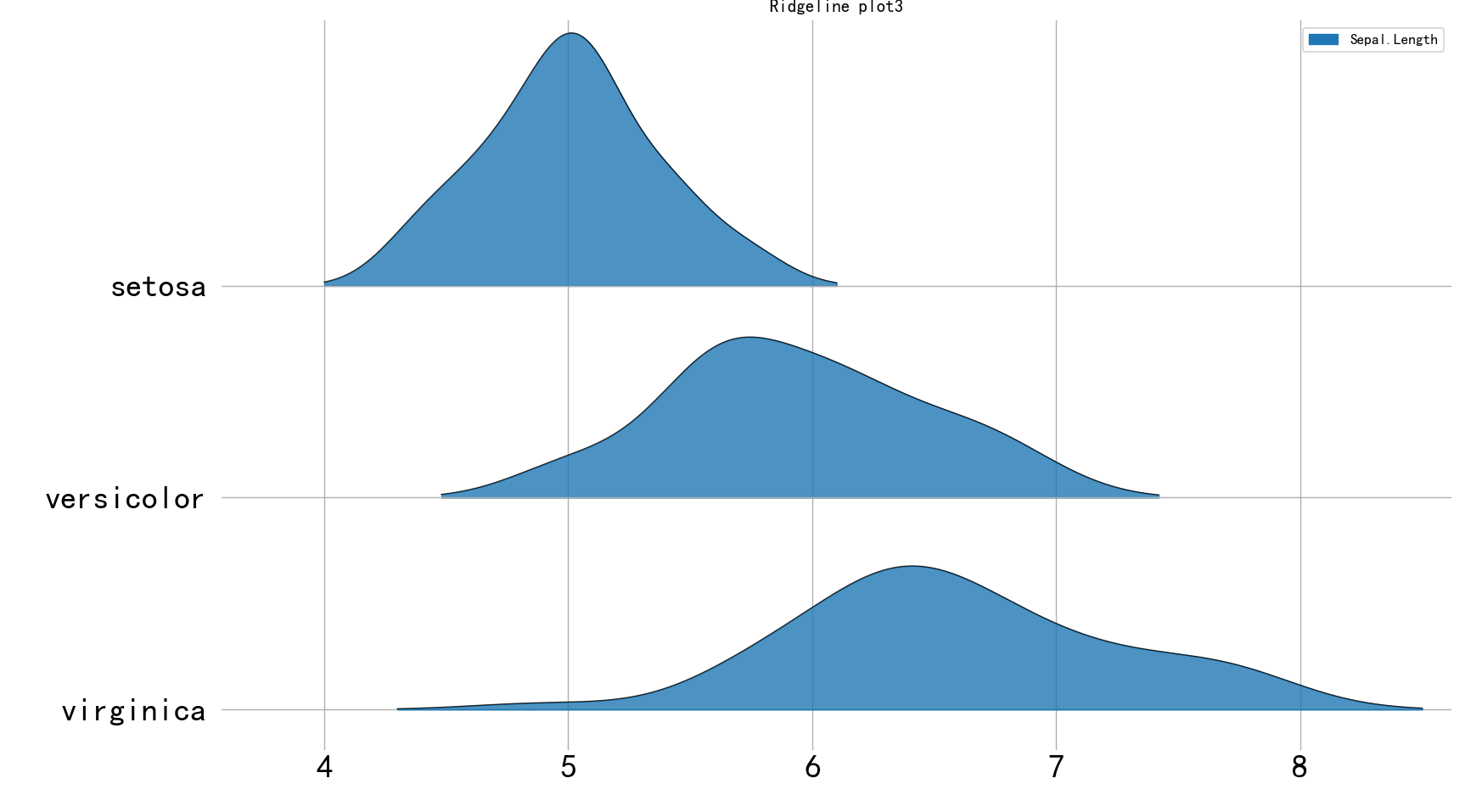
嵴线图-
# 脊线图3
import pandas as pd
import matplotlib.pyplot as plt
import joypy
import os
os.chdir(os.path.dirname(__file__))
tm1 = pd.read_csv("鸢尾花.csv", sep=",")
plt.rcParams['font.sans-serif'] = ['SimHei'] # 添加中文字体
plt.rcParams['axes.unicode_minus'] = False
tm2 = tm1.dropna()
fig, axs = joypy.joyplot(tm2, by="Species", column="Sepal.Length", fill=True, legend=True, alpha=.8,
range_style='own', xlabelsize=22, ylabelsize=22,
grid='both', linewidth=.8, linecolor='k', figsize=(8, 6))
plt.title("Ridgeline plot3")
plt.show()
数据可视化第二版-03部分-09章-时间趋势
总结
本系列博客为基于《数据可视化第二版》一书的教学资源博客。本文主要是第9章,时间趋势可视化的案例相关。
可视化视角-时间趋势

代码实现
安装依赖
pip install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install seaborn -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install tushare==1.2.89 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install mplfinance==0.12.9b7 -i https://pypi.tuna.tsinghua.edu.cn/simple
折线图
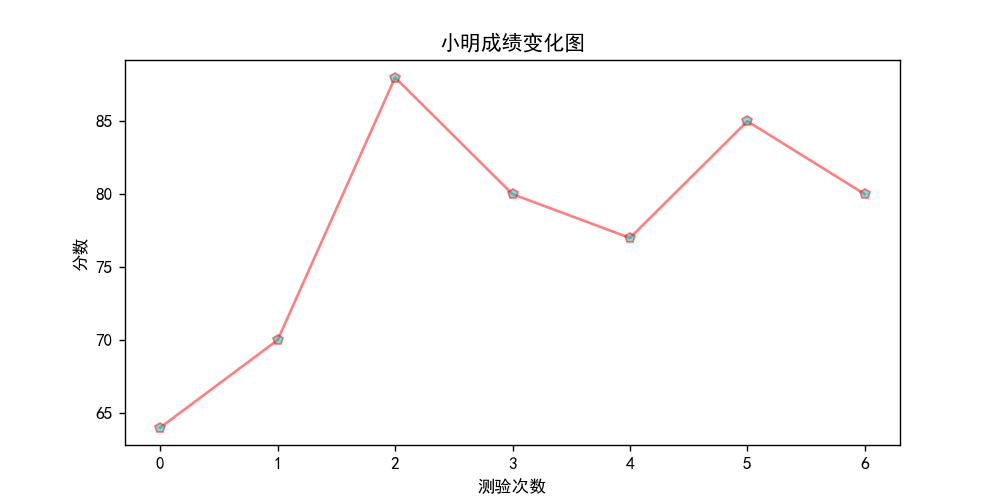
折线图1
# 折线图实现1
import matplotlib.pyplot as plt
# 解决中文乱码问题
plt.rcParams['font.sans-serif'] = ['SimHei']
# X轴,Y轴数据
x = [0, 1, 2, 3, 4, 5, 6]
y = [64, 70, 88, 80, 77, 85, 80]
plt.figure(figsize=(8, 4)) # 创建绘图对象
# 在当前绘图对象绘图,设置曲线参数(X轴,Y轴,红色实线,线宽度)
plt.plot(x, y, color="r", marker="p", linestyle="-", alpha=0.5, mfc="c")
plt.xlabel("测验次数") # X轴标签
plt.ylabel("分数") # Y轴标签
plt.title("小明成绩变化图") # 图标题
plt.show() # 显示图
输出为:
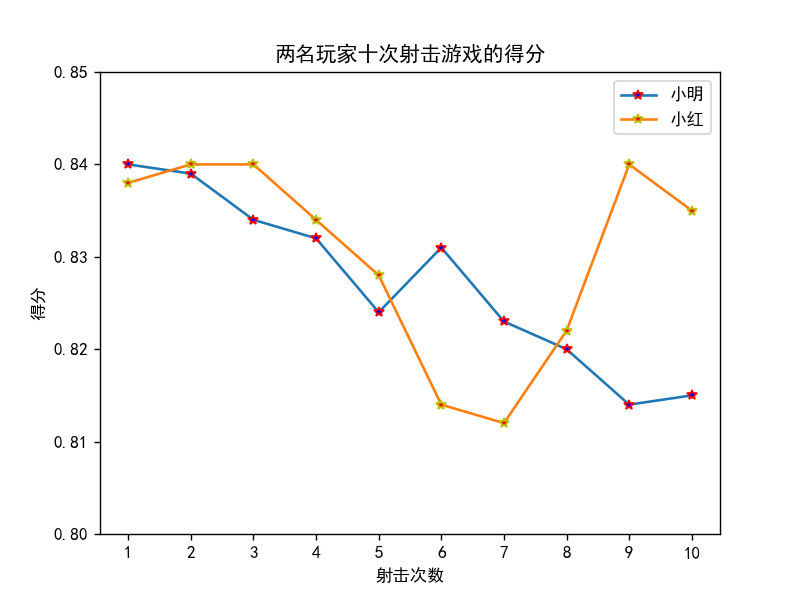
折线图案例2
# 折线图实现二
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文乱码问题
x = range(1, 11)
y1 = [0.840, 0.839, 0.834, 0.832, 0.824, 0.831, 0.823, 0.820, 0.814, 0.815]
y2 = [0.838, 0.840, 0.840, 0.834, 0.828, 0.814, 0.812, 0.822, 0.840, 0.835]
plt.plot(x, y1, marker='*', mec='r', mfc='b', label='小明')
plt.plot(x, y2, marker='*', mec='y', mfc='r', label='小红')
plt.legend() # 让图例生效
plt.xticks(x, rotation=1)
plt.xlabel('射击次数') # X轴标签
plt.ylabel("得分") # Y轴标签
plt.ylim(0.8, 0.85)
plt.title("两名玩家十次射击游戏的得分") # 标题
plt.show()
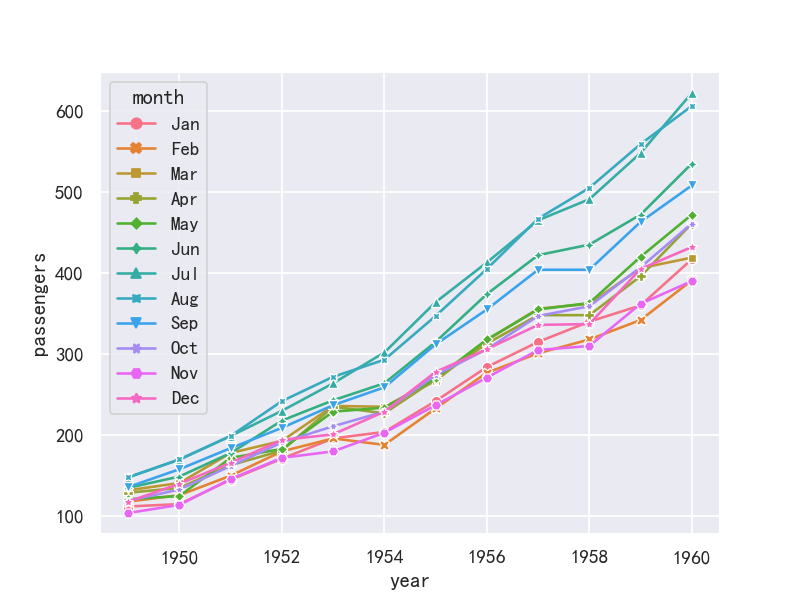
折线图示例3-seaborn
参考:https://blog.csdn.net/m0_38139250/article/details/129729191
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import matplotlib as mpl
import seaborn as sns
sns.set_theme(style="darkgrid")
mpl.rcParams['font.sans-serif']=['SimHei']
mpl.rcParams['axes.unicode_minus']=False
flights = sns.load_dataset("flights",cache=True,data_home=r'.\seaborn-data')
flights.head()
#使用标记而不是破折号来识别组
ax = sns.lineplot(x="year", y="passengers",hue="month", style="month",
markers=True, dashes=False, data=flights)
plt.show()
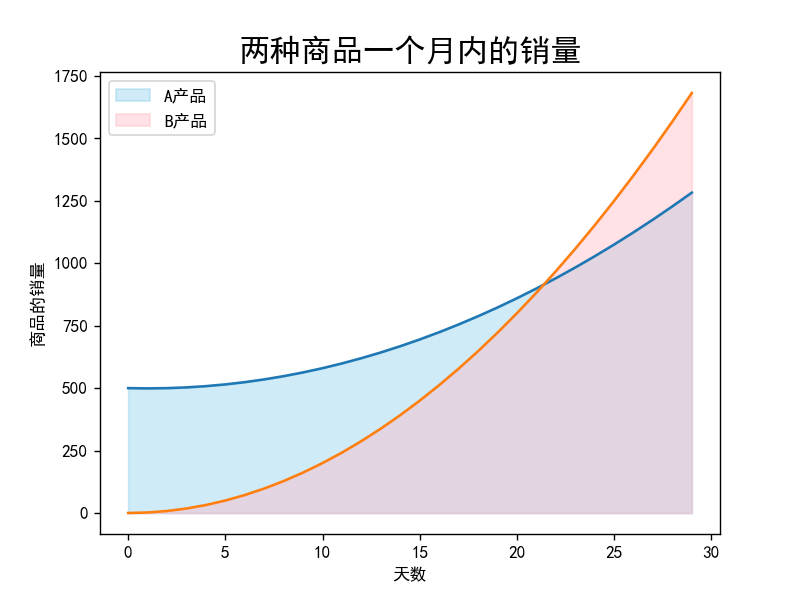
面积图
面积图1-堆叠面积图
# 堆叠面积图
from matplotlib import pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文乱码问题
x = [i for i in range(30)]
y1 = [x ** 2 - 2 * x + 500 for x in range(30)]
y2 = [2 * x ** 2 for x in range(30)]
plt.plot(x, y1)
plt.plot(x, y2)
plt.fill_between(x, y1, color='skyblue', alpha=0.4, label='A产品')
plt.fill_between(x, y2, color='lightpink', alpha=0.4, label='B产品')
plt.xlabel('天数')
plt.ylabel('商品的销量')
plt.title('两种商品一个月内的销量', fontsize=18)
plt.legend() # 让图例生效
plt.show()
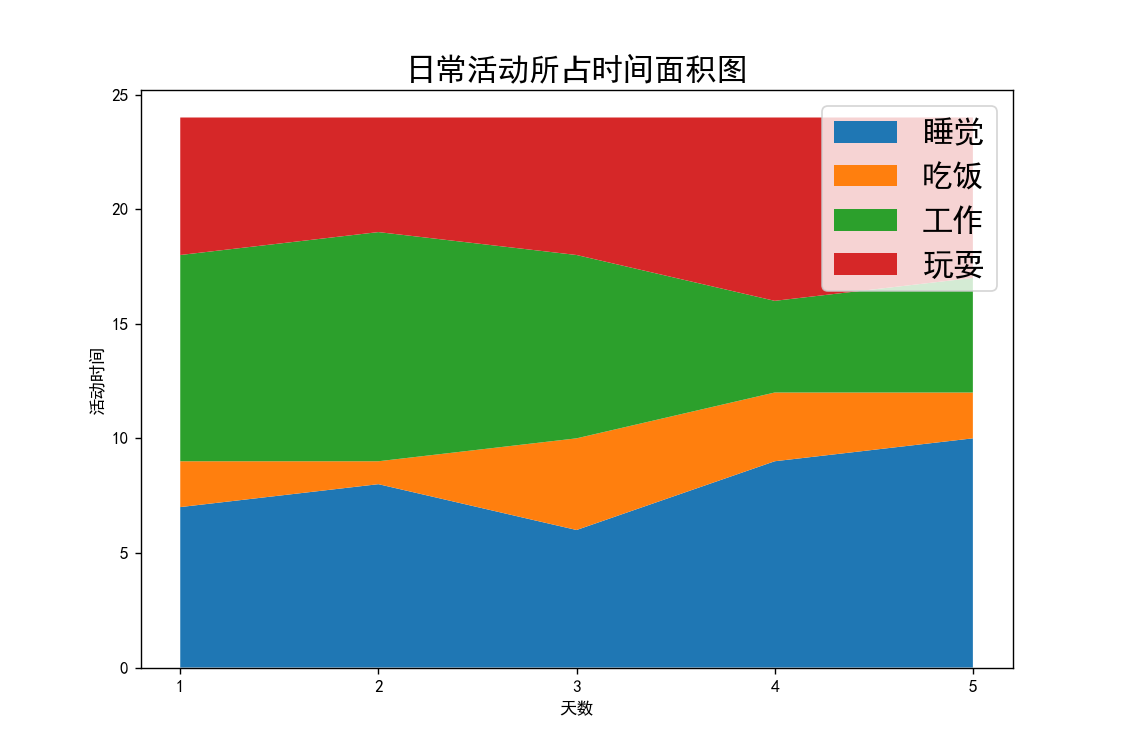
面积图2-堆积面积图
# 堆叠面积图
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文乱码问题
days = [1, 2, 3, 4, 5]
sleeping = [7, 8, 6, 9, 10]
eating = [2, 1, 4, 3, 2]
working = [9, 10, 8, 4, 5]
playing = [6, 5, 6, 8, 7]
plt.figure(figsize=(9, 6))
plt.stackplot(days, sleeping, eating, working, playing)
plt.xlabel('天数')
plt.ylabel('活动时间')
plt.xticks([1, 2, 3, 4, 5])
plt.title('日常活动所占时间面积图', fontsize=18)
plt.legend(['睡觉', '吃饭', '工作', '玩耍'], fontsize=18)
plt.show()
河流图
参考:
Themeriver - Theme_river
ThemeRiver:主题河流图
河流图1
# 社团招新河流图
import pyecharts.options as opts
from pyecharts.charts import ThemeRiver
x_data = ["书画协会", "嘻哈社", "厨艺社"]
y_data = [
["2018/09/01", 10, "书画协会"],
["2019/09/01", 1, "书画协会"],
["2020/09/01", 3, "书画协会"],
["2018/09/01", 1, "嘻哈社"],
["2019/09/01", 2, "嘻哈社"],
["2020/09/01", 3, "嘻哈社"],
["2018/09/01", 4, "厨艺社"],
["2019/09/01", 5, "厨艺社"],
["2020/09/01", 6, "厨艺社"],
]
(
ThemeRiver(init_opts=opts.InitOpts(width="1000px", height="500px"))
.add(
series_name=x_data,
data=y_data,
singleaxis_opts=opts.SingleAxisOpts(
pos_top="50", pos_bottom="50", type_="time"
),
)
.set_global_opts(
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="line")
)
.render("社团招新人数河流图.html")
)

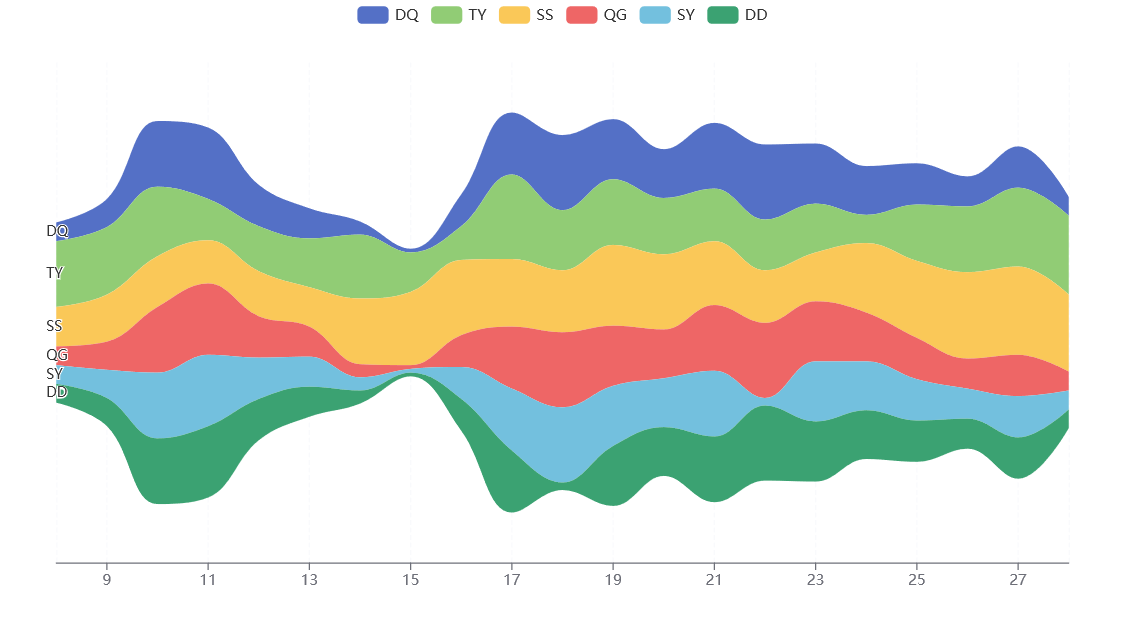
河流图2
import pyecharts.options as opts
from pyecharts.charts import ThemeRiver
"""
Gallery 使用 pyecharts 1.1.0
参考地址: https://echarts.apache.org/examples/editor.html?c=themeRiver-basic
目前无法实现的功能:
1、暂时无法设置阴影样式
"""
x_data = ["DQ", "TY", "SS", "QG", "SY", "DD"]
y_data = [
["2015/11/08", 10, "DQ"],
["2015/11/09", 15, "DQ"],
["2015/11/10", 35, "DQ"],
["2015/11/11", 38, "DQ"],
["2015/11/12", 22, "DQ"],
["2015/11/13", 16, "DQ"],
["2015/11/14", 7, "DQ"],
["2015/11/15", 2, "DQ"],
["2015/11/16", 17, "DQ"],
["2015/11/17", 33, "DQ"],
["2015/11/18", 40, "DQ"],
["2015/11/19", 32, "DQ"],
["2015/11/20", 26, "DQ"],
["2015/11/21", 35, "DQ"],
["2015/11/22", 40, "DQ"],
["2015/11/23", 32, "DQ"],
["2015/11/24", 26, "DQ"],
["2015/11/25", 22, "DQ"],
["2015/11/26", 16, "DQ"],
["2015/11/27", 22, "DQ"],
["2015/11/28", 10, "DQ"],
["2015/11/08", 35, "TY"],
["2015/11/09", 36, "TY"],
["2015/11/10", 37, "TY"],
["2015/11/11", 22, "TY"],
["2015/11/12", 24, "TY"],
["2015/11/13", 26, "TY"],
["2015/11/14", 34, "TY"],
["2015/11/15", 21, "TY"],
["2015/11/16", 18, "TY"],
["2015/11/17", 45, "TY"],
["2015/11/18", 32, "TY"],
["2015/11/19", 35, "TY"],
["2015/11/20", 30, "TY"],
["2015/11/21", 28, "TY"],
["2015/11/22", 27, "TY"],
["2015/11/23", 26, "TY"],
["2015/11/24", 15, "TY"],
["2015/11/25", 30, "TY"],
["2015/11/26", 35, "TY"],
["2015/11/27", 42, "TY"],
["2015/11/28", 42, "TY"],
["2015/11/08", 21, "SS"],
["2015/11/09", 25, "SS"],
["2015/11/10", 27, "SS"],
["2015/11/11", 23, "SS"],
["2015/11/12", 24, "SS"],
["2015/11/13", 21, "SS"],
["2015/11/14", 35, "SS"],
["2015/11/15", 39, "SS"],
["2015/11/16", 40, "SS"],
["2015/11/17", 36, "SS"],
["2015/11/18", 33, "SS"],
["2015/11/19", 43, "SS"],
["2015/11/20", 40, "SS"],
["2015/11/21", 34, "SS"],
["2015/11/22", 28, "SS"],
["2015/11/23", 26, "SS"],
["2015/11/24", 37, "SS"],
["2015/11/25", 41, "SS"],
["2015/11/26", 46, "SS"],
["2015/11/27", 47, "SS"],
["2015/11/28", 41, "SS"],
["2015/11/08", 10, "QG"],
["2015/11/09", 15, "QG"],
["2015/11/10", 35, "QG"],
["2015/11/11", 38, "QG"],
["2015/11/12", 22, "QG"],
["2015/11/13", 16, "QG"],
["2015/11/14", 7, "QG"],
["2015/11/15", 2, "QG"],
["2015/11/16", 17, "QG"],
["2015/11/17", 33, "QG"],
["2015/11/18", 40, "QG"],
["2015/11/19", 32, "QG"],
["2015/11/20", 26, "QG"],
["2015/11/21", 35, "QG"],
["2015/11/22", 40, "QG"],
["2015/11/23", 32, "QG"],
["2015/11/24", 26, "QG"],
["2015/11/25", 22, "QG"],
["2015/11/26", 16, "QG"],
["2015/11/27", 22, "QG"],
["2015/11/28", 10, "QG"],
["2015/11/08", 10, "SY"],
["2015/11/09", 15, "SY"],
["2015/11/10", 35, "SY"],
["2015/11/11", 38, "SY"],
["2015/11/12", 22, "SY"],
["2015/11/13", 16, "SY"],
["2015/11/14", 7, "SY"],
["2015/11/15", 2, "SY"],
["2015/11/16", 17, "SY"],
["2015/11/17", 33, "SY"],
["2015/11/18", 40, "SY"],
["2015/11/19", 32, "SY"],
["2015/11/20", 26, "SY"],
["2015/11/21", 35, "SY"],
["2015/11/22", 4, "SY"],
["2015/11/23", 32, "SY"],
["2015/11/24", 26, "SY"],
["2015/11/25", 22, "SY"],
["2015/11/26", 16, "SY"],
["2015/11/27", 22, "SY"],
["2015/11/28", 10, "SY"],
["2015/11/08", 10, "DD"],
["2015/11/09", 15, "DD"],
["2015/11/10", 35, "DD"],
["2015/11/11", 38, "DD"],
["2015/11/12", 22, "DD"],
["2015/11/13", 16, "DD"],
["2015/11/14", 7, "DD"],
["2015/11/15", 2, "DD"],
["2015/11/16", 17, "DD"],
["2015/11/17", 33, "DD"],
["2015/11/18", 4, "DD"],
["2015/11/19", 32, "DD"],
["2015/11/20", 26, "DD"],
["2015/11/21", 35, "DD"],
["2015/11/22", 40, "DD"],
["2015/11/23", 32, "DD"],
["2015/11/24", 26, "DD"],
["2015/11/25", 22, "DD"],
["2015/11/26", 16, "DD"],
["2015/11/27", 22, "DD"],
["2015/11/28", 10, "DD"],
]
(
ThemeRiver()
.add(
series_name=x_data,
data=y_data,
singleaxis_opts=opts.SingleAxisOpts(
pos_top="50", pos_bottom="50", type_="time"
),
)
.set_global_opts(
tooltip_opts=opts.TooltipOpts(trigger="axis", axis_pointer_type="line")
)
.render("theme_river.html")
)
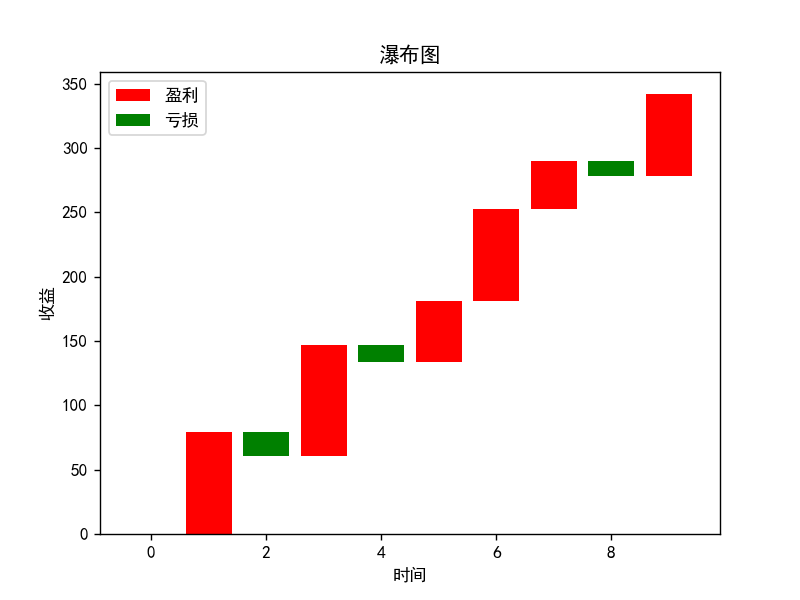
瀑布图
瀑布图-matplotlib
# 收益瀑布图
import numpy as np
import matplotlib.pyplot as plt
import random
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文乱码问题
plt.rcParams['axes.unicode_minus'] = False # 正常显示负号
profit = [random.randint(-50, 100) for i in range(10)]
bottom = 0
bar_width = 0.8
x_tic = np.arange(len(profit), dtype=np.float64)
for i in range(10):
x = x_tic[i]
y = profit[i]
if profit[i] > 0:
label1 = '盈利'
revenue = plt.bar(x, y, bar_width, align='center', bottom=bottom, label=label1, color='red')
else:
label1 = '亏损'
cost = plt.bar(x, y, bar_width, align='center', bottom=bottom, label=label1, color='green')
bottom += y
x += 0.8
plt.legend(handles=[revenue, cost])
plt.title("瀑布图")
plt.xlabel('时间')
plt.ylabel('收益')
plt.show()
瀑布图-pyecharts
参考:使用 Pyecharts 制作 Bar(柱状图/条形图/瀑布图)
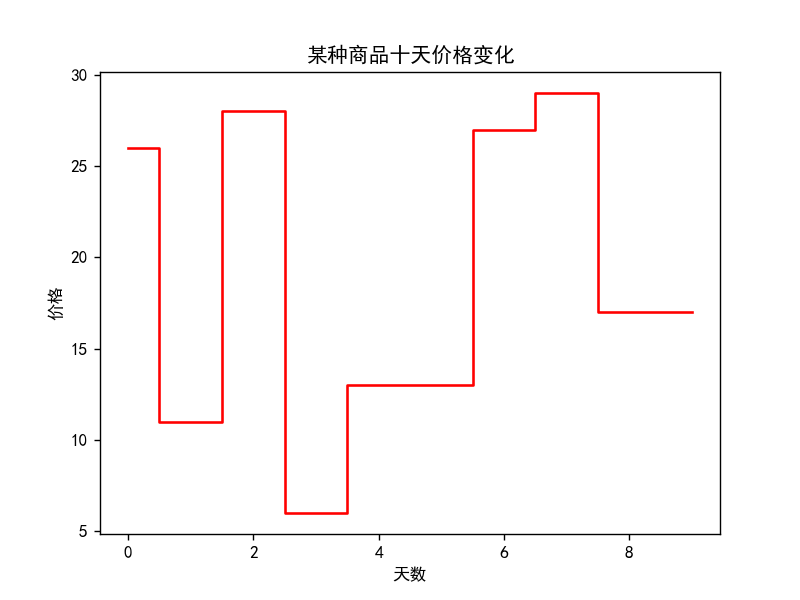
步进图
步进图1-
# 步近图
import matplotlib.pyplot as plt
import random
plt.rcParams['font.sans-serif'] = ['SimHei'] # 解决中文乱码问题
y = [random.randint(0, 30) for i in range(10)]
x = [i for i in range(10)]
plt.plot(x, y, drawstyle='steps-mid', c='red')
plt.xlabel('天数')
plt.ylabel('价格')
plt.title('某种商品十天价格变化')
plt.show()
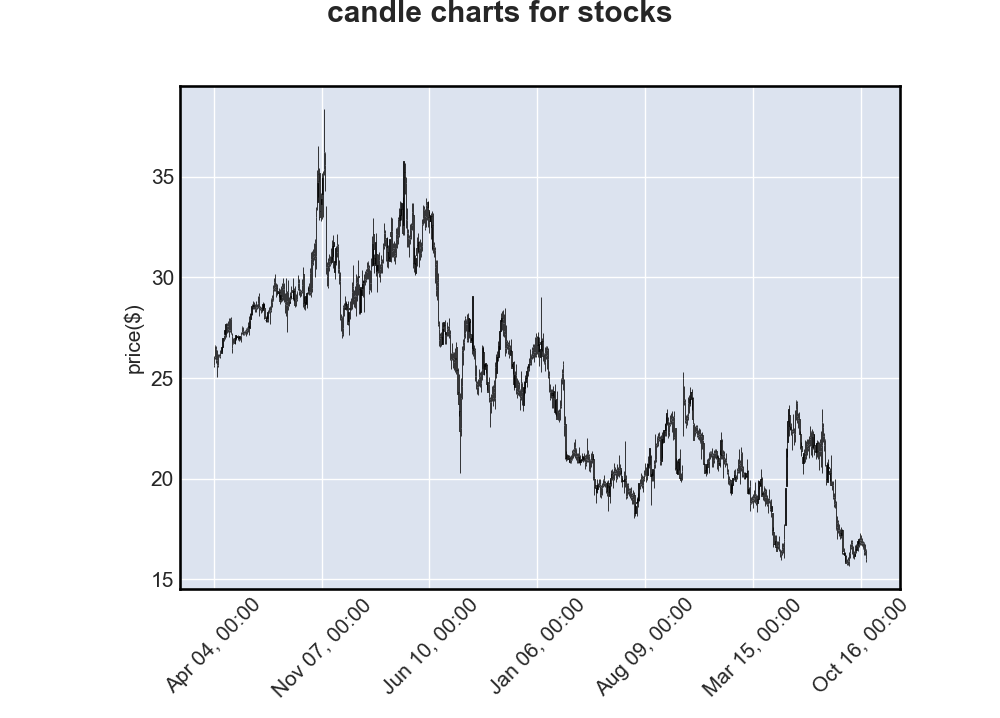
烛形图-
# 烛形图
import tushare as ts
import mplfinance as mpf
import pandas as pd
# 获得数据
quotes = ts.get_hist_data('603970', '2020')
print(quotes.head())
# 将索引转化为需要的格式
quotes.index = pd.to_datetime(quotes.index)
mpf.plot(quotes, type="candle", title="candle charts for stocks", ylabel="price($)")
数据可视化第二版-03部分-10章-地理特征
总结
本系列博客为基于《数据可视化第二版》一书的教学资源博客。本文主要是第10章,地理特征可视化的案例相关。
可视化视角-地理特征

代码实现
安装依赖
pip install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install seaborn -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install tushare==1.2.89 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install mplfinance==0.12.9b7 -i https://pypi.tuna.tsinghua.edu.cn/simple
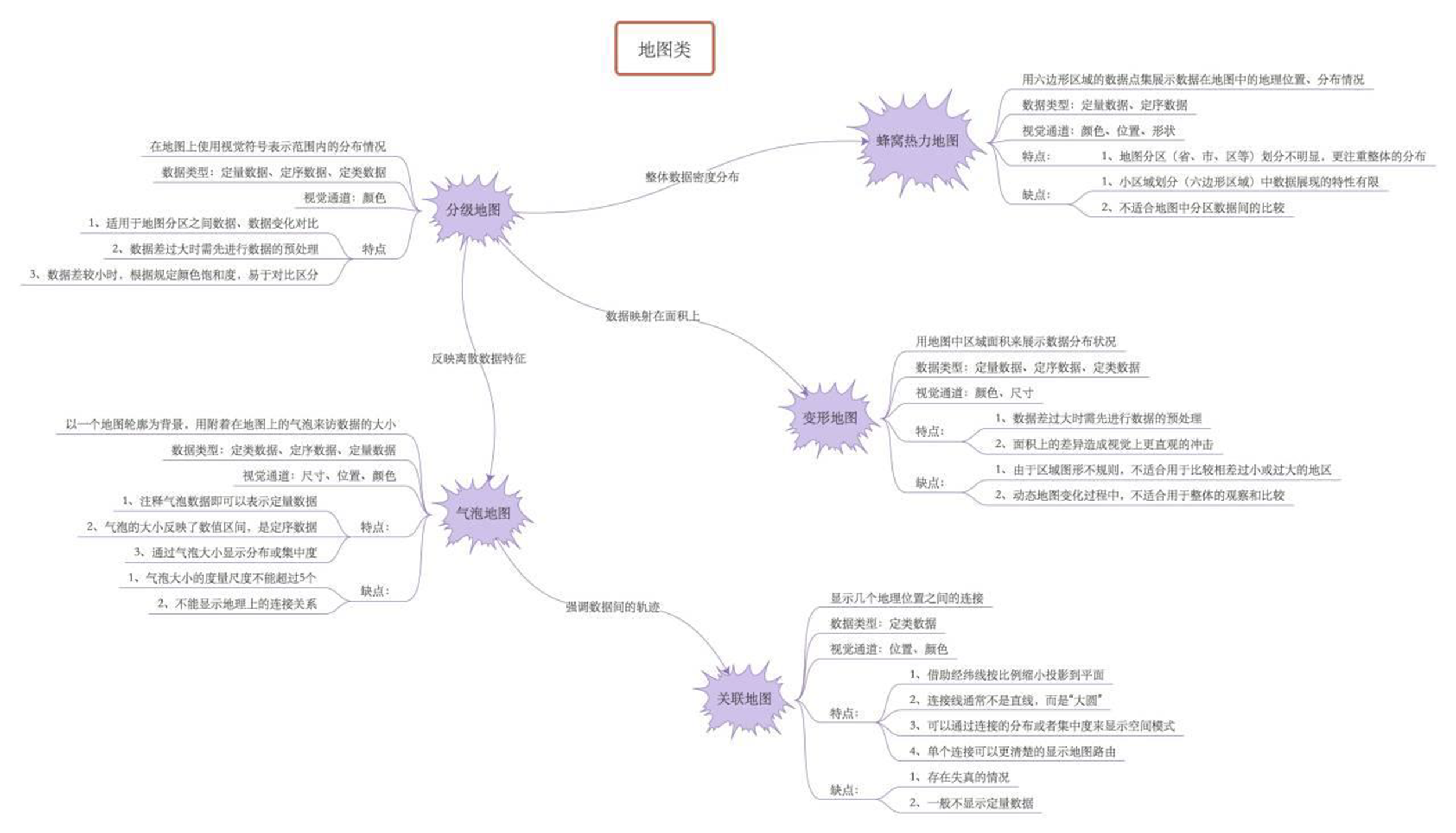
分级地图
地图1
from pyecharts import options as opts
from pyecharts.charts import Map
import os
# 创建基础数据
value = [95.1, 23.2, 43.3, 66.4, 88.5]
attr = ["China", "Canada", "Brazil", "Russia", "United States"]
data = []
for index in range(len(attr)):
city_ionfo = [attr[index], value[index]] # 逐个将国家名和数据搭配
data.append(city_ionfo) # 将数据导为一个字典
c = (
Map()
.add("世界地图", data, "world")
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts=opts.TitleOpts(title="世界地图示例"), # 设置标题
visualmap_opts=opts.VisualMapOpts(max_=200), # 设置图形大小
)
.render('density.html')
)
# 打开html
os.system("density.html")
输出为:
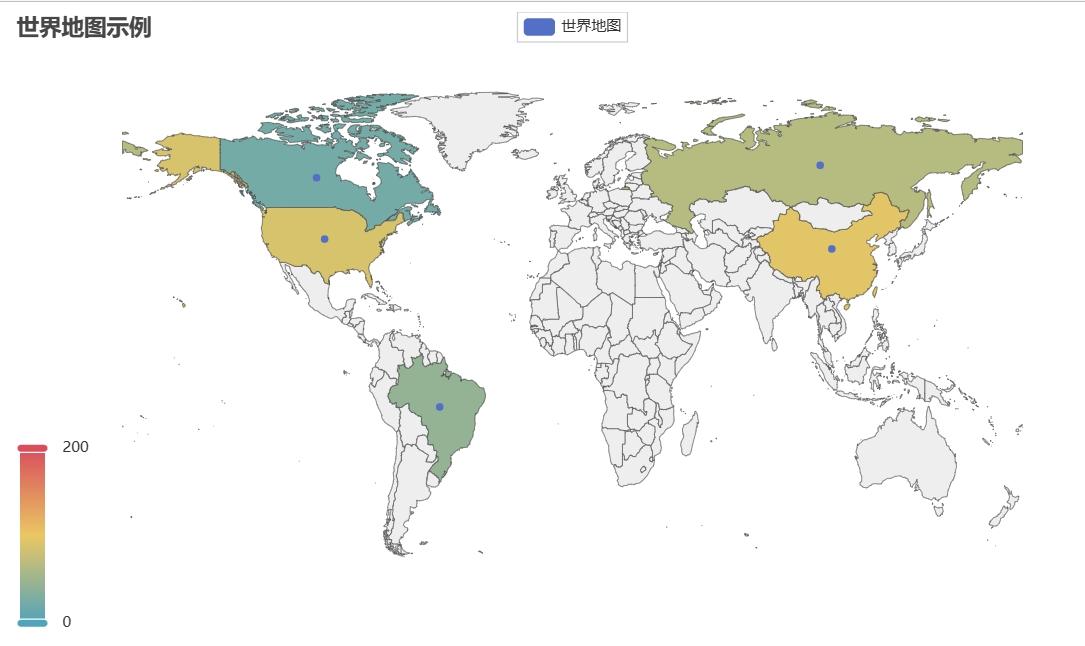
蜂窝图
蜂窝图1-
import matplotlib.pyplot as plt
import numpy as np
# create data
x = np.random.normal(size=50000)
y = (x * 3 + np.random.normal(size=50000)) * 5
fig,axes = plt.subplots(1,2)
# Control the color
axes[0].hexbin(x, y, gridsize=(25, 25), cmap=plt.cm.Greens)
# plt.show()
# Other color
axes[1].hexbin(x, y, gridsize=(25, 25), cmap=plt.cm.BuGn_r)
plt.show()
变形地图
参考:
如何优雅地选择一种地图变形方式
1 Cartogram简介
2 ArcGIS Cartogram Toolbox
3 QGIS Cartogram插件
4 Cartogram in R
5 GeoDa和geofacet
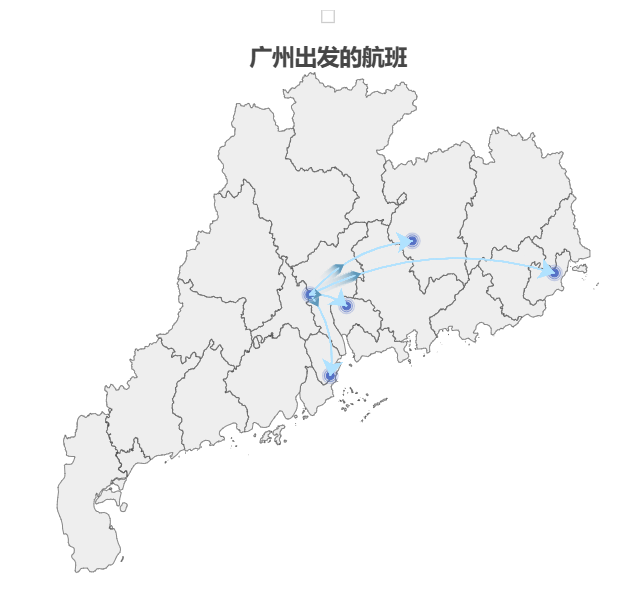
关联地图
关联地图1
from pyecharts import options as opts
from pyecharts.charts import Geo # 地理坐标系绘制方法
from pyecharts.globals import GeoType, ThemeType, SymbolType # Geo图的类型 主题 图形符号
import os
data = [("广州", "8302"), ("河源", "10006"), ("东莞", "9559"), ("汕头", "6860"), ("珠海", "11169")]
geo = (
Geo(init_opts=opts.InitOpts(width="600px", height="500px", theme=ThemeType.WHITE)) # 设置画板
.add_schema(maptype="广东", # 生成广东省的地图
emphasis_itemstyle_opts=opts.ItemStyleOpts(color="#31708f"), # 高亮颜色
)
.add("", # 读入数据,生成几个城市的点
data,
type_=GeoType.EFFECT_SCATTER,
symbol_size=6
)
.add("", # 建立联系
[("广州", "河源"), ("广州", "东莞"), ("广州", "汕头"), ("广东", "珠海")],
type_=GeoType.LINES,
effect_opts=opts.EffectOpts(symbol=SymbolType.ARROW, symbol_size=6, color='#5f99bb'),
linestyle_opts=opts.LineStyleOpts(curve=0.2, color="#B0E2FF"))
.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
.set_global_opts(
title_opts=opts.TitleOpts(title="广州出发的航班", pos_right="center", pos_top="5%"))
.render('linked.html'))
os.system('linked.html')
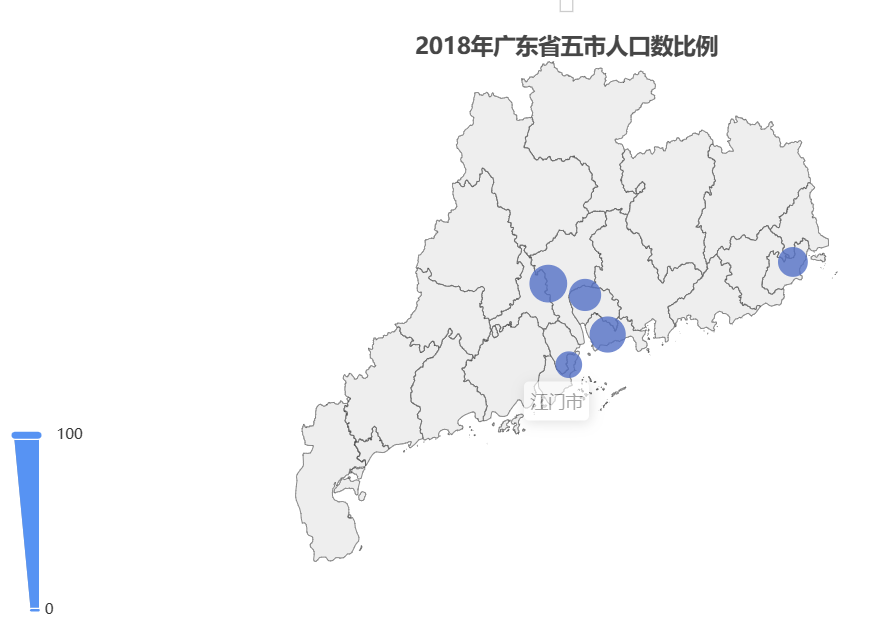
气泡地图
气泡地图1-
import os
from pyecharts import options as opts
from pyecharts.charts import Geo
# 2018末人口数
data = [("广州", 14.9), ("深圳", 13.03), ("东莞", 8.39), ("汕头", 5.64), ("珠海", 1.89)]
rate = [("广州", 33.98), ("深圳", 29.71), ("东莞", 19.13), ("汕头", 12.86), ("珠海", 4.31)]
c = Geo()
c.add_schema(maptype='广东') # 生成广东省地图
c.add('', rate) # 导入数据:rate
c.set_global_opts(visualmap_opts=opts.VisualMapOpts(type_='size'), # 可视化
title_opts=opts.TitleOpts(title="2018年广东省五市人口数比例", pos_right="center",
pos_top="5%")) # 使size由气泡大小呈现出来
c.set_series_opts(label_opts=opts.LabelOpts(is_show=False))
c.render('bubble.html')
os.system('bubble.html')
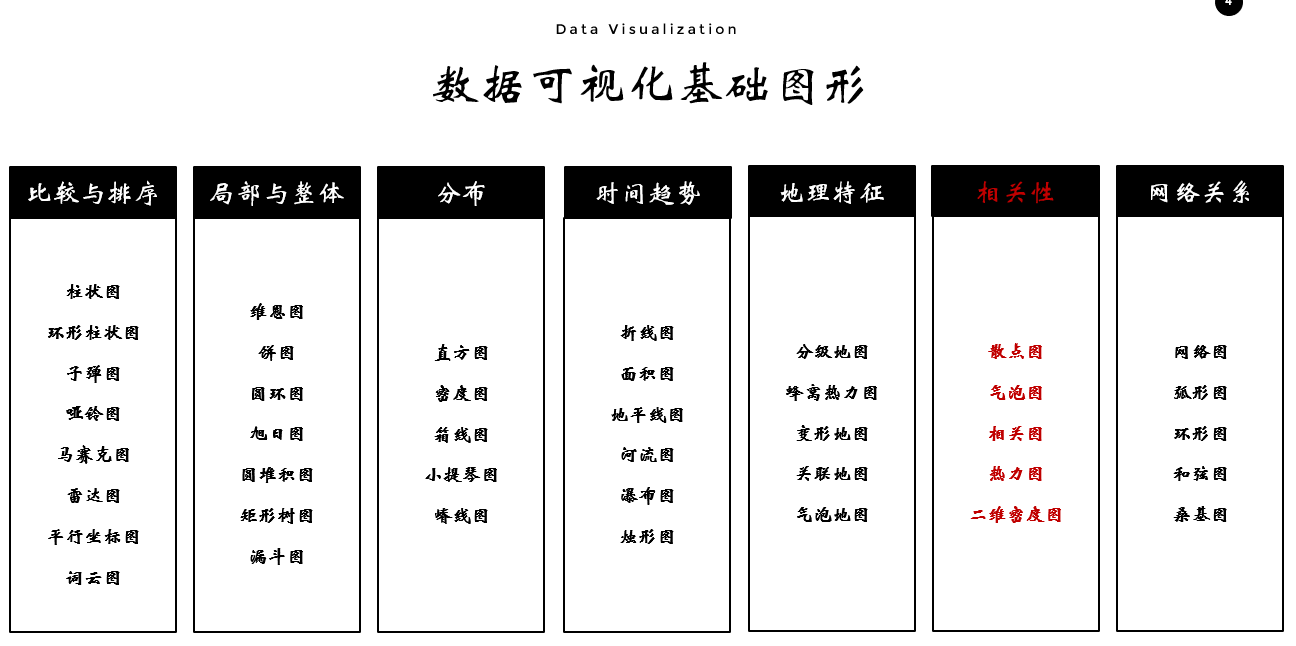
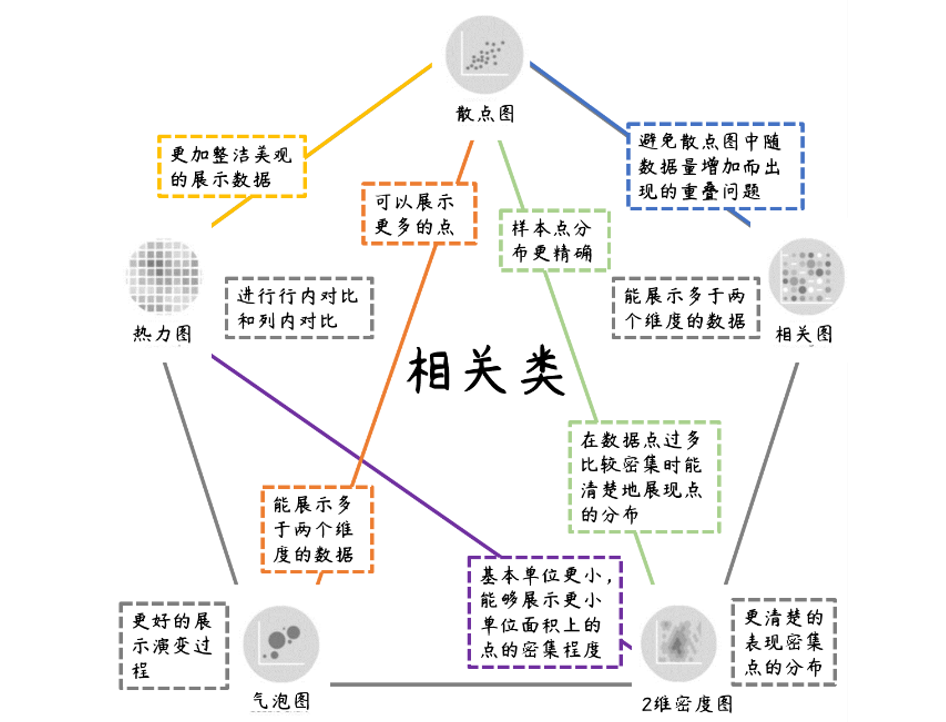
数据可视化第二版-03部分-11章-相关
总结
本系列博客为基于《数据可视化第二版》一书的教学资源博客。本文主要是第11章,相关可视化的案例相关。
可视化视角-相关
代码实现
安装依赖
pip install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install seaborn -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install tushare==1.2.89 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install mplfinance==0.12.9b7 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pyheatmap==0.1.12 -i https://pypi.tuna.tsinghua.edu.cn/simple
散点图
散点图1-基本散点图
import matplotlib.pyplot as plt
import numpy as np
from sklearn import datasets
import seaborn as sns
# 基本散点图
a = np.random.randint(30, size=100)
b = np.random.randint(20, size=100)
asorted = sorted(a)
bsorted = sorted(b)
bsorted2 = sorted(b, reverse=True)
plt.scatter(asorted, bsorted)
plt.scatter(asorted, bsorted2)
plt.show()
输出为:
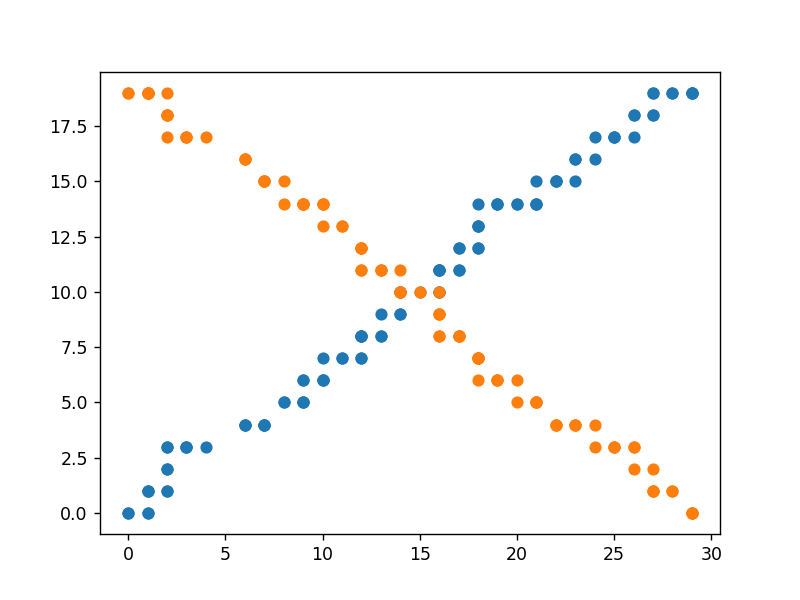
散点图2-散点折线图
# 散点折线图
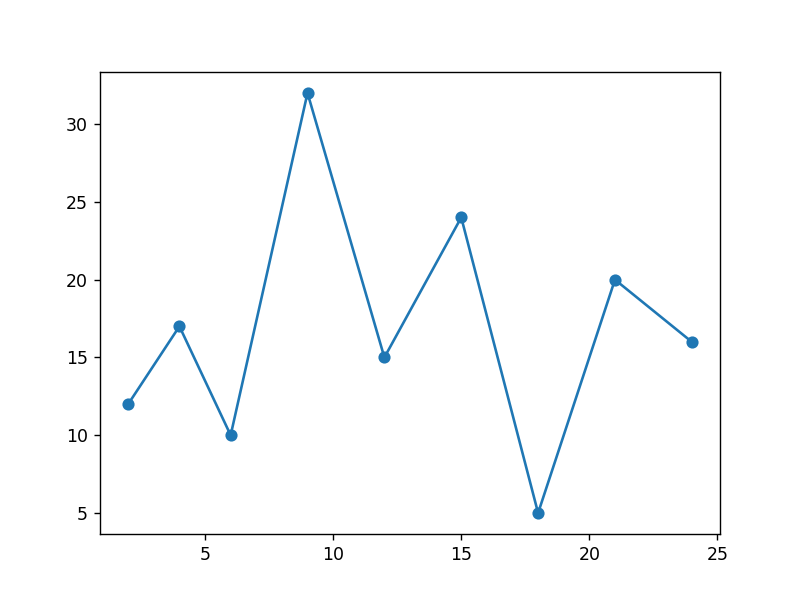
x = [2, 4, 6, 9, 12, 15, 18, 21, 24]
y = [12, 17, 10, 32, 15, 24, 5, 20, 16]
plt.scatter(x, y)
plt.plot(x, y)
plt.show()
输出为:
散点图3-回归散点图
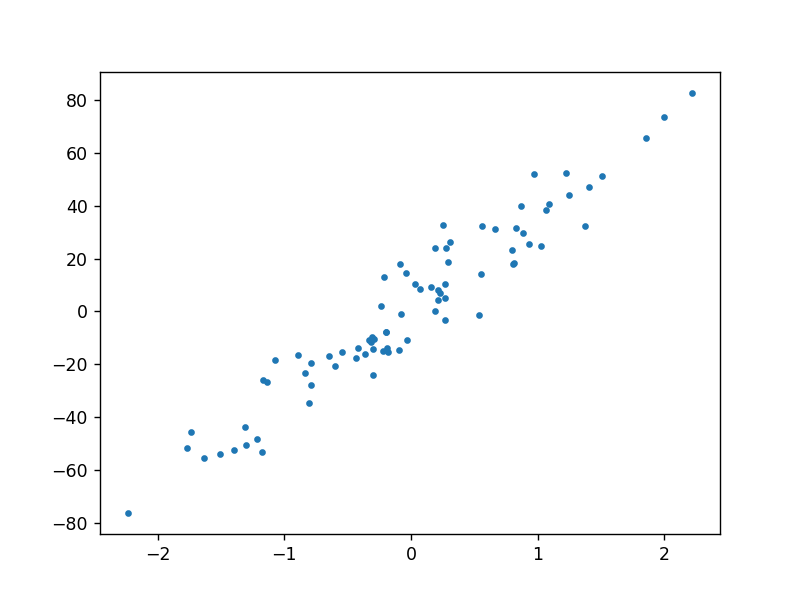
# 回归数据散点图
data = datasets.make_regression(n_samples=80,
n_features=1,
n_targets=1,
noise=10,
random_state=144) # 生成回归数据,添加轻微扰动
x = data[0] # x为50行1列
y = data[1] # y为1行50列
plt.scatter(x[:, 0], y, s=8)
plt.show()
输出为
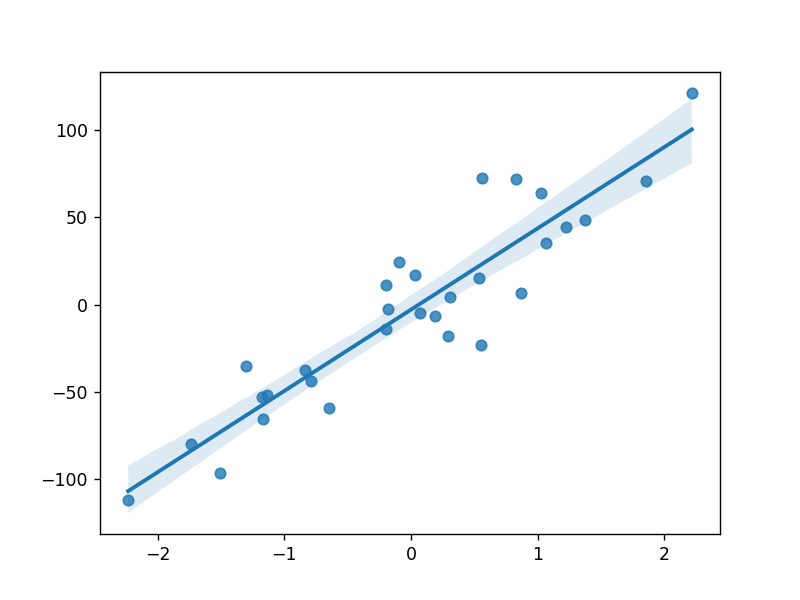
散点图4-回归数据散点图
# 回归
data = datasets.make_regression(n_samples=30,
n_features=1,
n_targets=1,
noise=20,
random_state=144) # 生成回归数据,添加轻微扰动
x = data[0] # x为50行1列
y = data[1] # y为1行50列
sns.regplot(x=x[:, 0], y=y) # 添加回归线
plt.show()
输出为:
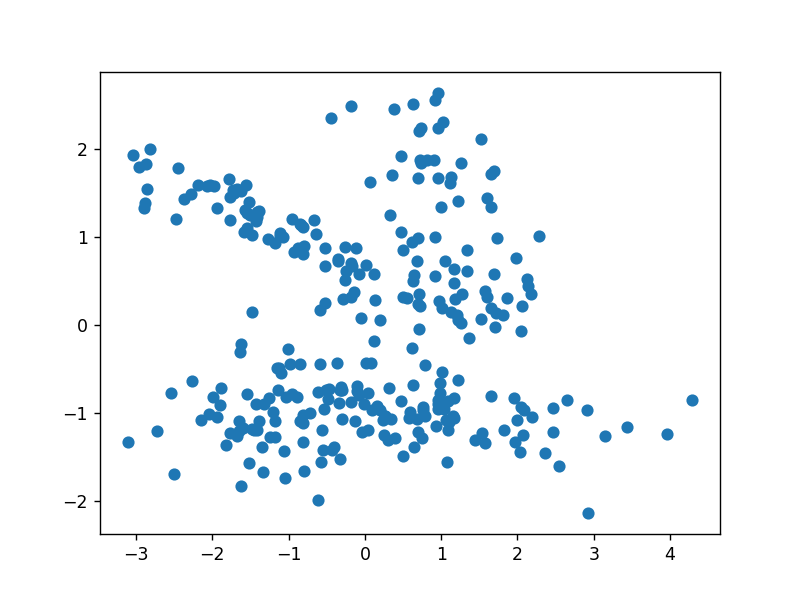
散点图5-分类数据散点图
# 分类数据散点图
X1, y1 = datasets.make_classification(
n_samples=300, random_state=1, n_features=2, n_redundant=0, n_informative=2)
plt.scatter(X1[:, 0], X1[:, 1])
plt.show()
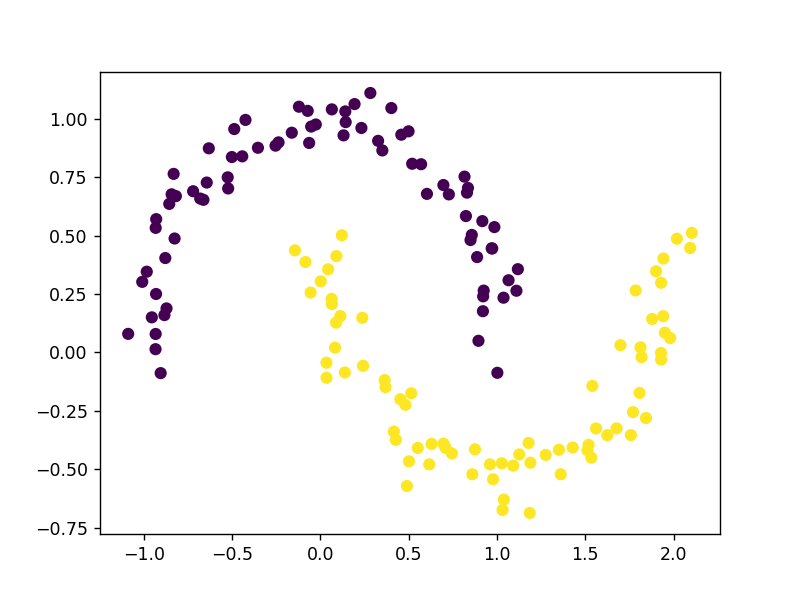
moons = datasets.make_moons(n_samples=150, noise=.09, random_state=10)
x = moons[0]
y = moons[1]
plt.scatter(x[:, 0], x[:, 1], c=y) # 可视化月牙图形
plt.show()
输出为:
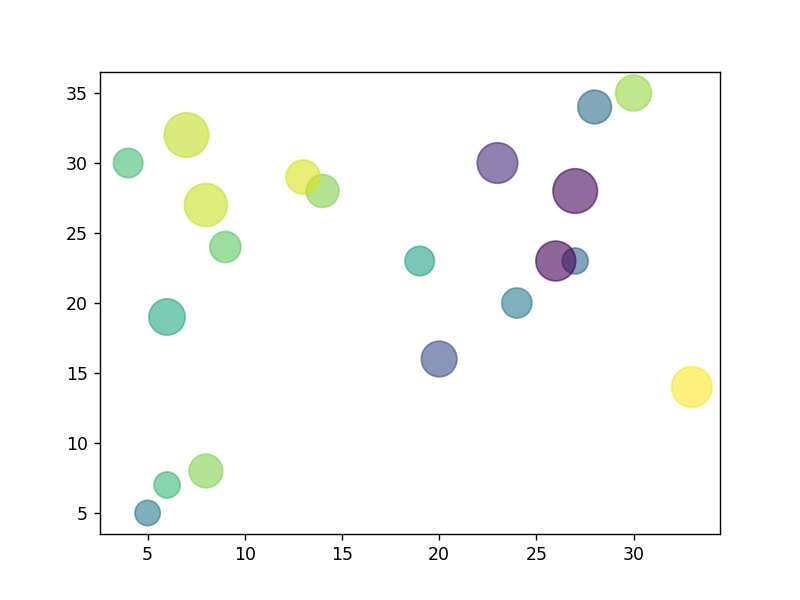
气泡图
气泡图1-
import matplotlib.pyplot as plt
import numpy as np
import seaborn as sns
# 图例1
a = [5, 6, 8, 20, 27, 14, 19, 24, 13, 28, 30, 23, 7, 8, 33, 6, 9, 26, 27, 4]
b = [5, 7, 8, 16, 23, 28, 23, 20, 29, 34, 35, 30, 32, 27, 14, 19, 24, 23, 28, 30]
colors = np.random.rand(len(a)) # 颜色数组
size = [212, 225, 375, 420, 225, 356, 287, 300, 382, 375, 425, 543, 654, 609, 543, 435, 320, 525, 656, 287]
plt.scatter(a, b, s=size, c=colors, alpha=0.6)
plt.show()
输出为:
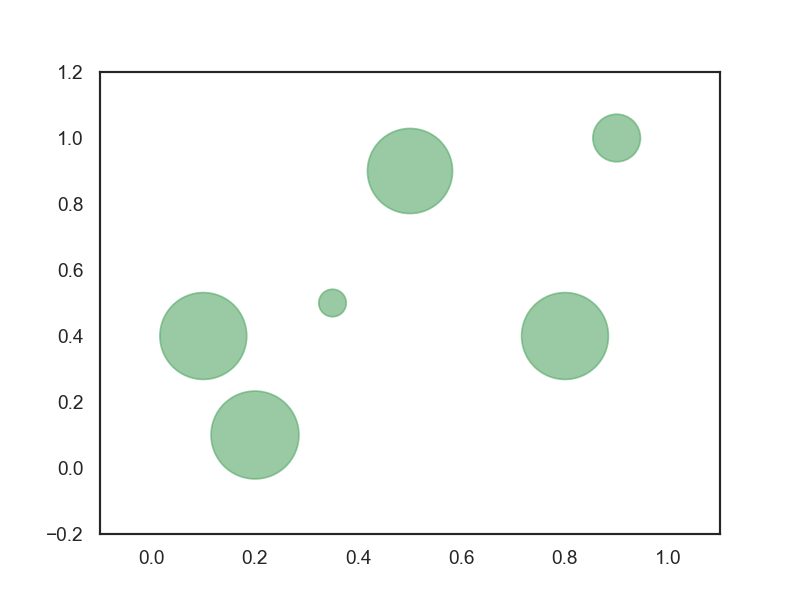
气泡图2-
sns.set(style="white")
a = [0.1, 0.2, 0.35, 0.5, 0.8, 0.9]
b = [0.4, 0.1, 0.5, 0.9, 0.4, 1]
size = [2500, 2560, 250, 2400, 2500, 750]
plt.scatter(a, b, s=size, c='g', alpha=0.6)
plt.axis([-0.1, 1.1, -0.2, 1.2])
plt.show()
输出为:
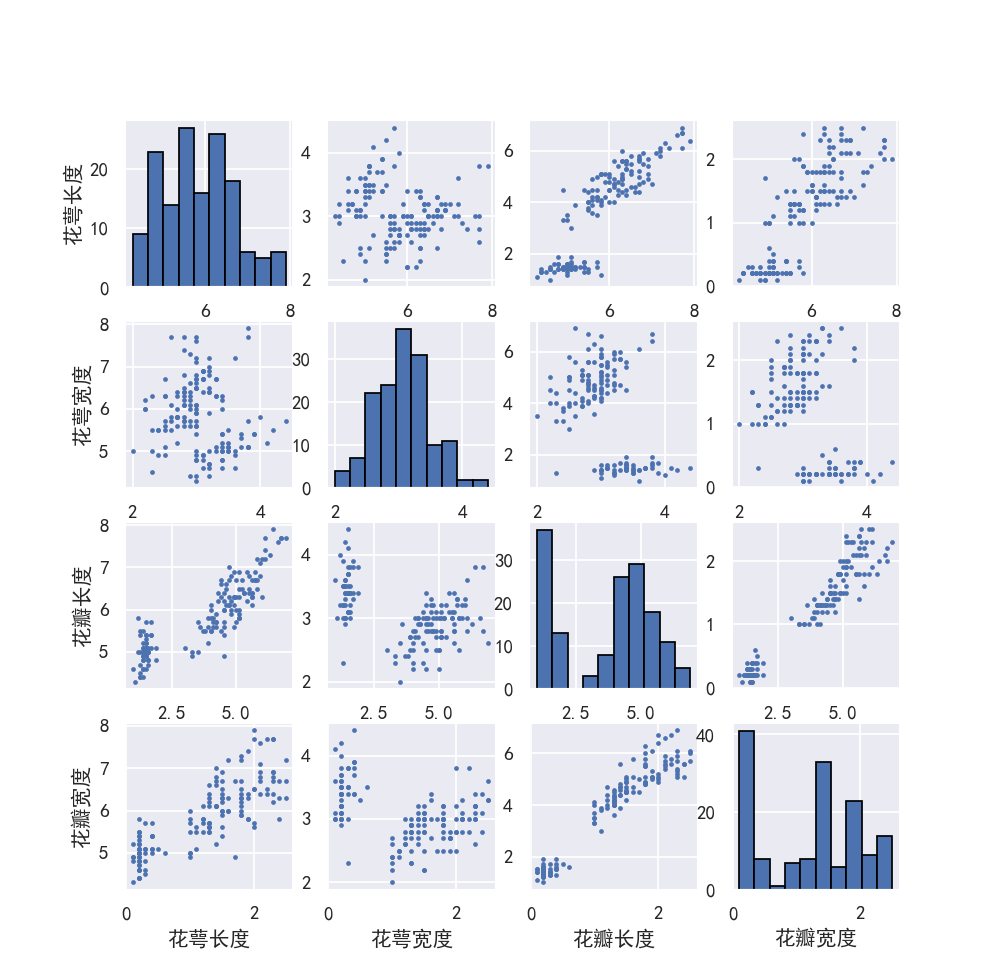
相关图
相关图1-
import seaborn as sns
import pandas as pd
import matplotlib.pyplot as plt
from sklearn import datasets
# 相关图图例一
x = datasets.load_iris().data
m = 0
l = x.shape[1]
plt.figure(figsize=(8, 8))
sns.set(style="darkgrid")
# matplotlib画图中文显示会有问题,需要这两行设置默认字体
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
name = ['花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度']
for i in range(l):
for j in range(l):
m += 1
plt.subplot(4, 4, m)
if i != j:
plt.scatter(x[:, i], x[:, j], s=3) # 画出散点图,设置点的大小为3
plt.grid(True) # 显示网格
if j == 0: plt.ylabel(name[i]) # 只在第一列设置纵标签
if i == 3: plt.xlabel(name[j]) # 只在最后一行设置横标签
else:
plt.hist(x[:, i], edgecolor='black') # 画直方图,使边框为黑色
plt.grid(True) # 显示网格
if i == 0: plt.ylabel(name[i]) # 只在第一列设置纵标签
if i == 3: plt.xlabel(name[i]) # 只在最后一行设置横标签
plt.show()
相关图2-
# 相关图图例2
x = datasets.load_iris().data
m = 0
l = x.shape[1]
plt.figure(figsize=(8, 8))
sns.set(style="darkgrid")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# matplotlib画图中文显示会有问题,需要这两行设置默认字体
name = ['花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度']
for i in range(l):
for j in range(l):
m += 1
plt.subplot(4, 4, m)
if i != j:
sns.regplot(x=x[:, i], y=x[:, j], marker='.') # 添加回归线
if j == 0: plt.ylabel(name[i]) # 只在第一列设置纵标签
if i == 3: plt.xlabel(name[j]) # 只在最后一行设置横标签
else:
plt.hist(x[:, i], edgecolor='black') # 画直方图,使边框为黑色
if i == 0: plt.ylabel(name[i]) # 只在第一列设置纵标签
if i == 3: plt.xlabel(name[i]) # 只在最后一行设置横标签
plt.show()
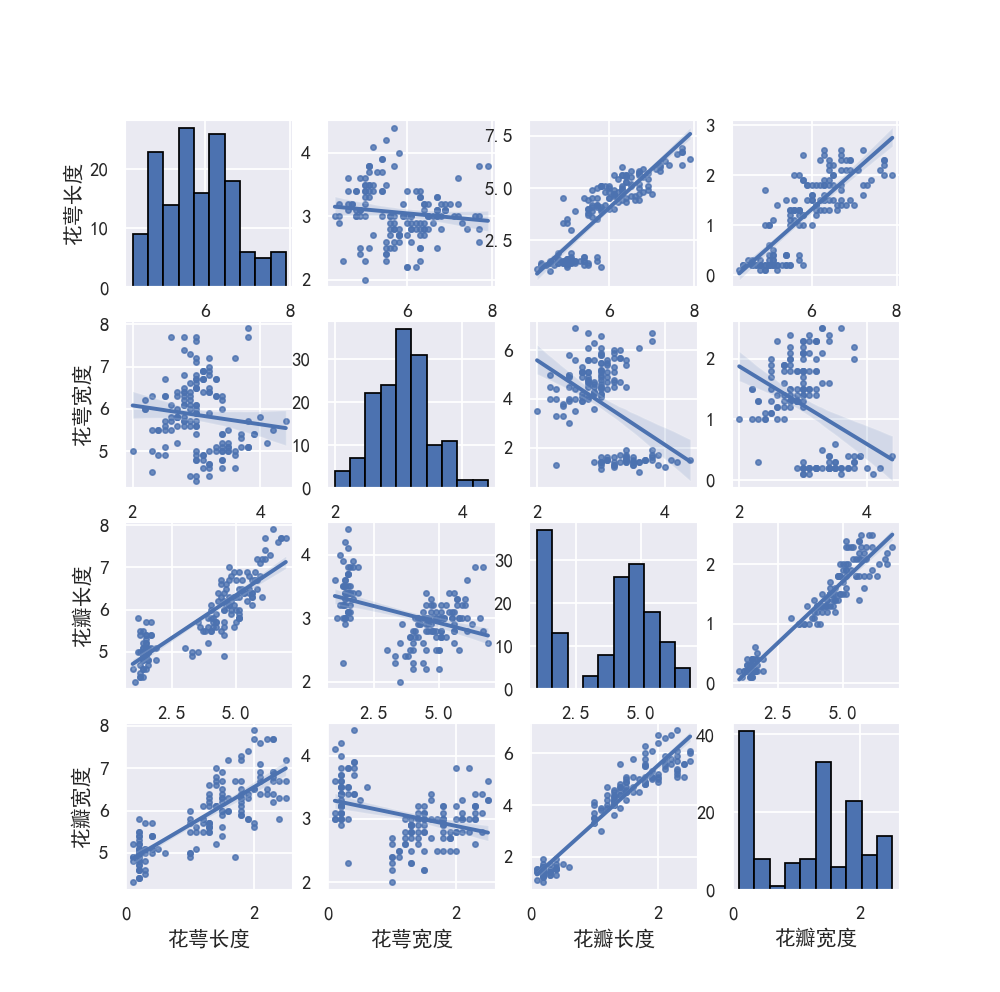
相关图3-
# 相关图图例3
sns.set(style="ticks", color_codes=True)
sns.set_style('whitegrid', {'font.sans-serif': ['simhei', 'FangSong']}) # 解决中文乱码问题
name = ['花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度']
data = datasets.load_iris()
x = pd.DataFrame(datasets.load_iris().data, columns=name)
sns.pairplot(x)
plt.show()
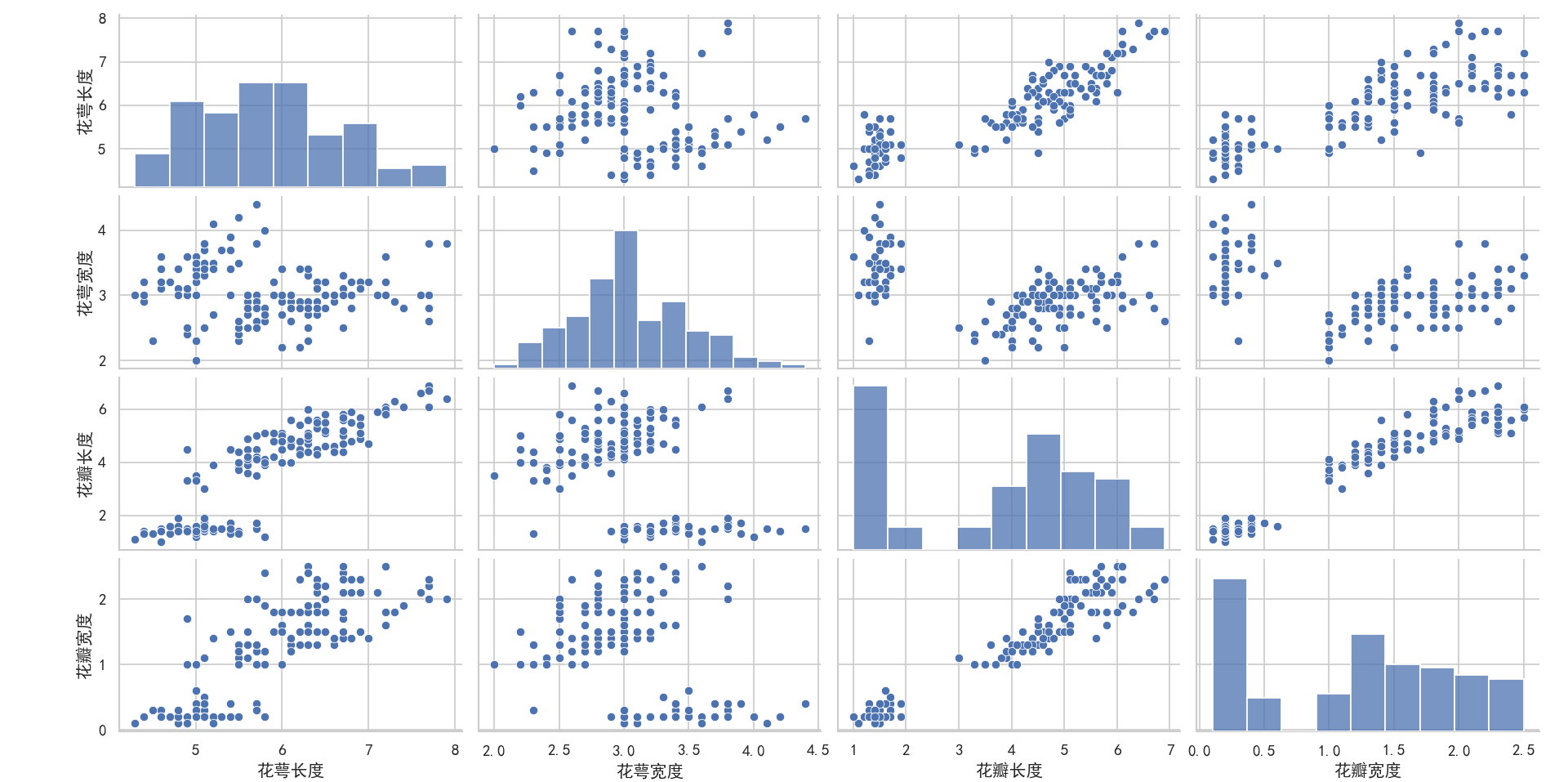
相关图4-
# 相关图图例4
x = datasets.load_iris().data
y = datasets.load_iris().target
m = 0
l = x.shape[1]
plt.figure(figsize=(8, 8))
sns.set(style="darkgrid")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# matplotlib画图中文显示会有问题,需要这两行设置默认字体
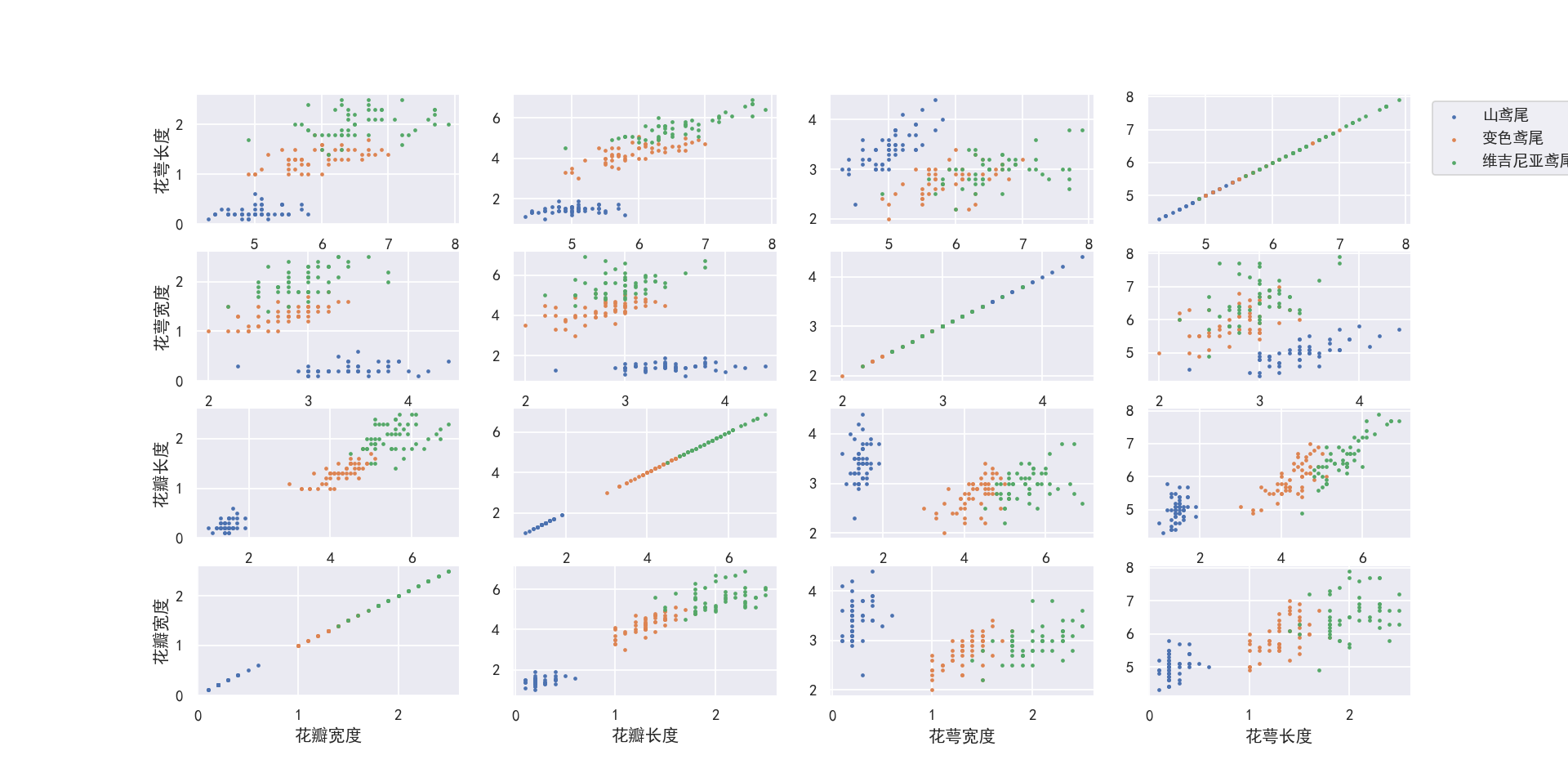
name = ['花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度']
labels = ['山鸢尾', '变色鸢尾', '维吉尼亚鸢尾']
for i in range(l):
for j in range(l):
m += 1
plt.subplot(4, 4, m)
if i != j:
plt.scatter(x[:, i][y == 0], x[:, j][y == 0], s=3) # 画出散点图,设置点的大小为3
plt.scatter(x[:, i][y == 1], x[:, j][y == 1], s=3) # 画出散点图,设置点的大小为3
plt.scatter(x[:, i][y == 2], x[:, j][y == 2], s=3) # 画出散点图,设置点的大小为3
plt.grid(True) # 显示网格
if j == 0: plt.ylabel(name[i]) # 只在第一列设置纵标签
if i == 3: plt.xlabel(name[j]) # 只在最后一行设置横标签
else:
sns.kdeplot(data=x[:, i][y == 0], shade=True)
sns.kdeplot(data=x[:, i][y == 1], shade=True)
sns.kdeplot(data=x[:, i][y == 2], shade=True)
if i == 0: plt.ylabel(name[i]) # 只在第一列设置纵标签
if i == 3: plt.xlabel(name[i]) # 只在最后一行设置横标签
plt.legend(labels, bbox_to_anchor=(1.05, 4.6), loc=2)
plt.show()
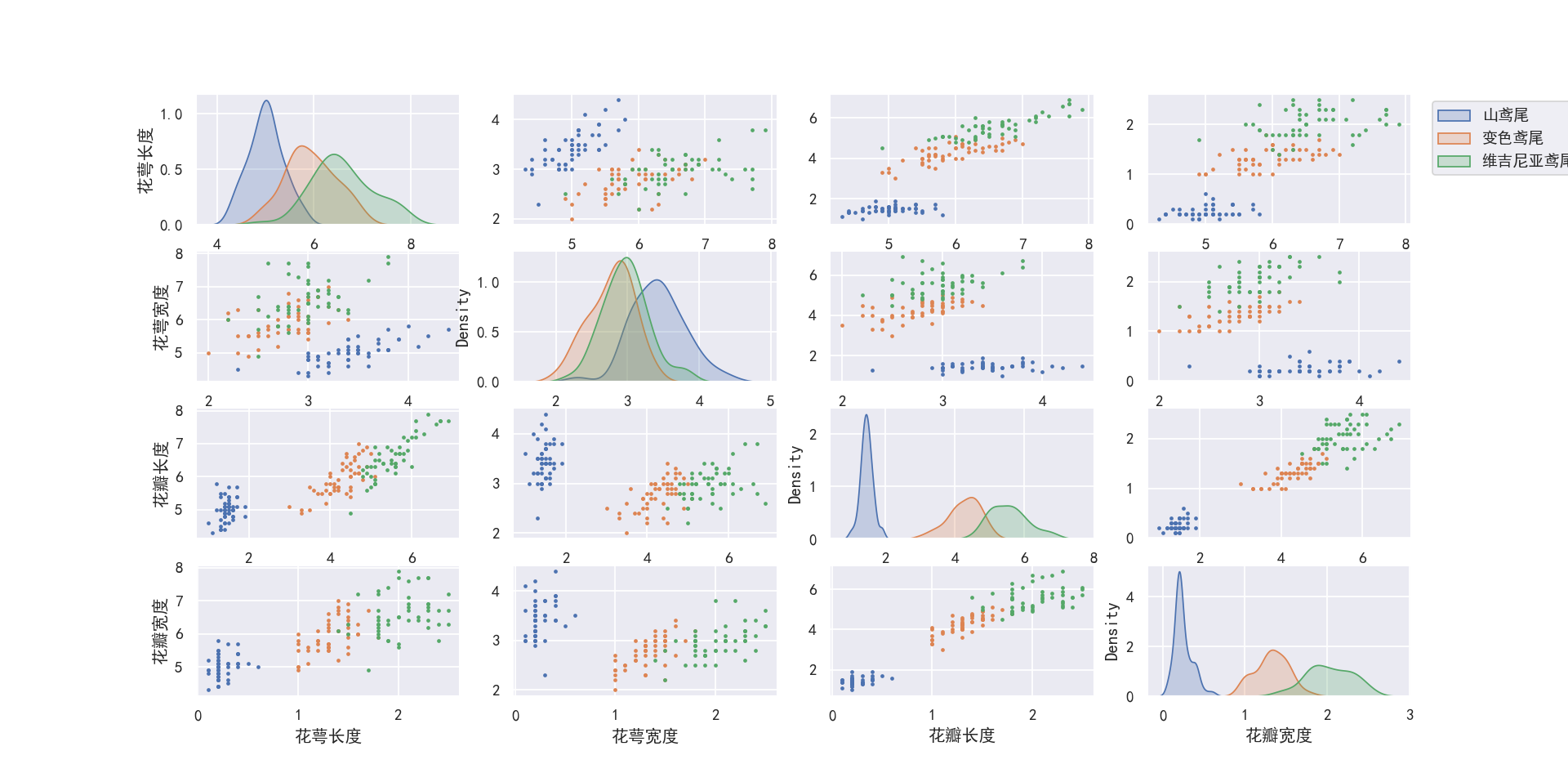
相关图5-
# 相关图图例5
data = datasets.load_iris()
x = datasets.load_iris().data
y = datasets.load_iris().target
m = 0
l = x.shape[1]
plt.figure(figsize=(8, 8))
sns.set(style="darkgrid")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# matplotlib画图中文显示会有问题,需要这两行设置默认字体
name = ['花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度']
# labels=['山鸢尾','变色鸢尾','维吉尼亚鸢尾']
for i in range(l):
for j in range(l):
m += 1
plt.subplot(4, 4, m)
plt.scatter(x[:, i][y == 0], x[:, j][y == 0], s=3, label='山鸢尾') # 画出散点图,设置点的大小为3
plt.scatter(x[:, i][y == 1], x[:, j][y == 1], s=3, label='变色鸢尾') # 画出散点图,设置点的大小为3
plt.scatter(x[:, i][y == 2], x[:, j][y == 2], s=3, label='维吉尼亚鸢尾') # 画出散点图,设置点的大小为3
plt.grid(True) # 显示网格
if j == 0: plt.ylabel(name[i]) # 只在第一列设置纵标签
if i == 3: plt.xlabel(name[j]) # 只在最后一行设置横标签
plt.legend(bbox_to_anchor=(1.05, 4.6), loc=2)
plt.show()
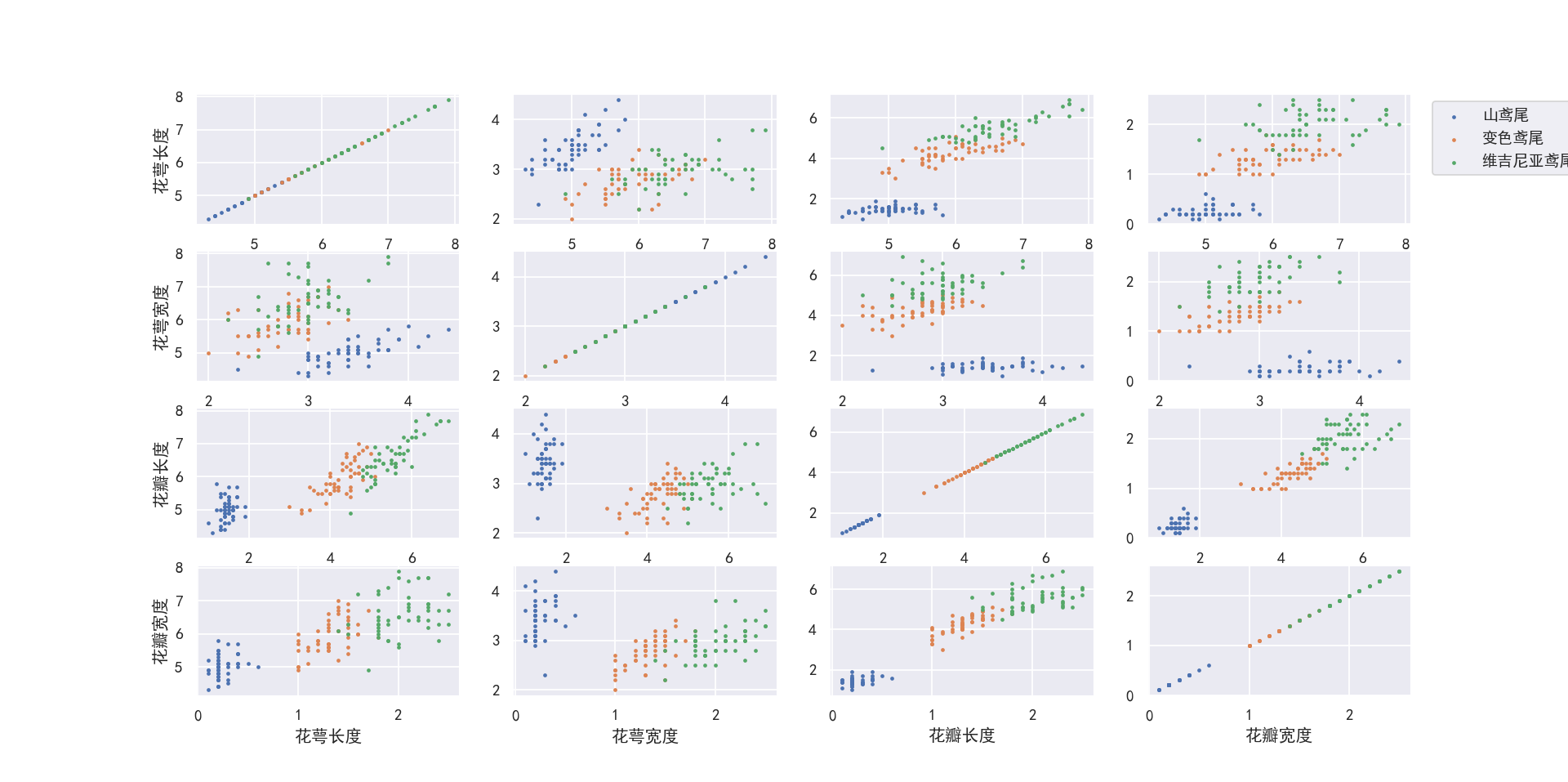
相关图6-
# 相关图图例6
data = datasets.load_iris()
x = datasets.load_iris().data
y = datasets.load_iris().target
m = 0
l = x.shape[1]
plt.figure(figsize=(8, 8))
sns.set(style="darkgrid")
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
# matplotlib画图中文显示会有问题,需要这两行设置默认字体
name = ['花萼长度', '花萼宽度', '花瓣长度', '花瓣宽度']
# labels=['山鸢尾','变色鸢尾','维吉尼亚鸢尾']
for i in range(l):
for j in range(l):
m += 1
plt.subplot(4, 4, m)
plt.scatter(x[:, i][y == 0], x[:, 3 - j][y == 0], s=3, label='山鸢尾') # 画出散点图,设置点的大小为3
plt.scatter(x[:, i][y == 1], x[:, 3 - j][y == 1], s=3, label='变色鸢尾') # 画出散点图,设置点的大小为3
plt.scatter(x[:, i][y == 2], x[:, 3 - j][y == 2], s=3, label='维吉尼亚鸢尾') # 画出散点图,设置点的大小为3
plt.grid(True) # 显示网格
if j == 0: plt.ylabel(name[i]) # 只在第一列设置纵标签
if i == 3: plt.xlabel(name[3 - j]) # 只在最后一行设置横标签
plt.legend(bbox_to_anchor=(1.05, 4.6), loc=2)
plt.show()
热力图
热力图1-
from pyheatmap.heatmap import HeatMap
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
plt.figure(figsize=(6, 5))
x = np.random.randn(4, 4)
sns.heatmap(x, annot=True, vmin=-1, vmax=1)
plt.show()

热力图2-
from pyheatmap.heatmap import HeatMap
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
# 1
X = [1, 23, 4, 34, 3, 47, 38, 7, 11, 9, 8, 44, 13, 5, 45, 24] * 10
Y = [26, 5, 35, 24, 18, 7, 28, 49, 6, 23, 54, 28, 8, 21, 52, 42] * 10
data = []
for i in range(len(X)):
tmp = [int(X[i]), int(Y[i]), 1]
data.append(tmp)
heat = HeatMap(data)
heat.clickmap().show() # 点击图
heat.heatmap().show() # 热图

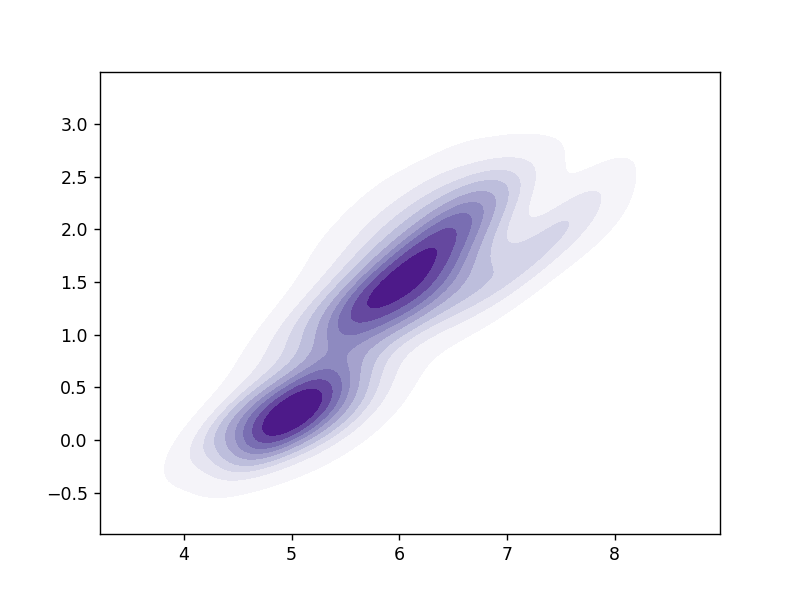
二维密度图
二维密度图1-
import numpy as np
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
from sklearn import datasets
import warnings
warnings.filterwarnings("ignore")
# 图例1
x = datasets.load_iris().data
y = datasets.load_iris().target
sns.kdeplot(x=x[:, 0], y=x[:, 3], cmap='Purples',
shade=True, shade_lowest=False)
plt.show()
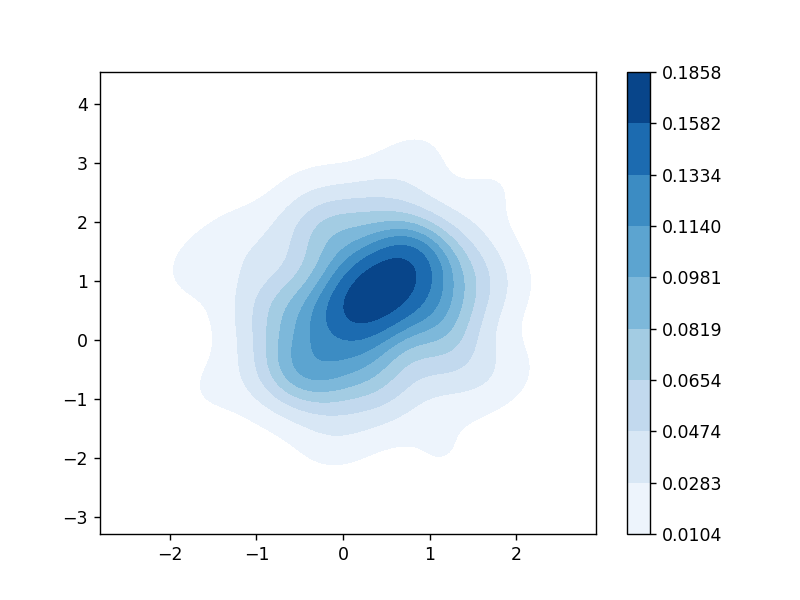
二维密度图2-
# 图例2
cov = [[0.2, 1], [0.5, 0.1]]
mean = [0.4, 0.7]
np.random.seed(123)
y = np.random.multivariate_normal(mean, cov, 100)
sns.kdeplot(x=y[:, 0], y=y[:, 1], shade=True, cmap="Blues", cbar=True)
plt.show()
二维密度图3-
# 图例3
np.random.seed(123)
x = np.random.randn(100)
y = np.random.binomial(50, 0.5, size=100)
sns.set(style="white", font_scale=1.5)
ax = sns.jointplot(x=x, y=y, kind='kde', cmap="Blues")
plt.show()
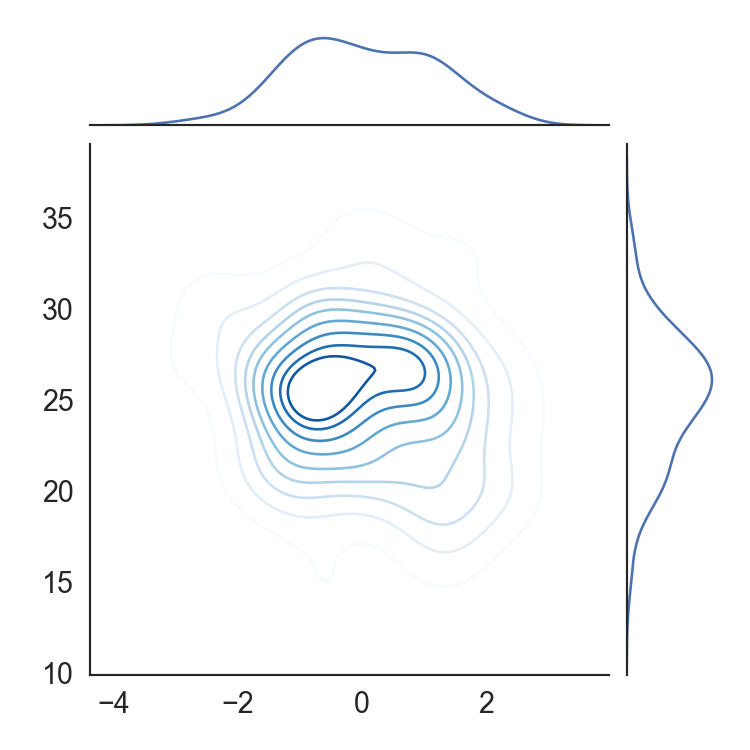
二维密度图4-
# 图例4
mean, cov = [0, 1], [(1, .5), (.5, 1)]
data = np.random.multivariate_normal(mean, cov, 200)
df = pd.DataFrame(data, columns=["x", "y"])
f, ax = plt.subplots(figsize=(6, 6))
cmap = sns.cubehelix_palette(as_cmap=True, dark=0, light=1, reverse=True)
sns.kdeplot(x=df.x, y=df.y, cmap=cmap, n_levels=60, shade=True)
plt.show()

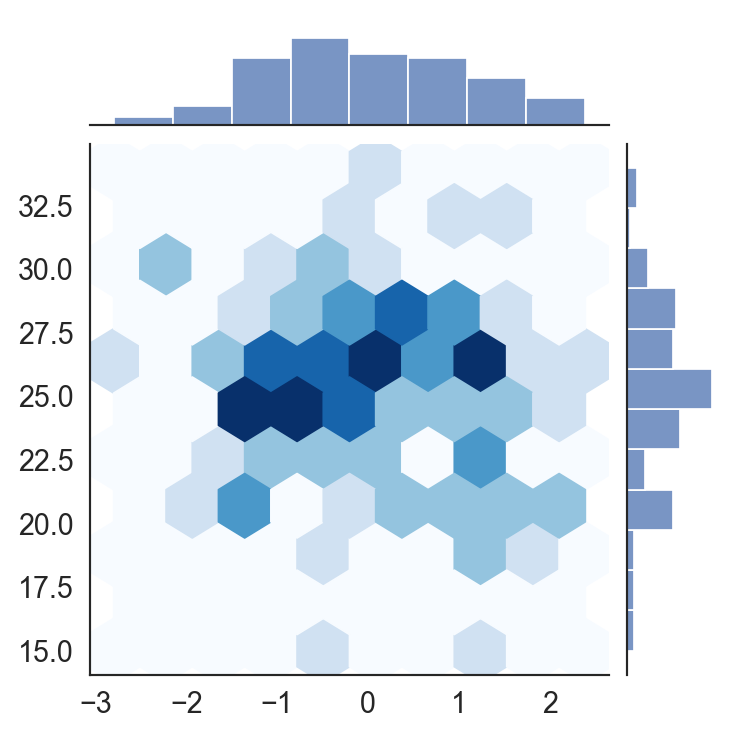
二维密度图5-
# 图例5
np.random.seed(123)
x = np.random.randn(100)
y = np.random.binomial(50, 0.5, size=100)
sns.set(style="white", font_scale=1.5)
ax = sns.jointplot(x=x, y=y, kind='hex', cmap="Blues")
plt.show()
数据可视化第二版-03部分-12章-网络
总结
本系列博客为基于《数据可视化第二版》一书的教学资源博客。本文主要是第12章,网络案例相关。
可视化视角-相关

代码实现
安装依赖
pip install scikit-learn -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install seaborn -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install tushare==1.2.89 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install mplfinance==0.12.9b7 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install pyheatmap==0.1.12 -i https://pypi.tuna.tsinghua.edu.cn/simple
pip install networkx==3.1
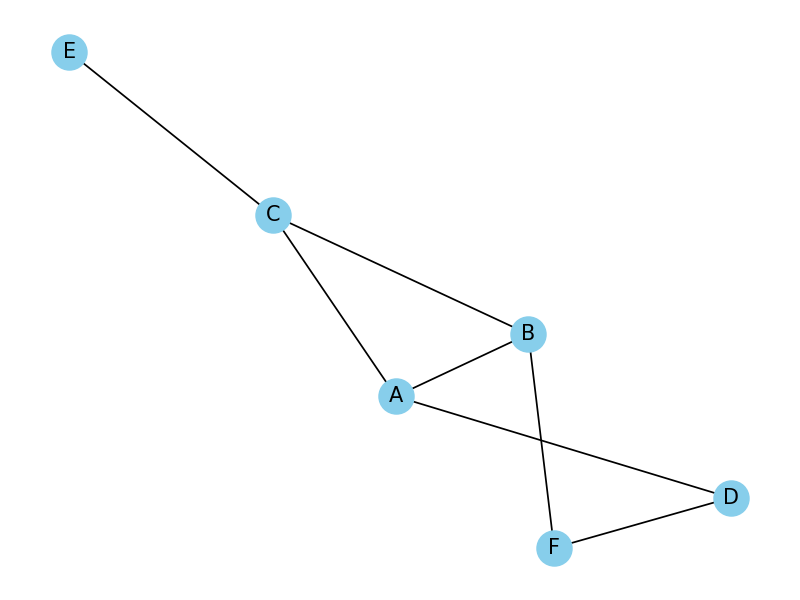
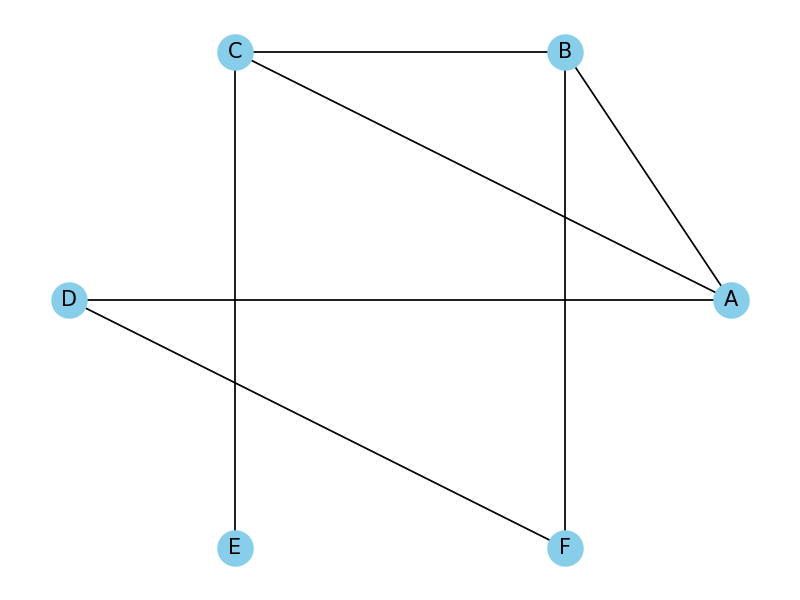
网络图
参考:基于NetworkX构建复杂网络的应用案例
网络图1-networkx
# 网络图
from matplotlib import pyplot as plt
import networkx as nx
G = nx.Graph()
G.add_nodes_from(["A", "B", "C", "D", "E", "F"])
G.add_edges_from([("A", "B"), ("A", "C"), ("A", "D"), ("B", "C"), ("B", "F"), ("C", "E"), ("D", "F")])
# with_labels是否显示标签,node_size节点大小,node_color节点颜色,node_shape节点形状,alpha透明度,linewidths线条宽度
# 左:跳跃式布局
nx.draw(G, with_labels=True, node_size=400, node_color="skyblue", node_shape="o", alpha=1, width=1, font_size=12,
font_color="black")
plt.show()
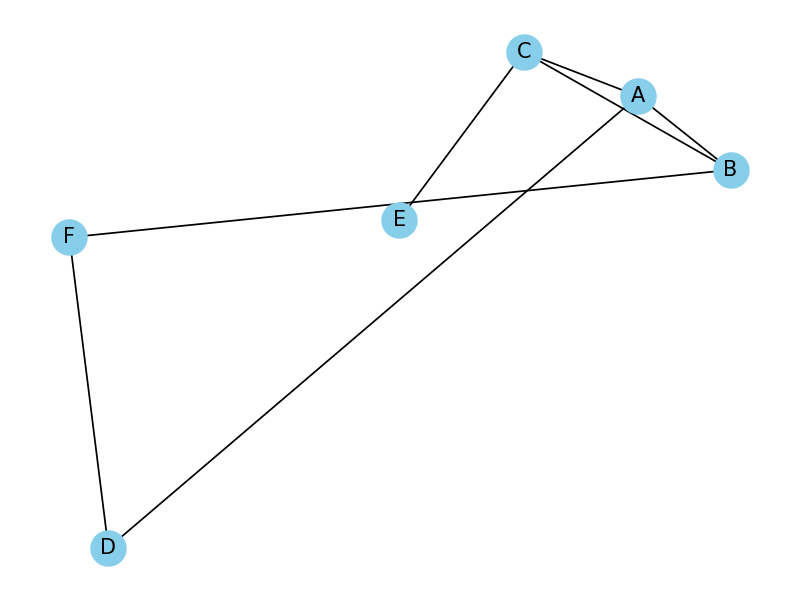
# 中:环形布局
nx.draw(G, with_labels=True, node_size=400, node_color="skyblue", node_shape="o", alpha=1, width=1, font_size=12,
font_color="black", pos=nx.circular_layout(G))
plt.show()
# 右:随机布局
nx.draw(G, with_labels=True, node_size=400, node_color="skyblue", node_shape="o", alpha=1, width=1, font_size=12,
font_color="black", pos=nx.random_layout(G))
plt.show()
'''
networkx 画图参数:
- node_size: 指定节点的尺寸大小(默认是300)
- node_color: 指定节点的颜色 (默认是红色,可以用字符串简单标识颜色,例如'r'为红色,'b'为绿色等,具体可查看手册),用“数据字典”赋值的时候必须对字典取值(.values())后再赋值
- node_shape: 节点的形状(默认是圆形,用字符串'o'标识,具体可查看手册)
- alpha: 透明度 (默认是1.0,不透明,0为完全透明)
- width: 边的宽度 (默认为1.0)
- edge_color: 边的颜色(默认为黑色)
- style: 边的样式(默认为实现,可选: solid|dashed|dotted,dashdot)
- with_labels: 节点是否带标签(默认为True)
- font_size: 节点标签字体大小 (默认为12)
- font_color: 节点标签字体颜色(默认为黑色)
e.g. nx.draw(G,node_size = 30, with_label = False)
绘制节点的尺寸为30,不带标签的网络图。
布局指定节点排列形式
pos = nx.spring_layout
建立布局,对图进行布局美化,networkx 提供的布局方式有:
- circular_layout:节点在一个圆环上均匀分布
- random_layout:节点随机分布
- shell_layout:节点在同心圆上分布
- spring_layout: 用Fruchterman-Reingold算法排列节点
- spectral_layout:根据图的拉普拉斯特征向量排列节
布局也可用pos参数指定,例如,nx.draw(G, pos = spring_layout(G)) 这样指定了networkx上以中心放射状分布.
'''
输出为:
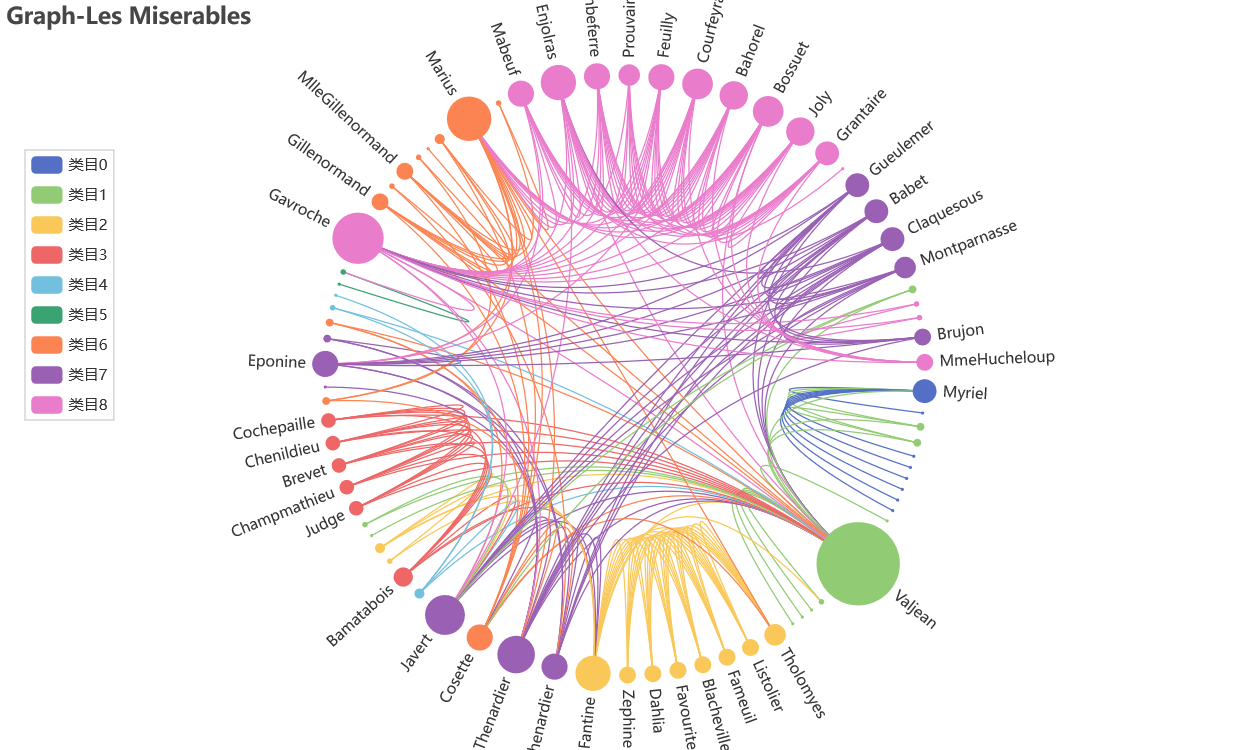
弧形图
环形弧形长链接图
# -*- coding: utf-8 -*-
"""
@reference
https://gallery.pyecharts.org/#/Graph/graph_les_miserables
https://github.com/pyecharts/pyecharts-gallery/blob/master/Graph/les-miserables.json
"""
import json
from pyecharts import options as opts
from pyecharts.charts import Graph
import os
os.chdir(os.path.dirname(__file__))
with open("les-miserables.json", "r", encoding="utf-8") as f:
j = json.load(f)
nodes = j["nodes"]
links = j["links"]
categories = j["categories"]
c = (
Graph(init_opts=opts.InitOpts(width="1000px", height="600px"))
.add(
"",
nodes=nodes,
links=links,
categories=categories,
layout="circular",
is_rotate_label=True,
linestyle_opts=opts.LineStyleOpts(color="source", curve=0.3),
label_opts=opts.LabelOpts(position="right"),
)
.set_global_opts(
title_opts=opts.TitleOpts(title="Graph-Les Miserables"),
legend_opts=opts.LegendOpts(orient="vertical", pos_left="2%", pos_top="20%"),
)
.render("graph_les_miserables.html")
)
import os
os.system("graph_les_miserables.html")
输出为:
桑基图
桑基图1-
# -*- coding: utf-8 -*-
"""
@reference:
https://pyecharts.org/#/zh-cn/basic_charts?id=sankey%ef%bc%9a%e6%a1%91%e5%9f%ba%e5%9b%be
https://gallery.pyecharts.org/#/Sankey/sankey_base
"""
from pyecharts import options as opts
from pyecharts.charts import Sankey
# 内置主题类型可查看 pyecharts.globals.ThemeType
"""
from pyecharts.globals import ThemeType
"""
nodes = [
{"name": "category1"},
{"name": "category2"},
{"name": "category3"},
{"name": "category4"},
{"name": "category5"},
{"name": "category6"},
]
links = [
{"source": "category1", "target": "category3", "value": 10},
{"source": "category1", "target": "category4", "value": 15},
{"source": "category2", "target": "category3", "value": 10},
{"source": "category2", "target": "category4", "value": 10},
{"source": "category3", "target": "category5", "value": 20},
{"source": "category4", "target": "category5", "value": 10},
{"source": "category4", "target": "category6", "value": 15},
]
# pyecharts V1 版本开始所有方法均支持链式调用。
sankey = (
Sankey() # 试试变换主题:Sankey(init_opts=opts.InitOpts(theme=ThemeType.LIGHT)),参考:进阶话题-定制主题
.add(
"sankey",
nodes,
links,
linestyle_opt=opts.LineStyleOpts(opacity=0.2, curve=0.5, color="source"),
label_opts=opts.LabelOpts(position="right"), # 节点标签位置可选,参考:配置项-系列配置项-标签配置项
)
.set_global_opts(title_opts=opts.TitleOpts(title="Sankey-基本示例"))
# 或者直接使用字典参数
# .set_global_opts(title_opts={"text": "主标题", "subtext": "副标题"})
.render("sankey_base_2.html")
# render 会生成本地 HTML 文件,默认会在当前目录生成 render.html 文件
# 也可以传入路径参数,如 Sankey.render("sankey_base.html")
)
import os
os.system("sankey_base_2.html")
# 不习惯链式调用的开发者依旧可以单独调用方法
"""
sankey = Sankey()
sankey.add("sankey",
nodes,
links,
linestyle_opt=opts.LineStyleOpts(opacity=0.2, curve=0.5, color="source"),
label_opts=opts.LabelOpts(position="right"),
)
sankey.set_global_opts(title_opts=opts.TitleOpts(title="Sankey-基本示例"))
sankey.render("sankey_base.html")
"""
# 渲染成图片文件
"""
from pyecharts.render import make_snapshot
# 使用 snapshot-selenium 渲染图片(需安装)
from snapshot_selenium import snapshot
make_snapshot(snapshot, sankey, "sankey_base.png")#sankey为html文件
#snapshot-selenium 报错处理可参考:https://blog.csdn.net/snwang_miss/article/details/117728949
"""
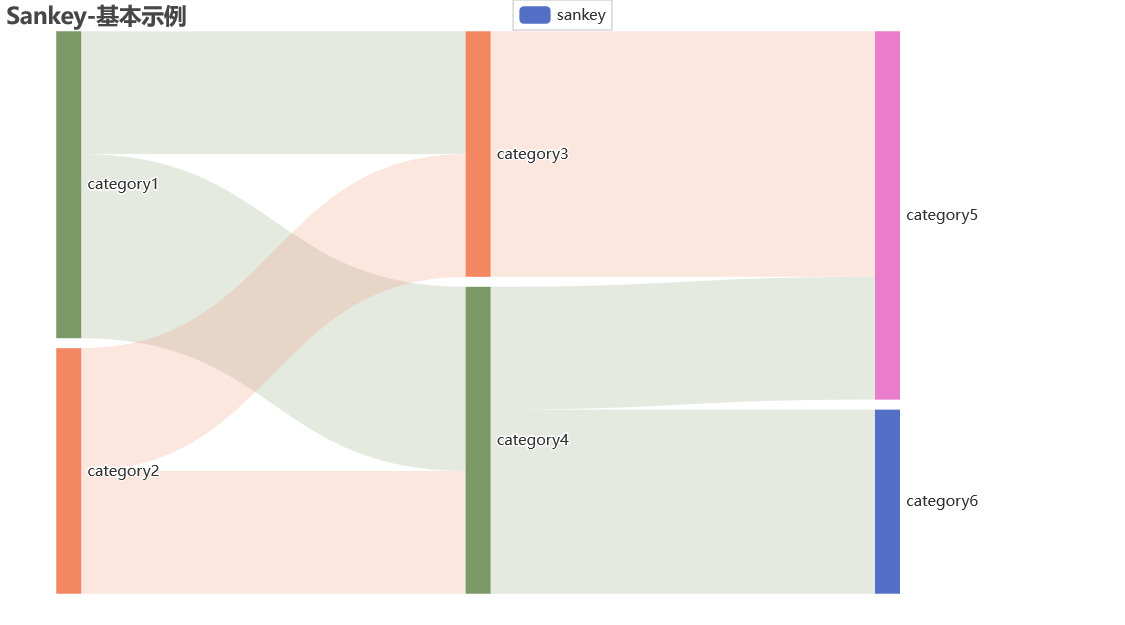
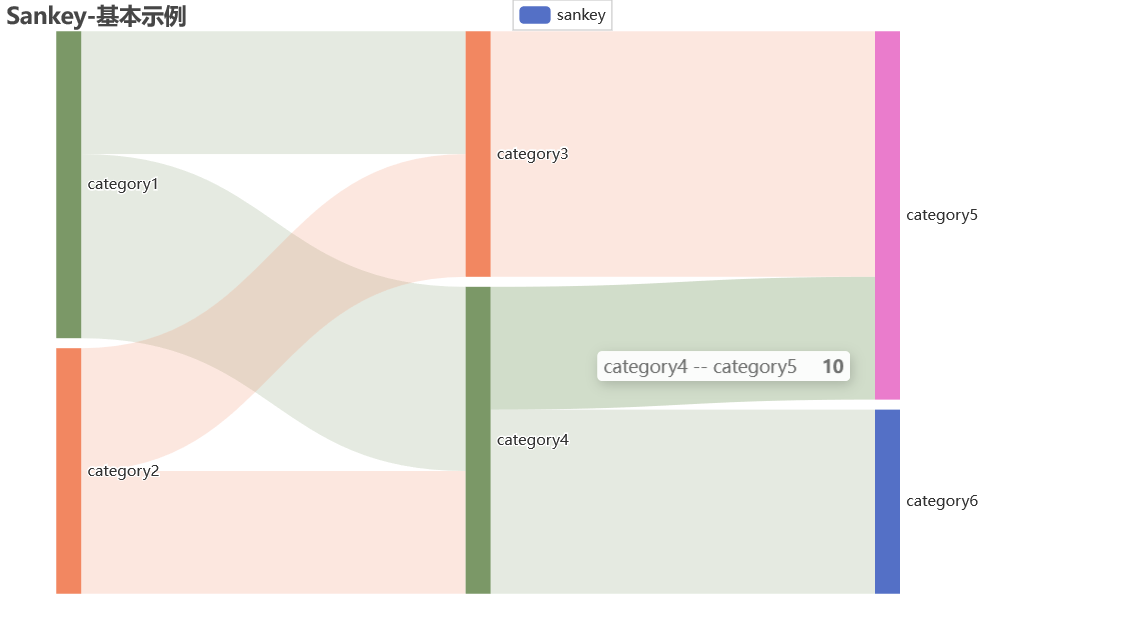
桑基图2-
from pyecharts import options as opts
from pyecharts.charts import Sankey
nodes = [
{"name": "category1"},
{"name": "category2"},
{"name": "category3"},
{"name": "category4"},
{"name": "category5"},
{"name": "category6"},
]
links = [
{"source": "category1", "target": "category3", "value": 10},
{"source": "category1", "target": "category4", "value": 15},
{"source": "category2", "target": "category3", "value": 10},
{"source": "category2", "target": "category4", "value": 10},
{"source": "category3", "target": "category5", "value": 20},
{"source": "category4", "target": "category5", "value": 10},
{"source": "category4", "target": "category6", "value": 15},
]
sankey = (
Sankey()
.add(
"sankey",
nodes,
links,
linestyle_opt=opts.LineStyleOpts(opacity=0.2, curve=0.5, color="source"),
label_opts=opts.LabelOpts(position="right"),#节点标签位置
)
.set_global_opts(title_opts=opts.TitleOpts(title="Sankey-基本示例"))
.render("sankey_base.html")
)
import os
os.system("sankey_base.html")
桑基图3-
from pyecharts import options as opts
from pyecharts.charts import Sankey
# 内置主题类型可查看 pyecharts.globals.ThemeType
from pyecharts.globals import ThemeType
nodes = [
{"name": "category1"},
{"name": "category2"},
{"name": "category3"},
{"name": "category4"},
{"name": "category5"},
{"name": "category6"},
]
links = [
{"source": "category1", "target": "category3", "value": 10},
{"source": "category1", "target": "category4", "value": 15},
{"source": "category2", "target": "category3", "value": 10},
{"source": "category2", "target": "category4", "value": 10},
{"source": "category3", "target": "category5", "value": 20},
{"source": "category4", "target": "category5", "value": 10},
{"source": "category4", "target": "category6", "value": 15},
]
sankey_vertical = (
Sankey(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
.add(
"sankey",
nodes,
links,
# Sankey 组件离容器外侧的距离 types.Union[str, types.Numeric]:默认值:pos_left="5%",pos_right="20%",
pos_left="20%",
orient="vertical",
linestyle_opt=opts.LineStyleOpts(opacity=0.2, curve=0.5, color="source"),
label_opts=opts.LabelOpts(position="inside"),#节点标签位置可选,参考:配置项-系列配置项-标签配置项
)
.set_global_opts(title_opts=opts.TitleOpts(title="Sankey-Vertical"))
.render("sankey_vertical.html")
)
import os
os.system("sankey_vertical.html")

有趣的可视化
https://plotapi.com/#billing_interval