精读(非常推荐) Generating Mammography Reports from Multi-view Mammograms with BERT(上)
这里的作者有个叫 Ilya 的吓坏我了
1. Abstract
Writing mammography reports can be errorprone and time-consuming for radiologists. In this paper we propose a method to generate mammography reports given four images, corresponding to the four views used in screening mammography. To the best of our knowledge our work represents the first attempt to generate the mammography report using deep-learning. We propose an encoder-decoder model that includes an EfficientNet-based encoder and a Transformerbased decoder. We demonstrate that the Transformer-based attention mechanism can combine visual and semantic information to localize salient regions on the input mammograms and generate a visually interpretable report. The conducted experiments, including an evaluation by a certified radiologist, show the effectiveness of the proposed method. Our code is available at
代码: https://github.com/sberbank-ai-lab/mammo2text.
2. Introduction
Breast cancer represents a global healthcare problem (Glo, 2016). Increasing numbers of new cases and deaths are observed in both developed and less developed countries, only partially attributable to the increasing population age. Serial screening with mammography is the most effective method to detect early stage disease and decrease mortality. The goal of screening is to detect breast cancers when still curable to decrease breast cancer-specific mortality (Duffy et al., 2020).
初衷是在可治愈的前提下,减少死亡率
The European Society of Breast Imaging (EUSOBI) together with 30 national breast radiology bodies recommend that only qualified radiologists should be involved in screening programs. (Sardanelli et al., 2017).As the amount of organized breast screening programs grows across the world, the burden on radiologists increases with it. In National screening programs such as in Holland or Sweden, radiologists may need to read 100 radiology images per hour (Abbey et al., 2020). With a growing number of screening programs , we need more trained radiologists and new technologies that can make their workflow more effective. Since one of the most time consuming procedures in radiology is writing medical-imaging reports, we explore the potential for deep-learning to automatically generate diagnostic reports of screening mammograms.
提出由于工作负担导致,智能生成报告的背景
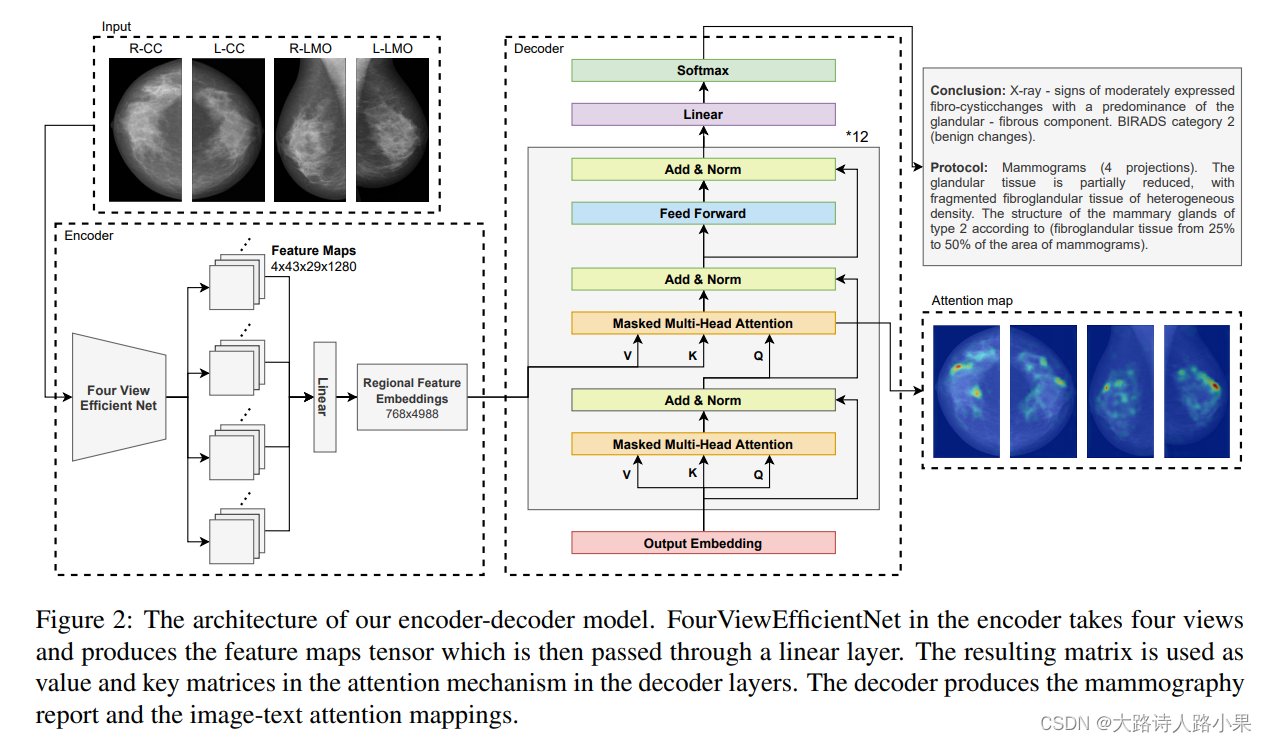
The rapid evolution of deep learning and artificial intelligence technologies enables them to be used as a strong tool for providing clinical decision-making support to the medical community. While many problems in the area of medical imaging and text analysis have been addressed effectively, there is no known approach to generating clinical reports for mammography studies. There are various reasons for this, such as the requirements regarding the accuracy, completeness and diagnostic relevance of the clinical information contained in the report. In this article, we present a framework (Figure1) that takes mammograms as an input, automatically generates mammography reports, and visualizes the attention of the model to provide the interpretability of the process.
We use an encoder-decoder architecture, where the encoder extracts visual features and the decoder generates reports. We adopt a convolutional neural network, specifically EfficientNet (M Tan, 2019), to extract visual features of the four images, corresponding to the four views used in screening mammography.
引文:
Tan, M., & Le, Q. (2019, May). Efficientnet: Rethinking model scaling for convolutional neural networks. In International conference on machine learning (pp. 6105-6114). PMLR.
EfficientNet (M Tan, 2019) 实际上是一种构建视觉模型网络的范式,😐 为什么要使用这样的视觉模型?如何更好的构建起来一个更好的混合视觉模型,如何组合参数,这里之所以使用这个是不是因为,医学图像并 不同于 自然图像,尤其是钼靶图像这样的有精确化的钙化点,会不会是就是它 重新思考 构建视觉模型结构的原因。
😐 这里实际上,作者解释了对于乳腺钼靶这样的高分辨率图像,使用 EfficientNet B0 可以效率更高!
We use a deep multi-view (N Wu, 2019) CNN based on EfficientNet B0 (M Tan, 2019). We chose EfficientNet B0 because it is relatively lightweight and fits in GPU memory when using high resolution images. We have one EfficientNet instance for all views (R-CC, L-CC, R-MLO, L-MLO), i.e. model weights are shared. The first convolutional layer is replaced to accept a one-channel image. The last fully-connected layer of EfficientNet is discarded. Outputs from all four views are averaged by channels and one fully connected layer is added.
For language modeling, we utilize BERT (Devlin et al., 2018), inserting an additional attention sub-layer to perform multi-head attention over the regional feature embeddings produced by the encoder.
We modify the Transformerbased attention mechanism (Vaswani et al., 2017) such that it attends to the visual information on four mammography views and previously generated words. We use the attention scores to build visually interpretable image-text attention mappings.
In addition to that, we conduct a series of indepth quantitative and qualitative experiments with the help of an experienced radiologist to demonstrate the clinical validity of our approach. We compare the predictions of our models with the ground truth to understand where the models make mistakes and demonstrate that our best model successfully describes different parts of the breast, and detects pathological regions and abnormalities. We evaluate the image-text attention mappings to demonstrate the interpretability of our model. As far as we are aware, our work represents the first attempt to generate the mammography report using deep-learning.
重点看看那个attention map,和视觉模型的比例,从论文上看效果非常好
-
To summarize, we make the following contributions in this paper:
-
- We propose a novel framework for mammography report generation using EfficientNet in the
encoder and BERT in the decoder. - We demonstrate that the Transformer-based attention mechanism can combine visual and textual
information to localize salient regions on the input mammograms and generate a visually interpretable
report. - We conduct doctor evaluation and extensive experiments with automatic metrics to show the effectiveness of the proposed framework.
- We conduct a qualitative analysis including interpretation of image-text attention mappings to demonstrate how the model is able to generate mammography reports in a meaningful way.
- We propose a novel framework for mammography report generation using EfficientNet in the
3. Related work
The task of image captioning is creating a model that given a previously unseen query image generates a caption that is both grammatically and semantically correct. The main approaches to image captioning are retrieval-based, template-based and novel caption generation.
-
方法汇总
-
- Retrieval-based, 检索式(Retrieval-based): 这种方法通过在一个预先定义的数据库中搜索最匹配当前图像的描述来工作。数据库中的描述是由人类创建的,针对不同的图像。当给定一个新图像时,系统会尝试找到与之最相似的图像(或图像集),然后将找到的图像的描述作为新图像的描述。这种方法的优点是生成的描述文本质量较高,因为所有的描述都是人类编写的。但是,它的缺点是难以扩展到新的、未见过的图像,而且在数据库中找到精确匹配的图像可能很困难。
- Template-based 模板式(Template-based): 这种方法使用预定义的模板来生成描述,模板中包含可变的插槽,这些插槽可以根据图像的内容动态填充。例如,模板可以是“这是一张关于[对象]的照片,在[场景]中”,其中“[对象]”和“[场景]”会根据图像识别的结果填充。模板方法的优点是易于实现和理解,而且生成的文本通常语法正确。然而,它的缺点是生成的描述可能缺乏多样性和创造性,因为所有的描述都是基于固定模板生成的。
- Novel caption generation. 新颖描述生成(Novel Caption Generation): 这种方法使用深度学习模型,如卷积神经网络(CNN)和循环神经网络(RNN)或Transformer模型,直接从图像中生成新颖的描述。这种方法不依赖于预定义的模板或数据库,而是通过学习大量图像和其对应描述的数据集,使模型能够学会如何根据图像的内容生成描述。新颖描述生成方法的优点是能够创造出多样化且丰富的描述,而且可以应用于未见过的图像。然而,这种方法的挑战在于需要大量的标注数据来训练模型,且模型的训练计算成本较高。
In retrieval-based methods (Hodosh et al., 2013), (Ordonez et al., 2011) candidate captions for query images are selected from a pool of existing captions based on some measure of similarity. The downside of this approach is the inability to generate novel image-specific captions.
In template-based methods (Farhadi et al., 2010), (Kulkarni et al., 2013), (Li et al., 2011) image captions are generated by filling the blanks in fixed templates. These methods can generate grammatically and semantically correct novel captions not present in the training set but cannot generate variable-length captions.
Novel caption generation methods (Xu et al., 2015), (Yao et al., 2017), (You et al., 2016) use a representation of the query image as an input for a language model responsible for generating the captions. This approach follows the encoder-decoder architecture first applied to machine translation tasks (Cho et al., 2014).
To generate an image caption, a representation of the image must first be constructed either via generating handcrafted features or extracting such features automatically, for example using deep neural networks. Examples of hand-crafted features are local binary patterns (Ojala et al., 2002), scaleinvariant keypoints (Lowe, 2004), or histograms of oriented gradients (Dalal and Triggs, 2005). Automatic feature extraction from images is commonly used by applying convolutional neural networks (CNN) (LeCun et al., 1998) to the query image. These features may be further enhanced, for example by using a spatial Transformer (Pedersoli et al.,2017).
A sub-field of image captioning is diagnostic captioning (DC). Diagnostic captioning is automatic generation of diagnostic text based on a set of medical images of a patient. DC systems can increase the speed of producing a report for experienced physicians and decrease the number of diagnostic errors for inexperienced doctors (for a recent survey on DC methods see (Pavlopoulos et al., 2021)). The majority of the work in DC is done using encoder-decoder architecture. In addition to evaluation of grammatical and semantical correctness of captions, which is commonly assessed by calculating lexical overlap between generated captions and ground truth (Pavlopoulos et al., 2019), DC quality can be assessed by clinical correctness by conducting clinical experiments with physicians evaluating the generated reports (Zhang et al., 2019), (Liu et al., 2019).
Language models commonly used in DC usually apply recurrent neural networks (RNN) such as LSTM (Hochreiter and Schmidhuber, 1997), see (Vinyals et al., 2015) (Xu et al., 2015), with works using Transformer-based models beginning to appear (Chen et al., 2020) . A common approach in DC is the use of ’visual attention’ that allows the decoder to focus on particular areas of input images when generating the captions (Jing et al., 2017), (Yuan et al., 2019). Such mechanisms also can be used to highlight the regions of interest on the input images adding to the interpretability of the models (Zhang et al., 2017).
(Chen et al., 2020)
Zhihong Chen
(Jing et al., 2017)
Baoyu Jing
(Yuan et al., 2019)
Jianbo Yuan,
We split the dataset into the training, validation and test subsets in the proportion of 91%, 4% and 5% respectively (having 22463, 934 and 1229 cases in each subset). The splits are the same for encoder
这里可能一个case对应多个标签,所以,这里的labels并不是总数的和。

这里数据集划分的很仔细,值得学习,但是具体如何使用,它应该是使用了一种方法,尽量使得种类平衡。
We use a deep multi-view (N Wu, 2019) CNN based on EfficientNet B0 (M Tan, 2019). We chose EfficientNet B0 because it is relatively lightweight and fits in GPU memory when using high resolution images. We have one EfficientNet instance for all views (R-CC, L-CC, R-MLO, L-MLO), i.e. model weights are shared . The first convolutional layer is replaced to accept a one-channel image. The last fully-connected layer of EfficientNet is discarded. Outputs from all four views are averaged by channels and one fully connected layer is added.
-
模型的设计和我预想大体的一致,但是也有很多不同,提供了一个很好的思路。
-
- 第一层卷积核并没有使用超大卷积核,而是正常的卷积核,同时,输入通道为1,而不是3
- 所有的图片经过同一个视觉编码器进行学习,所谓的分享权重
- 所有的output通过平均相加,最终得到输出特征
- 去掉了最后一层的全连接层
The encoder is pretrained to predict multilabel targets important for diagnosis in mammography screening, shown in Table 1. The binary targets were extracted with regular expressions from text descriptions of the studies. Targets № 0-4 are typical pathological changes in breasts tissues. During training, the images are cropped and resized to 1350x900 px.
这里的数据集处理的比我好,同时视觉模型的大概肯定也比我自己设计的好,但是预训练的过程现在可以使用更多方法。因为现在有了CLIP,GLoRIA这样的模型进行预训练模型结构。
跳过模型的结构,先看模型的测试部分
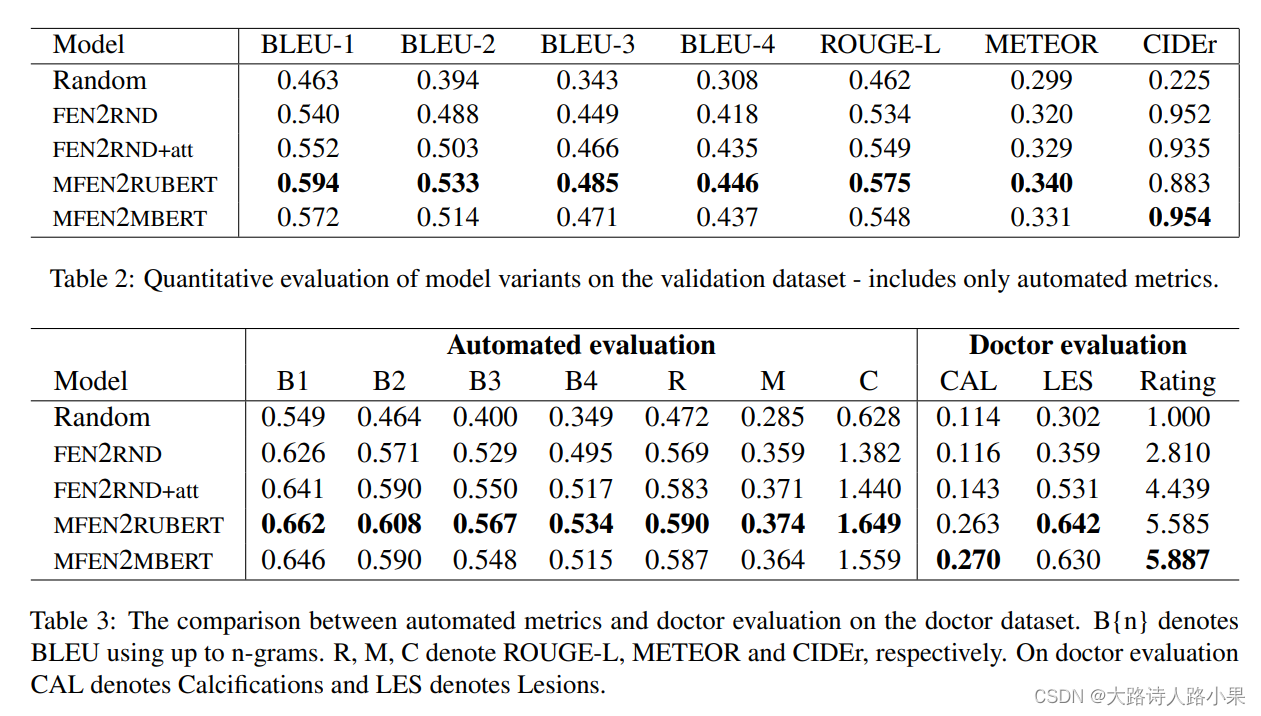
我觉得这里展示了一个很好的模型测试范式,这里的random很好的说明了模型的效果例子,同时不同于之前看到的BLEU, METEOR, ROUGE-L 这里还告诉了我们可以使用CIDEr模型。
-
评估指标:
-
-
BLEU (Bilingual Evaluation Understudy):这是机器翻译质量评估中使用最广泛的指标之一。它通过计算机器生成的翻译和一组人工翻译之间n-grams的重叠来评估翻译的质量。BLEU分数越高,意味着生成的翻译和参考翻译之间的重叠越多,通常认为翻译质量越好。
-
METEOR (Metric for Evaluation of Translation with Explicit Ordering):它是对BLEU的改进,不仅考虑了单词的精确匹配,还考虑了词形、同义词和词序的匹配。METEOR也会对匹配的单词进行加权,给予不同类型的匹配(如词干匹配或同义词匹配)不同的重要性。
-
ROUGE-L (Recall-Oriented Understudy for Gisting Evaluation - Longest Common Subsequence):ROUGE主要用于评估自动文本摘要或机器翻译的质量。ROUGE-L的“L”代表最长公共子序列(LCS),它考虑了候选文本和参考文本之间的最长公共子序列。这个度量考虑了候选文本和参考文本中的词序,使用最长公共子序列来评估它们之间的相似度。
-
CIDEr (Consensus-based Image Description Evaluation):专为评估图像描述任务设计的度量,通过计算候选描述和参考描述集中n-grams的相似性来衡量描述的质量。CIDEr特别强调词汇的独特性,通过TF-IDF统计来增加稀有词汇的权重,以鼓励生成的描述能够反映出图片的特定和独特内容。
-
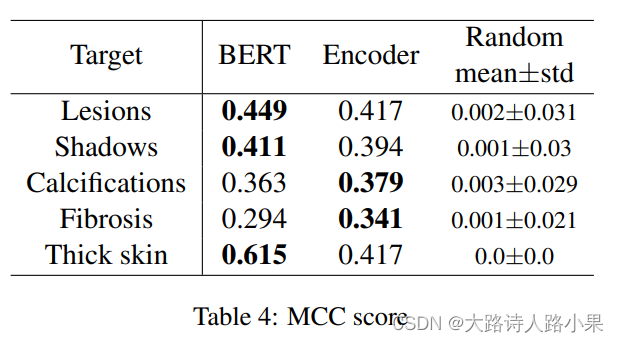
这里更甚使用了具体到病情的评估指标,这种好的思路真是太好了,太值得学习了
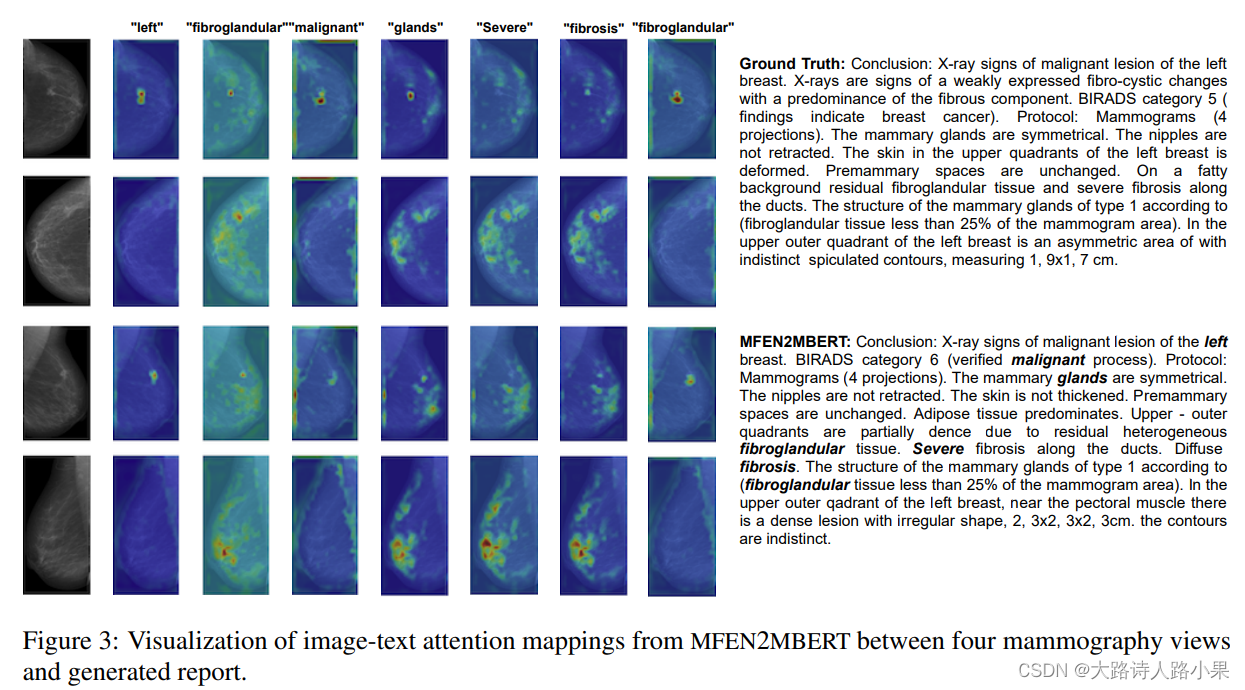
这样的展示图片真的太完美了,太值得学习了,俄罗斯的人工智能搞的是真好
模型的结构在(下)解析,这里跳到结论部分
In this paper we present a first-of-its-kind framework for generating mammography reports given four mammography views using deep-learning. Our model utilizes pretrained models including EfficientNet for visual extraction and BERT for report generation. We demostrate that the Transformerbased attention mechanism that simultaneously attends to four mammography views and text from the report significantly improves the performance. Our method provides a novel perspective for breast screening: generating mammography reports and providing image-text attention mappings, which makes the automatic breast screening process semantically and visually interpretable. The validity of our approach is confirmed by the corresponding doctor evaluation. In the conducted qualitative analysis we demonstrate that our best model successfully detects pathological regions, and describes abnormalities and parts of the breast.