目录
- 一.背景
- 二.技术目标
- 三.技术方案
- 3.1 整体流程
- 3.2 ES 切换前:完成整体新集群的搭建.
- i:拓扑结构设计
- ii: 如何选择整体的 **ES** 集群配置.
- 3.3 **ES** 版本切换中
- 3.3.1 多client版本兼容
- 3.3.2 Router的设计
- 3.4 ES 切换后
- 3.5 开箱即用
- 四.总结
专栏系列
-SaaS 电商设计 (一) 如何设计一套适应多规格的商品服务
-SaaS 电商设计 (二) 私有化部署-缓存中间件适配
-SaaS 电商设计 (三) 电商黄金流程(商详,购物车,提单)梳理,持续更新(建议收藏)
-SaaS 电商设计 (四) 谈一谈电商系统高并发多耦合上下游的系统压测怎么做
-SaaS 电商设计 (五) 私有化部署-实现 binlog 中间件适配(附源码)
-SaaS 电商设计 (六) 实现 id 生成器本地化生产 (附源码)
-SaaS 电商设计 (七) 利用 Spring 扩展点 ImportBeanDefinitionRegistrar 实现 toB 系统对接(附源码)
-SaaS 电商设计 (八) 直接就能用的一套电商商品池完整设计方案(建议收藏)
-SaaS 电商设计 (九) 动态化且易扩展的实现购物车底部弹层(附:一套普适的线上功能切量的发布方案)
一.背景
目前商品模块整体的商品数据存储频繁会使用到 Elasticsearch(以下简称 ES ) . 主要场景是一些复杂的 B 端查询以及一些非即时性的二方商品服务提供.
由于非技术原因,不得不从技术侧发起了一个 ES 迁移的技术性改造.具体的原因有以下几点:
- 原本的 ES 存储托管于云平台.由于资源到期(半年后)后续不再支持. 屋漏偏逢连夜雨,恰逢最近由于业务突增一些技术问题不得不进行技术支持,沟通尔尔,发现时下响应效率不高.最终也没有实质性解决业务问题.
- 现有的 ES 拓扑结构在目前的业务场景下难以更好的动态扩缩容.
基于以上的重重原故,计出无奈不得不进行 ES 内迁至内网.
以下为现有的拓扑结构.

每个节点的信息如下:
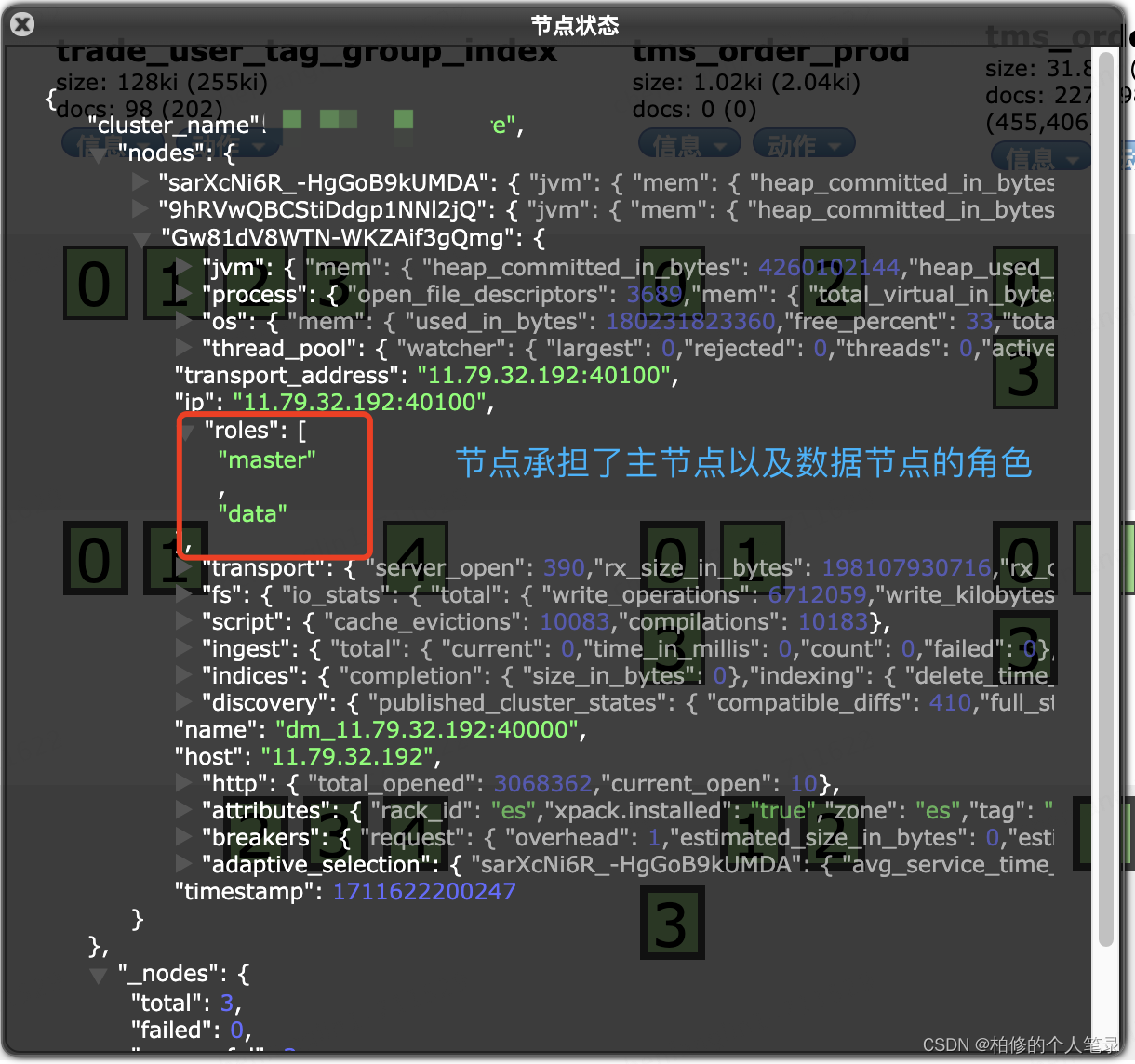
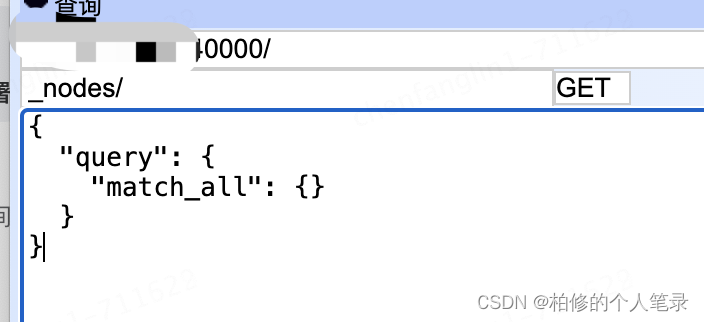
PS:如上的node信息可以通过 _nodes/ 得到.
从以上的节点拓扑以及系统查看可知,目前的 ES 4个节点均为主节点&数据节点.
目前的 Transport Client 形式的链接,如果需要水平扩容无法做到动态扩容,系统无感知,需要重新修改链接完成项目重启,对于分布式系统来说,在高峰时刻无疑是致命的.搞不好裁员广进的下一个就是我.
- 目前的链接方式存在一个跨网的网络链接.
目前是一个内部网络需要跨网去链接云端 ES ,中间不可避免涉及网络损耗.
基于以上的这三点,不得不发起一个 ES 集群迁移.
二.技术目标
-
Objectives: 完成 ES 集群迁移
-
Key Results
-
保证线上 租户150+ ,5000w+ 商品数据.平稳迁移.其中 重点 KA 客户数据 3000w 必须重点保证可用性;
-
迁移过程完成拓扑结构升级.保证后续的 ES 水平扩容能够对于服务透明;
-
迁移过程保证出现问题能够随时回切;
-
三.技术方案
3.1 整体流程
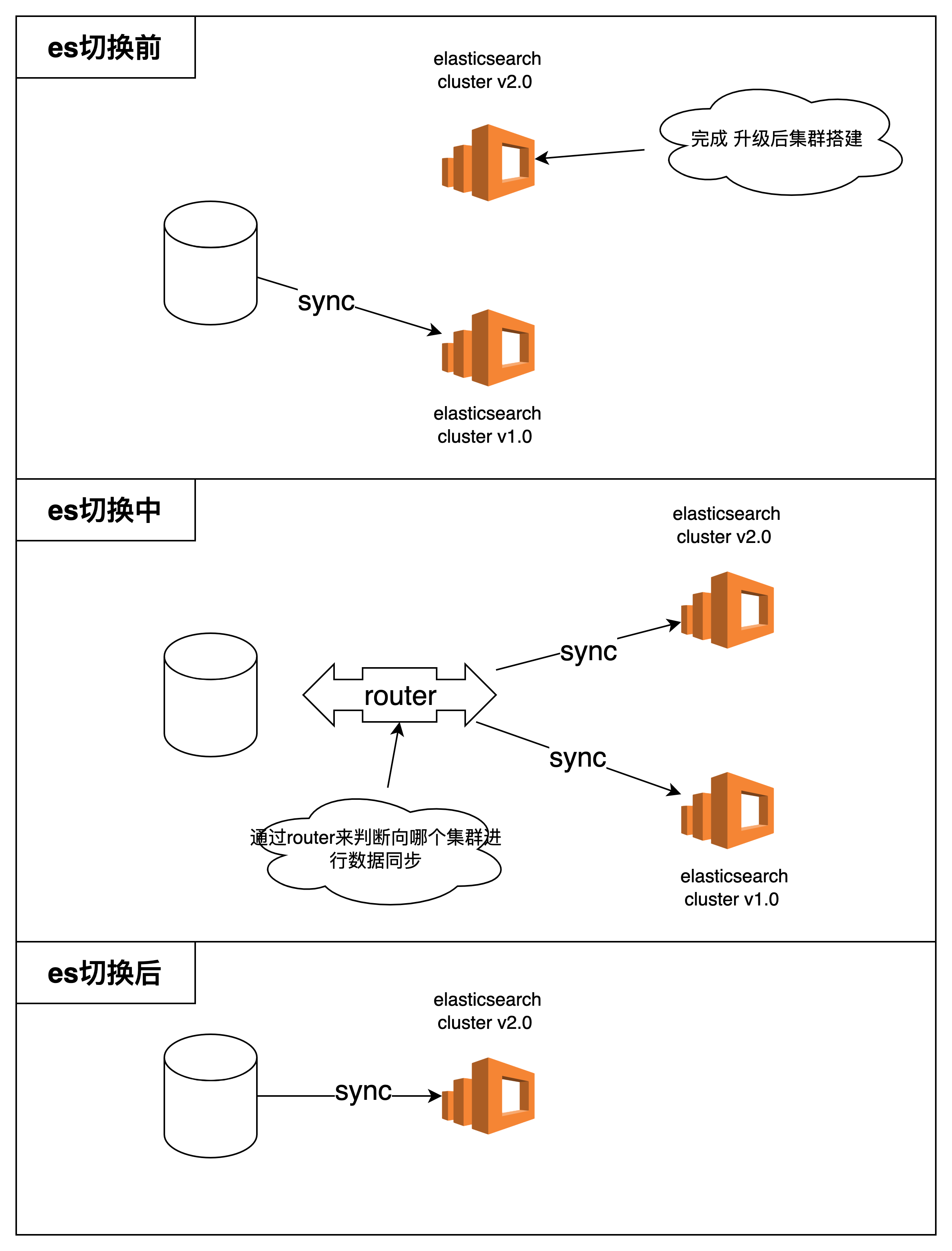
图中以数据同步流程为例.查询的流程类似.
3.2 ES 切换前:完成整体新集群的搭建.
i:拓扑结构设计
升级结构的必要性:
在整体的第一版过程中我们使用的是 5.4.3 版本.并采用的 TCP 节点直连的方式.用过的同学都知道.节点直连太坑了,连上了就别动.一旦集群发生节点变更.管你是水平还是集群重建都得动代码.生产环境哪里由得你乱动.就这样无法做到动态水平扩容后代码的无改动.
(使用 Http 方式链接可以或者增加协调节点后通过链接协调的节点的方式).且在整体的集群搭建中仅使用了数据节点.那么就不可避免出现现有的数据节点既承担数据存储,索引结构维护,归并排序等本不属于数据节点的角色内容.当然在数据量并不大的场景现有的拓扑结构是满足业务的.那随着业务的发展,势必是需要更新演进的.
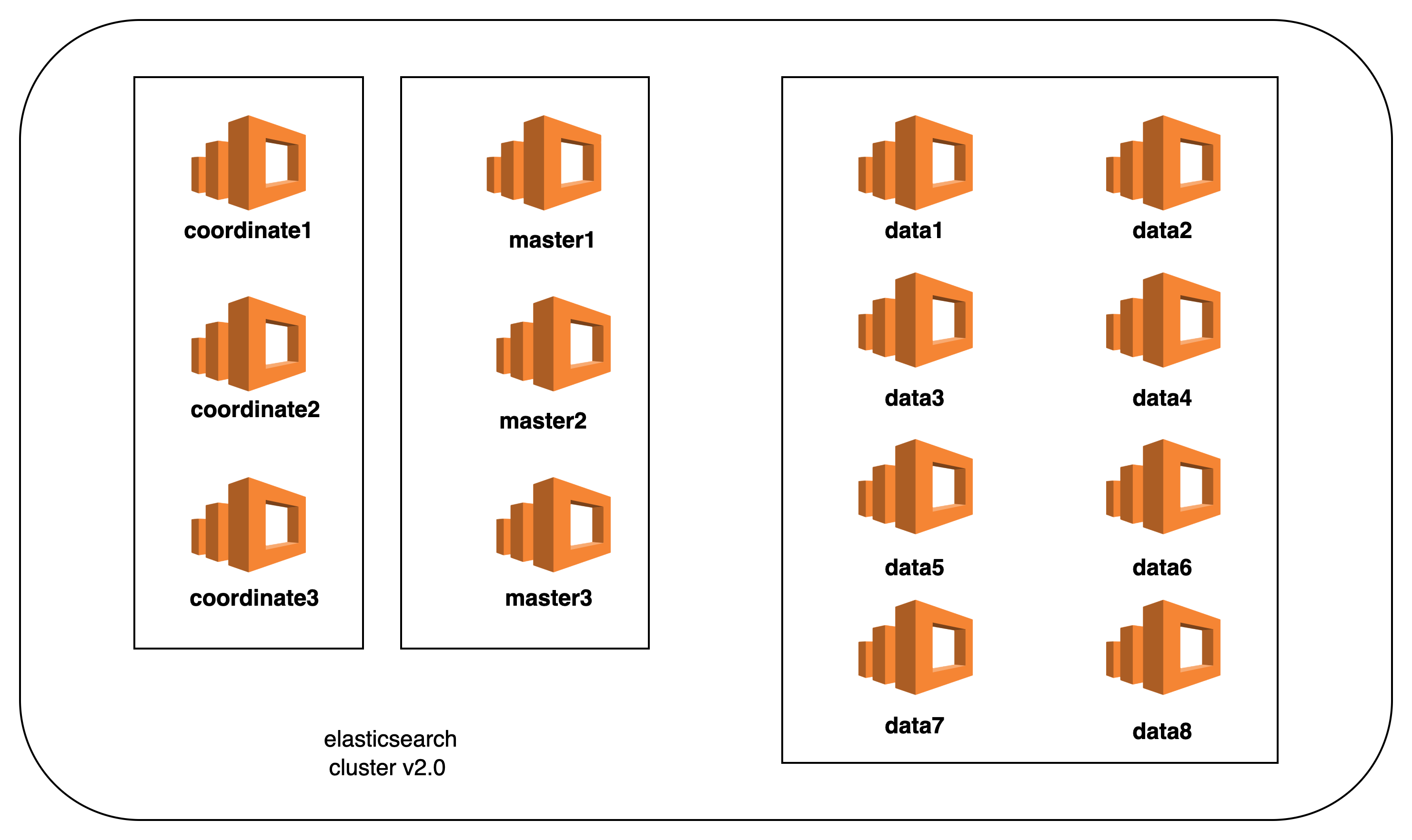
延伸一下:节点角色
- 协调节点:转发来自 ES client 的请求至各自的数据节点.数据节点本地查询符合条件的数据后返回给协调节点.协调节点通过本地归并排序分页等操作,返回最终符合条件的查询结果.通过以上描述可知,协调节点需要大量的 CPU ,以及内存资源去完成节点的工作.
通过下面的配置创建一个仅用于协调的节点:
node.master: false
node.data: false
node.ingest: false
- 主节点:维护集群内的索引增加,删除,更新,以及集群的管理工作.主节点是全局唯一的,一旦出现故障将从有资格成为 Master 的节点中进行选举.所以实际过程中配置为 Master 节点的数量一般建议为奇数个(但是集群中将只有一个生效),防止分布式常见的脑裂问题出现.
node.master: true
node.data: false
如上我们通过配置了数据节点以及主节点两个配置,将一个节点的角色同时设置为了主节点以及数据节点.那么在实际过程中面对数据量较多的场景,该节点就有可能因为角色的多种承受了不该承受的压力,进而导致集群的不稳定.所以这也是本次改造的一个原因之一.
- 数据节点:顾名思义就是单纯用以处理数据(存储,查询).所以数据节点就实际部署过程中对于内存以及 cpu 的要求都需要比较高.
如何配置一个ES数据节点:
node.master: false
node.data: true
node.ingest: false
ii: 如何选择整体的 ES 集群配置.
-
存储的配置
-
这里建议参考腾讯云官方的计算逻辑.虽然是腾讯云我觉得还是考虑的比较中肯.主要是以下几点:
- 副本的数量,相应的倍数即可.如:1个副本.那么单节点来说就是主(20g)+副(20g)=40g
- 原本宿主机的其他资源损耗5%.40+0.05*40=42g;
- es 内部任务开销的资源损耗20%.42+42*0.2=50.4g;
- es 本身的结构存储10%.50.4+50.4*0.1=55.8g.
https://cloud.tencent.com/document/product/845/19551
-
节点的选择
建议有一定查询的量级的场景.比如说千万级大概100T-200T的级别的查询都配置上协调节点.主节点.数据节点.保证各个节点都能够各司其职.而且也利于后期的垂直(单节点内存,cpu扩展),水平(新增同配置节点). -
分片的选择
- 首先主副分片的选择.一般场景下如果对于主副没有特别要求的情况是 1:1 的处理就好了. 虽然之前查阅腾讯的官方文档表明无单点故障考虑可以不用增加副本. 我想说的是都是生产环境多少还是要考虑的,除非你真的是在搞一个玩具.
- 建议分片大小.这里其实是有一些约定俗成的逻辑.一般大小 10g-50g .避免出现大的分片,以至于故障发生时影响集群的稳定性.另外在重新 rebalance 时也难以在节点之间移动.具体参考官方的文档:
https://www.elastic.co/guide/en/elasticsearch/reference/7.9/size-your-shards.html#shard-size-recommendation
我是怎么配置的?
主节点3个:4C16G100GB
网关节点3个:4C16G100GB
数据节点8个:8C16G500GB
3.3 ES 版本切换中
3.3.1 多client版本兼容
通过在业务代码中插入自定义 Router . Router 其实就是本次在整体ES 迁移过程中比较核心的内容.主要核心职责就是为了完成在流量进入的过程中(写入,读取)的版本 ES client 获取.下面通过图示来放大 ES Router 的核心设计内容.
首先是整体 spring 容器对于 client 的兼容处理.尝试了几个版本之后最后使用的 maven 是.
也就是如下版本才能完成 两种不同 TCP 版本 ES client 的同时链接(这一次选择了先不更改 ES client 的链接方式不然更改为 Rest sdk 工作量可能兜不住)
<dependency>
<groupId>org.elasticsearch.client</groupId>
<artifactId>transport</artifactId>
<version>5.6.10</version>
</dependency>
<dependency>
<groupId>org.elasticsearch</groupId>
<artifactId>elasticsearch</artifactId>
<version>5.6.10</version>
</dependency>
<dependency>
<groupId>org.elasticsearch.plugin</groupId>
<artifactId>transport-netty4-client</artifactId>
<version>5.6.10</version>
</dependency>
<!-- ES集群5.x -->
<bean name="esFiveClient" class="com.xxx.xxx.ElasticsearchTemplate" init-method="init">
<property name="clusterNodes" value="${es.clusterNodes.own}"/>
<property name="clusterName" value="${es.clusterName.own}"/>
<property name="clientTransportSniff" value="false"/>
<property name="username" value="${es.cluster.username}" />
<property name="password" value="${es.cluster.password}" />
</bean>
<!-- 新集群 -->
<!-- ES集群6.x -->
<bean name="esSixClient" class="com.xxx.xxx.ESForSixTemplate" init-method="init">
<property name="clusterNodes" value="${es6.clusterNodes.own}"/>
<property name="clusterName" value="${es6.clusterName.own}"/>
<property name="clientTransportSniff" value="false"/>
<property name="username" value="${es6.cluster.username}" />
<property name="password" value="${es6.cluster.password}" />
</bean>
<!-- 门店商品 -->
<!-- 门店商索引 同时注入两个版本client -->
<bean id="storeSkuInfoIndexBeanService" class="com.xxx.xxx.StoreSkuInfoIndexServiceImpl">
<property name="index" value="${es6.storeSku}"/>
<property name="type" value="${es6.storeSku}"/>
<property name="elasticsearchTemplate" ref="esFiveClient"/>
<property name="esTemplate" ref="esSixClient"/>
</bean>
....
/**
* 通过配置内容判定是否读取新版 6.0 client 还是 5.0 client
*
*/
private SearchRequestBuilder getSearchRequestBuilderBySwitch(Boolean isGoToJes) {
Client client = isGoToJes ? esSixClient.getClient() : esFiveClient.getClient();
String indexReal = isGoToJes ? indexForSix : index;
String typeReal = isGoToJes ? typeForSix : type;
return client.prepareSearch(indexReal).setTypes(typeReal);
}
....
在完成maven的适配之后我们就可以完成 spring 容器的两个 client 注入了.其实到了这一步算是其中一个非常关键的技术点被解决了.因为只要拿到了 client 后续相当于无论我们是用什么手段去实施切量就比较好做了,尽可能是去做到稳定性和可回滚.
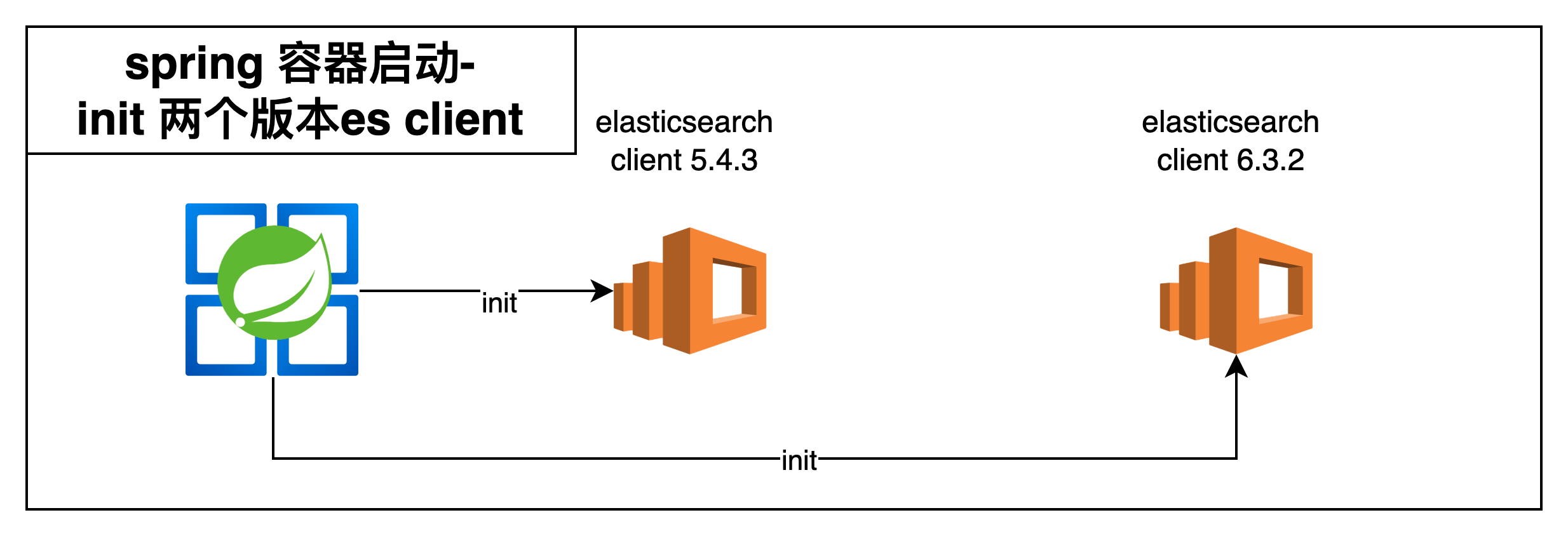
具体调用的链路以及实施切量的过程.
3.3.2 Router的设计
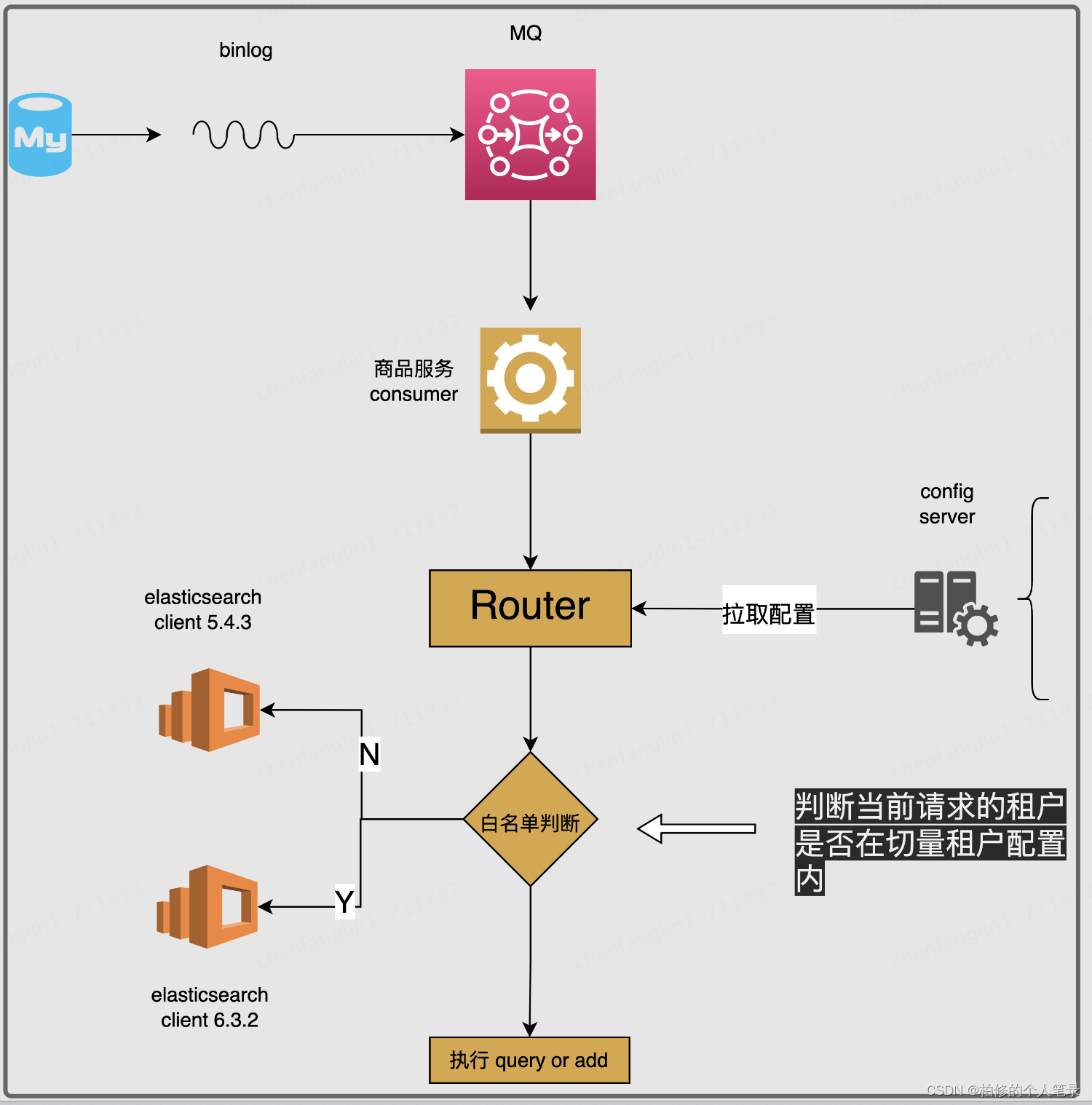
核心的思路是通过线上configServer配置来完成租户白名单控制,如果在白名单内我们将通过切到 es 6.0 client 来实现新集群切量.这样一来就能够做到线上的无缝切量以及即时的回退.
白名单配置
{
"2": "ALL_STORE_ID",
"100001601": "10005201",
"100005405": "ALL_STORE_ID",
"100008006": "ALL_STORE_ID",
"100008007": "10023233,10023835"
}
key:为具体租户Id.
value:ALL_STORE_ID :表达则是全部门店进行切换.
具体的门店值,则是表达指定租户指定门店完成切换.
具体灰度切量过程.
第一阶段:完成数据量在10w下租户的切量.
第二阶段:完成数据量在100w下租户的切量.
第三阶段:完成数据量在1000w下租户切量.
第四阶段:完成重点客户切量.
最终我们大概是花了三个月的时间完成了整体的切量.
3.4 ES 切换后
- 持续的流量监控
其实并不仅仅是 中间件切换 ,包括代码下线,老开关的移除.都需要一定的监控数据观测.在一定时间段后从监控的数据上能够确认流量的关闭.那么才能够继续往下继续后续的代码动作.
一般具体的方式就是在代码中插入指定的观测入口.比如上报流量监控的key,通过流量观测平台来完成日常的监控.比如3个月(具体的业务场景请参考具体的指标和时间跨度)后仍然没有流量.那么确认切换完成.
- 流量监控之后的代码移除以及资源的销毁
从资源和成本的角度,特别是时下降本增效的背景.有能力的前提下肯定是资源和成本能够进一步收缩是为更好.
3.5 开箱即用
老规矩:
https://github.com/Baixiu-code/elasticsearch-util-starter 一键直达
四.总结
行文总结了一次线上的由技术侧发起的一起 ES 集群数据迁移过程.从集群搭建到线上灰度以及灰度切换之后的资源释放的这样一个完整技术方案上线的闭环过程.欢迎大家一起讨论交流. 最后也放上了一个比较传统可能大家仍在使用的 Transport client 使用 api 封装.持续更新中.后续将更新 Restful ,欢迎大家的关注,交流.
赠人玫瑰 手有余香 我是柏修 一名持续更新的晚熟程序员
期待您的点赞,关注加收藏,加个关注不迷路,感谢
您的鼓励是我更新的最大动力
↓↓↓↓↓↓










![[图像处理] MFC载入图片并进行二值化处理和灰度处理及其效果显示](https://img-blog.csdnimg.cn/direct/135855f7a092446aa92442e9a47ab6e2.png)