编码和字符操作

.你觉得,迷茫的反义词是什么?有些人可能会说是坚定,但还有另一种说法:迷茫的反义词是具体。当你从一件件具体的事开始着手,焦虑就会一点点退去。——《夜读》
编码操作
UTF8编码
当谈到字符编码时,UTF-8(Unicode Transformation Format - 8-bit)是最为常见和广泛使用的字符编码之一。它是一种针对Unicode字符集的可变长度字符编码,可以表示几乎所有的Unicode字符。
以下是关于UTF-8的介绍:
-
可变长度编码: UTF-8 是一种可变长度编码,它使用不同长度的字节序列来表示不同范围的Unicode字符。单字节编码ASCII字符(0-127范围内),而多字节编码其他Unicode字符。
-
向后兼容性: UTF-8 对ASCII字符是向后兼容的,即ASCII字符在UTF-8编码中的表示与标准ASCII编码完全相同。这意味着使用UTF-8编码时,如果文本仅包含ASCII字符,它将与传统的ASCII文本兼容。
-
广泛支持: UTF-8由于其广泛的支持和适应性而成为互联网上的事实标准。它被用于HTML、XML、JSON等网络数据格式中,并且几乎所有的现代编程语言和操作系统都提供了对UTF-8的支持。
-
国际化支持: UTF-8可以表示几乎所有的Unicode字符,包括世界上几乎所有的语言的字符集。这使得它成为处理国际化文本和多语言应用程序的理想选择。
-
字节顺序无关: UTF-8编码不依赖于字节顺序(大端序或小端序),因此可以在不同的平台上进行交换并保持数据的完整性。
总之,UTF-8是一种灵活、高效且广泛支持的字符编码,适用于处理各种语言和国际化文本数据。在编写现代软件和开发Web应用程序时,使用UTF-8已成为一种标准做法。
# 字符串
text = "你好,世界!"
# 编码成 UTF-8
encoded_text = text.encode("utf-8")
print("UTF-8 编码后的数据:", encoded_text)
# 解码回原始字符串
decoded_text = encoded_text.decode("utf-8")
print("UTF-8 解码后的字符串:", decoded_text)
UTF-8 编码后的数据: b'\xe4\xbd\xa0\xe5\xa5\xbd\xef\xbc\x8c\xe4\xb8\x96\xe7\x95\x8c\xef\xbc\x81'
UTF-8 解码后的字符串: 你好,世界!
GBK编码
GBK(Guo Biao Kuò Zhàn)是汉字内码扩展规范的缩写,是中国国家标准GB 2312-1980的扩展。GB 2312-1980是中国国家标准化委员会于1980年发布的一种用于简体中文的字符集编码标准,其中包含了6763个常用汉字和682个其他符号、标点等字符。GBK编码在GB 2312-1980的基础上对其中的汉字部分进行了扩展,添加了包括繁体中文、日文、韩文等在内的更多汉字,共收录了21003个中文汉字和图形字符。GBK编码采用双字节编码方案,每个汉字用两个字节表示,每个字符都能被唯一地表示。
GBK编码的主要特点包括:
- 支持更多的汉字字符:相比于GB 2312-1980,GBK编码扩展了更多的汉字字符,使得其适用范围更广泛。
- 向下兼容GB 2312-1980:GBK编码保留了GB 2312-1980的编码方案,因此可以兼容GB 2312-1980编码的文件和系统。
- 支持多种语言:除了汉字字符外,GBK编码还包含了繁体中文、日文、韩文等字符,从而支持更多语言的编码需求。
尽管GBK编码在中国大陆和台湾地区广泛使用,但在国际范围内并不常见。随着Unicode的普及,现代的应用程序更倾向于使用Unicode字符集,因为Unicode可以统一表示世界上几乎所有的字符。
# 字符串
text = "你好,世界!"
# 编码成 GBK
encoded_text = text.encode("gbk")
print("GBK 编码后的数据:", encoded_text)
# 解码回原始字符串
decoded_text = encoded_text.d("gbk")
print("GBK 解码后的字符串:", decoded_text)
GBK 编码后的数据: b'\xc4\xe3\xba\xc3\xa3\xac\xca\xc0\xbd\xe7\xa3\xa1'
GBK 解码后的字符串: 你好,世界!
ASCII编码
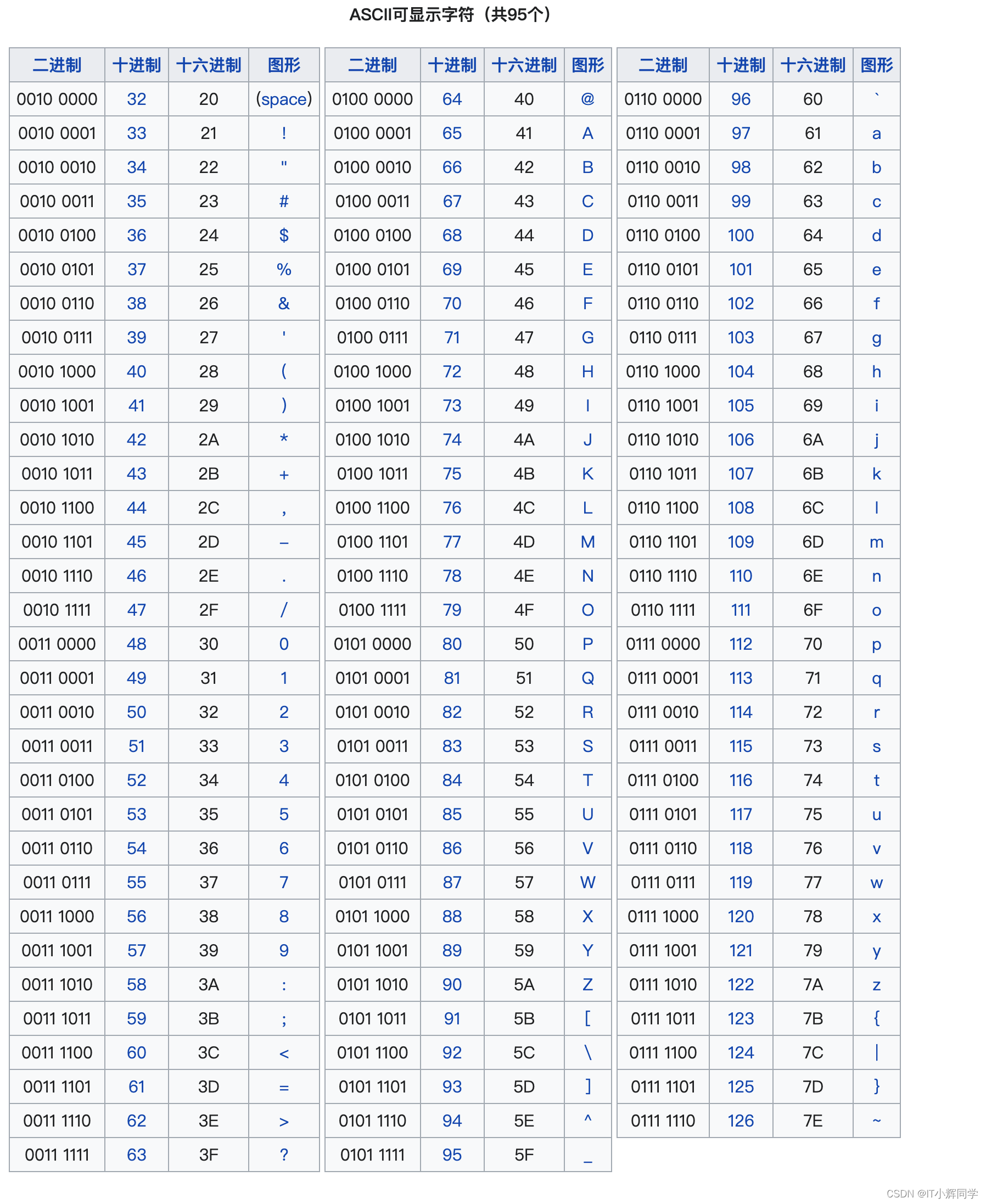
ASCII(American Standard Code for Information Interchange)是一种用于计算机与通信设备之间交换信息的字符编码标准。它使用7位二进制数字表示128个字符,包括基本的拉丁字母、数字、标点符号和控制字符。
ASCII码最初于1963年由美国国家标准协会(ANSI)制定,后来在1967年进行了修订。ASCII标准规定了每个字符在计算机内部的二进制表示方式,以及相应的十进制和十六进制表示。其中,基本的可打印字符占据了0到127的范围,其中包括了数字、大写和小写拉丁字母、标点符号等;剩余的一些字符则被用于控制通信设备,比如换行、回车等。
ASCII码的特点包括:
- 简洁明了:ASCII码只使用7位二进制数,每个字符用一个字节表示,使得它在计算机内部的处理非常高效。
- 兼容性强:由于ASCII码是一个标准,因此几乎所有的计算机和通信设备都能够支持它,这使得ASCII码成为了通信和数据交换中的基本标准。
- 适用范围广泛:ASCII码最初是为了英语而设计的,但它的应用已经扩展到了其他许多语言,虽然对于一些非拉丁字母的语言来说,ASCII并不是最佳的选择。
虽然ASCII码在许多方面具有优势,但由于其仅包含128个字符,无法涵盖所有的语言和符号。为了解决这个问题,后来出现了扩展的字符编码标准,如ISO-8859和Unicode。
# 将字符转换为ASCII码值
char = 'A'
ascii_value = ord(char)
print(f"字符 '{char}' 的ASCII码值为: {ascii_value}")
# 将ASCII码值转换为字符
ascii_value = 65
char = chr(ascii_value)
print(f"ASCII码值 {ascii_value} 对应的字符为: '{char}'")
字符 'A' 的ASCII码值为: 65
ASCII码值 65 对应的字符为: 'A'
字符操作
字符串定义
string = "Hello, World!"
转义符
Python中的转义字符是一种特殊的字符序列,用于表示无法直接键入或打印的字符,比如换行符、制表符等。以下是Python中常用的转义字符及其含义:
\n:换行符。将当前位置移到下一行开头。\t:制表符。将当前位置移到下一个制表符位置。\\:反斜杠。用于表示单个反斜杠字符。\':单引号。用于表示单引号字符。\":双引号。用于表示双引号字符。\b:退格符。将当前位置移到前一列。\r:回车符。将当前位置移到本行开头。\f:换页符。将当前位置移到下页开头。
print("Hello\nWorld")
Hello
World
print("Hello\tWorld")
Hello World
print("This is a single quote: \'")
This is a single quote: '
print("This is a double quote: \"")
This is a double quote: "
print("This is a backslash: \\")
This is a backslash: \
print("Hello\bWorld")
HellWorld
print("Hello\rWorld")
World
print("Hello\fWorld")
HelloWorld
字符串长度
print("字符串:", string)
print("字符串长度:", len(string))
字符串: Hello, World!
字符串长度: 13
切片操作
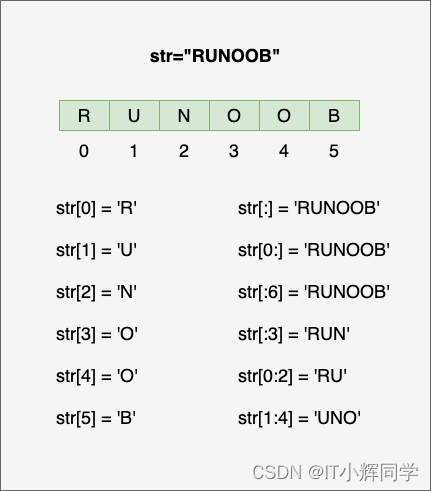
print("原始字符串:", string)
print("第一个字符:", string[0])
print("最后一个字符:", string[-1])
print("第2到第5个字符:", string[1:5])
print("从第7个字符到最后一个字符:", string[6:])
原始字符串: Hello, World!
第一个字符: H
最后一个字符: !
第2到第5个字符: ello
从第7个字符到最后一个字符: World!
连接字符串
string2 = "Welcome"
print("字符串1:", string)
print("字符串2:", string2)
concatenated_string = string + " " + string2
print("连接后的字符串:", concatenated_string)
连接字符串:
字符串1: Hello, World!
字符串2: Welcome
连接后的字符串: Hello, World! Welcome
替换操作
replaced_string = string.replace("World", "Python")
print("原始字符串:", string)
print("替换后的字符串:", replaced_string)
原始字符串: Hello, World!
替换后的字符串: Hello, Python!
分割操作
split_string = string.split(",")
print("原始字符串:", string)
print("分割后的字符串列表:", split_string)
原始字符串: Hello, World!
分割后的字符串列表: ['Hello', ' World!']
进阶练习
练习一
我喜欢吃苹果。我还喜欢香蕉。我数学考了一百分。老师给我奖励了一个大红花。
将该段文字中所有我转换为自己的名字,并且输出打印
page="我喜欢吃苹果。我还喜欢香蕉。我数学考了一百分。老师给我奖励了一个大红花。"
page.replace("我","王辉")
'王辉喜欢吃苹果。王辉还喜欢香蕉。王辉数学考了一百分。老师给王辉奖励了一个大红花。'
练习二
我喜欢吃苹果。我还喜欢香蕉。我数学考了一百分。老师给我奖励了一个大红花。
将所有的"我"替换为"王辉",并且一句换一行,句号结尾
# 原始字符串
original_text = "我喜欢吃苹果。我还喜欢香蕉。我数学考了一百分。老师给我奖励了一个大红花。"
replaced_text = original_text.replace("我", "王辉").replace("。", "。\n")
# 输出替换后的结果
print(replaced_text)
王辉喜欢吃苹果。
王辉还喜欢香蕉。
王辉数学考了一百分。
老师给王辉奖励了一个大红花。
练习三
我喜欢吃苹果。我还喜欢香蕉。我数学考了一百分。老师给我奖励了一个大红花。
将所有的"我"替换为"王辉",并且一句换一行,句号结尾,并且计算每一句话的长度
# 原始字符串
original_text = "我喜欢吃苹果。我还喜欢香蕉。我数学考了一百分。老师给我奖励了一个大红花。"
replaced_text = original_text.replace("我", "王辉").replace("。", "。\n")
# 输出替换后的结果
print(replaced_text)
# 分割文本为句子列表
sentences = replaced_text.split("\n")
# 输出每句的长度
for sentence in sentences:
print(f"句子 '{sentence}' 的长度为: {len(sentence)}")
王辉喜欢吃苹果。
王辉还喜欢香蕉。
王辉数学考了一百分。
老师给王辉奖励了一个大红花。
句子 '王辉喜欢吃苹果。' 的长度为: 8
句子 '王辉还喜欢香蕉。' 的长度为: 8
句子 '王辉数学考了一百分。' 的长度为: 10
句子 '老师给王辉奖励了一个大红花。' 的长度为: 14
句子 '' 的长度为: 0