生成式 AI 为企业带来了更多的机会,可以构建需要搜索和比较非结构化数据类型(例如文本、图像和视频等)的应用程序。通过 嵌入体 或 向量,以机器可读的格式捕获这些非结构化数据的含义和上下文,然后基于这种方法,可以在 Amazon Aurora PostgreSQL 兼容版本中使用 pgvector 来直接进行相似度比较:
https://www.youtube.com/watch?v=e9SHaO9RNzk&ab_channel=AWSDevelopers
pgvector 还增添了额外的功能,能够高效存储和快速检索以高维向量形式存储的数据。
一些应用场景,例如搜索电子商务产品目录或检索增强生成(RAG,Retrieval Augmented Generation),需要实时进行高性能的向量比较。这些应用场景需要存储数百万乃至数十亿个向量嵌入体,然后用于进行比较。此外,由于具有数百个维度的向量会非常大,因此内存中无法容纳整个向量索引,应用程序需要改为从磁盘进行读取。例如,Amazon Titan Embeddings G1 – 文本嵌入模型可以生成包含 1,536 个维度的嵌入体。如果这些嵌入体未缓存在内存中,那么在将它们移入和移出内存以进行相似度搜索时,会极大地影响性能。
Amazon Aurora 优化型读取是一项新的 Amazon Aurora 功能,有助于提升向量工作负载的性能,而且对于使用大型数据集的应用程序,当数据集超过了数据库实例的内存容量时,可以减少应用程序的资源使用。将 Amazon Aurora 优化型读取与 pgvector 分层可导航小世界(HNSW,Hierarchical Navigable Small World)索引结合使用,相较于 pgvector 倒排文件平面(IVFFlat,Inverted File Flat)索引,可以将查询性能提升 20 倍,让应用程序能够提供低延迟的响应。
在这篇文章中,我们将讨论如何通过优化型读取,提高在使用 pgvector 的 Amazon Aurora PostgreSQL 上运行的向量工作负载的性能。需要特别说明的是,这一方法使用了 HNSW 索引。使用 HNSW 索引的优化型读取实例,可以将平均查询吞吐量性能提高多达九倍,与没有使用优化型读取的 Aurora PostgreSQL 实例相比,这相当于将每次查询的成本减少了 75-80%。
Aurora 优化型读取
如何让向量工作负载获益
使用向量进行搜索时,最常用的技术称为 相似度搜索 或 最近邻,这种技术会通过计算向量彼此之间的距离来比较向量。相似度搜索分为不同的类型,包括搜索整个数据集的 k 最近邻(KNN,k-Nearest Neighbor),以及搜索子集的近似最近邻(ANN,Approximate Nearest Neighbor)。每种方法都存在取舍:KNN 返回最相关的结果,但是 ANN 搜索的性能通常更高。
嵌入模型生成的向量会占用大量内存。例如,Amazon Titan Embeddings G1 – 文本嵌入模型可生成包含 1536 个维度的嵌入体,约为 6 KiB 的数据。对 10 亿个这样的向量执行 KNN 时,需要在内存中移动 5.7 TiB 的数据才能完成操作。将诸如 Aurora PostgreSQL 这样的数据库与 pgvector 结合使用,提供了一种可靠、耐用的解决方案,在需要比较时将向量加载到内存中。但这确实造成了一些取舍,因为对于 KNN 和 ANN 搜索而言,将向量保存在内存中,通常比从网络端存储系统读取向量的性能更高。在评估如何查询数据库中的向量时,您必须考虑在使用具有更多内存的较大型实例时,所能获得的成本、性能和可扩展性。
Aurora 优化型读取为管理具有大型数据集的工作负载,提供了一种经济高效的高性能解决方案。优化型读取使用 r6gd 和 r6id 实例上提供的基于 NVMe 的本地 SSD 块级存储,来存储临时数据。这可减少对网络端存储的数据访问,从而改善读取延迟并提高吞吐量。还有一项功能可以为向量工作负载带来益处,这就是在分页(分页是 PostgreSQL 的基本存储单元)被逐出内存之后,会缓存在本地存储中。当查询操作访问逐出的分页时,Aurora 会从 NVMe 加载数据,而不必从存储中检索数据,从而缩短了查询延迟。优化型读取将临时表存储在本地 NVMe 上,为复杂查询提供了更好的查询性能,并可实现更快的索引重建操作。通过 Aurora 优化型读取的分层缓存功能,您能够利用向量工作负载的性能优势,此项功能只能在支持 Aurora I/O 优化版的实例上使用。
相比没有优化型读取的实例,优化型读取可以将查询延迟缩短 9 倍。对于使用超出数据库实例内存容量的大型数据集的应用程序,这可以带来性能效益,让您可以在相同的实例大小上进一步扩展工作负载。通过这种方法,数据库在使用 Aurora PostgreSQL 和 pgvector 访问向量数据时,可以获得接近内存的速度,而无需升级到更大的实例大小。以下部分演示了一项实验,重点介绍对十亿级向量工作负载采用优化型读取所能实现的益处。
Aurora 优化型读取的
性能优势基准测试
为了确定 Aurora 优化型读取可以为向量工作负载带来哪些益处,我们使用 pgvector 对存储在 Aurora 中的向量进行基准测试,测量了使用和不使用优化型读取的实例的性能。我们使用 BIGANN Benchmark(10 亿个向量)基准测试工具的修改版本,利用该工具,我们可对加载到 Aurora 的向量数据集并行运行相似度搜索。此基准测试使用 BIGANN-1B 数据集执行,其中包含尺度不变特征转换(SIFT, Scale-Invariant Feature Transform)描述符,这些描述符应用到从大型图像数据集提取的图像。基准测试中使用 128 个维度。为了确定基准查询的准确率(以查全率来衡量),我们使用了可用于 BIGANN-1B 数据集的真实情况文件。
我们使用这项基准测试,比较在使用和不使用优化型读取时 Aurora PostgreSQL 的性能。本次测试中,评估 Aurora 和 pgvector 的性能需要重点关注两个特性:
性能和吞吐量 – 数据库每秒可以运行多少次查询?
查全率 – 查询结果的质量如何?
这两个特性必须同时评估。性能是一个标准测量值,在本测试中以每秒查询数来计算。查全率是查询返回相关结果的百分比。通常,ANN 算法会提供参数,用于管理查全率与查询吞吐量之间的取舍。对于 HNSW 索引类型(自 pgvector 版本 0.5.0 开始支持),您可以使用 hnsw.ef_search 参数作为一种管理搜索质量的方法。此参数定义了在遍历相邻节点期间,要访问的候选节点队列的大小。
基准测试设置:pgvector 版本 = 0.5.0; ef_search=400 ,这是候选节点队列大小,可以实现 0.9578 的查全率。索引在构建时使用了 HNSW 算法,构建参数: m=16 ,这是在构造期间为每个新元素创建的双向链接数量; ef_construction=64 ,此参数控制 index_time/index_accuracy 。如前所述,我们修改了 BIGANN 基准测试,使用多个线程来运行并行查询。
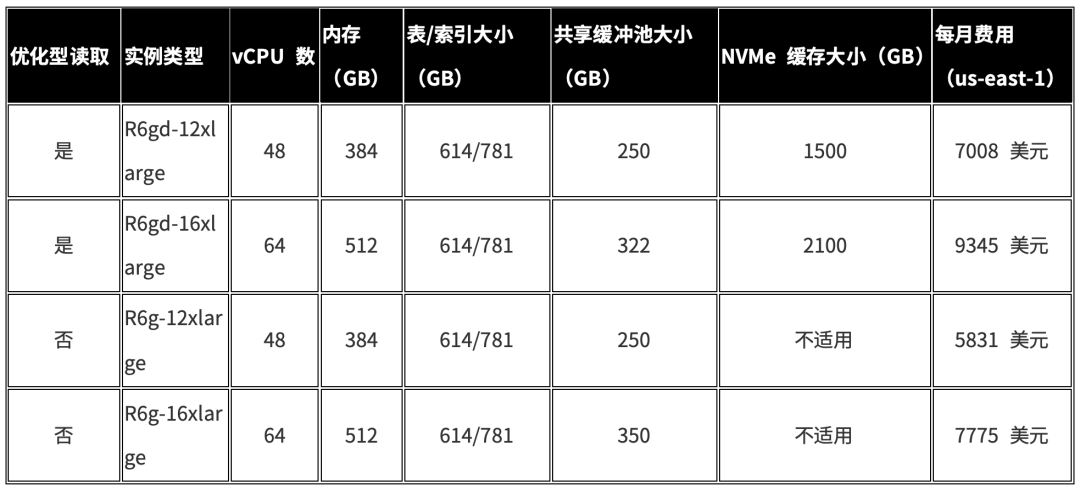
我们在两种不同的实例大小上进行了测试,这两种实例大小是专门选择的,目的是让内存无法容纳工作负载,这意味着 Aurora 必须从存储中读取数据。测试中使用了以下实例:R6gd-12xlarge(R6gd-12xl)和 R6gd-16xlarge(R6gd-16xl)实例,这两种实例均使用优化型读取;以及 R6g-12xl 和 R6g-16xl 实例,这两种实例均为基准实例,不使用优化型读取。16xl 实例上的表和索引大小为 781 GB。12xl 实例上的表和索引大小为 614 GB。
实例详细信息
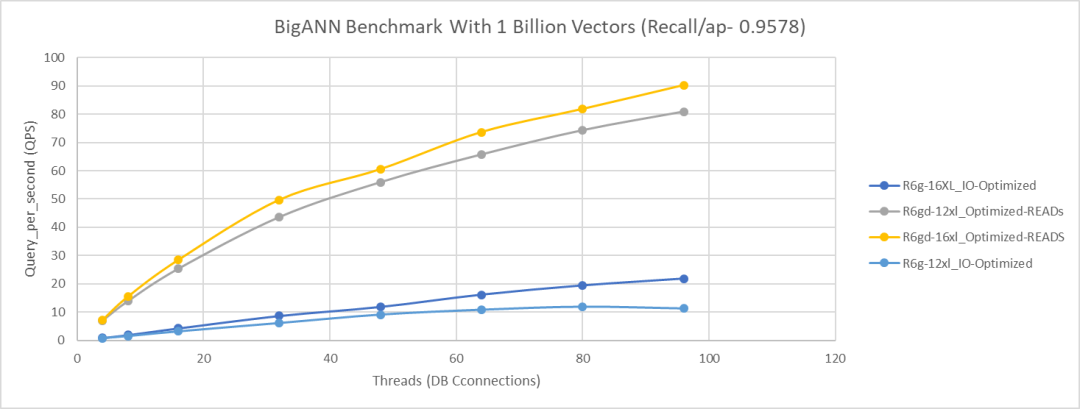
下图显示了以每秒查询数(QPS,Queries Per Second)为单位测量的吞吐量,这是在查全率为 0.9578 时,对 BIGANN 数据集的查询工作负载随同步线程数的增长。我们可以观察到,相比 R6g 实例,优化型读取 R6gd 12xl 和 16xl 实例能够处理更多的向量查询,这种查询依赖于磁盘 I/O 来搜索向量。请注意,在下图中,所有四个实例均配置为 Aurora I/O 优化版(https://aws.amazon.com/about-aws/whats-new/2023/05/amazon-aurora-i-o-optimized/)
下表显示,相比没有优化型读取(分层缓存功能)的基准 Aurora 实例,具备优化型读取的 R6gd-12xl 和 R6gd-16xl 实例的查询吞吐量平均高出 6 到 7 倍(范围在 4.1 到 9.3 之间)。优化型读取实例消除了向量搜索中的磁盘 I/O 瓶颈,使得基准测试中 R6gd-12xl 实例上的 CPU 利用率高达 95%。使用标准实例,CPU 利用率从未超过 15%,因为存储 I/O 是性能瓶颈。此外,随着并发度的增加,我们观察到优化型读取实例展现出更多的性能优势,这是因为随着工作负载的增加,分页逐出的频率也随之增加。优化型读取实例带来的吞吐量性能提升,可以降低每月的查询平均成本,仅相当于没有优化型读取的实例的 20-25%。
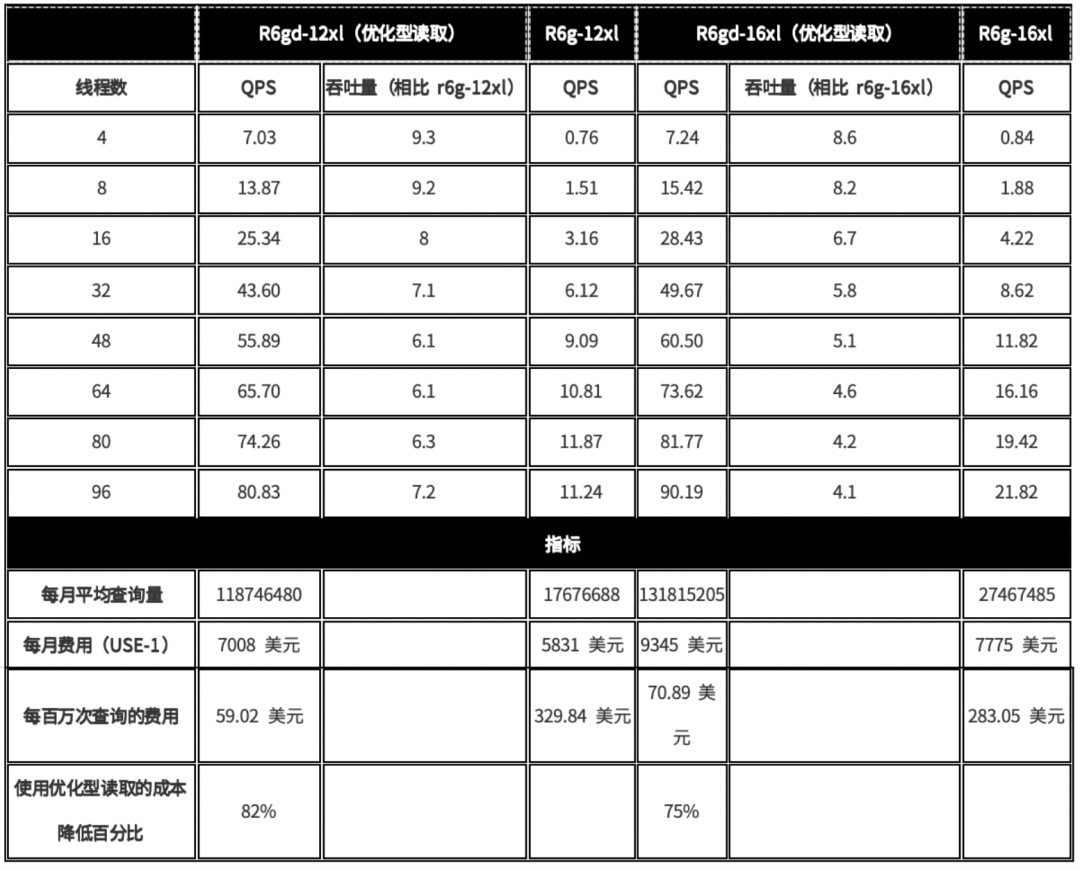
在本实验中,我们可以看到,与没有优化型读取的实例相比,优化型读取实例具有更高的性能,性价比更好。虽然这只是实验,但可以看到,当向量工作负载超出可用的实例内存大小时,优化型读取可以带来性能益处,因为本地 NVMe 缓存减少了从存储中提取数据的需求。并非所有向量工作负载都能从优化型读取获得益处。本地 NVMe 仅缓存未经修改的被逐出分页,因此,如果您的向量数据经常更新,则可能不会实现同样的提速。此外,如果您的向量工作负载可以完全装入内存中,则可能不需要优化型读取实例,不过运行这样的实例,有助于您的工作负载在相同的实例大小上继续扩展。
结论
开发人员可以使用 SQL 和 pgvector,对 Aurora PostgreSQL 数据库中的图像和文本执行向量相似度搜索,从而构建创新的生成式 AI 应用程序,以及使用新的或专有数据(RAG)来增强基础模型。亚马逊云科技将 Amazon Bedrock 的知识库与 Aurora 相集成,实现了 RAG 流程的自动化,您可以阅读 Build generative AI applications with Amazon Aurora and Knowledge Bases for Amazon Bedrock(使用 Amazon Aurora 和 Amazon Bedrock 的知识库来构建生成式 AI 应用程序)来了解更多信息:
https://aws.amazon.com/blogs/database/build-generative-ai-applications-with-amazon-aurora-and-knowledge-bases-for-amazon-bedrock/
Aurora 优化型读取提供了一种高性能、经济实惠的选项,与 IVFFlat 索引相比,pgvector HNSW 索引将每秒查询数提高了 20 倍。使用 BIGANN-1B 基准测试,我们发现,采用 HNSW 索引的 Aurora 优化型读取,相比同等实例类型,可以将性能提升高达 9 倍,而每次查询的成本比标准实例低 75-80%。
对于大小超过实例内存的向量工作负载,Aurora 优化型读取提供了一种高性能、经济实惠的选项,与 IVFFlat 相比,pgvector HNSW 索引的每秒查询数可提升达 20 倍,同时每次查询的成本比标准实例低 75-80%。有关如何开始使用优化型读取的更多信息,请参阅使用 Aurora 优化型读取功能提高 Aurora PostgreSQL 的查询性能:
https://docs.aws.amazon.com/AmazonRDS/latest/AuroraUserGuide/AuroraPostgreSQL.optimized.reads.html
点击阅读原文查看博客,获得更详细内容!
本篇作者

Steve Dille
亚马逊云科技高级产品经理,负责亚马逊云科技在 Aurora 数据库方面的全部生成式 AI 战略和产品计划。

Mark Greenhalgh
亚马逊云科技高级数据库工程师,拥有 20 多年的设计、开发和优化高性能数据库系统经验。他专长于分析数据库基准数据和指标,来提高性能和可扩展性。

Sunil Kamath
亚马逊云科技 Aurora 数据库性能和 PostgreSQL 引擎开发工程主管。他的团队推动了 Amazon Aurora 数据库的性能和可扩展性进步,以及 Aurora PostgreSQL 的无服务器和引擎功能。

Jonathan Katz
亚马逊云科技 Amazon RDS 团队的首席产品技术经理,常驻纽约。他是开源 PostgreSQL 项目的核心团队成员,并且是活跃的开源贡献者。

Sudhir Kumar
亚马逊云科技资深性能工程师,常驻东帕罗奥图,他运用自己的专业知识优化 Aurora PostgreSQL/MySQL 效率并提高了 Aurora RDS 的整体性能。他在系统性能领域取得了一系列出色的成绩,在确保 Amazon RDS 以最佳性能运行方面发挥了关键作用。

星标不迷路,开发更极速!
关注后记得星标「亚马逊云开发者」

听说,点完下面4个按钮
就不会碰到bug了!