💗💗💗欢迎来到我的博客,你将找到有关如何使用技术解决问题的文章,也会找到某个技术的学习路线。无论你是何种职业,我都希望我的博客对你有所帮助。最后不要忘记订阅我的博客以获取最新文章,也欢迎在文章下方留下你的评论和反馈。我期待着与你分享知识、互相学习和建立一个积极的社区。谢谢你的光临,让我们一起踏上这个知识之旅!

文章目录
- 🍋Abstract
- 🍋论文相关内容
- 🍋总结
🍋Abstract
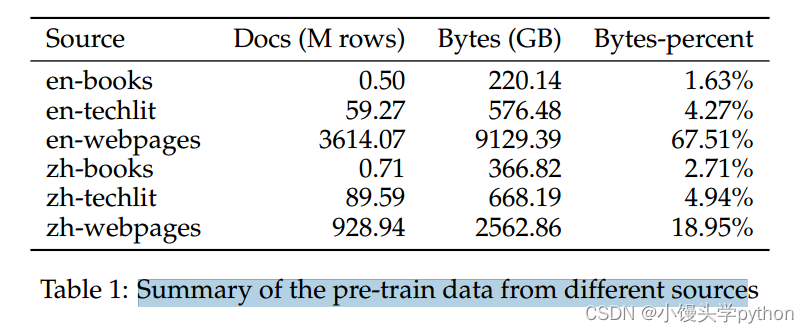
像ChatGPT和GPT-4这样的大型语言模型(llm)的发展引发了关于人工通用智能(AGI)出现的讨论。然而,在开源模型中复制这样的进步是具有挑战性的。本文介绍了一个开源法学硕士InternLM2,它通过创新的预训练和优化技术,在6个维度和30个基准的综合评估、长上下文建模和开放式主观评估方面优于其前身。InternLM2的预训练过程非常详细,突出了各种数据类型的准备,包括文本、代码和长上下文数据。InternLM2有效地捕获长期依赖关系,最初训练4k代币,然后在预训练和微调阶段提升到32k代币,在200k“大海捞针”测试中表现出卓越的性能。InternLM2进一步使用监督微调(SFT)和一种新的基于人类反馈的条件在线强化学习(COOL RLHF)策略进行协调,该策略解决了人类偏好和奖励黑客行为之间的冲突。通过发布不同训练阶段和模型大小的InternLM2模型,我们为社区提供了对模型演变的见解。
🍋论文相关内容
论文原文过多,这里针对实验图例等进行简要说明
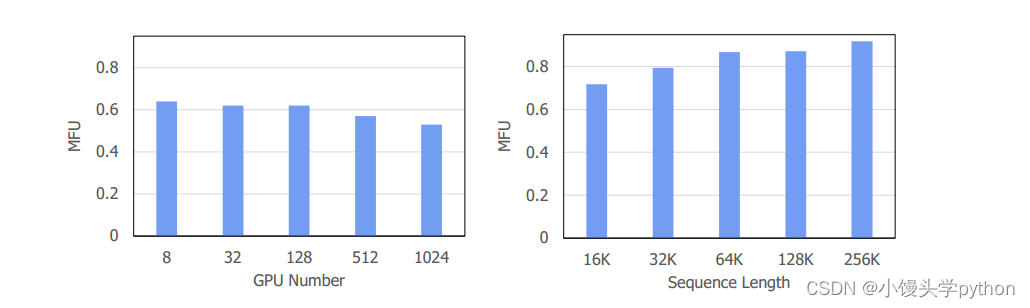
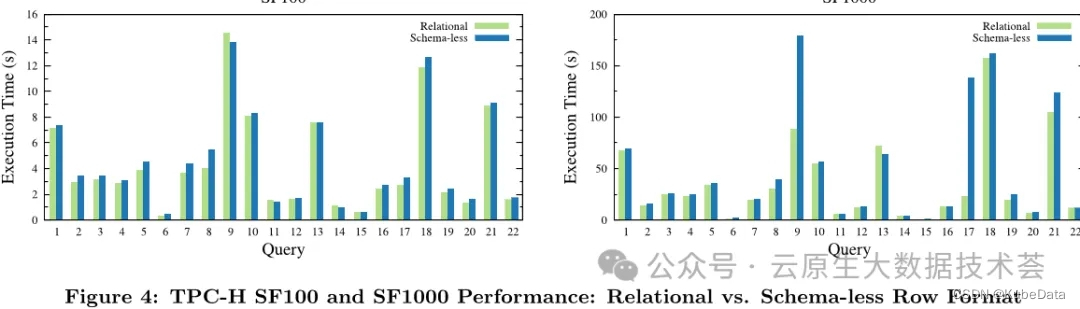
使用InternEvo训练InternLM-7B的模型FLOPs利用率(MFU)。我们使用具有不同GPU编号的4096个令牌的序列长度对训练性能进行基准测试,并在具有不同序列长度的128个GPU上对训练性能进行基准测试
注意:MFU最大训练利用率

当改变张量并行度(TP)大小时,不同的权重矩阵布局会导致不同的复杂度,不同的权重矩阵布局会导致在改变张量并行度(TP)大小时产生不同的复杂性。在分布式深度学习中,为了加速训练,通常会将模型的参数分布到多个处理单元(如GPU)上进行并行计算。而张量并行度指的就是将一个张量拆分成多个块,分别分配到不同的处理单元上进行计算。
相信感兴趣的小伙伴对于图中的代码也会有一定的疑问
这两段代码分别是InterLM和InterLM2中用于将权重矩阵Wqkv按照张量并行度(tp_size)进行分片的函数实现。当然他们也有一定的区别和联系
区别:
InterLM中的实现使用了手动的方式来分割Wqkv矩阵,通过计算每个分片的起始和结束位置来实现分片。
InterLM2中的实现使用了PyTorch的torch.split函数来直接将Wqkv按照指定的大小(split_size_or_sections=tp_size)在指定维度(dim=0)进行分割。
联系:
两者都是用于实现权重矩阵的张量并行度分片,目的是为了在分布式训练中有效地利用多个处理单元进行计算。
都需要指定张量并行度(tp_size),以确定分片的数量。
总体来说,InterLM2中的实现更加简洁和直观,利用了PyTorch提供的内置函数来完成分片操作,而InterLM中的实现则更加手动化,需要计算每个分片的位置
论文针对每个模块进行了详细的介绍
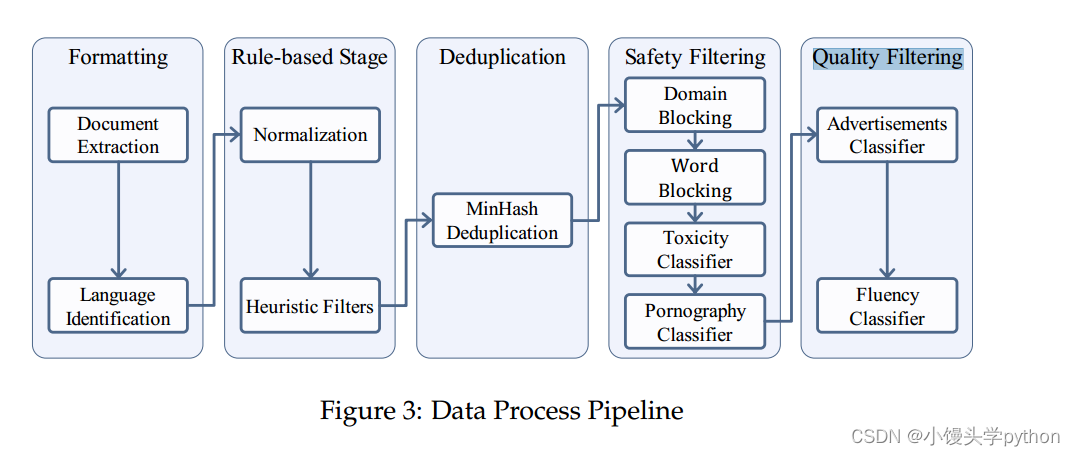
- Data Formatting:我们将以网页数据为例详细介绍数据处理管道。我们的网页数据主要来自Common Crawl1。首先,我们需要解压缩原始Warc格式文件,并使用Trafilatura (Barbaresi, 2021)进行HTML解析和主文本提取。然后,我们使用pycld22库对主要文本进行语言检测和分类。最后,我们为数据分配一个唯一标识符,并以JSON (JSON行)格式存储,从而获得format数据
- Rule-based Stage:从internet上随机抽取的Web页面数据通常包含大量低质量的数据,如解析错误、格式错误和非自然语言文本。一种常见的做法是设计基于规则的正则化和过滤方法来修改和过滤数据,如Gopher (Rae等人,2021)、C4 (Dodge等人,2021)和RefinedWeb (Penedo等人,2023)所示。根据我们对数据的观察,我们设计了一系列启发式过滤规则,重点关注分隔和换行异常、异常字符的频率和标点符号的分布。通过应用这些过滤器,我们获得了Clean数据
- Deduplication:互联网上存在大量的重复文本,这会对模型训练产生负面影响。因此,我们采用基于LSH (Locality-Sensitive hash)的方法对数据进行模糊重删。更具体地说,我们使用了MinHash方法(Broder, 1997),在5克文档上使用128个哈希函数建立签名,并使用0.7作为重复数据删除的阈值。我们的目标是保留最新的数据,也就是说,优先考虑具有较大CC转储数的数据。我们获得了LSH重复数据删除后的Dedup数据
这里我扩展一下LSH针对那些不太清楚的人群-------LSH(Locality-Sensitive Hashing)是一种在高维空间中用于近似最近邻搜索的技术。它特别适用于在大型数据集中高效地查找相似项。
MinHash是LSH中使用的一种具体算法,用于通过将它们哈希成短签名来估计集合之间的相似性。它通常用于重复文本检测。每个文档由一组shingles(连续的单词序列)表示,MinHash通过对shingles进行哈希来为每个文档创建签名。
通过比较两个文档的MinHash签名的Jaccard相似性来估计它们之间的相似度。如果Jaccard相似度高于某个阈值(在这种情况下为0.7),则认为这些文档是重复的。
- Safety Filtering:互联网上充斥着有毒和色情内容,使用这些内容进行模型训练会对性能产生负面影响,并增加生成不安全内容的可能性。因此,我们采用了“域屏蔽”、“词屏蔽”、“色情分类器”和“毒性分类器”相结合的综合安全策略对数据进行过滤。具体来说,我们构建了一个包含大约13M个不安全域的块域列表和一个包含36,289个不安全词的块词列表,用于初步的数据过滤。考虑到词块可能会无意中排除大量数据,我们选择了一种谨慎的方法来编译词块列表。
为了进一步提高不安全内容的检出率,我们使用Kaggle的“有毒评论分类挑战”数据集对BERT模型进行了微调,得到了一个毒性分类器。我们从Dedup数据中采样了一些数据,并使用Perspective API3对其进行注释,以创建一个色情分类数据集。然后我们用这个数据集对BERT模型进行微调,产生一个色情分类器。最后,我们使用这两个分类器对数据进行二次过滤,过滤掉得分低于阈值的数据,得到Safe数据。 - Quality Filtering:与书籍、论文和专利等来源相比,互联网来源的数据包含了大量低质量的内容。根据我们的观察,这种低质量内容的主要原因有两个:1。互联网上充斥着营销广告,这些广告往往是重复的,信息很少。2. 许多网页由文章摘要或产品描述列表组成,导致提取的文本难以阅读且缺乏逻辑连贯性。
为了过滤掉这些低质量的内容,我们首先组织了手工数据注释。对于广告分类任务,要求注释者识别一块数据是否包含广告内容(整体和部分广告都被标记为低质量)。对于流利度分类任务,注释者被要求从四个方面对数据进行评分:一致性、噪音、信息内容和语法,从而得出一个综合的流利度分数。然后,我们使用手动注释的数据对BERT模型进行微调,获得广告分类器和流利度分类器。最后,我们使用这两个分类器对数据进行二次过滤,过滤掉得分低于阈值的数据,得到高质量的预训练数据。
🍋总结
以上内容介绍仅仅是论文中一部分内容,我将会继续学习,持续更新~~~

挑战与创造都是很痛苦的,但是很充实。