SAP HANA SQL 进阶教程
- 5、HANA SQL 进阶教程
- (1)Databases
- (2)User & Role
- (3)Schemas
- (4)Tables
- (5)Table Index
- (6)Table Partitions
- (7)Comments
- (8)Views
- (9)Procedures
- (10)Functions
接上篇 《SAP HANA SQL 基础教程》。
5、HANA SQL 进阶教程
注:本进阶教程,需要具有Hana较高的系统管理权限,或者是相应的开发权限。
(1)Databases
HANA 使用 Database 来实现租户数据的物理隔离。一个租户对应一个 Database ,和其他数据库中的 “Database” 这一术语相比,HANA 中的 Database 更像是一个数据库实例,不同实例之间的数据是物理隔离的。
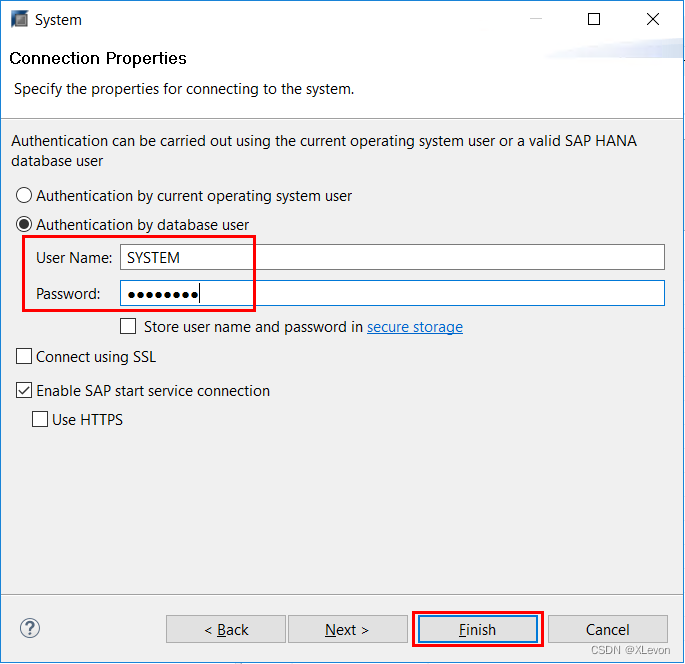
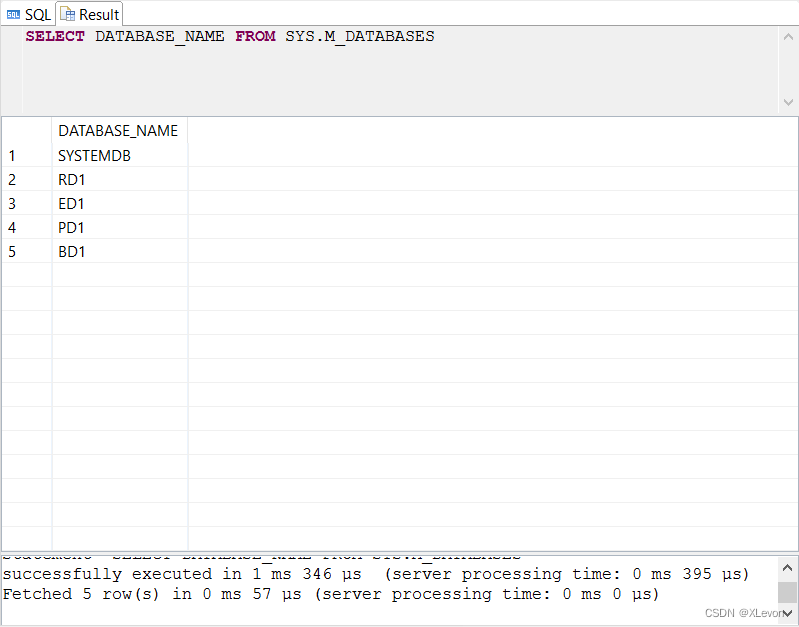
Script1:查询 HANA 服务器中已开辟的数据库租户(使用多租户主管理员 SYSTEM 账号登录):

-- 用多租户主管理员SYSTEM操作
SELECT DATABASE_NAME FROM SYS.M_DATABASES; -- 查询已有租户
Script2:创建与删除租户:
-- 用多租户主管理员SYSTEM操作
CREATE DATABASE DB1 SYSTEM USER PASSWORD Yourpas0; -- 创建租户
DROP DATABASE DB1; -- 删除租户
Script3:启停租户服务&更改租户密码:
-- 用多租户主管理员SYSTEM操作
alter system stop database DB1; -- 关闭DB1服务
alter database DB1 system user password Yourpas1; -- 修改密码
alter system start database DB1; -- 重新启动DB1服务
(2)User & Role
HANA 使用用户(User) 和 角色(Role) 来实现权限控制。
Script1:在租户中创建用户(使用租户的管理员 SYSTEM 账号登录):

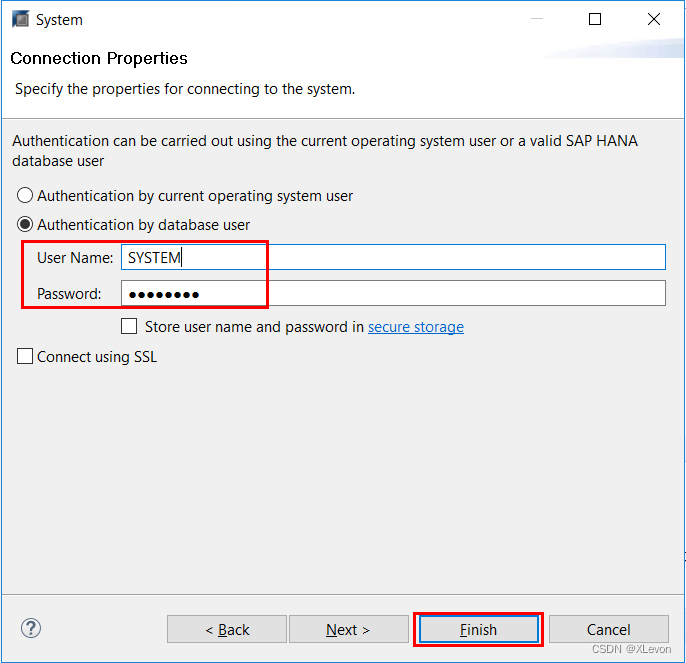
-- 用租户DB1的SYSTEM操作
-- 创建用户,自动生成同名SCHEMA,已经存在的SCHEMA名称无法再用作用户名
CREATE USER NewUser PASSWORD Yourpas0 NO FORCE_FIRST_PASSWORD_CHANGE;
-- 修改用户
ALTER USER NewUser PASSWORD Yourpas1; -- 修改密码
ALTER USER NewUser RESET CONNECT ATTEMPTS; -- 解锁
ALTER USER NewUser DISABLE PASSWORD LIFETIME; -- 设置密码永不过期
-- 删除用户
DROP USER NewUser CASCADE; -- 删除用户及相应schema,及其拥有的对象
Script2:创建角色,授予 SAPHANADB 只读权限:
-- 用SAPHANADB所在租户的SYSTEM操作
create role R_READER; -- 创建角色
-- 用SAPHANADB用户操作
GRANT SELECT, SELECT METADATA ON SCHEMA SAPHANADB to R_READER WITH GRANT OPTION; --只读访问SAPHANADB
-- 删除角色
drop role R_READER; -- 删除角色
Script3:创建只读用户 DBREADER,授予 SAPHANADB 只读权限:
-- 用SAPHANADB所在租户的SYSTEM操作
CREATE USER DBREADER PASSWORD Yourpas0 NO FORCE_FIRST_PASSWORD_CHANGE;
ALTER USER DBREADER DISABLE PASSWORD LIFETIME; -- 设置密码永不过期
GRANT R_READER to DBREADER; -- 授予角色
REVOKE R_READER from DBREADER; -- 撤回角色
Script4:创建不同的开发用户,授予不同的资源库访问权限:
-- 用SAPHANADB所在租户的SYSTEM操作
-- 创建开发者角色
create role R_DEVELOPER; -- 普通开发者角色
create role R_DEVADMIN; -- 开发管理员角色
GRANT R_READER to R_DEVELOPER; -- 角色授予角色
GRANT R_DEVELOPER to R_DEVADMIN; -- 角色授予角色
--授权资源库:普通开发人员
GRANT REPO.READ on "zdata.wkspace" to R_DEVELOPER;
GRANT REPO.ACTIVATE_NATIVE_OBJECTS on "zdata.wkspace" to R_DEVELOPER;
GRANT REPO.MAINTAIN_NATIVE_PACKAGES on "zdata.wkspace" to R_DEVELOPER;
GRANT REPO.EDIT_NATIVE_OBJECTS on "zdata.wkspace" to R_DEVELOPER;
--授权资源库:开发管理员
GRANT REPO.READ on "zdata.admin" to R_DEVADMIN;
GRANT REPO.ACTIVATE_NATIVE_OBJECTS on "zdata.admin" to R_DEVADMIN;
GRANT REPO.MAINTAIN_NATIVE_PACKAGES on "zdata.admin" to R_DEVADMIN;
GRANT REPO.EDIT_NATIVE_OBJECTS on "zdata.admin" to R_DEVADMIN;
--创建普通开发人员
CREATE USER DBDEV PASSWORD Yourpas0 NO FORCE_FIRST_PASSWORD_CHANGE;
ALTER USER DBDEV DISABLE PASSWORD LIFETIME; -- 设置密码永不过期
GRANT R_DEVELOPER TO DBDEV; -- 授予:普通权限
--创建开发管理员
CREATE USER DBDEVADMIN PASSWORD Yourpas0 NO FORCE_FIRST_PASSWORD_CHANGE;
ALTER USER DBDEVADMIN DISABLE PASSWORD LIFETIME; -- 设置密码永不过期
GRANT R_DEVADMIN TO DBDEVADMIN; -- 授予:管理权限
(3)Schemas
HANA 使用 Schema 来对数据库表进行隔离和区分。和其他数据库中的 “Schema” 这一术语相比,HANA 中的Schema 更像是一个“数据库”的概念。每个 Schema 都有自己的拥有者,以及对这个 Schema 下各种数据库对象进行各种操作的权限合集。
新建租户 DB1 的管理员 SYSTEM,默认可见较多的系统 SCHEMA: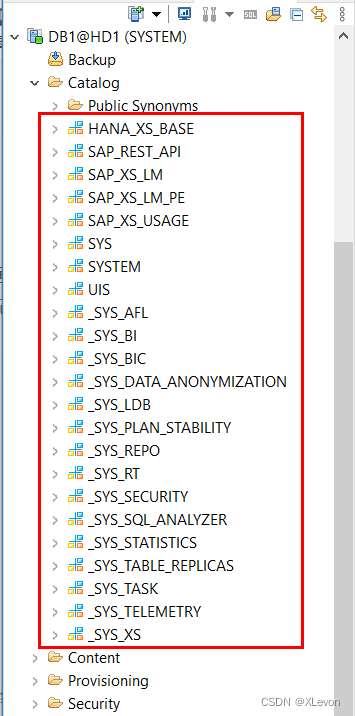
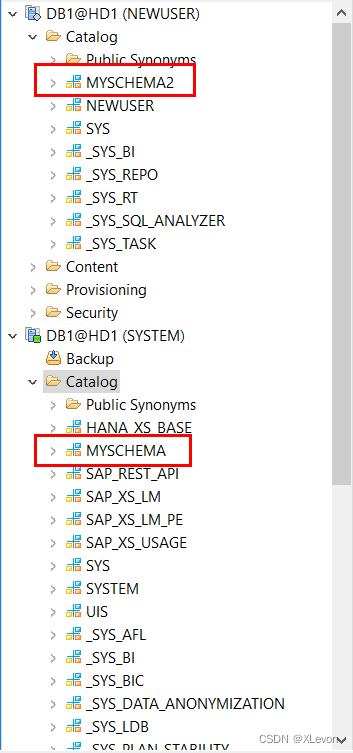
租户 DB1 的新建用户 NEWUSER,默认可见较少的系统 SCHEMA,以及与用户名同名的 SCHEMA:

创建 schema 的两种方法:
Script1:第一种直接创建 schema,默认拥有者为当前创建者,或者也可以指定拥有者,拥有者对 schema 具有所有操作权限:
-- 用租户DB1的SYSTEM操作
CREATE SCHEMA MYSCHEMA; -- 在SYSTEM用户下可见,拥有者为SYSTEM
CREATE SCHEMA MYSCHEMA2 OWNED BY NEWUSER; -- 在NEWUSER用户下可见,拥有者为NEWUSER
Script2:第二种通过创建用户的方式,在创建用户的时候,系统会自动添加一个同名的 schema ,该用户对自身同名 schema 具有所有操作权限:
CREATE USER NewUser PASSWORD Yourpas0; -- 上面已创建该用户
Script3:管理 NEWUSER 用户下的 SCHEMA:
-- 用租户DB1的NEWUSER操作
select * from SYS.schemas; -- 查询NEWUSER用户可见Schema
-- 删除拥有的schema(注:不可删除与用户名同名的schema)
DROP SCHEMA MYSCHEMA2; --无依赖时才能删除
-- 或者:
DROP SCHEMA MYSCHEMA2 CASCADE; --删除所有依赖对象
/*
DROP SCHEMA <SCHEMA_NAME> [<DROP_OPTION>]
DROP_OPTION: CASCADE | RESTRICT
RESTRICT:直接删除没有依赖的对象,如果对象有依赖关系,会抛出错误信息。
CASCADE:直接删除所有对象。
默认的DROP_OPTION为:RESTRICT(限制约束)
*/
Script4:授权 SYSTEM 用户可以访问自己拥有的 SCHEMA:
-- 用租户DB1的NEWUSER操作
GRANT SELECT, SELECT METADATA ON SCHEMA NEWUSER to SYSTEM WITH GRANT OPTION;
-- 撤回访问访问权限
REVOKE SELECT, SELECT METADATA ON SCHEMA NEWUSER From SYSTEM;
(4)Tables
HANA 数据库可以存储 ROW TABLE(行表)和COLUMN TABLE(列表),分别适用于不同的业务场景。
行表适用场景:
- 一次处理一条记录的情况
- 应用需要访问完整记录或记录的大部分(即一条记录中的所有字段或大多数字段
- 不需要压缩率
- 没有或很少的聚集、分组等复杂操作
- 表中的记录行数不是很多
列表适用场景:
- 通常只是在一个或少量列上执行计算操作
- 表在进行搜索时通常基于少量列上的值
- 表有很多列
- 表有很多行,并且通常进行的是列式操作(比如:聚集计算和where中字段值查找)
- 需要很高的压缩率
Script1:建表,同时添加表和字段注释
-- 用租户DB1的NEWUSER操作
-- 行表DEMO:
create row table newuser.zstudent -- 行表
(
ZNo int primary key comment '学号', -- 学号
ZName nvarchar(10) comment '姓名', -- 姓名
ZSex nvarchar(1) comment '性别', -- 性别
ZAge int comment '年龄' -- 年龄
)
comment 'Z学生表';
insert into newuser.ZStudent
values( 1, '张三', '男', 18 );
insert into newuser.ZStudent
values( 2, '李四', '女', 19 );
--查询表
select * from newuser.zstudent;
-- 列表DEMO:
create column table newuser.zstudent_c -- 列表
(
ZNo int primary key comment '学号', --学号
ZName nvarchar(10) comment '姓名', --姓名
ZSex nvarchar(1) comment '性别', --性别
ZAge int comment '年龄' --年龄
)
comment 'Z学生表';
insert into newuser.zstudent_c
values( 1, '张三', '男', 18 );
insert into newuser.zstudent_c
values( 2, '李四', '女', 19 );
--查询表
select * from newuser.zstudent_c;
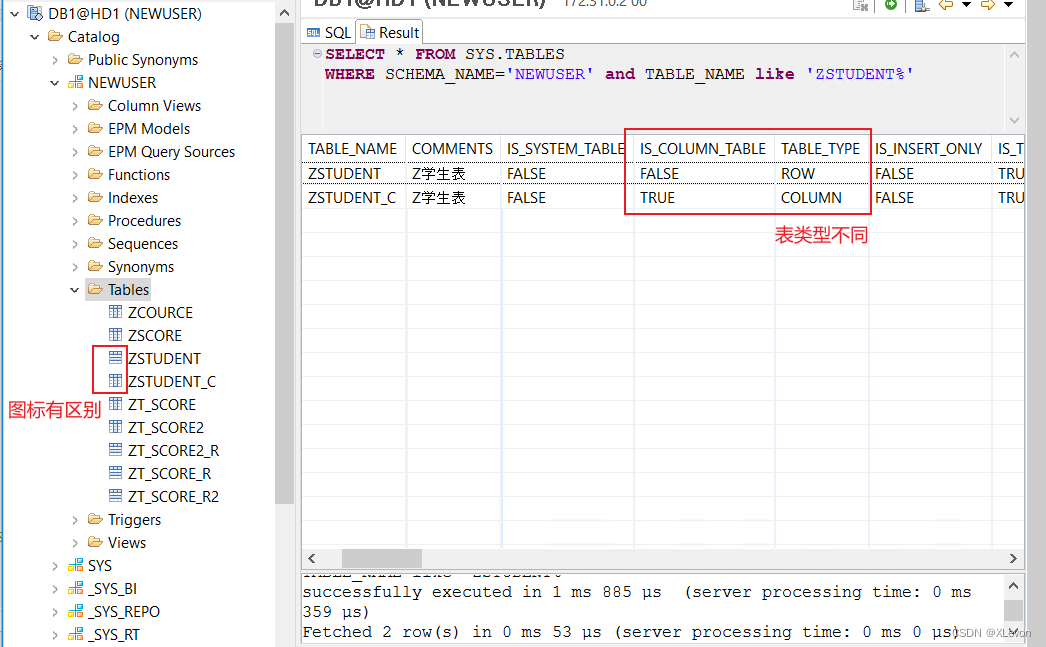
-- 查看表信息
SELECT * FROM SYS.TABLES
WHERE SCHEMA_NAME='NEWUSER' and TABLE_NAME like 'ZSTUDENT%';
Script2:建表,创建自增列
-- 用租户DB1的NEWUSER操作
create table newuser.zcource
(
ZID bigint not null generated by default as IDENTITY comment '递增ID',
ZName nvarchar(10) comment '课程名称',
primary key(ZID)
)
comment 'Z课程表';
insert into newuser.zcource(ZName)
select '语文' from dummy
union
select '数学' from dummy
union
select '英文' from dummy;
--查询表
select * from newuser.zcource;
Script3:建表,创建外键
-- 用租户DB1的NEWUSER操作
create column table newuser.zscore
(
ZID bigint not null generated by default as IDENTITY comment '递增ID',
ZSID int comment '学生ID',
ZCID bigint comment '课程ID',
ZSCORE float comment '成绩',
primary key INVERTED VALUE (ZID), -- 主键
UNIQUE (ZSID, ZCID), -- 唯一键
FOREIGN KEY(ZSID) REFERENCES newuser.zstudent ON UPDATE CASCADE, -- 外键
FOREIGN KEY(ZCID) REFERENCES newuser.zcource ON UPDATE CASCADE -- 外键
)
comment 'Z学生课程成绩表';
/*
创建列表时,我们指定的“UNIQUE”或“PRIMARY KEY”约束,HANA会自动创建相应的索引。这些索引分为两种类型:
INVERTED VALUE 适合于范围查询或like查询;
INVERTED HASH 使用HASH对组合唯一键或组合主键进行编码和压缩。对于等值查询(点查询),这种索引类型具有更好的性能;并且能够减少组合主键存储使用的内存数量。
如果不指定,缺省是 INVERTED VALUE。
*/
insert into newuser.zscore(ZSID, ZCID, ZSCORE)
values(1,1,95); --ok
insert into newuser.zscore(ZSID, ZCID, ZSCORE)
values(2,1,96); --ok
insert into newuser.zscore(ZSID, ZCID, ZSCORE)
values(3,1,98); --with error: foreign key constraint violation
insert into newuser.zscore(ZSID, ZCID, ZSCORE)
values(2,1,98); --with error: unique constraint
--查询表
select * from newuser.zscore;
Script4:表复制
-- 用租户DB1的NEWUSER操作
/*依据某个已经存在的表创建另外的新表。HANA SQL提供了两类方法*/:
--方法一:创建的表与源表数据类型、约束完全相同。例如:
CREATE TABLE newuser.zt_score LIKE newuser.zscore WITH NO DATA;
--方法二:创建的表字段类型和NULL/NOT NULL属性相同
CREATE TABLE newuser.zt_score2 AS (SELECT * FROM newuser.zscore) WITH DATA;
/*
WITH NO DATA:仅复制表结构,不复制表内数据;
WITH DATA:复制表结构,同时复制表内数据。
*/
Script5:更改表类型、表名
-- 用租户DB1的NEWUSER操作
-- 更改表类型
ALTER TABLE newuser.zstudent COLUMN THREADS 10 BATCH 10000; --改为:列表
ALTER TABLE newuser.zstudent_c ROW THREADS 10; ; --改为:行表
/*
参数说明:
THREADS:指定表转换时的并行执行线程数。线程数的最佳值是系统可用 CPU 内核数。如果未提供 THREADS,将使用 indexserver 中指定的 CPU 内核数的默认值。
BATCH:指定批量处理的行数。如果未指定 BATCH,将使用默认值 2000000。在每次达到批量处理的行数后将立即提交到列存储表中。BATCH 选项仅在从行转换为列存储时才能使用。
*/
--更改表名
RENAME TABLE newuser.zstudent_c TO newuser.zstudent_r;
--删除/增加主键
ALTER TABLE newuser.zstudent DROP PRIMARY KEY;
ALTER TABLE newuser.zstudent ADD PRIMARY KEY(ZNO, ZNAME);
Script6:更改表字段
--增加或删除字段
ALTER TABLE newuser.zstudent ADD(ZBIRTHDAY DATE NULL) ;
ALTER TABLE newuser.zstudent DROP (ZBIRTHDAY);
--修改字段类型
ALTER TABLE newuser.zstudent ALTER (ZNAME NVARCHAR (100) NULL);
--修改字段名称
RENAME COLUMN newuser.zstudent.ZNAME TO ZSTU_NAME;
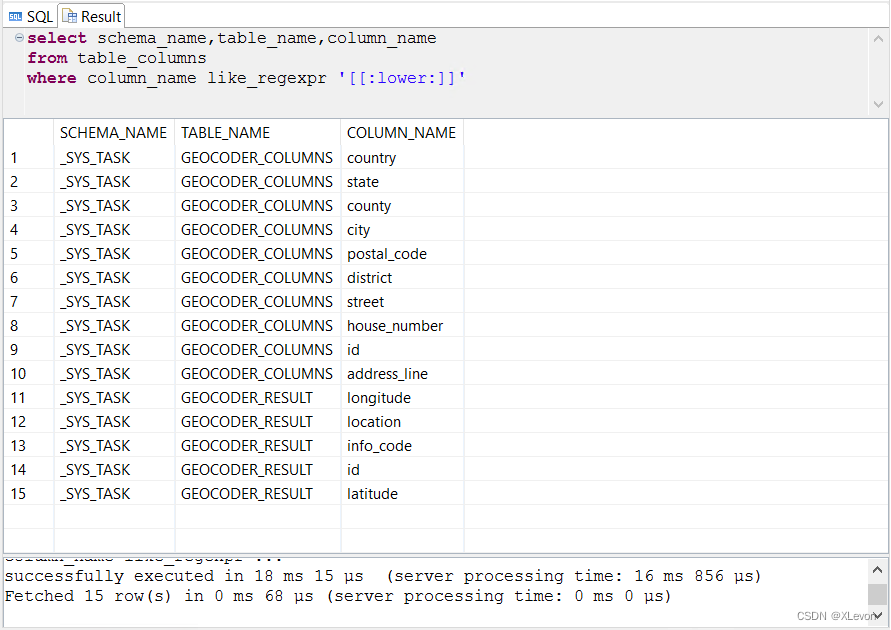
--查询小写字段名信息
select schema_name, table_name, column_name
from table_columns
where column_name like_regexpr '[[:lower:]]';
(5)Table Index
SAP HANA的索引都是保存在内存中。
Script1:HANA索引相关脚本。
--
--创建索引:
--语法:
CREATE [UNIQUE] [BTREE | CPBTREE] INDEX <index_name>
ON <table_name> (<column_name_order>, ...) [ASC | DESC]
--创建测试表:
create row table test_index (id INT,name nvarchar(10), remark nvarchar(10));
create index indextest1 on test_index(name);
CREATE CPBTREE INDEX indextest2 ON test_index(id, name DESC);
--创建唯一键索引:
create unique index indextest4 on test_index(id);
create unique index indextest3 on test_index(name,remark);
--删除索引:DROP INDEX <index_name>
drop index indextest2;--删除索引indextest2
--查询索引:
select * from indexes where table_name ='EMP'; --查询员工表中使用的索引
select * from index_columns where table_name ='EMP'; --查询索引列
select * from m_rs_indexes where table_name = 'EMP'; --查询索引的统计信息(B-tree and CPB-tree)
select * from fulltext_indexes where table_name = 'EMP'; --查询Fulltext 索引
select * from m_fulltext_queues; --查看fulltext 索引队列的状态
--修改索引名称
RENAME INDEX <old_index_name> TO <new_index_name>;
(6)Table Partitions
对于列式存储的表格,HANA 提供了三种分区方式:Hash分区、Range分区以及Roundrobin分区。前两者是针对某个或联合字段进行分区,区别在于hash分区是对字段的哈希值进行分区,而range分区则是定义了字段的取值范围。一般来说,如果涉及到年月日时间字段的数据,可以考虑通过Range分区,将数据划分到月或日的区间内;如果例如客户ID号这样的字段数据,可以考虑Hash分区,在真实系统中,ID号这样的自增数字字段,按照Hash值划分在可以达到较好的均匀分布。Roundrobin则是针对整张表记录进行随机划分,将数据按记录条数均匀分配到分区之中。
Script1:创建 Hash 散列分区
哈希分区用于把表平均分配到各个分区中,做到负载均衡和克服表2亿行数据的限制。
进行分区的表必须列表,字段必须是主键的一部分。
-- 用租户DB1的NEWUSER操作
create column table newuser.zsales_order
(
zorder_id int comment '订单ID',
zcustomer nvarchar(20) comment '客户',
zamount float comment '金额',
primary key(zorder_id)
)
comment 'Z销售订单表'
PARTITION BY HASH (zorder_id) PARTITIONS 4; -- 必须是primary key
insert into newuser.zsales_order
values(1, '张三', 100.00);
insert into newuser.zsales_order
values(2, '李四', 150.00);
--修改分区数量:
alter table newuser.zsales_order
PARTITION BY HASH (zorder_id)
PARTITIONS GET_NUM_SERVERS() ; -- 分区数是由数据库引擎在运行时根据其配置来决定
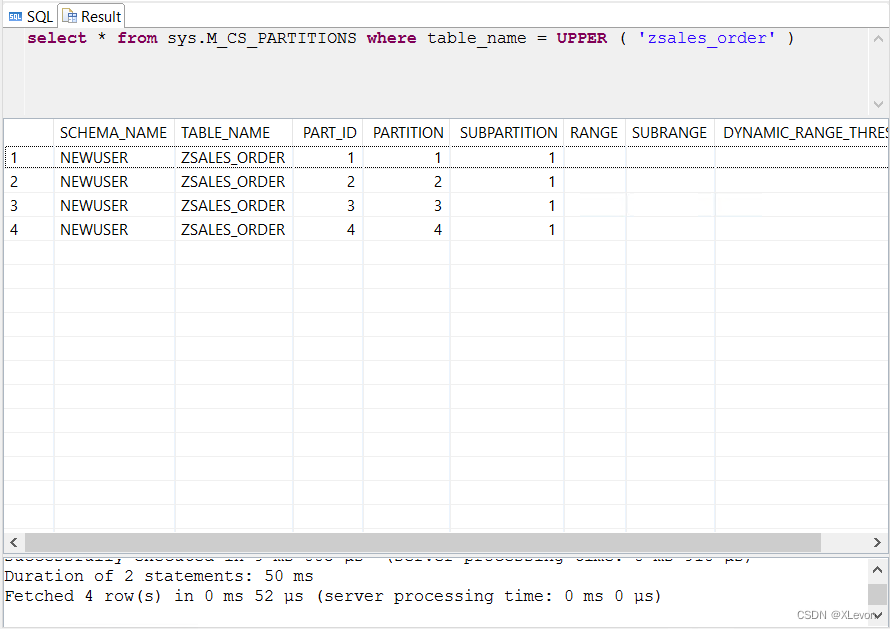
--查看表分区情况
select * from sys.M_CS_PARTITIONS where table_name = UPPER ( 'zsales_order' );
Script2:创建 Range 范围分区
范围分区对数据类型的限制:仅仅对字符串,整数,日期是可以使用的。
进行分区的表必须列表,字段必须是主键的一部分。
需要创建一个剩余分区,用于接收不在已定义分区范围内的记录,否则插入一条数据没有匹配上任何一个分区的记录时,系统会报错。
创建一个范围的分区用: PARTITION <= VALUES <
创建一个定值的分区用: PARTITION VALUE =
创建一个剩余分区用: PARTITION OTHERS
删除一个分区用:ALTER TABLE table_name DROP PARTITION partition_name
-- 用租户DB1的NEWUSER操作
create column table newuser.zsales_order_entry
(
zorder_id int comment '订单ID',
zorder_entry int comment '订单行号',
zorder_date date comment '订单日期',
zgoods nvarchar(20) comment '商品',
zqty int comment '数量',
primary key(zorder_id, zorder_entry, zorder_date)
)
comment 'Z销售订单明细表'
PARTITION BY RANGE (zorder_date) -- 必须是primary key
( PARTITION '20210101' <= VALUES < '20220101',
PARTITION '20220101' <= VALUES < '20230101',
PARTITION '20230101' <= VALUES < '20240101',
PARTITION OTHERS
);
insert into newuser.zsales_order_entry
values(1,1,'20221010', '苹果', 5);
insert into newuser.zsales_order_entry
values(1,2,'20221010', '香蕉', 10);
insert into newuser.zsales_order_entry
values(2,1,'20230110', '橙子', 7);
--查询表
select * from newuser.zsales_order_entry;
--修改/删除分区:
ALTER TABLE newuser.zsales_order_entry ADD PARTITION '20240101' <= VALUES < '20250101'; -- 增加分区
ALTER TABLE newuser.zsales_order_entry DROP PARTITION '20240101' <= VALUES < '20250101'; -- 删除分区
/* 注意事项:删除分区,需要慎重操作,会同时删除对应分区里面的数据,不会自动转移到OTHERS分区,且不会给出提醒。 */
--查看表分区情况
select * from sys.M_CS_PARTITIONS where table_name = UPPER ( 'zsales_order_entry' );

Script3:创建 Round-robin 循环分区
对整张表记录进行随机划分,将数据按记录条数均匀分配到分区之中
进行分区的表必须列表。
-- 用租户DB1的NEWUSER操作
CREATE COLUMN TABLE newuser.mytab (a INT, b INT, c INT)
PARTITION BY ROUNDROBIN PARTITIONS 4;
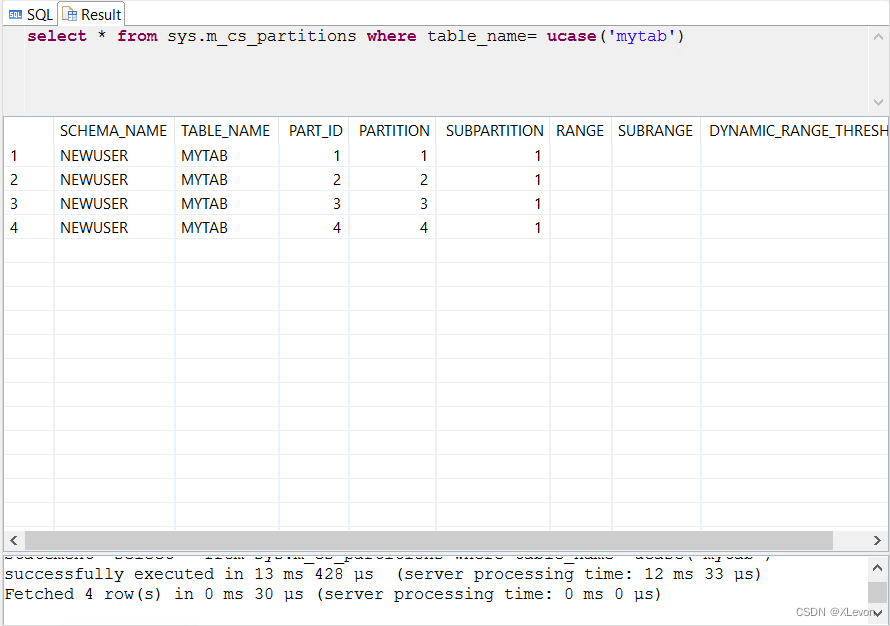
--查看表分区情况
select * from sys.m_cs_partitions where table_name= ucase('mytab');
Script4:创建多级分区
-- 用租户DB1的NEWUSER操作
-- 哈希-范围分区:
CREATE COLUMN TABLE newuser.mytab_hr (a INT, b INT, c INT, PRIMARY KEY (a,b))
PARTITION BY HASH (a, b) PARTITIONS 4,
RANGE (c)
(PARTITION 1 <= VALUES < 5,
PARTITION 5 <= VALUES < 20);
-- 循环-范围分区:
CREATE COLUMN TABLE newuser.mytab_rr (a INT, b INT, c INT)
PARTITION BY ROUNDROBIN PARTITIONS 4,
RANGE (c)
(PARTITION 1 <= VALUES < 5,
PARTITION 5 <= VALUES < 20);
-- 哈希-哈希分区:
CREATE COLUMN TABLE newuser.mytab_hh (a INT, b INT, c INT, PRIMARY KEY (a,b))
PARTITION BY HASH (a, b) PARTITIONS 4,
HASH (c) PARTITIONS 7;
Script5:转移分区
SAP HANA的分区和分区组可以从一台服务器转移到另外一台服务器
-- 用租户DB1的NEWUSER操作
-- 查询分区号
select * from sys.m_cs_partitions where table_name= ucase('mytab');
-- 按分区号转移
ALTER TABLE newuser.mytab MOVE PARTITION 1 TO '<host:port>'
--host:主机名或IP port: 目标index server的端口不是SQL 端口。
(7)Comments
Script1:追加表/视图/字段注释
-- 增加/更改:表/视图/字段 的注释
comment on table schema.tab_name is '表描述';
comment on view schema.view_name is '视图描述';
comment on column schema.v_name.field is '字段描述';
-- 查看表信息及注释
SELECT * FROM SYS.TABLES WHERE SCHEMA_NAME='NEWUSER';
-- 查看表中字段信息及注释
SELECT * FROM SYS.TABLE_COLUMNS WHERE TABLE_NAME='ZSTUDENT';
(8)Views
Script1:创建视图及注释
-- 用租户DB1的NEWUSER操作
create view newuser.znew_student as
select
zno as student_no,
zname as student_name,
zsex as student_sex,
zage as student_age
from newuser.zstudent;
--增加视图注释
comment on view newuser.znew_student is '学生信息视图';
comment on column newuser.znew_student.student_no is '学号';
comment on column newuser.znew_student.student_name is '姓名';
comment on column newuser.znew_student.student_sex is '性别';
comment on column newuser.znew_student.student_age is '年龄';
--查看视图数据
select * from newuser.znew_student;
-- 查看视图注释
SELECT * FROM SYS.VIEWS WHERE SCHEMA_NAME='NEWUSER';
-- 查看视图字段注释
SELECT * FROM SYS.VIEW_COLUMNS WHERE VIEW_NAME='ZNEW_STUDENT';
(9)Procedures
待发布专题《Hana存储过程开发》。
(10)Functions
自定义函数,请参考《Hana自定义函数》。