快速使用
- 打开
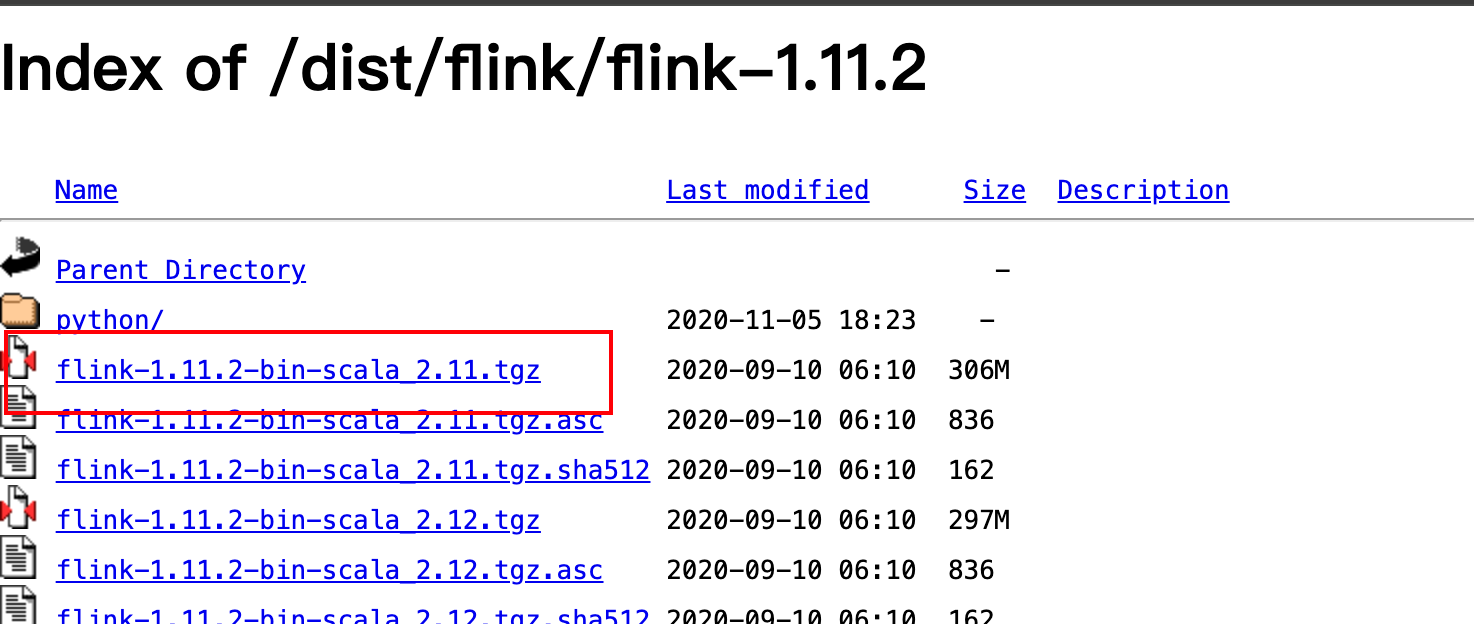
https://flink.apache.org/downloads/下载 flink
因为书籍介绍的是
1.12版本的,为避免不必要的问题,下载相同版本
- 解压
tar -xzvf flink-1.11.2-bin-scala_2.11.tgz
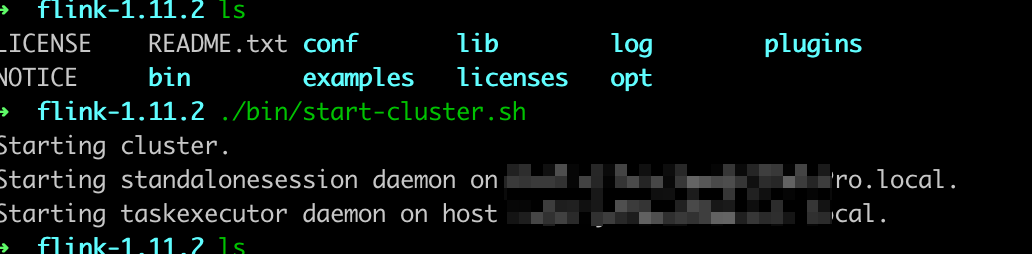
- 启动 flink
./bin/start-cluster.sh
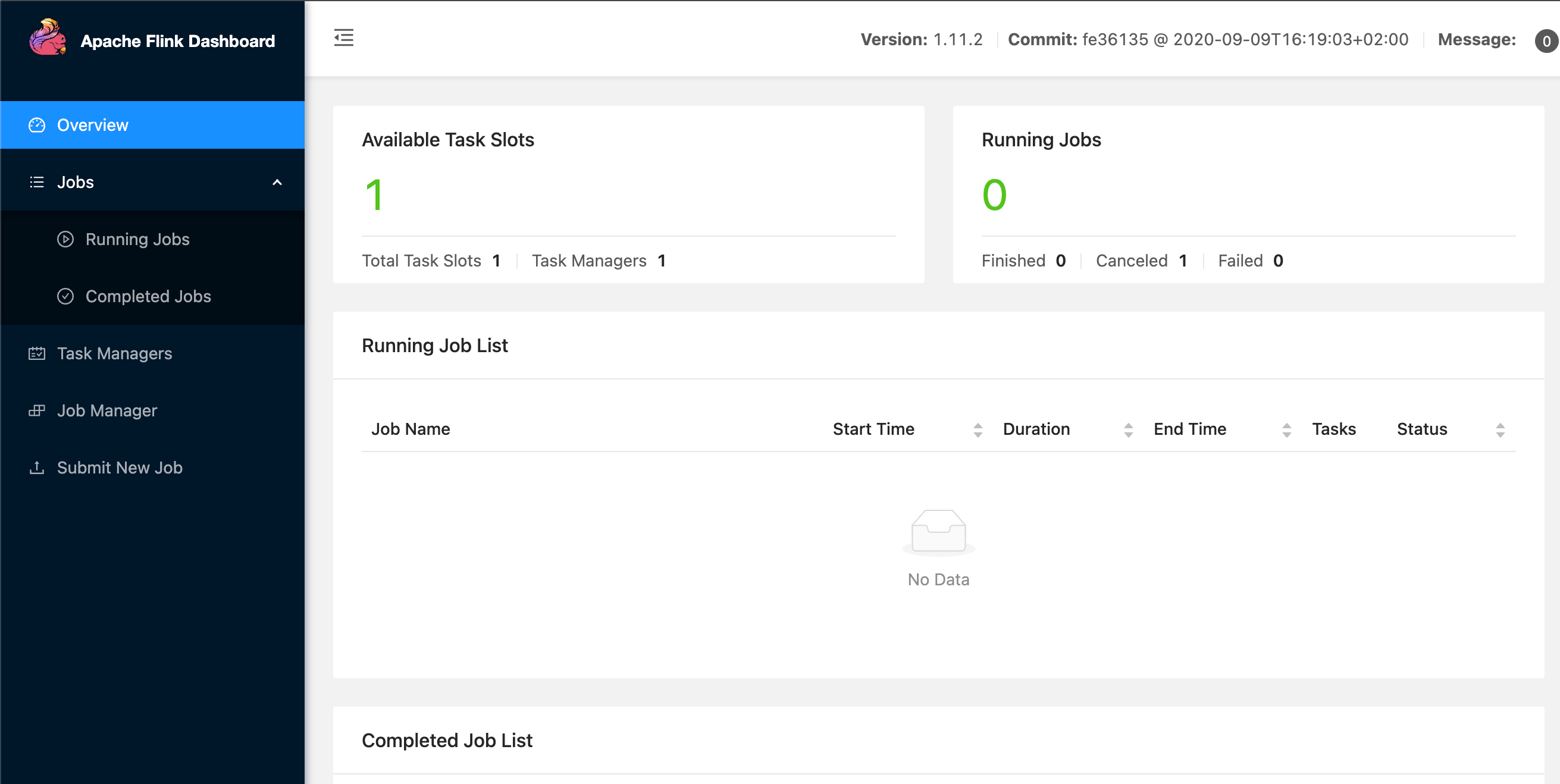
- 打开 flink web 页面
localhost:8081
- 编写结合 Kafka 词频统计程序
具体参考
https://weread.qq.com/web/reader/51032ac07236f8e05107816k1f032c402131f0e3dad99f3?
package org.example;
import org.apache.flink.api.common.serialization.SimpleStringSchema;
import org.apache.flink.api.common.typeinfo.Types;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.time.Time;
import org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer;
import org.apache.flink.util.Collector;
import java.util.Properties;
public class WordCountKafkaInStdOut {
public static void main(String[] args) throws Exception {
// 设置Flink执行环境
StreamExecutionEnvironment env =
StreamExecutionEnvironment.getExecutionEnvironment();
// Kafka参数
Properties properties = new Properties();
properties.setProperty("bootstrap.servers", "localhost:9092");
properties.setProperty("group.id", "flink-group");
String inputTopic = "Shakespeare";
String outputTopic = "WordCount";
// Source
FlinkKafkaConsumer<String> consumer =
new FlinkKafkaConsumer<String>(inputTopic, new SimpleStringSchema(),
properties);
DataStream<String> stream = env.addSource(consumer);
// Transformation
// 使用Flink API对输入流的文本进行操作
// 按空格切词、计数、分区、设置时间窗口、聚合
DataStream<Tuple2<String, Integer>> wordCount = stream
.flatMap((String line, Collector<Tuple2<String, Integer>> collector) -> {
String[] tokens = line.split("\\s");
// 输出结果
for (String token : tokens) {
if (token.length() > 0) {
collector.collect(new Tuple2<>(token, 1));
}
}
})
.returns(Types.TUPLE(Types.STRING, Types.INT))
.keyBy(0)
.timeWindow(Time.seconds(5))
.sum(1);
// Sink
wordCount.print();
// execute
env.execute("kafka streaming word count");
}
}
- 打包应用(当然在这之前需要本地调试一下,至少得运行通吧😄)
- 使用Flink提供的命令行工具flink,将打包好的作业提交到集群上。命令行的参数
--class用来指定哪个主类作为入口。
./bin/flink run --class org.example.WordCountKafkaInStdOut xxtarget/flink_study-1.0-SNAPSHOT.jar
class 建议直接拷贝引用
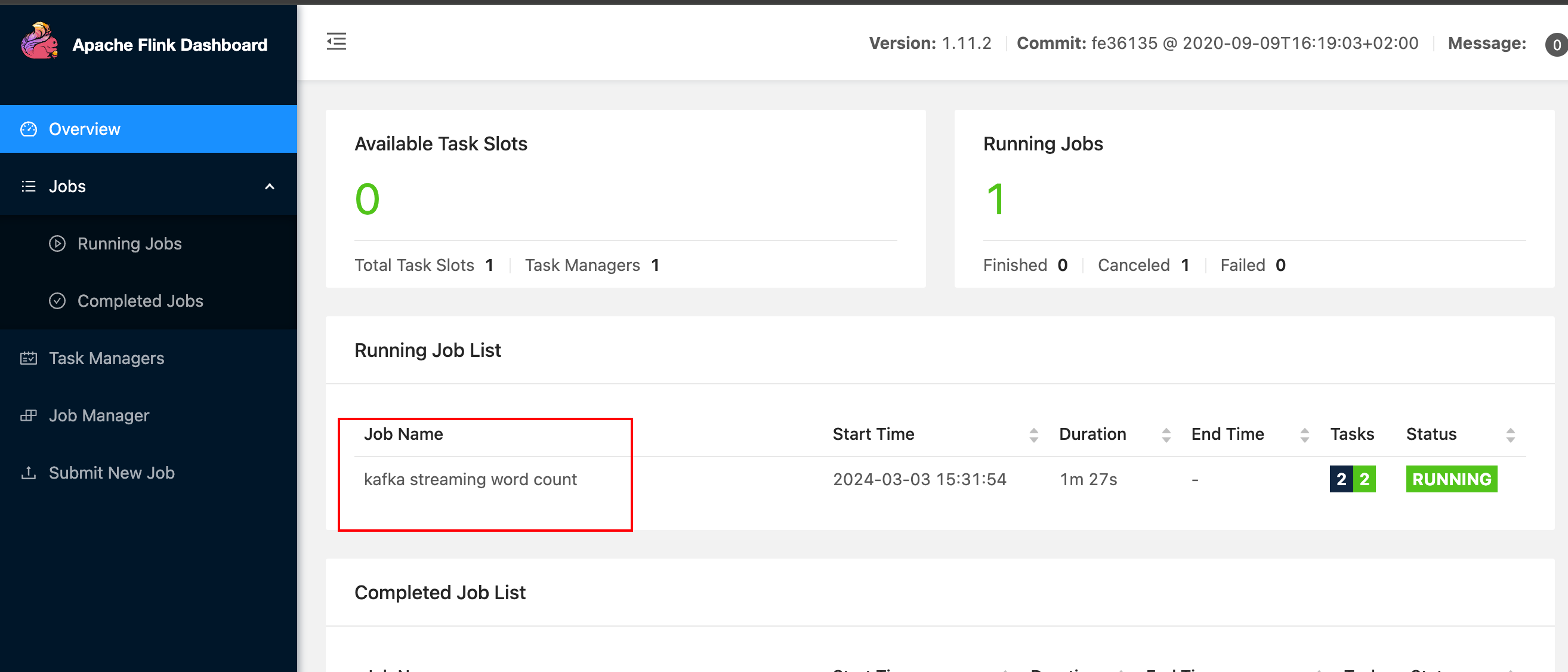
- web 页面查看作业提交成功
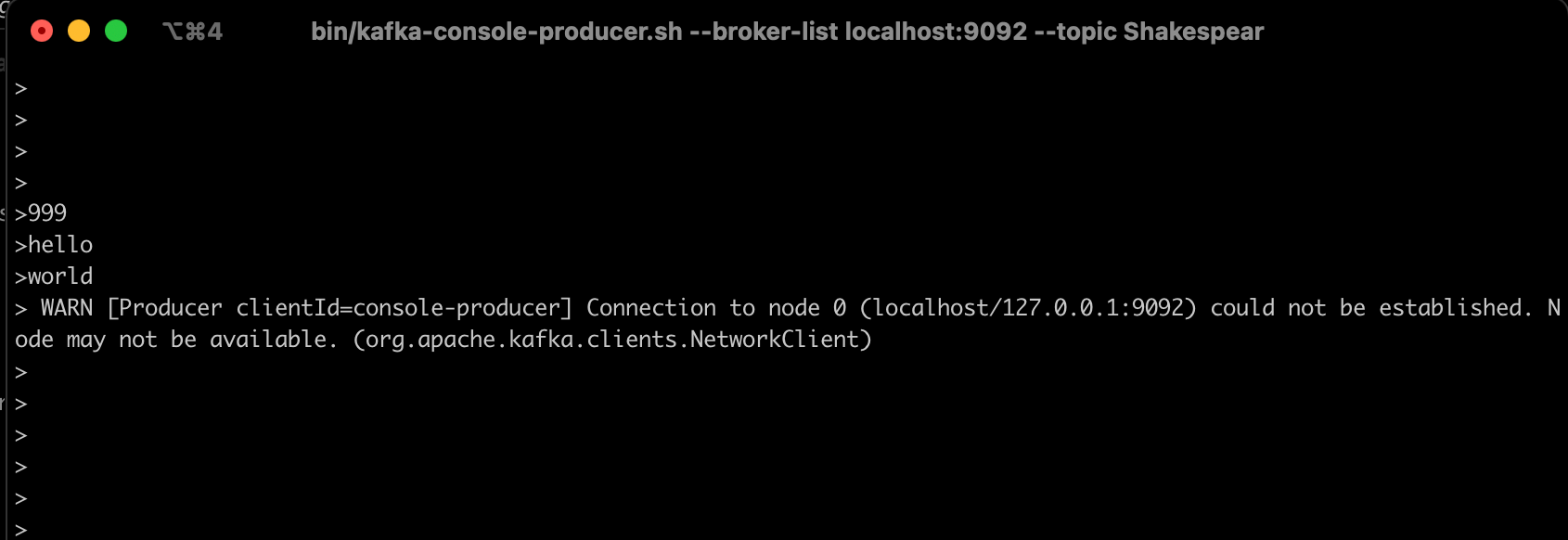
- kafka 生产者随便发点消息
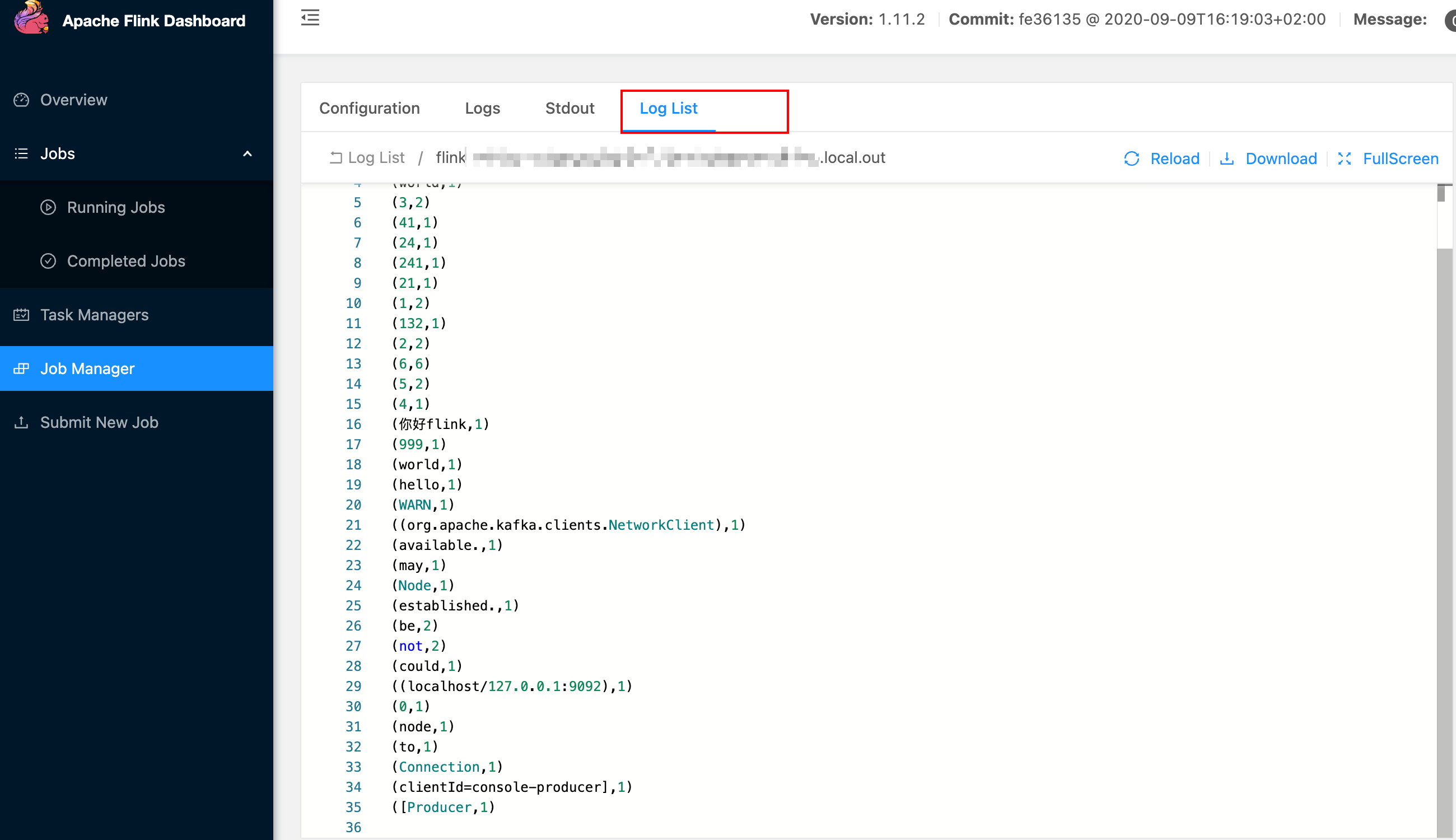
- 查看作业日志,词频统计结果
- 关闭
flink
./bin/stop-cluster.sh