ECS准备
开通阿里云ECS
略
控制台设置密码
连接ECS
远程连接工具连接阿里云ECS实例,这里远程连接工具使用xshell

根据提示接受密钥

根据提示写用户名和密码
用户名:root
密码:在控制台设置的密码
修改主机名
将主机名从localhost改为需要的主机名,例如:node1
[root@iZwz9hpiui8zhoe2pkat8nZ ~]# hostnamectl set-hostname node1 [root@iZwz9hpiui8zhoe2pkat8nZ ~]# hostname node1
发现未重启时,命令行@后面显示的主机名未变
重启 [root@iZwz9hpiui8zhoe2pkat8nZ ~]# reboot 重新连接 [root@node1 ~]#
重启后,命令行中的主机名改变了
创建普通用户
因为root用户权限太高,误操作可能造成一些麻烦。一般情况下,我们不会用root用户来安装hadoop,所以我们需要创建普通用户来安装hadoop。
创建新用户方法如下:
创建新用户,例如用户名为:hadoop,并设置新用户密码,重复设置2次,看不到输入的密码,这是linux的安全机制,输入即可。
[root@node1 ~]# adduser hadoop [root@node1 ~]# passwd hadoop Changing password for user hadoop. New password: BAD PASSWORD: The password is shorter than 8 characters Retype new password: passwd: all authentication tokens updated successfully.
给普通用户添加sudo执行权限
[root@node1 ~]# chmod -v u+w /etc/sudoers mode of ‘/etc/sudoers’ changed from 0440 (r--r-----) to 0640 (rw-r-----) [root@node1 ~]# vim /etc/sudoers 在%wheel ALL=(ALL) ALL一行下面添加如下语句: hadoop ALL=(ALL) ALL [root@node1 ~]# chmod -v u-w /etc/sudoers mode of ‘/etc/sudoers’ changed from 0640 (rw-r-----) to 0440 (r--r-----)
这种情况下,执行sudo相关命令时,需要输入当前普通用户的密码。
如果不想输入密码,在%wheel ALL=(ALL) ALL一行下面添加的语句更改为如下:
hadoop ALL=(ALL) NOPASSWD:ALL
关闭root连接
普通用户登录
使用xshell新建一个连接,
用户名:hadoop
密码:创建hadoop用户时设置的密码
映射IP和主机
[hadoop@node1 ~]$ sudo vim /etc/hosts
文件末尾一行,将ECS内网IP与实际的主机名node1映射,修改如下内容:
192.168.0.100 node1

注意:192.168.0.100为ECS内网IP,ECS内网IP可以在阿里云控制台查询,请根据实际情况设置。
配置免密登录
生成密钥对
ssh-keygen -t rsa
执行命令后,连续敲击三次回车键,运行过程如下:
[hadoop@node1 ~]$ ssh-keygen -t rsa Generating public/private rsa key pair. Enter file in which to save the key (/home/hadoop/.ssh/id_rsa): Enter passphrase (empty for no passphrase): Enter same passphrase again: Your identification has been saved in /home/hadoop/.ssh/id_rsa. Your public key has been saved in /home/hadoop/.ssh/id_rsa.pub. The key fingerprint is: SHA256:F7ztwW9iUTYORd3jGBD46lvznVHbxe0jZcAHeI7kVRk hadoop@node1 The key's randomart image is: +---[RSA 2048]----+ | .o+o+E+| | o o.=.oo| | * *oB..| | O Bo+.| | S + = .o=| | o . +o.=| | . o+.o+o| | ...ooo +| | .. . o | +----[SHA256]-----+
拷贝公钥
ssh-copy-id node1
安装jdk
创建安装包目录
创建一个目录,专门存放安装包(可选)
[hadoop@node1 ~]$ mkdir ~/installfile
下载jdk8安装包
官网下载jdk安装包:jdk-8u271-linux-x64.tar.gz,并将安装包上传到Linux的installfile目录。
解压安装包
解压安装包
[hadoop@node1 installfile]$ tar -zxvf jdk-8u271-linux-x64.tar.gz -C ~/soft
切换到soft目录,查看解压后的文件
[hadoop@node1 softinstall]$ cd ~/soft [hadoop@node1 soft]$ ls jdk1.8.0_271
配置环境变量
[hadoop@node1 soft]$ sudo nano /etc/profile.d/my_env.sh
内容如下
export JAVA_HOME=/home/hadoop/soft/jdk1.8.0_271 export PATH=$PATH:$JAVA_HOME/bin
让配置立即生效
[hadoop@node1 soft]$ source /etc/profile
验证版本号
[hadoop@node1 soft]$ java -version java version "1.8.0_271" Java(TM) SE Runtime Environment (build 1.8.0_271-b09) Java HotSpot(TM) 64-Bit Server VM (build 25.271-b09, mixed mode)
看到输出java version "1.8.0_271",说明jdk安装成功。
遇到的问题
验证java版本号时,遇到找不到libjli.so的问题
[hadoop@node1 ~]$ java -version java: error while loading shared libraries: libjli.so: cannot open shared object file: No such file or directory
排查问题,发现解压jdk包时出现了错误,造成该问题
jdk1.8.0_271/jre/lib/ jdk1.8.0_271/jre/lib/amd64/ jdk1.8.0_271/jre/lib/amd64/server/ jdk1.8.0_271/jre/lib/amd64/server/Xusage.txt jdk1.8.0_271/jre/lib/amd64/server/libjvm.so tar: Skipping to next header gzip: stdin: invalid compressed data--format violated tar: Child returned status 1 tar: Error is not recoverable: exiting now
重新上传jdk安装包,确保文件完整,然后再重新解压,解压正常,版本号验证正常。
安装hadoop伪分布式
下载hadoop
[hadoop@node1 soft]$ cd ~/softinstall/ [hadoop@node1 soft]$ wget https://archive.apache.org/dist/hadoop/common/hadoop-3.3.4/hadoop-3.3.4.tar.gz [hadoop@node1 softinstall]$ ls hadoop-3.3.4.tar.gz jdk-8u271-linux-x64.tar.gz
解压hadoop
[hadoop@node1 softinstall]$ tar -zxvf hadoop-3.3.4.tar.gz -C ~/soft
配置环境变量
[hadoop@node1 softinstall]$ sudo nano /etc/profile.d/my_env.sh
在文件末尾添加如下配置
export HADOOP_HOME=/home/hadoop/soft/hadoop-3.3.4 export PATH=$PATH:$HADOOP_HOME/bin export PATH=$PATH:$HADOOP_HOME/sbin
让环境变量生效
[hadoop@node1 softinstall]$ source /etc/profile
验证版本号
执行hadoop version命令,能看到Hadoop 3.3.4版本号,说明环境变量配置成功。
[hadoop@node1 softinstall]$ hadoop version Hadoop 3.3.4 Source code repository https://github.com/apache/hadoop.git -r a585a73c3e02ac62350c136643a5e7f6095a3dbb Compiled by stevel on 2022-07-29T12:32Z Compiled with protoc 3.7.1 From source with checksum fb9dd8918a7b8a5b430d61af858f6ec This command was run using /home/hadoop/soft/hadoop-3.3.4/share/hadoop/common/hadoop-common-3.3.4.jar
配置hadoop
进入配置目录
[hadoop@node1 softinstall]$ cd $HADOOP_HOME/etc/hadoop
配置core-site.xml
[hadoop@node1 hadoop]$ vim core-site.xml
在<configuration> 和</configuration>之间添加如下内容:
<!-- 指定NameNode的地址 -->
<property>
<name>fs.defaultFS</name>
<value>hdfs://node1:8020</value>
</property>
<!-- 指定hadoop数据的存储目录 -->
<property>
<name>hadoop.tmp.dir</name>
<value>/home/hadoop/soft/hadoop-3.3.4/data</value>
</property>
<!-- 配置HDFS网页登录使用的静态用户为hadoop,value里的hadoop代表用户 -->
<property>
<name>hadoop.http.staticuser.user</name>
<value>hadoop</value>
</property>
<!-- 配置该hadoop(superUser)(第二个hadoop代表用户)允许通过代理访问的主机节点 -->
<property>
<name>hadoop.proxyuser.hadoop.hosts</name>
<value>*</value>
</property>
<!-- 配置该hadoop(superUser)(第二个hadoop代表用户)允许通过代理用户所属组 -->
<property>
<name>hadoop.proxyuser.hadoop.groups</name>
<value>*</value>
</property>
<!-- 配置该hadoop(superUser)(第二个hadoop代表用户)允许通过代理的用户-->
<property>
<name>hadoop.proxyuser.hadoop.users</name>
<value>*</value>
</property>
配置hdfs-site.xml
[hadoop@node1 hadoop]$ nano hdfs-site.xml
在<configuration> 和</configuration>之间添加如下内容:
<!-- nn web端访问地址-->
<property>
<name>dfs.namenode.http-address</name>
<value>node1:9870</value>
</property>
<!-- 2nn web端访问地址-->
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>node1:9868</value>
</property>
<!-- HDFS副本的数量1 -->
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
注意:node1为ECS的主机名称,注意根据实际情况修改,之后的配置文件node1也需要注意修改。
配置yarn-site.xml
[hadoop@node1 hadoop]$ nano yarn-site.xml
在<configuration> 和</configuration>之间添加如下内容:
<!-- 指定MR走shuffle --> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <!-- 指定ResourceManager的地址--> <property> <name>yarn.resourcemanager.hostname</name> <value>node1</value> </property> <!-- 环境变量的继承 --> <property> <name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_YARN_HOME,HADOOP_MAPRED_HOME</value> </property> <!--yarn单个容器允许分配的最大最小内存 --> <property> <name>yarn.scheduler.minimum-allocation-mb</name> <value>512</value> </property> <property> <name>yarn.scheduler.maximum-allocation-mb</name> <value>4096</value> </property> <!-- yarn容器允许管理的物理内存大小 --> <property> <name>yarn.nodemanager.resource.memory-mb</name> <value>4096</value> </property> <!-- 关闭yarn对物理内存和虚拟内存的限制检查 --> <property> <name>yarn.nodemanager.pmem-check-enabled</name> <value>true</value> </property> <property> <name>yarn.nodemanager.vmem-check-enabled</name> <value>false</value> </property>
配置mapred-site.xml
[hadoop@node1 hadoop]$ nano mapred-site.xml
在<configuration> 和</configuration>之间添加如下内容:
<!-- 指定MapReduce程序运行在Yarn上 -->
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
配置workers
[hadoop@node1 hadoop]$ nano workers
删除原有内容,配置workers的主机名称,内容如下
node1
配置历史服务器
[hadoop@node1 hadoop]$ nano mapred-site.xml
添加如下配置
<!-- 历史服务器端地址 --> <property> <name>mapreduce.jobhistory.address</name> <value>node1:10020</value> </property> <!-- 历史服务器web端地址 --> <property> <name>mapreduce.jobhistory.webapp.address</name> <value>node1:19888</value> </property>
配置日志聚集
开启日志聚集功能,应用运行完成以后,将程序运行日志信息上传到HDFS系统上。
[hadoop@node1 hadoop]$ nano yarn-site.xml
添加如下功能
<!-- 开启日志聚集功能 --> <property> <name>yarn.log-aggregation-enable</name> <value>true</value> </property> <!-- 设置日志聚集服务器地址 --> <property> <name>yarn.log.server.url</name> <value>http://node1:19888/jobhistory/logs</value> </property> <!-- 设置日志保留时间为7天 --> <property> <name>yarn.log-aggregation.retain-seconds</name> <value>604800</value> </property>
格式化
格式化hdfs文件系统
[hadoop@node1 hadoop]$ hdfs namenode -format
部分输出如下
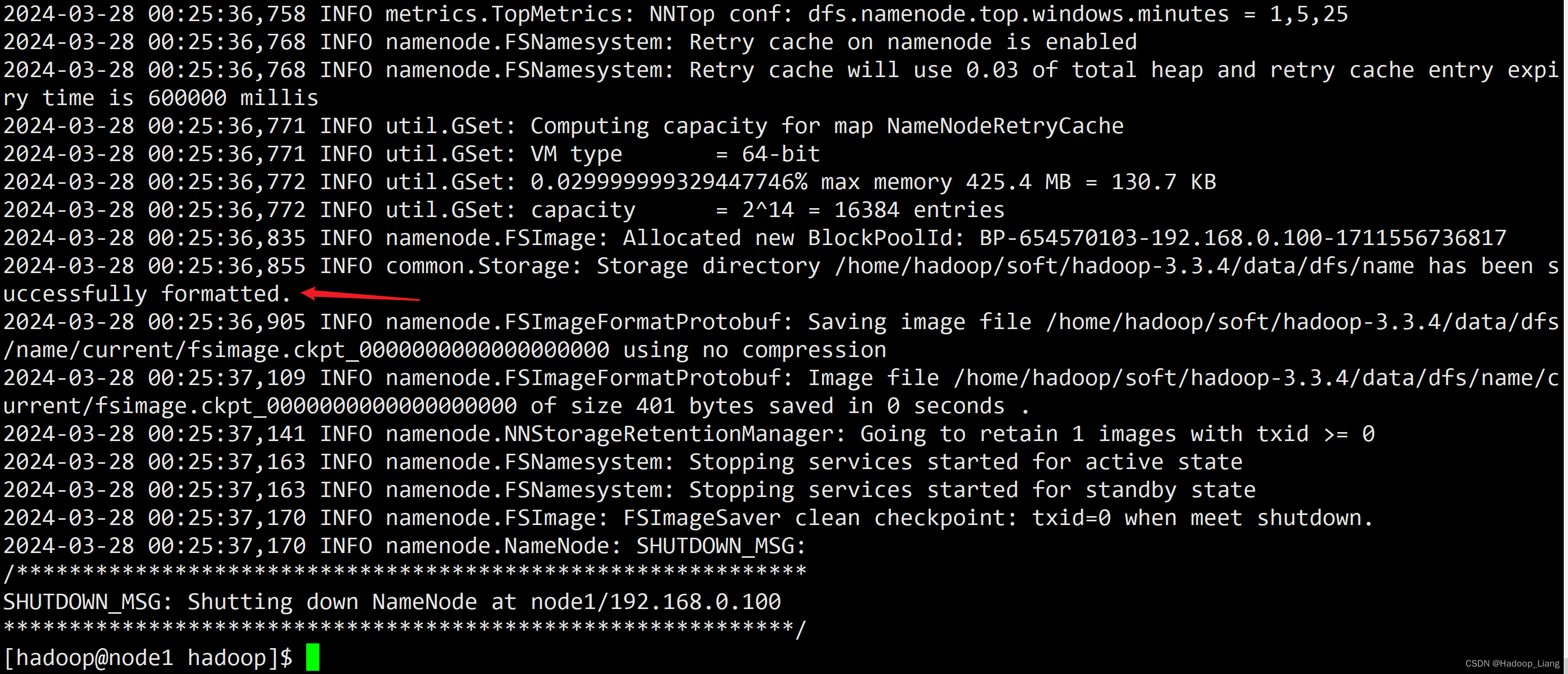
看到successfully formatted.说明格式化成功。
注意:格式化只能进行一次。
启动集群
[hadoop@node1 hadoop]$ start-dfs.sh [hadoop@node1 hadoop]$ start-yarn.sh
查看进程
[hadoop@node1 hadoop]$ jps 16944 DataNode 18818 Jps 17413 ResourceManager 17144 SecondaryNameNode 17513 NodeManager 16844 NameNode
看到如上进程,说明正常。
如果缺少进程:
1.检查配置是否正确;
2.查看对应$HADOOP_HOME/logs目录对应进程log文件的报错信息来解决。
放开Web UI端口
登录阿里云控制台,在安全组放开9870、8088、9868端口

注意:0.0.0.0/0代表所有ip均能访问,不安全。可以只授权给特定ip,例如自己当前电脑的公网ip地址,一般情况下,当前电脑的公网ip会变化,变化后就需要重新查询当前电脑的公网ip,再重新设置授权对象。
访问Web UI
浏览器访问
公网IP:9870

公网IP:8088

公网IP:9868

如果不想输入公网ip,可以在windows的hosts文件做映射:
公网IP node1 alinode
含义:公网IP映射的主机为node1,alinode为node1机器的别名。
使用node1或者alinode代替公网IP,访问相关端口,也能正常访问如下:

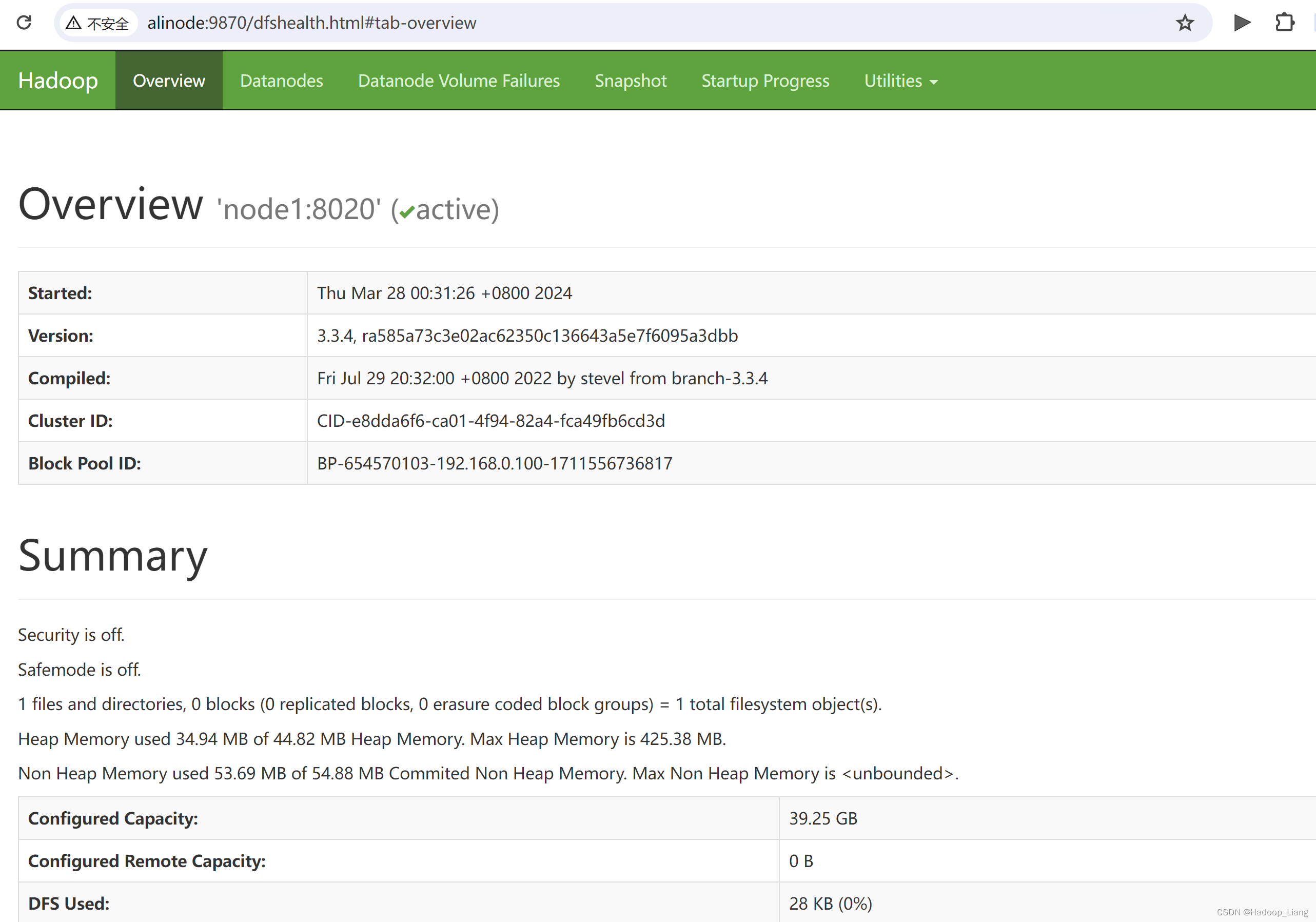
完成!enjoy it!