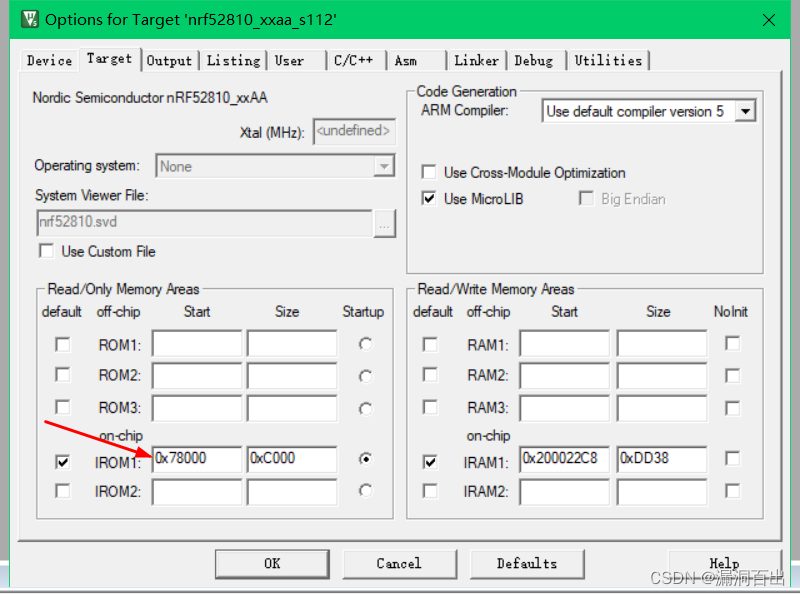
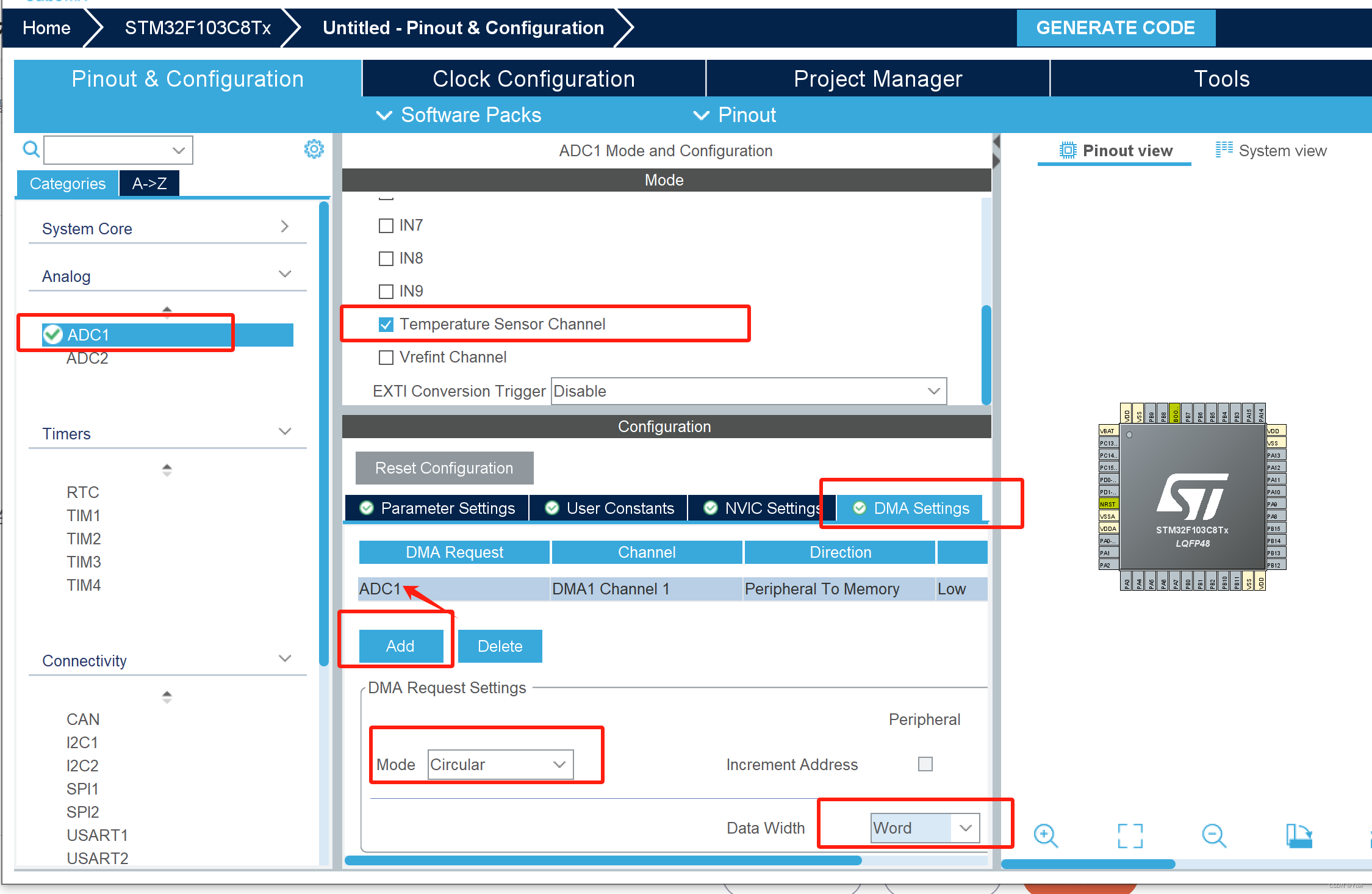
一、第一种方法,需要下载各种包:
要用到一个大佬的开源,GitHub地址如下:
https://github.com/wang-xinyu/tensorrtx/tree/master/yolov5
1. 安装pycuda,在线安装pycuda
pip3 install pycuda2. Windows操作(为了得到加速后的wts)
1.YOLOv5-7.0的原版的开源程序
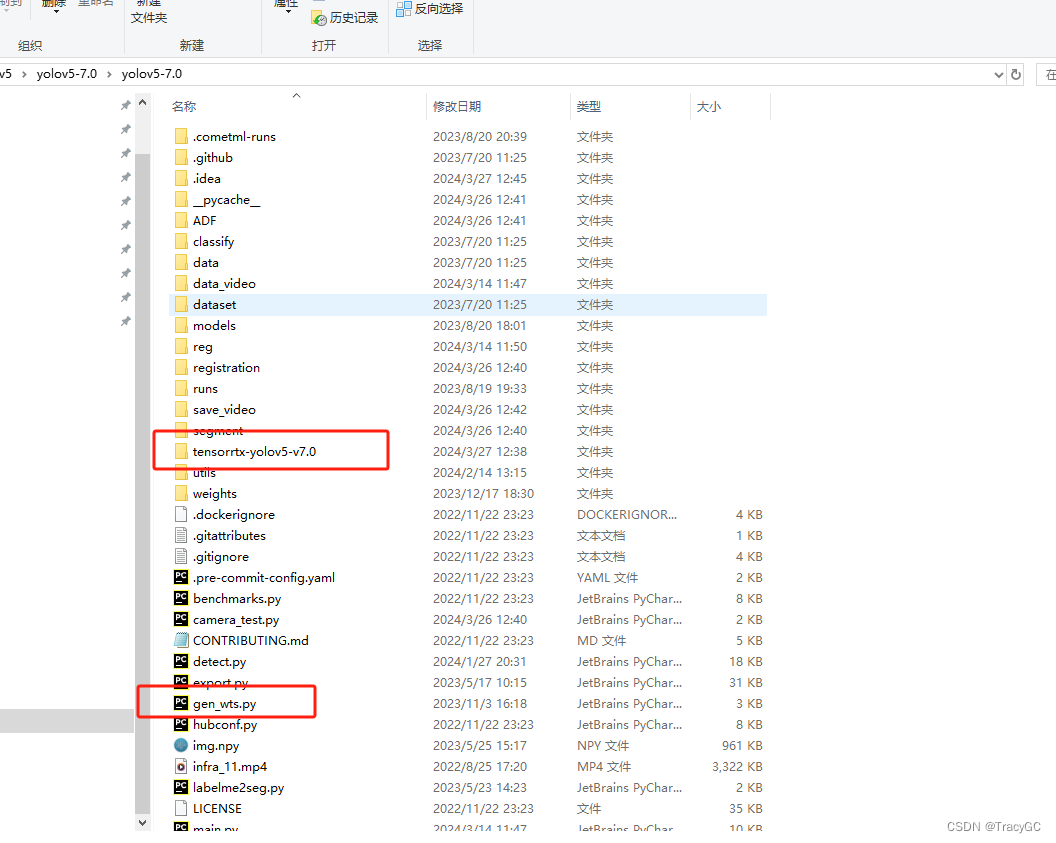
2. 将大佬开源的项目tensorrtx,下载到自己的windows电脑上
然后,把tensorrtx文件夹整体,复制粘贴到yolov5-7.0原版程序的文件夹中。再把tensorrtx-yolov5-v7.0\yolov5\gen_wts.py复制粘贴到yolov5原版文件夹中。
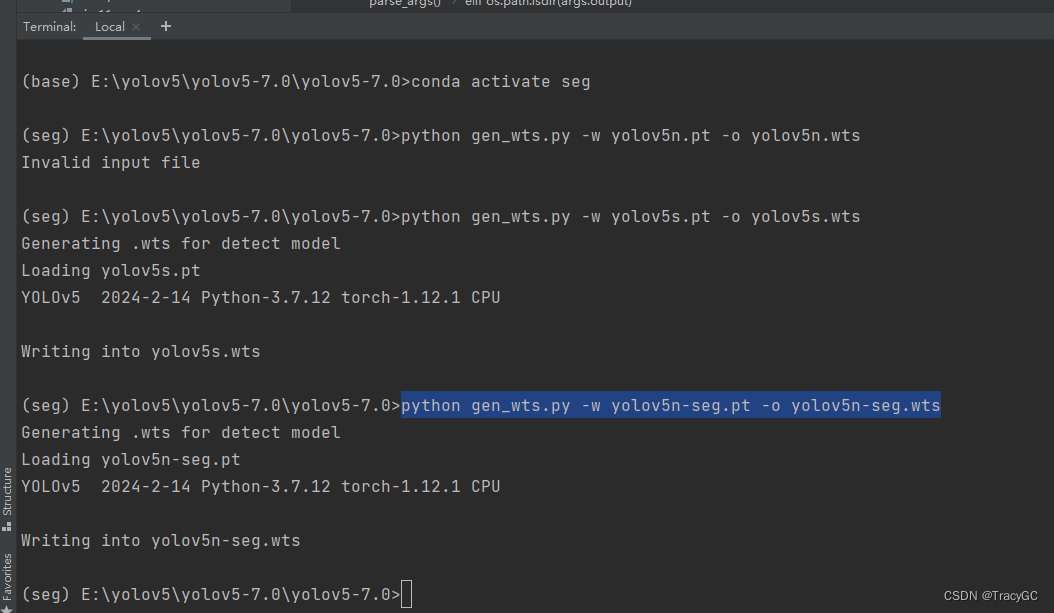
然后打开终端,激活在anaconda中自己创建的虚拟环境,输入命令:
python gen_wts.py -w yolov5n-seg.pt -o yolov5n-seg.wts因为我是需要YOLOV5-n模型的实例分割检测,所以生成的是yolov5n-seg.wts
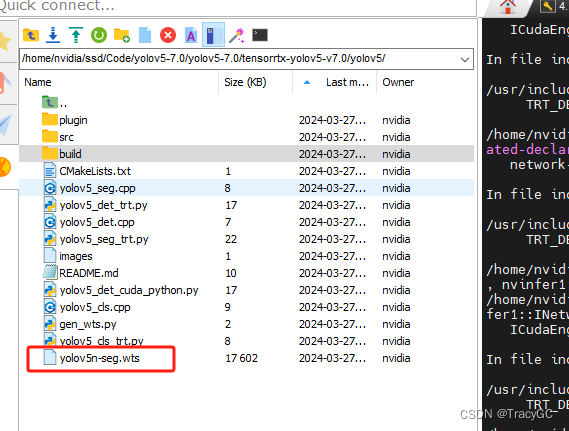
3. Unbtun操作(在Jetson orin上弄)(这一步是生成引擎文件)
将上述生成的.wts文件复制到Jetson orin里的yolov5-7.0\tensorrtx-yolov5-v7.0\yolov5文件夹中。
在上述文件夹中打开终端,依次运行指令:
mkdir build
cd build
cmake ..
make
sudo ../yolov5_seg -s ../yolov5s-seg.wts yolov5s.engine s因为在初始的里面是s模型,想要改成n模型:
1. 进入src/config.h,修改一下自己的检测类别和图片大小
kNumClass改成5,kInputH和kInputW改成640*512,kClsInputH = kInputH*depth_scale, kClsInputW = kInputW *width_scale。我是n模型,所以是depth_scale=0.33,width_scale=0.25,
constexpr static int kNumClass = 5;
constexpr static int kInputH = 640;
constexpr static int kInputW = 512;
constexpr static int kClsInputH = 212;
constexpr static int kClsInputW = 128;2. 打开build/yolov5_seg.cpp,找到主函数进行文件路径修改
std::string wts_name = "./yolov5n-seg.wts"; //wts文件
std::string engine_name = "./yolov5n-seg.engine"; // 生成engine
std::string labels_filename = "classes.txt"; //里面存放标签目录下的txt
float gd = 0.33, gw = 0.25; # 改成n模型的宽度深度
std::string img_dir "/home/nvidia/ssd/Code/yolov5-7.0/yolov5-7.0/dataset/images/val/" ; //测试图片文件夹
std::string modelcheck=-s”://-s生成engine, -d 推理在终端命令:
sudo ../yolov5_seg -s ../yolov5n-seg.wts yolov5n.engine s二、另一种方法:主目录的export.py(最简单)
主目录里有export.py,可以直接调用tensorRT包实现把模型从xx.pt到xx.engine的转换,非常方便,不需要其他操作。并且jetson orin有自带的tensorRT包,只需要和我们的conda环境里的包的安装目录建立软连接即可。
软连接:(从其他文章看的,因为我之前已经下载了pycuda,不用软链接了)
sudo ln -s /usr/lib/python3.6/dist-packages/tensorrt* /home/alen123/archiconda3/envs/yolov5/lib/python3.6/site-packages
查看tensorRT版本:
>>> python
>>> import tensorrt
>>> tensorrt.__version__
完成上面工作之后,tensorRT已经作为一个包可以直接调用了,然后直接在终端执行以下代码:
python export.py --weights yolov5n-seg.pt --include engine --
device 0
想要在开发板上跑时有更快的速度可以加--half,降低精度的,同时可以显著提高速度:
python export.py --weights yolov5n-seg.pt --include engine --half --device 0
遇到下面的问题:
ONNX: export failure ❌ 0.0s: /usr/lib/aarch64-linux-gnu/libstdc++.so.6: version `GLIBCXX_3.4.29' not found (required by /home/nvidia/ssd/anaconda3/lib/libprotobuf.so.31)
TensorRT: starting export with TensorRT 8.2.1.8...
TensorRT: export failure ❌ 0.1s: failed to export ONNX file: yolov5n-seg.onnx
是因为使用的是Jeston Orin
改成:
python3 export.py --weights yolov5n-seg.pt --include onnx --data my.yaml --half --device 0 --batch-size 4
trtexec --onnx=yolov5n-seg.onnx --fp16 --saveEngine=yolov5n-seg_static.engine --useCudaGraph使用的时候就把weight改成yolov5n-seg_static.engine就可以啦