机器人寻路算法双向A*(Bidirectional A*)算法的实现C++、Python、Matlab语言
最近好久没更新,在搞华为的软件挑战赛(软挑),好卷只能说。去年还能混进32强,今年就比较迷糊了,这东西对我来说主要还是看运气,毕竟没有实力哈哈哈。
但是,好歹自己吭哧吭哧搞了两周,也和大家分享一下自己的收获吧,希望能为后来有需要的同学提供一些帮助。
我其实不太了解寻路算法的,很多代码也是找的demo自己改的,非常感谢这些大佬的帮助,有些引用可能现在也找不太到了,列不出来,非常感谢万能网友的代码,在此一起感谢啦!部分参考如下:
A*算法路径规划之Matlab实现
A算法路径规划博文附件1.zip
基于matlab的双向A*算法
【路径规划】A*算法方法改进思路简析
等等等
代码和运行资源下载:机器人寻路算法双向A*(Bidirectional A*)算法的实现C++、Python、Matlab语言
目录
- 机器人寻路算法双向A*(Bidirectional A*)算法的实现C++、Python、Matlab语言
- 1、基于Matlab的双向A*寻路算法
- 1.1、基本地图
- 1.2、非联通区域的地图处理
- 1.3、双向A*寻路算法Matlab实现
- 1.4、双向A*寻路算法的加速小TIPS
- 1.5、现存的问题
- 2、双向A*寻路算法的C++实现
- 2.1、在C++得到类似结果
- 2.2、得到最大联通区域地图
- 2.3、有限时间的寻路计算
- 2.4、使用历史路网结构
- 2.5、中转站机制
- 2.6、一坨稀烂的机器人防碰撞
- 2.7、提前规划路径
- 2.8、运行前修改main.h的日志导出路径,不然报错
- 3、双向A*寻路算法的python实现
1、基于Matlab的双向A*寻路算法
C++的代码也是用Matlab导出的,因此实现的功能是相近的。
1.1、基本地图
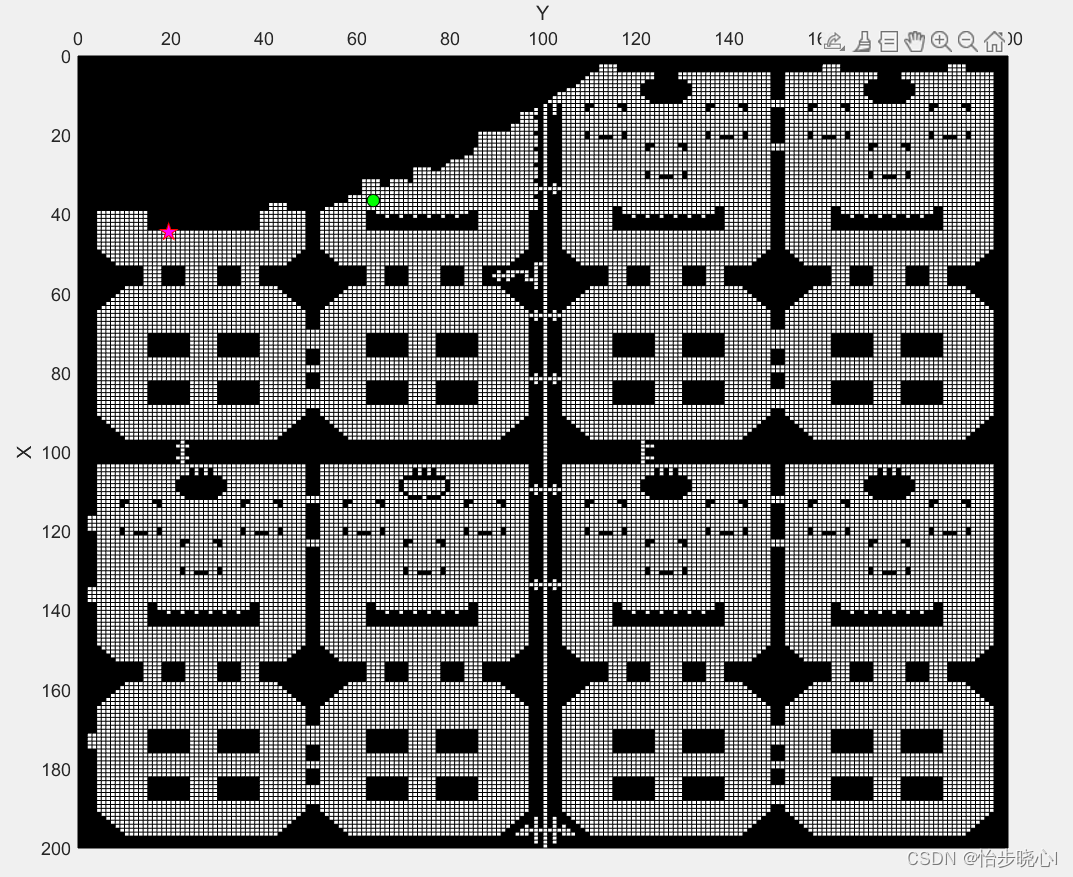
这是我主要改的地方,C++的代码也是用这个Matlab导出去的。首先就是读入地图数据,华为任务书里面写了对应的格式。给出的地图原始格式为txt,有200行200列,代表200*200的地图(第一行代表横坐标为0,纵坐标为0-199,以此类推),海洋和障碍是不能走的地方,泊位、空地都是能够行走的。

在实际的地图中,我们只考虑实际的空地和障碍,实际的空地包括泊位、空地,实际的障碍包括海洋和障碍,得到的地图如下所示:
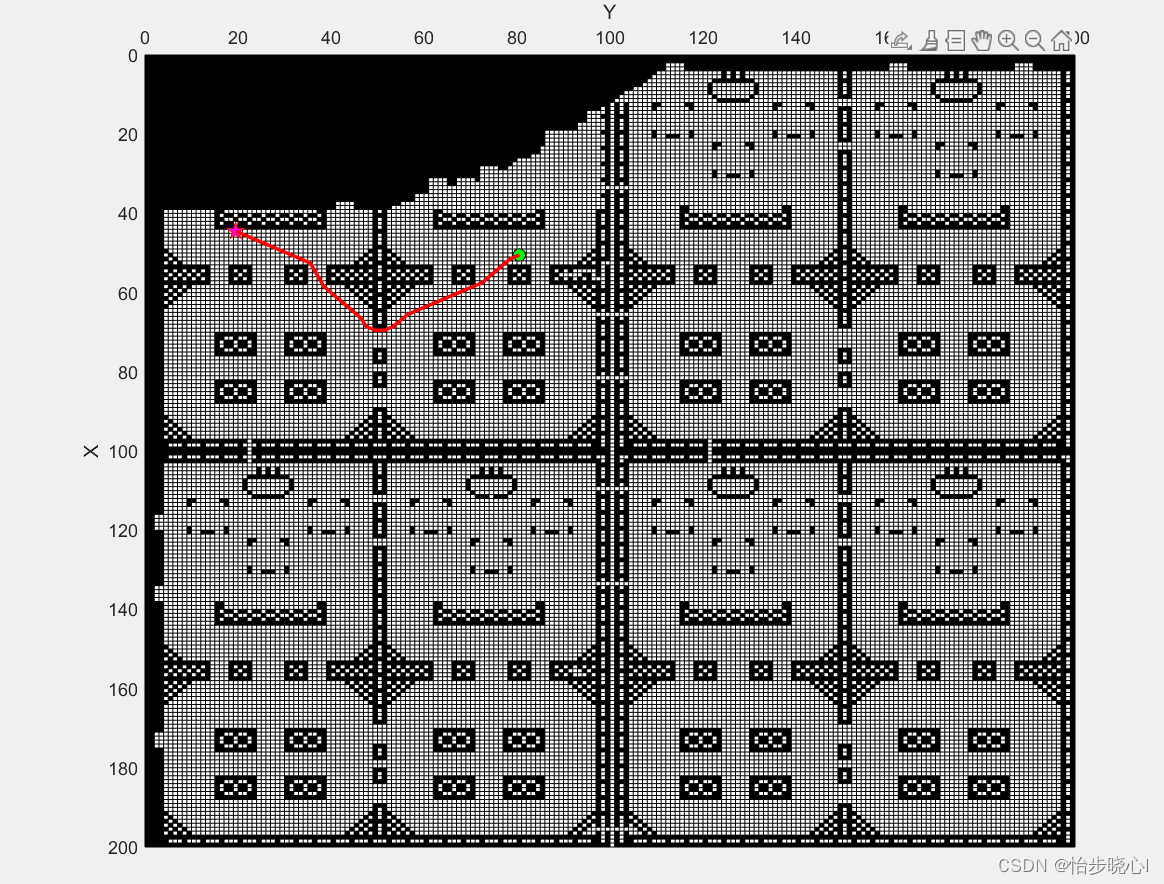
地图的读取主要使用了下面的核心代码:
%% 双向A星24域
% 读入的sign就是对应的格子图
[sign] = readHWmap('map1.txt');
% 定义地图的宽
row=200;
col=200;
% 寻路的起点和终点坐标
start_xy=[44 19];
end_xy=[50 80];
1.2、非联通区域的地图处理
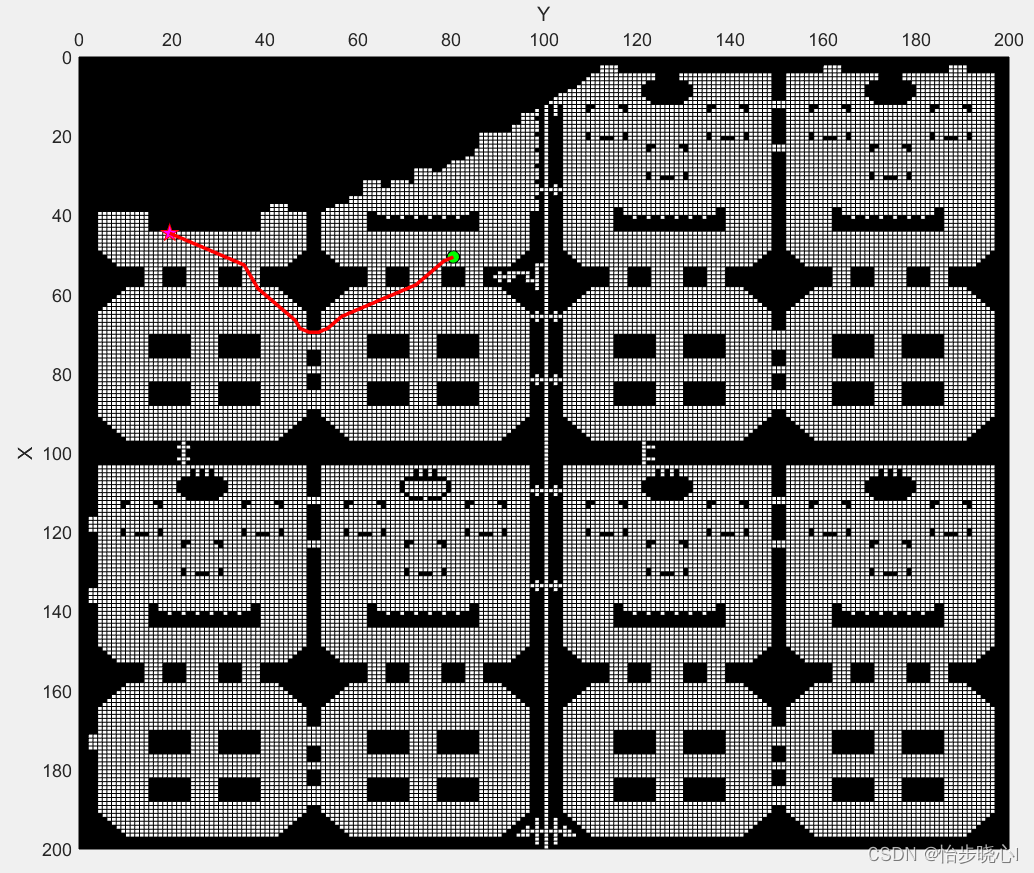
值得注意的是,上面地图中有些空地是被障碍物包围的,因此无法到达。因此我对初始地图进行了处理,获得最大的联通区域(使用搜索算法)。这一步可以在地图初始化的时候进行:
% 得到和坐标【66,66】相连的大联通区域,避免不可达到的空地影响
[sign,area]=getAllOb(sign,66,66);
处理后得到的地图如下所示,可以看到不可抵达的空地全部使用障碍来填充了:
1.3、双向A*寻路算法Matlab实现
A*算法是一种传统的路径规划算法,相较于Dijkstra算法,其引入了启发式算子,有效的提高了路径的搜索效率。主要步骤包括:
1)设置起始点、目标点以及带障碍物的栅格地图
2)选择当前节点的可行后继节点加入到openlist中
3)从openlist中选择成本最低的节点加入closelist节点
4)重复执行步骤2和步骤3,直到当前节点到达目标点,否则地图中不存在可行路径
5)从closelist中选择从起点到终点的路径,并画图展示
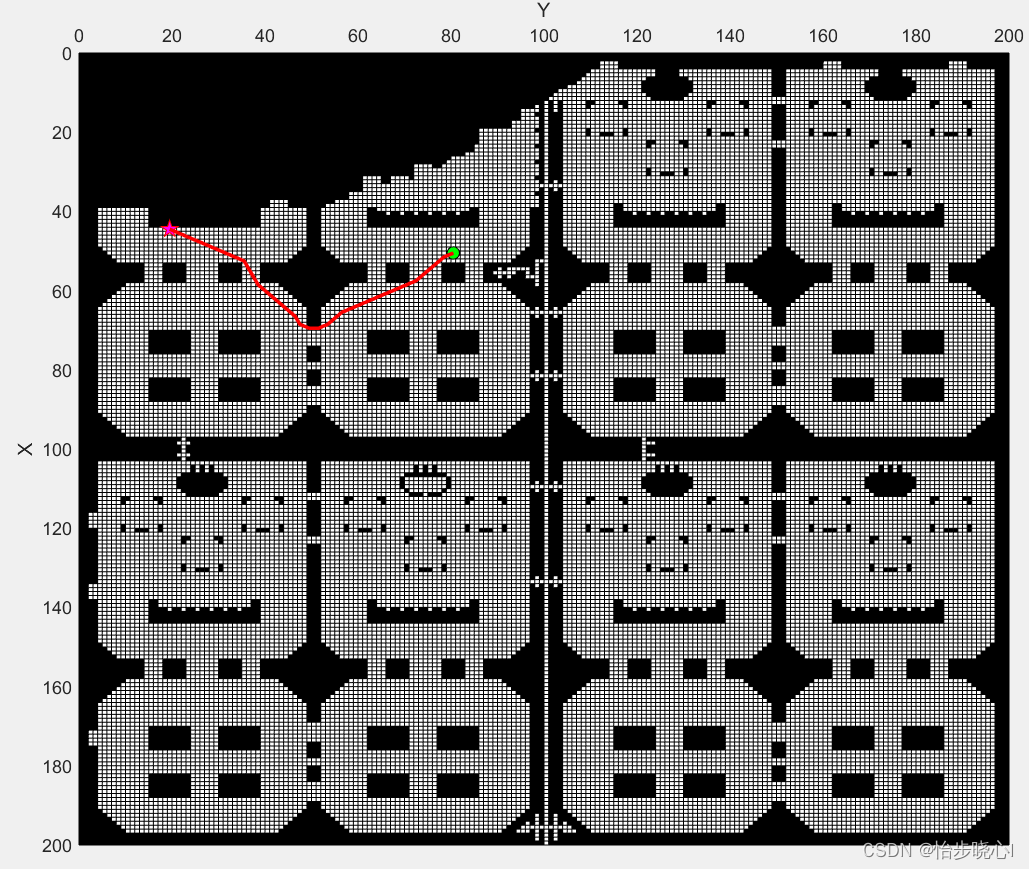
传统A* 算法从起点开始搜索,而双向A*从起点和终点同时开始搜索,所以运算速度会大大加快。以华为的地图为例,按照下面设置起点和终点:
% 寻路的起点和终点坐标
start_xy=[44 19];
end_xy=[50 80];
最终得到的结果如下所示:
1.4、双向A*寻路算法的加速小TIPS
1、扩展邻域法
扩展邻域法的思想是通过提高单次邻域的搜索范围,从而减少整个过程中的搜索次数,从而降低计算量。此处实现使用的是24邻域。
但是24邻域和此处网格机器人不太一样,网格机器人只能上下左右移动,所以从物理上看只能有四邻域。使用24邻域能够加快搜索速度,但是在实际控制时需要额外的判断。
因此,我在实际实现时是使用双向Astar算法得到关键的路径节点,但是机器人的实际行动是用Astar算法控制的。因为双向Astar算法得到的节点之间的距离都非常近,在此基础上使用A*算法进行二次寻路和避障速度比较快(把其他机器人当成障碍物来避障)。
2、有限区域初始化搜索
我们知道地图时非常大的,每次进行Astar算法的搜索都要进行很多的数组的初始化。按照此处的地图大小,是200*200的,一共有40000个数据。
所以在实际搜索时,我先依据起点和终点的位置,并留出一定的余量,从大地图中剥离出一个小地图,在这个小地图中进行搜索,这样速度会提升20-50%左右吧,起点和终点横跨的区域越小,这样做的优势就越明显。
实际实现留出的余量是这个参数:
% 在有些区域内使用算法加快速度,起点终点所含区域向外衍生20格,改为200则使用全局寻路
area_shift=20;
1.5、现存的问题
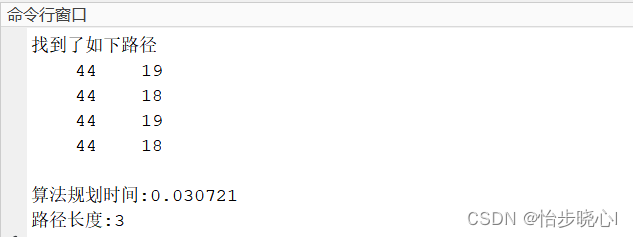
1、距离为1时进行搜索会抖动
但是我实际使用时发现在特别短的距离下寻路效果不好,会出现抖动的情况(不知道是不是代码问题),虽然长距离运算速度确实不错,例如我起点和终点的距离只差一格:
%% 双向A星24域
% 读入的sign就是对应的格子图
[sign] = readHWmap('map1.txt');
% 定义地图的宽
row=200;
col=200;
% 寻路的起点和终点坐标
start_xy=[44 19];
end_xy=[44 18];
得到的结果抖的不行,这是因为寻路是双向进行的,因此得到的最短的路径长度也是2,非常难受(但是只差1格感觉可以不用寻路了哈哈哈):
2、奇奇怪怪的点无法搜索得出路径
如果起点和终点弯弯绕绕,那么寻路算法最终会失败。这和路径的长短没有关系,而是看之间寻路的角度,这个现象非常奇怪,照理说Astar算法是100%可以寻到路径的,但是某项情况就是不行。我也试了一些其他的代码,都会寻路失败,C++代码里面也是这样,例如这样的:
% 寻路的起点和终点坐标
start_xy=[44 19];
end_xy=[36 63];
2、双向A*寻路算法的C++实现
此处我是使用Matlab的Coder Generater产生的C++代码,功能是一致的,简单介绍一下调试的流程和小小的优化。
2.1、在C++得到类似结果
正常来说,调用地图数据是软挑配套的脚本提供的,但是为了调试需要,我直接把地图1的数据存入C文件,这样可以直接debug调用了。
debug时,没有输入和输出内容,因此需要在和官方判题器交互之前打上断点,debug的内容在sys_fun.cpp中实现。
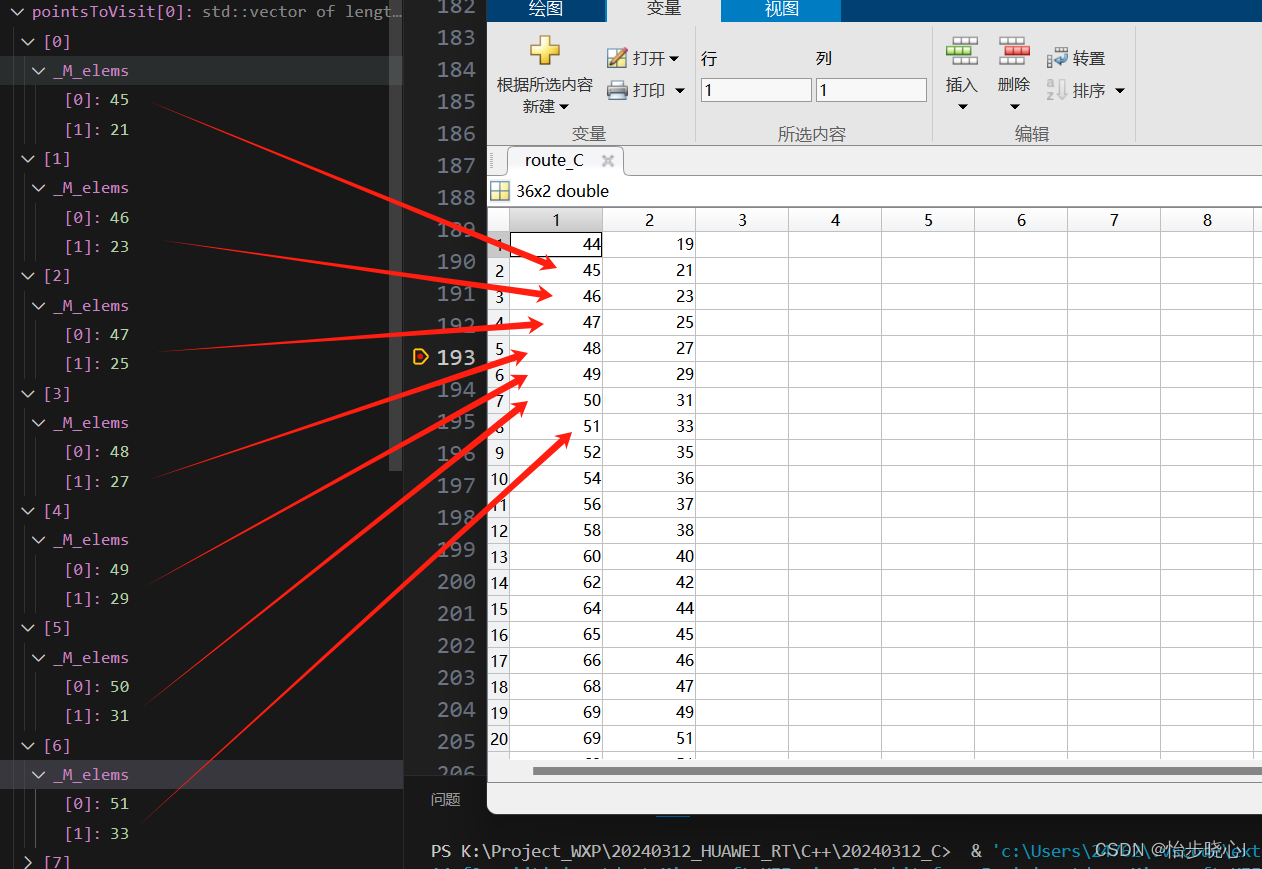
简单的测试代码如下,寻路结果保存在pointsToVisit[0]中:
std::vector<std::vector<int>> mapdata_matrix_tmp(SIZE_MAP, std::vector<int>(SIZE_MAP, 0));
signed char mapdata_vector_tmp[SIZE_MAP*SIZE_MAP];
findRouteOKFlag=FLAG_END;
// 得到最大联通区域
getAllOb(map1_test, 66, 66, mapFindRouteAStat, obstaclesCoords);
// mapFindRouteAStat转化为二维地图数组
int index111 = 0;
for (int i = 0; i < SIZE_MAP; ++i) {
for (int j = 0; j < SIZE_MAP; ++j) {
Map1_2D_Bit[j][i] = mapFindRouteAStat[index111];
Map1_2D_Char[j][i] = mapFindRouteAStat[index111];
index111++;
}
}
// 得到地图所有障碍的索引
find_nonzero_indices(mapFindRouteAStat, map_Ind1, map_Ind2);
// 历史路网数据复位
initRouteMemory();
//下面一行打开则使用历史的路网结构
// loadRouteMemory();
//定义起点和终点,寻路结果保存在pointsToVisit[0]
int start_xy_int[] = {44,19};
int end_xy_int[] = {50,80};
RobotTowardResource destination;
destination.x = end_xy_int[0];
destination.y = end_xy_int[1];
robotDestinations[0].push_back(destination);
getRoutePath(start_xy_int, end_xy_int,0);
if(!myFindRouteTask.empty())
{
float start_xy[2]={myFindRouteTask[0][0],myFindRouteTask[0][1]};
float end_xy[2]={myFindRouteTask[0][2],myFindRouteTask[0][3]};
//初始化任务
findroute_limit_Init(start_xy,end_xy, 20, SIZE_MAP, SIZE_MAP,myFindRouteTask[0][4]);
myFindRouteTask.erase(myFindRouteTask.begin());
}
while(findRouteOKFlag==FLAG_RUNNING)
{
findroute_limit(mapFindRouteAStat, map_Ind1,map_Ind2, route_debug, &dis);
}
可以看到得到的结果和Matlab中的一致。
2.2、得到最大联通区域地图
值得注意的是,上面地图中有些空地是被障碍物包围的,因此无法到达。因此我对初始地图进行了处理,获得最大的联通区域。在C++中,这个实现对应下面的语句:
getAllOb(map1_test, 66, 66, mapFindRouteAStat, obstaclesCoords);
其中map1_test是我预存的地图数据,是1 * 40000的数组,相当于把200 * 200的地图数据展平了,数据中只包含0,1。0表示可以通过,1表示为障碍。mapFindRouteAStat是处理后的1*40000的地图,和map1_test的区别就是不可到达的空地也被视为了障碍。
为了方便使用二维索引,把这个数据转化为了二维数组:
// mapFindRouteAStat转化为二维地图数组
int index111 = 0;
for (int i = 0; i < SIZE_MAP; ++i) {
for (int j = 0; j < SIZE_MAP; ++j) {
Map1_2D_Bit[j][i] = mapFindRouteAStat[index111];
Map1_2D_Char[j][i] = mapFindRouteAStat[index111];
index111++;
}
}
下面的索引计算相当于对地图障碍位置预先存入数组了,之后直接调用就行,方便加速计算:
// 得到地图所有障碍的索引
find_nonzero_indices(mapFindRouteAStat, map_Ind1, map_Ind2);
2.3、有限时间的寻路计算
在寻路时需要考虑到实时性的要求,寻路的函数被封装为了,其中前两个参数为起点和终点,最后一个参数表示是为第几个机器人寻路的,寻路完成后路径会直接加到目标机器人要走的路径上去:
getRoutePath(start_xy_int, end_xy_int,0);
getRoutePath函数并非直接调用了双向Astar寻路算法。函数中,对于较短的路径,一次性使用双向Astar得到路径:
//距离短直接进行运算得到结果
// OutputData(LOG_PATH,0,"Direct Found Begin %f %f %f %f\n",start_xy_float[0],start_xy_float[1],end_xy_float[0],end_xy_float[1]);
std::vector<std::array<float, 2>>pointstovisit_tmp;
findroutevalid=findroute_Direct(start_xy_float,end_xy_float, FIND_ROUTE_AREA_SHIFT,
SIZE_MAP, SIZE_MAP, mapFindRouteAStat, map_Ind1,map_Ind2, route_debug, &dis,pointstovisit_tmp,robot_id);
if(!findroutevalid)
{
//没有找到路径
OutputData(LOG_PATH,0,"ID:%d Direct Found error\n");
}
else
{
pointsToVisit[robot_id].insert(pointsToVisit[robot_id].end(), pointstovisit_tmp.begin(), pointstovisit_tmp.end());
OutputData(LOG_PATH,0,"ID:%d %f %f %f %f\n",frame_ID,pointsToVisit[robot_id][0][0],pointsToVisit[robot_id][0][1],pointsToVisit[robot_id][1][0],pointsToVisit[robot_id][1][1]);
}
对于较长的路径,如果要进行寻路,则会将创建一个任务列队,每次只运算有限的时间,这主要是考虑实时控制的要求:
myFindRouteTask.push_back({start_xy_float[0],start_xy_float[1],end_xy_float[0],end_xy_float[1],float(robot_id)});
模拟处理寻路任务时,其中while(findRouteOKFlag==FLAG_RUNNING)是模拟每帧不断处理的情况,事实上,每帧运行一次findroute_limit函数即可,因为函数中使用了std::chrono来限制每次运算的时间:
if(!myFindRouteTask.empty())
{
float start_xy[2]={myFindRouteTask[0][0],myFindRouteTask[0][1]};
float end_xy[2]={myFindRouteTask[0][2],myFindRouteTask[0][3]};
//初始化任务
findroute_limit_Init(start_xy,end_xy, 20, SIZE_MAP, SIZE_MAP,myFindRouteTask[0][4]);
myFindRouteTask.erase(myFindRouteTask.begin());
}
while(findRouteOKFlag==FLAG_RUNNING)
{
findroute_limit(mapFindRouteAStat, map_Ind1,map_Ind2, route_debug, &dis);
}
实际运行处理时的函数是这样的:
void findLongRouteTask(void)
{
//如果正在计算
if(findRouteOKFlag==FLAG_RUNNING)
{
findroute_limit(mapFindRouteAStat, map_Ind1,map_Ind2, route_debug, &dis);
findLongRouteTask_Time++;
//计算超时,不再计算了to do导出计算超时的点路径,超时导致不会再计算?
if(findLongRouteTask_Time>500)
{
findRouteOKFlag=FLAG_END;
findLongRouteTask_Time=0;
//一定删除目标点!!!!!!!!!!!!!!!!!!!!!!其实就是最后一个
OutputData(LOG_LONG_PATH,0,"ID:%d robotID:%d findLongRouteTask END OVERTIME\n",frame_ID,robotFindRouteID);
robotDestinations[robotFindRouteID].erase(robotDestinations[robotFindRouteID].end());
}
if(frame_ID%100==0)
{
// OutputData(LOG_PATH,0,"ID:%d findLongRouteTask ing\n",frame_ID);
}
}
else
{
// OutputData(LOG_PATH,0,"ID:%d findLongRouteTask FREE\n",frame_ID);
//空闲则判断是否有任务没有完成
//有任务没有执行完成
if(!myFindRouteTask.empty())
{
findLongRouteTask_Time=0;
float start_xy[2]={myFindRouteTask[0][0],myFindRouteTask[0][1]};
float end_xy[2]={myFindRouteTask[0][2],myFindRouteTask[0][3]};
//初始化任务
findroute_limit_Init(start_xy,end_xy, 20, SIZE_MAP, SIZE_MAP,myFindRouteTask[0][4]);
myFindRouteTask.erase(myFindRouteTask.begin());
OutputData(LOG_LONG_PATH,0,"ID:%d robotID:%d findLongRouteTask Begin sx%f sy%f ex%f ey%f\n",
frame_ID,robotFindRouteID,start_xy[0],start_xy[1],end_xy[0],end_xy[1]);
}
}
}
2.4、使用历史路网结构
loadRouteMemory();函数会加载历史走过的路径数据,因此曾经走过的路径不再需要寻路了。getRoutePath(start_xy_int, end_xy_int,0);函数会判断这条寻路能否使用历史的路网数据。
主要加载的数据有这三个,在main.h中设置导出路径,会把历史的寻路数据直接导出来txt,加到Cpp文件就行了,非常方便:

简单介绍这三个的含义,routeMemoryBufTmp是路径数据,所有路径数据都存在这里面。
routeMemoryLengthBufTmp是每条路径的长度,知道了了长度就能把routeMemoryBufTmp的全部路径的数据进行恢复了。
unReachablePointTmp是寻路失败的目标点,如果这些点产生了货物,那么就会忽略这些货物。
float routeMemoryBufTmp[]={};
std::vector<int> routeMemoryLengthBufTmp={};
std::vector<int> unReachablePointTmp={};
加载的代码如下:
unsigned int index_tmp=0;
//赋值给要走的路径
for(int j=0;j<routeMemoryLengthBufTmp.size();j++)
{
for(int i=0;i<routeMemoryLengthBufTmp[j];i++)
{
routeMemoryBuf[j].push_back({routeMemoryBufTmp[0+2*index_tmp], routeMemoryBufTmp[1+2*index_tmp]});
//涂黑路径边沿,方便进行路径重新调用
setBitsAroundPosition(routeMemoryIndex[routeMemoryBufSize],
routeMemoryBuf[routeMemoryBufSize][i][0], routeMemoryBuf[routeMemoryBufSize][i][1], ROUTE_MEMORYBUF_DIFFUSION);
index_tmp++;
}
routeMemoryBufSize=routeMemoryBufSize+1;
}
for(int j=0;j<unReachablePointTmp.size();j=j+2)
{
deletedTargets.push_back({unReachablePointTmp[j],unReachablePointTmp[j+1]});
}
我设置最多可以存储20000条历史路网数据,路网数据的索引使用了一点小技巧来加速。对于每个搜索得到的路网数据,我都创建了一个200x200的bit数组routeMemoryIndex,将路径节点和节点周围N格的数据都设置为1,其余为0。这样我得到一个寻路任务时,我只需要判断起点和终点在这个200x200的bit数组中的位置是否为1,就能判断能否使用这条路径了。
//先判断能否使用现有的路网结构
for(int i=0;i<routeMemoryBufSize;++i)
{
if(routeMemoryIndex[i][start_xy[0]][start_xy[1]]==1&&routeMemoryIndex[i][end_xy[0]][end_xy[1]]==1)
{
routememoryindex_tmp=i;
//找到了现有路网,跳出For循环
break;
}
}
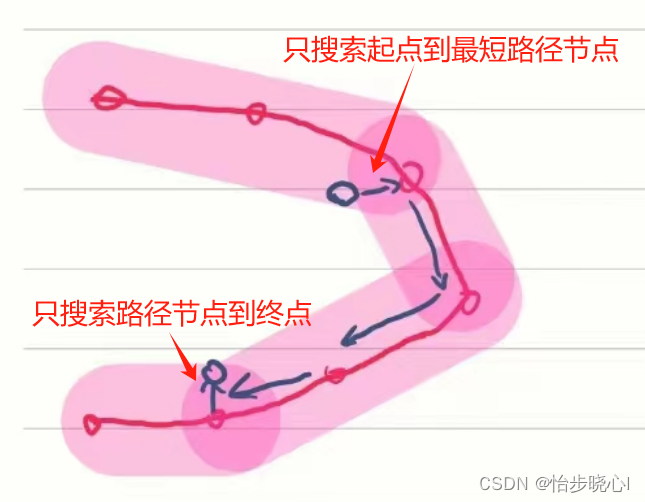
例如,红色为历史的路网数据。粉红色为将路径节点和节点周围N格的数据都设置为1的示意,在进行搜索时,如果起点和终点都位于一条路径的粉红色区域内,则判断为能使用这条历史路径,如蓝色圆圈所示的起点和终点。这样就会搜索起点到最短路径节点的距离,和终点到最短节点的距离,其余使用路网数据,由此可以省下许多时间。
2.5、中转站机制
奇奇怪怪的点无法搜索得出路径,那么我就设置了一个中转站机制,就是起点和终点位于给定区域的话,就先走到中转站,在前往目标点。但是这种方法逻辑复杂,唉,全书败笔,如果起点和终点分别位于station_area1、station_area2,那么就先前往中转区域station_area:
TransferStation station;
station.station_area1.clear();
station.station_area2.clear();
station.area1 = {{0, 0}, {100, 100}};
station.area2 = {{0, 100}, {100, 200}};
station.station_area1.push_back({{32, 94}, {35, 96}});
station.station_area1.push_back({{64, 93}, {66, 95}});
station.station_area1.push_back({{80, 92}, {82, 95}});
station.station_area2.push_back({{32, 105}, {35, 107}});
station.station_area2.push_back({{64, 105}, {66, 107}});
station.station_area2.push_back({{80, 105}, {82, 107}});
map1TransferStation.push_back(station);
使用getRoutePathByTransfer(start_xy_int, end_xy_int,0);在寻路时调用中转站,实际上是对getRoutePath的二次封装。
2.6、一坨稀烂的机器人防碰撞
我用双向Astar得到关键节点,机器人前往节点的具体行动使用Astar算法(因为这段非常好寻路的,距离很短且没有障碍),行动时将其他机器人当作障碍来避障,效果很差,主要是狭窄通道有问题,多个机器人堵起来也有问题。
寻路没问题,就是要撞起来!!!
2.7、提前规划路径
会提前为机器人规划路径加入缓存,比如说我正在去拿货物,会提前规划从货物到码头的路径节点等等。
2.8、运行前修改main.h的日志导出路径,不然报错
3、双向A*寻路算法的python实现
参考:https://blog.csdn.net/m0_56662453/article/details/126426863
大佬现成的代码,学习的。双向Astar相比Astar节省了50%的时间。