在开始之前,我先来给大家讲一下顺序表与链表的区别:

它们在堆上存储的差异:

我们可以很容易的知道,循序表是连续的有序的,但链表是杂乱的,它们通过地址彼此联系起来。
1. 链表的概念及结构
概念:链表是⼀种物理存储结构上⾮连续、⾮顺序的存储结构,数据元素的逻辑顺序是通过链表?
中的指针链接次序实现的。

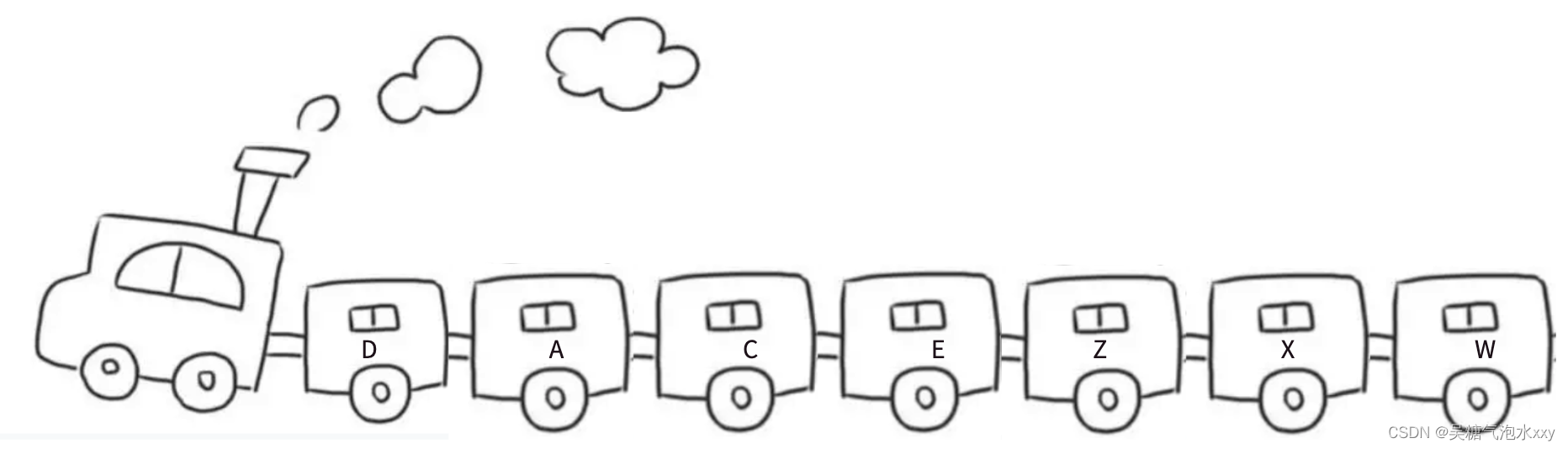
链表的结构跟⽕⻋⻋厢相似,淡季时⻋次的⻋厢会相应减少,旺季时⻋次的⻋厢会额外增加⼏节。只需要将⽕⻋⾥的某节⻋厢去掉/加上,不会影响其他⻋厢,每节⻋厢都是独⽴存在的。
⻋厢是独⽴存在的,且每节⻋厢都有⻋⻔。想象⼀下这样的场景,假设每节⻋厢的⻋⻔都是锁上的状态,需要不同的钥匙才能解锁,每次只能携带⼀把钥匙的情况下如何从⻋头⾛到⻋尾?
最简单的做法:每节⻋厢⾥都放⼀把下⼀节⻋厢的钥匙。
在链表⾥,每节“⻋厢”是什么样的呢?

与顺序表不同的是,链表⾥的每节"⻋厢"都是独⽴申请下来的空间,我们称之为“结点/节点”?
节点的组成主要有两个部分:当前节点要保存的数据和保存下⼀个节点的地址(指针变量)。
图中指针变量?plist保存的是第⼀个节点的地址,我们称plist此时“指向”第⼀个节点,如果我们希
望plist“指向”第⼆个节点时,只需要修改plist保存的内容为0x0012FFA0
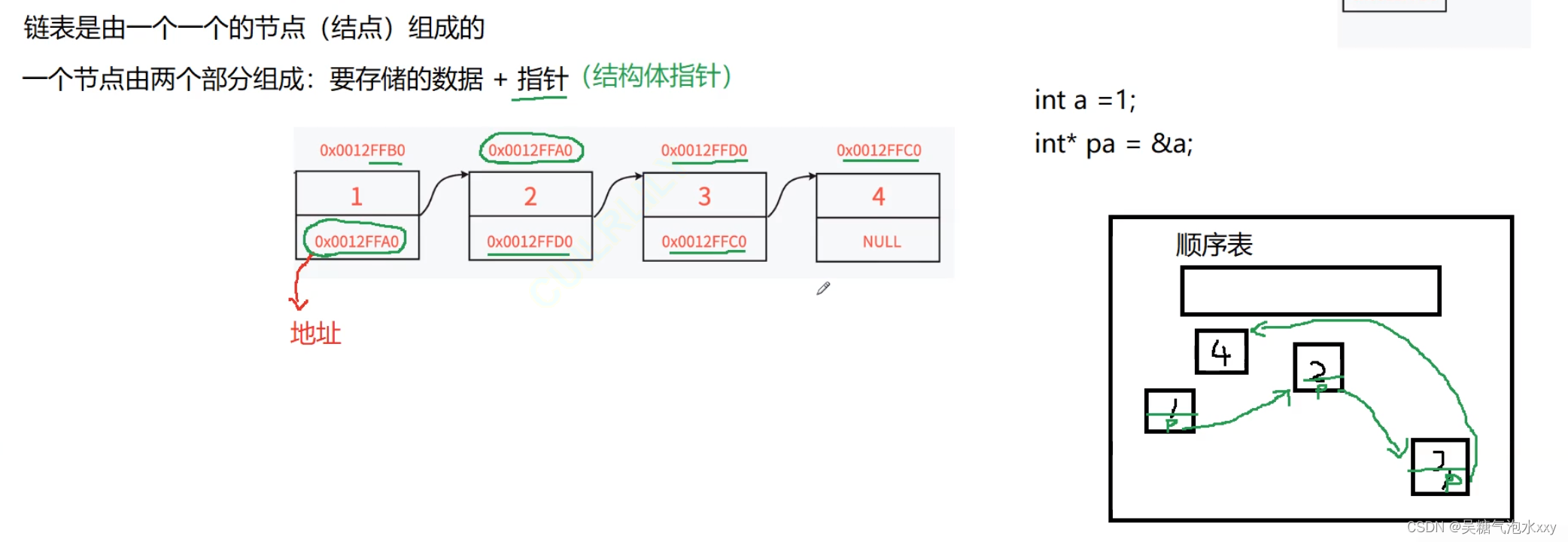
为什么还需要指针变量来保存下⼀个节点的位置?
链表中每个节点都是独⽴申请的(即需要插⼊数据时才去申请⼀块节点的空间),我们需要通过指针变量来保存下⼀个节点位置才能从当前节点找到下⼀个节点。
结合前⾯学到的结构体知识,我们可以给出每个节点对应的结构体代码:
假设当前保存的节点为整型:
struct SListNode
{
int data; //节点数据
struct SListNode* next; //指针变量⽤保存下⼀个节点的地址
};
struct SListNode*是一个结构体指针那我们现在开始进入正题吧。

2.链表的打印
给定的链表结构中,如何实现节点从头到尾的打印?

2.1节点的申请

由于我们不需要扩容,所以就使用 malloc。
2.2节点的链接

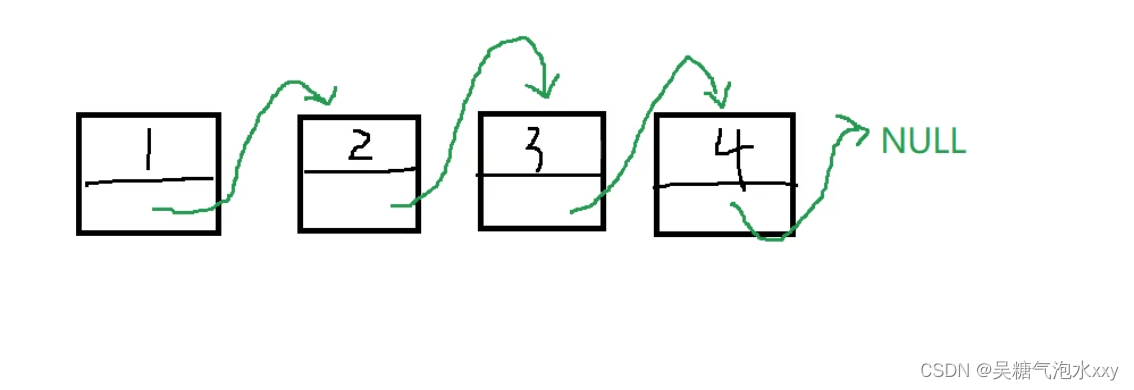
2.3打印过程
打印函数:


定义一个新的 plist 把第一个节点传过去。
我们来看一下结果:
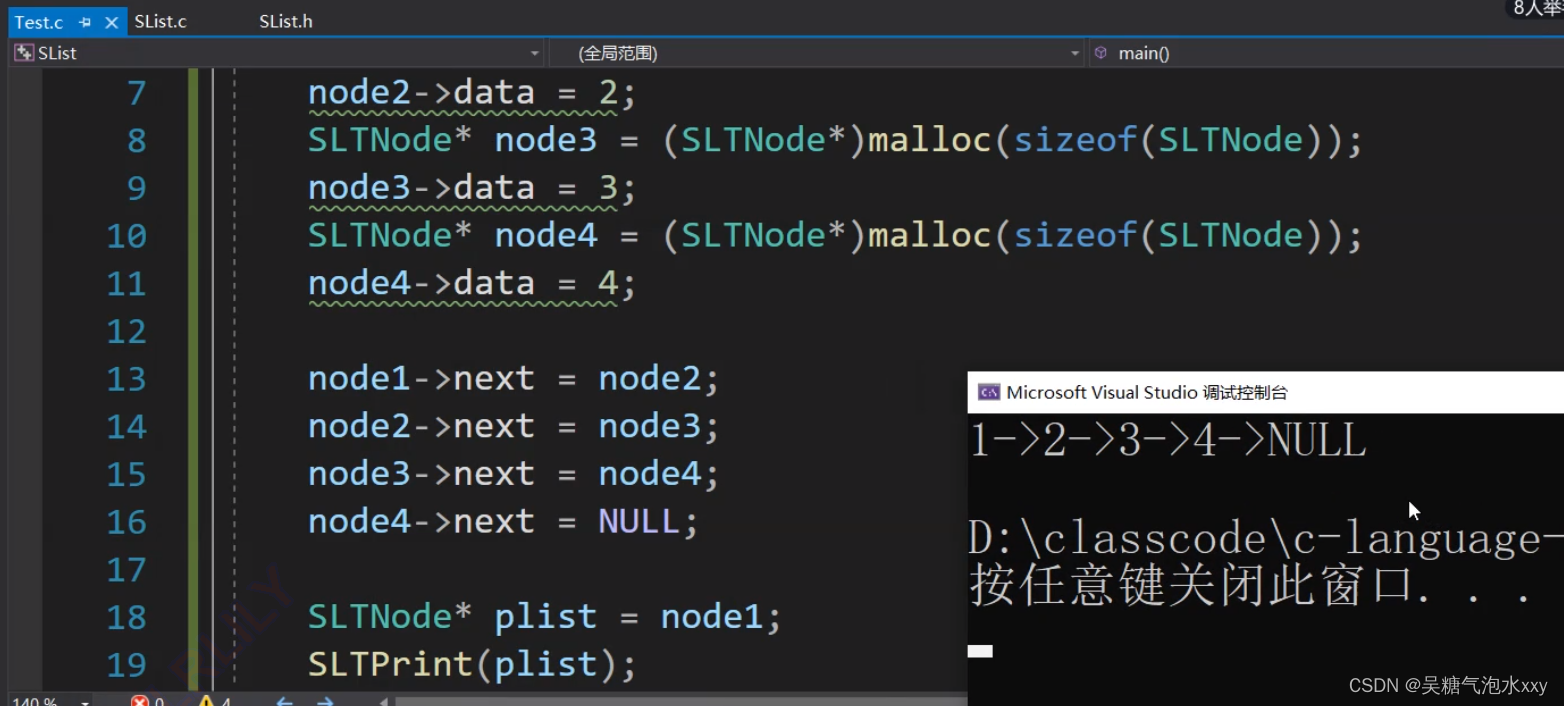
大家肯定会有疑问但是不用着急,我来为大家一点一点解释清楚。
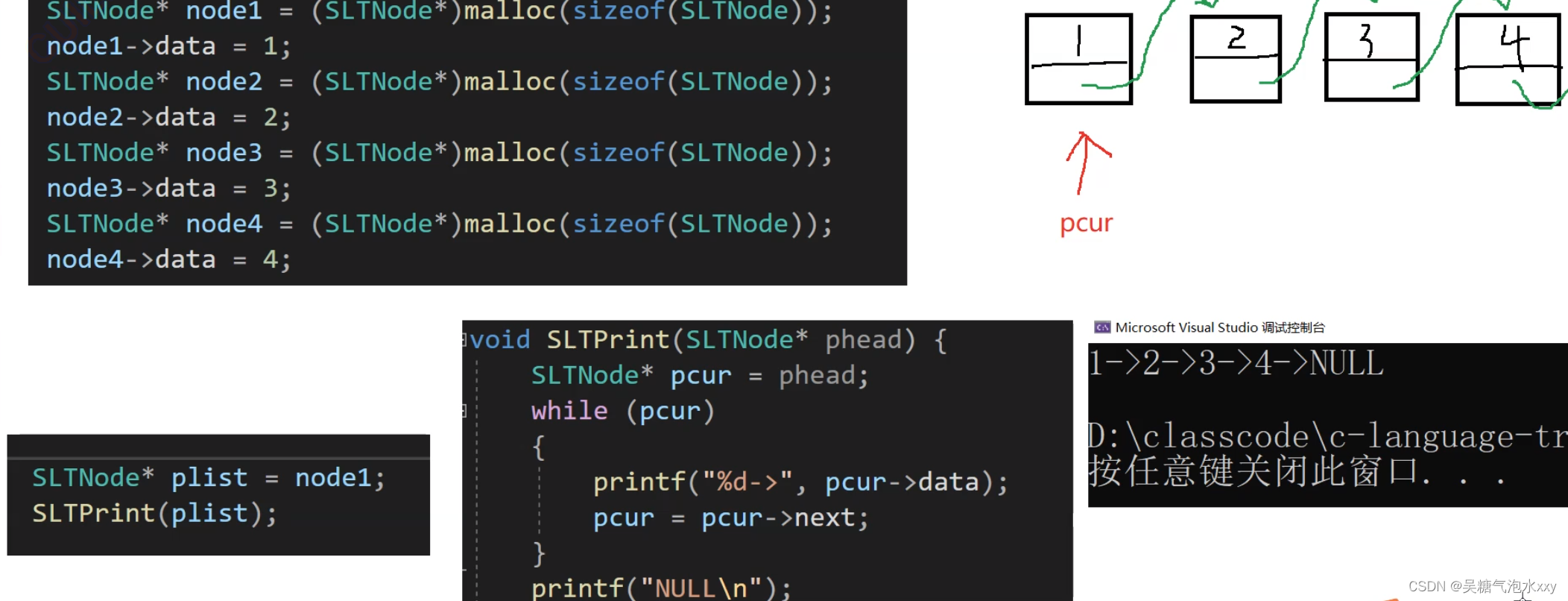
先来讲一下打印过程:

我们来看这段代码:

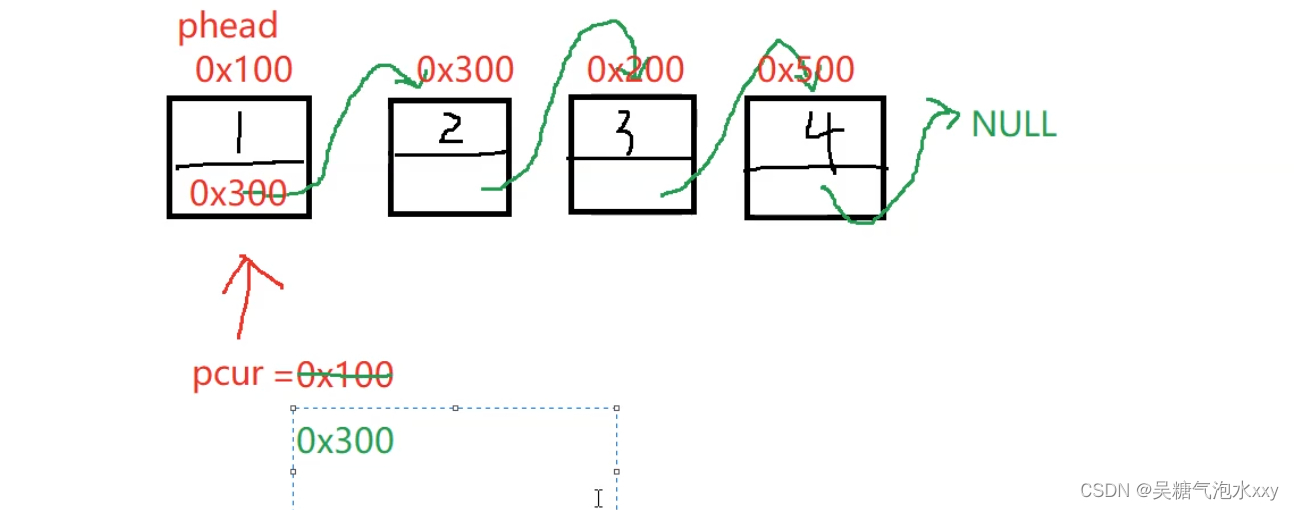
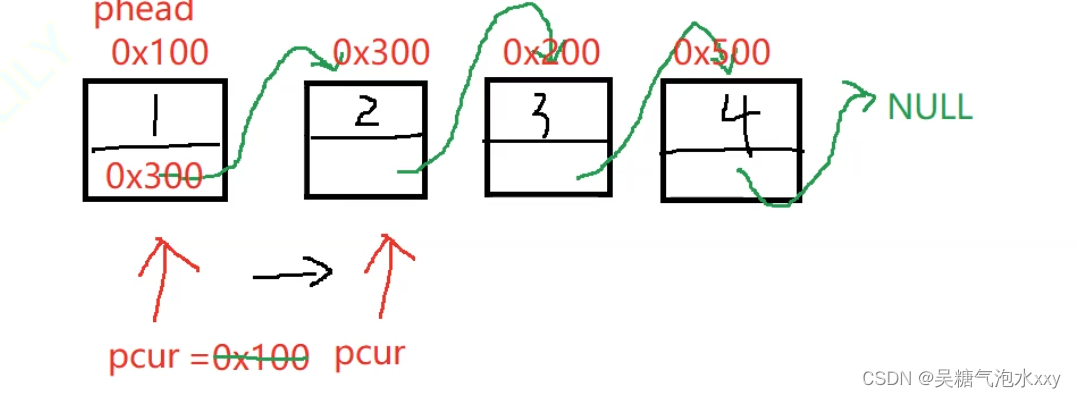
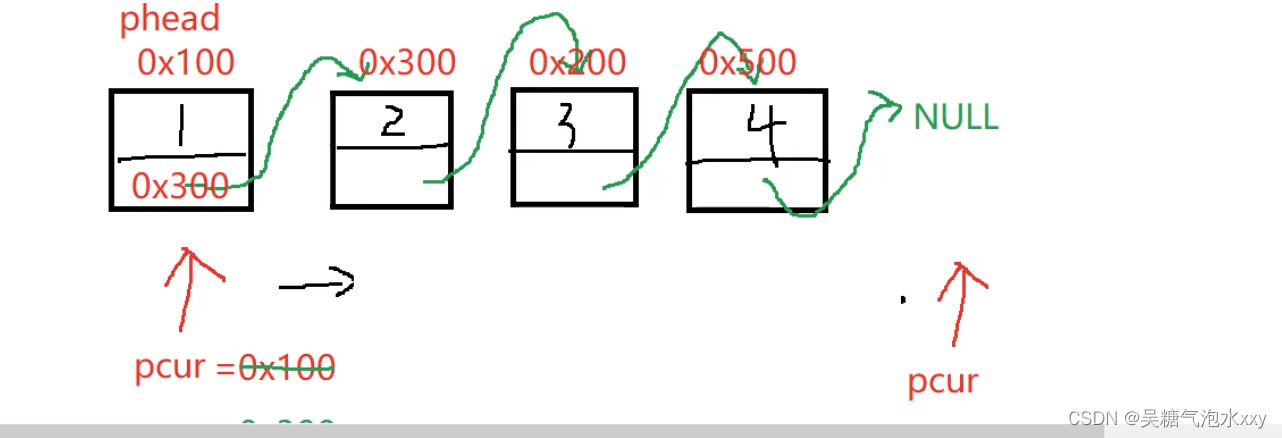
pcur 的运行过程:我们随便给几个地址更直观的来观察。
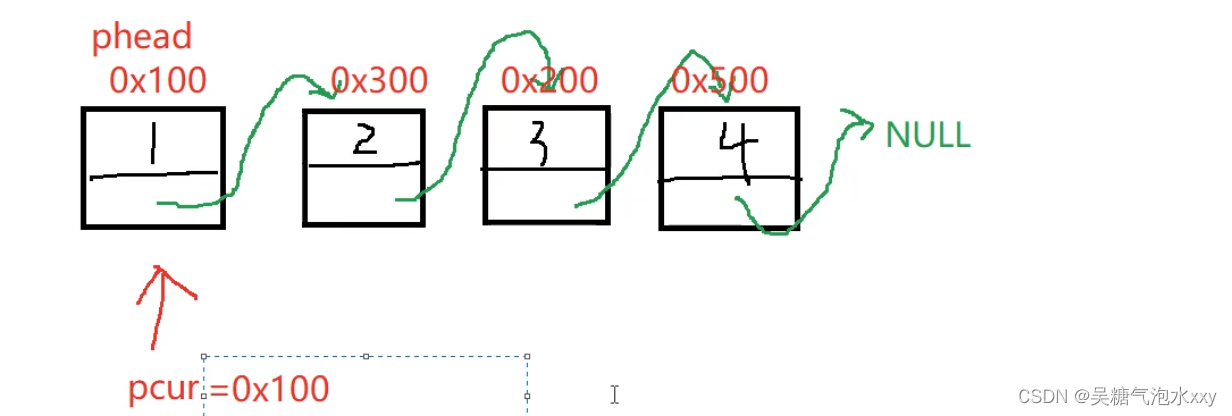
关键点拨:pcur刚开始保存第一个节点0x100, 此时指向第一个节点。
pcur = pcur -> next ; 此时 next 保存的是第二个节点的。
把第二个节点的地址赋给了 pcur 使向后移动指向第二节点。
以此类推这个过程就实现了节点的打印。


以上是链表的打印过程,现在我们来实现链表。
3.链表的实现
3.1 链表的头插和尾插
头插和尾插(顺序表)我们在上一篇博客中有讲解感兴趣的同学可以去看看,把链接放在这了。
CSDN
3.1.1尾插
3.1.1.1链表不为空
我们老样子画图来展示
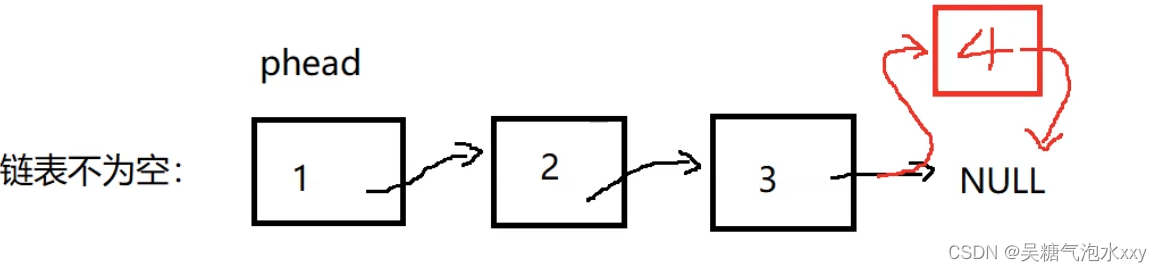
红色方块是我们插入的内容 ,那么怎么实现呢?
我们需要改变走向,使3后面的指向4,让4再去指向空。
3.1.1.2链表为空

我们之间创建一个4,让4的next指向NULL。
代码如下:
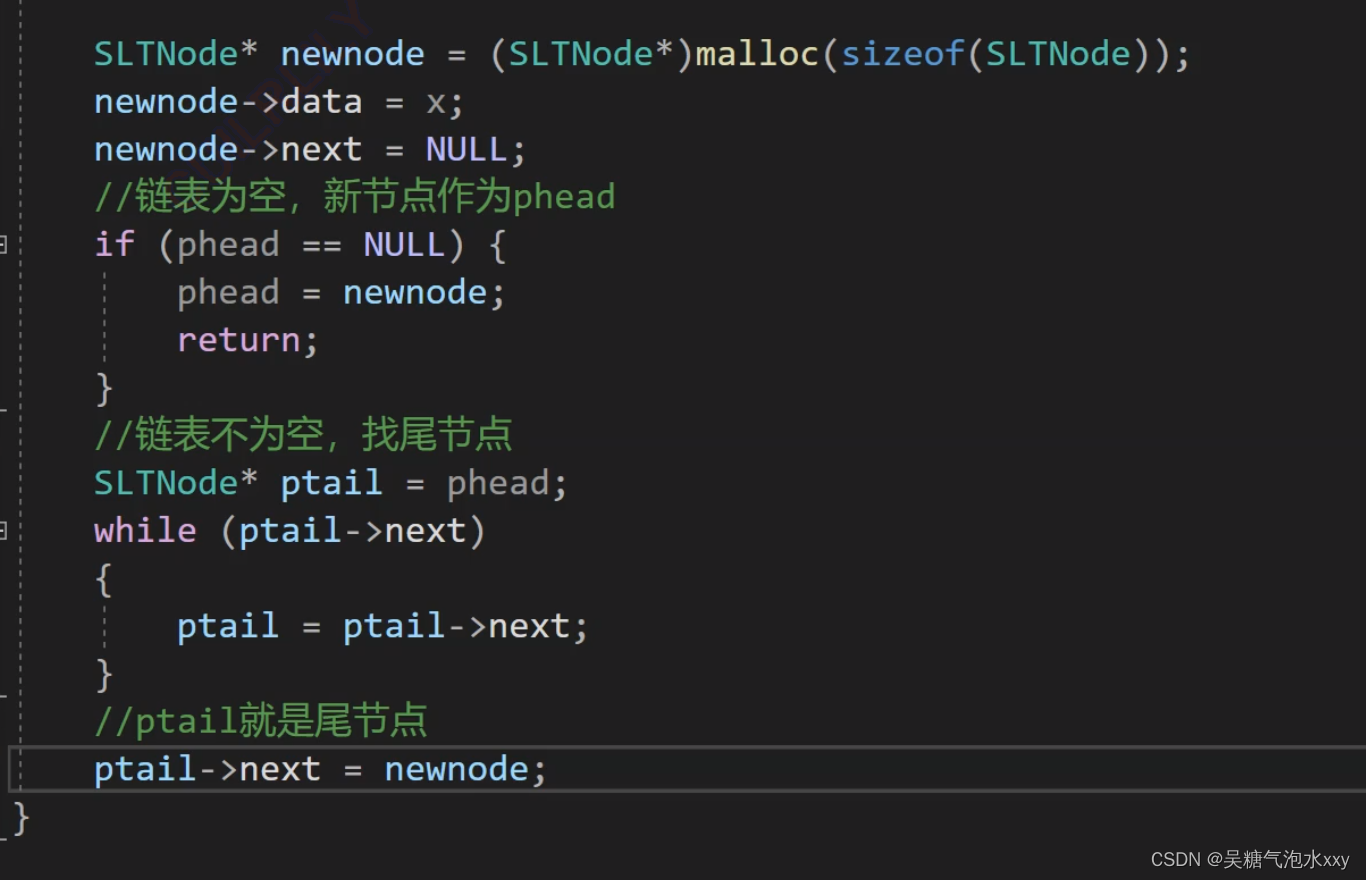
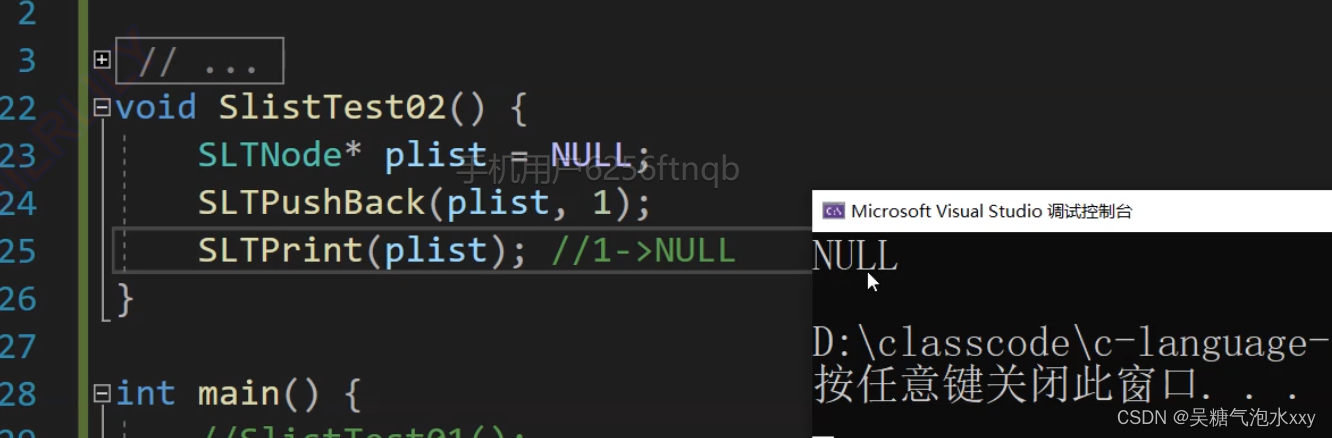
为什么是空链表呢?

来检查一下:调试,监视窗口。
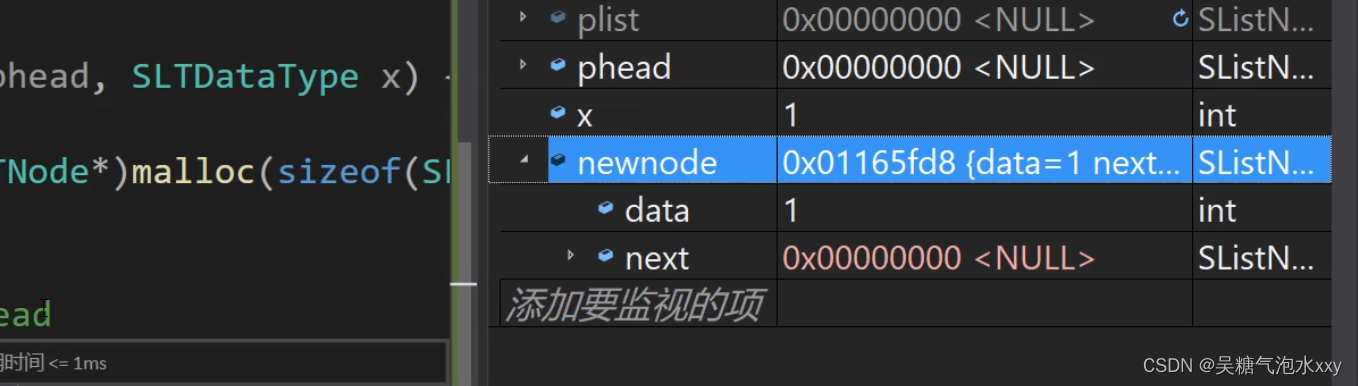
在进入测试代码之前一切正常,我们继续。

问题找到了,我们发现 plist 没有改变,还是空指针。
我们来看看到底是哪出了问题:


我们发现--plist中存的是值并不是地址。(plist中放的是NULL)但我们接收时使用的是指针,所以就会出现问题。
修改如下:由于需要传地址,又因为plist是一个一级指针,所以接收的时候应使用二级指针来接收。

我们再来运行一次

到这里就没有问题了。
尾插完了我们接着继续来头插
3.1.2头插
3.1.2.1链表不为空
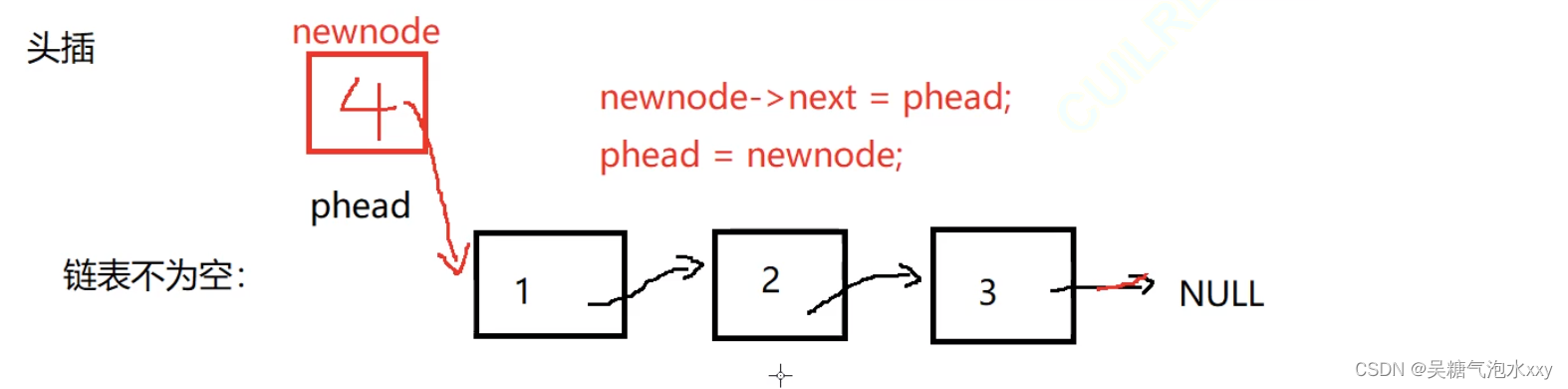
3.1.2.2;链表为空
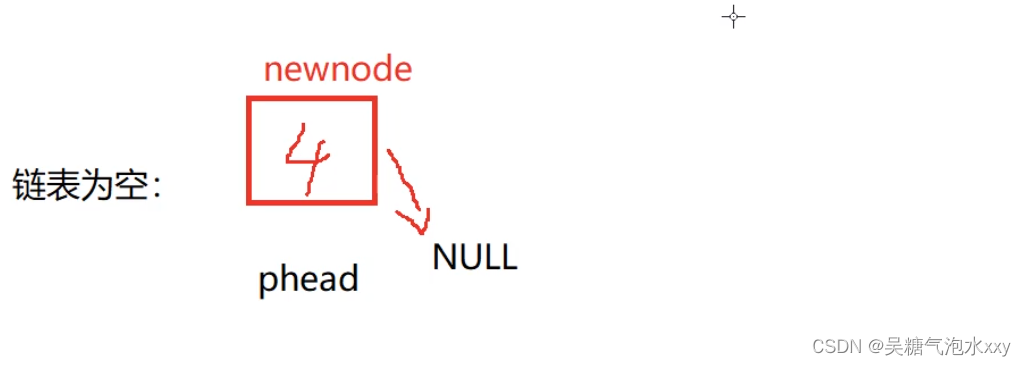
代码如下:

4.单链表的实现
typedef int SLTDataType;
typedef struct SListNode
{
SLTDataType data; //节点数据
struct SListNode* next; //指针保存下⼀个节点的地址
}SLTNode;
void SLTPrint(SLTNode* phead);
//头部插⼊删除/尾部插⼊删除
void SLTPushBack(SLTNode** pphead, SLTDataType x);
void SLTPushFront(SLTNode** pphead, SLTDataType x);
void SLTPopBack(SLTNode** pphead);
void SLTPopFront(SLTNode** pphead);
//查找
SLTNode* SLTFind(SLTNode* phead, SLTDataType x);
//在指定位置之前插⼊数据
void SLTInsert(SLTNode** pphead, SLTNode* pos, SLTDataType x);
//删除pos节点
void SLTErase(SLTNode** pphead, SLTNode* pos);
//在指定位置之后插⼊数据
void SLTInsertAfter(SLTNode* pos, SLTDataType x);
//删除pos之后的节点
void SLTEraseAfter(SLTNode* pos);
//销毁链表
void SListDesTroy(SLTNode** pphead);5. 链表的分类
链表的结构⾮常多样,以下情况组合起来就有8种(2x2x2)链表结构:

链表说明:
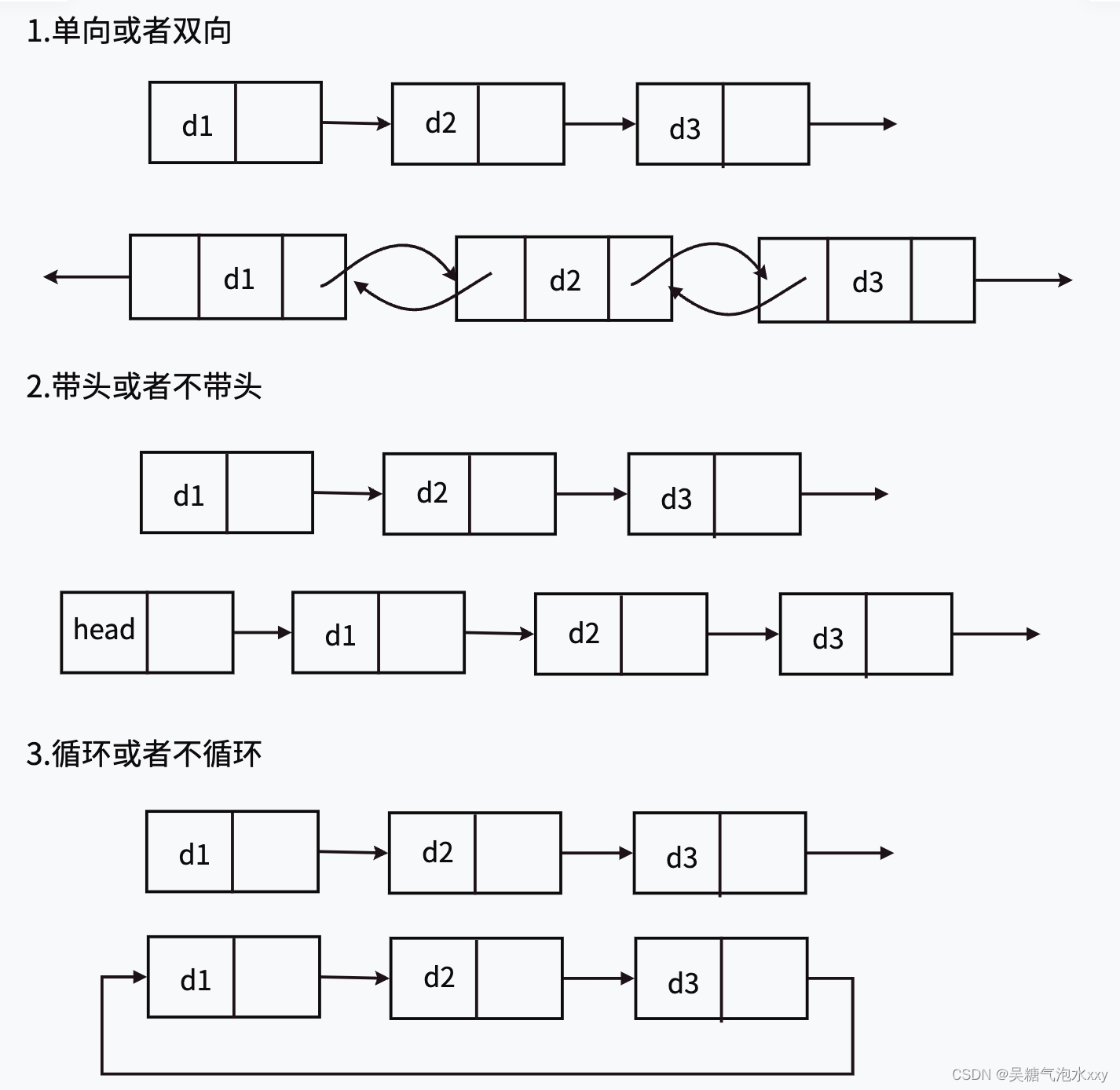
虽然有这么多的链表的结构,但是我们实际中最常⽤还是两种结构: 单链表 双向带头循环链表.
1.⽆头单向⾮循环链表:结构简单,⼀般不会单独⽤来存数据。实际中更多是作为其他数据结
构的⼦结构,如哈希桶、图的邻接表等等。另外这种结构在笔试⾯试中出现很多。
2.带头双向循环链表:结构最复杂,⼀般⽤在单独存储数据。实际中使⽤的链表数据结构,都
是带头双向循环链表。另外这个结构虽然结构复杂,但是使⽤代码实现以后会发现结构会带
来很多优势,实现反⽽简单了,后⾯我们代码实现了就知道了。
今天的博客就到这里了
后续会持续更新数据结构的相关知识
请大家持续关注
感谢你的观看。



![[CISCN2019 华东北赛区]Web2](https://img-blog.csdnimg.cn/img_convert/9da188646ff17b2386d7b836e48a2a89.png)
![【P1328】[NOIP2014 提高组] 生活大爆炸版石头剪刀布](https://img-blog.csdnimg.cn/img_convert/cb242bcc076eb19b2e006cd6118d44a3.png)
![[Android]创建Google Play内购aab白包](https://img-blog.csdnimg.cn/direct/a1c0bdd8ed754881ad03444872c6befa.png)