文章目录
- 2.2 消息存储在文件时涉及到的流对象
- 2.3 序列化、反序列化的方法
- 2.3.1 JSON的ObjectMapper
- 2.3.2 ObjectOutputStream 、 ObjectInputStream
- 2.3.3 第三方库的Hessian
- 2.3.4 protobuffer
- 2.3.5 thrift
- 2.4 使用类MessageFileManager封装文件存储操作
- 2.4.1 sendMessage()实现思路:
- 2.4.2 deleteMessage()实现思路:
- 2.4.3 loadAllMessageFromQueue()实现思路:
- 2.4.4 gc()实现思路:
- 三、使用类DiskDataCenter封装硬盘存储的数据
- 四、将broker server 里的数据存储在内存上
2.2 消息存储在文件时涉及到的流对象
1、InputStream、OutputStream 、 FileInputStream 、 FileOutputStream
2、DataInputStream 、 DataOutputStream
3、RandomAccessFile(随机访问)
4、ObjectInputStream 、 ObjectOutputStream(序列化、反序列化)
2.3 序列化、反序列化的方法
将消息存储至文件时,由于是消息数据文件queue_data.txt是二进制文件,因此此时Message对象无法直接存储到queue_data.txt文件中,我们需要将Message对象进行序列化,对象序列化之后方便进行存储(存储在文件上)和传输(通过网络进行传输,譬如socket)
此处我们在工具包common下新建一个工具类BinaryTool,实现序列化/反序列化功能。
序列化:将一个对象(结构化数据)转成一个字符串/字节数组。
反序列化:将一个 字符串/字节数组 转成 一个 对象(结构化数据)。
注意: 序列化之后,想要进行反序列化时,必须要保证当前对象信息没有改变(譬如没有进行属性增加或属性删除等),此时才会反序列化成功。在RabbitMQ中,使用属性serialVersionUID 进行标记当前对象是否变化,以防序列化后想进行反序列化失败。

2.3.1 JSON的ObjectMapper
那我们应该使用什么方式进行序列化、反序列化呢?我们以前用过JSON提供的ObjectMapper类里的方法writeValueAsString()进行序列化、方法readValue()进行反序列化。但是由于JSON序列化后得到的是文本数据,因此无法存储二进制数据(二进制数据可以存储文本数据)
因此我们还有4种办法进行序列化/反序列化:
2.3.2 ObjectOutputStream 、 ObjectInputStream
1、java标准库提供的类:ObjectOutputStream、ObjectInputStream,其中的 writeObject(Object object)方法将传入的对象进行序列化,将对象转化成字符串/字节数组。read(byte[] bytes) 方法将传入的字节数组进行反序列化,将字节数组/字符串转成对象。
2.3.3 第三方库的Hessian
2.3.4 protobuffer
2.3.5 thrift
项目中我使用的是 ObjectOutputStream、ObjectInputStream 类进行序列化和反序列化,此时无需引入任何额外依赖就可以进行序列化/反序列化:
/**
* 序列化:将一个对象(结构化对象) 转化成 一个字符串/字节数组
* 使用java标准库中提供的 针对二进制数据进行序列化/反序列化 的类 :ObjectInputStream 、 ObjectOutputStream
* @param object
* @return
*/
public static byte[] toBytes(Object object){
/**
* ByteArrayOutputStream :该流相当于一个 可变长的字节数组,
* 由于不知道 Message 对象里面的内容长度是多少,
* 所以使用一个可变长 的字节数组 接收 Message 对象序列化后的二进制数据
* */
try(ByteArrayOutputStream byteArrayOutputStream = new ByteArrayOutputStream()){
try(ObjectOutputStream outputStream = new ObjectOutputStream(byteArrayOutputStream)){
/**
* 此处的 writeObject()会将对象进行序列化,
* 生成的二进制数据写到 outputStream 流里,
* 由于 outputStream 关联了 byteArrayOutputStream,
* 因此实际上序列化得到的二进制数据是写到了 byteArrayOutputStream里
* */
outputStream.writeObject(object);
/**
* byteArrayOutputStream.toByteArray():表示将
* byteArrayOutputStream 里持有的二进制数据取出来,
* 转成 字节数组
* */
return byteArrayOutputStream.toByteArray();
}
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
/**
* 反序列化:将一个 字符串/字节数组 转化成一个 对象(结构化对象)
* @param bytes
* @return
*/
public static Object fromBytes(byte[] bytes) {
Object object = new Object();
/**
* ByteArrayInputStream流相当于 是一个 可变长的字节数组
* 使用 ByteArrayInputStream 流 接收 传进来的参数 bytes
* */
try(ByteArrayInputStream byteArrayInputStream = new ByteArrayInputStream(bytes)){
try (ObjectInputStream objectInputStream = new ObjectInputStream(byteArrayInputStream)) {
// 将 bytes 字节数组里的内容 读出来,放到 object 中
return object = objectInputStream.read(bytes);
}
} catch (IOException e) {
e.printStackTrace();
}
return null;
}
2.4 使用类MessageFileManager封装文件存储操作
类中的方法主要是为了实现消息持久化存储在硬盘(文件)上的。该类中提供14个操作消息存入文件的方法,外加一个静态内部类Stat。
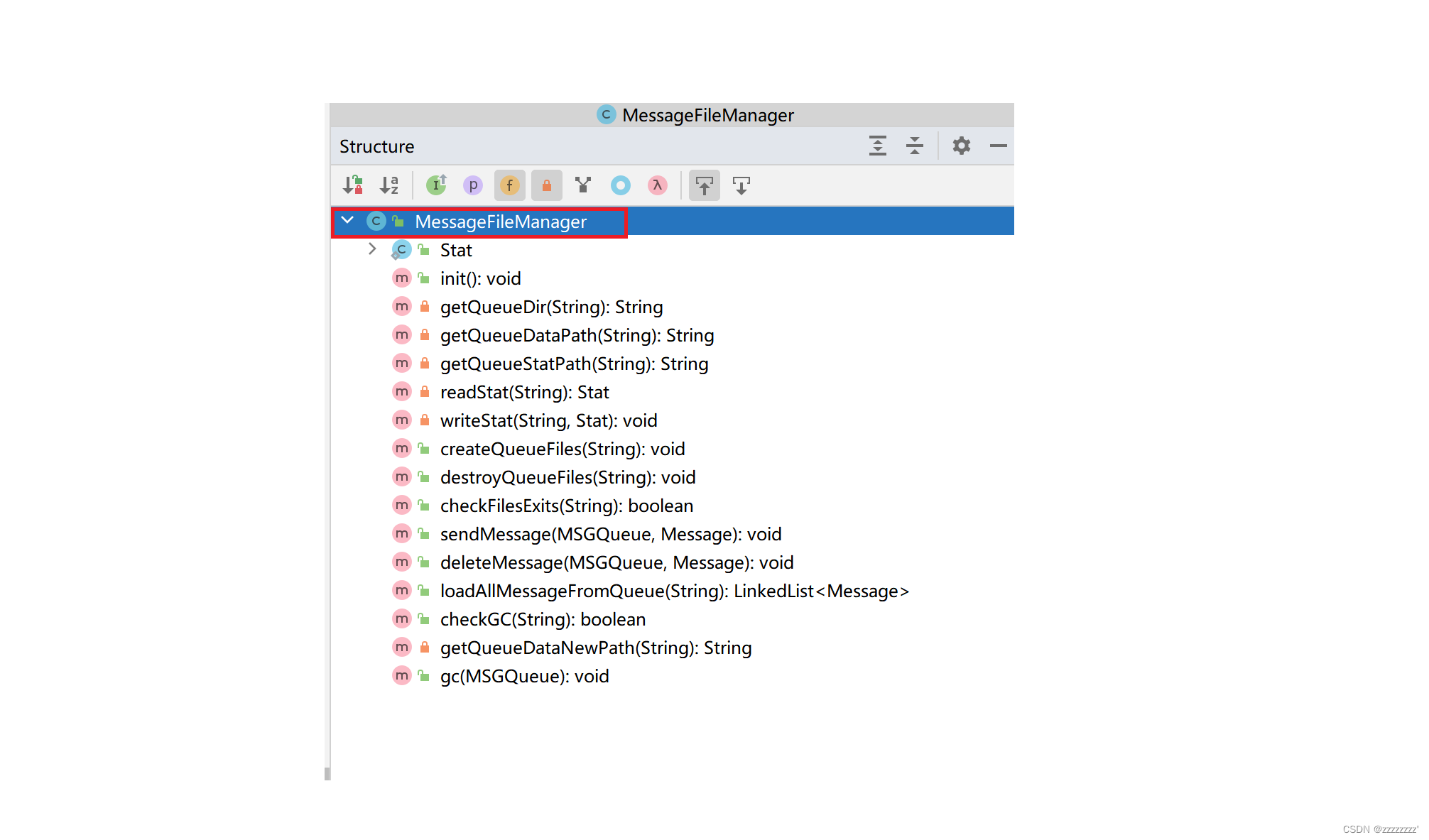
现在说一下MessageFileManager类里面的几个重要方法的实现思路。
2.4.1 sendMessage()实现思路:
sendMessage(MSGQueue queue,Message message)方法表示要将一个消息送入队列中,因此该方法需要指定将哪个消息送入哪个队列中这两个参数。接下来说明一下 sendMessage()的实现思路:
1、将一个新消息增加到队列中,首先需要判定该队列子目录下是否含有消息数据文件queue_data.txt、消息统计文件queue_stat.txt文件,如果不含有,那就需要抛出异常,记录日志。如果含有,此时我们才能写把消息插入文件的下一步代码。
2、由于消息数据文件queue_data.txt是个二进制文件,只存储二进制数据,因此此时需要将待插入队列的消息Message对象转成字节数组(这步操作叫做序列化操作)。
3、此时我们还不急着将已经转成二进制数据(字节数组)的消息插入队列,我们还有至关重要的部分还没完成——>我们首先需要获取到消息数据文件queue_data.txt文件的长度,以及该待插入队列消息的长度,以此去设置 offsetBeg、offsetEnd。由于一个文件里存储多个消息,当想要从队列中取出某个消息时,就要获取到它的位置才能顺利找到消息并取出。因此offsetBeg、offsetEnd 是 用来记录消息在文件里的位置。我们每次写入新的消息到文件中,都是写入到文件的末尾。前面 我们规定 offsetBeg 表示消息头部距离文件头部的距离,offsetEnd 表示消息尾部到文件尾部的距离,当 offsetEnd - offsetBeg 时,就是消息在文件中所占的位置。offsetBeg 就是 消息数据文件此时的长度 + 4(因为消息的长度我们规定是4个字节),offsetEnd 就是 消息数据文件此时的长度 + 4 + 消息的内容长度(消息内容长度就是Message对象序列化后的二进制数据,其长度是可变长的)。我们每次进行完第2小步操作后,都需要将消息的offsetBeg、offsetEnd记录下来,同时将其保存至Message对象中。
4、将消息写入到消息数据文件中。(不管是读/写操作,我们都需要先打开文件,然后才能针对文件里面的内容进行读取/写入)这里也有一个需要注意的点:在进行消息写入文件操作时,由于消息在文件里的存储格式是如下形式的(这个形式也是由我们进行约定的):
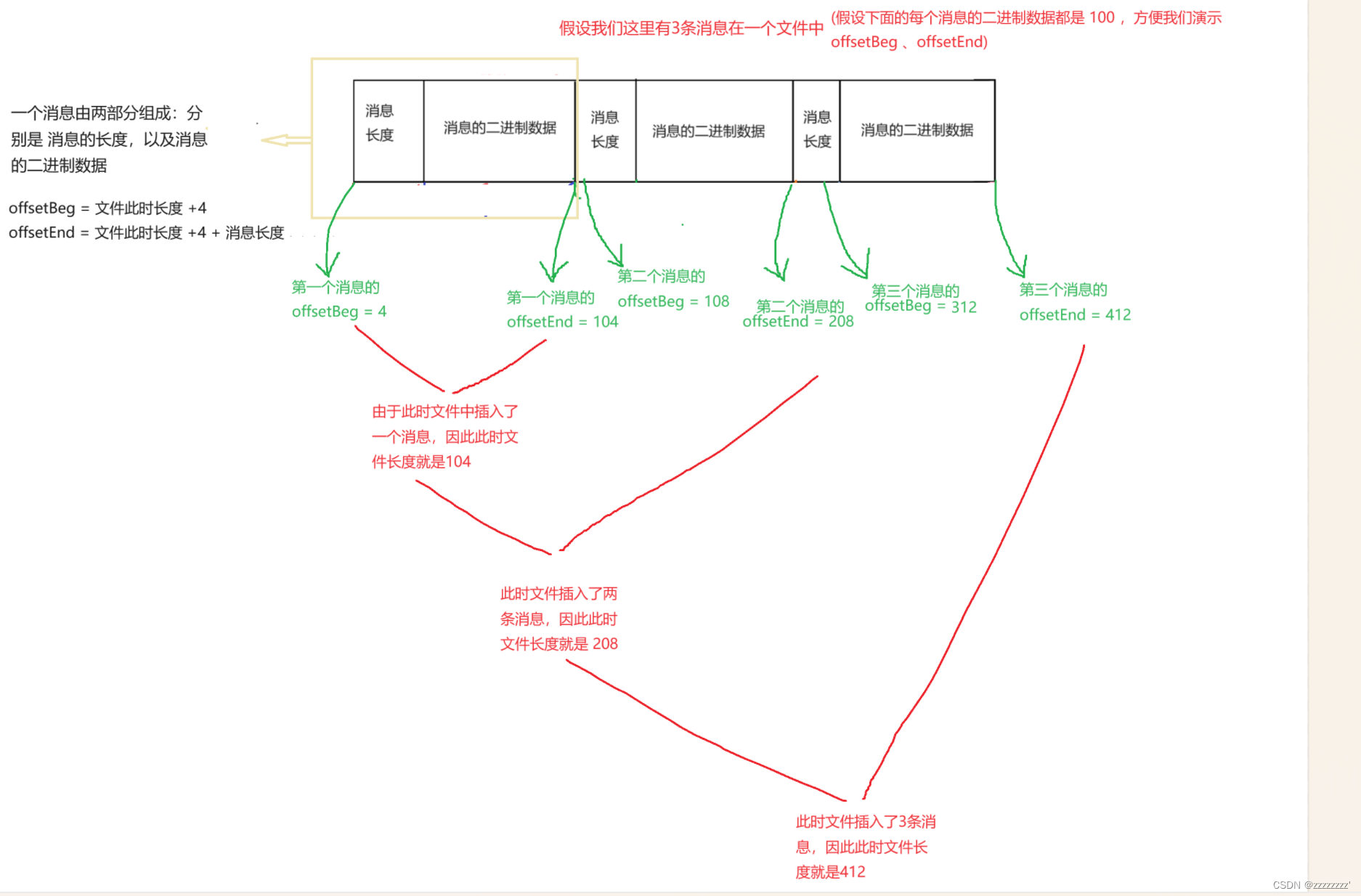
因此我们在进行消息写入文件时,需要注意,一个消息,分为两部分,因此写入文件时,需要先将消息的长度4字节写入,然后再是写入消息的二进制数据。但是,这里有个需要注意的问题:OutputStream流的write(int a)方法,一次只能写入1个字节,但咱们的消息长度占据了4个字节,因此此时我们需要借助流对象DataOutputStream中的writeInt(int a)方法,就可以一次写入4个字节。然后再借助流对象DataOutputStream中的write()方法写入消息二进制数据即可。
5、将消息添加至队列后,不要忘记更新消息统计文件里的属性值。
6、由于 可能会有多个客户端访问broker server进行sendMessage()操作,因此此时我们需要考虑多线程安全问题,以队列维度加锁,确保线程安全。
2.4.2 deleteMessage()实现思路:
咱们这个删除消息的方法中,也必须包含删除哪个队列中的哪个消息这两个重要参数,传入的消息对象参数必须是包含有效的 offsetBeg、offsetEnd 因为后续读取文件中的消息时,需要使用 offsetEnd - offsetBeg 作为 字节数组的容量,表示读取这样大小的消息数据到字节数组中。
1、打开文件,将文件中的消息读取出来。由于删除消息时,我们进行随机位置的删除,此时就需要通过流对象RandomAccessFile里的seek()方法获取到任意位置。
2、将读取到的消息反序列化成消息对象,然后将对象里的属性isValid改成0x0,表示此条消息无效(逻辑删除)。
3、再将此消息对象序列化成字节数组,打开文件,重新将消息写入文件。
4、更新消息统计文件。此时要注意更新前,先进行判定属性validCount > 0,大于0才进行更新。
5、该方法可能会被多个客户端进行调用,因此需要加锁确保线程安全。
2.4.3 loadAllMessageFromQueue()实现思路:
该方法打算在 broker server 启动时调用,将文件中的所有消息读取出来,加载到内存中。 在 broker server 运行的过程中,会收到很多消息并进行存储,如果 broker server 重启了,我们就期望将硬盘中之前保存的消息数据还原到内存中,方便 broker server 高效读取数据。
1、打开文件,顺序读取文件里的消息。
2、一个文件中含有许多消息,因此循环读取消息,判定 消息长度 与 读到的消息长度是否一致,一致就下一步代码,否则抛异常。(循环外定义一个全局变量记录消息位置)
3、将读到的消息反序列化成Message对象,判定该消息对象是否无效,无效就记录一下消息的当前位置,然后跳过。
4、记录一下消息的offsetBeg、offsetEnd,然后再将全局变量记录一下,然后将消息 加入到链表中。
2.4.4 gc()实现思路:
消息的垃圾回收机制使用的是复制算法,由于gc可能在文件过大时消耗许多时间导致程序性能降低,因此在gc时记录其消耗的时间长度。
1、创建一个新的消息数据文件queue_data_new.txt,判定一下该文件是否存在,存在就抛出异常表示gc失败。
2、把之前消息数据文件中的有效数据都读取出来,写到新文件中。
3、删除旧的消息数据文件,再把新消息数据文件重命名为旧消息数据文件。
4、更新消息统计文件中的属性值。
5、gc是对文件中的所有消息进行大洗牌,此时需要保证线程安全。
三、使用类DiskDataCenter封装硬盘存储的数据
我们已经知道,交换机、队列、绑定在硬盘上的持久化存储是使用数据库进行存储,消息在硬盘上的持久化存储是使用文件进行存储。前面我们使用类DataBaseManager来对一切针对数据库操作进行了封装,使用MessageFileManager来对一切针对消息进行文件存储操作的封装。但不管是存储在数据库还是文件,都是对硬盘的操作,因此此时我们使用类DiskDataManager对硬盘操作进行封装,给上层调用者提供一套接口,整合硬盘里的所有信息。上层逻辑如果需要操作硬盘,同意通过类DiskDataManager来使用。
在类DiskDataManager里,我们给交换机、队列、绑定分别提供 增加、删除、查询的方法,给消息提供了 发送消息、删除消息、将全部消息从队列中取出 这3个方法。
四、将broker server 里的数据存储在内存上
对于MQ来说,内存存储数据为主,以便数据库高效的获取/转存数据,硬盘存储数据为辅,以便 broker server 重启后,可以将硬盘上持久化存储的数据恢复到内存中。因此此时我们考虑将数据存储在内存中是很有必要的。那么将 broker server 里的数据存储在内存上,首先需要思考,这些数据应该以 何种数据结构组织 以便在内存中存储时进行管理。
1、交换机:我们考虑使用哈希表HashMap进行管理交换机,key是exchangeName,value是Exchange。
ConcurrentHashMap<String,Exchange> exchangeMap= new ConcurrentHashMap<>();
2、队列,我们也考虑使用哈希表HashMap进行管理队列,key是queueName,value是MSGQueue。
ConcurrentHashMap<String,MSGQueue> queueMap= new ConcurrentHashMap<>();
3、绑定:我们考虑使用嵌套的HashMap进行管理绑定,key是exchangeName,value是一个HashMap,该HashMap,其key是queueName,value是binding。其实就是先按交换机的exchangeName进行查找,找到的是一个HashMap表,如果该HashMap表不存在,表明交换机没有绑定队列,也就获取不到绑定对象了;如果该HashMap表存在,表明交换机有绑定队列,再通过队列的queueName查找,就知道此时交换机和队列绑定的绑定对象是谁了。
ConcurrentHashMap<String,ConcurrentHashMap<String,Binding>> bindingsMap= new ConcurrentHashMap<>();
4、消息:内存中通过HashMap进行管理,key是messageId,value是Message对象。
ConcurrentHashMap<String,Message> messageMap = new ConcurrentHashMap<>();
5、队列中有哪些消息:使用此来表示一个队列下具有哪些消息。使用HashMap表示,key是queueName,获取到的是LinkedList。
ConcurrentHashMap<String,LinkedList<Message>> queueMessageMap = new ConcurrentHashMap<>();
6、未确认消息:使用此来表示那部分被消费者获取到、但没有应答的消息。使用嵌套的HashMap进行管理,key是queueName,获取到的HashMap的key是messageId,value是Message。
ConcurrentHashMap<String,ConcurrentHashMap<String,Message>> queueMessageWaitAckMap = new ConcurrentHashMap<>();

![[套路] 浏览器引入Vue.js场景-WangEditor富文本编辑器的使用 (永久免费)](https://img-blog.csdnimg.cn/direct/7d003533fd61452c805872c31636e5b8.png)