文章目录
- 3.基于Selenium爬取携程网景点详细数据
- 3.1前提环境
- 3.2思路
- 3.3代码详讲
- 3.3.1查询指定城市的所有景点
- 3.3.2获取详细景点的访问路径
- 3.3.3获取景点的详细信息
- 3.4数据库设计
- 3.5全部代码
- 3.6效果图
3.基于Selenium爬取携程网景点详细数据
3.1前提环境
- 确保安装python3.x环境
- 以管理员身份打开cmd,安装selenium、pymysql、datetime,默认安装最新版即可
pip install selenium
pip install pymysql
pip install datetime
-
确保chrome安装对应版本的驱动(将该驱动放在chrome安装路径下),用于控制chrome浏览器,并将路径添加到环境变量的Path变量中,如图所示!
#安装chrome驱动教程链接: https://blog.csdn.net/linglong_L/article/details/136283810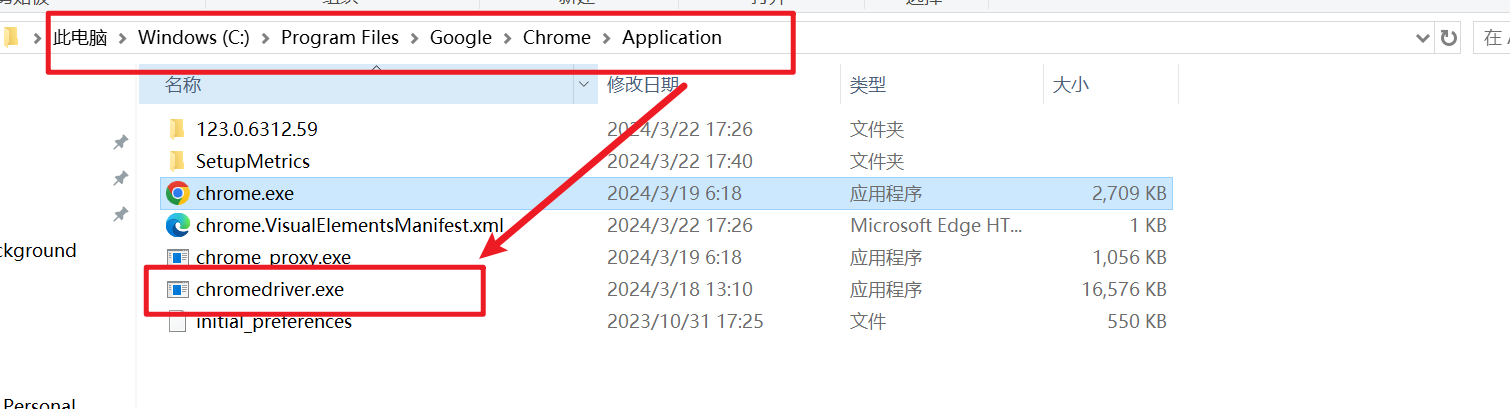
3.2思路
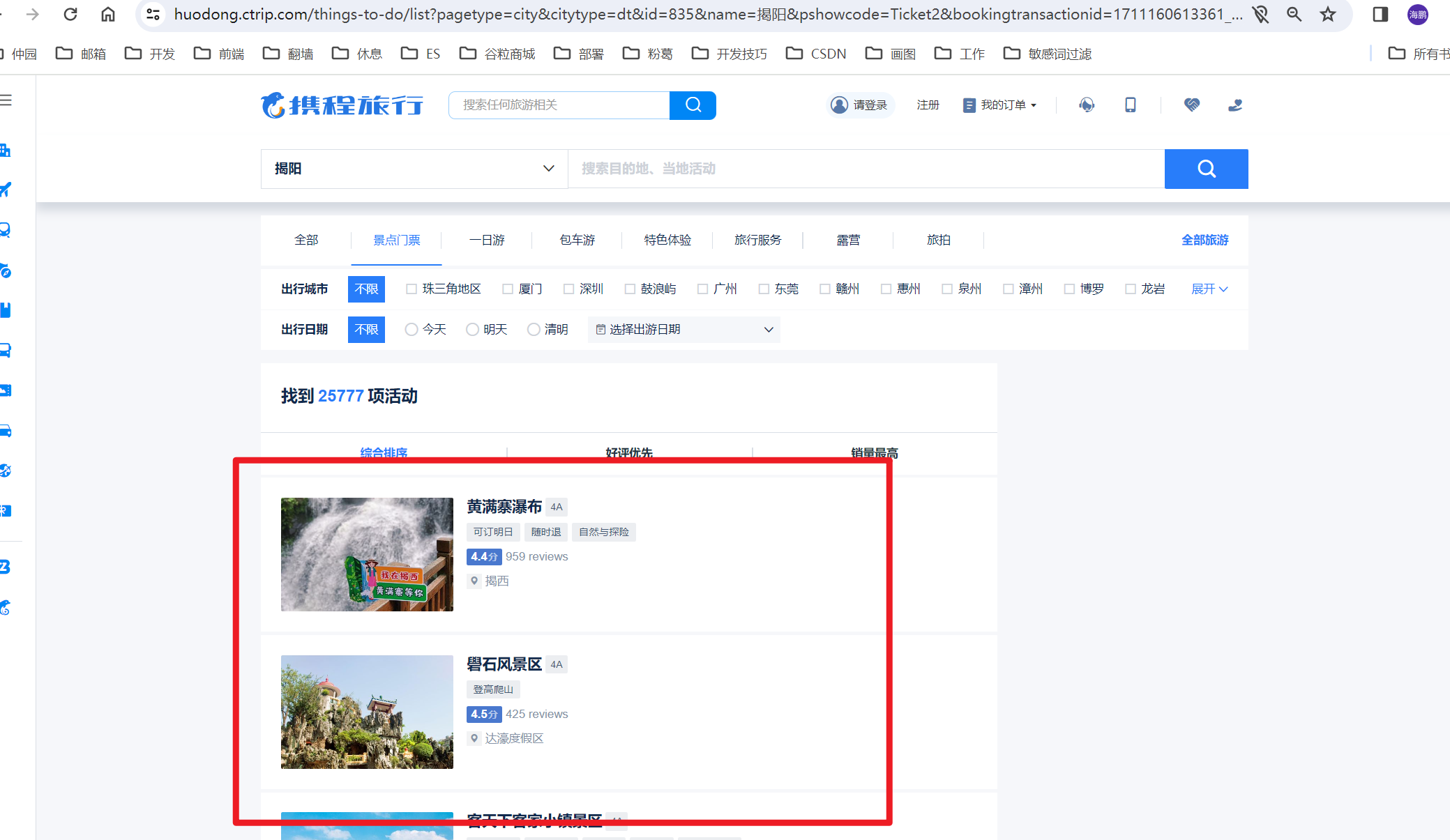
- 搜索指定城市景点,网站通过分页进行展示;
- 使用selenium每个景点的详细访问路径,并点击该路径获取详细景点信息,再通过正则表达式获取需要的内容;
-
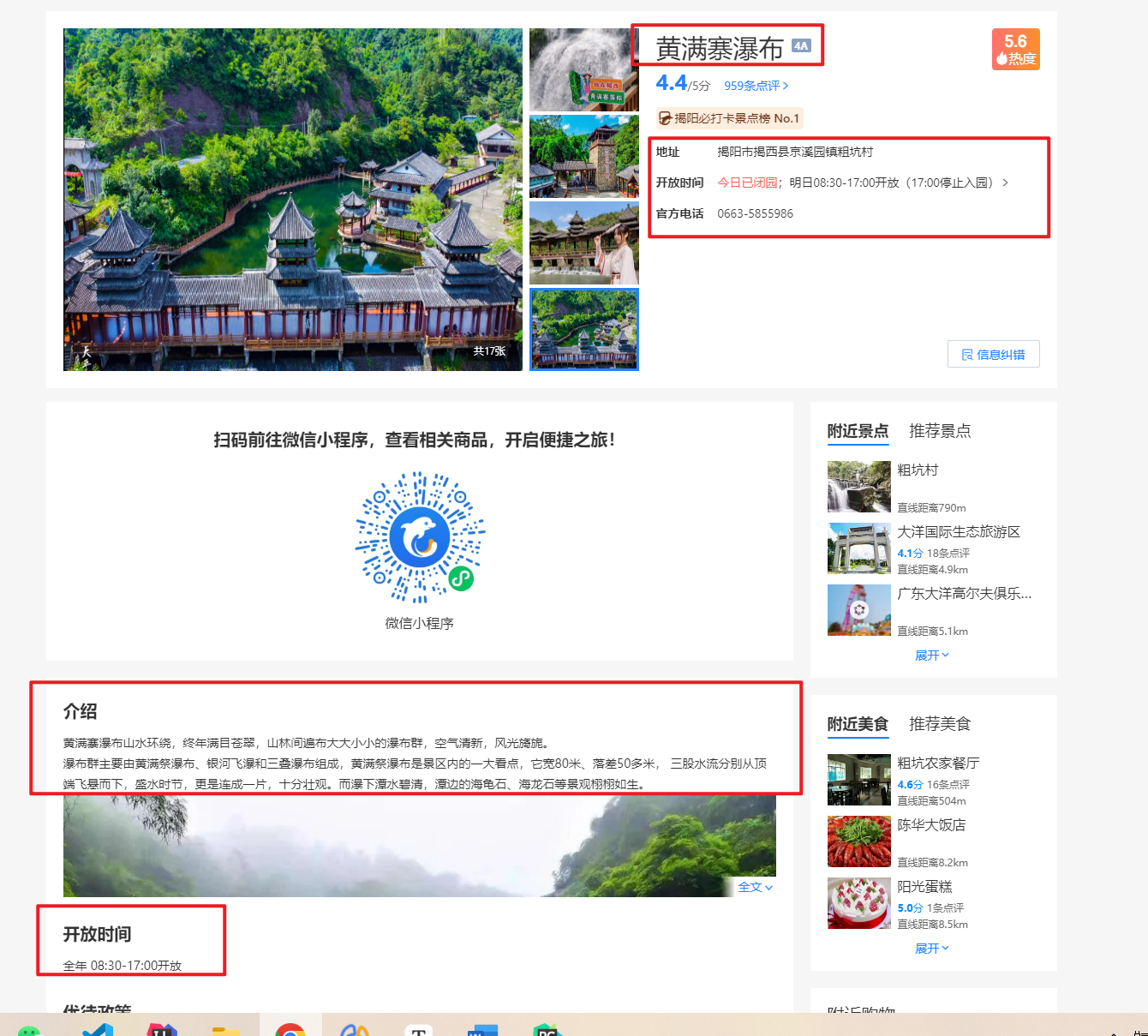
如下图,景点的详细信息有:景点名称、景点等级(1-5A)、景点地址、开放时间(有两种,我们采用下面的)、联系电话、景点介绍、景点图片等内容
3.3代码详讲
3.3.1查询指定城市的所有景点
- 控制打开chrome,并访问指定查询所有景点路径
def __init__(self):
options = Options()
options.add_argument('--headless')
service = Service()
self.chrome = Chrome(service=service)
self.chrome.get(
'https://huodong.ctrip.com/things-to-do/list?pagetype=city&citytype=dt&keyword=%E6%A2%85%E5%B7%9E&id=523&name=%E6%A2%85%E5%B7%9E&pshowcode=Ticket2&kwdfrom=srch&bookingtransactionid=1711160613361_6064')
time.sleep(3)
self.page = 1
self.headers = {
'cookie': 'suid=lh/P1+4RKuhAYg684ErS+g==; suid=lh/P1+4RKuhAYg684ErS+g==',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
}
3.3.2获取详细景点的访问路径
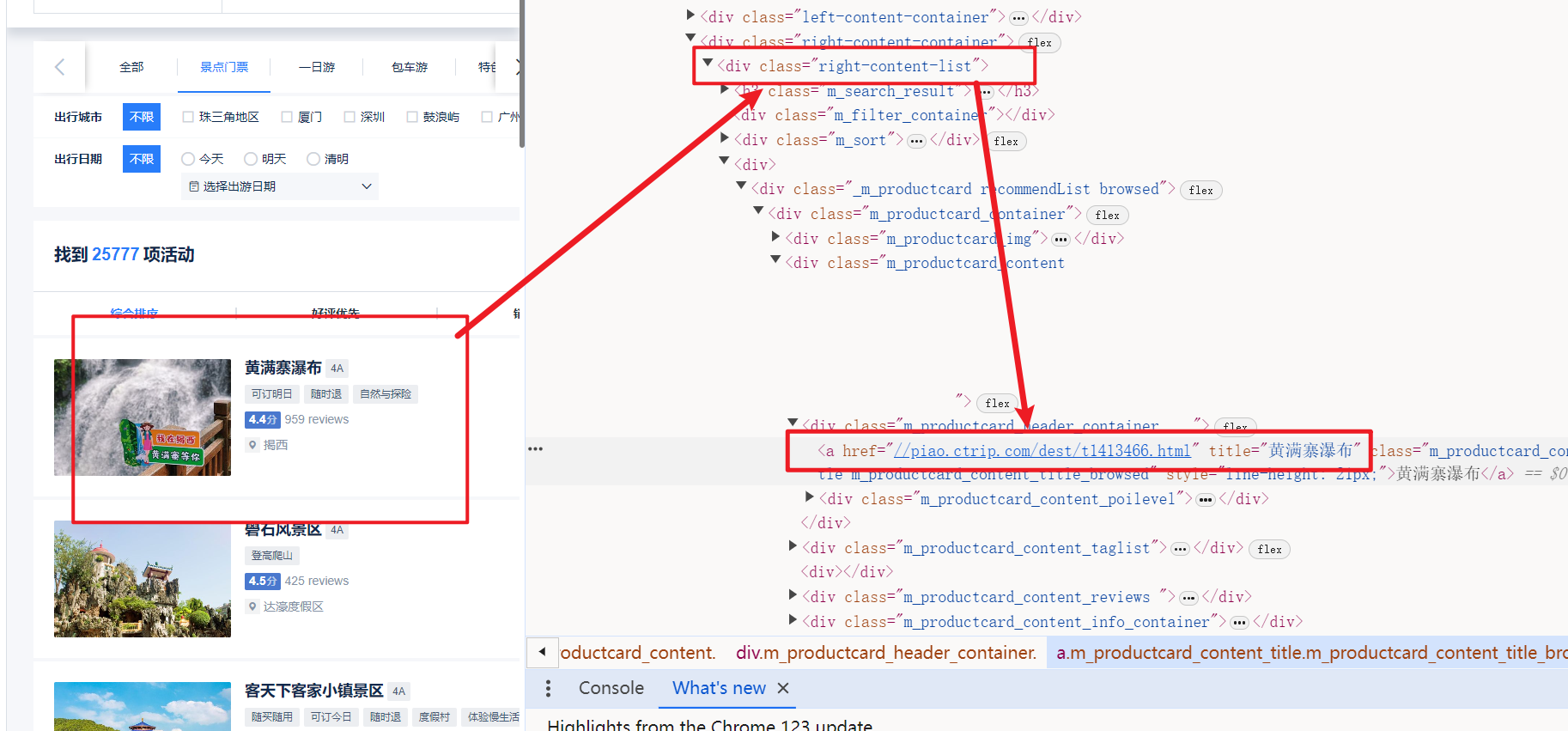
- 使用selenium的根据class定位元素方法,找到详细景点的href属性,即为该景点的访问路径
- 并通过page属性控制访问的页数
#获取景点请求路径
def get_url(self):
while True:
content = self.chrome.find_element(By.CLASS_NAME, "right-content-list").get_attribute('innerHTML')
cons = re.findall(r'href="(.*?)" title="(.*?)"', content)
for con in cons:
self.detail_url = 'https:' + con[0]
self.title = con[1]
print(self.detail_url, self.title)
self.get_detail()
self.chrome.find_element(By.CLASS_NAME,'u_icon_enArrowforward').click()
time.sleep(1)
self.page += 1
if self.page == 120:
break
3.3.3获取景点的详细信息
- 景点的详细信息有:景点名称、景点等级(1-5A)、景点地址、开放时间(有两种,我们采用下面的)、联系电话、景点介绍、景点图片等内容
- 通过正则表达式获取,详细代码如下:
- 并每次获取详细信息之后,将信息保存到mysql数据库中
def get_detail(self):
detail_con = requests.get(self.detail_url, verify=False, headers=self.headers).text
# time.sleep(2)
'''使用正则获取信息'''
self.title = ''.join(re.findall(r'<div class="title"><h1>(.*?)<', detail_con, re.DOTALL))
print('景点名称:'+self.title)
#self.rank = ''.join(re.findall(r'rankText">(.*?)<', detail_con, re.DOTALL))
self.address = ''.join(re.findall(r'地址</p><p class="baseInfoText">(.*?)<', detail_con, re.DOTALL))
self.mobile = ''.join(re.findall(r'官方电话</p><p class="baseInfoText">(.*?)<', detail_con, re.DOTALL))
self.quality_grade= ''.join(re.findall(r'<div class="titleTips"><span>(.*?)<!--', detail_con, re.DOTALL))
#self.openTime = ''.join(re.findall(r'开放时间</div><div class="moduleContent">(.*?)<', detail_con, re.DOTALL))
first_three_characters = self.address[:3]
print('所在省份城市:'+'广东省'+first_three_characters)
print('详细地址:'+self.address)
#print('开放时间:'+self.openTime)
print('电话:'+self.mobile)
print('等级:'+self.quality_grade)
if self.quality_grade=='':
self.quality_grade=0
'''使用xpath获取信息'''
ret = etree.HTML(detail_con)
desc_cons = ret.xpath('//div[@class="detailModule normalModule"]//div[@class="moduleContent"]')
desc_titles = ret.xpath('//div[@class="detailModule normalModule"]//div[@class="moduleTitle"]')
desc_list = []
desc_title_list = []
for d in desc_cons:
des = ''.join(d.xpath('.//text()'))
desc_list.append(des)
for d in desc_titles:
des = ''.join(d.xpath('.//text()'))
desc_title_list.append(des)
desc_dict = dict(zip(desc_title_list, desc_list))
#print(desc_dict)
first_value = list(desc_dict.values())[:2] # 获取前两个值
if len(first_value) >= 1:
introduction = first_value[0]
else:
introduction = ''
if len(first_value) >= 2:
opening_hours = first_value[1]
else:
opening_hours = ''
print('介绍:'+introduction)
print('开放时间:'+ opening_hours)
'''获取图片链接'''
img_list = []
imgs = re.findall(r'background-image:url\((.*?)\)', detail_con, re.DOTALL)
for img in imgs:
'''匹配到的同一张图片会有两种尺寸,我们只要大图,所以把尺寸为521*391的匹配出来即可'''
image = re.search(r'521_391', img)
if image:
img_list.append(img)
print(",".join(img_list))
conn = pymysql.connect(host='localhost', user='root', password='root',
database='travel_ams', charset='utf8mb4')
cursor = conn.cursor()
sql = "INSERT INTO ams_attraction (attraction_name, quality_grade, province_city, location, open_hour, phone, introduction, images, add_time) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s)"
values = (self.title, self.quality_grade, '广东省'+first_three_characters, self.address, opening_hours, self.mobile, introduction,",".join(img_list) ,datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
cursor.execute(sql, values)
conn.commit()
conn.close()
#self.get_ticket()
3.4数据库设计
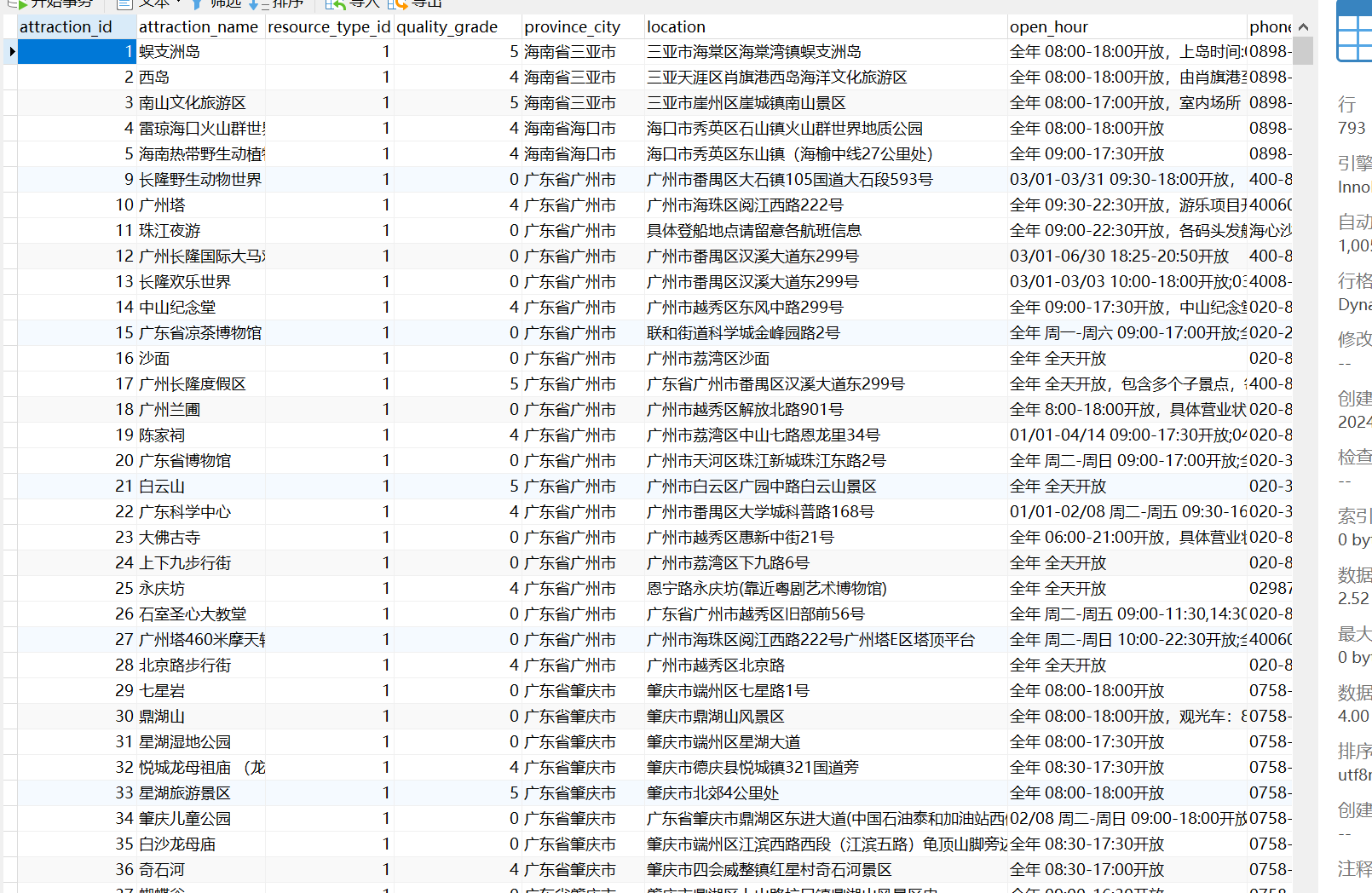
travel_ams数据库的ams_attraction表
| 字段名 | 字段类型 | 是否为主键 | 是否有唯一约束 | 是否有非空约束 | 注释 |
|---|---|---|---|---|---|
| attraction_id | int | 是 | 景点id,自增 | ||
| attraction_name | varchar(20) | 景点名称 | |||
| resource_type_id | int | 景点资源类型id | |||
| quality_grade | int | 景点等级 | |||
| province_city | varchar(20) | 景点所在省份城市 | |||
| location | varchar(1000) | 详细位置 | |||
| open_hour | varchar(1000) | 开放时间 | |||
| phone | varchar(1000) | 电话 | |||
| introduction | varchar(10000) | 景点介绍 | |||
| images | varchar(1000) | 景点图片列表 | |||
| staus | int | 状态【1为显示,0为不显示】 | |||
| add_time | datetime | 添加时间 | |||
| update_time | datetime | 修改时间 |
创建表语句如下:
CREATE TABLE ams_attraction (
attraction_id INT PRIMARY KEY AUTO_INCREMENT COMMENT '景点id,自增',
attraction_name VARCHAR(20) COMMENT '景点名称',
resource_type_id INT COMMENT '景点资源类型id',
province_city VARCHAR(20) COMMENT '景点所在省份城市',
location VARCHAR(1000) COMMENT '详细位置',
open_hour VARCHAR(1000) COMMENT '开放时间',
phone VARCHAR(1000) COMMENT '电话',
introduction VARCHAR(10000) COMMENT '景点介绍',
images VARCHAR(1000) COMMENT '景点图片列表',
status INT COMMENT '状态【1为显示,0为不显示】',
add_time DATETIME COMMENT '添加时间',
update_time DATETIME COMMENT '修改时间'
);
3.5全部代码
- 执行该main方法,即可完成导入指定访问路径的景点数据
- 可以在控制台查询是否导入成功
import pandas
import re
import time
import requests
import urllib3
from lxml import etree
from selenium.webdriver import Chrome
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.chrome.service import Service
from selenium.webdriver.common.by import By
import pymysql
import datetime
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
class Jy_jd(object):
def __init__(self):
options = Options()
options.add_argument('--headless')
service = Service()
self.chrome = Chrome(service=service)
self.chrome.get(
'https://huodong.ctrip.com/things-to-do/list?pagetype=city&citytype=dt&keyword=%E6%A2%85%E5%B7%9E&id=523&name=%E6%A2%85%E5%B7%9E&pshowcode=Ticket2&kwdfrom=srch&bookingtransactionid=1711160613361_6064')
time.sleep(3)
self.page = 1
self.headers = {
'cookie': 'suid=lh/P1+4RKuhAYg684ErS+g==; suid=lh/P1+4RKuhAYg684ErS+g==',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36',
}
#获取景点请求路径
def get_url(self):
while True:
content = self.chrome.find_element(By.CLASS_NAME, "right-content-list").get_attribute('innerHTML')
cons = re.findall(r'href="(.*?)" title="(.*?)"', content)
for con in cons:
self.detail_url = 'https:' + con[0]
self.title = con[1]
print(self.detail_url, self.title)
self.get_detail()
self.chrome.find_element(By.CLASS_NAME,'u_icon_enArrowforward').click()
time.sleep(1)
self.page += 1
if self.page == 120:
break
def get_detail(self):
detail_con = requests.get(self.detail_url, verify=False, headers=self.headers).text
# time.sleep(2)
'''使用正则获取信息'''
self.title = ''.join(re.findall(r'<div class="title"><h1>(.*?)<', detail_con, re.DOTALL))
print('景点名称:'+self.title)
#self.rank = ''.join(re.findall(r'rankText">(.*?)<', detail_con, re.DOTALL))
self.address = ''.join(re.findall(r'地址</p><p class="baseInfoText">(.*?)<', detail_con, re.DOTALL))
self.mobile = ''.join(re.findall(r'官方电话</p><p class="baseInfoText">(.*?)<', detail_con, re.DOTALL))
self.quality_grade= ''.join(re.findall(r'<div class="titleTips"><span>(.*?)<!--', detail_con, re.DOTALL))
#self.openTime = ''.join(re.findall(r'开放时间</div><div class="moduleContent">(.*?)<', detail_con, re.DOTALL))
first_three_characters = self.address[:3]
print('所在省份城市:'+'广东省'+first_three_characters)
print('详细地址:'+self.address)
#print('开放时间:'+self.openTime)
print('电话:'+self.mobile)
print('等级:'+self.quality_grade)
if self.quality_grade=='':
self.quality_grade=0
'''使用xpath获取信息'''
ret = etree.HTML(detail_con)
desc_cons = ret.xpath('//div[@class="detailModule normalModule"]//div[@class="moduleContent"]')
desc_titles = ret.xpath('//div[@class="detailModule normalModule"]//div[@class="moduleTitle"]')
desc_list = []
desc_title_list = []
for d in desc_cons:
des = ''.join(d.xpath('.//text()'))
desc_list.append(des)
for d in desc_titles:
des = ''.join(d.xpath('.//text()'))
desc_title_list.append(des)
desc_dict = dict(zip(desc_title_list, desc_list))
#print(desc_dict)
first_value = list(desc_dict.values())[:2] # 获取前两个值
if len(first_value) >= 1:
introduction = first_value[0]
else:
introduction = ''
if len(first_value) >= 2:
opening_hours = first_value[1]
else:
opening_hours = ''
print('介绍:'+introduction)
print('开放时间:'+ opening_hours)
'''获取图片链接'''
img_list = []
imgs = re.findall(r'background-image:url\((.*?)\)', detail_con, re.DOTALL)
for img in imgs:
'''匹配到的同一张图片会有两种尺寸,我们只要大图,所以把尺寸为521*391的匹配出来即可'''
image = re.search(r'521_391', img)
if image:
img_list.append(img)
print(",".join(img_list))
conn = pymysql.connect(host='localhost', user='root', password='root',
database='travel_ams', charset='utf8mb4')
cursor = conn.cursor()
sql = "INSERT INTO ams_attraction (attraction_name, quality_grade, province_city, location, open_hour, phone, introduction, images, add_time) VALUES (%s, %s, %s, %s, %s, %s, %s, %s, %s)"
values = (self.title, self.quality_grade, '广东省'+first_three_characters, self.address, opening_hours, self.mobile, introduction,",".join(img_list) ,datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S"))
cursor.execute(sql, values)
conn.commit()
conn.close()
#self.get_ticket()
#获取门票
def get_ticket(self):
id = self.detail_url.split('/')[-1]
print(id)
ticket_url = f'https://piao.ctrip.com/ticket/dest/{id}?onlyContent=true&onlyShelf=true'
ticket_res = requests.get(ticket_url, verify=False, headers=self.headers).text
# time.sleep(1)
ticket_ret = etree.HTML(ticket_res)
ticket = ticket_ret.xpath('//table[@class="ticket-table"]//div[@class="ttd-fs-18"]/text()')
price = ticket_ret.xpath(
'//table[@class="ticket-table"]//td[@class="td-price"]//strong[@class="ttd-fs-24"]/text()')
print(ticket)
print(price)
'''拿到的列表里可能存在不确定数量的空值,所以这里用while True把空值全部删除,这样才可以确保门票种类与价格正确对应上'''
while True:
try:
ticket.remove(' ')
except:
break
while True:
try:
price.remove(' ')
except:
break
'''
这里多一个if判断是因为我发现有些详情页即便拿到门票信息并剔除掉空值之后仍然存在无法对应的问题,原因是网页规则有变动,
所以一旦出现这种情况需要使用新的匹配规则,否则会数据会出错(不会报错,但信息对应会错误)
'''
if len(ticket) != len(price):
ticket = ticket_ret.xpath(
'//table[@class="ticket-table"]/tbody[@class="tkt-bg-gray"]//a[@class="ticket-title "]/text()')
price = ticket_ret.xpath('//table[@class="ticket-table"]//strong[@class="ttd-fs-24"]/text()')
while True:
try:
ticket.remove(' ')
except:
break
while True:
try:
price.remove(' ')
except:
break
print(ticket)
print(price)
ticket_dict = dict(zip(ticket, price))
print(ticket_dict)
if __name__ == '__main__':
jy_jd = Jy_jd()
jy_jd.get_url()
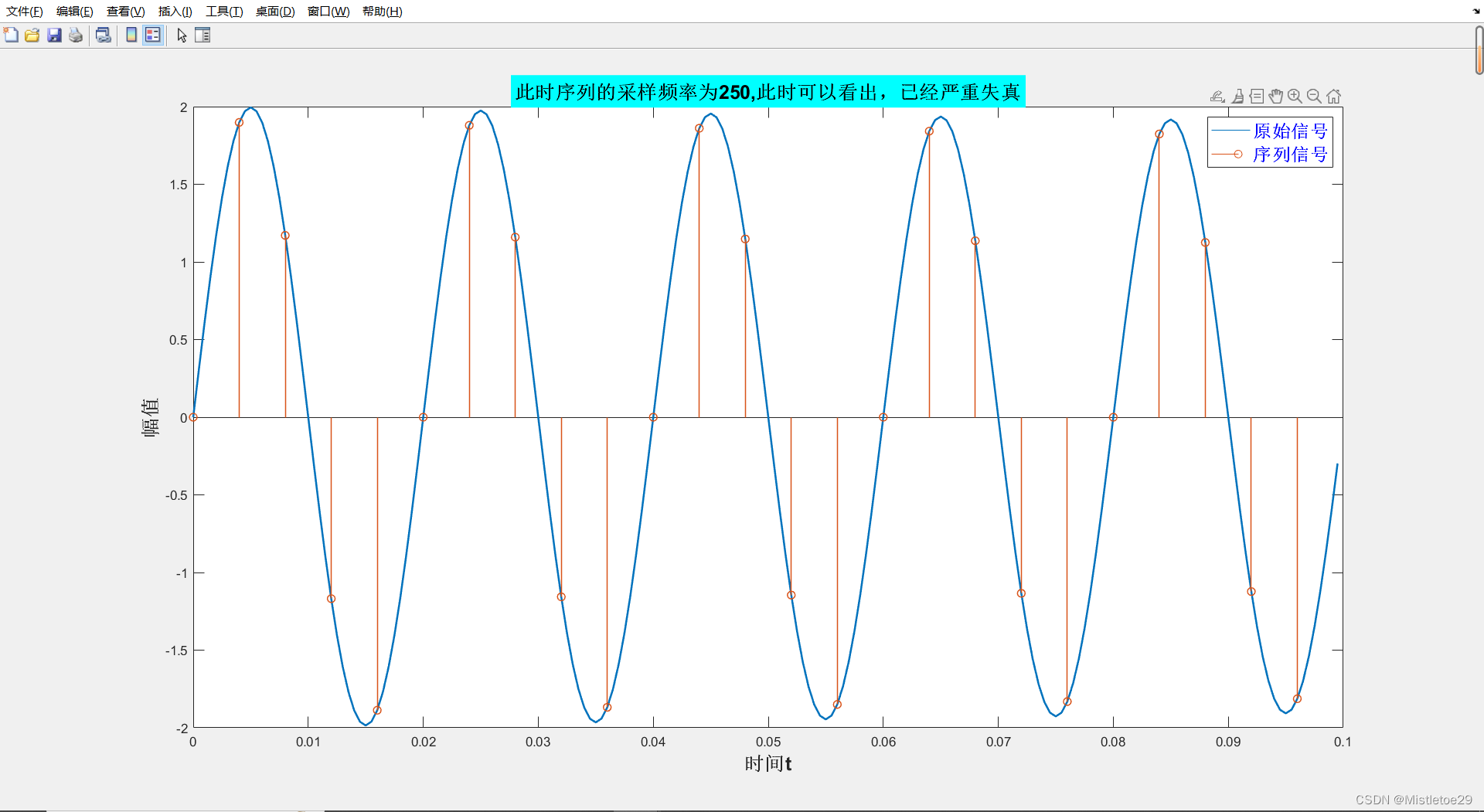
3.6效果图


![[AutoSar]BSW_Com020 Handle_ID,Global_PDU,Local_PDU的联系](https://img-blog.csdnimg.cn/direct/c04895863f1249cabf1ab04dcf48d825.png)


![[金三银四] 操作系统上下文切换系列](https://img-blog.csdnimg.cn/direct/478cb0db2c88434abd4bcaedd9c8b31b.png)