B-tree - 深度解析+C语言实现+opencv绘图助解
- 1. 概述
- 2. B-tree介绍
- 3. Btree算法实现
- 3.1 插入
- 3.1.1 排序
- 3.1.2 分裂
- 1) 叶子节点的分裂
- 2) 根节点的分裂(特殊的分裂)
- 3) 内节点的分裂
- 3.2 删除
- 3.2.1 再平衡(Rebalance)
- 左旋
- 右旋
- 合并
- 3.2.2 从Btree节点删除key
- 从叶子节点删除key(包含叶子节点状态的根节点的情况)
- 从内节点删除key(包括非叶子节点状态的根节点的情况)
- 从btree节点删除key小结
- 3.2.3 补充删除示例
- 3.3 查询和遍历
- 3.3.1 查询
- 3.3.2 遍历
- 顺序遍历
- 逆序遍历
- 搜索遍历
- 逐层遍历
- 4. 代码
- 5. 写在最后
1. 概述
看过很多讲btree的,大多一知半解。有一些能大概讲清原理,但是实现的代码漏洞百出。最近花了点时间整理了一下这些年的资料,建了个代码仓库,从0开始实现了btree。这里成文记录,争取把btree讲透彻。
本文将完成:
- 详细介绍btree的算法实现逻辑,用C语言实现一种Btree的算法,该算法代码:
- 支持构建任意阶的Btree(只要满足m >= 3就行)
- 支持存储任意类型的key
- 代码尽量简洁易懂
- 纯C实现,以便有需要的同学可直接拿去应用。当btree应用于内核这种更底层的场景时,C++实现的版本就不可用了。
- 尽量保证内存安全,代码经过比较严格的UT,以及所有测试代码都通过了valgrind的检测。
- 使用opencv来绘制btree,协助理解btree。包括绘制一些关键的中间临时状态的btree,高亮关键节点展示算法过程等,以进一步理解Btree的实现原理。
B树(B-tree)是一种自平衡的树数据结构,它能够保持数据有序,允许搜索、顺序访问、插入和删除数据的操作都在对数时间内完成。B树特别适用于读写大量数据的系统中,比如数据库和文件系统,因为它们能够有效地最小化磁盘I/O操作。
本文专注介绍Btree的实现以及详细的算法过程。由于这部分已经很多且稍许有一些杂,就不再混入btree的其他内容,比如不讲解B树的应用,为什么能减少IO,与其他树之间的对比等。后续可能会在另外的文本中讲述这些东西。
注意!之前有小伙伴疑惑一个问题:B减树是啥?
- 事实是:没有B减树,只有B树(英文: B-tree)和B加树(英文: B+tree)。不要看到B+tree中的+是加号,就以为B-tree中的“-”是减号,它只是一个短横线,不是减号!!!
B是balance的首字母,你看到的B-tree = Btree,二者是同一个东西。
本文中出现的btree = Btree = B-tree
2. B-tree介绍
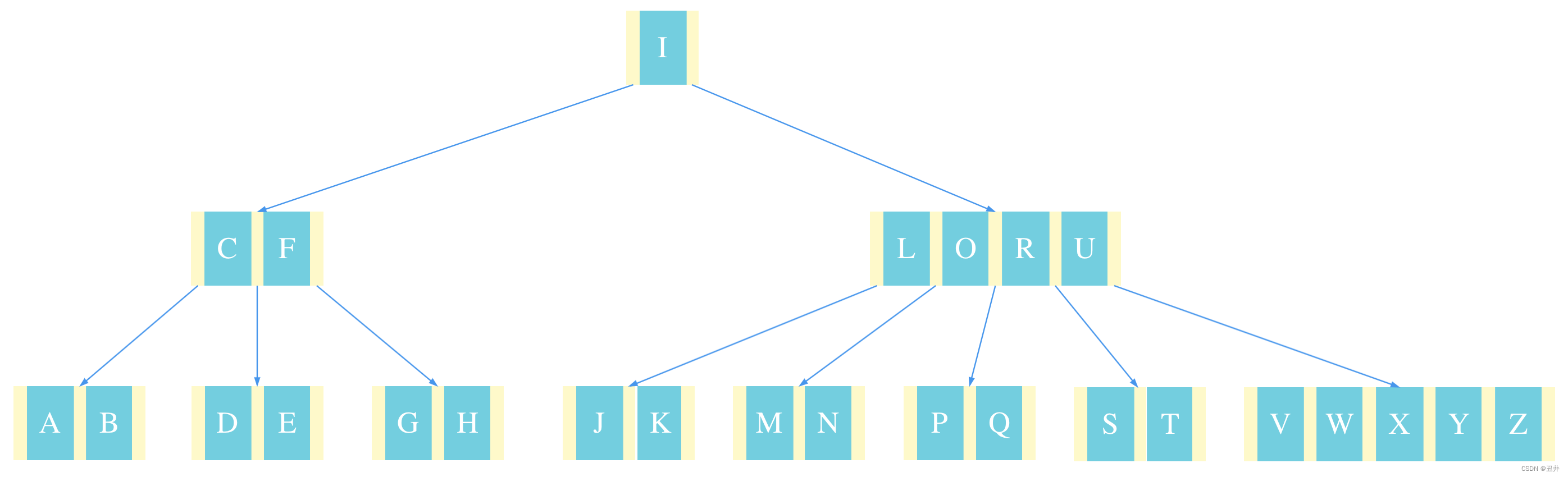
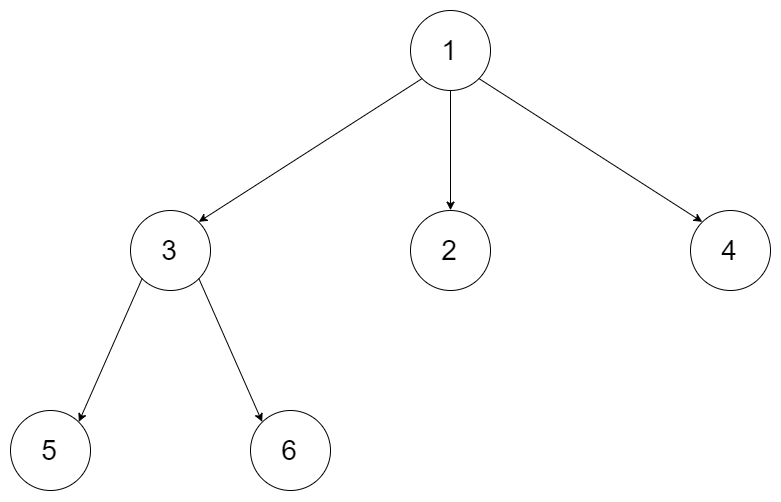
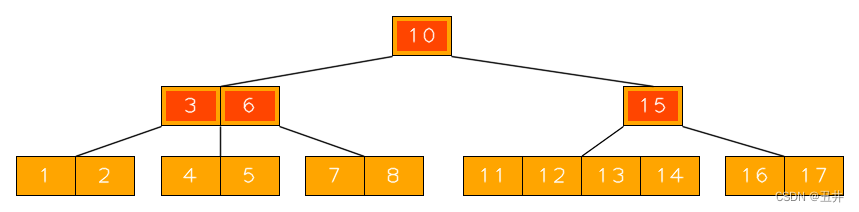
上图就是一棵B树,参照图,对几个名词进行解释:
- Btree节点:一棵B-tree是由1个或多个节点组成的,这些就是btree节点。
- 一个btree节点包含两个关键成员:
- 关键字数组/链表(keys):每个btree节点会存储1个或多个关键字,这些关键字就是btree这个结构体存储的外部数据信息。keys中每一个元素就是一个关键字,本文用key来表示一个关键字。上图中每个节点的绿色部分就是key。
- 孩子节点数组/链表(children):如果btree节点不是叶子节点,那么它就会将自己所有的孩子节点指针存入children。本文用英文child表示一个孩子节点。上图中每个节点的浅黄色部分就是children。
- 父节点:一个根节点或者内节点是自己children中每个节点的父节点。
- 分隔符key,也叫separator:
如上图所示,除了叶子节点,btree节点中的每个key可以看做是2个孩子节点的分隔符key(separator)。
- 也可以说每个key拥有2个孩子节点,一个是左孩子(left child),一个是右孩子(right child)。例如上图中,关键字C的左孩子是节点"AB",右孩子是节点“DE”
- 相邻的两个key共有一个孩子:前一个key的右孩子是后一个key的左孩子。例如上图中,关键字C和F共有孩子节点“DE”,节点“DE”是关键字C的右孩子,是关键字F的左孩子。
- 左孩子及其所有子子孙孙的任意一个key都小于它的separator;同理,右孩子及其所有子子孙孙的任意一个key都大于它的separator。
一棵m阶B-tree满足下面的属性约束:
Btree的属性约束总共有6条,由5条官方标准属性约束(1~5条)和1条推导/约定属性约束(第6条)组成。详细如下:
1. 每个节点最多有m个孩子节点(每个节点最多有m棵子树)
2. 每个内节点至少有⌈m/2⌉个孩子节点(每个内节点至少有⌈m/2⌉棵子树)
- 注1:这里⌈m/2⌉是对m/2的值向上取整
- 注2:这里的内节点不包括根节点
3. 如果根节点有孩子节点,那么根节点至少有2个孩子节点
- 注1:当根节点是叶子节点时,它没有孩子节点。此时孩子节点个数为0。
- 注2:如果根节点有孩子节点,那么这些孩子节点的个数至少是2个。
4. 所有叶子节点都在同一层上
- 注1:如果节点A是叶子节点,那么它的兄弟节点肯定也是叶子节点。
- 注2:推导 -> 如果节点A是内节点,那么它的兄弟节点肯定也是内节点。
5. 有k个孩子节点的
非叶子节点拥有k-1个key。
- 注:很多中文定义中还包含下面的第6条属性,实质上可以根据上面1、2和5来推导
6. (非官方)除了根节点以外,其他节点的关键字数量n满足⌈m/2⌉-1 <= n <= m-1。
- 注1:对于根节点来说,根节点的关键字个数n满足:1<= n <= m-1。
如果根节点是叶子节点时,其key的个数最小可以是1。- 注2:对于内节点来说,此条是毫无疑问的,前面1、2、5都是完全可应用到内节点上的。
由1和2可以推导出:内节点的孩子节点个数k满足⌈m/2⌉ <= k <= m
再结合5,可推导出:内节点的key个数n满足⌈m/2⌉ -1 <= n <= m - 1
所以,对于内节点而言,属性约束6实际上是一个“推导属性约束”
- 注3:对于叶子节点来说,虽然上面1~5的官方属性约束中都未描述对叶子节点的key个数的限制,但是仍然限制叶子节点的key个数n满足⌈m/2⌉-1 <= n <= m-1,分析:
(注意,这里的分析会涉及到分裂的概念,你可以暂时先跳过,往后了解了分裂操作之后,再回头来这里阅读)
- n <= m-1:理论上叶子节点的key个数可以无限大。因为无论多大的n发生分裂,上移一个key到父节点,只要保证父节点(内节点或者根节点)满足属性约束1 ~ 5就行了,剩余分裂出的2个节点仍然是叶子节点。
但是:当一个叶子节点的key个数n被定义得太大时,
- 1)会增加这个节点上key值的搜索时间,因为一般btree节点存储key的是一个数组或者链表,其搜索时间复杂度就是数组或者链表的容量大小(O(n))。
- 2)会导致btree的树高生长非常缓慢,从而没有体现出btree算法的索引优势
所以: 在本算法中,为了更好的利用btree的优势,将叶子节点的key个数最大限制为m-1,跟内节点的限制保持一致。- ⌈m/2⌉-1 <= n:除了是叶子节点状态的根节点以外,其他情况的叶子节点初始都是由一个满key的叶子节点分裂而来的。我们已经限制了叶子节点最大key个数为m-1了,那么满key的时候,key个数临时达到m。另外再考虑m的奇偶性,就可以得到分裂后的节点(2个新的叶子节点)的key个数最少为⌈m/2⌉-1个。
综上,对于叶子节点而言,属性约束6实际上是一个本算法特有的“约定属性约束。
一棵B树有三种节点:
- 根节点(root node)
根节点是B-tree最顶层的那一个节点。B-tree只有1个根节点。当我们对B-tree进行增、删、查的时候,都需要遍历B-tree,而对B-tree的遍历都是从根节点开始的。
根节点的关键字个数肯定大于0,但孩子节点个数可能等于0(当根节点也是叶子节点的时候)。
跟根节点相关的属性约束有1、3、5和6
- 属性约束1:根节点也满足最多只有m个孩子节点。
- 属性约束3:根节点也可以同时是叶子节点,此时整个btree中只有根节点一个节点,且此时根节点没有孩子节点。但是一旦根节点有了孩子节点,那么孩子节点的个数至少为2。
- 属性约束5:有k个孩子节点的根节点,至少有k-1个key。
根节点的key个数n满足:1 <= n <= m-1 (注意区别于属性约束6)
如果根节点有了孩子节点,那么必须满足属性约束3
- 内节点(inner node)
除根节点和叶子节点以外的节点,内节点处于btree的内部。
内节点肯定拥有关键字,内节点也肯定拥有孩子节点指针,即其key和children肯定不为空。
跟内节点相关的属性约束有1、2、5和6
- 属性约束1:每个内节点最多只有m个孩子节点。
- 属性约束2:每个内节点至少有⌈m/2⌉(m/2向上取整)个孩子节点。
- 属性约束5:有k个孩子节点的内节点,至少有k-1个key。
- 属性约束6:由1、2和5可以推导出本属性约束。
- 叶子节点(leaf node)
处在B-tree最下层的节点,这些节点没有孩子节点(即其children为空),只包含关键字(keys)。
跟叶子节点相关的属性约束有4和6
- 属性约束4:所有的叶子节点都在同一层,且是btree的最下面那一层。
- 属性约束6:对此条的理解说明,参见属性约束中第6条的注3。
3. Btree算法实现
本章详细描述Btree的算法实现,基本节奏是先文字描述实现过程,然后上图直观描述过程细节。
后文中一些表达式说明
- 表达式【1,2,3】表示一个包含了3个key的btree节点,三个key分别为1,2,3。
- 表达式key(3)表示3是一个key。区别于【3】表示一个btree节点,该节点包含一个key(3)。
3.1 插入
btree的插入操作,是指将key插入到合适的btree节点中。这个过程由搜索合适的btree节点和插入key到btree节点两部分组成。
- 搜索合适的btree节点这个过程,需要知道3个点:
1)btree不允许插入2个相同的key。即如果在btree某个节点中找到了要插入的key,那么插入失败。 2)btree的插入key操作,都是插入到某个叶子节点上的。
理解1:算法设计如此。如果可以插入内节点,会非常复杂。先看完本文的算法,再回头来理解为什么复杂。
理解2:由于1)的限制,使得在搜索过程中都不会找到等于key的节点,那么最终会搜索到某个叶子节点上。这个叶子节点就是key要被插入的节点。
3)搜索过程是个遍历btree的递归过程,详细参见后面章节[查询和遍历](#query_btree)的描述。 - 接下来着重讲解将key插入btree节点的过程,这个过程包含两个关键的操作:排序和分裂。
3.1.1 排序
关键字key最终是被插入到某个btree节点的关键字数组(或者链表)keys中的,要求是keys中存储的key是有序的,一般是从小到大的顺序。
本算法选取的是链表类型的keys来存储关键字key,原因是方便key的插入、删除、拆分等操作,时间复杂度都是O(m),m是btree的阶。使用数组类型的keys时,插入、删除、拆分操作都变得更复杂了一些,因为除了O(m)的定位搜索时间,还有元素整体前移或后移的时间。
3.1.2 分裂
当插入key操作使得某个btree节点的keys数量临时达到m的时候,由于超出了限制的最大m-1个,违背了btree的属性约束。就需要将该节点一分为二,这就是btree节点的分裂。
- 分裂只发生在btree的插入操作中。
分裂的标准流程:
1)将达到m个key的btree节点的“相对中间”的那个key上移到父节点。
- 如果m是奇数,那么“相对中间”的key就是中间那个key。例如m=5时,
临时节点【1,2,3,4,5】的中间key就是3- 如果m是偶数,那么“相对中间”的key可以是中间2个key中的任意一个。本算法使用的是中间2个key中的第一个。例如m=4时,
临时节点【1,2,3,4】的中间key就是2。
这就使得当m是偶数时,分裂出的两个节点,左节点key个数少于右节点key个数。2)以上移的中间key为界,前后两部分的key分裂为两个btree节点。这两个节点作为刚刚上移到父节点的key的左右孩子。
3)如果分裂的是内节点或者非叶子状态的根节点,分裂的时候还需要将children分成两部分,分别放入分裂出的两个btree节点中。
- children的分裂没有上移操作
- 分裂children的分界点为上移的中间key的左孩子,且该左孩子归属于分裂出的第一部分。
4)由于分裂过程会向父节点插入一个key,这有可能导致父节点的key个数达到m,即可能需要继续对父节点进行分裂操作。
下面以m=3阶的btree为例,直观感受三种节点的分裂:
1) 叶子节点的分裂
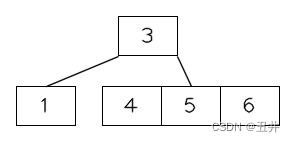
叶子节点的分裂是最简单的,只需要上移中间key,再以中间key分裂key数组(或者链表)就行了。例如当插入key=5时的临时状态,如图所示:
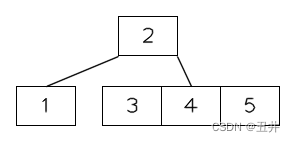
此时节点【3,4,5】的key个数达到m个,开始分裂:
- 上移中间key(4)到父节点
- 剩余分裂为2个节点【3】和【5】,作为父节点中key(4)的左右孩子
如图所示:
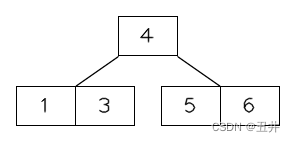
2) 根节点的分裂(特殊的分裂)
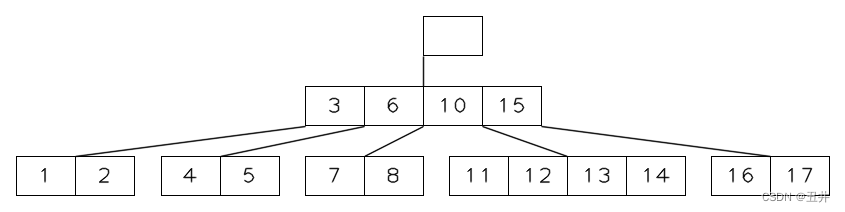
根节点的分裂是特殊的分裂,因为它没有父节点,无法完成“上移key到父节点”这个操作。
需要给根节点构建一个“虚拟的”父节点来解决。下面是根节点分裂的详细流程。
当根节点插入第m个key的时候(注:节点最多只有m-1个key,m个key只是个临时状态),如图:
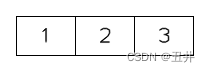
此时开始分裂:
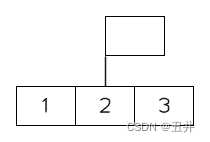
- 给根节点构建一个“虚拟的”父节点:构造一个空的根节点(没有key),将原来的根节点作为这个虚拟根节点的左子树。
如图所示:
- 此时原来的根节点就变成一个叶子节点,就可以对其执行叶子节点的分裂流程:
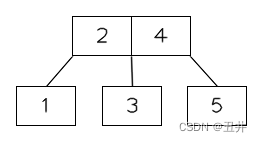
- 上移中间key(2)
- 以中间key(2)为界,将节点分裂为2个节点【1】和【3】。作为新根节点中key(2)的左右孩子。
至此,根节点的分裂结束,如图所示:
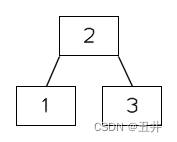
根节点分裂的几个说明:
- btree树高的增加,就是由根节点的分裂产生的。
- 根节点的分裂产生了新的根节点。
3) 内节点的分裂
前面已经讲过“btree的插入key操作,都是插入到某个叶子节点上的”,不会直接插入key到某个内节点。内节点的key个数增加只有一个途径:其孩子节点发生了分裂,上移了一个key给自己。
那么可以得出结论:内节点的分裂肯定是由于孩子节点分裂导致的。详细过程为:插入key到叶子节点导致该叶子节点发生分裂,分裂过程中会往父节点上移一个“中间key”,这个“上移中间key”导致父节点(某个内节点或者根节点)的key个数达到m个,就需要分裂。
- 内节点分裂前的过程:其孩子节点的分裂
顺序从1开始插入btree,当插入key=11的时候,临时状态如下图所示:
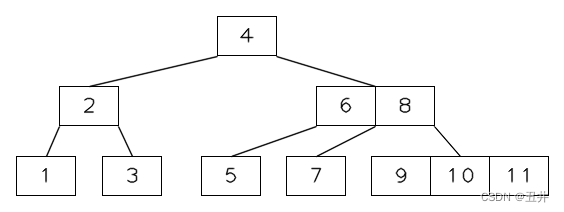
此时叶子节点【9,10,11】的key个数达到m个,开始分裂:- 上移中间key(10)。
- 以key(10)为界,分裂为2个节点【9】和【11】,分别作为父节点中key(10)的左右孩子。
如图:
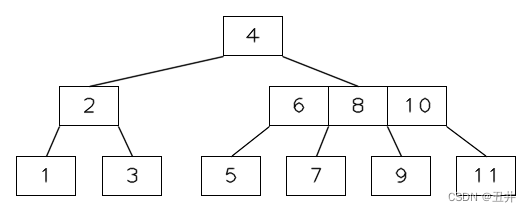
此时,内节点【6,8,10】达到m个key。(注意:上图只是个临时状态)。
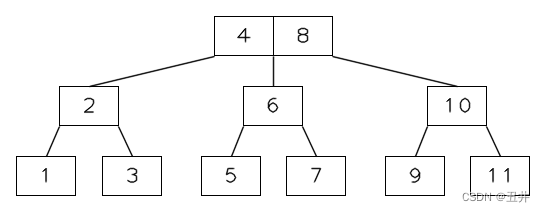
- 内节点的分裂:
现在开始对内节【6,8,10】进行分裂,分裂过程为:- 将中间key(8)上移
- 剩余分裂为2个节点【6】和【10】,分别作为父节点中key(8)的左右孩子。
- 作为内节点,还需要分裂自己的孩子节点数组(或者链表):以中间key(8)的左孩子为界,拆分为2部分,第一部分(包含作为分界的那个左孩子)作为新节点【6】的孩子节点,第二部分作为新节点【10】的孩子节点。
分裂结束后,如图所示:
3.2 删除
从btree中删除key,是一个搜索key和从btree节点中删除key的过程。
- 搜索key的过程,参考下一节查询,目标是定位key所在的btree节点。
- 从btree节点删除key这个过程是Btree最难的部分。因为对于一棵健康的btree,删除key会破坏这棵树,使其无法满足5+1属性约束。
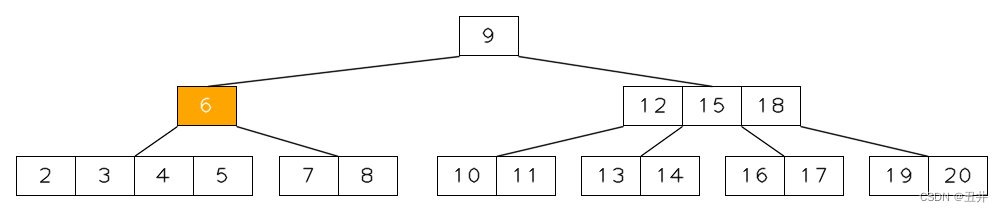
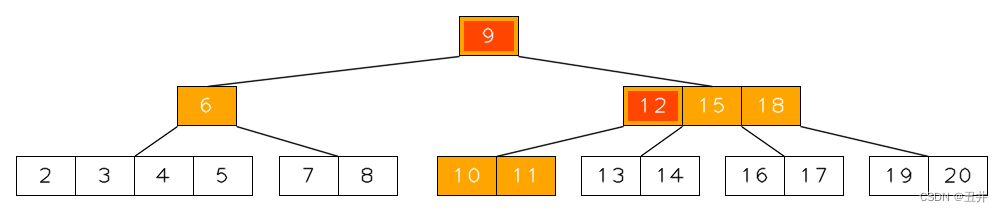
对btree进行删除key操作,会导致btree失去平衡,不满足btree的5+1属性约束。例如,一棵m=5的btree,如下图:
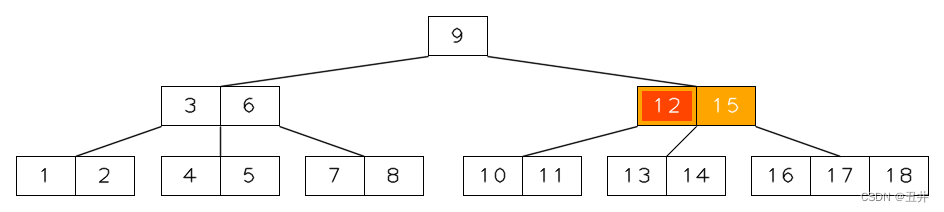
现在删除key(12)(上图红色高亮的位置,黄色高亮部分表示该key所在的btree节点),该节点的key只留下一个key(15),此时的btree就出现“不平衡”了:
- 黄色高亮的节点的key个数只有1,小于了
⌈m/2⌉-1=2个。违背标准属性约束2和5以及推导属性约束6。 - 原节点【12,15】的最左边孩子【10,11】现在无处安放。
这就需要对Btree进行再平衡(Rebalancing),使其最终满足Btree的5+1属性约束。
上图示例的删除和再平衡过程会在本章后面给出详细过程。
从节点删除key会用到再平衡(rebalancing)技术,而再平衡技术中还会涉及到对节点进行删除key,二者是相互调用、相互依赖的关系,比较复杂。综合考虑之下,下面将从内向外讲解:先讲解再平衡的算法逻辑,然后再讲解从不同类型节点删除key的逻辑。
3.2.1 再平衡(Rebalance)
再平衡包含3个操作,分别为左旋、右旋和合并。
说明:
左旋和右旋,在一些btree讲解资料中也被叫做“借位”。详细参见下面对左旋和右旋的讲解,体会“借位”的含义。
左旋和右旋实际是相似的一类操作。但为了方便理解,本文以及代码实现就稍微唠叨一点,都将它俩分开讲解和实现。执行再平衡操作时,三种操作是三选一的,且它们之间是有优先级顺序的
- 先尝试
左旋,可以左旋则再平衡结束,否则- 尝试
右旋,可以右旋则再平衡结束,否则合并(不能左旋和右旋的时候,肯定能合并),再平衡结束后续的讲解中会体现这样的优先级,请注意关注及体会。
左旋
左旋只会发生在从叶子节点或者内节点删除key的时候(根节点没有左旋,因为根节点没有兄弟节点看完本小节再来理解这句)。
当从节点A中删除1个key,导致A的key个数小于key个数最小限制(推导属性约束6规定:n >= ⌈m/2⌉-1)的时候,可以从A的左兄弟(left brother node)或者右兄弟(right brother node)节点中借1个key来填补自己,使自己的key个数维持在最小个数上。前提是:
- 左兄弟或者右兄弟节点被借走1个key以后,它的key个数仍然是大于或等于最小个数限制的。
如何选择从左兄弟还是右兄弟节点中借key?
- 如果左兄弟和右兄弟只存在其中一个(也肯定至少存在其中一个):谁存在选谁。
- 谁的key多就选择谁。这是为了让btree更加平衡
- 当左兄弟和右兄弟的key个数相同的时候,本算法约定
优先从右兄弟节点借key。
所以,当节点A存在右兄弟节点,且右兄弟节点有足够的key,且右兄弟节点的key个数大于左兄弟的时候,那么从右兄弟节点“借”key,发生左旋操作。左旋的标准流程:
在父节点中定位节点A和右兄弟节点的separator。
1)父节点将separator下移到节点A,放在A的keys数组(或者链表)的最后一个位置上。
2)右兄弟最左边的key被“借走”,上移到父节点,放在父节点中原来separator的位置。
3)A节点是内节点的情况,还需要将右兄弟节点的第一个孩子移动到A,作为A的最后一个孩子。
整个过程就是将右兄弟节点的最左侧key、父节点的separator和左兄弟的第一个孩子(内节点才有)整体往左侧旋转了一下,这也是左旋名称的来历。
-
叶子节点的左旋
下面以m=5的一棵btree为例,看看叶子节点的左旋过程:
现在从这棵btree中删除key(2),删除后,临时状态如下图
此时节点【1】的key个数小于⌈m/2⌉-1=2个,其右兄弟节点【4,5,6】的key个数大于2个,发生左旋:- 节点【1】和节点【4,5,6】在父节点【3】的separator为key(3),将其下移到节点【1】中最后一个key
- 右兄弟节点【4,5,6】中最左侧的key(4)上移到父节点,填补原来separator(3)的位置
左旋结束后,如图所示
-
内节点的左旋
下面是m=5的一棵btree(节点最小key个数限制为⌈m/2⌉-1=2个)的临时状态:
上面这个临时状态是由孩子节点的合并操作而来的,合并操作将在后面讲解。我会在合并章节补充描述这张图是如何而来的。
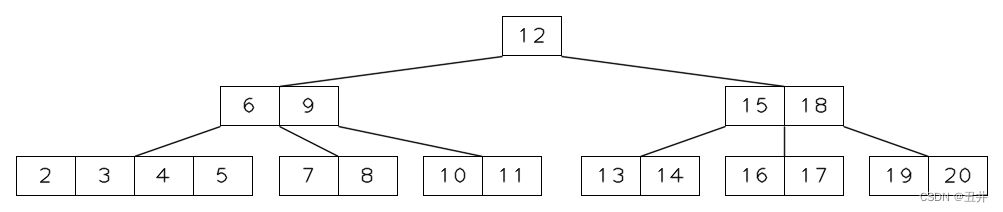
点击查看该临时状态btree的由来。此时,对节点【6】进行再平衡:由于节点【6】没有左兄弟,且其右兄弟节点【12,15,18】存在,且右兄弟节点的key个数大于最小个数限制,可以进行左旋操作:
- 节点【6】和节点【12,15,18】在父节点中的separator为key(9),将其下移到【6】节点作为最后一个key
- 右兄弟节点【12,15,18】的最左侧key(12)上移,填补原来separator(9)的位置
- 右兄弟节点第一个孩子移动到【6】节点,作为最后一个孩子。
(这是区别于叶子节点的左旋,内节点左旋特有的)
需要参与左旋的节点和key如下图中高亮的部分:
上图中,红色部分为左旋相关的key;黄色部分为左旋相关的节点。左旋结束后,如下图所示:
右旋
有了前面“左旋”的铺垫,右旋就简单了,只是方向不同。
右旋只会发生在从叶子节点或者内节点删除key的时候(根节点没有右旋,因为根节点没有兄弟节点)。
当从节点A中删除1个key,导致A的key个数小于key个数最小限制(⌈m/2⌉-1)的时候,从左兄弟节点借key来填补自己,使自己的key个数维持在最小个数上。前提是:
- A节点没有右兄弟节点且左兄弟节点有足够的key(大于key个数最小限制),或者
- A节点左右兄弟节点都存在,且左兄弟节点的key个数比右兄弟多,且左兄弟有足够的key(大于key个数最小限制)
上面2个前提,实际就是不能
左旋,但是能右旋的条件。因为优先级:不能左旋之后,才能考虑是否进行右旋
右旋的标准流程:
在父节点中定位节点A和左兄弟节点的separator。
1)父节点将separator下移到节点A,放在A的keys数组(或者链表)的第一个位置上。
2)左兄弟最右边的key被“借走”,上移到父节点,放在父节点中原来separator的位置。
3)A节点是内节点的情况,还需要将左兄弟节点的最后一个孩子移动到A,作为A的第一个孩子。
整个过程就是将右左兄弟节点的最右侧key和父节点的separator key整体往右侧旋转了一下,这也是右旋名称的来历。
-
叶子节点的右旋
下面以m=5的一棵btree为例,看看叶子节点右旋的过程:
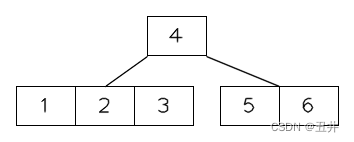
现在从这棵btree中删除key=5,删除后,临时状态如下图
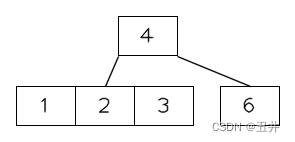
此时节点【6】的key个数小于⌈m/2⌉-1=2个,并且其没有右兄弟节点,且其左兄弟节点的key个数大于最小限制的2个,发生右旋:- 两个子节点在父节点【4】的separator为4,将其下移到节点【6】中第一个key的位置
- 左兄弟节点【1,2,3】中最右侧的key 3上移到父节点,填补原来4的位置
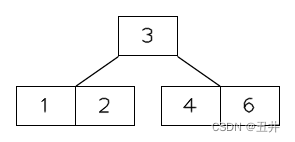
右旋结束后,如图所示
-
内节点的右旋
下面是m=5的一棵btree的临时状态
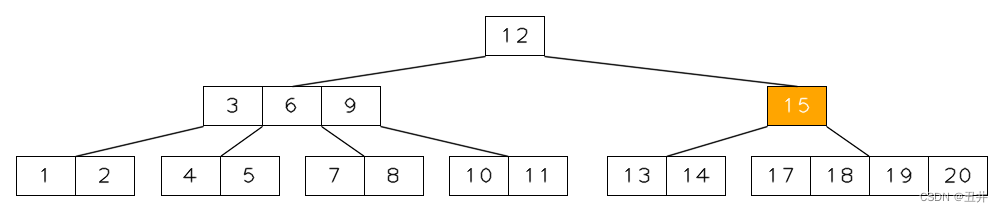
上面这个临时状态是由孩子节点的合并操作而来的,合并操作将在后面讲解。我会在合并章节补充描述这张图是如何而来的。
点击查看该临时状态btree的由来。此时,对节点【15】进行再平衡:由于节点【15】没有右兄弟,且其左兄弟节点【3,6,9】存在,且左兄弟节点的key个数大于最小个数限制,可以进行右旋操作:
- 节点【15】和节点【3,6,9】在父节点中的separator为12,将其下移到【15】节点作为第一个key
- 左兄弟节点【3,6,9】的最右侧key(9)上移,填补原来separator(12)的位置
- 左兄弟节点最后一个孩子移动到【15】节点,作为第一个孩子节点。
(这是区别于叶子节点的右旋,内节点右旋特有的)
需要参与右旋的节点和key如下图中高亮的部分:
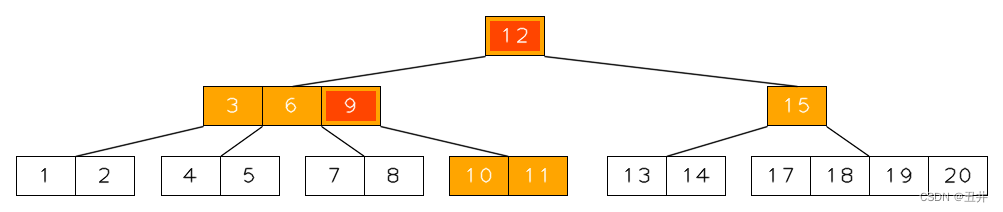
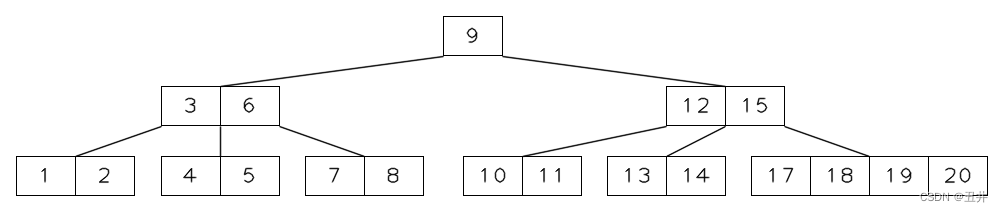
上图中,红色的key(9和12)会发生右旋;叶子节点【10,11】会迁移到填补后的节点【15】中,作为其第一个孩子。右旋结束后,如下图所示:
合并
本节先以叶子节点为例介绍合并操作,然后讲解内节点的合并,最后讲解父节点是根节点的合并,以及补充一些前文涉及到的合并操作。
当从节点A中删除1个key,导致A的key个数小于key个数最小限制(⌈m/2⌉-1)的时候,有三种情况会出现合并操作:
情况1:左兄弟节点不存在,右兄弟节点存在,但是右兄弟节点的key个数是最小限制个数
情况2:左兄弟节点存在,右兄弟节点不存在,但是左兄弟节点的key个数是最小限制个数
情况3:左兄弟节点和右兄弟节点都存在,但是它们的key个数都是最小限制个数
上面的三种情况,实际就是即不能左旋,又不能右旋的情况。因为优先级:不能左旋和右旋之后,才进行合并
合并的标准流程:
1)确定节点A要与之合并的节点B
- 在情况1中:B为右兄弟节点
- 在情况2中:B为左兄弟节点
- 在情况3中:B可以是左兄弟,也可以是右兄弟。本算法中优先选择右节点,所以B是右节点。
2)将A和B在父节点中的separator从父节点中删除
3)将A和separator以及B合并为一个节点,合并到A、B两个节点中左侧的那个节点中。
- 在情况1和情况3中,A节点是左侧的节点,所以是合并到A节点中。
- 在情况2中,B节点是左侧的节点,所以是合并到B节点中。
4)删除A、B两个节点中右侧的那个节点。
- 在情况1和情况3中,B是右侧的节点,所以删除的是B
- 在情况2中,A是右侧的节点,所以删除的是A。
5)如果A是内节点,还需要将A和B的孩子进行合并。合并到A、B两个节点中左侧的那个节点中。
下面以m=5的一棵btree为例,看看几种情况下的合并过程:
-
情况1的合并:
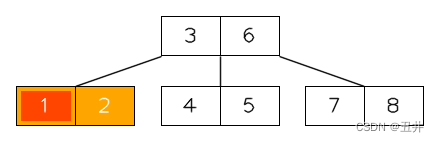
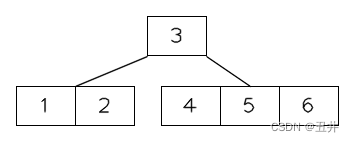
在这棵btree中删除key(1),临时状态为:
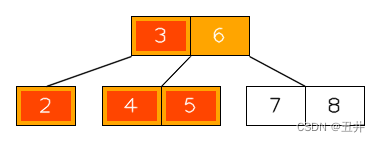
此时节点【2】的key个数少于最小限制,并且无法发生左旋或者右旋。所以需要进行合并,上图红色部分就是需要合并的节点和key,详细如下:- 此时节点【2】没有左兄弟,且其右兄弟节点【4,5】的key个数刚好等于最小限制,无法进行左旋。所以需要与右兄弟【4,5】进行合并。
- 从父节点中删除它们的separator(3)
- 节点【2】是左侧的节点,所以将【2】、key(3)和【4,5】合并到节点【2】中。
- 删除偏右侧的节点【4,5】
合并后,如图:
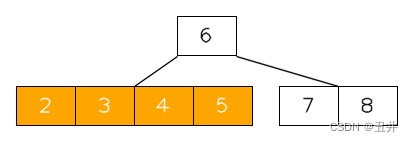
-
情况2的合并:
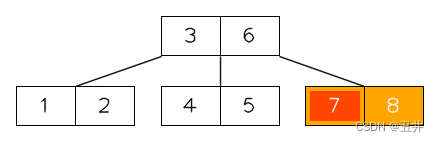
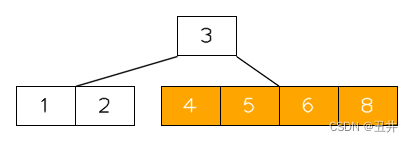
在这棵btree中删除key(7),临时状态为:
此时节点【8】的key个数少于最小限制,并且无法发生左旋或者右旋。所以需要进行合并,上图红色部分就是需要合并的节点和key,详细如下:- 此时节点【8】没有右兄弟,且其左兄弟节点【4,5】的key个数刚好等于最小限制,无法进行右旋。所以需要与左兄弟【4,5】进行合并。
- 从父节点中删除它们的separator(6)
- 节点【4,5】是左侧的节点,所以将【4,5】、key(6)和【8】合并到节点【4,5】中。
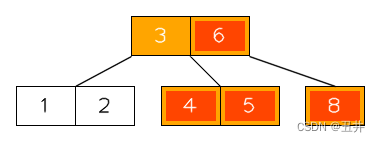
- 删除偏右侧的节点【8】
合并后,如图:
-
情况3的合并:
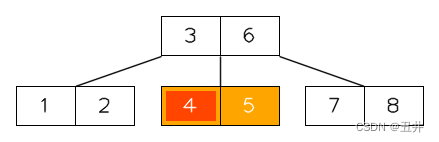
在这棵btree中删除key(4),临时状态为:
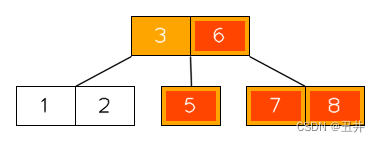
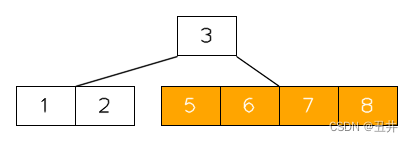
此时节点【5】的key个数少于最小限制,并且无法发生左旋或者右旋。所以需要进行合并,上图红色部分就是需要合并的节点和key,详细如下:- 此时节点【5】的左兄弟和右兄弟都存在,且都只有最小限制个数个key(2个),无法发生左旋或者右旋。所以需要进行合并,由于左兄弟和右兄弟的key个数相同,本算法在这种情况下优先选择与右兄弟进行合并,即需要与节点【7,8】进行合并
- 从父节点中删除它们的separator(6)
- 节点【5】是左侧的节点,所以将【5】、key(6)和【7,8】合并到节点【5】中。
- 删除偏右侧的节点【7,8】
合并后,如图:
-
补充1:父节点是根节点,且根节点只有一个key的合并:
此种情况,跟上述合并逻辑一样,只不过会导致合并后的节点成为新的根节点,btree高度减1。
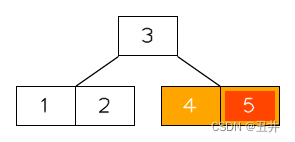
在这棵btree中删除key(5),临时状态为:
此时节点【4】的key个数少于最小限制,并且无法发生左旋或者右旋。所以需要进行合并,上图红色部分就是需要合并的节点和key,详细如下:
- 此时节点【4】的没有右兄弟,所以需要与左兄弟节点【1,2】进行合并
- 从父节点中删除它们的separator(3)
- 节点【1,2】是左侧的节点,所以将【1,2】、key(3)和【4】合并到节点【1,2】中。
- 删除偏右侧的节点【4】
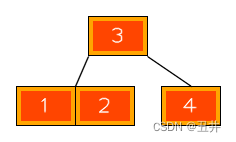
合并后,如图:
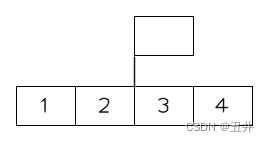
根节点被删空了,修正之后:合并后的节点【1,2,3,4】成为新的根节点,如图:
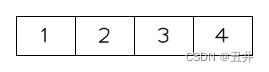
-
补充2:内节点的合并:
内节点的合并是由从内节点删除key触发的。这句话不完全正确,稍后修正它。
首先需要了解从内节点删除key是存在2种情况:1)直接从内节点删除key:目标key就在内节点中。这种情况的删除不会
立即触发再平衡(左旋/右旋/合并),详细参见从内节点删除key-情况2。
2)间接从内节点删除key:要删除的key不在内节点,而是在叶子节点中。对叶子节点执行删除key操作,然后叶子节点发生合并,导致父节点被下移一个key。如果父节点不是根节点,即父节点是内节点,且此时父节点的key个数少于了最小key个数限制,那么就需要立即对父节点进行再平衡操作。此时只有在父节点不能发生左旋和右旋的时候,才会发生父节点的合并,即内节点的合并。现在再来修正这句话“内节点的合并是由从内节点删除key触发的”:
只有孩子节点合并引发的内节点删除key才有可能立即触发内节点的再平衡操作(左旋/右旋/合并)或者跟本节相关的内节点的合并是由其孩子节点合并触发的。前面讲
内节点的左旋和右旋的时候,由于当时还未讲解合并操作,都是直接从需要左旋或右旋的内节点临时状态开始讲解的。现在可以补充上:内节点的左旋和右旋是由其孩子节点合并触发的。这个触发流程的整体演示,将在后面完整演示。
下面以
m=5的一棵btree为例,演示内节点的合并过程:-
内节点合并前的过程:孩子节点的合并
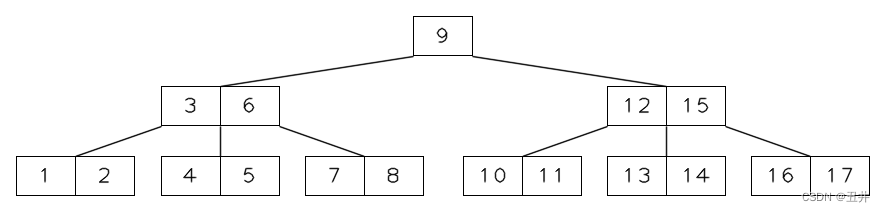
在这棵btree中删除key(5),导致节点【4,5】变为【4】,key个数少于最小限制2,需要对其执行再平衡。- 由于它的左兄弟【1,2】和右兄弟【7,8】都没有足够的key来发生右旋和左旋,于是发生合并操作。
- 由于左右兄弟的key个数相同,优先选择右兄弟,所以与右兄弟【7,8】进行合并:
- 在父节点的separator(6)下移
- 临时节点【4】是左侧的节点,所以将【4】、key(6)和【7,8】合并到节点【4】中
- 删除右侧的节点【7,8】
孩子节点合并后,如图:
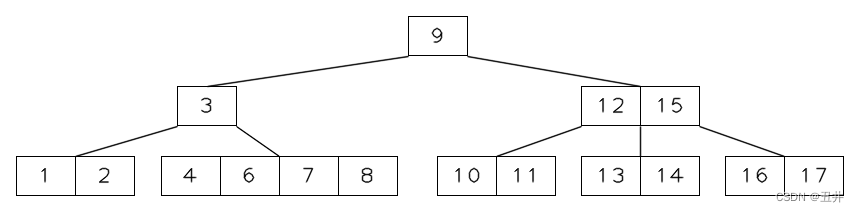
此时需要对内节点【3】进行再平衡。由于节点【3】没有左兄弟节点,且其右兄弟节点【12,15】没有足够的key来提供左旋。所以会发生内节点的合并,合并的对象是右节点【12,15】 -
内节点的合并
1)已确定节点【3】与右兄弟节点【12,15】进行合并
2)从父节点中删除它们的separator(9)
3)节点【3】是左侧的节点,所以将【3】、key(9)和【12,15】合并到节点【3】中。
4)删除偏右侧的节点【12,15】
5)由于是内节点,还需要合并孩子。将节点【12,15】的孩子合并到【3】中。合并结束后,如图所示:
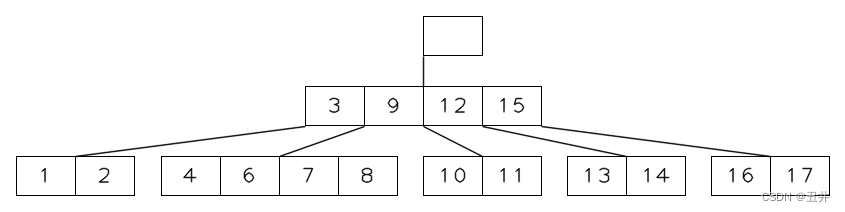
由于根节点被删空了,新合并的节点【3,9,12,15】成为新的根节点,最终结果为:

-
补充3:前面几个临时状态btree的由来
1)内节点左旋示例临时状态由来
实际是由孩子节点的合并而来:
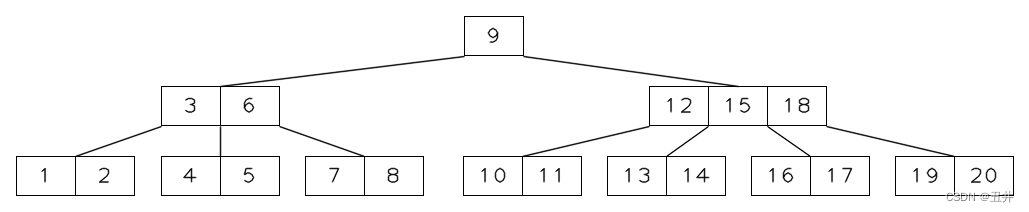
上图为m=5的一棵btree,现在删除key=1,节点【1,2】变为【2】,其个数小于最小个数限制,需要再平衡。
由于【2】的左右兄弟节点都没有足够的key来发生左旋或者右旋,所以将只需合并。由于没有左兄弟节点,所以与右节点【4,5】进行合并。
父节点中separator(3)下移与节点【2】和【4,5】合并。于是得到临时状态:
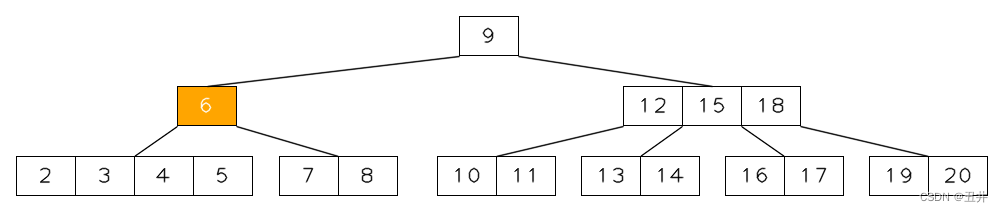
2)内节点右旋示例临时状态由来
实际也是由孩子节点的合并而来:
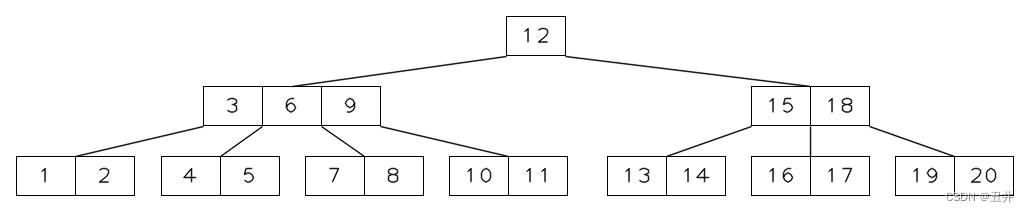
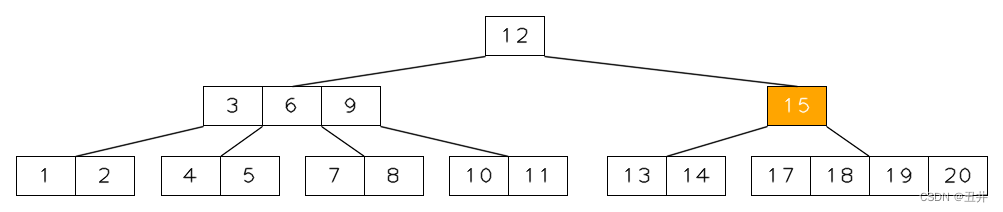
上图为m=5的一棵btree,现在删除key=16,节点【16,17】变为【17】,其个数小于最小个数限制,需要再平衡。
由于【17】的左右兄弟节点都没有足够的key来发生左旋或者右旋,所以将只需合并。由于左右兄弟节点的key个数相同,所以选择与右兄弟节点【19,20】进行合并。
父节点中separator(18)下移与节点【17】和【19,20】合并。于是得到临时状态:
3.2.2 从Btree节点删除key
从叶子节点删除key(包含叶子节点状态的根节点的情况)
从叶子节点中删除key的流程:
1)直接删除key
2)如果删除后key个数仍然大于等于最小key个数限制,那么删除结束。
3)如果删除后key个数小于了最小key个数限制,那么从这个叶子节点开始进行再平衡
- (1) 能左旋?能就左旋,不能就继续
- (2) 能右旋?能就右旋,不能就继续
- (3) 肯定可以合并(除非是叶子节点),进行合并
- (4) 合并会导致父节点删除一个key,如果父节点的key个数少于了最小key个数限制,对父节点进行再平衡(对父节点执行从(1)开始的操作)
从内节点删除key(包括非叶子节点状态的根节点的情况)
从内节点中删除key,是稍微特殊的操作。
首先要明确一点,从内节点删除key存在2种情况:
情况1 - 间接删除:要删除的key不在内节点中。但由于内节点的孩子节点的合并操作,导致内节点作为父节点会删除一个key(下移一个key)。这种形式的内节点删除key,只需要对内节点进行再平衡操作就行,本节不再进行阐述。详情参见“内节点的左旋”“内节点的右旋”“内节点的合并”
情况2 - 直接删除:要删除的key就在内节点中。这是本节要阐述的情况。
当要删除的key在内节点时(情况2 - 直接删除),不管是否会导致key个数小于最小限制,也不管是否有左或者右兄弟节点,都需要进行处理。处理流程如下:
从内节点删除key
情况2 - 直接删除的流程:
1)从要删除的key的左子树或者右子树中找到最值key,来替换要被删除的key,作为这两棵子树新的separator。
- 1.1 如果是从右子树中寻找
最值key,那么是寻找右子树的最小值key。从右子树根节点(要删除key的右孩子节点)开始逐级往下遍历,每次遍历节点的最左孩子,一直到叶子节点。这个最小值key就是这个叶子节点的第一个key。- 1.2 如果是从左子树中寻找
最值key,那么是寻找左子树的最大值key。从左子树根节点(要删除key的左孩子节点)开始逐级往下遍历,每次遍历节点的最右孩子,一直到叶子结点。这个最大值key就是这个叶子节点的最后一个key。- 1.3 如何选择从左子树还是右子树中找
最值key呢?
- 首先要明确一点,左和右都可以,没有限制。
- 出于优化的目的,本算法是这样选择的:
要删除key的左孩子和右孩子节点,谁的key个数多,就选谁。如果key个数相同,则选择右子树。这是因为选中的最值key是需要被删除的,选中key个数多的,可以让左右子树个数尽量平衡。2)对
最值key所在的叶子节点执行删除key的操作,详细参见从叶子节点删除key的描述。
小结:从内节点删除key情况2-直接删除,本质上是将问题简化转移到从叶子节点删除key。
坑位提醒again:上述流程只适用于
情况2 - 直接删除,即要删除的key就在内节点中。而情况1 - 间接删除是由于孩子节点合并引发的内节点删除key,只需要进行再平衡就好了。
这个区分很重要,没区分好,会让自己和算法陷入死循环中。
从内节点删除key - 情况2 - 直接删除的示例(以本章开头的btree删除为例):
上图是m=5的一棵btree,现在执行删除内节点【12,15】的key(12)(红色高亮)。
- 现在开始选取
最值key来替换key(12)- 根据1.3的规则(左右孩子的key个数相同,则选择右孩子),选取key(12)的右孩子【13,14】。
- 再根据1.1的规则(从右子树中寻找最值key,寻找的是最小值key),最值key为key(13)。
替换后如下图所示:
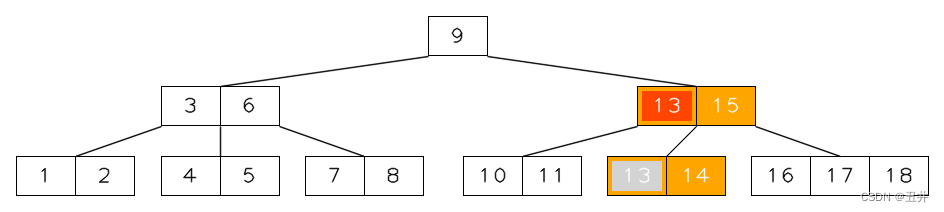
然后,对节点【13,14】这个叶子节点执行删除key(13)的操作。
删除key(13)后,临时状态如图:
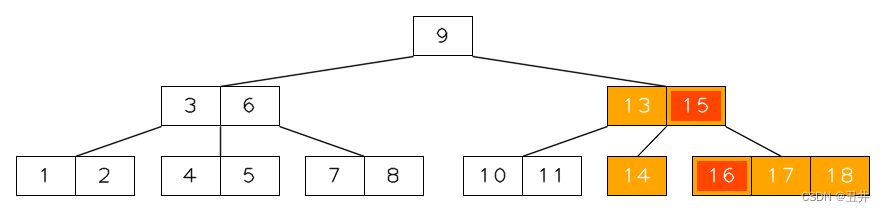
对节点【14】执行再平衡:左旋(右节点有足够的key,于是从右节点借key来填补,左旋的key是上图红色高亮部分)
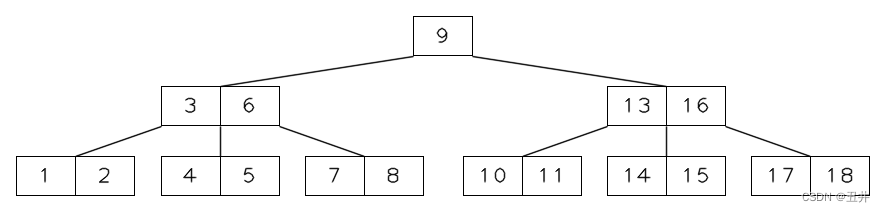
此时Btree达到了平衡,从内节点删除key结束。
从btree节点删除key小结
现在可以将各种情况的删除key汇总到一起了,如下图所示:
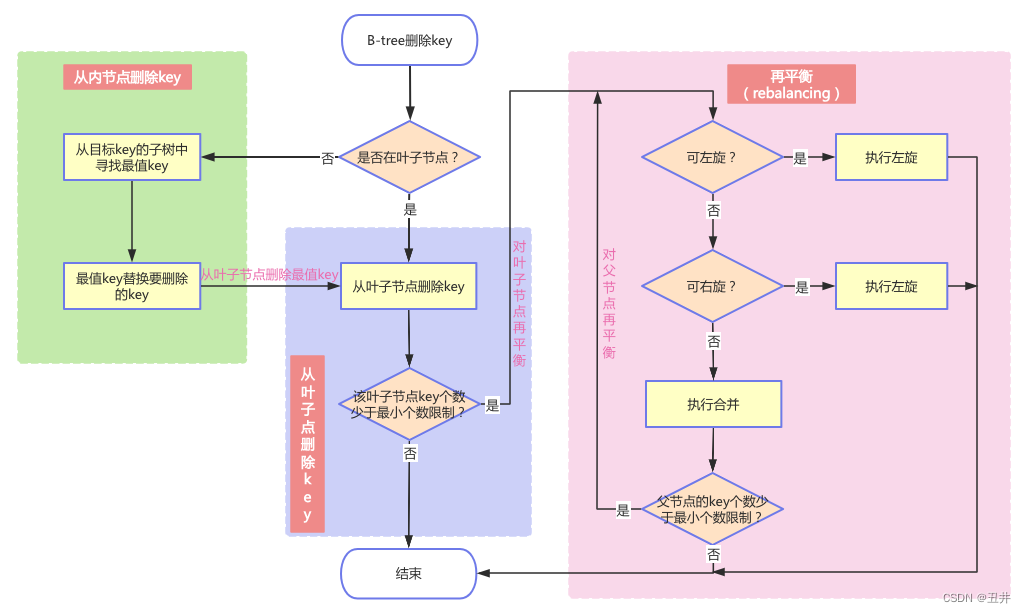
说明:
- 绿色框是“从内节点删除key”的主要逻辑,包含从非叶子状态的根节点中删除key的情况。
- 紫色框是“从叶子节点删除key”的主要逻辑,包含从叶子状态的根节点中删除key的情况。
- 粉色框是“再平衡(rebalancing)”的主要逻辑。包含递归对父节点进行再平衡的逻辑。
3.2.3 补充删除示例
本小节再举几个更复杂的删除key的例子,请结合上面的流程图,再来巩固btree的删除key流程。
示例1:删除的key在内节点,多次合并

上图是一棵m=5的btree(最小key个数限制为2个),现在删除key(15),最终结果为:

小伙伴们可以自己尝试复盘删除的过程。
删除的详细过程:
-
最值key替换:删除的key(15)在内节点中,属于从内节点删除key的情况2 - 直接删除。第一步,寻找最值key来替换key(15):- 由于key(15)的左右孩子拥有相同的key个数,根据1.3的规则,优先选择右孩子。
- 再根据1.1的规则,
最值key为key(16)
用key(16)替换key(15),如图所示:

-
从叶子节点删除key:对最值key(16)所在的叶子节点【16,17】执行删除key(16)的操作,删除后临时状态如图:

现在节点【17】需要再平衡:由于它没有右兄弟节点,左兄弟节点key个数无法提供右旋,所以是执行与左节点【13,14】合并:

如上图所示,高亮部分就是合并的参与者,包括父节点中的separator(16),左侧节点【13,14】和右侧节点【17】,这是叶子节点的合并,合并过程细节为:- separator(16)下移
- 节点【13,14】、separator(16)和节点【17】合并到左侧节点【13,14】中
- 删除右侧节点【17】
合并结束后,如下图所示:

上图中红色高亮的节点【13,14,16,17】就是合并后的节点。
如上图所示,刚才叶子节点的合并导致原来的父节点【12,16】下移了一个key(删除了key(12),由孩子合并导致自己删除key属于从内节点删除key的情况1-间接删除),现在变成【12】,需要继续对这个内节点【12】执行再平衡:由于它左右兄弟都存在,且都没有足够的key来提供左旋或者右旋,所以是执行合并。 -
对临时状态的内节点【12】执行合并操作:
- 1)确定要合并的节点:由于【12】的左右兄弟都存在,且它们的key个数相同,此种情况下是优先选择右兄弟节点【21,24】
- 2)将【12】和【21】的separator(18)从父节点删除
- 3)将【12】、separator(18)和【21,24】合并到偏左侧的【12】节点中。
- 4)删除偏右侧的节点【21,24】
- 5)将【12】和【21,24】的孩子合并,放入新合并的节点中。
下图展示需要合并的节点和key(红色是合并的主力,叶子层高亮节点是需要合并的孩子):

合并完成以后如下图所示(这也是本次删除的最终结果形态):

示例2:删除的key在内节点,降低树高
从非叶子状态的根节点删除key,也是属于从内节点删除key的范畴。
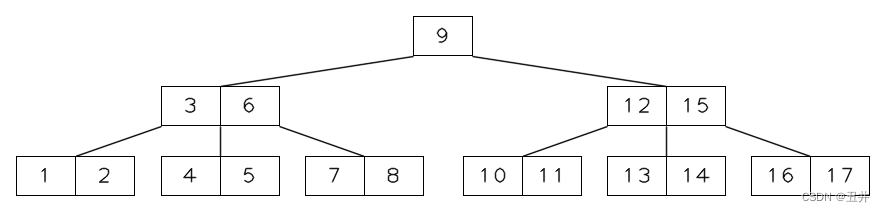
上图是一棵m=5的btree(最小key个数限制为2个),现在删除key(9),最终结果为:

删除的详细过程:
-
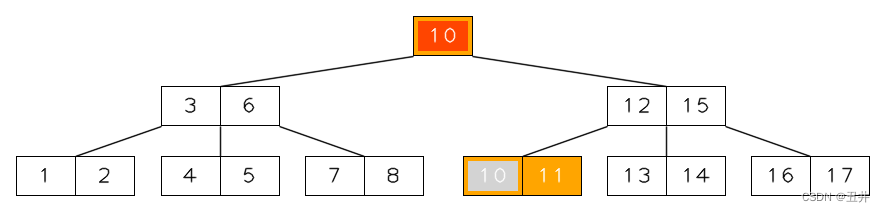
最值key替换:删除的key(9)在非叶子状态的根节点中,也是属于从内节点删除key的情况2 - 直接删除。第一步,寻找最值key来替换key(9):- 由于key(9)的左右孩子拥有相同的key个数,根据1.3的规则,优先选择右孩子。
- 再根据1.1的规则,最值key是节点【10,11】上的key(10)
用key(10)替换key(9),如图所示:
-
从叶子节点删除key:对最值key(10)所在的叶子节点【10,11】执行删除key(10)的操作,删除后临时状态如图:
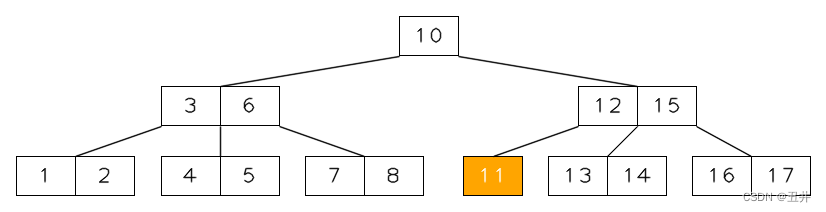
现在节点【11】需要再平衡:由于它没有左兄弟节点,右兄弟节点key个数无法提供左旋,所以是执行与右节点【13,14】合并:
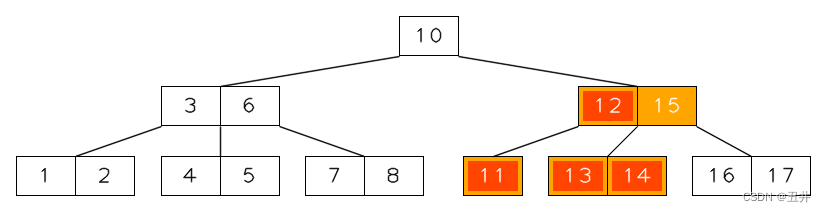
如上图所示,高亮部分就是合并的参与者,包括父节点中的separator(12),左侧节点【11】和右侧节点【13,14】,这是叶子节点的合并,合并过程细节为:- separator(12)下移
- 节点【11】、separator(12)和节点【13,14】合并到偏左侧的【11】节点中
- 删除偏右侧【13,14】
合并结束后,如下图所示:
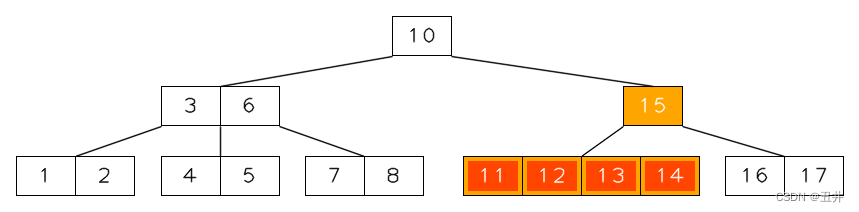
上图中红色高亮的节点【11,12,13,14】就是合并后的节点。
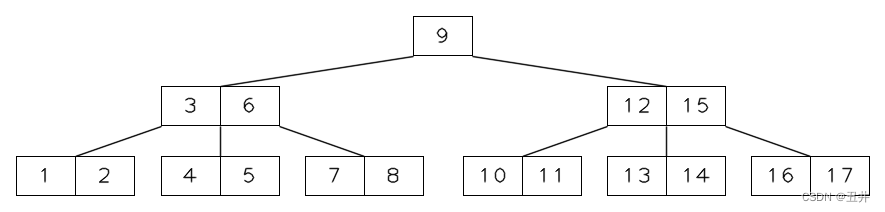
如上图所示,刚才叶子节点的合并导致原来的父节点【12,15】下移了一个key(删除了key(12),由孩子合并导致自己删除key属于从内节点删除key的情况1-间接删除),现在变成【15】,需要继续对这个内节点【15】执行再平衡:由于它没有右兄弟节点,且左兄弟节点没有足够的key来提供右旋,所以是执行合并,与左侧节点【3,6】合并。 -
对临时状态的内节点【15】执行合并操作:
上图红色高亮的为合并的主力:左侧节点【3,6】、separator(10)和右侧节点【15】;叶子层高亮的节点是需要合并的children。- 1)前面已经确认是与左兄弟节点【3,6】合并。
- 2)将separator(10)从父节点删除
- 3)将【3,6】、separator(10)和【15】合并到左侧的【3,6】节点中。
- 4)删除偏右侧的节点【15】
- 5)将【3,6】和【15】的孩子合并,放入新合并的节点中。
合并后,如下图所示:
此时根节点被删空了,修复:降低树高,新合并的节点【3,6,10,15】成为新的根节点。修复后,本次删除结束。最终结果如图所示:

Tip:
本小节举的例子都是归属从内节点删除key情况2-直接删除的类别。没有举从叶子节点删除的例子。
那是因为从叶子节点删除key的过程,是从内节点删除key情况2-直接删除过程的一个子集。后者包含前者。
3.3 查询和遍历
3.3.1 查询
从btree中搜索目标key,是一个从根节点开始向下遍历btree的过程。搜索的时间复杂度为O(height*m),式子中height为树的高度,m为btree的阶。因为总共最多遍历height个节点,每个节点最多m-1个key的遍历查询。搜索一个目标key的详细流程如下:
1)从根节点开始遍历btree节点,在经过的节点上寻找第一个大于等于
目标key的key。
2)若找到第一个大于目标key的key,则继续往该key的左子树上搜索目标key。
因为左子树里的每个key都小于separator(key)。
3)若没有找到大于或等于目标key的key,则继续从该节点的最右子树上搜索目标key
因为右子树里的每个key都大于separator(key)。
4)若找到等于目标key的key,则搜索结束。
下图展示从一棵btree中搜索key(35)的过程(从根节点开始高亮的节点,红色的key是所在节点中第一个大于或等于35的key):

- 第1次遍历:节点【27】没有大于或等于key(35)的key,所以继续遍历其
最右子树(根节点为【36,45】的子树) - 第2次遍历:节点【36,45】存在第一个大于或等于key(35)的key(36),所以继续遍历key(36)的左子树(根节点为【30,33】的子树)
- 第3次遍历:节点【30,33】没有大于或等于key(35)的key,所以继续遍历其
最右子树(根节点为【34,35】的子树) - 第4次遍历:节点【34,35】搜索到key(35),搜索结束。
3.3.2 遍历
本文提供了4种btree的遍历,分别是
顺序遍历:按照key的顺序来遍历btree
逆序遍历:按照key的逆序来遍历btree
搜索遍历:(搜索不太恰到,暂时用了)按照类似搜索key时的递归来遍历btree。
逐层遍历:一层一层地遍历btree
本小节的遍历都以下面这棵m=5的btree为例来演示:
顺序遍历
由于
- btree每个节点中的key是顺序存储的
- 内节点和非叶子状态的根节点的每个key大于其左子树中的任意key,小于其右子树中的任意key。
即,btree在某个维度上是有序的。每个节点遍历顺序:
- 叶子节点: key1 -> key2 … -> keyn
- 非叶子节点:child1 -> key1 -> child2 -> key2 … -> keyn -> childn+1
顺序遍历的测试用例:
./hjs_test btree traverse sequence
顺序遍历的结果输出:
注:输出的每行格式为[
key值](层数/当前btree节点在当前层的索引/key在节点中的索引/key的全局索引)【当前的btree节点】
例如:[ 1](3/0/0/00)【1,2】表示key(1)在第3层的0号btree节点,key(1)在当前节点中的索引为0,在当前的遍历模式中,key(1)的全局索引为00,所在的btree节点为【1,2】
[ 1](3/0/0/00)【1,2】
[ 2](3/0/1/01)【1,2】
[ 3](2/0/0/02)【3,6】
[ 4](3/1/0/03)【4,5】
[ 5](3/1/1/04)【4,5】
[ 6](2/0/1/05)【3,6】
[ 7](3/2/0/06)【7,8】
[ 8](3/2/1/07)【7,8】
[ 9](1/0/0/08)【9】
[10](3/3/0/09)【10,11】
[11](3/3/1/10)【10,11】
[12](2/1/0/11)【12,15】
[13](3/4/0/12)【13,14】
[14](3/4/1/13)【13,14】
[15](2/1/1/14)【12,15】
[16](3/5/0/15)【16,17】
[17](3/5/1/16)【16,17】
逆序遍历
逆序遍历的原理同顺序遍历,只不过方向相反。
逆序遍历的测试用例:
./hjs_test btree traverse reverse
逆序遍历的结果输出:
[17](3/0/0/00)【16,17】
[16](3/0/1/01)【16,17】
[15](2/0/0/02)【12,15】
[14](3/1/0/03)【13,14】
[13](3/1/1/04)【13,14】
[12](2/0/1/05)【12,15】
[11](3/2/0/06)【10,11】
[10](3/2/1/07)【10,11】
[ 9](1/0/0/08)【9】
[ 8](3/3/0/09)【7,8】
[ 7](3/3/1/10)【7,8】
[ 6](2/1/0/11)【3,6】
[ 5](3/4/0/12)【4,5】
[ 4](3/4/1/13)【4,5】
[ 3](2/1/1/14)【3,6】
[ 2](3/5/0/15)【1,2】
[ 1](3/5/1/16)【1,2】
搜索遍历
搜索遍历,是按照从根节点开始,逐级往下递归每个节点及孩子节点。它的特点是优先遍历到叶子节点,然后再递归回溯。这个过程前半部分跟搜索key过程类似,所以暂时命名这种遍历方式为“搜索遍历”。
搜索遍历的测试用例:
./hjs_test btree traverse search
搜索遍历的结果输出:
[ 9](1/0/0/00)【9】
[ 3](2/0/0/01)【3,6】
[ 6](2/0/1/02)【3,6】
[ 1](3/0/0/03)【1,2】
[ 2](3/0/1/04)【1,2】
[ 4](3/1/0/05)【4,5】
[ 5](3/1/1/06)【4,5】
[ 7](3/2/0/07)【7,8】
[ 8](3/2/1/08)【7,8】
[12](2/1/0/09)【12,15】
[15](2/1/1/10)【12,15】
[10](3/3/0/11)【10,11】
[11](3/3/1/12)【10,11】
[13](3/4/0/13)【13,14】
[14](3/4/1/14)【13,14】
[16](3/5/0/15)【16,17】
[17](3/5/1/16)【16,17】
逐层遍历
逐层遍历,是从根节点出发,一层一层地向下,每层中从左往右地遍历btree。
前面的三种遍历(顺序/逆序/搜索)每个节点都只会遍历一次,但逐层遍历就会出现某些节点会多次经过的情况。原因是:
- 寻找父节点不同的堂兄弟时,只能借助父节点或者更上一级的爷辈或祖辈节点才能找到。
当然可以在实现btree的时候给每个节点新增parent和left_brother和right_brother的属性,这样就能快速从某个btree节点出发定位到想要寻找的节点。
我提供的btree实现,是接近原生的,没有这仨属性。具体实现,请查看代码中的traverse_btree_layer函数。
逐层遍历的测试用例:
./hjs_test btree traverse layer
逐层遍历的结果输出:
[ 9](1/0/0/00)【9】
[ 3](2/0/0/01)【3,6】
[ 6](2/0/1/02)【3,6】
[12](2/1/0/03)【12,15】
[15](2/1/1/04)【12,15】
[ 1](3/0/0/05)【1,2】
[ 2](3/0/1/06)【1,2】
[ 4](3/1/0/07)【4,5】
[ 5](3/1/1/08)【4,5】
[ 7](3/2/0/09)【7,8】
[ 8](3/2/1/10)【7,8】
[10](3/3/0/11)【10,11】
[11](3/3/1/12)【10,11】
[13](3/4/0/13)【13,14】
[14](3/4/1/14)【13,14】
[16](3/5/0/15)【16,17】
[17](3/5/1/16)【16,17】
4. 代码
完整的代码,点击链接获取。该代码仓库的一些说明:
- B-tree的代码在
btree目录 - opencv绘制btree的代码在
btree/draw_btree目录 - 测试btree的代码在
test目录下的test_btree.cpp和test_btree.h中 - 代码库中有完整的opencv2的头文件和动态链接库,无需安装opencv就可以编译并运行测试代码。
- 编译的方法参见README中
编译章节描述 - 运行测试的方法参见README中
运行测试->3. B 树(B-tree)的描述。
代码的一些说明:
- 完全本人手敲的每一行代码,所有关键逻辑都写了中文或英文注释。
- 本文中的btree的图,99%都是该代码生成的。
- btree节点中存储key和child的容器,我没有使用数组,而是使用的是双向链表。原因是为了更高效和更优雅的删除元素、拆分节点等操作。双向链表使用的是代码库中
list目录实现的链表。 - 基本每个函数都有UT覆盖,每一个UT都通过了valgrind的内存检查,所以代码基本上是内存和逻辑安全的。但是个人能力和时间有限,如果发现有bug,或者逻辑不对的地方,欢迎指正。
代码中关键函数对照表如下,你可以对照本文相关关键点的描述去看代码,结合代码中的注释来进一步理解算法。
- 插入key
- 插入key:
btree_insert - 分裂节点:
btree_split_node
- 插入key:
- 删除key
- 删除key:
btree_delete - 再平衡:
btree_rebalance - 左旋:
btree_rotate_left - 右旋:
btree_rotate_right - 合并:
btree_merge_node - 从叶子节点删除key:
btree_delete_key_from_leaf - 从内节点删除key:
btree_delete_key_from_inner
- 删除key:
- 查询key:
btree_search - 遍历btree:
btree_traverse
5. 写在最后
- 对代码中有疑问的地方,随时来这里咨询。
- 后续会继续补充B+tree的实现和绘图理解
- 有机会会给出B树在文件系统中的实例
- 最后,那个曾经纠结B减树的小伙伴,是10年前的我,哈哈哈