目录
一、什么是C++
二、关键字:
三、命名空间 :
1. C语言存在的问题:
2. namespace关键字:
3. 注意点:
4.使用命名空间分为三种:
四、输入输出:
五、缺省函数:
1. 什么是缺省函数:
2.注意点:
3. 这个省略函数的用途:
一、什么是C++
C++是一种面向对象的高级程序设计语言。
C++是在C语音的基础上,添加了一些祖师爷在写代码的时候的一些困惑。把他自己的想法在C语言的基础上实现。因此C++也可以兼容C语言。

二、关键字:
c++ 一共63个关键字
对比c语言的32个更多了一些,在之后的学习中我会挑一部分来讲

三、命名空间 :
1. C语言存在的问题:
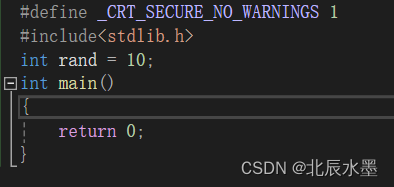
在预处理的时候,会把#include<stdlib.h>展开,里面也有rand,这个是作用在全局域中,然后你又在全局域中定义了一个rand变量。这就是名字冲突,在C语言中没有很好的解决方法,只能通过改名字。
但是在实际的项目中,由不同小组的人完成,刚好他们都用到了同一个变量名,C语言的话就只能他们两个干一架,决定名字的使用权。
在C++中就引入了一个命名空间。

2. namespace关键字:
namespace ABC { ... }像这样子就把你写的代码放到了一个名字叫ABC的域中(建起了一座围墙,如果你不开一条路,你就不能访问里面的东西)
在正常情况下,编译会先去局部空间中查找有没有这个变量,然后再去全局中找。如果没有找到,也没有using namespace的话,不会到命名空间中找。(就相当于建起了一座保护墙)
3. 注意点:
1) namespace的命名空间:
只影响使用,不影响生命周期。因为namespace的命名空间也是全局域的,只是编译器不去查找,不要自我认为它不是全局域的。
2)可以嵌套使用namespace关键字
namespace ABC { namespace DEF { int a; } }这样子使用的时候是ABC::DEF::a=10;
3)标准库的命名空间是std 也就是说你要使用标准库的cout等,
你需要包含#include<iostream> 然后在用的时候std::cout<<i<<std::endl;
4)多个文件中定义的域的名字相同,会把他们合并起来。
讲了什么是命名空间之后,我再讲命名空间怎么使用,其实上面我已经提到了一些。在这里我再详细说一下。
讲的时候会涉及到::符号,::域作用限定符,会去前面提到的域中查找,如果前面为空,就去全局去找,不会在其他域中查找。
std::cout<<i<<std::endl;//endl相当于换行,和printf("\n");一样的效果
::n=10;//前面没有提到是什么域,就会去全局域中查找4.使用命名空间分为三种:
1.全局展开:
#include<iostream> using namespace std;//全局展开 int main() { int i; cin>>i; cout<<i<<endl; }辛辛苦苦把墙建起来,用了全局展开,就相当于把墙给拆掉了。
在练习的代码中,可以这么干,因为就几十行的代码,大不了我们把命名改了。
但是在项目的时候,一定不能这么写。那是十几万行的代码。很容易和其他组的人写重名。
2.局部展开:
#include<iostream> using std::endl; using std::cout; int main() { int i=10; std::cin>>i; cout<<i<<endl; }展开一部分比较常用的,如果不展开,每一次都写,太繁琐了。
3.不展开:
在每一次要用的时候就 域::变量;
四、输入输出:
<< 符号是流插入运算符
比我们c语言方便的一点是 可以自动识别类型。
我们这里cin是一个标准输入流,cout是标准输出流。
#define _CRT_SECURE_NO_WARNINGS 1
#include<iostream>
int main()
{
int i = 0;
std::cin >> i;
double* arr = (double*)malloc(sizeof(double) * i);
if (arr == NULL)
{
perror("malloc error");
exit(-1);
}
for (int j = 0; j < i; j++)
{
std::cin >> arr[j];
}
for (int j = 0; j < i; j++)
{
std::cout << arr[j]<<std::endl;
}
return 0;
}
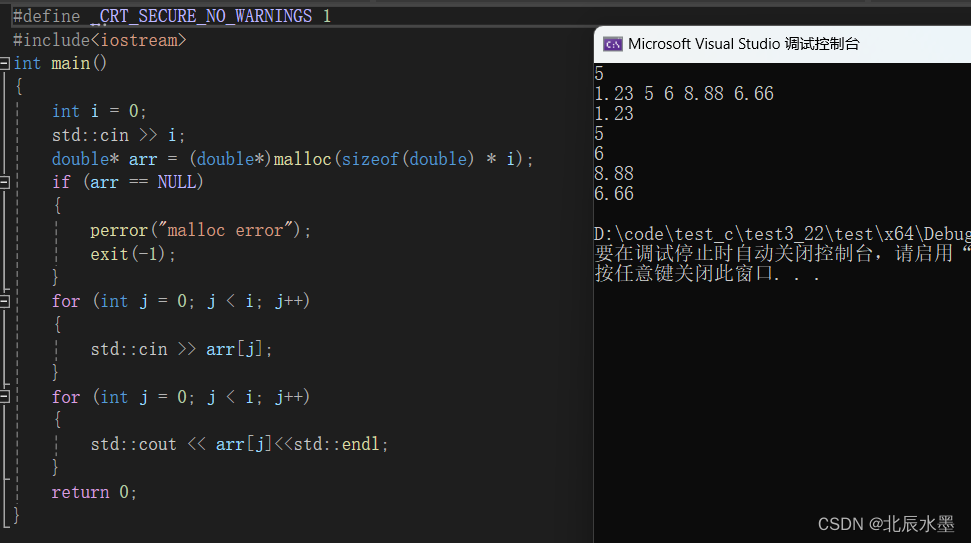
可以看出,cin可以自动识别类型。你可以觉得不怎么样。但是到后面结构体那些的时候就会很方便了。
五、缺省函数:
1. 什么是缺省函数:
函数传参的时候,如果不想传,也可以不传,会有一个默认参数值。
void fun(int a = 0) { std::cout << a << std::endl; } int main() { fun(1); fun(); return 0; }
如果传了参数,int a=0就不起作用。
这个0就是舔狗界的王。当人家有男票的时候,你有多远就走多远。当人家没有男票的时候,你就屁颠屁颠的靠近。

2.注意点:
不能跳跃,省略参数必须从右往左连续缺省。
因为实参是从左往右传的。
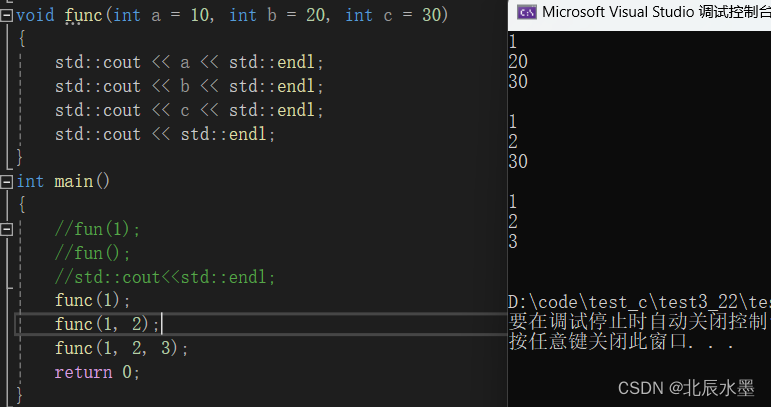
//不能跳跃 //省略参数必须从右往左连续缺省 如func(int a=10;int b;int c=30) -->错误的,要从右往左缺省 // func(int a;int b=20;int c=30) -->对的 //因为实参是从左往右传给形参的 void func(int a = 10, int b = 20, int c = 30) { std::cout << a << std::endl; std::cout << b << std::endl; std::cout << c << std::endl; } int main() { func(1); func(1, 2); func(1, 2, 3); return 0; }
3. 这个省略函数的用途:
当你初始化栈的时候,不可以写死,一开始就开4个大小的空间。那如果需要100万的空间,那你还需要不断的扩容。
你可能知道最大的空间是多少,那你就直接传参。
有可能你也不知道传多大。那就什么都不传。
这个情况就很适合用缺省函数了。
//用途在初始化的时候,很灵活,只要你知道你想开多少的空间,就按你传的数据来,如果你不知道想要传多少,就用缺省产生 typedef struct stack { int* arr; int top; int capacity; }stack; void stackInit(stack* st, int a = 4) { st->arr = (int*)malloc(sizeof(int*) * a); if (st->arr == NULL) { perror("malloc error"); exit(-1); } st->top = 0; st->capacity = a; } int main() { stack st1; stack st2; stackInit(&st1,100);//在你知道最多需要100个空间的时候,你直接传进去,可以省略多次的扩容 stackInit(&st2);//不传参,就一开始开辟4个空间 return 0; }