golang
变量作用域
- 局部作用域:代码块、函数内的
- 全局作用域:顶层作用域,代码块外的就是全局,如果变量名大写,则改变量整个程序都可以使用。
类型断言
golang的类型断言在变量后加上.(type),如果类型断言与实际类型不一致会返回第二个参数bool代表是否成功
func main(){
var a inteface{}
b := 1
b = a
c,ok := b.(boolean)
if ok {
... succcess
}
// 简写
if c,ok := b.(boolean); ok {
... succcess
}
}
错误处理
默认情况发生错误panic程序会退出。golang中捕获错误采用如下方法,defer+recover
func tes(){
defer func(){
err := recover()
if err != nil{
//
}
}()
fmt.Println(a+b)
}
自定义错误
golang中自定义错误采用errors.New和panic函数
func main(){
}
流程控制的细节
switch
- 穿透:golang的
switch默认不会穿透,不需要像js一样在case内加上break,如果需要穿透加上fallthrough - case后面可有多个值
func main(){
a := 5
switch a{
case 1,2,3,4:
println("ok1,2,3")
case 5:
println("ok5")
default:
println("default")
}
}
可以将switch当作if else分支
func main(){
a := 5
switch {
case a == 5:
println("a = 5 true")
}
}
Type Switch
switch可以用来判断某个变量的实际类型
var mapData map[string]interface{}
func main(){
for k,v := range mapData{
switch v.(type){
case nil:
//
case int:
//
case float64:
//
case bool,string:
//
default:
//
}
}
}
函数
函数传递两种方式
- 值传递
- 引用传递。
引用传递效率高,因为只拷贝地址。对于引用类型,指针、slice切片、map、管道、chan、interface都属于引用类型。 值类型 int、float、bool、string、数组和结构体
init函数
每一个源文件都可以包含一个init函数,该函数将会在main函数之前被调用
defer关键字
defer使用场景主要是函数执行完毕后释放函数执行期间创建的资源
当go执行到defer时,会将defer后的代码压入栈中,当函数执行完毕后会从栈中取出语句执行(语句中引用的值会做一个拷贝)。
func sum(a int,b int)int{
// 将println(a) println(b)语句入栈,此时a,b值10,20被拷贝,
defer println(a) //10
defer println(b) //20
a++ //11
b++ //21
res := a + b
return res
}
sum(10,20)
打印操作
golang打印需要导入fmt包,如果需要详细打印信息需要符号%#,使用%v打印任何值,%.2f可以打印小数并展示到小数后两位
s := "hello"
f := 3.1415926
fmt.Printf("s=%v",s)
fmt.Printf("%.2f",f)
new和make的区别
new函数不太常用,使用new函数得到的是一个类型的指针,并且该指针对应的值为该类型的零值。举个例子:
func main() {
a := new(int)
b := new(bool)
fmt.Printf("%T\n", a) // *int
fmt.Printf("%T\n", b) // *bool
fmt.Println(*a) // 0
fmt.Println(*b) // false
}
var a *int只是声明了一个指针变量a但是没有初始化,指针作为引用类型需要初始化后才会拥有内存空间,才可以给它赋值。应该按照如下方式使用内置的new函数对a进行初始化之后就可以正常对其赋值了:
func main() {
var a *int
a = new(int)
*a = 10
fmt.Println(*a)
}
make也是用于内存分配的,区别于new,它只用于slice、map以及chan的内存创建,而且它返回的类型就是这三个类型本身,而不是他们的指针类型,因为这三种类型就是引用类型,所以就没有必要返回他们的指针了。make函数是无可替代的,我们在使用slice、map以及channel的时候,都需要使用make进行初始化,然后才可以对它们进行操作。
总结
- 二者都是用来做内存分配的。
- make只用于slice、map以及channel的初始化,返回的还是这三个引用类型本身;
- 而new用于类型的内存分配,并且内存对应的值为类型零值(初始值),返回的是指向类型的指针。
结构体
结构体相当于java、js的class
type userInfo struct{
name string
age int
hobby []
}
定义结构体方法
func (u *userInfo) resetPassword(password string){
u.password = password
}
func (u userInfo) checkPassword(password string) bool {
return u.password == password
}
结构体的实例化
我们还可以通过使用new关键字对结构体进行实例化,得到的是结构体的地址。 格式如下:
var p2 = new(person)
fmt.Printf("%T\n", p2) //*main.person
fmt.Printf("p2=%#v\n", p2) //p2=&main.person{name:"", city:"", age:0}
只有当结构体实例化时,才会真正地分配内存。也就是必须实例化后才能使用结构体的字段。
结构体本身也是一种类型,我们可以像声明内置类型一样使用var关键字声明结构体类型。
type person struct {
name string
city string
age int8
}
func main() {
var p1 person
p1.name = "pprof.cn"
p1.city = "北京"
p1.age = 18
fmt.Printf("p1=%v\n", p1) //p1={pprof.cn 北京 18}
fmt.Printf("p1=%#v\n", p1) //p1=main.person{name:"pprof.cn", city:"北京", age:18}
}
使用&对结构体进行取地址操作相当于对该结构体类型进行了一次new实例化操作。
p3 := &person{}
fmt.Printf("%T\n", p3) //*main.person
fmt.Printf("p3=%#v\n", p3) //p3=&main.person{name:"", city:"", age:0}
p3.name = "博客"
p3.age = 30
p3.city = "成都"
fmt.Printf("p3=%#v\n", p3) //p3=&main.person{name:"博客", city:"成都", age:30}
结构体的初始化
type person struct {
name string
city string
age int8
}
func main() {
var p4 person
fmt.Printf("p4=%#v\n", p4) //p4=main.person{name:"", city:"", age:0}
}
使用键值对对结构体进行初始化时,键对应结构体的字段,值对应该字段的初始值。
p5 := person{
name: "pprof.cn",
city: "北京",
age: 18,
}
fmt.Printf("p5=%#v\n", p5) //p5=main.person{name:"pprof.cn", city:"北京", age:18}
也可以对结构体指针进行键值对初始化,例如:
p6 := &person{
name: "pprof.cn",
city: "北京",
age: 18,
}
fmt.Printf("p6=%#v\n", p6) //p6=&main.person{name:"pprof.cn", city:"北京", age:18}
当某些字段没有初始值的时候,该字段可以不写。此时,没有指定初始值的字段的值就是该字段类型的零值。
p7 := &person{
city: "北京",
}
fmt.Printf("p7=%#v\n", p7) //p7=&main.person{name:"", city:"北京", age:0}
使用值的列表初始化
初始化结构体的时候可以简写,也就是初始化的时候不写键,直接写值:
p8 := &person{
"pprof.cn",
"北京",
18,
}
fmt.Printf("p8=%#v\n", p8) //p8=&main.person{name:"pprof.cn", city:"北京", age:18}
使用这种格式初始化时,需要注意:
1.必须初始化结构体的所有字段。
2.初始值的填充顺序必须与字段在结构体中的声明顺序一致。
3.该方式不能和键值初始化方式混用。
结构体标签(Tag)
Tag是结构体的元信息,可以在运行的时候通过反射的机制读取出来。
Tag在结构体字段的后方定义,由一对反引号包裹起来,具体的格式如下:
`key1:"value1" key2:"value2"`
结构体标签由一个或多个键值对组成。键与值使用冒号分隔,值用双引号括起来。键值对之间使用一个空格分隔。 注意事项: 为结构体编写Tag时,必须严格遵守键值对的规则。结构体标签的解析代码的容错能力很差,一旦格式写错,编译和运行时都不会提示任何错误,通过反射也无法正确取值。例如不要在key和value之间添加空格。
例如我们为Student结构体的每个字段定义json序列化时使用的Tag:
//Student 学生
type Student struct {
ID int `json:"id"` //通过指定tag实现json序列化该字段时的key
Gender string //json序列化是默认使用字段名作为key
name string //私有不能被json包访问
}
func main() {
s1 := Student{
ID: 1,
Gender: "女",
name: "pprof",
}
data, err := json.Marshal(s1)
if err != nil {
fmt.Println("json marshal failed!")
return
}
fmt.Printf("json str:%s\n", data) //json str:{"id":1,"Gender":"女"}
}
JSON操作
JSON的键需要大写,如果想小写,则需要加上tag,例如下面的json:age
type userInfo struct{
Name string
Age int `json:age`
Hobby []string
}
序列化和反序列化对象
import (
"encoding/json"
"fmt"
)
a:= userinfo{Name:"Yu",Age:25,Hobby:[]string{"Golang","TypeScript"} }
buf,err := json.Marshal(a)// 序列化后编程buf数组(16进制编码) 可以通过string(buf)转为字符串
string(buf)
var b userInfo
err = json.Unmarshal(buf,&b)
if err!= nil{
panic(err)
}
日期操作
- 两个时间相减 调用
Sub方法 - 格式化时间不同于其他语言传入
YYMM,需要传入固定时间2006-01-02 15:04:05进行格式化
package main
import (
"fmt"
"time"
)
func main(){
now := time.Now()// 获取现在时间
t := time.Date(2023,3,27,1,25,36,0,time.UTC) // 2023-03-27 01:25:36 +0000 UTC
t2 := time.Date(2023.3.27,2,30,36,0,time.UTC)
fmt.Println(t.Year(),t.Month(),t.Day(),t.Hour(),t.Minute())//2023, March 27 1 25
dif := t2.Sub(t)// 时间相减
t.Format("2006-01-02 15:04:05") // 格式化时间
now.Unix() // 当前时间戳
}
切片
创建/初始化切片
func main() {
//1.声明切片
var s1 []int
if s1 == nil {
fmt.Println("是空")
} else {
fmt.Println("不是空")
}
// 2.:=
s2 := []int{}
// 3.make()
var s3 []int = make([]int, 0)
fmt.Println(s1, s2, s3)
// 4.初始化赋值
var s4 []int = make([]int, 0, 0)
fmt.Println(s4)
s5 := []int{1, 2, 3}
fmt.Println(s5)
// 5.从数组切片
arr := [5]int{1, 2, 3, 4, 5}
var s6 []int
// 前包后不包
s6 = arr[1:4]
fmt.Println(s6)
}
// 通过make创建切片 创建了一个长度为2容量为5的切片
var slice []int = make([]int,2,5)
// 初始化切片
全局:
var arr = [...]int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
var slice0 []int = arr[start:end]
var slice1 []int = arr[:end]
var slice2 []int = arr[start:]
var slice3 []int = arr[:]
var slice4 = arr[:len(arr)-1] //去掉切片的最后一个元素
局部:
arr2 := [...]int{9, 8, 7, 6, 5, 4, 3, 2, 1, 0}
slice5 := arr[start:end]
slice6 := arr[:end]
slice7 := arr[start:]
slice8 := arr[:]
slice9 := arr[:len(arr)-1] //去掉切片的最后一个元素
| 操作 | 含义 |
|---|---|
s[n] | 切片s中索引位置为n的项 |
s[:] | 从切片s的索引0到len(s)-1处 |
s[start:] | 从start到len(s)-1 |
s[:end] | 从0到end处 |
s[start:end] | 从start到end处 |
s[start:end:max] | 从start到end cap=max-low len=hight-low |
len(s) | 切片长度 |
cap(s) | 切片 |
切片内存布局
读写操作实际目标是底层数组,只需注意索引号的差别
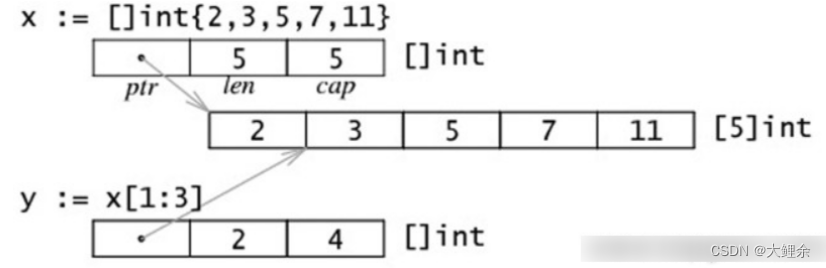
关于cap
:::tip
超出原 slice.cap 限制,就会重新分配底层数组,即便原数组并未填满。
:::
package main
import (
"fmt"
)
func main() {
data := [...]int{0, 1, 2, 3, 4, 10: 0}
s := data[:2:3]
s = append(s, 100, 200) // 一次 append 两个值,超出 s.cap 限制。
fmt.Println(s, data) // 重新分配底层数组,与原数组无关。
fmt.Println(&s[0], &data[0]) // 比对底层数组起始指针。
}
// [0 1 100 200] [0 1 2 3 4 0 0 0 0 0 0]
// 0xc4200160f0 0xc420070060
Go并发编程
go并发编程中有三个核心
- Goroutine 协程 调用函数的时候在函数前加上
go关键字即可 - Channel
- Sync
1.1协程之间通信Channel
提倡通过**通信共享内存(通道)**而不是共享内存实现通信(存在多个协程同时操作一个数据的情况)
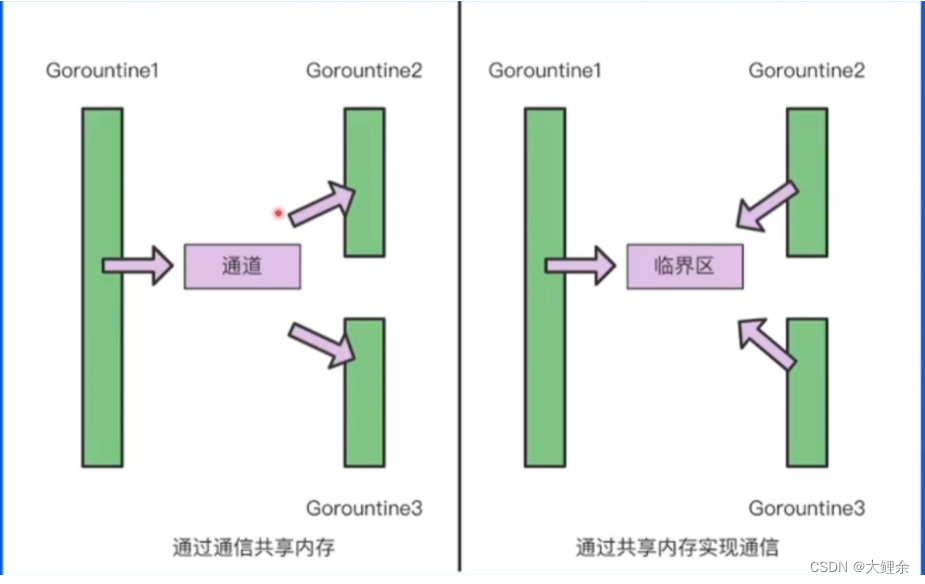
1.2通道-通信共享内存
通道分为两类
- 有缓冲通道
make(chan int,通道大小example:2)类似于快递格子,如果满了就没法放快递等待格子腾出来才行,典型的生产消费模型。 - 无缓冲通道
make(chan int),也被称为同步通道
func CalSquare(){
src := make(chan int)
dest := make(chan int,3)
go func(){
defer close(src)
for i:=0;i<10;i++ {
src <- i
}
}()
go func(){
defer close(dest)
for i:=range src {
dest <- i * i
}
}()
for i:= range dest {
println(i)
}
}
//0 1 4 9 16 25 36 49 64 81
1.3通信-共享内存
var (
x int64
lock sync.Mutex
)
func addWithLock(){
for i := 0; i < 2000; i++ {
lock.Lock()// 临界区资源上锁
x += 1
lock.Unlock()//释放临界区资源
}
}
func addWithoutLock(){
for i := 0; i < 2000; i++ {
x += 1
}
}
func Add(){
x = 0
for i := 0; i <5; i++ {
go addWithLock()
}
time.Sleep(time.Second)
println("addWithLock",x)
x = 0
for i := 0; i <5; i++ {
go addWithoutLock()
}
time.Sleep(time.Second)
println("addWithoutLock",x)
}
addWithLock 10000
addWithoutLock 6550
WaitGroup
之前防止主进程结束导致协程还没运行完就接触,我们采用time.Sleep,正确方式来了
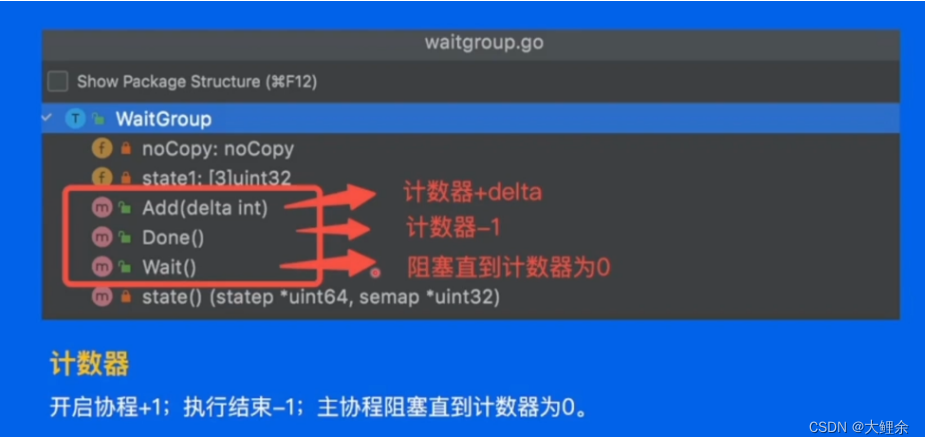
func helloRoutine(i int) {
println("hello" + fmt.Sprint(i))
}
func ManyGoWait(){
var wg sync.WaitGroup
wg.Add(5)
for i := 0; i < 5; i++{
go func(j int){
defer wg.Done()
helloRoutine(j)
}(i)
}
wg.Wait()
}
func main(){
ManyGoWait()
}
依赖管理
Go依赖管理的演进GOPATH->GO Vendor -》Go Module
GOPATH和GO Vendor 都是采用源码副本方式管理依赖没有版本规则
依赖管理三要素:
- 配置文件,描述依赖 go.mod
- 中心仓库管理依赖库 Proxy
- 本地工具 go get/go mod
GOPATH
$GOPATH工作区
- bin 项目编译的二进制文件
- pkg 项目编译的中间产物,加速编译
- src 项目源码
这种管理方式,项目代码直接依赖src目录下的代码,然后通过go get下载最新包到src目录下
这种管理方式的缺点
本地两个项目A,B ;A和B依赖某一个PKG的不同版本,没法构建成功,无法实现多版本控制
Go Vendor
为了解决GOPATH的问题,该方式在项目目录下增加vendor文件,所有依赖包副本形式放在项目根目录下/vendor(如果没有找到就去GOPATH),每个项目都引入一份依赖的副本就解决了依赖同包不同版本的问题
Go Vendor问题
如果A项目依赖pkg B和pkg C,而B和C同时依赖了pkg D的不同版本,我们无法控制其版本选择问题
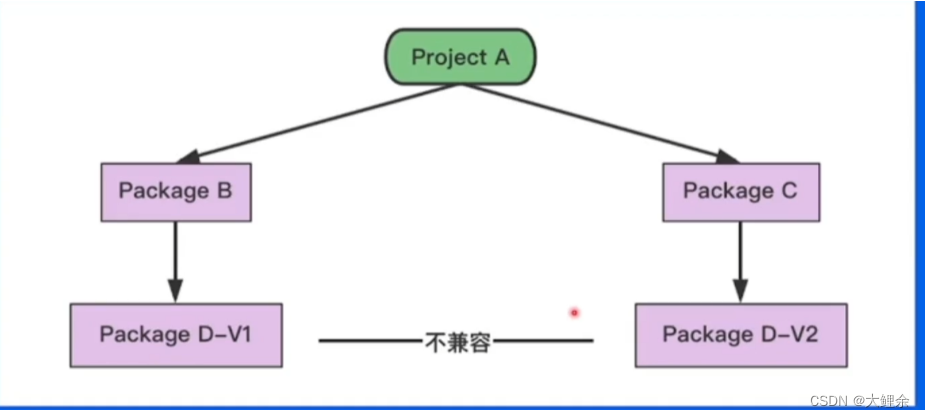
Go Module
通过go.mod文件管理依赖包版本,通过go get/go mod指令管理依赖包
go.mod的配置 类似于前端package.json
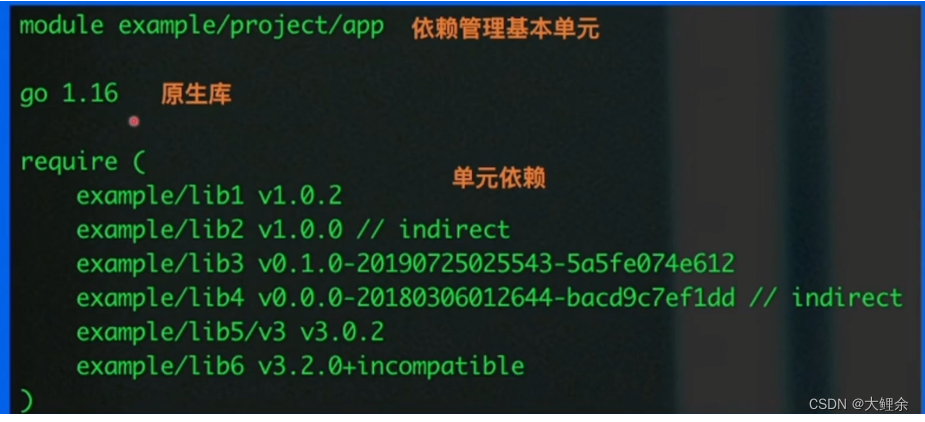
go mod工具
go mod init #初始化 创建go.mod文件,项目开始前的必备操作
go mod download #下载模块到本地
go mod tidy #增加需要的依赖,删除不需要的 每次提交代码前可以执行
依赖分发Proxy
由于依赖一般放在github等代码托管平台,就会存在一些问题
- 作者可能增删改软件的版本,无法保证构建稳定性
- 无法保证依赖可用性,作者可以删除
- 代码托管平台负载问题
proxy会缓存原站的内容,版本也不会变。
当存在proxy项目依赖会先从proxy上查找,当proxy代理的地址没有时,就去direct源站
go项目初始化
go mod init 名字
go mod tidy
安装gorm
go get -u gorm.io/gorm
go get -u gorm.io/driver/sqlite
创建models文件夹,该文件夹用于gorm创建表