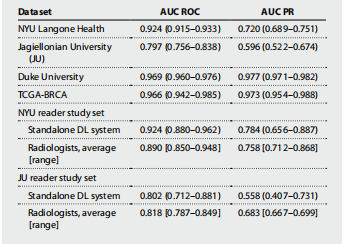
ETCD跨城容灾与异地多活网络故障的相关表现分析
- 1. 网络架构
- 2. 单个网络中断-跟leader区中断
- 2.1. 网络中断
- 2.2. 网络恢复
- 3. 单个网络中断-跟非leader区中断
- 4. 两个网络中断-leader区中断
- 5. 两个网络中断-非leader区中断
- 6. 两个网络中断-非leader区中断
- 7. 总结
- 8. 参考文档
etcd集群进行分布式设计,并且通过raft协议来进行选leader以及确保数据一致性和高可用能力。本文重点分析在不同网落区之间出现网络中断时,相关的etcd集群的表现,以探究和加强对etcd集群的理解。更多raft协议的理解可以参考 分布式Raft原理详解,从不同角色视角分析相关状态
1. 网络架构
etcd集群一共有7个节点,分别部署在3个IDC,整体架构如下
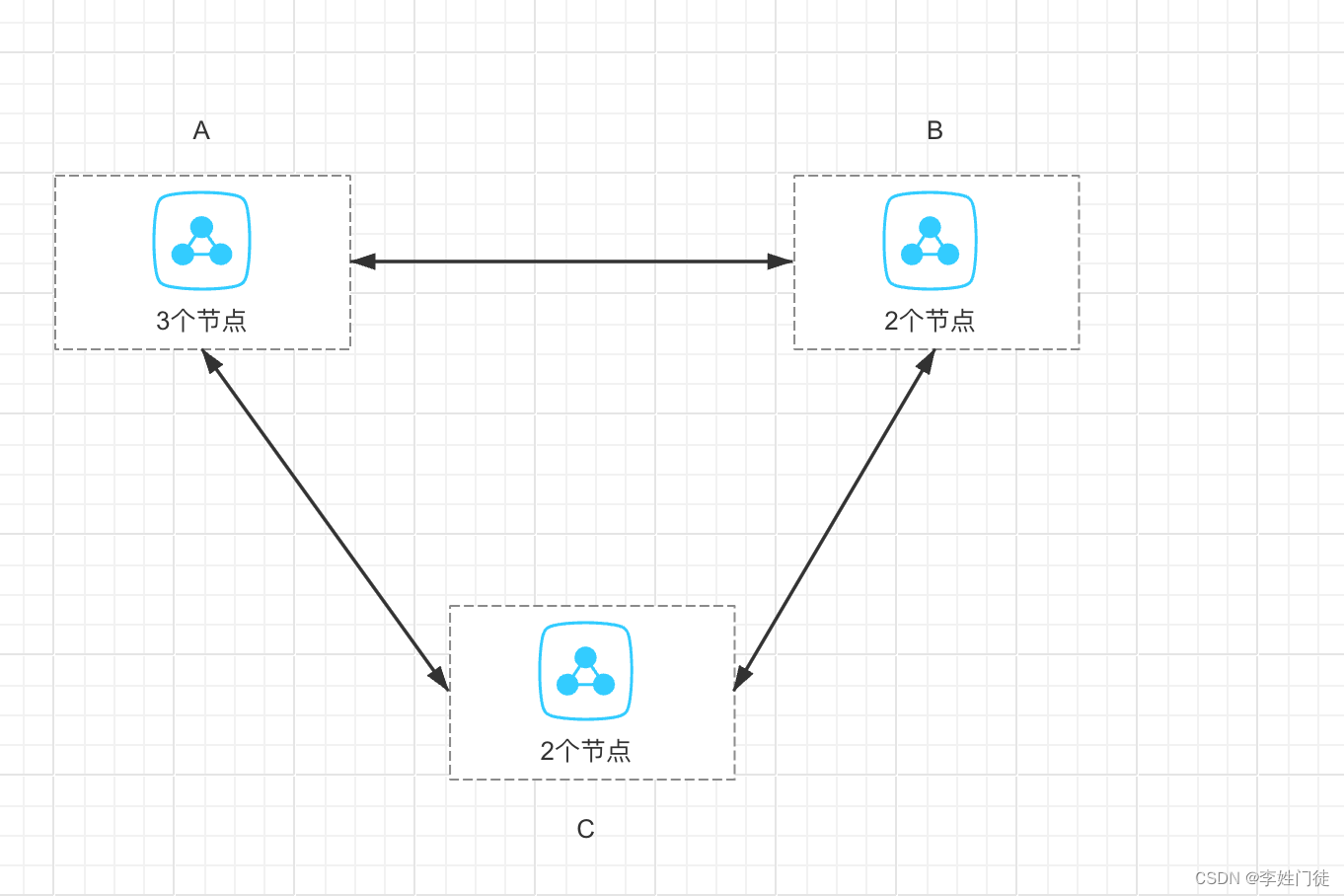
在该架构下,理论上能够兼容任意网络区域之间的网络中断,能够重新选举出leader,从而保证etcd整体的可用性。但是当区域的集群表现时,我们通过分析相关日志来验证。
2. 单个网络中断-跟leader区中断
架构如下
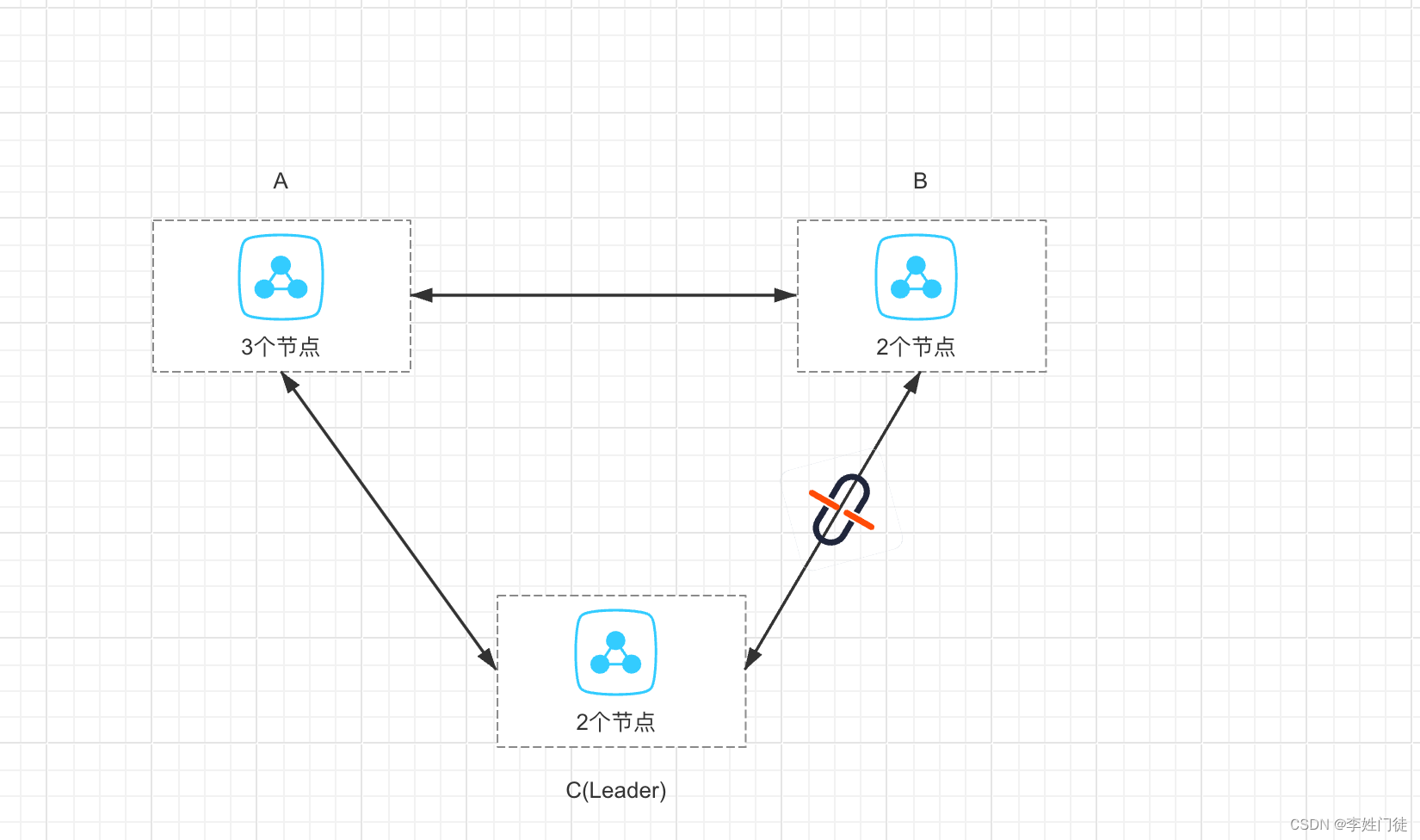
2.1. 网络中断
上图中BC之间的网络出现了中断,leader节点在C区域,集群整体可用
-
由于leader在C区,并且能够接受来自AC两个区的节点心跳,因此集群leader不会触发选举,整体可用
-
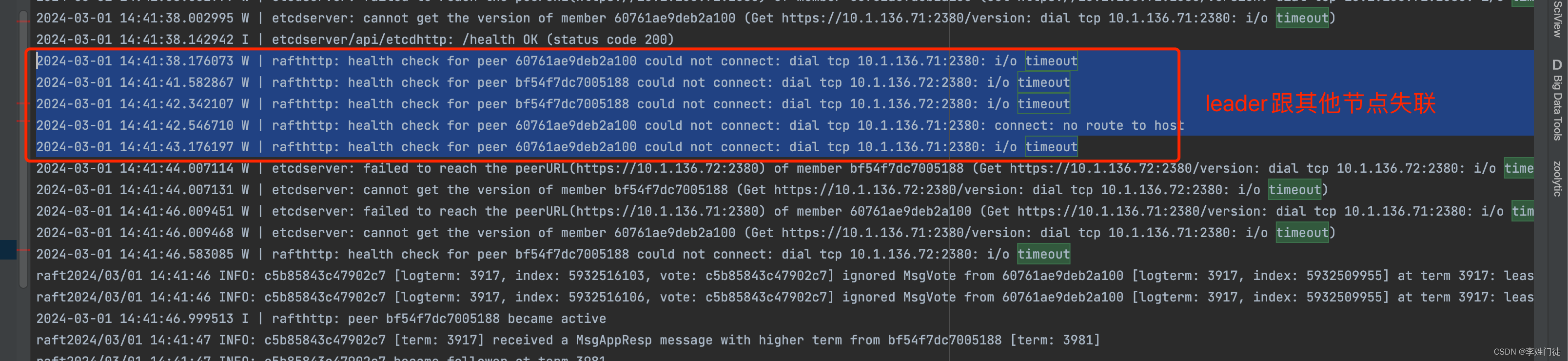
B区由于不能跟C区域通信,跟集群的leader失联,会尝试进行投票选举出新的leade
-
B区的2个节点除了自己投票外,会给A区域的3个节点发送投票申请
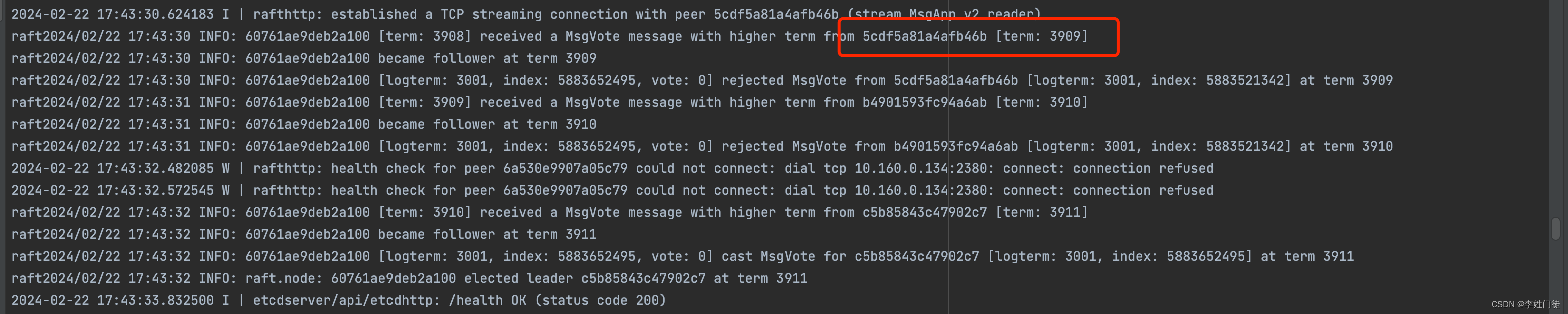
-
A区的节点由于能够感知到C区的leader心跳,因此会拒绝B区的投票请求
-
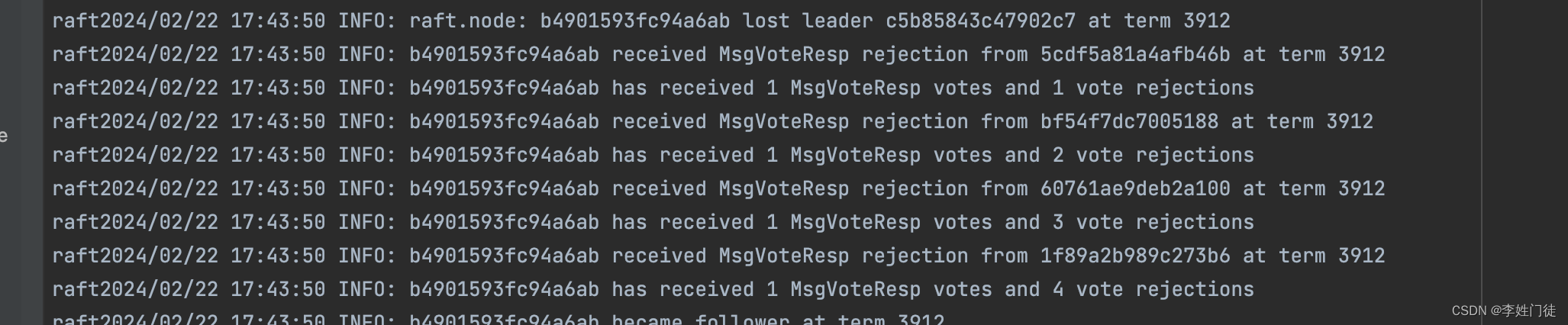
B区的节点由于无法获取到足够的选票,因此无法选举出leader,并且持续发送投票,因此投票的周期会持续增大
2.2. 网络恢复
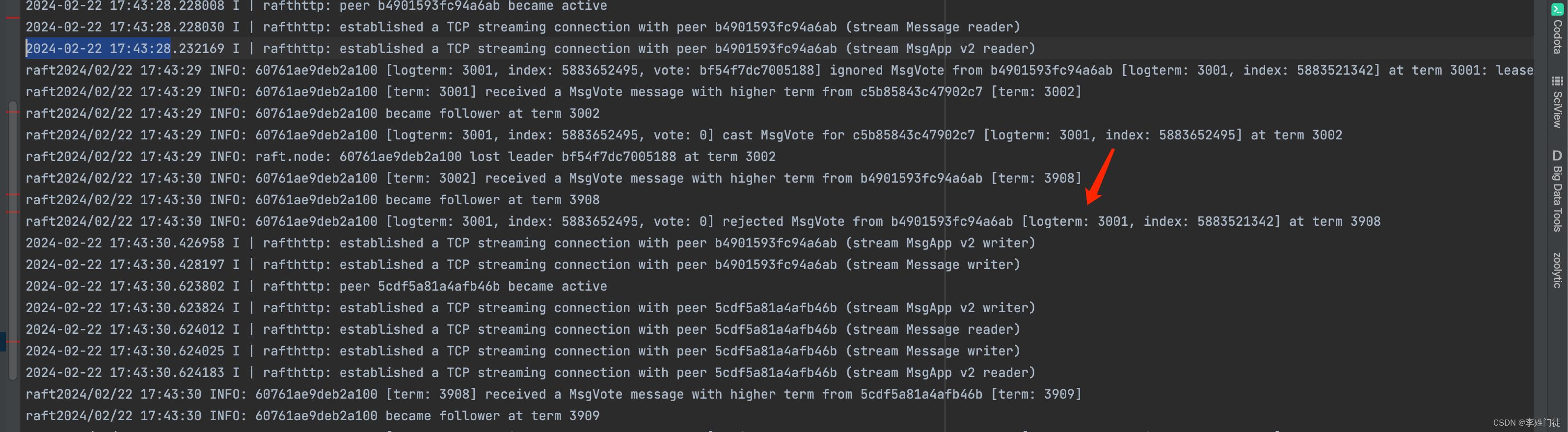
上图中BC之间的网络恢复后,原leader收到了更高选票周期的B的通信,为了保证数据一致性,会重新出发选
- B区的节点选票周期虽然更高,但是由于持续没有从原leader同步数据,因此数据索引index小于AC区节点,因此B区不能被选举出leader
- 重新触发选举后,leader会在AC中的节点选举出新leader,从而集群恢复可用
- 新leader选举出来后,会同步相关数据到其他follower节点,保持数据一致
恢复后,重新触发选举leader的原理,在 分布式Raft原理详解,从不同角色视角分析相关状态有说明
4.3. Leader(主节点)
节点成为Leader节点后,此时可以接受客户端的数据请求,负责日志同步
如果遇到更高任期Term的Candidate的通信请求,这说明Candidate正在竞选Leader,此时之前任期的Leader转化为Follower,且完成投票;
如果遇到更高任期Term的Leader的通信请求,这说明已经选举成功新的Leader,此时之前任期的Leader转化为Follower
3. 单个网络中断-跟非leader区中断
架构如下
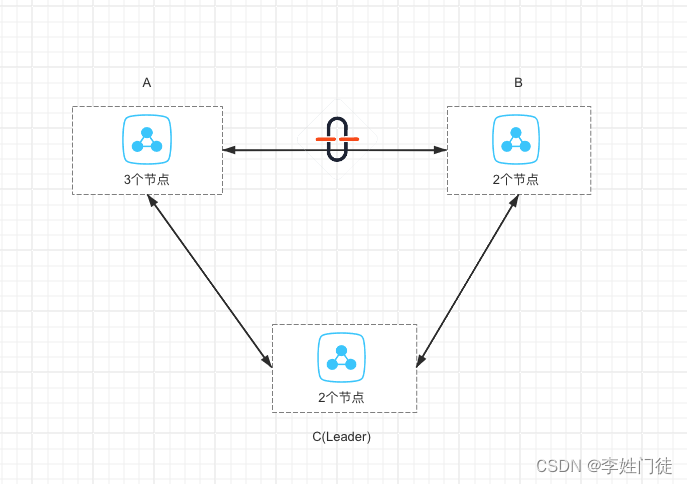
如上图AB区连接中断,由于leader在C区,能够跟A\B正常连接,因此这种情形下,整体集群能够正常提供访问,不会导致leader重新触发选举。
4. 两个网络中断-leader区中断
架构如下
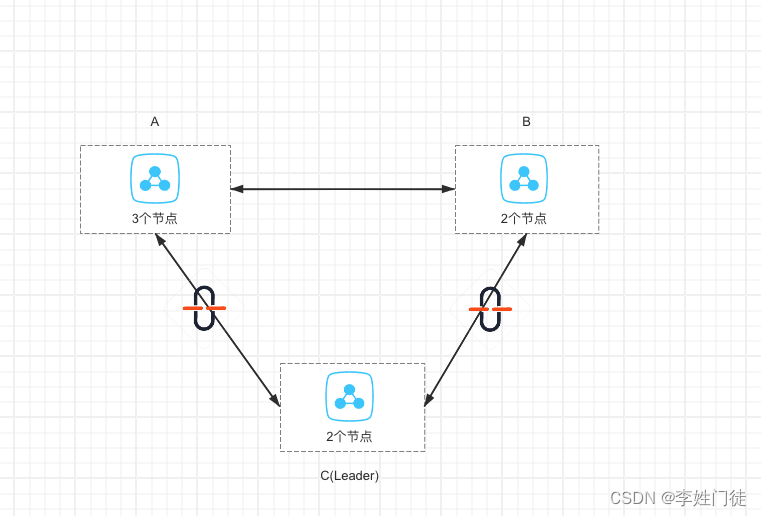
在这种情况下,由于AC\AB区网络不通,因此会在AB区重新进行选举leader,从而重新提供服务
5. 两个网络中断-非leader区中断
架构如下
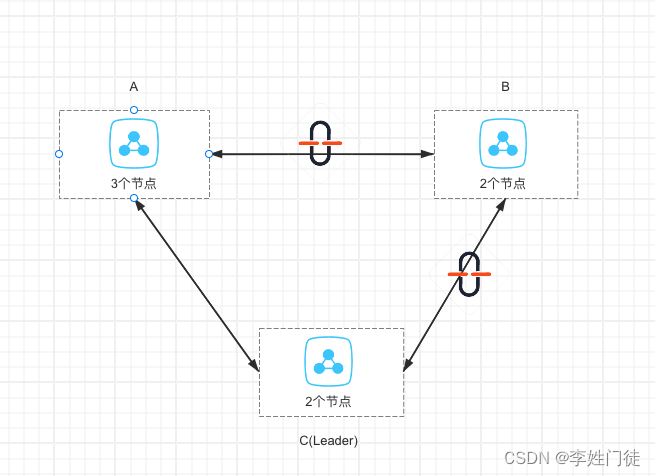
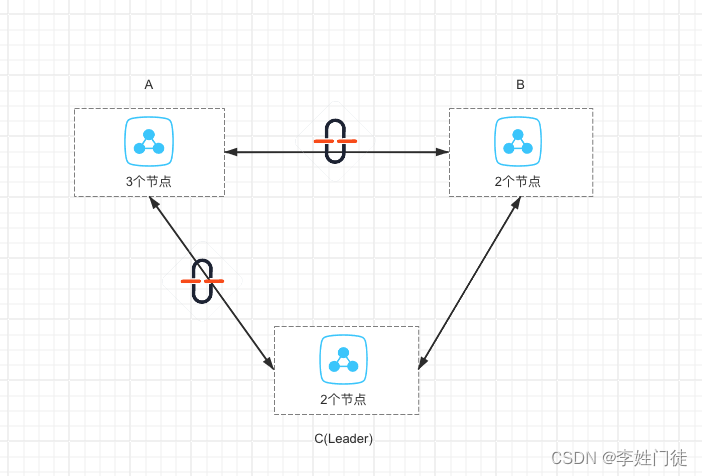
在这种情况下,leader能够跟其他的区正常连接,因此整体集群能够正常提供服务,也不会重新触发leader选举
6. 两个网络中断-非leader区中断
架构如下
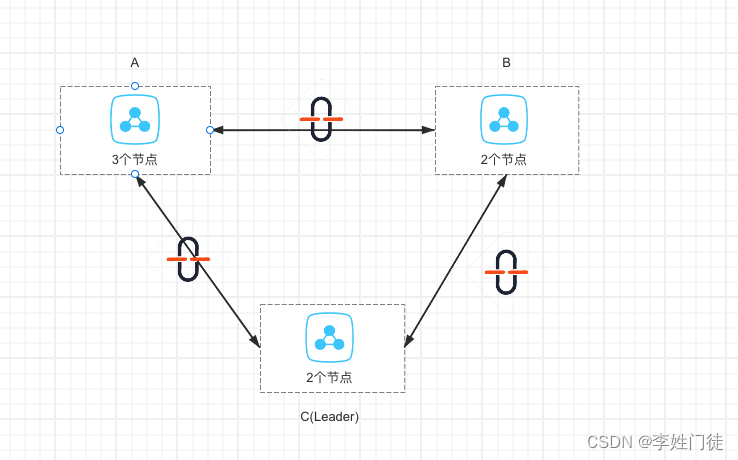
在这种情况下,由于各个区域网络中断,不能获取超过半数节点选举出leader,因此集群不能对外提供服务。
7. 总结
- 在3区域环境,按照这样的架构设计,能够兼容非所有区域网络中断的场景,能够兼容2个区网络中断。因此能够提供比较高的高可用服务能力
- 其他组件在设计多区域高可用时,为了能够保证集群能够兼容多区域之间的网络中断问题,需要确保集群节点数为单数,并且至少3区域,才能在人工不干预的情况下,实现多区域间的网络中断荣灾能力
- 通常由于在高qps情况下,不通城区之间的网络带宽以及网络时延限制,应当实现多活,并且考虑应用访问 就近原则 以减少网络时延的影响
8. 参考文档
- 分布式Raft原理详解,从不同角色视角分析相关状态