聚合聚类(Agglomerative Clustering)是一种层次聚类算法,通过逐步合并或“聚集”它们来构建嵌套聚类。这种方法采用自底向上的方式构建聚类层次:它从将每个数据点作为单个聚类开始,然后迭代合并最接近的聚类对,直到所有数据点合并为一个聚类,或直到达到指定的聚类数量。以下是更详细的概述:
聚合聚类的工作原理
- 初始化:开始时,将每个数据点视为一个单独的聚类。因此,如果你有N个数据点,你最初会有N个聚类。
- 相似性度量:选择一个度量标准来衡量聚类之间的距离(例如,对于空间中的点使用欧几里得距离,但根据数据的性质可以使用其他距离)。
- 连接准则:选择一个连接准则,这决定了作为观测对之间距离的函数的聚类集合之间的距离。常见的连接准则包括:
- 最短连接:两个聚类之间的距离定义为一个聚类中任何成员到另一个聚类中任何成员的最短距离。
- 最长连接:两个聚类之间的距离定义为一个聚类中任何成员到另一个聚类中任何成员的最长距离。
- 平均连接:两个聚类之间的距离定义为一个聚类中每个成员到另一个聚类中每个成员的平均距离。
- Ward方法:两个聚类之间的距离通过两个聚类合并后总体内聚类方差增加量来定义。
- 迭代合并:在每一步中,根据所选的距离和连接准则,找到最接近的聚类对并将它们合并为一个单独的聚类。更新存储聚类之间距离的距离矩阵。
- 终止:重复迭代合并,直到所有数据点合并为一个聚类或达到停止准则(例如,期望的聚类数量)。
优点和缺点
优点:
- 聚合聚类在距离和连接准则的选择上具有多样性,使其适用于各种数据集。
- 它产生了一个层次结构,这对于不同规模的聚类数据结构是有信息量的。
-缺点:
- 对于大数据集来说,它可能计算成本高,因为它需要在每次迭代中计算和更新所有聚类对之间的距离。
- 算法的结果可能对距离和连接准则的选择敏感。
应用
聚合聚类在广泛的应用领域中被使用,包括:
- 生物学:用于构建系统发育树。
- 文档和文本挖掘:用于对相似文档进行分组或在语料库中找到主题。
- 图像分析:用于分割图像中的相似区域。
- 客户细分:基于购买行为或偏好识别客户数据中的不同组。
聚合聚类是一种强大的工具,用于探索和理解复杂数据集内的结构,通过揭示数据的
要在Python中实现聚合聚类,您可以使用scikit-learn库的AgglomerativeClustering类。此示例演示了如何将聚合聚类应用于合成数据集:
from sklearn.datasets import make_blobs
from sklearn.cluster import AgglomerativeClustering
import matplotlib.pyplot as plt
# 生成一个合成数据集
X, _ = make_blobs(n_samples=150, centers=4, cluster_std=1.0, random_state=42)
# 实例化并拟合聚合聚类模型
# n_clusters指定要找到的聚类数量
# linkage='ward'表示算法将最小化被合并的聚类的方差
agg_clustering = AgglomerativeClustering(n_clusters=4, affinity='euclidean', linkage='ward')
cluster_assignment = agg_clustering.fit_predict(X)
# 绘制聚类
plt.scatter(X[:, 0], X[:, 1], c=cluster_assignment, cmap='rainbow')
plt.title('聚合聚类')
plt.xlabel('特征1')
plt.ylabel('特征2')
plt.show()
它是如何工作的:
- 使用
make_blobs生成一组合成的数据点,这些数据点分布在几个“blob”中。这是我们要聚类的数据集。 - 使用所需的聚类数量(
n_clusters=4)和要使用的链接类型实例化AgglomerativeClustering。在这种情况下,使用的是linkage='ward',它最小化了被合并的聚类的方差。 - 在数据集上调用
fit_predict方法来执行聚类。此方法返回每个数据点的聚类标签。 - 最后,用表示其聚类分配的颜色绘制数据点。这种可视化有助于理解数据点在算法创建的不同聚类之间的分布。
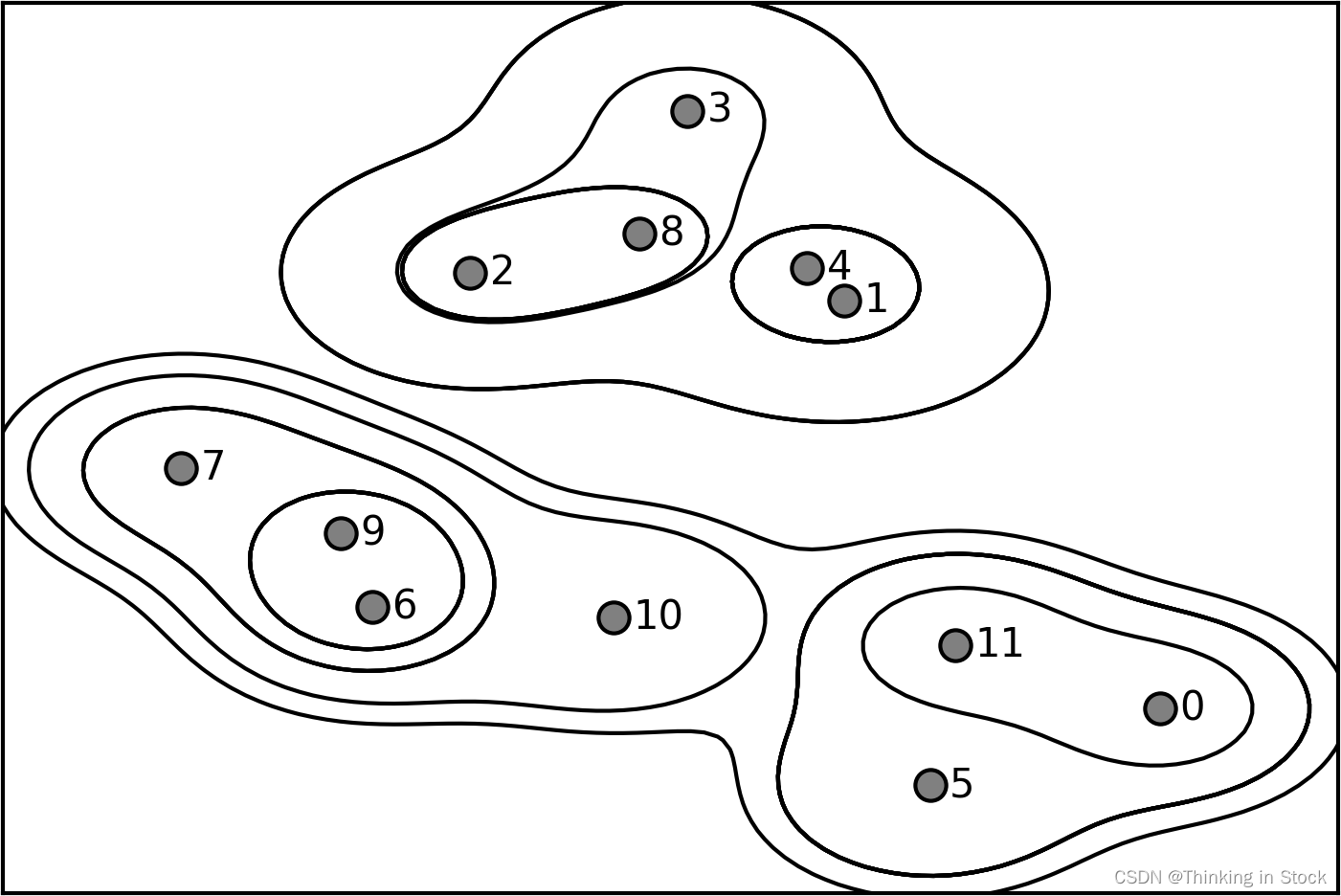

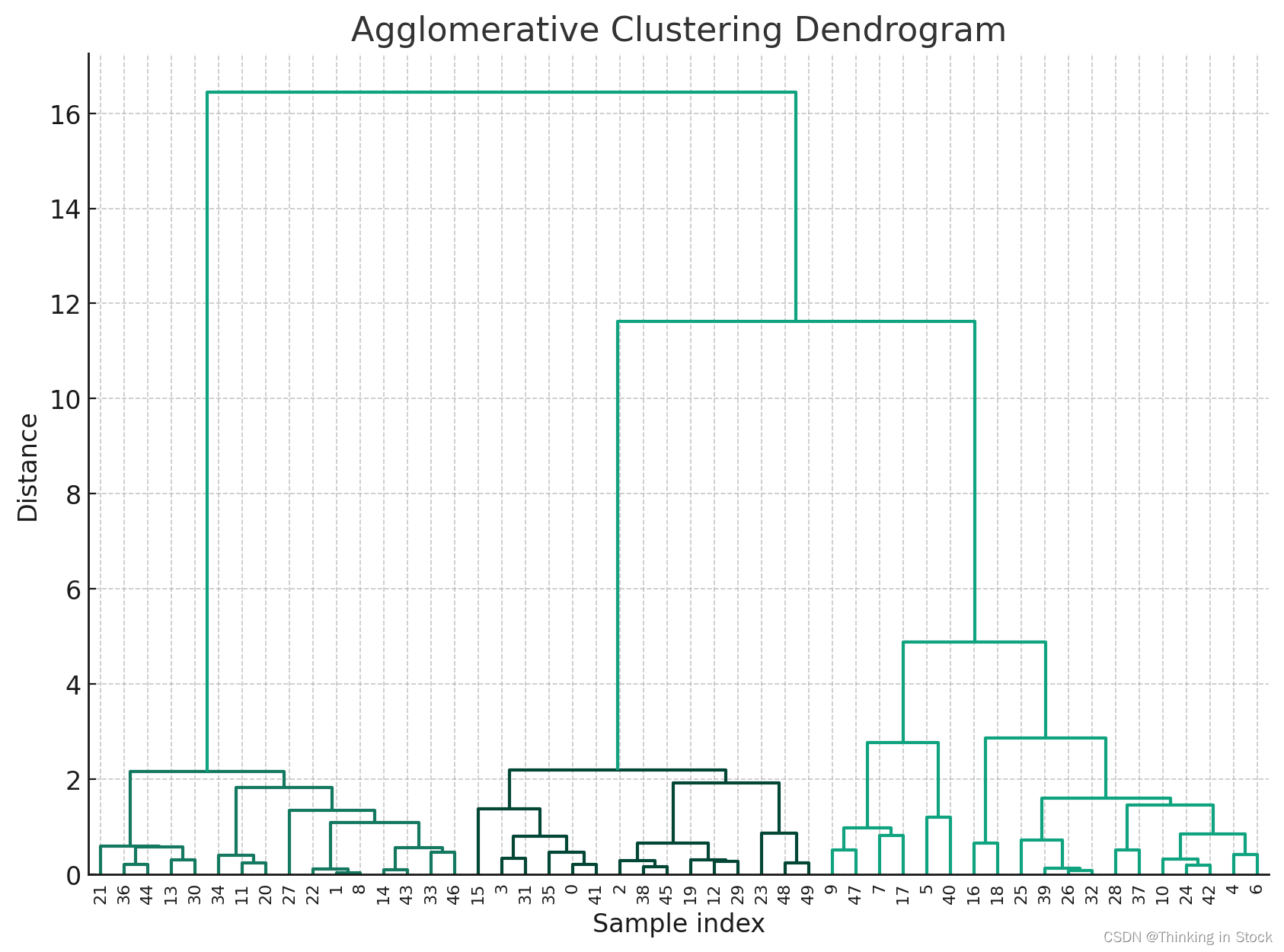
Dendograms树状图解释
树状图是显示对象之间层次关系的图表。它通常用于描绘由层次聚类产生的聚类排列。树状图通过在非单一聚类及其子聚类之间绘制U型链接来说明每个聚类是如何组成的。U型链接的高度指示了联合聚类之间的距离(或不相似性)。当您向上移动树状图时,聚类之间的不相似性变得更大。在聚合聚类的上下文中,树状图提供了聚类过程的视觉总结,显示了聚类合并的顺序以及每次合并发生的距离。
现在,让我们编写代码,对一个示例数据集执行聚合聚类,然后用树状图可视化层次聚类:
import numpy as np
import matplotlib.pyplot as plt
from scipy.cluster.hierarchy import dendrogram, linkage
from sklearn.datasets import make_blobs
# 生成一个样本数据集
X, labels_true = make_blobs(n_samples=50, centers=3, cluster_std=0.60, random_state=0)
# 执行层次/聚合聚类
Z = linkage(X, 'ward') # 'ward'连接方式最小化合并的聚类的方差
# 绘制树状图
plt.figure(figsize=(10, 7))
plt.title("聚合聚类树状图")
plt.xlabel("样本索引")
plt.ylabel("距离")
dendrogram(Z, leaf_rotation=90., leaf_font_size=8.,)
plt.show()