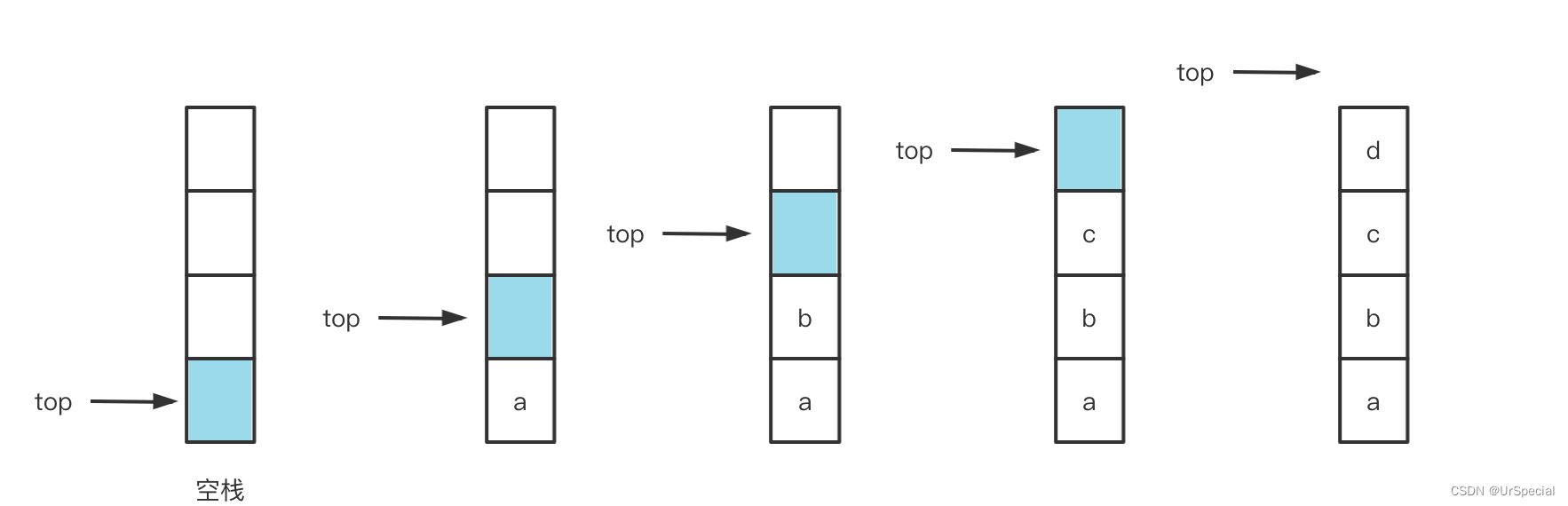
自己搭建一棵决策树【长文预警】
忙了一个周末就写到了“构建决策树”这一步,还没有考虑划分测试集、验证集、“缺失值、连续值”,预剪枝、后剪枝的部分,后面再补吧(挖坑)
第二节内容:验证集划分\k折交叉检验 机器学习——编程从零实现决策树【二】-CSDN博客
目录
1、信息
1)基本算法过程
2)信息熵和信息增益的计算方式
2、做点假设,简化运算
3、拆解算法过程
0)结点类
1)同类样本判断
2)数据集能否再拆解
3)选取最优属性
步骤1
步骤2:
步骤3:
步骤4:
步骤5:
4)构造新结点
4、完整的结点类代码
5、完整的构造树的过程
6、建树
1)准备数据集
2)建树
7、绘图查看树的结构
1)绘图代码
2)结果
3)预测
完整的代码指路
DrawPixel/decisionTree.ipynb at main · ndsoi/DrawPixel (github.com)
1、信息
1)基本算法过程

2)信息熵和信息增益的计算方式


2、做点假设,简化运算
① 为了选择最优的属性进行划分,我们需要计算信息增益,而计算信息增益需要用到信息:
1、选取的属性attr有多少种取值?
(用西瓜分类的例子,考虑属性”纹理“,就有3种取值——”清晰“、”稍糊“和”模糊“)
2、每种取值有哪些数据?这些数据中有多少是A类别的,又有多少是B类别的..?
比如对原始数据集考虑”纹理=清晰“的数据,那么有7个是好瓜,有2个是坏瓜
② 计算完信息增益之后,我们选信息增益最大的属性,按照这个属性划分数据集,生成子结点
注意这里的划分数据集,事实上我们在完成①.2问题的时候就已经“划分了”一次数据集,只是我们没有记录下来,类似这样的“冗余”计算有很多,为了尽量减少“重复”计算,我重规划算法的步骤如下:
1、设总共有class_num个类别,假设我们初始化结点node的时候就知道了这个数据集的如下信息:
数据集 self.data
属性集 self.attr
该数据集内样本数量最多的类别 self.max
该数据集内每个类别的样本数量 self.cal_class 是一个列表,每一个元素是|Dv|
2、基于假设1:
计算Ent(D):
def Ent(D,cal_class):
sum = len(D) # 样本总数
# 求占比
re = 0
for k in cal_class:
pk_class = k/sum
if pk_class != 0:
re -= pk_class* math.log(pk_class,2)
return re3、拆解算法过程
0)结点类
class Node():
def __init__(self,D,A,max,cal_class,class_num):
self.data = D
self.attr = A
self.class_num = class_num
self.cal_class = cal_class
self.max = max
self.label = 0 # 0表示非叶结点 1表示叶结点
self.Class = 0 # 默认一个
self.flag = "init"1)同类样本判断
若要判断D中的样本是否同属于一个类别:只需要判断self.max的数量是否等于class_num
def isSameClass(self):
if self.cal_class[self.max] == len(self.data):
return True
return False
2)数据集能否再拆解
若D中样本不属于同一类,那么接下来要看D中的样本是否还能再分解:
def isNoAttr(self):
# 属性集为空
if self.attr == None or self.attr==[]:
return True,[]
# 存储取值不同的属性
self.Attr_Div = []
for a in self.attr:
a1 = self.data[0][a]
for d in self.data:
if d[a] != a1:
self.Attr_Div.append(a)
break
# 无可分的属性
if self.Attr_Div == []:
return True,[]
return False,self.Attr_Div3)选取最优属性
从2)中获取了当前node数据集进一步可以分解的属性范围(self.Attr_Div),对于self.Attr_Div中的每一个attr,我们需要做的事情还有:
1. 找出属性attr的所有取值
2. 按照attr的不同取值将self.data划分成互斥的子集 简称为Dv
3. 计算|Dv|和 Ent(Dv)
4. 计算出attr的Gain
5. 重复步骤2-4 计算出所有attr的Gain, 选出Gain最大的attr
步骤1
# 属性attr的取值大全
def attrAllvalue(D,attr):
Allvalue = {}
for d in D:
Allvalue[d[attr]] = 0
return Allvalue步骤2:
def divDataByattr(D,attr):
# 建立一个字典,key是attr的取值,已初始化数值为0
re = attrAllvalue(D,attr)
n = len(re) # 要划分出n个子数据集
SubDataSets = {}
for key,value in re.items():
SubDataSets[key] = []
for d in D:
SubDataSets[d[attr]].append(d)
return SubDataSetsdivDataByattr获得形如: {'清晰':[数据1,数据2],'模糊':[数据3],'稍糊':[数据4]} 的字典
步骤3:
为了计算Ent(Dv)我们需要获得Dv的cal_class,下列函数计算了数据集子集Dv的max和cal_class
# 获取maxnumClass
def calMaxClass(D,class_num):
# 统计数据集D中各类样本的数目
cal_class = [0 for i in range(class_num)]
max = 0
for d in D:
cal_class[d['Class']]+=1
if cal_class[d['Class']] > cal_class[max]:
max = d['Class']
return max,cal_class步骤4:
确定一个attr,划分出子集的集合,遍历子集集合,然后调用Ent函数,组合计算(加粗部分就是Gain函数所做的事情)
# 信息增益
def Gain(D,attr,class_info):
max,cal_class = calMaxClass(D,class_num)
EntD = Ent(D,cal_class)
SubDataSets = divDataByattr(D,attr)
EntDv = 0
for value,Dv in SubDataSets.items():
# cal_class
max,cal_class=calMaxClass(Dv,class_num)
class_info.append([max,cal_class])
EntDv +=len(Dv)/len(D)*Ent(Dv,cal_class)
Gain_D_attr = EntD-EntDv
return Gain_D_attr补充:这里的class_info就是记录下每一个Dv的max和cal_class,用于后续传参给node 初始化
步骤5:
def choseAttr(D,attrSet):
compar = 0
Gain_D = {}
for attr in attrSet:
SubDataSets = divDataByattr(D,attr)
EntDv = 0
# 补充上Dv额外的参数
class_info = []
Gain_D_attr = Gain(D,attr,class_info)
# 记录数据集D用属性attr做划分时所有的已知信息,包括gain,数据子集,数据子集的class_num和max类
Gain_D[attr] = {'gain':Gain_D_attr,'Dv':SubDataSets,'Dv_info':class_info}
# 找gain最高的attr
target = attrSet[0]
for attr in attrSet:
if Gain_D[attr]['gain'] > compar:
compar = Gain_D[attr]['gain']
target = attr
return target,Gain_D4)构造新结点
在完成3)的步骤5后,应该为选定的attr划分的子集生成新结点,新结点
# 选取最优属性
attr,info = node.bestAttr()
# 获取划分好的数据集
SubDataSets = info[attr]['Dv']
SubInfo = info[attr]['Dv_info']
# 生成子node
Attr = copy.deepcopy(Attr_Div)
Attr.remove(attr)
st = 0
for value,subds in SubDataSets.items():
# 因为假设是离散属性,所以新的self.attr必然要去掉已经选出的attr
subnodeAttr = copy.deepcopy(Attr)
# 获取已经算好的Dv的max和cal_class
submax = SubInfo[st][0]
subcal_class = SubInfo[st][1]
st+=1
# 生成新结点
subnode = Node(subds,subnodeAttr,submax,subcal_class,class_num)
subnode.setflag(attr)
# 新结点还要继续加入tree进行讨论
tree.put(subnode)
# 父结点记录子结点的指引
node.addsubDs(subnode,value)4、完整的结点类代码
# 说明:
# 设数据集是[{},{},{},...,{}]的格式
# {}的格式是{'attr1':'value1,'attr2':'value2',..,'label':'class'}
# label是结点node:表明其为叶节点还是非叶节点
# Class 是当node为叶结点时,该集合的类别
#
# 类别的数量
class_num = 2
class Node():
def __init__(self,D,A,max,cal_class,class_num):
self.data = D
self.attr = A
self.class_num = class_num
self.cal_class = cal_class
self.max = max
self.label = 0 # 0表示非叶结点 1表示叶结点
self.Class = 0 # 默认一个
self.flag = "init"
def isSameClass(self):
if self.cal_class[self.max] == len(self.data):
return True
return False
def isNoAttr(self):
# 属性集为空
if self.attr == None or self.attr==[]:
return True,[]
# 存储取值不同的属性
self.Attr_Div = []
for a in self.attr:
a1 = self.data[0][a]
for d in self.data:
if d[a] != a1:
self.Attr_Div.append(a)
break
# 无可分的属性
if self.Attr_Div == []:
return True,[]
return False,self.Attr_Div
# 计算选取最优划分属性
def bestAttr(self):
# 指向划分的子结点
self.subDs = {}
self.bestattr,self.Gain_D = choseAttr(self.data,self.Attr_Div)
return self.bestattr,self.Gain_D
def setflag(self,attr):
self.flag = attr
# 设置subDs
def addsubDs(self,node,value):
self.subDs[value] = node
5、完整的构造树的过程
import copy
import queue
def do_tree(tree):
node = tree.get()
print(node.data)
# 判断D中的类别是不是都是一类
re = node.isSameClass()
if re:
print("当前node都属于同一类别")
# 如果D中的数据都属于同一个类别
node.Class = node.max
node.label = 1 # 标记为叶子结点
return
# D中的数据并不属于同一个类别
# 判断属性是否可分
boolre,Attr_Div = node.isNoAttr()
print(f"Attr_Div={Attr_Div}")
# D中的属性不可再分
if boolre == True:
print("当前类别属性不可再分")
node.label = 1
node.Class = node.max
return
# 选取最优属性
attr,info = node.bestAttr()
# 获取划分好的数据集
SubDataSets = info[attr]['Dv']
SubInfo = info[attr]['Dv_info']
# 生成子node
Attr = copy.deepcopy(Attr_Div)
Attr.remove(attr)
st = 0
for value,subds in SubDataSets.items():
# 因为假设是离散属性,所以新的self.attr必然要去掉已经选出的attr
subnodeAttr = copy.deepcopy(Attr)
# 获取已经算好的Dv的max和cal_class
submax = SubInfo[st][0]
subcal_class = SubInfo[st][1]
st+=1
# 生成新结点
subnode = Node(subds,subnodeAttr,submax,subcal_class,class_num)
subnode.setflag(attr)
# 新结点还要继续加入tree进行讨论
tree.put(subnode)
# 父结点记录子结点的指引
node.addsubDs(subnode,value)
def TreeGenerate(D,A):
# 计算初始数据集的max和cal_class
max,cal_class = calMaxClass(D,class_num)
# 生成根结点
node = Node(D,A,max,cal_class,class_num)
tree = queue.Queue()
tree.put(node)
while tree.empty() == False:
do_tree(tree)
return node
6、建树
1)准备数据集
dataSet = [
# 1
['青绿', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
# 2
['乌黑', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '好瓜'],
# 3
['乌黑', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
# 4
['青绿', '蜷缩', '沉闷', '清晰', '凹陷', '硬滑', '好瓜'],
# 5
['浅白', '蜷缩', '浊响', '清晰', '凹陷', '硬滑', '好瓜'],
# 6
['青绿', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '好瓜'],
# 7
['乌黑', '稍蜷', '浊响', '稍糊', '稍凹', '软粘', '好瓜'],
# 8
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '硬滑', '好瓜'],
# ----------------------------------------------------
# 9
['乌黑', '稍蜷', '沉闷', '稍糊', '稍凹', '硬滑', '坏瓜'],
# 10
['青绿', '硬挺', '清脆', '清晰', '平坦', '软粘', '坏瓜'],
# 11
['浅白', '硬挺', '清脆', '模糊', '平坦', '硬滑', '坏瓜'],
# 12
['浅白', '蜷缩', '浊响', '模糊', '平坦', '软粘', '坏瓜'],
# 13
['青绿', '稍蜷', '浊响', '稍糊', '凹陷', '硬滑', '坏瓜'],
# 14
['浅白', '稍蜷', '沉闷', '稍糊', '凹陷', '硬滑', '坏瓜'],
# 15
['乌黑', '稍蜷', '浊响', '清晰', '稍凹', '软粘', '坏瓜'],
# 16
['浅白', '蜷缩', '浊响', '模糊', '平坦', '硬滑', '坏瓜'],
# 17
['青绿', '蜷缩', '沉闷', '稍糊', '稍凹', '硬滑', '坏瓜']
]
Attr = ['色泽', '根蒂', '敲击', '纹理', '脐部', '触感']
# 硬编码类别
class_dict = {'坏瓜':0,'好瓜':1}
# 将数据合并格式
D = []
for i in range(len(dataSet)):
d = {}
for j in range(len(Attr)):
d[Attr[j]] = dataSet[i][j]
d['Class'] = class_dict[dataSet[i][-1]]
D.append(d)
print(D)
2)建树
root = TreeGenerate(D,Attr)7、绘图查看树的结构
1)绘图代码
只是打印每层的结点,通过分支数目得知父子结点的关系
cur = root
# 表示区分的属性
q = queue.Queue()
q.put(cur)
while q.empty()==False:
# 这层的宽度
width = q.qsize()
for i in range(width):
# 用/**/包住一个node
print(" /*",end="")
cur = q.get()
if cur.label == 1:
# 叶子结点
print(f"叶子:{cur.Class,cur.flag,cur.data[0][cur.flag]}",end="")
else:
l = len(cur.subDs)
print(f"被分类依据:{cur.flag}",end="")
if cur.flag != "init":
print(f"值:{cur.data[0][cur.flag]}",end=" ")
print(f",分支:{l}个",end="")
for key,nod in cur.subDs.items():
q.put(nod)
print("*/ ",end="")
print("")
2)结果
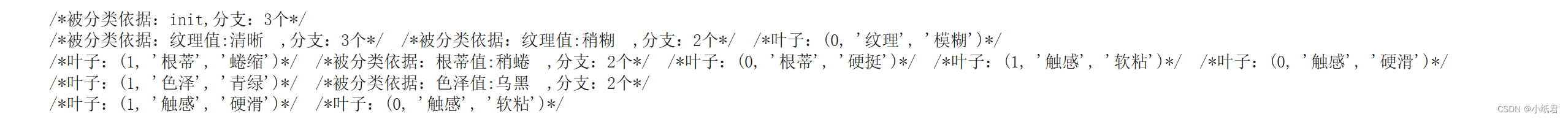
手绘还原:
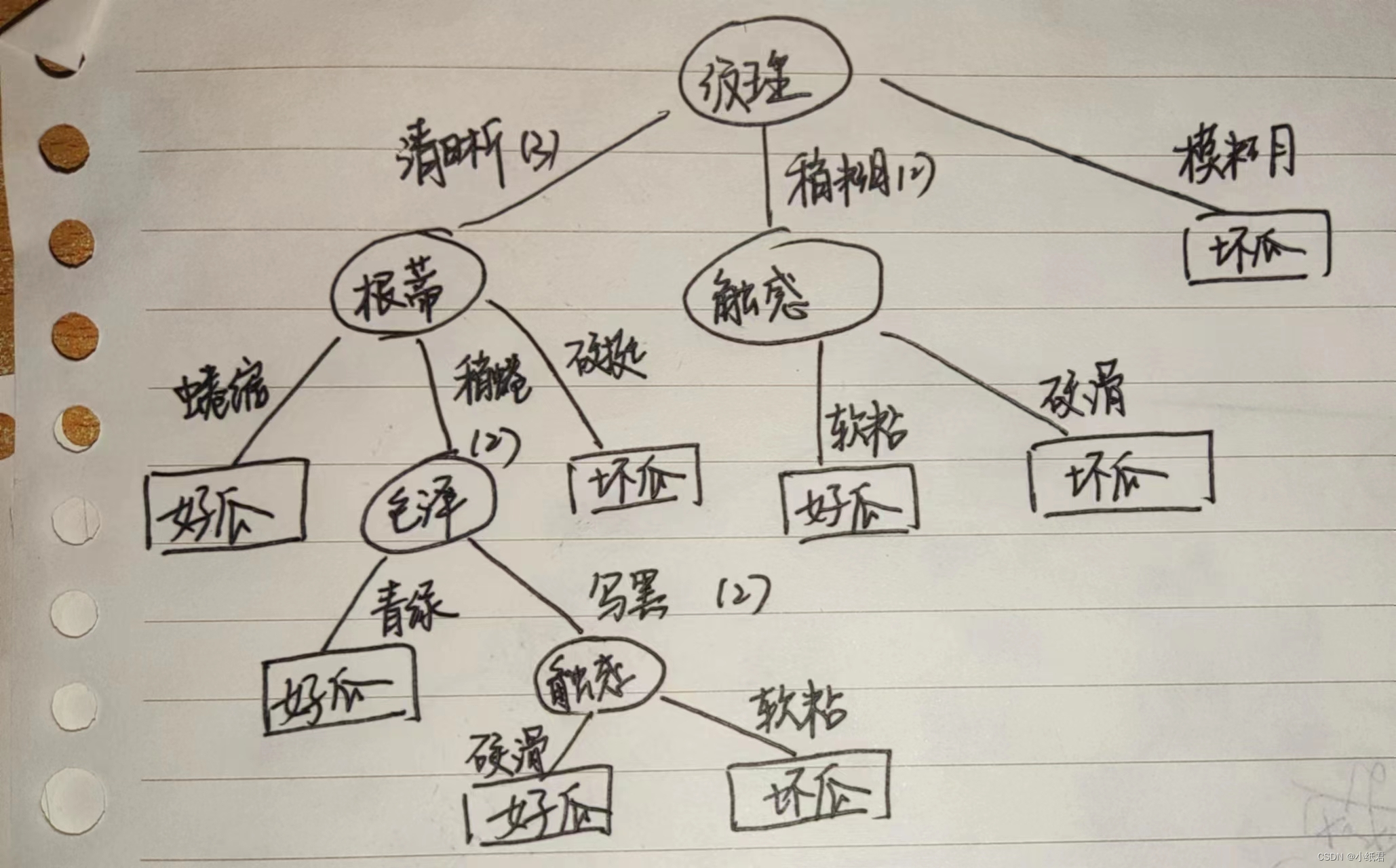
3)预测
投入一个样本,返回好瓜/坏瓜判断
def predict(data,root):
cur = root
while cur.label != 1:
attr = cur.bestattr
cur = cur.subDs[data[attr]]
return cur.Class
for d in D:
pd_label = predict(d,root)
if pd_label == 0:
print("坏瓜")
else:
print("好瓜")
结果打印8行好瓜,9行坏瓜