MPIKGC:大语言模型改进知识图谱补全
- 提出背景
- MPIKGC框架
论文:https://arxiv.org/pdf/2403.01972.pdf
代码:https://github.com/quqxui/MPIKGC
提出背景
知识图谱就像一个大数据库,里面有很多关于不同事物的信息,这些信息是以三元组的形式存在的,比如(人物,关系,事物),如(Ian Bryce,制片,变形金刚:月黑之时)。
知识图谱补全的任务有两个:判断给定的三元组是否正确(三元组分类),以及预测缺失的部分,例如找出缺失的实体或关系(链接预测)。
为了解决这些问题,我们提出了一个新型的技术框架MPIKGC,该框架通过利用大型语言模型(LLMs)生成辅助文本来提升KGC模型的性能。
具体解法可以拆解为以下几个子解法:
-
实体信息补全:
- 子解法:使用LLMs扩展实体描述。
- 之所以使用此子解法,是因为面对实体描述的不完整性问题。
- 我们通过设计链式思考(CoT)提示让LLM逐步生成不同方面的描述,以补全和丰富实体的信息。
-
关系模糊消除:
- 子解法:通过三种精心设计的提示策略查询LLMs以改进对关系含义的理解。
- 之所以使用此子解法,是因为需要解决关系名称可能带来的歧义问题。
- 这些策略包括全局提示、局部提示和反向提示,它们捕捉关系之间的联系,并促进更好的反向预测。
-
图连接稀疏问题:
- 子解法:查询LLMs提取额外的结构信息来丰富知识图谱。
- 之所以使用此子解法,是因为需要解决图中链接稀疏,特别是长尾实体间连接不足的问题。
- 我们通过使用LLMs总结的关键词测量实体间的相似度,并创建新的三元组来构建相关实体之间的联系,从而在KGC模型中形成新的结构模式。
在研究和改进知识图谱(一种存储实体及其相互关系的数据库)的过程中,存在两个主要方法:基于结构的方法和基于描述的方法。
-
基于描述的知识图谱补全(KGC)方法主要使用文本描述来提高对实体和关系的理解,通过如下方式:
- 利用文本描述,通过不同的技术(如卷积神经网络、BERT模型)编码实体和关系,特别擅长处理信息不足的实体。
- 这些方法可以通过描述来更好地理解实体间的关系,尤其对于那些难以通过简单的结构信息识别的实体。
-
大型语言模型(LLMs)在知识图谱中的应用:
- 近年来,大型语言模型(如GPT-4)显示出在处理知识图谱相关任务时的巨大潜力,它们可以提供丰富的知识和强大的理解能力。
- 这些模型可以帮助识别和生成新的事实,通过理解文本描述来增强知识图谱的完整性和准确性。
基于描述的KGC方法通过分析文本描述来理解实体和关系,而大型语言模型则为这些方法提供了一个强大的工具,可以深入挖掘文本中的知识,帮助填补知识图谱中的缺口。
MPIKGC框架
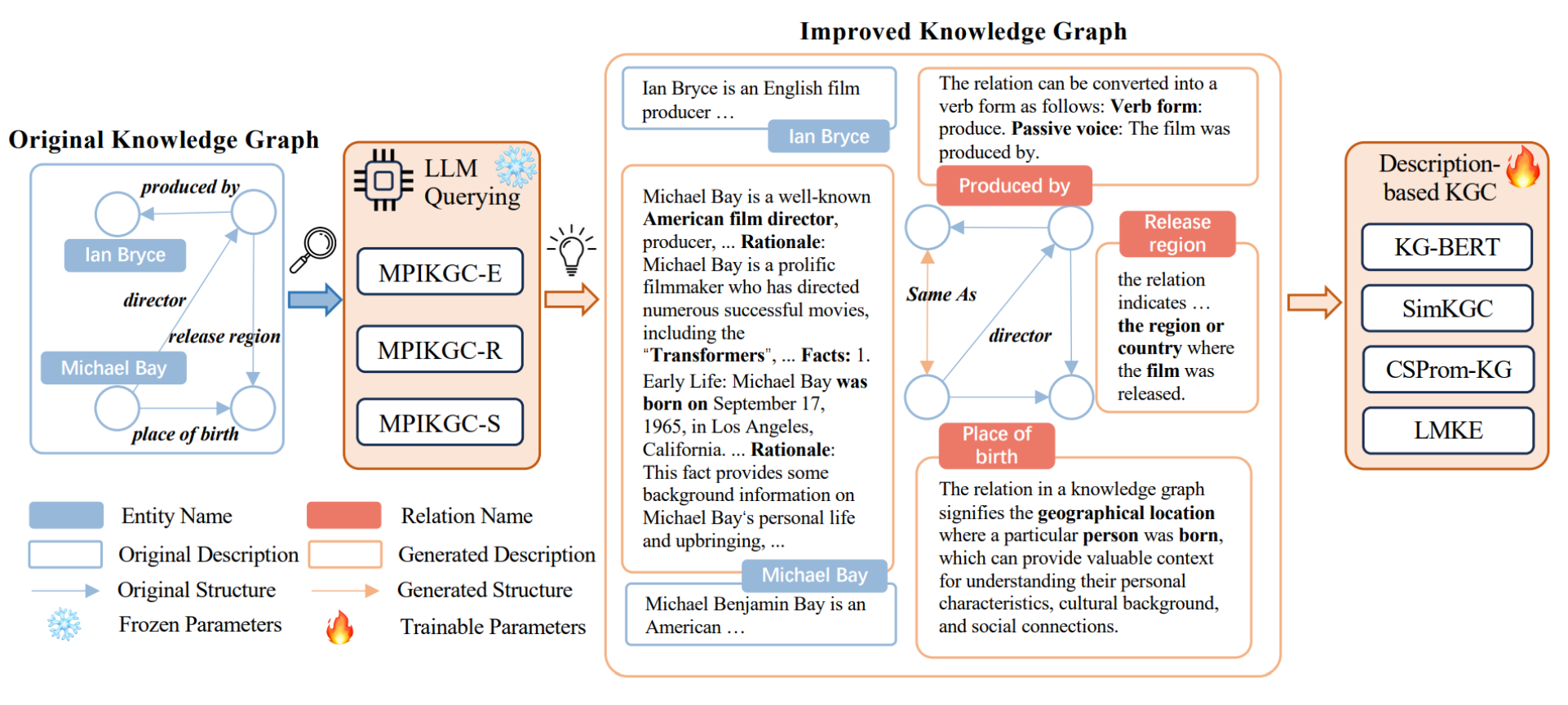
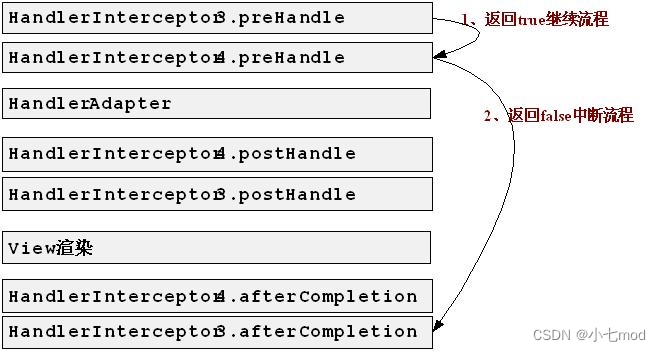
上图描绘了一个名为MPIKGC的框架,这是一个旨在通过从实体、关系和结构的角度改进知识图谱的模型。
这个框架通过LLM查询来生成额外的描述和结构,使得知识图谱更完整、信息更丰富。
MPIKGC框架包含以下三个主要部分:
- 实体描述扩展(MPIKGC-E):使用Chain-of-Thought(CoT)提示策略,让LLMs逐步生成更丰富的实体描述。
- 关系理解(MPIKGC-R):通过全局、局部和反向提示策略,提高KGC模型对关系含义的理解,从而改善链接预测的反向预测性能。
- 结构提取(MPIKGC-S):利用LLMs的关键词总结和匹配能力,提取额外的结构信息,丰富知识图谱,特别是对于长尾实体。
假设我们有一个简单的医学知识图谱,它包含实体(如疾病、症状、药物)和它们之间的关系。
在这个知识图谱中,我们可能有如下三元组:
- (糖尿病, 关联症状, 高血糖)
- (阿司匹林, 用于治疗, 发热)
但是,知识图谱可能不完整,缺少某些关键信息,例如糖尿病的其他症状或与阿司匹林相关的副作用。
为了补全这些信息,我们可以使用下面的方法:
-
描述扩展:我们询问一个大型语言模型,比如GPT-4,关于糖尿病的更多信息。
模型可能会告诉我们,除了高血糖,糖尿病还可能导致视力模糊和疲劳。
现在我们可以在知识图谱中添加新的三元组,如(糖尿病, 关联症状, 视力模糊)和(糖尿病, 关联症状, 疲劳)。
-
关系理解:如果知识图谱只是简单地标记了阿司匹林“用于治疗”发热,我们可能会用提示策略让语言模型提供更多上下文,比如阿司匹林还能“减少炎症”或“预防血栓”。
这样我们就能在知识图谱中添加更准确的关系描述,比如(阿司匹林, 用于预防, 血栓)。
-
结构提取:对于长尾实体,比如一个不太为人知的罕见疾病,我们可以让语言模型提取该疾病的特征或相关信息。
如果模型提供了与其他疾病相似的症状,我们可以创建新的链接,显示这些疾病之间的相似性,从而丰富知识图谱的结构。
以一种罕见疾病“多发性硬化症”作为例子来说明结构提取的过程。
在我们的知识图谱中,“多发性硬化症”可能与几个症状相关联,例如肌肉无力和视觉问题。
但是,我们的图谱可能没有完全覆盖这个疾病的所有相关信息。
我们现在使用一个大型语言模型来提取更多信息。
-
关键词提取:语言模型可能会从医学文献或数据库中提取出“多发性硬化症”通常与“认知功能障碍”和“步态不稳”这些症状相关联的信息。
-
新的链接创建:有了这些新提取的关键词,我们可以在知识图谱中创建新的三元组,如:
- (多发性硬化症, 关联症状, 认知功能障碍)
- (多发性硬化症, 关联症状, 步态不稳)
-
结构丰富:进一步地,如果语言模型指出“系统性红斑狼疮”也与“认知功能障碍”有关,我们可以在这两种疾病之间添加一个“相似症状”类型的链接,以显示它们之间的相似性。
-
新的结构模式形成:通过这样的操作,我们不仅补充了单个疾病的信息,还在不同疾病之间创建了新的联系,有助于揭示它们之间可能的共同生物学机制或治疗方法的对比。
这增加了知识图谱的丰富性,使得研究者能够看到不同疾病间的联系,这些联系以前可能未被注意到。例如:
- (多发性硬化症, 症状相似, 系统性红斑狼疮)
这个过程有助于研究人员理解不同疾病间的潜在联系,为疾病诊断和治疗提供更多线索。
通过这种方式,知识图谱变得更加完整,能够支持更复杂的查询和分析,最终提升医疗保健领域的知识发现和决策支持。
-