文章目录
- 一、简介
- 二、寄存器
- 三、内存模型
- 3.1 Heap
- 3.2 Stack
- 四、指令
- 4.1 示例
- 4.2 语法
- 4.3常用指令
一、简介
汇编语言(英语:assembly language)是任何一种用于电子计算机、微处理器、微控制器,或其他可编程器件的低级语言。在不同的设备中,汇编语言对应着不同的机器语言指令集。一种汇编语言专用于某种计算机系统结构,而不像许多高级语言,可以在不同系统平台之间移植。
使用汇编语言编写的源代码,然后通过相应的汇编程序将它们转换成可执行的机器代码。这一过程被称为汇编过程。
汇编语言使用助记符(Mnemonics)来代替和表示特定低级机器语言的操作。特定的汇编目标指令集可能会包括特定的操作数。许多汇编程序可以识别代表地址和常量的标签(Label)和符号(Symbols),这样就可以用字符来代表操作数而无需采取写死的方式。普遍地说,每一种特定的汇编语言和其特定的机器语言指令集是一一对应的。
许多汇编程序为程序开发、汇编控制、辅助调试提供了额外的支持机制。有的汇编语言编写工具经常会提供宏,它们也被称为宏汇编器。
现在汇编语言已不像其他大多数的程序设计语言一样被广泛用于程序设计,在今天的实际应用中,它通常被应用在底层硬件操作和高要求的程序优化的场合。驱动程序、嵌入式操作系统和实时运行程序中都会需要汇编语言。

最早的时候,编写程序就是手写二进制指令,然后通过各种开关输入计算机,比如要做加法了,就按一下加法开关。后来,发明了纸带打孔机,通过在纸带上打孔,将二进制指令自动输入计算机。
为了解决二进制指令的可读性问题,工程师将那些指令写成了八进制。二进制转八进制是轻而易举的,但是八进制的可读性也不行。很自然地,最后还是用文字表达,加法指令写成 ADD。内存地址也不再直接引用,而是用标签表示。
这样的话,就多出一个步骤,要把这些文字指令翻译成二进制,这个步骤就称为 assembling,完成这个步骤的程序就叫做 assembler。它处理的文本,自然就叫做 aseembly code。标准化以后,称为 assembly language,缩写为 asm,中文译为汇编语言。
每一种 CPU 的机器指令都是不一样的,因此对应的汇编语言也不一样。本文介绍的是目前最常见的 x86 汇编语言。
- x86/x64 汇编:这是应用最广泛的汇编语言类型,用于 Intel 和 AMD 等 x86 架构的处理器,包括 32 位 (x86) 和 64 位 (x64)。这种汇编语言在 PC、服务器和许多嵌入式系统中被广泛使用。
- ARM 汇编:ARM 架构是另一种常见的处理器架构,广泛应用于移动设备、嵌入式系统以及一些服务器。ARM 汇编用于编写针对 ARM 处理器的低级代码。
- MIPS 汇编:MIPS 是一种 RISC 架构(精简指令集计算机),在一些嵌入式系统和早期的个人计算机中使用。MIPS 汇编用于编写针对 MIPS 处理器的低级代码。
- 68k 汇编:68k 汇编用于 Motorola 68k 系列处理器,这些处理器在历史上曾经被广泛应用于个人电脑、工作站和嵌入式系统中。
- AVR 汇编:AVR 是一种常见的低功耗、高性能的 8 位和 32 位微控制器架构,用于许多嵌入式系统和物联网设备。AVR 汇编用于编写针对 AVR 微控制器的低级代码。
- PowerPC 汇编:PowerPC 是 IBM、Motorola 和苹果公司合作开发的一种处理器架构,曾被广泛应用于苹果电脑和一些服务器中。PowerPC 汇编用于编写针对 PowerPC
处理器的低级代码。
二、寄存器
寄存器(Register)是CPU 内用来暂存指令、数据和地址的电脑存储器。寄存器的存贮容量有限,读写速度非常快。在计算机体系结构里,寄存器存储在已知时间点所作计算的中间结果,通过快速地访问数据来加速计算机程序的执行。
寄存器位于存储器层次结构的最顶端,也是CPU可以读写的最快的存储器,事实上所谓的暂存已经不像存储器,而是非常短暂的读写少量信息并马上用到,因为通常程序执行的步骤中,这期间就会一直使用它。寄存器通常都是以他们可以保存的比特数量来计量,举例来说,一个8位寄存器或32位寄存器。在中央处理器中,包含寄存器的部件有指令寄存器(IR)、程序计数器和累加器。寄存器现在都以寄存器数组的方式来实现,但是他们也可能使用单独的触发器、高速的核心存储器、薄膜存储器以及在数种机器上的其他方式来实现出来。
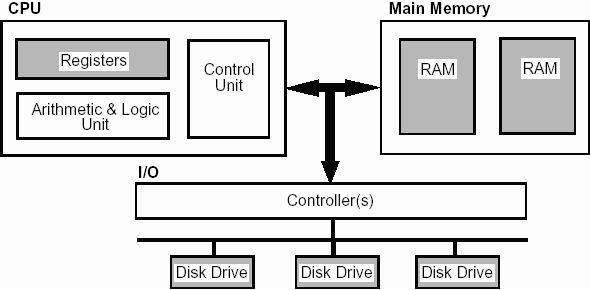
寄存器也可以指代由一个指令之输出或输入可以直接索引到的寄存器组群,这些寄存器的更确切的名称为“架构寄存器”。例如,x86指令集定义八个32位寄存器的集合,但一个实现x86指令集的CPU内部可能会有八个以上的寄存器。
32位 CPU、64位 CPU 这样的名称,其实指的就是寄存器的大小。32 位 CPU 的寄存器大小就是4个字节。
x86架构CPU中常见的寄存器,包括通用寄存器、段寄存器、标志寄存器和指令指针寄存器。这些寄存器在不同的x86处理器中可能会有所不同,但是以下是通用的:
| 寄存器 | 描述 |
|---|---|
| EAX | 累加器 (Accumulator) |
| EBX | 基址寄存器 (Base) |
| ECX | 计数寄存器 (Counter) |
| EDX | 数据寄存器 (Data) |
| ESI | 源索引寄存器 (Source Index) |
| EDI | 目的索引寄存器 (Destination Index) |
| ESP | 栈指针寄存器 (Stack Pointer) |
| EBP | 基址指针寄存器 (Base Pointer) |
| EIP | 指令指针寄存器 (Instruction Pointer) |
| CS | 代码段寄存器 (Code Segment) |
| DS | 数据段寄存器 (Data Segment) |
| SS | 栈段寄存器 (Stack Segment) |
| ES | 附加段寄存器 (Extra Segment) |
| FS | 附加段寄存器 (Extra Segment) |
| GS | 附加段寄存器 (Extra Segment) |
| EFLAGS | 标志寄存器 (Flags) |
这些寄存器的前缀"E"表示32位寄存器,若是64位寄存器,则为"R"。例如,64位下的累加器寄存器为RAX。(16位则没有前缀)
三、内存模型
3.1 Heap
寄存器只能存放很少量的数据,大多数时候,CPU 要指挥寄存器,直接跟内存交换数据。所以,除了寄存器,还必须了解内存怎么储存数据。
程序运行的时候,操作系统会给它分配一段内存,用来储存程序和运行产生的数据。这段内存有起始地址和结束地址,比如从0x1000到0x8000,起始地址是较小的那个地址,结束地址是较大的那个地址。
程序运行过程中,对于动态的内存占用请求(比如新建对象,或者使用malloc等命令),系统就会从预先分配好的那段内存之中,划出一部分给用户,具体规则是从起始地址开始划分(实际上,起始地址会有一段静态数据,这里忽略)。举例来说,用户要求得到10个字节内存,那么从起始地址0x1000开始给他分配,一直分配到地址0x100A,如果再要求得到22个字节,那么就分配到0x1020
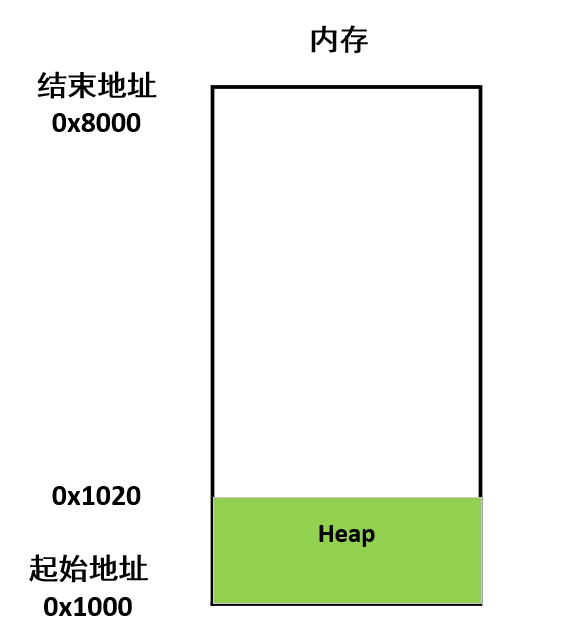
这种因为用户主动请求而划分出来的内存区域,叫做 Heap(堆)。它由起始地址开始,从低位(地址)向高位(地址)增长。Heap 的一个重要特点就是不会自动消失,必须手动释放,或者由垃圾回收机制来回收。
“堆”(Heap)也可以指代一种数据结构,与内存中的堆不同。在数据结构中,堆通常指的是一种特殊的树形结构,用于实现优先队列。
3.2 Stack
除了 Heap 以外,其他的内存占用叫做 Stack(栈)。简单说,Stack 是由于函数运行而临时占用的内存区域。
int main() {
int a = 2;
int b = 3;
}
上面代码中,系统开始执行main函数时,会为它在内存里面建立一个帧(frame),所有main的内部变量(比如a和b)都保存在这个帧里面。main函数执行结束后,该帧就会被回收,释放所有的内部变量,不再占用空间。
int main() {
int a = 2;
int b = 3;
return add_ab(a, b);
}
上面代码中,main函数内部调用了add_ab函数。执行到这一行的时候,系统也会为add_ab新建一个帧,用来储存它的内部变量。也就是说,此时同时存在两个帧:main和add_ab。一般来说,调用栈有多少层,就有多少帧。
等到add_ab运行结束,它的帧就会被回收,系统会回到函数main刚才中断执行的地方,继续往下执行。通过这种机制,就实现了函数的层层调用,并且每一层都能使用自己的本地变量。
所有的帧都存放在 Stack,由于帧是一层层叠加的,所以 Stack 叫做栈。生成新的帧,叫做"入栈"(push);栈的回收叫做"出栈(pop)。Stack 的特点就是,最晚入栈的帧最早出栈(因为最内层的函数调用,最先结束运行),这就叫做"后进先出(LIFO)"的数据结构。每一次函数执行结束,就自动释放一个帧,所有函数执行结束,整个 Stack 就都释放了。
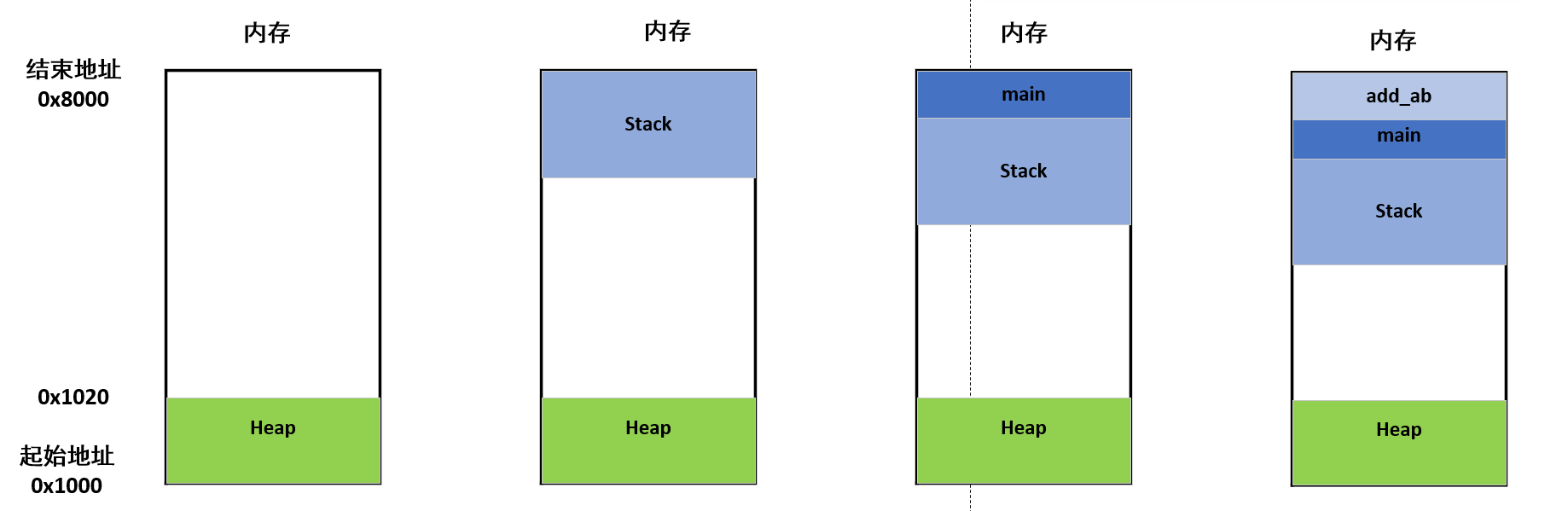
Stack 是由内存区域的结束地址开始,从高位(地址)向低位(地址)分配。 比如,内存区域的结束地址是0x8000,第一帧假定是16字节,那么下一次分配的地址就会从0x7FF0开始;第二帧假定需要64字节,那么地址就会移动到0x7FB0。
四、指令
4.1 示例
C语言:
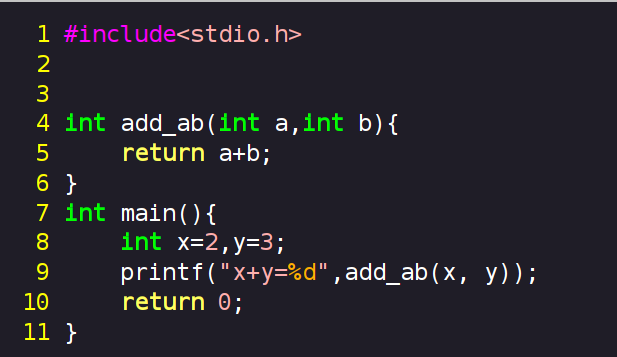
转成汇编:
gcc -S temp.c
汇编代码:一个高级语言的简单操作,底层可能由几个,甚至几十个 CPU 指令构成。CPU 依次执行这些指令,完成这一步操作。(注释是我加的)
.file "temp.c" ; 源文件名称
.text ; 开始文本段
.globl add_ab ; 声明 add_ab 是一个全局函数
.type add_ab, @function ; 指定 add_ab 是一个函数类型
add_ab: ; 函数 add_ab 的开始
.LFB0:
.cfi_startproc
endbr64 ; 提高对分支目标地址(BTA)的保护
pushq %rbp ; 保存旧的栈基址指针
.cfi_def_cfa_offset 16 ; 指定栈上的数据偏移量
.cfi_offset 6, -16 ; 指定寄存器 %rbp 的偏移
movq %rsp, %rbp ; 设置 %rbp 指向当前栈顶,建立新的栈帧
.cfi_def_cfa_register 6 ; 指定 %rbp 为当前帧指针
movl %edi, -4(%rbp) ; 将函数参数 %edi(第一个参数)存储到栈上的位置
movl %esi, -8(%rbp) ; 将函数参数 %esi(第二个参数)存储到栈上的位置
movl -4(%rbp), %edx ; 从栈中加载第一个参数 %edx
movl -8(%rbp), %eax ; 从栈中加载第二个参数 %eax
addl %edx, %eax ; 将 %edx 和 %eax 相加
popq %rbp ; 恢复之前的栈基址指针
.cfi_def_cfa 7, 8 ; 指定栈顶为 %rsp,栈基址为 %rbp
ret ; 函数返回
.cfi_endproc
.LFE0:
.size add_ab, .-add_ab ; 指定函数 add_ab 的大小
.section .rodata ; 开始只读数据段
.LC0:
.string "x+y=%d" ; 定义一个字符串常量,用于 printf 函数
.text ; 返回文本段
.globl main ; 声明 main 函数为全局函数
.type main, @function ; 指定 main 是一个函数类型
main: ; main 函数的开始
.LFB1:
.cfi_startproc
endbr64 ; 提高对分支目标地址(BTA)的保护
pushq %rbp ; 保存旧的栈基址指针
.cfi_def_cfa_offset 16 ; 指定栈上的数据偏移量
.cfi_offset 6, -16 ; 指定寄存器 %rbp 的偏移
movq %rsp, %rbp ; 设置 %rbp 指向当前栈顶,建立新的栈帧
.cfi_def_cfa_register 6 ; 指定 %rbp 为当前帧指针
subq $16, %rsp ; 为局部变量分配空间
movl $2, -8(%rbp) ; 将常量 2 存储到栈上的位置(第一个局部变量)
movl $3, -4(%rbp) ; 将常量 3 存储到栈上的位置(第二个局部变量)
movl -4(%rbp), %edx ; 从栈中加载第一个局部变量 %edx
movl -8(%rbp), %eax ; 从栈中加载第二个局部变量 %eax
movl %edx, %esi ; 复制 %edx 到 %esi
movl %eax, %edi ; 复制 %eax 到 %edi
call add_ab ; 调用 add_ab 函数
movl %eax, %esi ; 将返回值(和)存储到 %esi 中
leaq .LC0(%rip), %rdi ; 将字符串地址存储到 %rdi 中
movl $0, %eax ; 将 0 存储到 %eax
call printf@PLT ; 调用 printf 函数
movl $0, %eax ; 将 0 存储到 %eax,表示返回值为 0
leave ; 恢复栈帧
.cfi_def_cfa 7, 8 ; 指定栈顶为 %rsp,栈基址为 %rbp
ret ; 函数返回
.cfi_endproc
.LFE1:
.size main, .-main ; 指定函数 main 的大小
.ident "GCC: (Ubuntu 9.4.0-1ubuntu1~20.04.2) 9.4.0" ; 编译器的版本信息
.section .note.GNU-stack,"",@progbits ; 用于指示栈是否是可执行的
.section .note.gnu.property,"a" ; GNU 属性节
.align 8
.long 1f - 0f
.long 4f - 1f
.long 5
0:
.string "GNU"
1:
.align 8
.long 0xc0000002
.long 3f - 2f
2:
.long 0x3
3:
.align 8
4:
4.2 语法
汇编语言的语法可以根据不同的体系结构有所不同,以下是 x86 架构汇编语言的一般语法:
指令格式:
[label:] mnemonic [operands] [;comment]
label:可选的,用于标识代码的位置,以冒号结尾。mnemonic:指令助记符,代表要执行的操作。operands:操作数,指定指令要操作的数据。comment:注释,用于解释指令的作用或其他信息。
基本元素:
- 指令(Instructions):表示要执行的操作,如
mov,add,sub,jmp等。 - 寄存器(Registers):用于存储数据和执行操作,如
eax,ebx,ecx等。 - 内存操作数(Memory Operands):表示内存中的数据,如
[address],[ebx]等。 - 立即数(Immediate Values):常数值,直接指定在指令中,如
5,0xFF,0b1010等。 - 标签(Labels):用于标识代码的位置,通常在循环或条件跳转中使用。
指令示例:
; 注释示例
section .text ; 代码段开始
global _start ; 全局声明,程序入口
_start:
mov eax, 5 ; 将立即数 5 存入 eax 寄存器
mov ebx, 3 ; 将立即数 3 存入 ebx 寄存器
add eax, ebx ; eax = eax + ebx
sub eax, 1 ; eax = eax - 1
cmp eax, 10 ; 比较 eax 和立即数 10
jl less_than_ten ; 如果 eax < 10,则跳转到 less_than_ten 标签
mov eax, 10 ; 如果不满足条件,将立即数 10 存入 eax
less_than_ten:
mov ecx, eax ; 将 eax 的值存入 ecx
; 调用系统调用 exit
mov eax, 1 ; 系统调用号 1 表示 exit
xor ebx, ebx ; 退出码为 0
int 0x80 ; 调用系统调用
section .data ; 数据段开始
my_var db 'A' ; 定义一个名为 my_var 的字节数据,值为字符 'A'
汇编语言对空白字符不敏感,但大小写敏感。同时,注释以分号 ; 开始,可以在语句后添加注释。
4.3常用指令
常用的汇编指令以及简要说明和示例:
| 指令 | 说明 | 示例 |
|---|---|---|
mov | 将数据从一个位置复制到另一个位置 | mov eax, ebx |
add | 加法操作 | add eax, ebx |
sub | 减法操作 | sub eax, ebx |
mul | 无符号乘法 | mul ebx |
div | 无符号除法 | div ebx |
and | 按位与操作 | and eax, ebx |
or | 按位或操作 | or eax, ebx |
xor | 按位异或操作 | xor eax, ebx |
not | 按位取反操作 | not eax |
shl | 逻辑左移 | shl eax, 1 |
shr | 逻辑右移 | shr eax, 1 |
cmp | 比较两个操作数的值,设置标志位 | cmp eax, ebx |
test | 测试两个操作数的位并设置标志位 | test eax, ebx |
jmp | 无条件跳转 | jmp label |
je | 等于时跳转 | je label |
jne | 不等于时跳转 | jne label |
jl | 小于时跳转 | jl label |
jg | 大于时跳转 | jg label |
jle | 小于等于时跳转 | jle label |
jge | 大于等于时跳转 | jge label |
call | 调用函数或过程 | call function_name |
ret | 从函数返回 | ret |
push | 将数据压入栈 | push eax |
pop | 从栈中弹出数据 | pop eax |
nop | 空操作 | nop |
int | 产生软中断 | int 0x80 |
hlt | 暂停处理器执行 | hlt |
示例:
假设有以下寄存器的初始值:
eax= 5ebx= 3
示例汇编指令和注释如下:
; 将 ebx 加到 eax 中
add eax, ebx ; eax = 5 + 3 = 8
; 乘以 ebx 的值
mul ebx ; eax = 8 * 3 = 24
; 将结果保存到变量 result 中
mov [result], eax ; result = 24
; 比较 eax 和 ebx 的值
cmp eax, ebx ; 设置标志位,用于后续条件跳转
; 如果 eax 大于 ebx,跳转到 label1
jg label1 ; 如果 24 > 3,则跳转
; 否则跳转到 label2
jmp label2
label1:
; 如果跳转到这里,说明 24 > 3
; 这里可以添加一些操作
label2:
; 如果跳转到这里,说明 24 <= 3
; 这里可以添加一些操作
; 函数调用示例
call my_function ; 调用函数 my_function
; 从函数返回
ret
; 定义一个标签,用于跳转
label3:
; 这里可以添加一些操作