1.题目
Data Science London正在举办一场关于Scikit-learn的聚会。 这个比赛是尝试、分享和创建 sklearn 分类能力示例的练习场(如果这变成了有用的东西,我们可以跟进回归或更复杂的分类问题)。Scikit-learn(sklearn)是一个成熟的开源机器学习库,在NumPy,SciPy和Cython的帮助下用Python编写。
数据集描述
这是一个包含 40 个特征的合成数据集,表示来自两个类(标记为 0 或 1)的对象。训练集有 1000 个样本,测试集有 9000 个样本。
这是一个二元分类任务,将根据分类准确性(正确预测的标签百分比)评估您。 训练集有 1000 个样本,测试集有 9000 个样本。 您的预测应该是 9000 x 1 的 1 或 0 向量。您还需要一个 Id 列(1 到 9000),并且应该包含一个标题。

2.数据处理
2.1观察
首先新打印一些数据的前五行,看看数据长什么样子:
print(df_train.head())
特征列的标题实在太长,显示列很少,没有观察到什么有用的信息,继续观察。
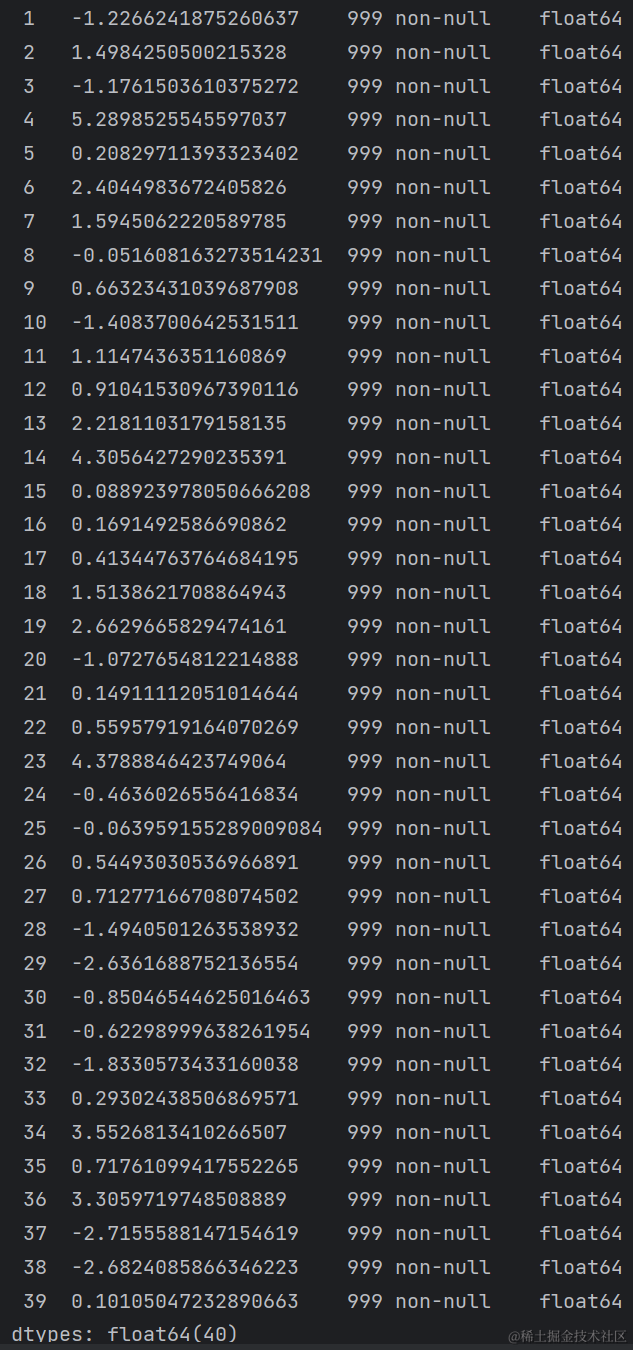
再打印一下数据的简明摘要,显示数据的索引类型、列名、列数据类型、非空值数量,以了解数据的基本情况。
print(df_train.info())
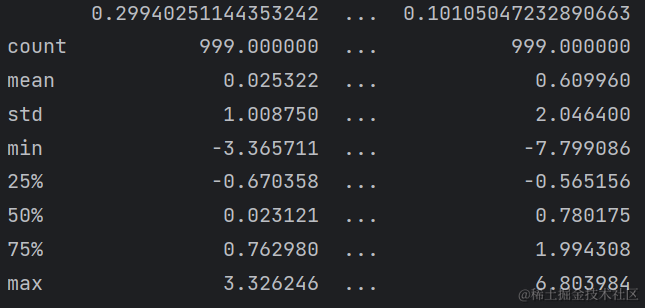
打印一下数据的基本统计信息,如百分比、均值、标准差等方法,如下图:
print(df_train.describe())
我还想再看一下数据中存在哪些缺失值:
print(df_train.isnull().sum())
出乎意料🤪,我还是第一次遇到给出不存在缺失值的数据!这个题变得有意思起来了😜
再看一下数据中是否有重复值。
print(df_train.nunique())
第一列表示每一列标题,第二列表示每一列中不一样的值,好家伙,每一列的值都不一样。
print(df_train.nunique(axis=1))
第一列表示特征列标题,第二列表示每一行中不一样的值,好家伙,每一列的值都不一样。

好好好,这写数据每一行,每一列都是不同的,真是越来越有意思了。😎继续玩下去。

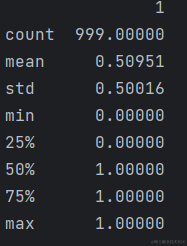
似乎还给一个标签的表,也去看看这个表长什么样:
print(df_train_label.describe())
似乎这张表就是一张标签表,对train表格中的每一行打标签,0或1.
现在对train、trainLabels、test(和train一样的操作就没有贴出来啦)数据都很清楚了,下面就开始数据化分析吧!
3.探索和可视化EDA
3.1制直方图以查看特征分布
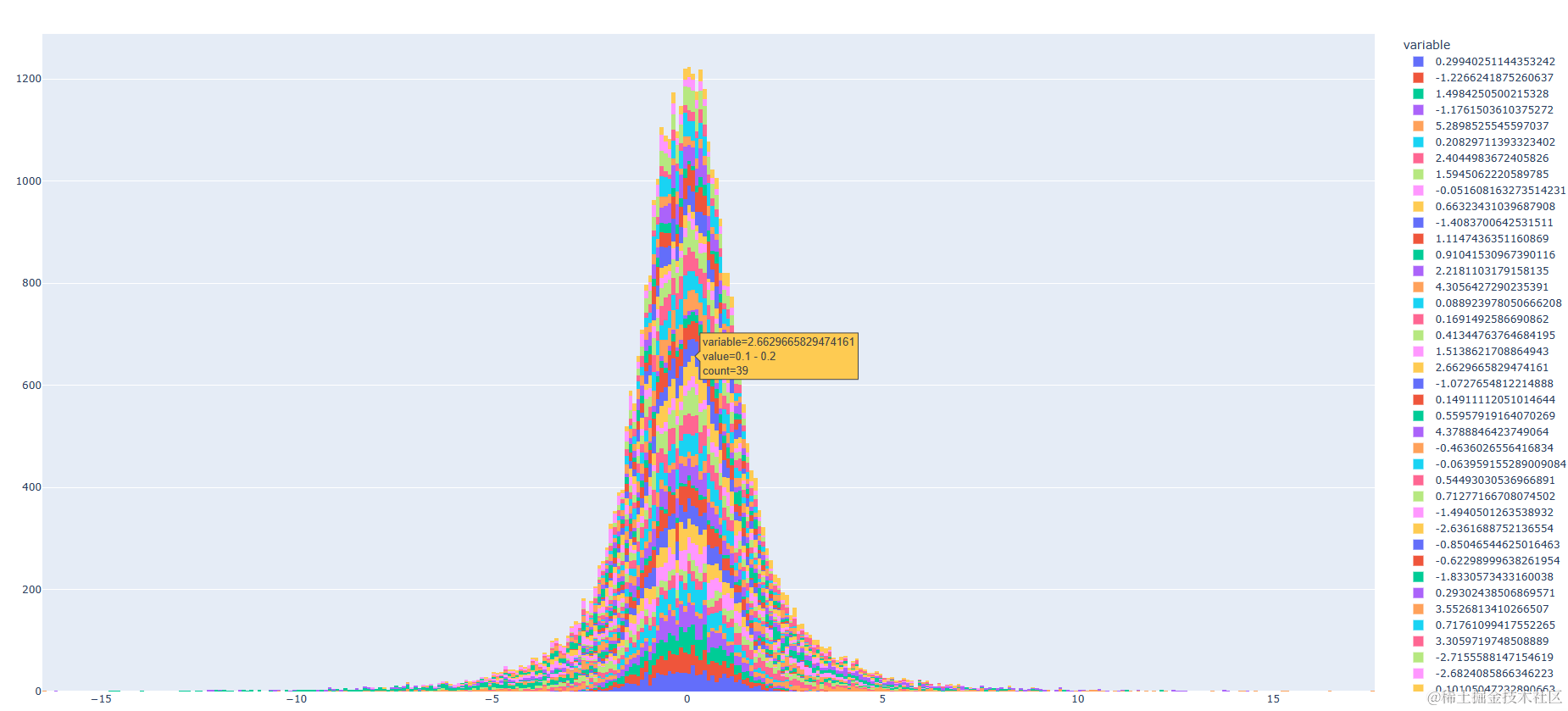
我想通过直方图的去查看特征分布,目的是了解数据的形状、中心、范围和异常值。
fig = px.histogram(df_train)
fig.show()
40个特征还是有点东西的,颜色四十彩斑斓花里胡哨,但是仔细一点还是可以看出所有特征基本都是符合正态分布的。
3.2制作箱线图查看数据的分布和异常值
plt.figure(figsize = (20,20))
for i in range (len(df_train.columns)):
plt.subplot(5, 10, i+1)
sns.boxplot(df_train.iloc[:,i])
plt.xlabel(df_train.columns[i], size = 10)
plt.show()
画出所有特征列的箱线图,在画布上创建一个5*10的子图网格,使用sns.boxplot函数绘制当前列的箱线图。

箱线图是一种用于显示数据分布的图形,它可以显示数据的最小值、最大值、中位数、四分位数和异常值。
箱子在中位数两边对称,数据都是对称分布的,而且还可以观察到,箱子很长,即数据比较散。
3.3制作热力图查看特征之间的相关性
plt.figure(figsize = (20,20))
sns.heatmap(df_train.corr(), annot = True,cmap="YlOrRd",annot_kws={"size": 3})
plt.show()
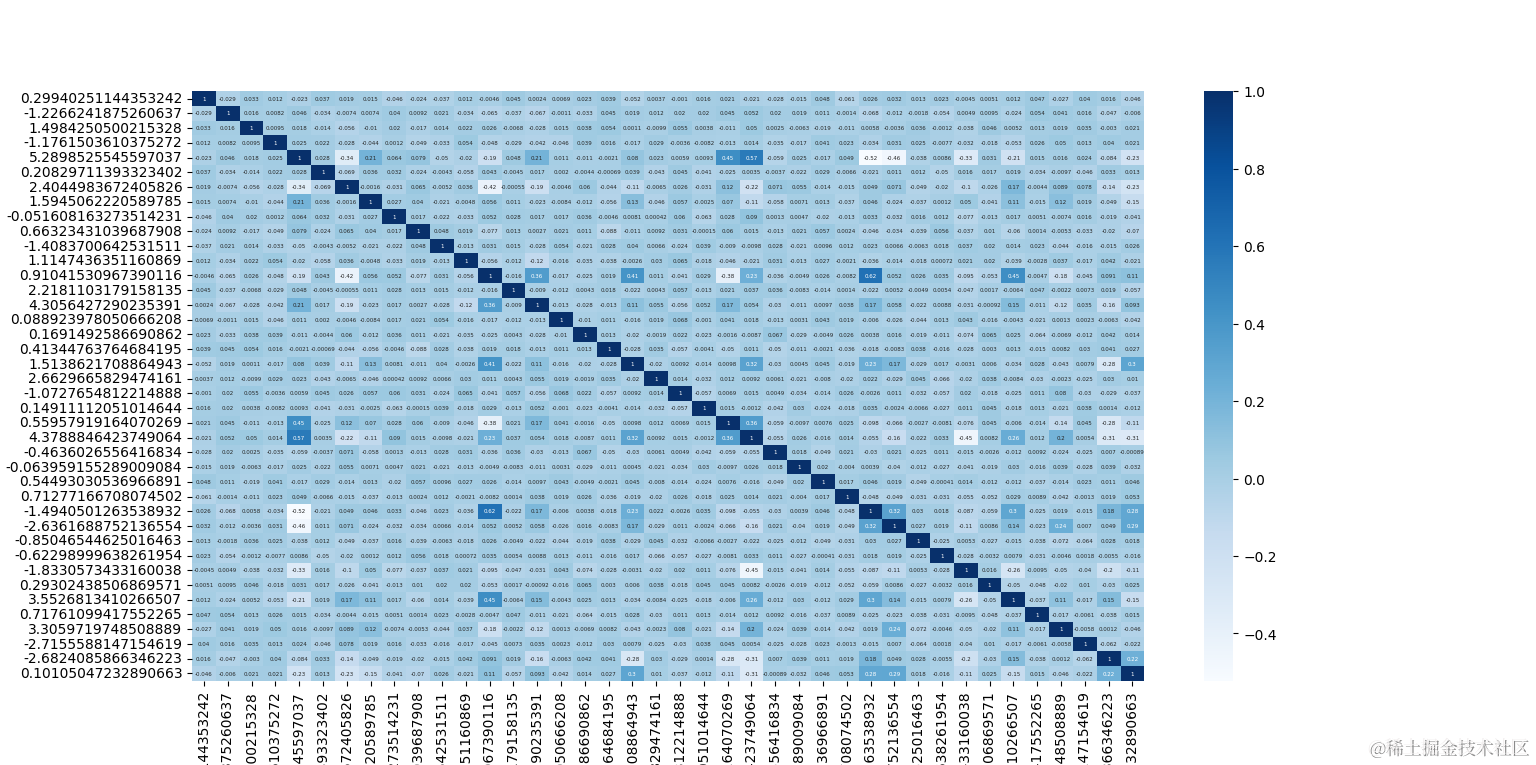
观察上图,似乎数据间的相关性并不是很高,更多的是不呈相关性。
4 模型预测
这次的数据如此不同,异常数据没有,连缺省数据都没有,数据也不需要处理,那就多用几个模型预测吧,看看什么样的模型更适合这个数据。这次共选取6种模型进行预测📈。
先将train数据分割成训练集和测试集,按照7-3分。
x_train, x_test, y_train, y_test = train_test_split(train, trainLabels, test_size=0.30, random_state=101)
print(x_train.shape, x_test.shape, y_train.shape, y_test.shape)
分好的训练集和测试集如下所示:

开始测试吧🤗
4.1 📉Logistic Regression 逻辑回归
逻辑回归是一种用来预测二元变量(如0或1)的概率的模型。
logistic_model = LogisticRegression()
logistic_model.fit(x_train, y_train.values.ravel())
l_predicted = logistic_model.predict(x_test)
print('Logistic Regression准确率:', accuracy_score(y_test, l_predicted))

4.2 K-Nearest Neighbors KNN K-最邻近
K-最邻近是一种基于实例的模型,可以用来分类或回归。
K-最邻近的思想是根据一个新的数据点与已知的数据点的距离,找出最近的k个邻居,然后根据这些邻居的类别或数值进行投票或平均,得到新数据点的预测结果。
knn_model = KNeighborsClassifier()
knn_model.fit(x_train, y_train.values.ravel())
knn_predicted = knn_model.predict(x_test)
print('KNN model准确率:', accuracy_score(y_test, knn_predicted))

4.3 Support Vector Machine SVM 支持向量机
支持向量机是一种非线性模型,可以用来分类或回归。
支持向量机的核心思想是通过一个核函数(如高斯核),将数据映射到一个高维空间,然后在这个空间中寻找一个超平面,使得不同类别的数据点之间的距离最大化。
svc_model = SVC(gamma='auto')
svc_model.fit(x_train, y_train.values.ravel())
svc_predicted = svc_model.predict(x_test)
print('SVM准确率:', accuracy_score(y_test, svc_predicted))

4.4 🌲Random Forest RF 随机森林
随机森林是一种集成学习模型,可以用来分类或回归。
它的核心思想是通过构建多棵决策树,并让这些决策树对同一个数据点进行预测,然后根据这些决策树的预测结果进行投票或平均,得到最后的预测结果。
rforest_model = RandomForestClassifier()
rforest_model.fit(x_train, y_train.values.ravel())
rf_predicted = rforest_model.predict(x_test)
print('Random Forest准确率:', accuracy_score(y_test, rf_predicted))

4.5 📐Extreme Gradient Boosting XGBoost 极致梯度提升
XGBoost就太熟悉了吧,上一篇文章还详细介绍过。
还是简单介绍一下吧。
XGBoost是一种集成学习模型,也是基于决策树的模型,但与随机森林不同的是,它是通过迭代地构建决策树,并让每一棵树对前面所有决策树预测结果的误差进行拟合,从而不断的提高预测精度。
xgb = XGBClassifier()
xgb.fit(x_train, y_train.values.ravel())
xgb_predicted = xgb.predict(x_test)
print('XGBoost准确率:', accuracy_score(y_test, xgb_predicted))

4.6 😸Categorical Boosting CatBoost 分类梯度提升
CatBoost是一种集成学习模型,也可以用来分类或回归。与极致梯度提升类似,也是基于决策树的模型,但它的特点是能够很好的处理分类特征,而不需要对分类特征进行编码或转换。
cat = CatBoostClassifier()
cat.fit(x_train, y_train.values.ravel())
cat_predicted = cat.predict(x_test)
print('CatBoost准确率:', accuracy_score(y_test, cat_predicted))
通过上面实验可以观察到,支持向量机模型对这组数据的预测准确率最高,达到了92.3%,其次是KNN和XGBoost均有87%的准确率。(题外话,XGBoost终于赢了CatBoost🥇)

4.7交叉验证
使用sklearn库中的cross_val_score函数来进行交叉验证,此函数可以对给定的模型和数据,使用指定的折数(cv参数)进行k折交叉验证,并返回准确率。
我在代码中对每个模型进行10折交叉验证,并打印出每个模型的平均交叉分数,目的是比较不同模型在同一数据集上的性能,并选择最优的模型。
norm = Normalizer()
norm_train = norm.fit_transform(train)
knn_model = KNeighborsClassifier(n_neighbors=5)
print('KNN', cross_val_score(knn_model, norm_train, trainLabels.values.ravel(), cv=10).mean())
rfc_model = RandomForestClassifier(n_estimators=100, random_state=100)
print('Random Forest', cross_val_score(rfc_model, norm_train, trainLabels.values.ravel(), cv=10).mean())
lr_model = LogisticRegression(solver='saga')
print('Logistic Regression', cross_val_score(lr_model, norm_train, trainLabels.values.ravel(), cv=10).mean())
svc_model = SVC(gamma='auto')
print('SVM', cross_val_score(svc_model, norm_train, trainLabels.values.ravel(), cv=10).mean())
xgb = XGBClassifier()
print('XGBoost', cross_val_score(xgb, norm_train, trainLabels.values.ravel(), cv=10).mean())
cat = CatBoostClassifier()
print('CatBoost', cross_val_score(cat, norm_train, trainLabels.values.ravel(), cv=10).mean())
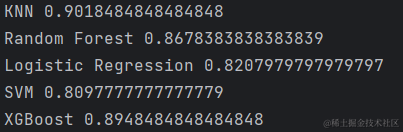

观察到打印出的结果,CatBoost模型和KNN模型均以0.90的平均验证分数位居前列,CatBoost以微弱的优势暂居第一。其他模型的表现也很不错,均有0.80以上得分。✌
5 数据预测
通过上面的可视化探索,得到支持向量机和CatBoost模型两个模型的评分不错,接下来就用这两个模型都分别预测一下吧。
5.1支持向量机进行预测
print(train.shape, test.shape)
svc_model.fit(train, trainLabels.values.ravel())
svc_predicted = svc_model.predict(test)
svc_predicted = pd.DataFrame(svc_predicted)
svc_predicted.columns = ['Solution']
svc_predicted['Id'] = np.arange(1, len(svc_predicted) + 1)
svc_predicted = svc_predicted[['Id', 'Solution']]
svc_predicted.to_csv(r'C:\Users\19313\Desktop\其他\kaggle竞赛\伦敦数据科学+Scikit-learn\output_data\svc_predict.csv', index=False)
将用SVM模型预测得到的数据输出为csv文件,然后提交到kaggle上,得分是0.913,分数应该还不错,但是我不知道排名,因为这个比赛已经结束了。

5.2CatBoost进行预测
cat.fit(train, trainLabels.values.ravel())
cat_predicted = cat.predict(test)
cat_predicted = pd.DataFrame(cat_predicted)
cat_predicted.columns = ['Solution']
cat_predicted['Id'] = np.arange(1, cat_predicted.shape[0] + 1)
cat_predicted = cat_predicted[['Id', 'Solution']]
cat_predicted.to_csv(r'C:\Users\19313\Desktop\其他\kaggle竞赛\伦敦数据科学+Scikit-learn\output_data\cat_predict.csv', index=False)
同上,将CatBoost模型预测得到的数据也提交,得分为0.895,比向量机的得分要低一些。这两个还是SVM更胜一筹呀😎

这个比赛也完成了,总的来说,这次的数据是非常神奇的。比如说,没有缺失数据,没有异常数据,没有表头(我在这个点上栽了好大一个跟头😩),不过总体还是很有意思的。