当你不知道从何入手研究或解决一个复杂系统的问题时,通常意味着你没有找到合适的切入点或者缺乏对系统整体和细节之间联系的理解。在这种情况下,一个有用的策略是寻找系统的基本原理或构成要素。
小时候,你可能也玩过玩具四驱车。有的四驱车设计得比较封闭,集成度高,除了换电池外几乎不允许拆卸。而另一种则是可组装的,允许在有限的零件中自由更换,为你提供了丰富的选择空间。我个人偏爱后者,它不仅展示了玩具车的整体构造,还让每一个零件都呈现在我的眼前。对我来说,这不仅仅是一辆车,而是一个由众多零件组成的系统,我能够向我的伙伴详细介绍每个零件独特之处和它们如何共同作用。
其实你也看出来了,当一个被外壳裹挟的四驱车你可能玩过一段时间就不会再去玩它,渐渐被你淡忘。而以一件一件零件的形式摆在你面前,你会更好奇的去探索它,并且印象深刻。
那么我要上第一板斧就是拆解:
“要想了解一个复杂系统,我们需要从拆解的角度去看问题”
我们需要分解这个系统
要深入理解一个复杂系统,首先要将其分解成更小、更易于理解的部分。
上大学的时候,老师让我们在自己的计算机上安装一个服务器(更懒的老师可能就直接在机房直接给你安装好,你再软件中操作就是了),然后再从window系统的某个角落掏出一个你不知道什么时候就安装好的自带的客户端,通过远程连接,连上了。然后教你理论知识,什么是范式理论,如何去画一个ER图,接下来就教你第一句MYSQL命令了。可能老师没有点出来,但是这会,你不知不觉就接触到了这个系统,虽然此时蒙上了厚厚的一层灰。你看:
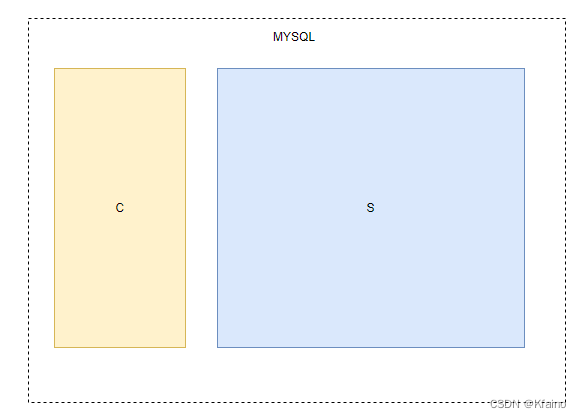
客户端/服务器模型
现在,我们知道了,MySQL这个系统,它遵循客户端/服务器(Client/Server)模型,其中:
客户端:提供用户接口,允许用户通过各种客户端工具或者是编程语言接口发送SQL查询。
服务器:MySQL服务器是核心组件,负责处理所有数据库命令和操作,包括查询解析、分析、优化以及执行。
连接器
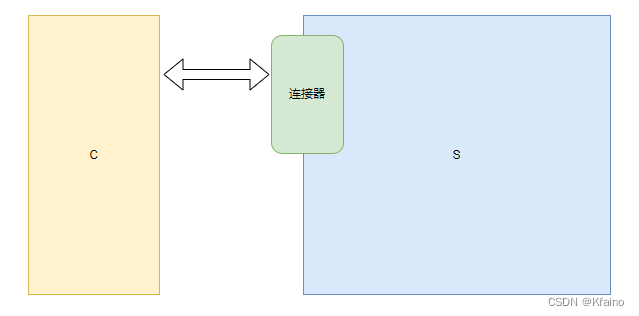
紧接着我们来到服务器端的连接器。客户端在与服务器进行通信时,首先要和连接器打交道。连接管理器负责处理网络连接、授权客户端、管理连接的安全验证。
授权认证:在这一层,MySQL使用用户名、密码等信息验证连接请求的合法性。
安全:提供SSL加密连接,保证数据传输的安全性。
解析优化执行一条龙
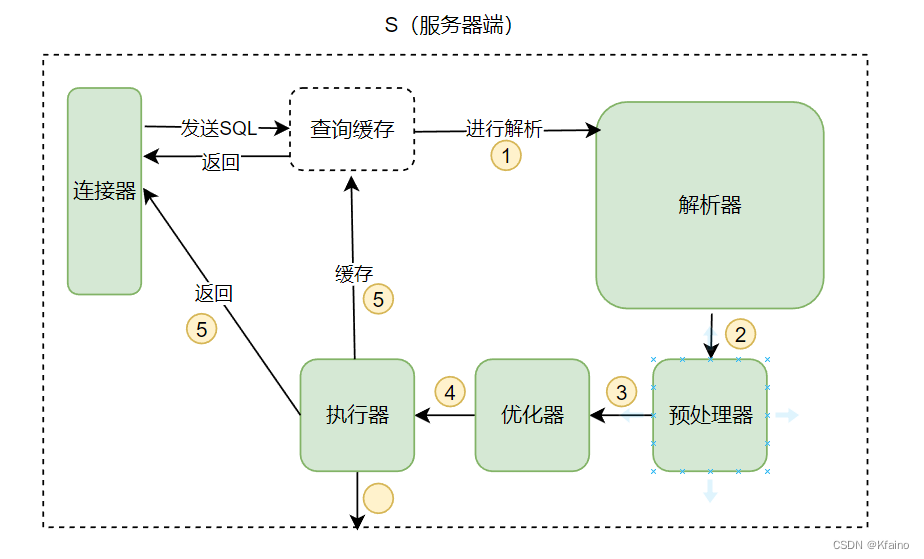
通过第一关后,MYSQL就可以正儿八经的处理你发送过来的SQL命令了。接收到SQL命令后,MySQL进入查询处理阶段,包括:
解析器:将SQL语句分解成解析树,这一过程涉及词法、语法分析。
预处理器:进一步检查解析树是否符合MySQL规则,包括数据类型和表结构等。
优化器:负责查询优化,决定最有效的查询执行计划。
执行器:一旦优化器确定了最佳的查询执行计划,执行器就会按照这个计划来操作数据。
执行器到哪里去取数据呢?答案是存储引擎
存储引擎层
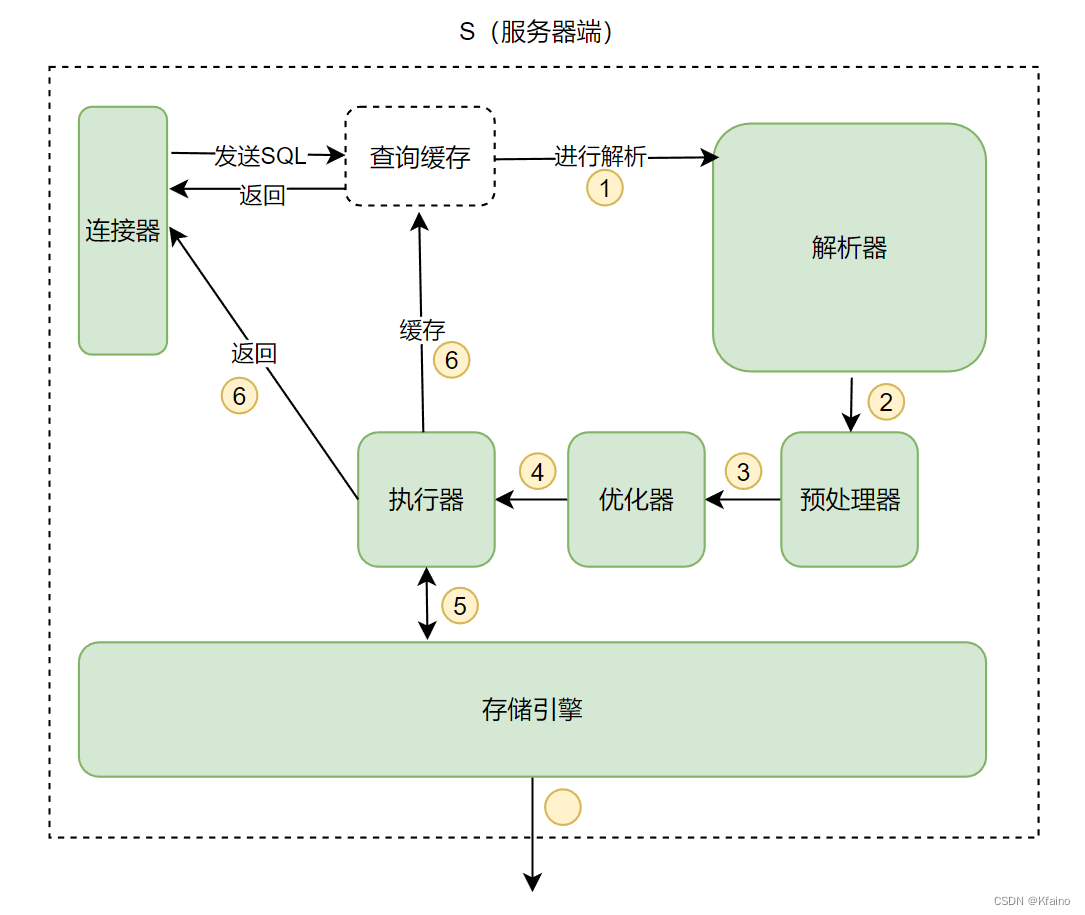
MySQL提供了插件式的存储引擎架构,不同的存储引擎对数据的存储方式和索引技术有着不同的实现。我们常见的存储引擎就有以下两种:
InnoDB:提供事务安全(ACID兼容)、行级锁定和外键约束等。
MyISAM:提供高速存取但不支持事务安全。
要想在MYSQL中使用也很简单,你只需要在创建表的时候加上这么一句就可以:
CREATE TABLE my_table (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100)
) **ENGINE=InnoDB**;
当然也可以修改这个表的存储引擎:
ALTER TABLE my_table ENGINE = MyISAM;
其实到了存储引擎层面,软件层的事情就万事大吉了。但是如果你可以再往下探索看到不同存储引擎的存放规则,那你的印象肯定会进一步加深。
数据存储和文件系统
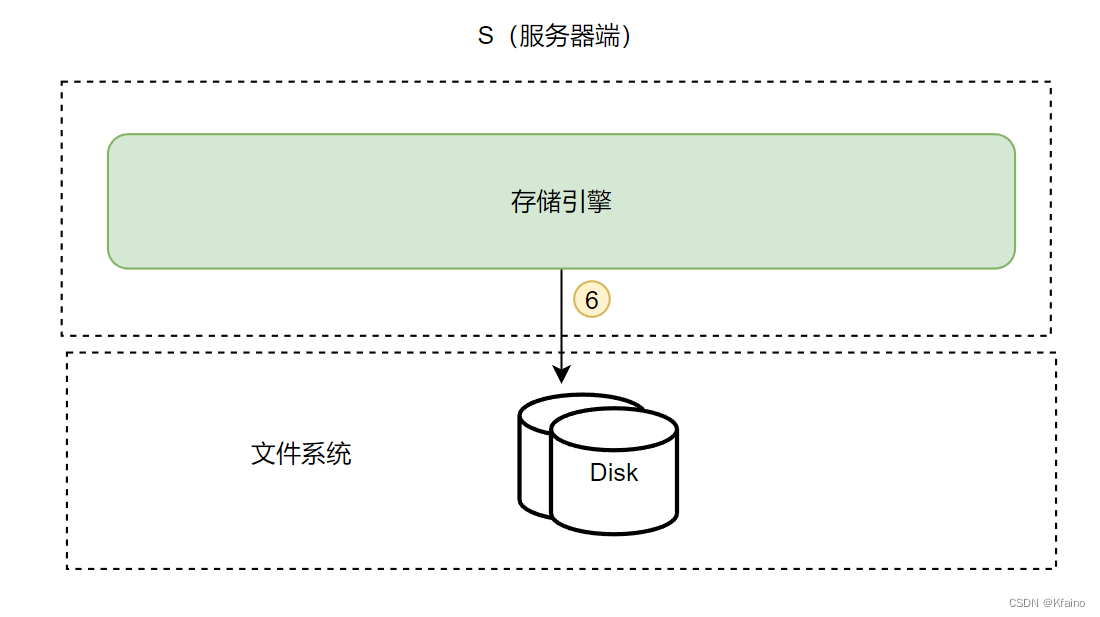
底层数据存储涉及到如何在物理存储介质(如硬盘)上存储数据和索引文件。不同存储引擎有着不同的文件组织方式和存储格式,如MyISAM为每个表创建独立的文件,而InnoDB使用表空间存储数据和索引。
MyISAM
首先,我们创建一个使用MyISAM存储引擎的表:
CREATE TABLE myisam_table (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100)
) ENGINE=MyISAM;
查看磁盘创建了这三个文件:

- myisam_table.MYD:这是数据文件,存储表的实际数据。
- myisam_table.MYI:这是索引文件,存储表的索引信息。
- myisam_table.frm:这是表定义文件,存储表的结构。
InnoDB
接下来,我们创建一个使用InnoDB存储引擎的表:
CREATE TABLE innodb_table (
id INT AUTO_INCREMENT PRIMARY KEY,
name VARCHAR(100)
) ENGINE=InnoDB;
紧接着在磁盘中就找到了这两个文件:

对于InnoDB表,情况稍有不同:
- innodb_table.frm:表定义文件,与MyISAM相同,存储表的结构。
- innodb_table.ibd:当MySQL配置为innodb_file_per_table=ON时,每个InnoDB表的数据和索引会存储在独立的.ibd文件中。如果innodb_file_per_table=OFF,则所有InnoDB表的数据和索引存储在共享表空间ibdata1中。
除此之外,InnoDB还会使用其它一些文件来管理数据。为了避免啰嗦,这里我们按下不表,如果感兴趣可以持续关注我后续的文章,感谢支持。
当然, 会拆玩具可不行,你还得深谙每个零部件的重要作用。接下来是第二板斧
识别其中关键因素
一旦系统被拆解,下一步是识别出影响系统性能、稳定性等一些关键因素。
暂停一分钟思考下,有哪些地方是贯穿我们工作的关键要素呢?
…
…
…
…
…
数据索引机制
数据索引机制是数据库查询性能优化的核心。索引允许数据库快速定位和检索数据,而无需扫描整个表。MySQL支持多种类型的索引,包括B-Tree索引、全文索引、哈希索引等,每种索引适用于不同的查询类型和数据模式。合理的索引管理策略,包括选择合适的索引类型、维护索引以避免过度索引,对于维持数据库性能至关重要。这甚至可以成为不同程序员的一道分水岭。
查询优化器
你知道要让这个查询走什么样的索引,你说了不算。你要让查询优化器听你的才行。查询优化器负责生成查询的执行计划。它评估多个可能的计划,并选择成本最低(预计最快)的那个执行。调优大部分时间也是围绕它来。通过去分析执行计划,我们可以识别性能瓶颈,进而调整查询语句或数据库结构,实现性能优化。
数据存储方式
你知道软件层面的优化,也要兼顾到硬件层面的事情。那么存储引擎这件事情你就要知晓(虽然现在闭眼就用InnoDB)。数据的组织、存储格式以及如何在磁盘上排列,都直接影响到数据访问的速度和效率。适当的数据模型设计可以减少I/O开销,提高查询性能。对于需要支持复杂事务的应用,选择支持ACID属性的存储引擎(如InnoDB)是关键。事务处理机制确保了数据库操作的原子性、一致性、隔离性和持久性。
我们把它拆回去,有仔细分析了一些我们觉得非常重要的零部件之后。还是要给它装起来,接下来就是第三板斧了
形成整体的视角
通过分解系统并识别关键因素后,我们需要重新将这些部分组合起来,形成对系统整体工作原理的理解。要想有一个整体的视角,我们要怎么训练呢?
我们可以从一个简单的Select/Update语句开始,逐层分析,一点一点剥离出来。
完整的生命周期,从数据被插入数据库开始,经过存储、查询、更新,最终可能被删除,这个过程构成了数据的生命周期。理解数据如何流经MySQL的各个组成部分,是形成整体视角的关键一环。
这里也是你漫长训练求索的过程,通过这样的训练之后,你就会达到拥有整体视角的快感。那还在等什么呢?行动起来!
总结
相信通过拆解复杂系统、识别关键因素,并最终形成对系统整体的深入理解,这三板斧,我们可以更有效地诊断问题、提出解决方案和实施改进。这种方法论不仅适用于其它技术系统,也适用于任何复杂的问题解决过程,是一种强大的思维工具。要想精通这一策略,关键在于实践和经验积累,随着时间的推移,我们就能够更快地识别不同系统的核心要素,更有效地解决问题。