💡💡💡本文改进内容:通道注意力和空间注意力CBAM,全新注意力GAM:超越CBAM,不计成本提高精度
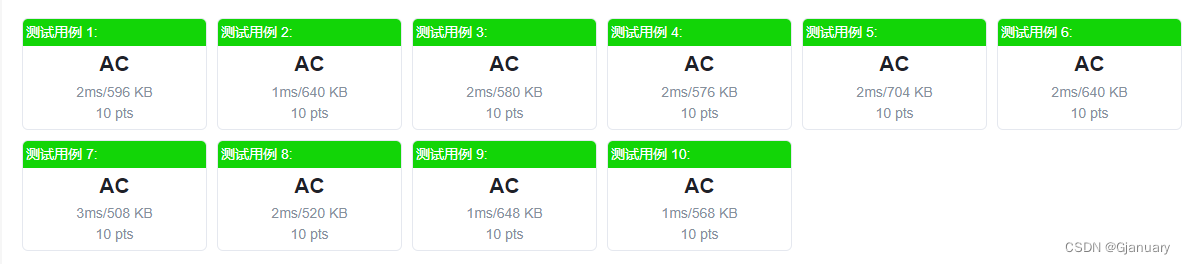
改进结构图如下:
YOLOv9魔术师专栏
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️ ☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
包含注意力机制魔改、卷积魔改、检测头创新、损失&IOU优化、block优化&多层特征融合、 轻量级网络设计、24年最新顶会改进思路、原创自研paper级创新等
☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️☁️
✨✨✨ 新开专栏暂定免费限时开放,后续每月调价一次✨✨✨
🚀🚀🚀 本项目持续更新 | 更新完结保底≥50+ ,冲刺100+🚀🚀🚀
🍉🍉🍉 联系WX: AI_CV_0624 欢迎交流!🍉🍉🍉
🍉🍉🍉 专属微信交流群 欢迎交流!🍉🍉🍉

YOLOv9魔改:注意力机制、检测头、blcok魔改、自研原创等
YOLOv9魔术师
💡💡💡全网独家首发创新(原创),适合paper !!!
💡💡💡 2024年计算机视觉顶会创新点适用于Yolov5、Yolov7、Yolov8等各个Yolo系列,专栏文章提供每一步步骤和源码,轻松带你上手魔改网络 !!!
💡💡💡重点:通过本专栏的阅读,后续你也可以设计魔改网络,在网络不同位置(Backbone、head、detect、loss等)进行魔改,实现创新!!!
1.YOLOv9原理介绍

论文: 2402.13616.pdf (arxiv.org)
代码:GitHub - WongKinYiu/yolov9: Implementation of paper - YOLOv9: Learning What You Want to Learn Using Programmable Gradient Information摘要: 如今的深度学习方法重点关注如何设计最合适的目标函数,从而使得模型的预测结果能够最接近真实情况。同时,必须设计一个适当的架构,可以帮助获取足够的信息进行预测。然而,现有方法忽略了一个事实,即当输入数据经过逐层特征提取和空间变换时,大量信息将会丢失。因此,YOLOv9 深入研究了数据通过深度网络传输时数据丢失的重要问题,即信息瓶颈和可逆函数。作者提出了可编程梯度信息(programmable gradient information,PGI)的概念,来应对深度网络实现多个目标所需要的各种变化。PGI 可以为目标任务计算目标函数提供完整的输入信息,从而获得可靠的梯度信息来更新网络权值。此外,研究者基于梯度路径规划设计了一种新的轻量级网络架构,即通用高效层聚合网络(Generalized Efficient Layer Aggregation Network,GELAN)。该架构证实了 PGI 可以在轻量级模型上取得优异的结果。研究者在基于 MS COCO 数据集的目标检测任务上验证所提出的 GELAN 和 PGI。结果表明,与其他 SOTA 方法相比,GELAN 仅使用传统卷积算子即可实现更好的参数利用率。对于 PGI 而言,它的适用性很强,可用于从轻型到大型的各种模型。我们可以用它来获取完整的信息,从而使从头开始训练的模型能够比使用大型数据集预训练的 SOTA 模型获得更好的结果。对比结果如图1所示。

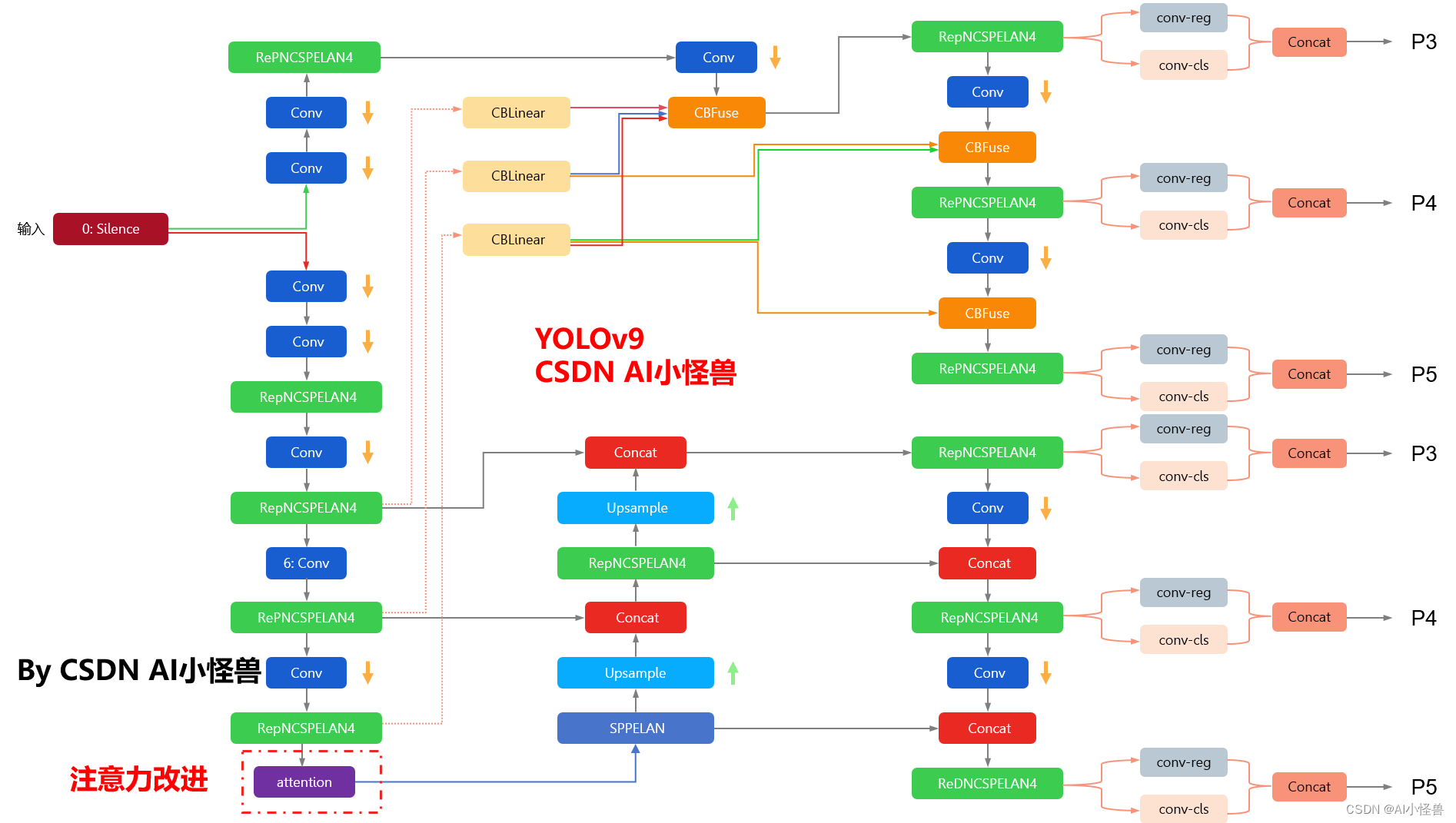
YOLOv9框架图
2.计算机视觉中的注意力机制
一般来说,注意力机制通常被分为以下基本四大类:
通道注意力 Channel Attention
空间注意力机制 Spatial Attention
时间注意力机制 Temporal Attention
分支注意力机制 Branch Attention
2.1.CBAM:通道注意力和空间注意力的集成者
轻量级的卷积注意力模块,它结合了通道和空间的注意力机制模块
论文题目:《CBAM: Convolutional Block Attention Module》
论文地址: https://arxiv.org/pdf/1807.06521.pdf
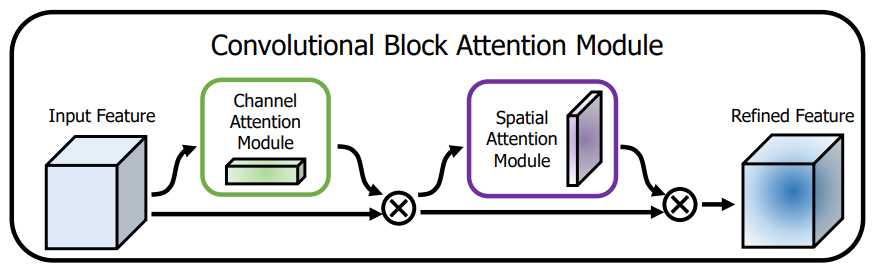
上图可以看到,CBAM包含CAM(Channel Attention Module)和SAM(Spartial Attention Module)两个子模块,分别进行通道和空间上的Attention。这样不只能够节约参数和计算力,并且保证了其能够做为即插即用的模块集成到现有的网络架构中去。
2.2 GAM:Global Attention Mechanism
超越CBAM,全新注意力GAM:不计成本提高精度!
论文题目:Global Attention Mechanism: Retain Information to Enhance Channel-Spatial Interactions
论文地址:https://paperswithcode.com/paper/global-attention-mechanism-retain-information
从整体上可以看出,GAM和CBAM注意力机制还是比较相似的,同样是使用了通道注意力机制和空间注意力机制。但是不同的是对通道注意力和空间注意力的处理。
3.CBAM、GAM加入到YOLOv9
3.1新建py文件,路径为models/attention/attention.py
import torch
from torch import nn
from torch.nn import init
import torch.nn.functional as F
class ChannelAttention(nn.Module):
# Channel-attention module https://github.com/open-mmlab/mmdetection/tree/v3.0.0rc1/configs/rtmdet
def __init__(self, channels: int) -> None:
super().__init__()
self.pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Conv2d(channels, channels, 1, 1, 0, bias=True)
self.act = nn.Sigmoid()
def forward(self, x: torch.Tensor) -> torch.Tensor:
return x * self.act(self.fc(self.pool(x)))
class SpatialAttention(nn.Module):
# Spatial-attention module
def __init__(self, kernel_size=7):
super().__init__()
assert kernel_size in (3, 7), 'kernel size must be 3 or 7'
padding = 3 if kernel_size == 7 else 1
self.cv1 = nn.Conv2d(2, 1, kernel_size, padding=padding, bias=False)
self.act = nn.Sigmoid()
def forward(self, x):
return x * self.act(self.cv1(torch.cat([torch.mean(x, 1, keepdim=True), torch.max(x, 1, keepdim=True)[0]], 1)))
class CBAM(nn.Module):
# Convolutional Block Attention Module
def __init__(self, c1,c2, kernel_size=7): # ch_in, kernels
super().__init__()
self.channel_attention = ChannelAttention(c2)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
return self.spatial_attention(self.channel_attention(x))
def channel_shuffle(x, groups=2): ##shuffle channel
# RESHAPE----->transpose------->Flatten
B, C, H, W = x.size()
out = x.view(B, groups, C // groups, H, W).permute(0, 2, 1, 3, 4).contiguous()
out = out.view(B, C, H, W)
return out
class GAM_Attention(nn.Module):
# https://paperswithcode.com/paper/global-attention-mechanism-retain-information
def __init__(self, c1, c2, group=True, rate=4):
super(GAM_Attention, self).__init__()
self.channel_attention = nn.Sequential(
nn.Linear(c1, int(c1 / rate)),
nn.ReLU(inplace=True),
nn.Linear(int(c1 / rate), c1)
)
self.spatial_attention = nn.Sequential(
nn.Conv2d(c1, c1 // rate, kernel_size=7, padding=3, groups=rate) if group else nn.Conv2d(c1, int(c1 / rate),
kernel_size=7,
padding=3),
nn.BatchNorm2d(int(c1 / rate)),
nn.ReLU(inplace=True),
nn.Conv2d(c1 // rate, c2, kernel_size=7, padding=3, groups=rate) if group else nn.Conv2d(int(c1 / rate), c2,
kernel_size=7,
padding=3),
nn.BatchNorm2d(c2)
)
def forward(self, x):
b, c, h, w = x.shape
x_permute = x.permute(0, 2, 3, 1).view(b, -1, c)
x_att_permute = self.channel_attention(x_permute).view(b, h, w, c)
x_channel_att = x_att_permute.permute(0, 3, 1, 2)
# x_channel_att=channel_shuffle(x_channel_att,4) #last shuffle
x = x * x_channel_att
x_spatial_att = self.spatial_attention(x).sigmoid()
x_spatial_att = channel_shuffle(x_spatial_att, 4) # last shuffle
out = x * x_spatial_att
# out=channel_shuffle(out,4) #last shuffle
return out3.2修改yolo.py
1)首先进行引用
from models.attention.attention import *2)修改def parse_model(d, ch): # model_dict, input_channels(3)
在源码基础上加入CBAM,GAM_Attention
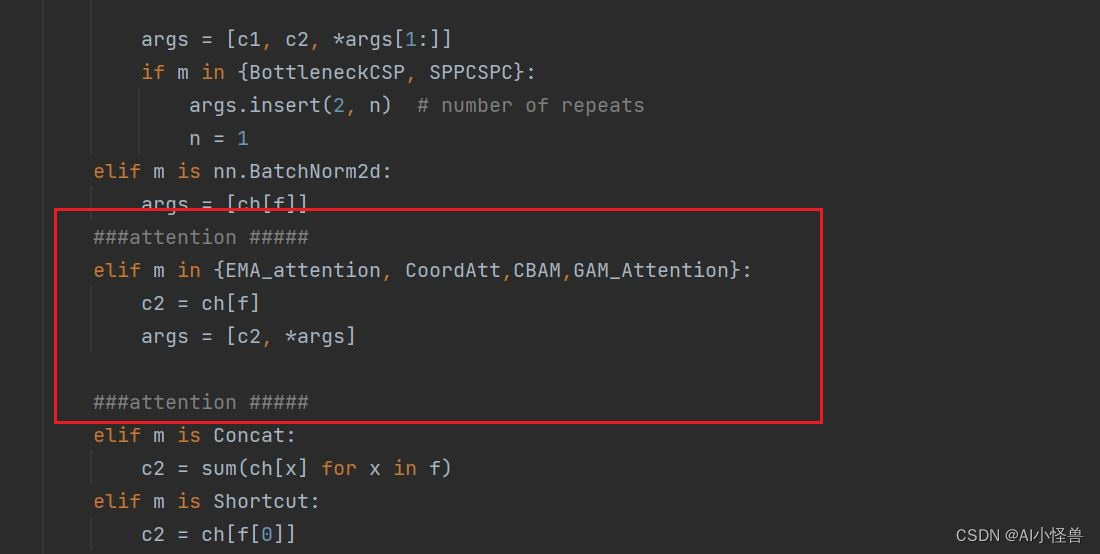
elif m is nn.BatchNorm2d:
args = [ch[f]]
###attention #####
elif m in {EMA_attention, CoordAtt,CBAM,GAM_Attention}:
c2 = ch[f]
args = [c2, *args]
###attention #####3.3 yolov9-c-CBAM.yaml
# YOLOv9
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
#activation: nn.LeakyReLU(0.1)
#activation: nn.ReLU()
# anchors
anchors: 3
# YOLOv9 backbone
backbone:
[
[-1, 1, Silence, []],
# conv down
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
# conv down
[-1, 1, Conv, [128, 3, 2]], # 2-P2/4
# elan-1 block
[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 3
# avg-conv down
[-1, 1, ADown, [256]], # 4-P3/8
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 5
# avg-conv down
[-1, 1, ADown, [512]], # 6-P4/16
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 7
# avg-conv down
[-1, 1, ADown, [512]], # 8-P5/32
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 9
[-1, 1, CBAM, [512]], # 10
]
# YOLOv9 head
head:
[
# elan-spp block
[-1, 1, SPPELAN, [512, 256]], # 11
# up-concat merge
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 7], 1, Concat, [1]], # cat backbone P4
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 14
# up-concat merge
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 5], 1, Concat, [1]], # cat backbone P3
# elan-2 block
[-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 17 (P3/8-small)
# avg-conv-down merge
[-1, 1, ADown, [256]],
[[-1, 14], 1, Concat, [1]], # cat head P4
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 20 (P4/16-medium)
# avg-conv-down merge
[-1, 1, ADown, [512]],
[[-1, 11], 1, Concat, [1]], # cat head P5
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 23 (P5/32-large)
# multi-level reversible auxiliary branch
# routing
[5, 1, CBLinear, [[256]]], # 24
[7, 1, CBLinear, [[256, 512]]], # 25
[9, 1, CBLinear, [[256, 512, 512]]], # 26
# conv down
[0, 1, Conv, [64, 3, 2]], # 27-P1/2
# conv down
[-1, 1, Conv, [128, 3, 2]], # 28-P2/4
# elan-1 block
[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 29
# avg-conv down fuse
[-1, 1, ADown, [256]], # 30-P3/8
[[24, 25, 26, -1], 1, CBFuse, [[0, 0, 0]]], # 31
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 32
# avg-conv down fuse
[-1, 1, ADown, [512]], # 33-P4/16
[[25, 26, -1], 1, CBFuse, [[1, 1]]], # 34
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 35
# avg-conv down fuse
[-1, 1, ADown, [512]], # 36-P5/32
[[26, -1], 1, CBFuse, [[2]]], # 37
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 38
# detection head
# detect
[[32, 35, 38, 17, 20, 23], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)
]3.4 yolov9-c-GAM.yaml
# YOLOv9
# parameters
nc: 80 # number of classes
depth_multiple: 1.0 # model depth multiple
width_multiple: 1.0 # layer channel multiple
#activation: nn.LeakyReLU(0.1)
#activation: nn.ReLU()
# anchors
anchors: 3
# YOLOv9 backbone
backbone:
[
[-1, 1, Silence, []],
# conv down
[-1, 1, Conv, [64, 3, 2]], # 1-P1/2
# conv down
[-1, 1, Conv, [128, 3, 2]], # 2-P2/4
# elan-1 block
[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 3
# avg-conv down
[-1, 1, ADown, [256]], # 4-P3/8
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 5
# avg-conv down
[-1, 1, ADown, [512]], # 6-P4/16
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 7
# avg-conv down
[-1, 1, ADown, [512]], # 8-P5/32
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 9
[-1, 1, GAM_Attention, [512]], # 10
]
# YOLOv9 head
head:
[
# elan-spp block
[-1, 1, SPPELAN, [512, 256]], # 11
# up-concat merge
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 7], 1, Concat, [1]], # cat backbone P4
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 14
# up-concat merge
[-1, 1, nn.Upsample, [None, 2, 'nearest']],
[[-1, 5], 1, Concat, [1]], # cat backbone P3
# elan-2 block
[-1, 1, RepNCSPELAN4, [256, 256, 128, 1]], # 17 (P3/8-small)
# avg-conv-down merge
[-1, 1, ADown, [256]],
[[-1, 14], 1, Concat, [1]], # cat head P4
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 20 (P4/16-medium)
# avg-conv-down merge
[-1, 1, ADown, [512]],
[[-1, 11], 1, Concat, [1]], # cat head P5
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 23 (P5/32-large)
# multi-level reversible auxiliary branch
# routing
[5, 1, CBLinear, [[256]]], # 24
[7, 1, CBLinear, [[256, 512]]], # 25
[9, 1, CBLinear, [[256, 512, 512]]], # 26
# conv down
[0, 1, Conv, [64, 3, 2]], # 27-P1/2
# conv down
[-1, 1, Conv, [128, 3, 2]], # 28-P2/4
# elan-1 block
[-1, 1, RepNCSPELAN4, [256, 128, 64, 1]], # 29
# avg-conv down fuse
[-1, 1, ADown, [256]], # 30-P3/8
[[24, 25, 26, -1], 1, CBFuse, [[0, 0, 0]]], # 31
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 256, 128, 1]], # 32
# avg-conv down fuse
[-1, 1, ADown, [512]], # 33-P4/16
[[25, 26, -1], 1, CBFuse, [[1, 1]]], # 34
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 35
# avg-conv down fuse
[-1, 1, ADown, [512]], # 36-P5/32
[[26, -1], 1, CBFuse, [[2]]], # 37
# elan-2 block
[-1, 1, RepNCSPELAN4, [512, 512, 256, 1]], # 38
# detection head
# detect
[[32, 35, 38, 17, 20, 23], 1, DualDDetect, [nc]], # DualDDetect(A3, A4, A5, P3, P4, P5)
]










![[SWPUCTF 2021 新生赛]crypto6](https://img-blog.csdnimg.cn/direct/ce04fa4cdc854df09a777c2b4326a3f3.png)