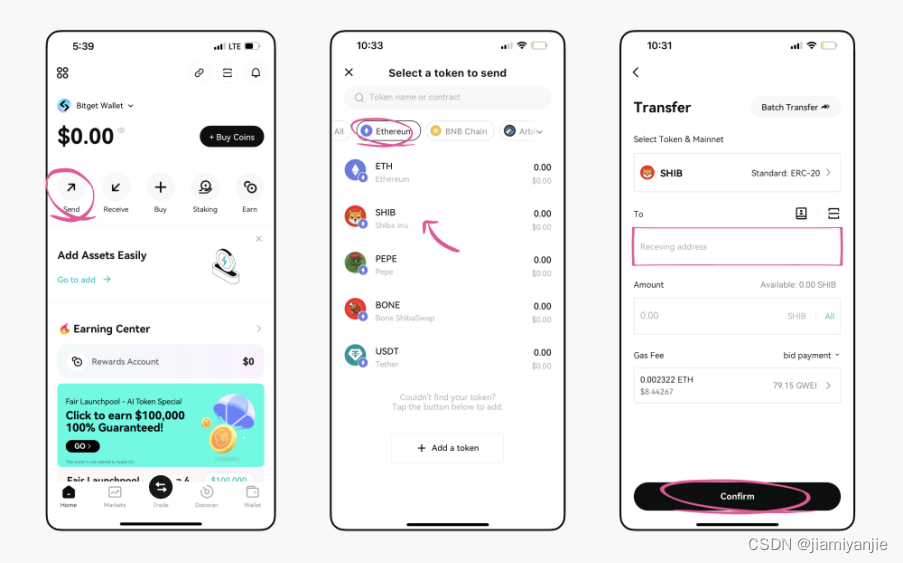
随着技术的不断发展,我们现在可以使用稳定扩散技术(Stable Diffusion)来生成同一角色但不同姿势的人脸图片。本文将介绍这一方法的具体步骤,以及如何通过合理的提示语和模型选择来生成出更加真实和多样化的人脸图像。
博客首发地址:用Stable Diffusion生成同角色不同pose的人脸 - 知乎
1.拼模版
首先,我们需要将同一个人的不同姿势的照片按照相应的姿势拼接在一起,形成一个模版。这样可以为后续的生成过程提供参考。

本照片用sd生成
2.获取轮廓
利用拼接好的模版图像,我们可以轻松地获取到人脸的轮廓信息,这对于后续的处理步骤至关重要。

3. 生成监督图
接下来,我们可以利用一些预训练好的模型,如 controlnet 中的 openpose 模型或 depth 模型,来生成对应的 pose 图或深度图。这些监督图将有助于我们更好地控制生成过程。


4.输入提示语生成图片
在生成过程中,我们可以选择使用 pose 图或深度图作为输入,并选择使用 canny 或 Lineart 这样的边缘检测技术。同时,结合合适的提示语,我们可以使用两个 controlnet 模型来生成图像。
5. 效果展示
接下来,让我们来展示一些使用 Stable Diffusion 生成的同角色不同 pose 的人脸图片,以展示其效果。

a girl, long hair, happy

a girl, short hair, happy

a girl, short hair, happy,be wearing glasses,

a girl,short hair, happy,he wore a mask over his mouth,

a girl,short hair, happy,wear sunglasses,

a girl,short hair, happy,wear sunglasses,(by the sea:1.1),

a girl,short hair,wear sunglasses,(in the mountainside:1.1),

old woman,short hair,laugh, wear sunglasses,(in the mountainside:1.1),
6. 进一步完善提示词
在生成过程中,选择合适的提示语对于生成结果的影响至关重要。我们可以通过尝试不同的提示词来进一步改善生成的图像质量和多样性。
7. 原理分析
在训练数据中,存在大量类似板式的数据,因此模型可能会默认为生成的所有人都具有相同的ID。需要对这一点进行注意和解释。
8.注意
注意不要将男性和女性的模版混用来生成图片,因为男女脸型有所区别,混用可能会影响生成的真实性。
最后,感谢每位朋友的陪伴,如果大家有疑问、见解,欢迎留言、讨论。您的点赞、关注是我持续分享的动力。APlayBoy,期待与您一起在AI的世界里不断成长!。