去模糊的3D高斯泼溅,看Demo比3D高斯更加精细,对场景物体细节的还原度更高,[官网](https://benhenryl.github.io/Deblurring-3D-Gaussian-Splatting/)
背景技术
Volumetric rendering-based nerual fields:NeRF.
Rasterization rendering: 3D-GS.
Rasterization比volumetric方法更加高效。
摘要
一种新的field-based的网络模型,实现对最新的rasterization rendering技术——3D高斯泼溅的去模糊。
设计MLP,对各个3D高斯的协方差建模;既能重建出优异、锐利的细节,又能保证实时渲染。
方法
一个MLP处理3D高斯模型,其输入包含视线方向向量
v
v
v,模型的位置
x
x
x、姿态
r
r
r、尺度系数
s
s
s,输出偏置量
δ
r
\delta r
δr,
δ
s
\delta s
δs,在训练时加入此MLP,实现模型变换,再渲染;推理时则直接渲染。如下图。
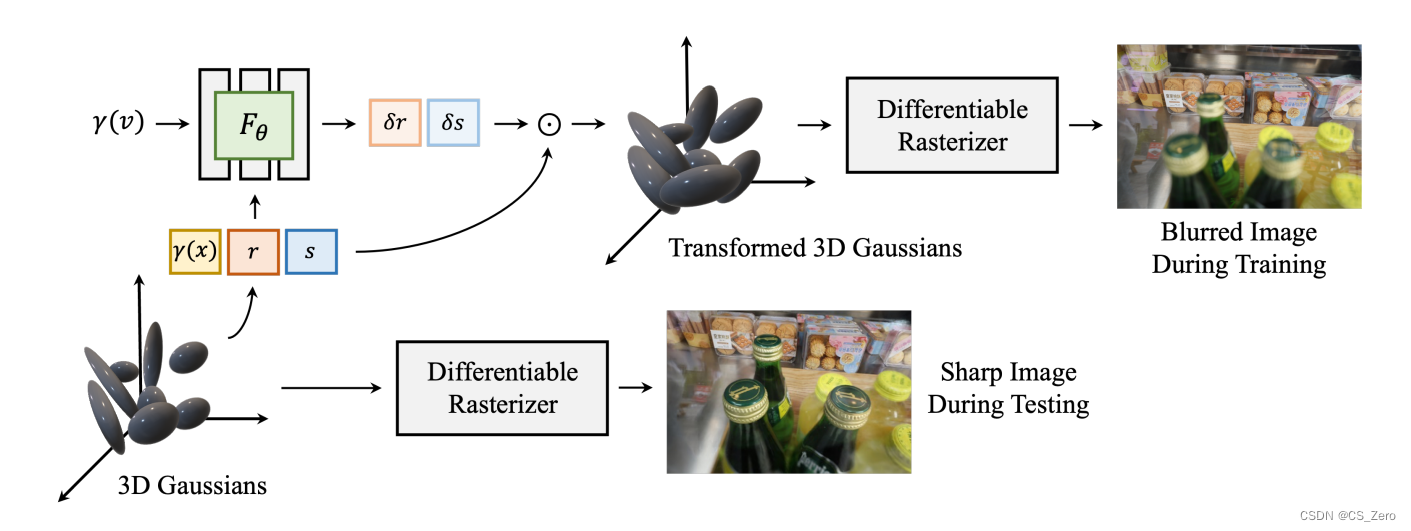
MLP输出的系数对应各个3D高斯,则能控制不同的3D高斯产生不同程度的模糊,即实现选择性模糊图像不同区域,不同程度;一个高斯卷积无法实现此种能力的。
问题的假设、解决方法的原理
原作者从模糊是由于理想图像的高斯卷积之结论,提出如下假设,
We assume that big sized 3D Gaussians cause the blur, while relatively smaller 3D Gaussians correspond
to the sharp image.
又根据
The minima of these scaling factors (δr, δs) are clipped to 1 and element-wisely
multiplied to r and s, respectively, to obtain the transformed attributes r′ = r · δr and s′ = s · δs.
为什么这样的设计,即在训练过程用MLP输出的系数放大3D高斯的协方差矩阵,即导致3D、图像更模糊,而在正常推理时,省去放大过程,则能实现去模糊的效果?
一种解释:
训练过程类似假性近视的人佩戴矫正眼镜,一般是凸透镜,人眼会看到比不戴眼镜时更模糊的图,人眼尽力调节使得摘下矫正眼镜后能看得更清楚。
原作者的实验结果符合预期,则论证了他们的假设是合理的。
实现细节
- 补偿稀疏点云
为解决SfM常常由于景深范围大、图像模糊而输出点云稀疏,论文设计增加 N p N_p Np个点,主要思路是在训练 N s t N_{st} Nst次后,对已有点云的bounding box内均匀取样,对每个新增点使用KNN获取相邻元素,以此给新点的颜色插值,并剔除距离最近点的距离大于阈值 t d t_d td的新点。
笔者认为可在SfM之后用MVS输出稠密点云。 - 管理3D高斯的数目
3D高斯泼溅原论文用单一的阈值剔除3D高斯,本参考论文使用因高而异的阈值,根据相对深度剔除较少的远端高斯,能更好地还原远端场景物体的细节。
实验结果
配置
- Pytorch实现
- MLP有3层隐藏层,每层64通道带ReLU,学习率lr = 1e-3
- 参数初始化方法Xavier
- 补偿点云的设置: N s t = 2500 N_{st} = 2500 Nst=2500, N p = 100000 N_p = 100000 Np=100000, K = 4 K = 4 K=4, t d = 10 t_d = 10 td=10
- 数据,Deblur-NeRF数据集,使用Blender合成模糊图像;用COLMAP求解原、模糊图像的位姿。在哪里获取点云?
结果
评测指标:峰值信噪比PSNR(衡量图像指标)、结构相似性SSIM(衡量图像相似性)、帧率FPS。
本文方法比参考方法Deblur-NeRF、DP-NeRF、PDRF、3D-Gussians,基本接近或取得SOTA精度,速度也接近SOTA。
思考
图像模糊主要有时空两个因素,时间维度上由于曝光时段,由于目标相对相机运动导致blur,空间上则是由于实际相机成像并非是理想针孔模型,光圈越大,则越不符合针孔模型,即物距与焦距越大,成像越模糊,参考论文的方法解决了消减这类模糊的问题。另一方面,更复杂的图像质量问题,还有眩光、 曝光过度或不足。