每当看到有人的简历上写着熟悉 tcp/ip, http 等协议时, 我就忍不住问问他们: 你给我说说, 端口是啥吧! 可惜, 很少有人能说得让人满意... 所以这次就来谈谈端口(port), 这个熟悉的陌生人.
在此过程中, 还会谈谈间接层, naming service 等概念, IoC, 依赖倒置等原则以及 TCP 协议的一些重点知识.
常见端口
在我们的日常开发过程中, 特别是后端的开发人员, 即便他没有真正理解端口的细节, 他还是会听过见过各类的端口, 这个东西几乎无处不在,
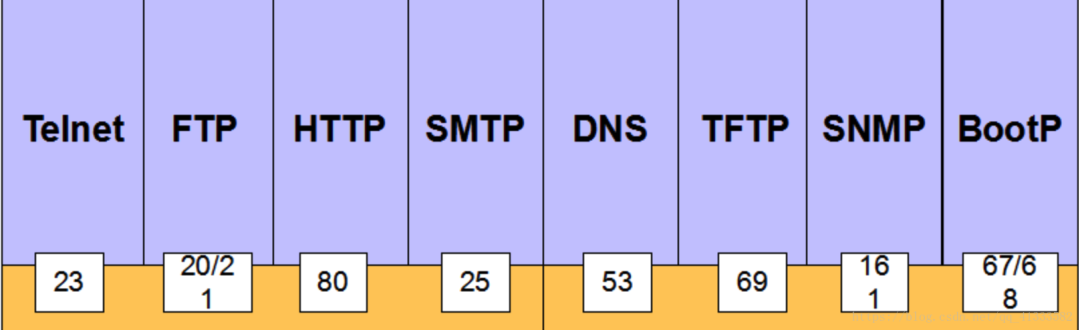
比如:
-
mysql 缺省用的 3306 端口,
-
redis 的 6379 端口,
-
tomcat 默认用的 8080 端口,
-
ssh 用的 22 端口,
-
等等...
当然我们最关注的还是 web 相关的端口, 涉及的主要为 80 和 443 两个端口, 下面就来重点说说.
端口是必须的吗?
在本地 web 开发调试过程中, 我们可能都碰到过端口, 比如或许是/最著名的 8080 端口, 一般我们会这样去访问本地的 web 程序:
localhost:8080
但一旦 web 程序部署到了正式的网站中, 端口似乎就消失了, 正式的网址中就不需要端口了吗? 答案是否定的, 在这里起作用的是缺省值.
比如你访问我的网站: https://xiaogd.net, 这个 url 中似乎没有端口, 但其实是有的, 它有一个默认值 443, 所以完整的形式实际是这样的:
https://xiaogd.net:443.
你可以通过 Chrome 的开发人员调试工具看到这一点:
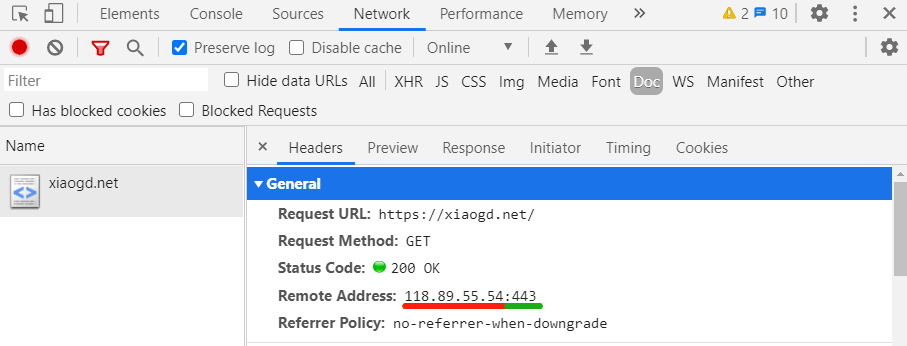
可以看到, ip 地址后面跟着一个 443
如果你输入一个错误的端口, 比如 80, 像这样: https://xiaogd.net:80, 结果就是无法访问.
但是如果你改成 http://xiaogd.net:80, 它又可以访问了.
注意, 因为我服务器后台配置了 http 自动跳转 https 的 301 重定向, 所以最终浏览器会再次跳转到 https://xiaogd.net:443.
注意勾选 'Preserve log' 以保留日志, 可以看到第一个 80 端口的请求会被响应一个 301 跳转, 并指示跳转目标, 也即是 Location 字段中的 https 请求, 浏览器接收此跳转指示并重新发起 https 请求, 也即是图中第二个 xiaogd.net 的请求. 所以地址栏最终还是会变成 https 的, 特此说明.
此时如果你输入 http://xiaogd.net:443, 它又不能访问了...
那么原因是什么呢? 你找到规律了没有?
注意一个是 http, 一个是 https.
协议的缺省端口
当你没有显式的在 url 中输入端口时, 浏览器实际上会根据所用的协议来为你指定一个缺省端口:
-
如果是 http 协议, 就使用 80 端口
-
如果是 https 协议, 就使用 443 端口
如果你自己输入端口呢? 那就用你输入的端口, 你输入啥就是啥, 输错了, 访问不了那就是你的责任了, 谁让你瞎搞来着?
本来不用你劳神的, 你偏要脱裤子放屁, 搞不好自然就是画蛇添足, 弄巧成拙了.
比如上面的用了 http 却输入了 443, 或者用了 https 却输入了 80, 就无法成功访问了.
另外, 如果你胡乱地输入一个比如 9527, http://xiaogd.net:9527, 自然也是无法访问的, 原因也很简单, 因为我的服务器上根本没有在 9527 端口上进行监听.
即便我有在 9527 端口上监听, 提供的也未必是 web 服务, 使用的协议可能既不是 http, 也不是 https, 所以你用浏览器试图去访问也可能会碰壁的.
当然了, 我是完全可以在服务器上的 9527 端口上再部署一个 web 服务的, 比如放一个 apache 或 tomcat server 之类的 web server 监听在那个端口上, 再放通防火墙, 安全组之类的, 也是可以访问的. 只是我没有这么去做而已.
那么为啥大家都不在那些奇奇怪怪的端口上提供 web 服务呢? 原因其实也很简单, 为了方便用户, 同时也减轻了用户的认知负担.
其实关于用户, 你只要记住两点就好了:
-
用户是傻瓜
-
用户是懒汉
深刻地理解了这一点, 你才可能成为一个好的程序员(包括但不限于产品经理, 设计师...)
其实呀, 何止了省略了端口呀, 你看看现在的地址栏, 不但 http, https 这些协议省了, 最末尾的斜杠 / 省了, 甚至连 www 都省了...
是的, 我也帮你们省了 www, 事实上你通过 https://www.xiaogd.net/ 也能访问到, 但如果通过 https://xiaogd.net/ 就能访问到, 又何苦去再去录入三个达不溜呢?
必须得承认, 缺省的存在是有很大的帮助的, 这其实是进步; 但另一方面, 这些缺省有时也会给不明就里的开发人员带来了一些困惑, 好像端口不是必要的, 但其实不是这样的.
为什么需要端口?
那为什么一定要端口这个东西呢? 它到底起了什么作用, 想必很多同学想要了解, 下面就来说说为什么, 而一个首先需要了解的概念就是进程间通讯(所谓的 IPC(inter-process communication)
进程间通讯(IPC)
你在浏览器地址栏输入某个网站的域名, 然后回车, 就生成了一次请求, 然后服务器响应你的请求, 浏览器再把结果渲染出来, 你就能最终看到到一个网页.
如果你曾经 ping 过一个域名, 比如你现在 ping 我的域名 xiaogd.net, 你就能得到一个 ip 地址, 118.89.55.54:
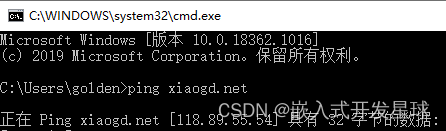
有了 ip, 浏览器自然就能找到我的主机, 但还是有个问题, 我的主机上运行着好多的进程, 好多的服务, 除了最常见的 web 服务, 我可能还有 ftp 服务, mysql 服务等等不一而足.
简单地讲, 如果一个请求只有 ip 地址这一信息, 操作系统将不知道把这个请求交给哪个进程去处理, 如果是你来设计整个系统, 你想象一下, 是不是这样?
如果你仅仅是输入域名, 经过 DNS 解析后, 只能得到一个 IP 地址.
所谓的一次请求, 从一个比较底层的角度去看, 就是一次进程间的通讯.
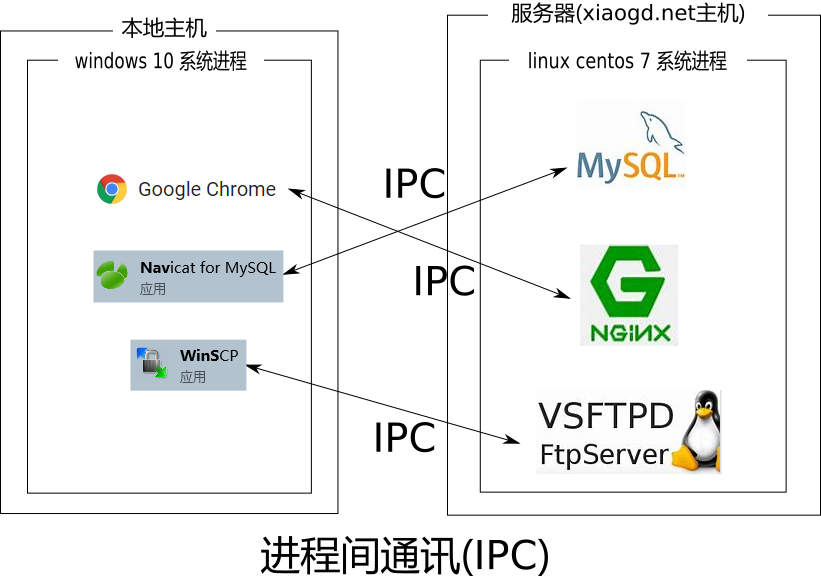
它可以是 navicat 客户端与 mysql 数据库服务的一次通讯, 也可以是 winScp 客户端与 vsftpd FTP 服务的一次通讯等等.
以上面的具体为例, 可以说就是 Chrome 浏览器这个本地操作系统上的进程与我的服务器上的一个叫做 Nginx 的进程间的一次通讯.
那么, 所谓的端口, 其实可以简单地视作为进程 ID.
当然, 它与进程 ID 还是有不同的, 下面再分析, 或者目前你可以认为端口就是进程 ID 的影子.
也即是说, 如果仅有域名(ip), 是无法定位到一个进程的, 通讯的发起方不但需要给出 ip, 还需要给出端口, 只有这样, 服务器才能知道由哪个进程去响应.
端口, 一个间接层
那么问题又来了, 为什么引入端口, 而不是直接使用进程 ID 呢? 这个原因想想也不难明白, 大概有这么几点原因:
-
作为客户端无法知道服务端对应进程的 ID
-
服务端对应进程重启后 ID 会改变
-
一个网站的 web 进程 ID 是这个, 另一个网站的可能又是另一个
自然, 原因是很多的, 我也是随便的列举了一些, 你或许还能想到更多. 而为了解决这些个问题, 就引入了端口这一间接层(indirection).
计算机世界里有一句名言: 任何计算机问题均可通过增加一个间接(indirection)层来解决.(Any problem in computer science can be solved with another layer of indirection. -- David Wheeler)
这个名言其实还有后面一句: But what usually will create another problem.(但通常会带来另一个问题)
这里所谓另一个问题, 比如它会使得层次结构复杂化, 交互效率下降等等. 当然了, 这就是架构师们要去权衡的问题了, 很多时候, 架构就是关于平衡的艺术. 打死都不肯引入任何的间接层, 这是一个极端; 而一上来就引入好多个间接层, 这又是另一个极端.
如果没有这个间接层, 客户端要与服务端通讯, 就要知道服务端对应进程的 ID, 也即是客户端是依赖于服务端的:
显然, 这种模式对于 web 这种一个服务端对应大量客户端访问的情形是极不适应的, 你都不知道有谁可能会来访问你的网站! 你根本无法告诉它们.
而有了端口这一间接层, 对于 web 的情形, 这种依赖被倒置了, 客户端总是把请求发送到 80(或443) 端口, 这些成为标准的一部分, 并要求服务端反过来去适应, 服务端去监听端口的通讯并处理, 变成了一种反向依赖.
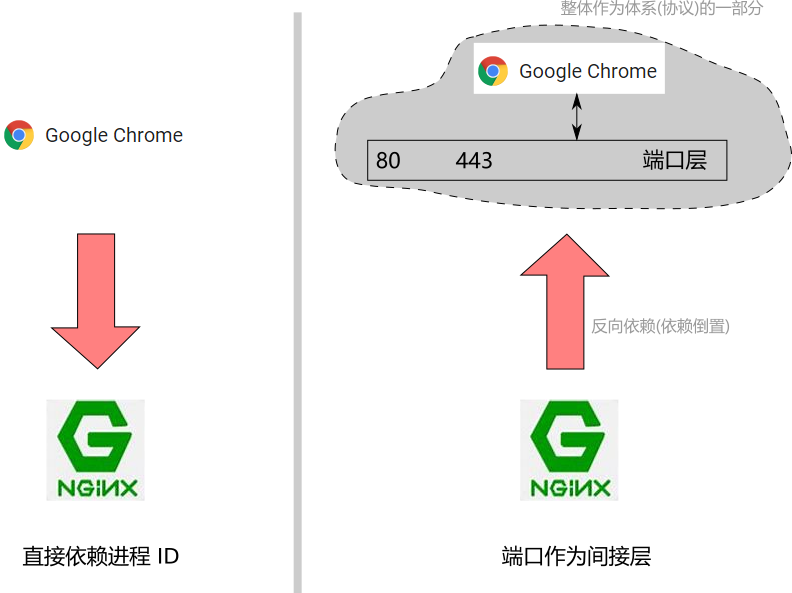
如果一个进程想要提供 web 服务, 它启动之后就要去绑定(binding) web 相关的端口,
如果端口已经被其它进程绑定了(即所谓占用了), 就会绑定失败; 又或者被自身前一个未完全退出的进程占据着, 也会绑定失败, 在开发过程中你可能会遇到类似的问题, 一个 web 进程没有关闭, 你又试图启动另一个, 而两者都用了相同的端口, 就会产生冲突.
并在其上持续的监听(listen), 同时在有请求到来的时候去响应(response). 这样一来, 进程 ID 的问题就消解了:
这类似于一个接口回调, 浏览器只需要面向接口索取服务, 而无需知道接口服务的具体提供者, 这些细节被端口层所封装并隐藏起来了.
端口这一间接层的存在解耦(decouple)了客户端与服务端之间的强依赖, 整个体系变得很灵活.
可以把端口视作一般编程概念中的接口(interface), 而想 Nginx, apache, tomcat 等等可以认为是这个接口的不同实现(Implementation).
端口与现实世界的一个类比
为加深理解, 可以举一个现实世界中的例子. 相信大家都有过去市民中心办事的经历, 比如去办理居住证, 护照, 社保等等业务, 你通常会收到一个小纸条让你去某个窗口办理对应业务, 这个窗口其实就类似于端口了:
比如 80 窗口就对应港澳台通行证业务
那么你要办港澳台通行证, 你就奔向 80 号窗口就完了. 你不要去问门口保卫处的王大爷, 到底是哪位同志办理这个业务.
今天可能是小明在办理, 隔了几天, 小明可能受伤了, 流血了, 又轮到小红在那里办理, 又过段时间, 小红也出意外了, 流产了, 又轮到小张在办理, 又过段时间, 小张被发现在办理业务过程中徇私舞弊, 流放了...
等等, 如果此时你的同事问你怎么办港澳台通行证, 你需要知道这些个人事变动的细节吗? 根本不需要呀, 你只需告诉他去 80 号窗口办理就好了...
市民中心的整个体系, 会确保有个会办理这些业务的人员坐在那个窗口下面, 你唯一需要做的, 就是到那个窗口下请求服务即可.
端口与名称服务(naming service)
通过上面现实世界类比的例子, 对于端口的机制, 相信你已经理解得比较深入了. 广义上讲, 端口层也可以视作一个 naming service(名称服务), 这与比如 spring cloud 中的 eureka 里的机制本质上是一样的, 只是这个 name 就是一个抽象的数字, 比如 80. 80 就代表了一个 web 服务, Nginx 之类的 web server 绑定并监听就相当于把自身提供的 web 服务注册于其上.
DNS 域名系统其实也是 naming service, 你通过 xiaogd.net 这个名字(name), 就能获取到我所提供给你的网页服务.
类似的还有 java 里的 JNDI 等, 把一个名字与一个服务关联起来, 比如一个名字就代表一个数据源(数据库连接)之类的.
端口与 IoC(控制反转)
广义上, 端口的上述机制也是控制反转(Ioc: Inversion of Control)思想的一种体现, 如果客户端需要知道服务端的进程 ID, 实际上就被服务端控制了, 毕竟我服务端在哪个 ID 上提供服务, 你就得把你的请求发到相应的 ID 上来;
而有了端口这一中间层呢? 作为客户端, 总是把请求发到对应端口上, 并要求服务端绑定并监听那些端口以及作出响应, 你服务端是反过来被我客户端所控制, 我客户端发到哪个端口, 你服务端就要去相应端口上监听并响应.
大家可以体会一下这种转变. 这种设计或思想在编程领域其实是特别重要的, 在很多其它地方都有体现.
因为浏览器总是把 web 请求发到了 80 或 443 端口, 这就要求一个 web server 进程去监听这些端口. 比如在我的服务器上, web server 是 Nginx, 它启动之后就会去监听 80 和 443 端口, 任何想要访问我的主页的人, 并不需要知道我的 Nginx 进程 ID 是啥, 借助于端口这一间接层, 你就能够与我的 Nginx 进程通讯, 并获取你想要的东西.
事实上你可以这么认为, 浏览器实际上只是在与端口通讯, 端口层再把这些请求委托(delegate)或代理(proxy)给相应的 web server 去处理, 端口的角色就是一个中间人, 一个间接层.
再论缺省端口
现在, 我们应该明白了, 端口是必要的了, 当然, 对最终的用户来说, 则不需要知道这些实现的细节, 对于他们, 应该遵循最小知识原则, 知道得越少越好.
如果你一定要让用户在输入 url 的过程中输入端口, 又或者要输入个 www 等等, 用户就要给你扔过来"十万个为什么"了...
为什么要加个 443?
为什么不是 334, 443是啥意思?
为什么一会儿是 80, 一会儿又是 443?
为什么加个 www, 啥意思?
为什么末尾还加个斜杠, 不加会死吗?
...
惹不起, 惹不起...
还记得前面说的, 用户是笨蛋, 用户是懒汉吗?
这里又要引用一句计算机世界的名言了: 程序员和上帝打赌要开发出更大更好连傻瓜都会用的软件, 而上帝却总能创造出更大更傻的傻瓜。目前为止,上帝赢了。
Programmers are in a race with the Universe to create bigger and better idiot-proof programs. The Universe is trying to create bigger and better idiots. So far the Universe is winning.
说句心里话, 很多时候, 用户能记住你的域名就阿弥陀佛了, 你就该烧高香了, 你还想用户记住你的端口, 真的想多了...
另一方面, 说到这里我们应该也能明白了, 那就是理论上, web 服务实际上可以构建在任何端口之上. 比如在本地开发的时候, 用户只有你自己, 那当然你可以随便挑一个端口, 比如 8080, 只要自己知道就好了或顶多告诉另一个与你配合的前端同事.
同理, 其它非 web 的服务, 比如 ftp 服务, 也不一定说非得在 21 端口上等等; mysql 服务的端口同样可以调整为 3306 之外的端口.
又或者说, 你想提供一个服务, 但只想小范围内的人知道, 你可以挑一个很偏门的端口, 这样一般人只输一个域名就没法访问到你的服务了.
比如有人想偷偷提供一些服务, 放一些广淫民群众喜闻乐见的小视频啥的...刑法警告, 后果自负!! 别说我没有提醒你.
端口与 TCP/UDP 协议
前面一直在说, 什么 3306 端口, 80 端口, 443 端口, 其实严格来说, 端口是分 TCP 端口和 UDP 端口的, 不过多数时候遇到的都是 TCP 端口, 但 TCP 80 端口和 UDP 80 端口是不同的端口.
UDP 的 80 端口, 包括 443 端口其实被保留了, 目前的 http 协议只构建在 TCP 协议之上.
当然, 理论上讲, 在 UDP 上构建 http 也不能说就完全不行, 毕竟, 无论 UDP 还是 TCP 都是构建在 IP 协议之上, 总之呢, 计算机的世界没什么是不可能的, 而且似乎真有人在做这些尝试, 不过这就属于两小母牛对屁股--比较牛逼的范畴了, 深水区了, 咱也不懂, 不多说了.
还有一点, 对于进程间的端口通讯, 实际上是对称的, 也即是说, 服务器的响应也是先回到一个客户端的端口上.
如果你用 Windows 10 系统, 可以在 任务管理器 > 性能 > 打开资源监视器 > 网络 > TCP 连接, 点击下远程端口可以按照从小到大排列, 通常就可以看到 443 的相关连接了, 可以看到左边有一栏本地端口, 一个 TCP 连接总是有一个远程端口, 一个本地端口:
当发起一个 TCP 连接时, 客户端首先自己先随机挑选一个没有被使用的端口作为服务器响应的接收端口, 比如 38672. 在一个 TCP 的包里, 无论是握手包还是后续的数据包, 包头部分最重要的两个字段, 一个就是源端口(source port), 比如 38672; 另一个就是目标端口(destination port), 比如 80, 或者 443.
可以这样看, 服务器的响应也是先回到源端口, 比如 38672 上, 源端口再转给最终的进程, 比如浏览器.
而对于一个 IP 包, 同样的, 包头部分最重要的两个字段, 一个就是源IP(source IP); 另一个就是目标 IP(destination IP).
而 TCP 包会作为 IP 包的数据包被打包到 IP 包里面, 也一个 IP 包里其实包含了 IP + 端口.
IP 加端口再加上端口与进程间的关联, 分属两个不同主机间的进程就能通过 TCP(UDP)/IP 协议愉快地进行进程间的通讯(IPC)了.
当然了, 同一个主机间的进程也同样可以利用这套机制. 但同一个主机间还可以有其它选择, 这个具体看各个操作系统是否提供相关机制及支持. 而 TCP/IP 属于广泛应用的标准协议, 从而得到了广泛支持.
因为篇幅关系, 关于这样 TCP 协议等的细节, 以及包括 Socket, 连接等概念, 以及虚拟主机, 反向代理等等就不再展开去说, 如果你感兴趣, 欢迎留言, 后续会考虑再写一些文章去介绍.
同样因为篇幅的原因以及同时我也不是计算机网络及协议方面的专家, 关于端口方面的, 如果有什么说得不到位, 或不正确的地方, 欢迎留言指正, 关于端口方面的介绍就到这里.