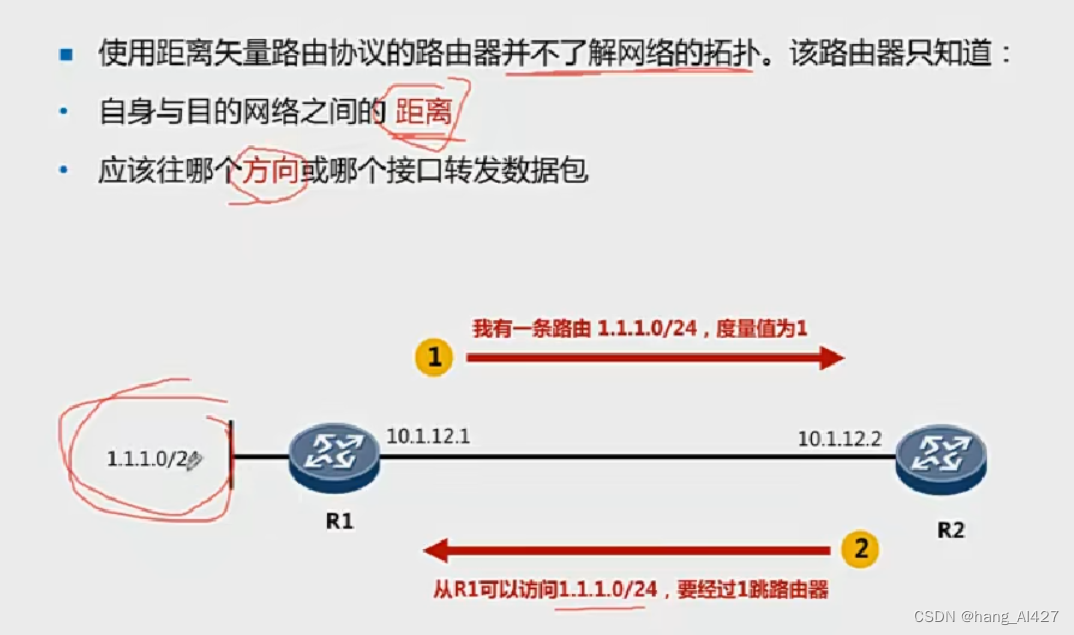
在实际开发中,发现打印Python打印经常出现乱码,大部分都是编码引起,这里只是简单说一下utf-8/ gbk/ unicode编码之间的相互转换问题:
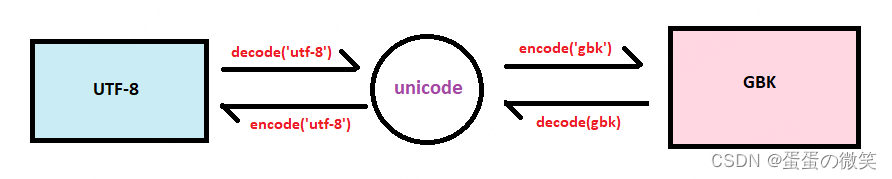
utf-8是Unix下的一种通用编码,gbk是win环境下的一种汉字编码,unicode是一种二进制编码,所有的utf-8和gbk编码都得通过unicode编码进行转码如图:
首先,我们可以查看自己的字符串是什么编码格式:
注意:在Python3 中,需要将strTest转换成二进制,再获取编码格式;而在2.x时,不需要转换,之接传入:print chardet.detect(strTest)
import chardet
strTest = "这是一个测试用例"
print(chardet.detect(str_test.encode()))得到输出结果:

然后根据你的需要转码:如 xxx.decode('utf-8').encode('gbk')
python中有两个函数 decode() 和 encode()
decode(‘utf-8’) 是从utf-8编码转换成unicode编码,当然括号里也可以写'gbk'
encode('gbk') 是将unicode编码编译成gbk编码,当然括号里也可以写'utf-8'
str_to_gbk = str_test.encode('gbk')
print(chardet.detect(str_to_gbk))![]()
另外,有些时候,我们输出打印时,会出现中文打印是 \uxxx 等,可以试试以下代码:
xxx.encode('utf-8').decode('unicode_escape')