【算法】一类支持向量机OC-SVM(2)
- 前言
- 纠正内容
- 数据集创建方式
- 适应度函数
- 新增内容
- 散点图示例
- 模型散点图展示
前言
在上则博文【算法】一类支持向量机OC-SVM(1) 中,我们提及到了蜂群算法优化一类支持向量机超参数模型,采用的适应度函数是r方,用的python 自带的 r2_score 模块,后来想想,不太合适,效果不佳,索性简单粗暴,直接比较分类正确的数量,然后进行适应度判断。同时,增加散点图分布来提高查阅效果。基于以上情况,对编写过程进行一个记录,方便后续同样情况的适用。
纠正内容
数据集创建方式
在优化后的模型中,数据集不再用make_blobs自动生成,采用excel 导入的形式展开。
orignal = pd.read_excel('C:/Users/11003189/Desktop/py/data.xlsx', sheet_name='点') # 读取数据
print(orignal)
col =['X','Y']
col1 =['Unnamed: 3']
data =orignal[col]
target =orignal[col1]
array =target.to_numpy()
这里有一个问题,输出导入的excel 数据,选取其中的列,它的输出格式如下所示:

这并不是数组,这个要明确,否则编写代码时候会有问题。
通过to_numpy对一列数据进行数组转换,它并不会变成一维数组,而是如下所示:
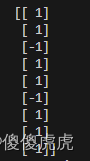
因此在数据读取时应该时a[index][0]。
适应度函数
将预测的分类结果与真实的分类结果进行比较,然后统计预测正确的个数,并进行适应度返回。
# 适应度函数
def fitness_function(params):
# 选取X_train 为正类
# X_train, X_test, _, y_test = train_test_split(X, y, test_size=0.3, random_state=42)
# y_test = np.where(y_test == 0, -1, 1) # 将标签转换为-1和1
nu = params['nu']
kernel = params['kernel']
gamma = params['gamma']
# 创建和训练One-Class SVM模型
ocsvm = OneClassSVM(nu=nu, kernel=kernel, gamma=gamma)
# ocsvm.fit(X_train)
ocsvm.fit(data,target)
# 预测测试集并计算ROC AUC分数作为适应度值
# y_pred = ocsvm.predict(X_test)
predictions = ocsvm.predict(data)
# fitness =r2_score(y_test, y_pred)
count =0
for index, element in enumerate(predictions):
if(element ==array[index][0]):
count=count+1
return count
# return fitness
新增内容
散点图示例
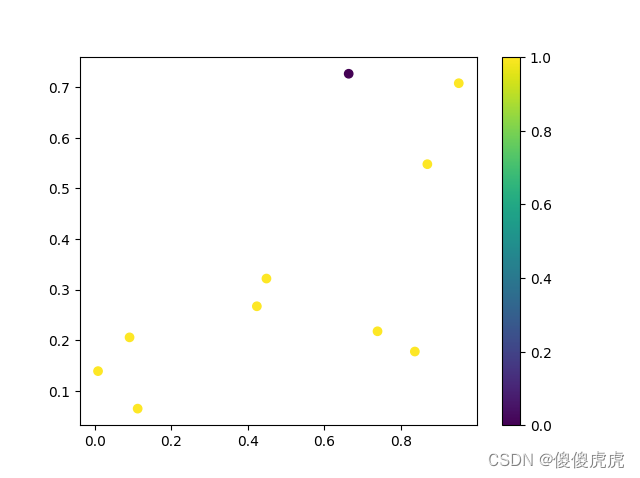
跟前面博文画折线图用的模块一样,也是pyplot,只不过用的是scatter方法,示例代码如下:
import matplotlib.pyplot as plt
import numpy as np
import time
# 生成数据
x = np.random.rand(10)
y = np.random.rand(10)
# colors = np.random.rand(10)
colors =[1,0,1,1,1,1,1,1,1,1]# 0黑色 1亮色
#colors =['#FFFFFF','#FFFFFF','#FFFFFF','#FFFFFF','#FFFFFF','#FFFFFF','#FFFFFF','#FFFFFF','#FFFFFF','#000000']# 0黑色 1亮色
print(colors)
fig, ax = plt.subplots()
scatter = ax.scatter(x, y, c=colors)
plt.colorbar(scatter) # 显示颜色条
# 动态更新颜色
# for i in range(10):
# colors = np.random.rand(10)
# scatter.set_facecolors(plt.cm.viridis(colors)) # 使用viridis colormap
# plt.draw()
# time.sleep(0.5) # 等待0.5秒
# plt.savefig('test5.png')
plt.show()
- 其中
colors的赋值,可以是直接用颜色的RGB 十六进制,也可以用0-1中的数值来指代,只不过1是黄色,0是黑色。
效果图如图所示:
模型散点图展示
在模型中增加散点图也是一样的编写,在资源绑定中提供的代码,里面包括预测数据的生成图和真实数据的生成图,xy分别表示2个特征值,点的颜色以正例和负例进行区分,负例黑色,正例黄色。同时也用plt.savefig('predictions.png')进行图片的保存,但建议这里保存路径用绝对路径,相对路径有时候会找不到,得全局搜寻。
路径编写时,斜杠/和反斜杠\不同,可以参考大佬python中关于\和/的使用说明介绍
plt.savefig('C:/Users/11003189/Desktop/py/test5.png')
plt.savefig(r'C:\Users\11003189\Desktop\py\test5.png')
plt.savefig('C:\\Users\\11003189\\Desktop\\py\\test5.png')

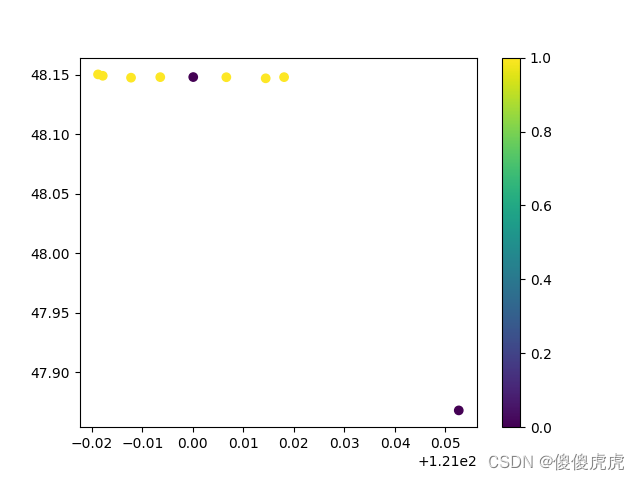
这里图片主要是展示一个效果,数据集的相关性和优化效果都没进行考虑,为了方便输出,迭代次数和种群都是按照最小的配置,因此图片效果不佳。但不影响代码的适用性,可根据需要进行数据集替换和相关超参数范围的选取。