异常检测方法通常可分为使用参数的方法和基于距离的方法。
1. 使用参数的异常检测方法
1.1 基础理论
使用参数的异常检测方法基于假设数据符合特定的分布(如高斯分布、二项分布)或模型(如混合模型)。这些方法通常通过对数据进行建模,确定正常数据的边界,将不符合模型的数据视为异常。
1.2 典型方法
高斯混合模型(Gaussian Mixture Model,GMM)、正态分布、概率密度估计等。
1.3 原理
模型建立:使用参数方法会对数据进行分布拟合或模型训练,得出数据的概率分布或模型参数。
异常判定:基于模型或分布,采用统计方法计算数据点与模型之间的偏差或概率,将超出阈值的数据点识别为异常值。
1.4 特点
适用性:对于符合特定分布假设的数据集效果较好,但对非正态分布的数据可能不够灵活。
参数需求:需要指定模型参数或假设数据分布,可能需要对数据进行预处理以满足分布假设。
1.5 实验结果
优点:当数据符合模型假设时,参数方法通常能够较好地识别异常点。
局限性:对于复杂数据或多模态数据效果较差,可能过度拟合正常数据分布,导致对异常点的辨识能力下降。
2. 基于距离的异常检测方法
2.1 基本理论
基于距离的方法不需要对数据分布做出假设,而是通过计算数据点之间的距离来识别异常值。
2.2 典型方法
k 最近邻算法、LOF(局部异常因子)、孤立森林等
2.3 原理
距离计算:基于距离的方法通过计算数据点与其周围点之间的距离,探测数据点的离群程度。
异常度量:根据数据点与其邻近点之间的距离或密度来评估其异常性,距离较远或密度较低的点可能被认为是异常值。
2.4 特点
适用性:适用于各种类型的数据分布,对多模态数据和非线性数据有较好的适应性。
参数需求:相比使用参数方法,通常不需要事先假设数据的分布情况。
2.5 实验结果
优点:相对于使用参数的方法,基于距离的方法在处理非典型数据分布时表现更好,能够捕获数据集中的局部异常点。
局限性:在高维空间下,距离计算可能变得复杂且容易受到噪声影响。
3. 马氏距离
是一种用于衡量数据集中样本之间差异性的指标,考虑了数据集的协方差结构和各个特征之间的相关性。

3.1 优点
考虑特征之间的相关性: 马氏距离考虑了各个特征之间的相关性和协方差矩阵,因此可以更好地反映数据的真实分布情况。
适用于高维数据: 在高维数据情况下,考虑到了不同维度之间的相关性,可以更好地度量样本之间的距离。
有效地处理异常值: 由于考虑了协方差结构,因此对于异常值的影响较小,更能反映正常数据点之间的相对位置。
3.2 缺点
对数据分布的假设: 马氏距离假设数据服从多元正态分布,当数据不符合此假设时,可能导致距离计算不准确。
计算复杂度高: 当特征维度较高时,涉及协方差矩阵的计算和求逆,可能会导致计算复杂度的增加。
对协方差矩阵估计的敏感性: 协方差矩阵的估计可能受到样本量的影响,在样本量较小或不足以准确估计协方差时,可能导致距离计算不准确。
3.3 适用场景
异常检测: 马氏距离在异常检测中被广泛应用,特别是在多元数据分析中,可以识别样本点是否与其他样本不同。
模式识别: 在模式识别领域中,用于分类、聚类和特征选择等任务。
数据降维: 马氏距离在特征选择和降维方面具有一定作用,可以消除冗余特征和减少数据维度。
总的来说,马氏距离适用于需要考虑特征之间相关性以及异常值对距离影响的场景,但在使用时需要注意对数据分布的假设以及计算复杂度。
3.4 与欧式距离的对比
欧式距离(Euclidean Distance)特点
欧式距离是最常见的距离度量方式,它衡量的是数据空间中两点之间的直线距离。
对于n维空间中的两个点x和y,其欧式距离为√((x₁ - y₁)² + (x₂ - y₂)² + ... + (xₙ - yₙ)²)。
特点:
- 简单易懂,计算容易;
- 适用于特征空间是欧式空间的情况;
- 对离群点敏感。
马氏距离(Mahalanobis Distance)特点
马氏距离考虑了特征之间的协方差,因此它是一种基于协方差矩阵的度量方式。它可以消除特征之间相关性和不同尺度带来的影响。
对于具有协方差矩阵S的n维空间中的两个点x和y,其马氏距离为√((x - y)ᵀS⁻¹(x - y))。
特点:
- 考虑了特征之间的相关性和不同尺度,对数据进行了更有效的度量;
- 在特征之间存在相关性或者不同尺度时,更加合适;
- 对离群点的影响较小,能够有效处理数据的异常值。
对比
适用性: 欧式距离适用于特征空间是欧式空间的情况,而马氏距离适用于特征之间存在相关性或不同尺度的情况。
稳健性: 马氏距离相对于离群值更加稳健,而欧式距离对离群值更加敏感。
计算方式: 欧式距离更简单直接,而马氏距离需要计算协方差矩阵的逆。
在选择使用哪种距离度量方法时,需要根据数据特点和分析任务的要求进行考量。如果特征之间存在相关性或者不同尺度,可能更适合使用马氏距离。否则,欧式距离可能会是一个更简单且有效的选择。
3.5 代码实例
from numpy.linalg import inv
X = delta.values
S = covValue.values
for i in range(3):#对每个特征进行中心化操作,即减去均值
X[:,i] = X[:,i] - meanValue[i]
def mahalanobis(row):#定义了计算马氏距离的函数
return np.matmul(row,S).dot(row)
anomaly_score = np.apply_along_axis( mahalanobis, axis=1, arr=X)#计算每个数据点的马氏距离
#可视化
fig = plt.figure(figsize=(10,6))
ax = fig.add_subplot(111, projection='3d')
p = ax.scatter(delta.MSFT,delta.F,delta.BAC,c=anomaly_score,cmap='jet')
ax.set_xlabel('Microsoft')
ax.set_ylabel('Ford')
ax.set_zlabel('Bank of America')
fig.colorbar(p)
plt.show()
前2个异常在上图中显示为棕点。 最高的异常对应于所有3只股票的价格显着上涨的当天,而第二高的异常对应于所有3只股票的收盘价格下跌很大的一天。 我们可以检查与前2个最高异常分数相关的日期,如下所示。
anom = pd.DataFrame(anomaly_score, index=delta.index, columns=['Anomaly score'])
result = pd.concat((delta,anom), axis=1)
result.nlargest(2,'Anomaly score')
#将马氏距离异常检测的结果与原始数据合并,并找出其中具有最高异常检测得分的两个数据点 
fig, (ax1,ax2) = plt.subplots(nrows=1, ncols=2, figsize=(15,6))
ts = delta[440:447]
ts.plot.line(ax=ax1)
ax1.set_xticks(range(7))
ax1.set_xticklabels(ts.index)
ax1.set_ylabel('Percent Change')
ts = delta[568:575]
ts.plot.line(ax=ax2)
ax2.set_xticks(range(7))
ax2.set_xticklabels(ts.index)
ax2.set_ylabel('Percent Change')
所以“所有3只股票的收盘价格下跌”是在2008年10月7日出现的
通过网络搜索等方式分析为何当时出现了“所有3只股票的收盘价格下跌”的情况
金融危机影响: 2008年金融危机是全球范围内金融市场的一次大幅震荡,导致了股票市场的崩溃。10月7日可能是金融危机期间股票市场持续下跌的一天。
宏观经济数据: 可能有发布的宏观经济数据(如失业率、国内生产总值、通货膨胀率等)或其他经济因素对市场情绪产生了负面影响,导致了股票价格整体下跌。
公司特定消息: 三家公司可能在这一天发布了负面消息,例如业绩下滑、产品问题、法律诉讼等,导致投资者对这些公司的信心下降,股票价格下跌。
全球市场走势: 除了公司特定消息外,全球股票市场的走势也会对股票价格产生影响。全球性的不确定性或负面消息可能导致整体市场下跌。
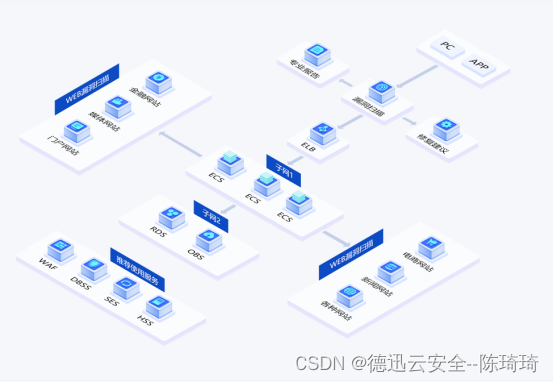
4. 基于距离的异常检测方法/实例
这是一种无需模型(model-free)的异常检测方法,因为它不需要构造正常数据的显式模型来确定数据实例的异常评分。
下面显示的示例代码采用k最近邻方法来计算异常分数。具体而言,正常实例预计与其第k个最近邻居的距离较小,而异常可能与其第k个最近邻居的距离较大。
在下面的示例中,我们应用基于距离的方法(k = 4)从上一节中描述的股市数据中识别异常交易日。
from sklearn.neighbors import NearestNeighbors
import numpy as np
from scipy.spatial import distance
knn = 4
nbrs = NearestNeighbors(n_neighbors=knn, metric=distance.euclidean).fit(delta.values)
distances, indices = nbrs.kneighbors(delta.values)
anomaly_score = distances[:,knn-1]
fig = plt.figure(figsize=(10,6))
ax = fig.add_subplot(111, projection='3d')
p = ax.scatter(delta.MSFT,delta.F,delta.BAC,c=anomaly_score,cmap='jet')
ax.set_xlabel('Microsoft')
ax.set_ylabel('Ford')
ax.set_zlabel('Bank of America')
fig.colorbar(p)
plt.show()
由于我们使用欧几里德距离(而不是马氏距离)来检测异常,所以结果与前面显示的结果略有不同。
对癌症据集“breast-cancer-wisconsin.data”中的一个或者多个维度进行基于距离的异常方法,并简述你的观察结果与相关分析
import pandas as pd
data = pd.read_csv("D:\\数据挖掘\\实验4 异常检测 代码与数据\\breast-cancer-wisconsin.data", header='infer' )
data.index = stocks['Date']
data = stocks.drop(['Date'],axis=1)
data.head()
import numpy as np
N,d = data.shape
data_af = pd.DataFrame(100*np.divide(data.iloc[1:,:].values-data.iloc[:N-1,:].values, data.iloc[:N-1,:].values),
columns=data.columns, index=data.iloc[1:].index)
delta.head()
from sklearn.neighbors import NearestNeighbors
import numpy as np
from scipy.spatial import distance
knn = 4
nbrs = NearestNeighbors(n_neighbors=knn, metric=distance.euclidean).fit(data_af.values)
distances, indices = nbrs.kneighbors(data_af.values)
anomaly_score = distances[:,knn-1]
fig = plt.figure(figsize=(10,6))
ax = fig.add_subplot(111, projection='3d')
p = ax.scatter(delta.MSFT,delta.F,delta.BAC,c=anomaly_score,cmap='jet')
ax.set_xlabel('Microsoft')
ax.set_ylabel('Ford')
ax.set_zlabel('Bank of America')
fig.colorbar(p)
plt.show()