背景:生产环境由于堆内存较大,fullgc 垃圾回收导致程序卡顿问题(假死)
目录
一、程序卡顿导致的影响
- 前端页面空白
- 后端数据重复
二、解决方法
- 降低堆内存大小
- 使用合适的垃圾回收器(可以尝试,还未进行测试)
- 对Survivor区的解读
三、使用到的工具等
- jvisualvm
- jstat
总结
- 花时间测试,寻找答案
- 调整Xmx降低回收时延时
- jvm调优是下下策
一、程序卡顿导致的影响:
- 前端页面空白。如前端页面刷新时无数据(显示空白页,影响他人使用)
- 后端数据重复。卡顿导致数据重复插入(卡顿导致线程等待,在垃圾回收完成后执行,重启线程,重复插入数据)
注:2中提到的重复插入数据目前还没有想到有效的方法进行测试
二、解决方法
- 降低堆内存大小
注:降至fullgc回收内存空间产生的卡顿不影响程序正常运行(也就是能够从jvisual监视页面上看不出堆监控曲线会出现卡顿的现象) - 使用合适的垃圾回收器(可以尝试,还未进行测试)
注:jdk8 默认使用并行回收器 -XX:+UseParallelGC并行回收会导致线程卡顿,目前发现,卡顿效果明显的场景发生在堆内存大小超5G的情况下发生,当调整 -Xmx4g -XX:NewRatio=3 的配置后,并没有再发现卡顿的情况
注:也可以使用并发垃圾回收器G1(Garbage-First)。这个回收器是充分利用cpu时间片的方式将回收时卡顿的情况尽可能的减少。但目前还没有对他进行使用。如果PG仍然会出现问题,将对此款回收器进行测试。
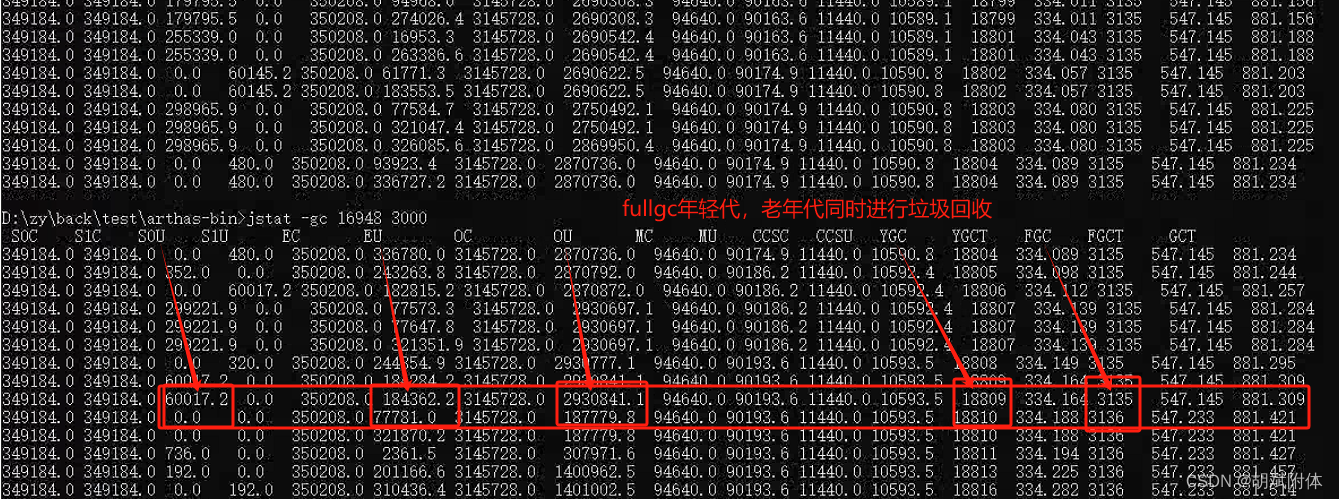
图注:CPU监视图中CUP利用率高的部分是由于每次Fullgc时引起的,因为全局垃圾回回收(fullgc)会产生并行线程计算清除无用的内存垃圾。会发生资源竞争的情况

注:年轻代与老年代同时进行垃圾回收.
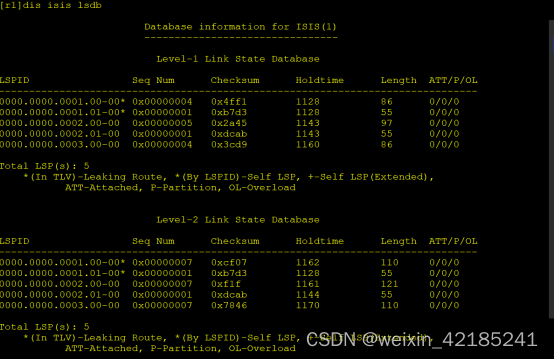
注:图片中S0U, EU, OU, YGC, FGC 分别是fullgc垃圾回收是监测到的结果。列名意思分别是Survivor0区已使用内存大小、Egen区已使用内存大小,老年代已使用内存大小,年轻代垃圾回收次数,老年代垃圾回收次数。
注:结果中S0U, EU, OU 的内存使用大小被减少,如S0U的 60017.2 减小至0等
注:结果中YGC, FGC 的GC次数加一
jstat -gc <pid> <时间/毫秒>
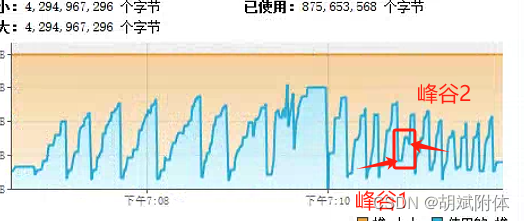
- 对Survivor区的解读
注:survior是存活之意,相比与Egen区就是出生后经过Egen区的垃圾回收后留存下来的对象会被保存到Survivor区。在监视上看到的情况会是垃圾回收后的峰谷要比上一个峰谷海拔要高,是因为有对象存活了下来
三、使用到的工具等
- jvisualvm
使用的jdk8中bin目录下的exe程序 - jstat
jstat -gc <pid> <时间/毫秒>
总结
1. 花时间测试,寻找答案。
jvm的调优需要花时间进行测试,这其中要找对监测工具,正确使用监测命令和读懂监测命令打印出的指标内容是个关键。
2. 调整Xmx降低回收时延时。
1). jstat打印的指标内容中,S与E区处于年轻代, O区是老年代,通过监控发现,垃圾回收当EU大小1G左右并伴随老年代OU进行垃圾回收时就会出现时长20秒左右的假死(应用程序卡顿)。
2). 通过调整Xmx的大小,由5g 降至 4g情况明显好转,现在便没有再反馈由于卡顿导致的问题
3. jvm调优是下下策。
如果能减少对程序产生的短生命周期,jvm如果运行正常,参数也可以不进行设置,除非像我这种情况有特定的应用场景。