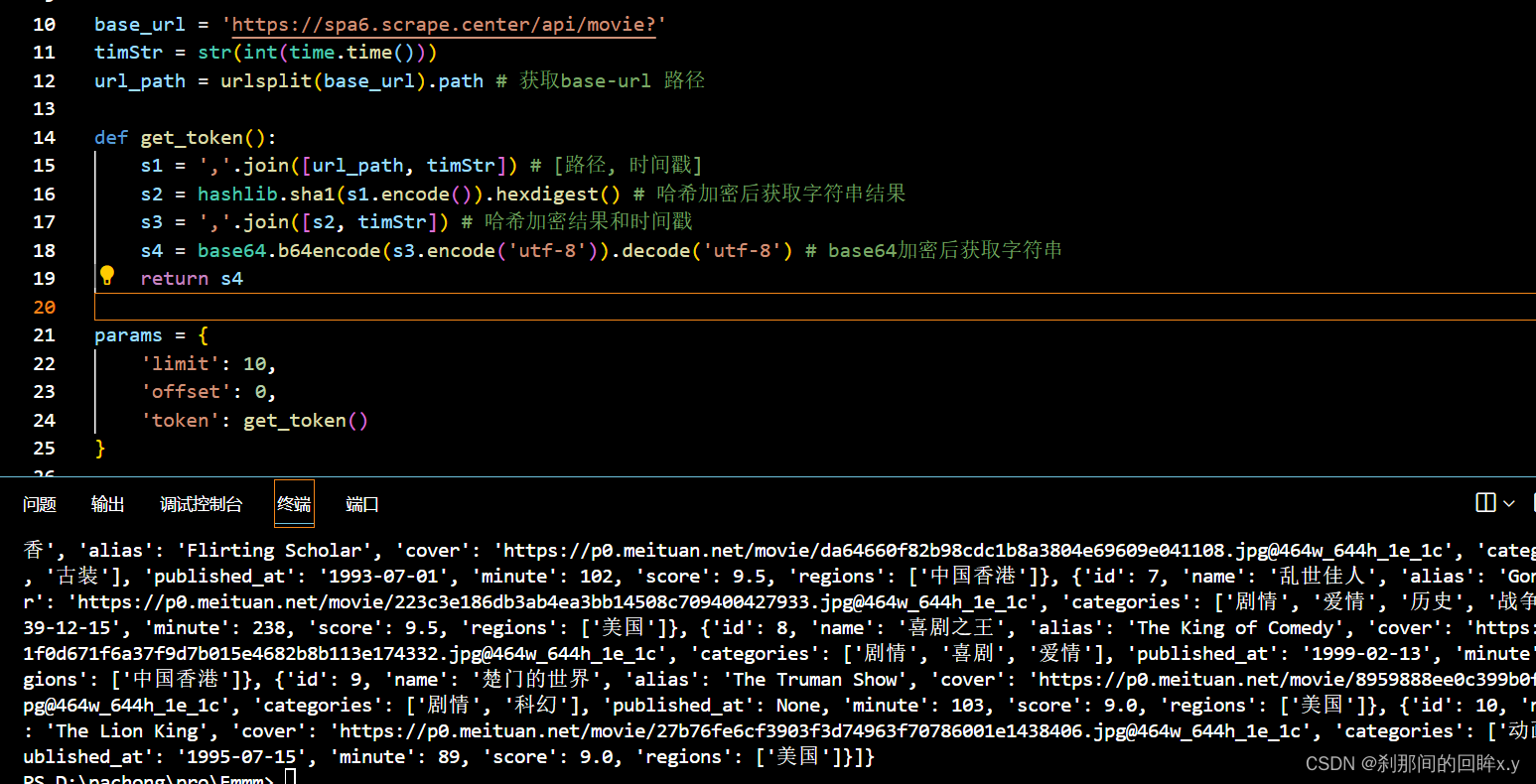
通过get请求直接获取电影信息
目标页面: https://spa6.scrape.center/

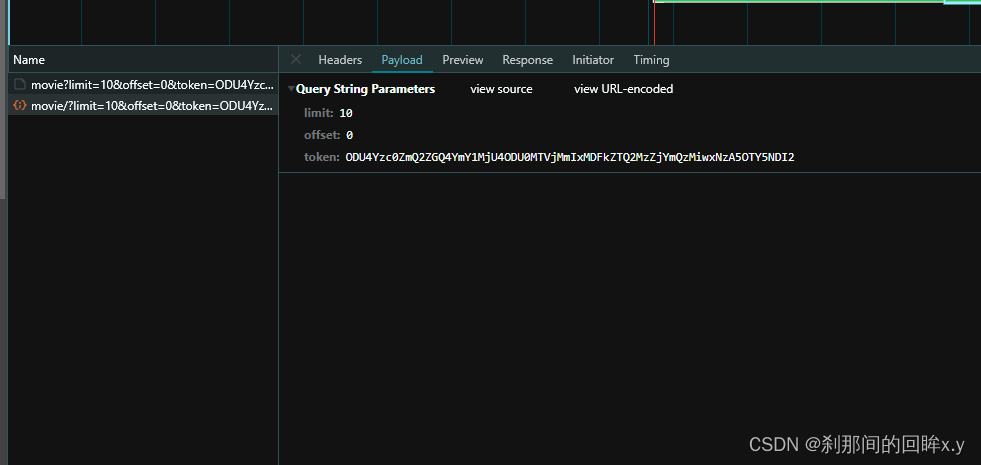
在network中可以看到是通过Ajax发送的请求,这个请求在postman中也可以直接请求成功,这只是一个用来练习爬虫的,没有达到js逆向的过程,需要通过分析js 代码来获取到token的值,
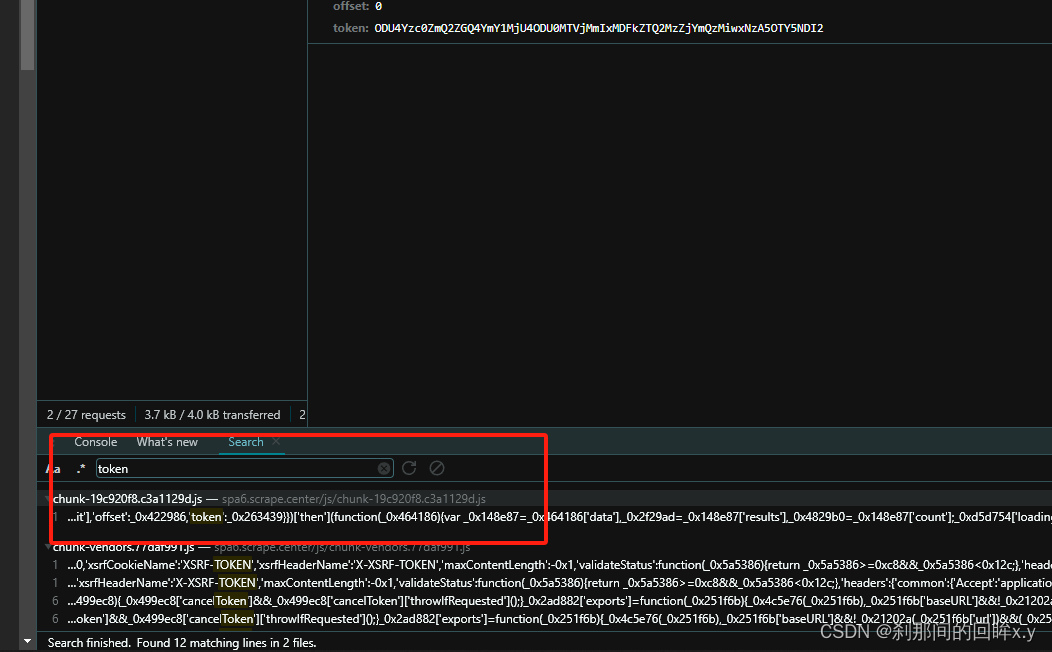
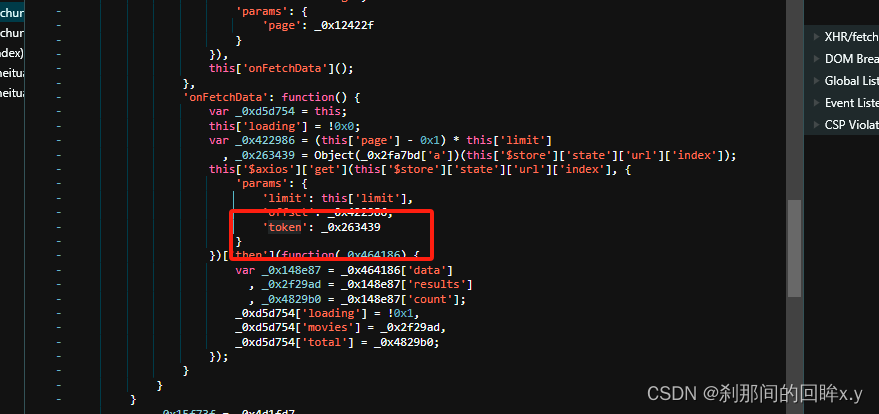

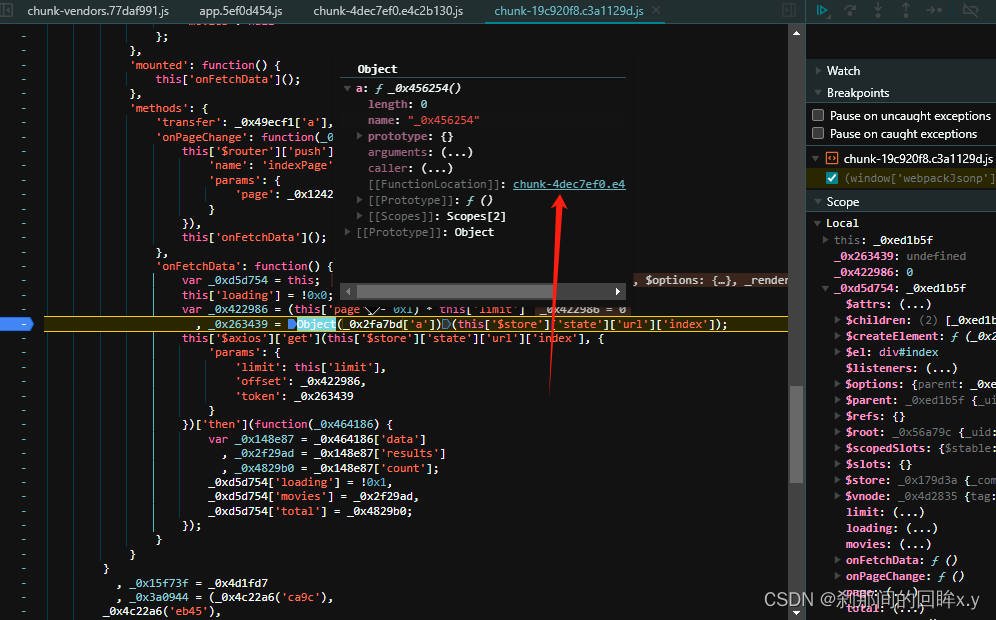
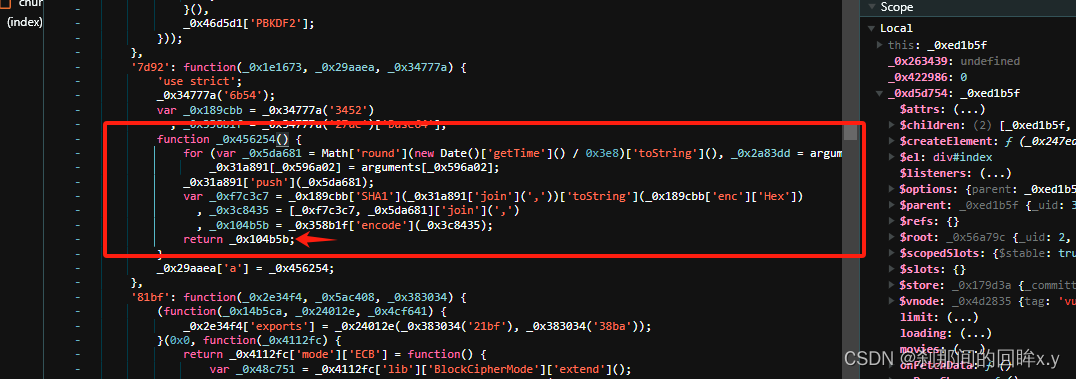
红色箭头返回的就是token
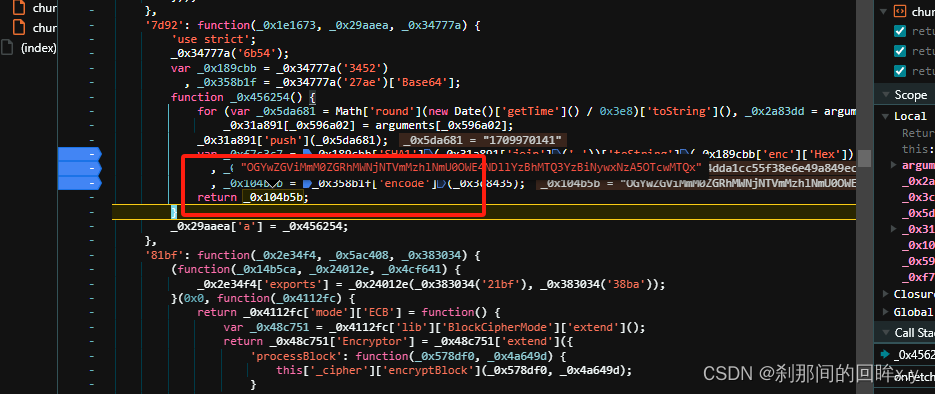
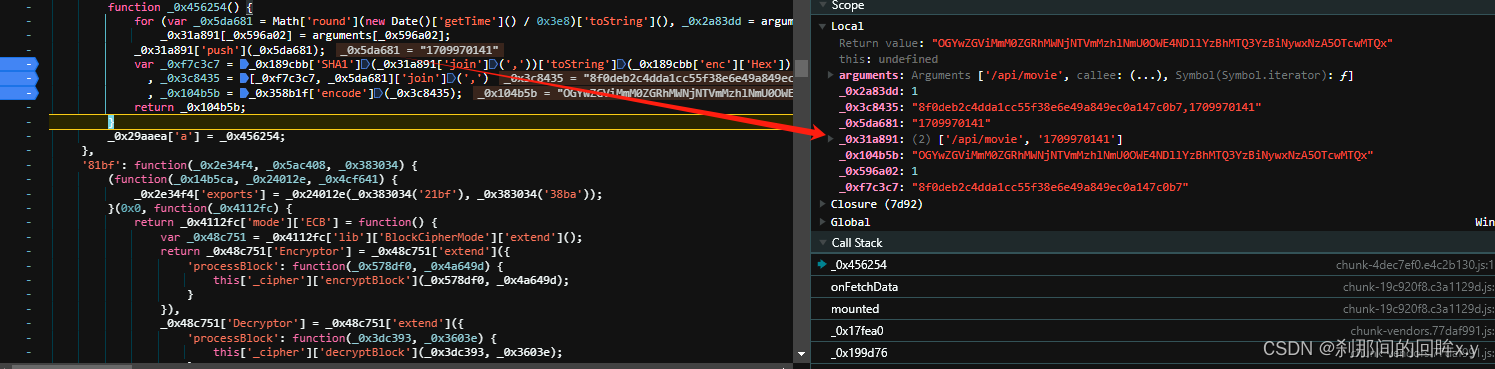
_0x31a891是一个list,在js中是array,使用join 方法 变成 '/api/movie,1709970141' , 第一个值是链接的路径是固定的,第二值是时间戳是整数的哦,在观察,是通过js中的哈希加密的,使用的方法是SHA1

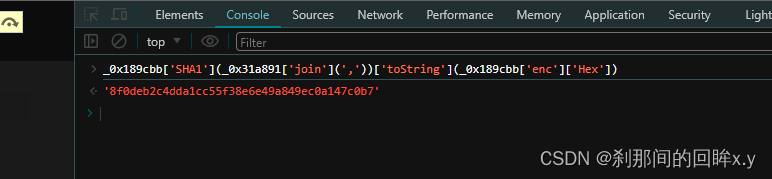

再次重组成array 时间戳用了两次,上一次是哈希加密的时候,第二次是在这里重组 [哈希加密值,时间戳]
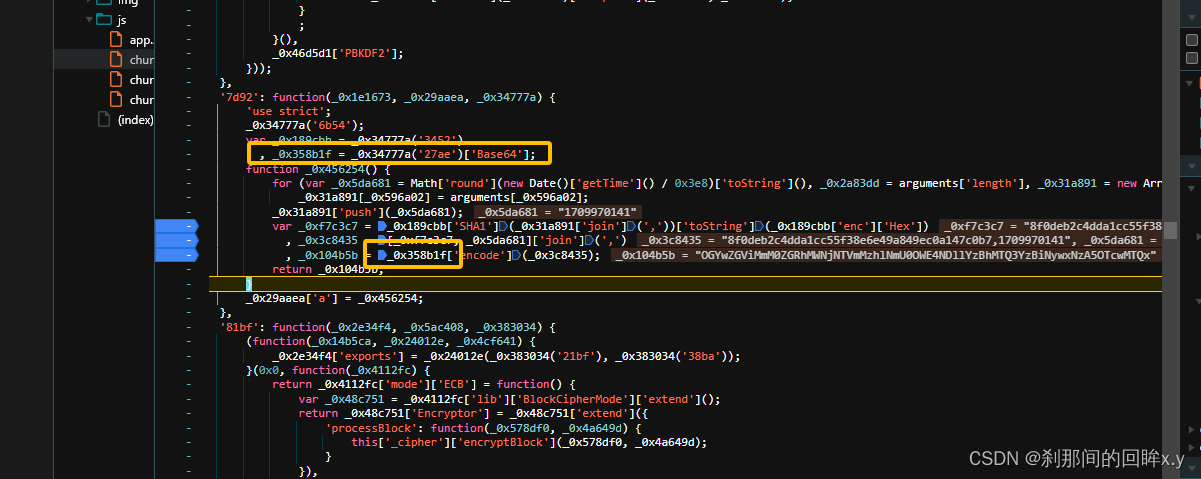
最后 base64加密 [哈希加密值,时间戳][‘join].(’,')
import hashlib
import requests
import base64
import time
from urllib.parse import urlsplit, urlencode
base_url = 'https://spa6.scrape.center/api/movie?'
timStr = str(int(time.time()))
url_path = urlsplit(base_url).path # 获取base-url 路径
def get_token():
s1 = ','.join([url_path, timStr]) # [路径, 时间戳]
s2 = hashlib.sha1(s1.encode()).hexdigest() # 哈希加密后获取字符串结果
s3 = ','.join([s2, timStr]) # 哈希加密结果和时间戳
s4 = base64.b64encode(s3.encode('utf-8')).decode('utf-8') # base64加密后获取字符串
return s4
params = {
'limit': 10,
'offset': 0,
'token': get_token()
}
url = base_url + urlencode(params)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'
}
resp = requests.get(url=url, headers=headers)
print(resp.status_code)
print(resp.json())