目录
一、实战场景
二、知识点
python 基础语法
python 文件读写
pandas 数据处理
web 连续采集
三、菜鸟实战
列表页断点连续采集基本思路
基本思路
网页列表页断点连续采集实现
Pandas 保存数据 csv 文件
详情页断点采集思路
基本思路
网页详情页断点连续采集代码实现
Pandas 保存数据 csv 文件
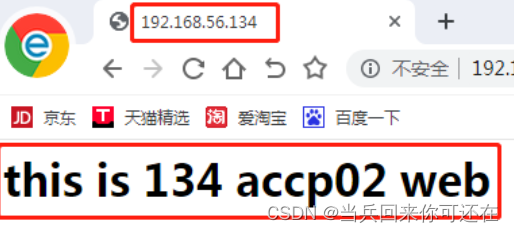
运行结果
运行效果
连续采集截图
一、实战场景
python + pandas 如何实现web网页的断点连续采集
二、知识点
python 基础语法
python 文件读写
pandas 数据处理
web 连续采集
三、菜鸟实战
列表页断点连续采集基本思路
基本思路
列表页采集的时候,采集数据保存到文件, 每次采集的时候,通过读取文件确认上一次采集的页面
网页列表页断点连续采集实现
def __init__(self):
# 初始化日志
self.init_log()
# 默认采集的上一页为第 1 页
start_page = self.PAGE_START
list_file_path = self.fileManger.get_data_file_path(self.list_data_file)
if os.path.isfile(list_file_path):
# 读取列表文件, 确定上一次采集的第几页, 以支持连续采集
self.logger.info("数据文件存在")
self.data_file_exist = True
# 计算从第几页开始采集
list_df = pd.read_csv(list_file_path, usecols=['第几页'], encoding=self.encoding)
max_page = pd.DataFrame(list_df[2:]).max()
start_page = int(max_page) + 1
print("采集页面范围: 第[%s]页至第[%s]页" % (start_page, start_page + self.PAGE_STEP - 1))
for page in range(start_page, start_page + self.PAGE_STEP):
# 初始化采集链接
url = self.target_url.replace("p1", "p" + str(page))
# 构造采集对象
url_item = UrlItem(url=url, page=page)
self.url_items.append(url_item)Pandas 保存数据 csv 文件
def save_to_file(self, data, cols):
# 保存到文件
file_path = self.fileManger.get_data_file_path(self.list_data_file)
# 初始化数据
frame = pd.DataFrame(data)
if not self.data_file_exist:
# 第一次写入带上列表头,原文件清空
frame.columns = cols
frame.to_csv(file_path, encoding=self.encoding, index=None)
self.data_file_exist = True # 写入后更新数据文件状态
else:
# 后续不写如列表头,追加写入
frame.to_csv(file_path, mode="a", encoding=self.encoding, index=None, header=0)
self.logger.debug("文件保存完成")详情页断点采集思路
基本思路
详情页采集的时候,采集数据保存到文件, 为避免重复采集,每次采集的时候,确认采集链接是否在采集的数据文件中,如果在则跳过采集,不在就执行采集
网页详情页断点连续采集代码实现
def __init__(self):
# 初始化日志
self.init_log()
# 从列表文件读取等待采集的链接
list_file_path = self.fileManger.get_data_file_path(self.list_data_file)
list_df = pd.read_csv(list_file_path, encoding=self.encoding)
self.url_items = list_df.values # 初始化待采集链接数组
detail_file_path = self.fileManger.get_data_file_path(self.detail_data_file)
if os.path.isfile(detail_file_path):
# 从详情文件读取已采集的信息
self.data_file_exist = True
detail_df = pd.read_csv(detail_file_path, encoding=self.encoding)
self.detail_df = detail_dfPandas 保存数据 csv 文件
def save_to_detail_file(self, data, cols):
# 保存到详情文件
file_path = self.fileManger.get_data_file_path(self.detail_data_file)
# 初始化数据
frame = pd.DataFrame(data)
if not self.data_file_exist:
# 第一次写入带上列表头,原文件清空
frame.columns = cols
frame.to_csv(file_path, encoding=self.encoding, index=None)
self.data_file_exist = True # 写入后更新数据文件状态
else:
# 后续不写如列表头,追加写入
frame.to_csv(file_path, mode="a", encoding=self.encoding, index=None, header=0)
self.logger.debug("文件保存完成")运行结果
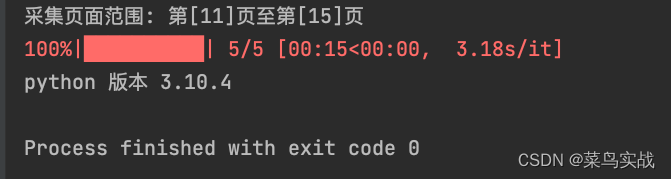
运行效果
采集页面范围: 第[16]页至第[20]页
100%|██████████| 5/5 [00:14<00:00, 2.91s/it]
python 版本 3.10.4
连续采集截图

菜鸟实战,持续学习!