JUC线程池架构
在Java开发中,线程的创建和销毁对系统性能有一定的开销,需要JVM和操作系统的配合完成大量的工作。
- JVM对线程的创建和销毁:
- 线程的创建需要JVM分配内存、初始化线程栈和线程上下文等资源,这些操作会带来一定的时间和内存开销。
- JVM需要通过与操作系统的交互进行系统调用,涉及到资源分配、权限检查等操作。
- 线程的销毁需要释放已分配的内存和其他系统资源,这也需要一定的开销。
- 操作系统对线程的管理:
- 操作系统在内核层面管理线程,每个线程都需要占用操作系统的资源,包括内存、CPU时间片、线程调度等。
- 创建和销毁线程涉及到操作系统的系统调用,如创建线程栈、设置线程上下文、更新线程调度信息等。
- 过多的线程会增加操作系统的负担,导致资源竞争和上下文切换的开销增加。
为了减少这些开销,Java引入了线程池的概念。线程池可以预先创建一定数量的线程,并重用这些线程来处理任务,从而减少线程的创建和销毁频率,提高系统的性能和效率。
使用线程池的主要优势包括:
- 减少线程创建和销毁的开销:线程池在应用启动时创建一定数量的线程,并将它们保存在池中,避免了频繁的创建和销毁操作。
- 线程重用:线程池可以重用线程来执行多个任务,避免了反复创建线程的开销。
- 动态调整线程数量:线程池可以根据任务负载情况动态调整线程数量,提高系统的处理能力和响应性能。
- 管理和监控线程:线程池提供管理和监控线程的功能,可以设置线程的优先级、超时时间等,提供更好的线程控制和调优能力。
1.JUC线程池架构
在多线程编程中,
任务都是一些经过抽象的工作单元,而线程就是让任务异步执行的基本机制。随着我们应用开发的扩张,线程和任务的管理也开始变得非常复杂,为了简化这些复杂的线程管理,这个时候就需要一个“管理者”,来统一管理线程及任务分配,这个就是线程池。
有关线程池接口 和 类的架构图大致如下
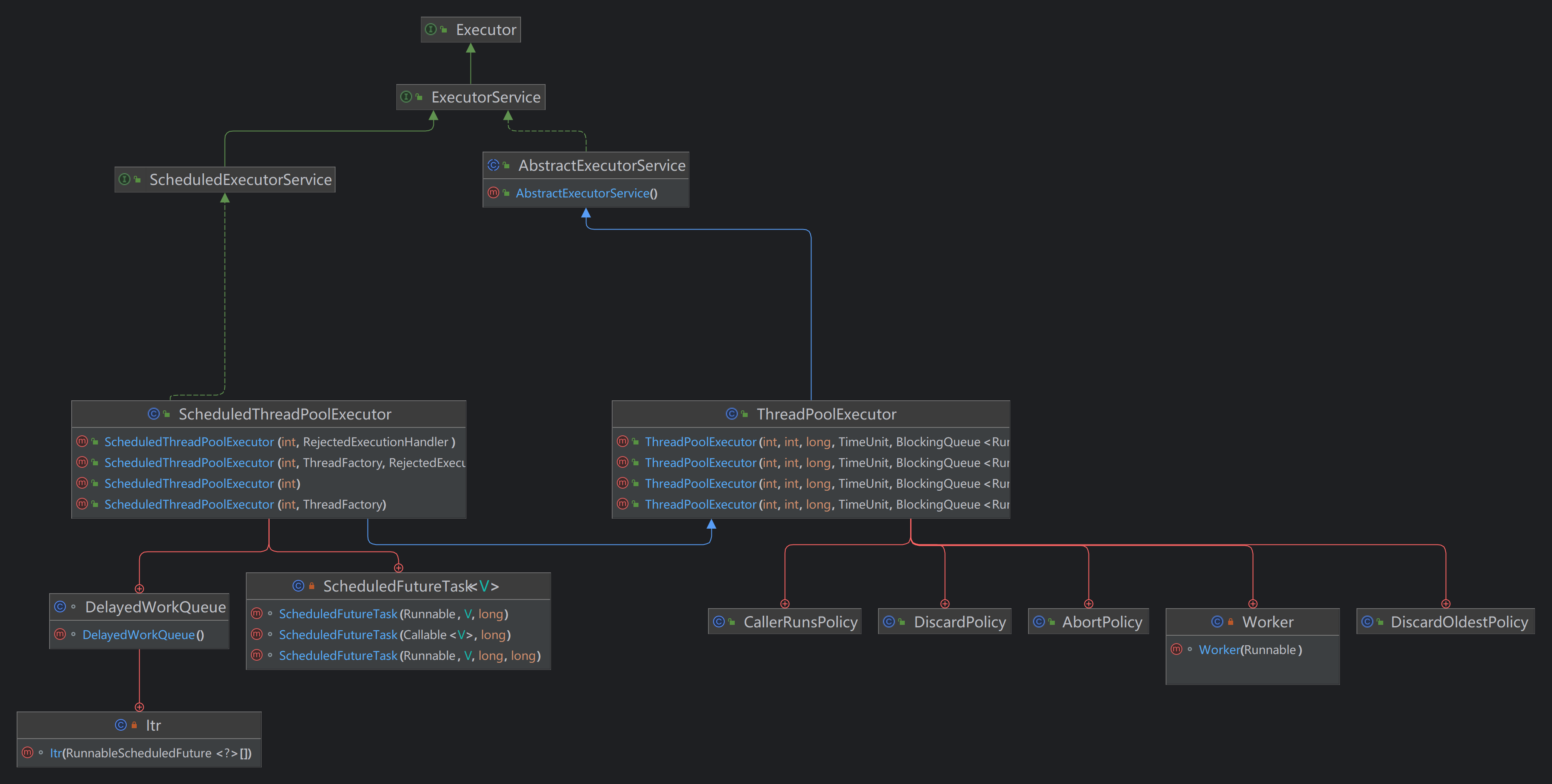
Executor(执行任务)
Executor是Java异步目标任务的执行者接口,其目的就是来执行目标任务。Executor通过execute()接口来执行已经提交的Runnable目标实例。其目的就是将任务执行者,任务提交者分离开来。
Executor框架的主要目的是将任务的提交和执行进行解耦,将任务的创建和执行逻辑分离开来。通过使用Executor框架,可以将任务的提交和执行过程进行灵活管理,并提供了一些常用的线程池实现,简化了多线程编程的复杂性。
它只包含了一个方法
public interface Executor {
/**
* Executes the given command at some time in the future. The command
* may execute in a new thread, in a pooled thread, or in the calling
* thread, at the discretion of the {@code Executor} implementation.
*
* @param command the runnable task
* @throws RejectedExecutionException if this task cannot be
* accepted for execution
* @throws NullPointerException if command is null
*/
void execute(Runnable command);
}
ExecutorService(提交任务)
ExecutorService继承Executor。他是Java中异步目标任务的执行者服务接口,对外提供异步任务的接收服务。ExecutorService对外提供了接收异步任务并转发给执行者的方法,例如submit系列方法,invoke系列方法等。
// 向线程池提交单个任务
<T> Future<T> submit(Callable<T> task);
<T> Future<T> submit(Runnable task, T result);
Future<?> submit(Runnable task);
// 批量向线程池提交任务
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks) throws InterruptedException;
<T> List<Future<T>> invokeAll(Collection<? extends Callable<T>> tasks,long timeout, TimeUnit unit) throws InterruptedException;
AbstractExecutorService
AbstractExecutorService是Java中ExecutorService接口的一个抽象实现类。它提供了ExecutorService接口的部分默认实现,以便更方便地创建自定义的ExecutorService实现。
AbstractExecutorService实现了ExecutorService接口中的大部分方法,包括提交任务、关闭执行器、等待任务完成等。它还提供了一些辅助方法和模板方法,可以供子类进行扩展和定制。
以下是AbstractExecutorService中一些重要的方法和概念:
submit(Runnable task)和submit(Callable<T> task)方法:这些方法用于将任务提交给执行器并返回一个代表任务结果的Future对象。submit(Runnable task)方法接受Runnable任务,不返回结果;submit(Callable<T> task)方法接受Callable任务,返回一个Future对象,可以通过它获取任务的执行结果。shutdown()和shutdownNow()方法:shutdown()方法用于平缓关闭执行器,不再接受新的任务提交,但会等待已提交的任务执行完成。shutdownNow()方法更加强制,它尝试停止执行器并取消所有未执行的任务。shutdown()方法:shutdown()方法是一个平缓的关闭方法。调用该方法后,ExecutorService将停止接受新的任务提交,但会等待已提交的任务执行完成。shutdown()方法不会中断正在执行的任务,而是会等待任务自行完成或等待超时。- 在调用
shutdown()方法后,可以使用awaitTermination()方法来等待所有任务执行完成,或者使用isTerminated()方法来判断是否所有任务都已经执行完成。
shutdownNow()方法:shutdownNow()方法是一个强制关闭方法。调用该方法后,ExecutorService将尝试停止当前正在执行的任务,并取消所有未执行的任务。shutdownNow()方法会中断正在执行的任务,即使任务正在阻塞中,它们也会收到InterruptedException。shutdownNow()方法返回一个List<Runnable>,其中包含所有未执行的任务。这样可以检查和处理未执行的任务。
invokeAny(Collection<? extends Callable<T>> tasks)和invokeAll(Collection<? extends Callable<T>> tasks)方法:这些方法用于提交一组任务,并等待其中一个或所有任务完成。invokeAny()方法返回其中一个任务的结果,invokeAll()方法返回所有任务的结果。isShutdown()和isTerminated()方法:isShutdown()方法用于判断执行器是否已经关闭,isTerminated()方法用于判断是否所有任务都已经执行完成。
ThreadPoolExecutor
下面我们就来了解一下,大名鼎鼎的线程池实现类,ThreadPoolExecutor,它继承与AbstractExecutorService抽象类。ThreadPoolExecutor是JUC线程池的核心实现类,线程的创建和中止都需要很大的开销,线程池为我们提供了指定数量的可重用的线程,所以使用线程池可以很大程度上节省系统资源,并且每个线程池都维护了一些基础的数据统计,方便线程的管理和监控。
我们先来简单了解一下ThreadPoolExecutor的参数,后面会详细讲解每个参数具体的意义。
ThreadPoolExecutor的一些重要概念:
- 核心线程(Core Threads):
核心线程是线程池中保持活动状态的最小线程数。即使线程是空闲的,也会保持这个数量的线程。核心线程在线程池的整个生命周期中都会存在,除非显式地调用了allowCoreThreadTimeOut()方法来允许核心线程超时退出。 - 最大线程数(Maximum Threads):
最大线程数指定了线程池中允许的最大线程数。当任务数量超过核心线程数且工作队列已满时,线程池会创建新的线程,直到达到最大线程数。超过最大线程数的任务将被拒绝执行,默认情况下会抛出RejectedExecutionException异常。 - 工作队列(Work Queue):
工作队列用于存储还未执行的任务。当线程池的线程都处于忙碌状态时,新提交的任务会被放入工作队列中等待执行。ThreadPoolExecutor提供了不同的工作队列实现,例如ArrayBlockingQueue、LinkedBlockingQueue、SynchronousQueue等。 - 拒绝策略(Rejected Execution Policy):
当线程池无法接受新的任务时(例如达到最大线程数并且工作队列已满),拒绝策略定义了如何处理这些被拒绝的任务。ThreadPoolExecutor提供了几种预定义的拒绝策略,如AbortPolicy、CallerRunsPolicy、DiscardPolicy和DiscardOldestPolicy,同时还支持自定义拒绝策略。 - 线程池生命周期(ThreadPool Lifecycle):线程池存在着不同的生命周期阶段,包括
初始化、运行中和关闭。线程池的生命周期可以通过调用shutdown()或shutdownNow()方法进行关闭。在关闭线程池之前,可以使用isShutdown()方法检查线程池是否已经关闭,使用isTerminated()方法判断是否所有任务都已经执行完成。
CallerRunsPolicy
CallerRunsPolicy是Java线程池中的一个饱和策略(RejectedExecutionHandler)。当线程池无法接受新的任务时,该策略会将任务交给调用线程来执行。
当线程池中的工作队列已满且无法继续接受新的任务时,饱和策略会决定如何处理这些被拒绝的任务。CallerRunsPolicy是其中一种饱和策略,它的行为是将被拒绝的任务交给调用线程来执行,而不是在新的线程中执行。
CallerRunsPolicy的特点如下:
- 任务在调用线程中执行:当线程池无法接受新的任务时,被拒绝的任务会由调用线程直接执行,而不是在新的线程中执行。这意味着任务的执行会阻塞调用线程,可能导致调用线程的执行时间延长。
- 保证任务不会丢失:CallerRunsPolicy保证被拒绝的任务不会丢失。尽管任务可能无法在期望的时间内执行,但它们最终会被执行,从而确保任务不会被丢弃。
- 适用于一些特定场景:CallerRunsPolicy适用于一些需要保证任务执行顺序或依赖调用线程的场景。当线程池的工作队列已满时,将任务交给调用线程执行可以确保任务的顺序性和正确性。
AbortPolicy
AbortPolicy是Java线程池中的一个饱和策略(RejectedExecutionHandler)。当线程池无法接受新的任务时,该策略会抛出RejectedExecutionException异常,拒绝执行新的任务。
当线程池中的工作队列已满且无法继续接受新的任务时,饱和策略会决定如何处理这些被拒绝的任务。AbortPolicy是其中一种饱和策略,它的行为是直接抛出异常,不执行被拒绝的任务。
AbortPolicy的特点如下:
- 抛出异常:当线程池无法接受新的任务时,被拒绝的任务会导致RejectedExecutionException异常被抛出。这意味着无法处理的任务会被拒绝执行,并且调用方可以捕获该异常进行处理。
- 不保证任务的执行:AbortPolicy不保证被拒绝的任务一定不会执行。由于线程池已经饱和且无法接受新的任务,被拒绝的任务可能无法执行,并且不会进入工作队列等待执行。
- 适用于需要严格控制任务提交的场景:AbortPolicy适用于一些需要严格控制任务提交的场景。当线程池无法接受新的任务时,抛出异常可以通知调用方任务无法执行,从而确保任务提交的可控性。
DiscardPolicy
DiscardPolicy是Java线程池中的一个饱和策略(RejectedExecutionHandler)。当线程池无法接受新的任务时,该策略会默默地丢弃被拒绝的任务,不做任何处理。
当线程池中的工作队列已满且无法继续接受新的任务时,饱和策略会决定如何处理这些被拒绝的任务。DiscardPolicy是其中一种饱和策略,它的行为是直接丢弃被拒绝的任务,不执行也不抛出异常。
DiscardPolicy的特点如下:
- 默默丢弃任务:当线程池无法接受新的任务时,被拒绝的任务会被默默地丢弃,不做任何处理。这意味着无法处理的任务会被直接丢弃,不会被执行。
- 不保证任务的执行:DiscardPolicy不保证被拒绝的任务一定不会执行。由于线程池已经饱和且无法接受新的任务,被拒绝的任务会被直接丢弃,不会进入工作队列等待执行。
- 适用于忽略任务执行的场景:DiscardPolicy适用于一些对任务执行无关紧要的场景。当任务被拒绝执行时,丢弃任务可以忽略任务执行,从而避免对整个系统产生影响。
DiscardOldestPolicy
DiscardOldestPolicy是Java线程池中的一个饱和策略(RejectedExecutionHandler)。当线程池无法接受新的任务时,该策略会丢弃工作队列中最旧的任务,为新的任务腾出空间,并尝试将新任务添加到工作队列中。
当线程池中的工作队列已满且无法继续接受新的任务时,饱和策略会决定如何处理这些被拒绝的任务。DiscardOldestPolicy是其中一种饱和策略,它的行为是丢弃工作队列中最旧的任务,并尝试将新任务添加到工作队列中。
DiscardOldestPolicy的特点如下:
- 丢弃最旧的任务:当线程池无法接受新的任务时,被拒绝的任务会导致工作队列中最旧的任务被丢弃。这意味着最旧的任务会被抛弃,为新的任务腾出空间。
- 尝试添加新任务:DiscardOldestPolicy会尝试将新的任务添加到工作队列中。如果添加成功,则新任务可以被执行;如果添加失败(例如工作队列已满),则新任务也会被丢弃。
- 不保证任务的执行:DiscardOldestPolicy不保证被拒绝的任务一定不会执行。由于线程池已经饱和且无法接受新的任务,被拒绝的任务可能无法执行,并且不会进入工作队列等待执行。
ThreadFactory
ThreadFactory是Java中的一个接口,用于创建线程对象。它提供了一种自定义线程创建方式的机制,允许开发者在创建线程时进行一些额外的配置或处理。
ThreadFactory接口定义了一个方法newThread,该方法接收一个Runnable对象作为参数,并返回一个新创建的Thread对象。开发者可以根据自己的需求,在newThread方法中实现自定义的线程创建逻辑。
下面是ThreadFactory接口的定义:
public interface ThreadFactory {
Thread newThread(Runnable r);
}
ThreadFactory接口只有一个方法newThread,它接收一个Runnable参数,并返回一个Thread对象。在实现ThreadFactory接口时,开发者需要提供自己的线程创建逻辑,例如设置线程的名称、优先级、异常处理等。
Worker
Worker指的是执行任务的工作线程。线程池是一种用于管理和复用线程的机制,它通过预先创建一组工作线程来执行提交的任务,从而提供了一种有效地处理并发任务的方式。
Worker是线程池中的核心组成部分,它负责从任务队列中获取任务并执行。线程池中的每个Worker都是一个独立的工作线程,可以并发地执行任务。
Worker的主要职责包括:
- 从任务队列中获取任务:Worker会不断地从任务队列中获取待执行的任务。任务队列可以是一个阻塞队列,当队列为空时,Worker会等待直到有新的任务被提交到队列中。
- 执行任务:一旦Worker获取到任务,它会执行任务的具体逻辑。任务可以是一个Runnable对象或Callable对象,根据任务的类型进行执行。
- 处理异常:Worker负责捕获和处理任务执行过程中可能抛出的异常。它可以根据需要记录异常信息、进行错误处理或通知相关方。
- 生命周期管理:Worker的生命周期由线程池进行管理。线程池可以动态地创建、销毁和管理Worker线程,以适应不同的工作负载。
通过使用Worker线程,线程池可以提供以下好处:
- 重用线程:Worker线程可以被线程池重用,避免了频繁地创建和销毁线程的开销。
- 并发执行:线程池中的多个Worker线程可以并发地执行多个任务,提高任务处理的效率。
- 控制并发度:线程池可以限制并发执行的任务数量,防止系统资源被过度占用。
- 提供任务排队和调度:线程池通过任务队列来管理待执行的任务,可以灵活地控制任务的排队和调度策略。
ScheduledExecutorService
ScheduledExecutorService是Java中的一个接口,继承自ExecutorService接口,用于在预定的时间间隔内执行任务。它提供了一种方便的方式来调度任务的执行,并且可以支持延迟执行和周期性执行。
ScheduledExecutorService的主要特点如下:
- 任务调度:ScheduledExecutorService可以安排任务在指定的时间点执行,或者延迟一定时间后执行。它提供了一些方法,如
schedule()、scheduleAtFixedRate()和scheduleWithFixedDelay(),用于安排任务的执行时间。 - 延迟执行:ScheduledExecutorService可以延迟任务的执行。通过
schedule()方法,可以指定任务的延迟时间,任务将在延迟时间过后执行一次。 - 周期性执行:ScheduledExecutorService支持周期性执行任务。通过
scheduleAtFixedRate()方法,可以指定任务的初始延迟时间和执行周期,任务将在指定的延迟时间过后开始执行,并在每个周期结束后立即重新执行。 - 线程池支持:ScheduledExecutorService通常使用线程池来执行任务。它可以使用线程池中的线程来执行任务,以便高效地管理和复用线程资源。线程池可以通过
Executors类的方法创建,例如newScheduledThreadPool()。 - 可取消任务:ScheduledExecutorService允许取消已安排的任务。通过返回的
ScheduledFuture对象,可以使用cancel()方法取消任务的执行。取消的任务将不再执行,已经在执行的任务可以被中断。
通过使用ScheduledExecutorService,可以实现定时任务、周期性任务和延迟任务的调度。它提供了灵活的任务调度功能,使得在应用程序中执行定时或延迟任务变得简单和可靠。
请注意,ScheduledExecutorService是一个接口,它的具体实现类是ScheduledThreadPoolExecutor,它是ThreadPoolExecutor的扩展,提供了调度任务的功能。
ScheduledThreadPoolExecutor
ScheduledThreadPoolExecutor是Java中的一个类,它是ScheduledExecutorService接口的具体实现类。它继承自ThreadPoolExecutor类,并增加了调度任务的功能。
ScheduledThreadPoolExecutor具有以下特点:
- 任务调度:ScheduledThreadPoolExecutor可以安排任务在指定的时间点执行,或者延迟一定时间后执行。它提供了一些方法,如
schedule()、scheduleAtFixedRate()和scheduleWithFixedDelay(),用于安排任务的执行时间。 - 线程池支持:ScheduledThreadPoolExecutor使用线程池来执行任务。它继承自ThreadPoolExecutor类,因此可以充分利用线程池的功能,包括线程的复用、线程池大小的控制和线程的生命周期管理。
- 优雅关闭:ScheduledThreadPoolExecutor可以通过调用
shutdown()或shutdownNow()方法来关闭线程池。在关闭之前,它会等待所有已安排的任务执行完成,并停止接受新的任务。可以使用isShutdown()方法检查线程池是否已经关闭,使用isTerminated()方法判断是否所有任务都已经执行完成。 - 灵活的任务调度策略:ScheduledThreadPoolExecutor提供了多种任务调度策略。例如,
scheduleAtFixedRate()方法可以按照固定的速率执行任务,无论任务的执行时间是否超过周期;scheduleWithFixedDelay()方法可以在任务执行完成后,等待固定的延迟时间再执行下一个任务。 - 可取消任务:ScheduledThreadPoolExecutor允许取消已安排的任务。通过返回的
ScheduledFuture对象,可以使用cancel()方法取消任务的执行。取消的任务将不再执行,已经在执行的任务可以被中断。
使用ScheduledThreadPoolExecutor可以轻松地实现定时任务、周期性任务和延迟任务的调度。它提供了灵活的任务调度功能,并且通过线程池的管理,能够高效地执行任务。
请注意,ScheduledThreadPoolExecutor是ScheduledExecutorService接口的默认实现,它提供了最常用的功能和调度策略。如果需要更高级的功能,也可以通过自定义实现ScheduledExecutorService接口来实现。
DelayedWorkQueue
DelayedWorkQueue是Java中的一个工作队列实现,用于存储延迟执行的任务。它是ScheduledThreadPoolExecutor类中使用的默认工作队列。
DelayedWorkQueue的特点如下:
- 存储延迟任务:DelayedWorkQueue用于存储延迟执行的任务。每个任务都有一个延迟时间,任务将在延迟时间过后才能被执行。延迟时间可以是固定的时间段,也可以是任务提交的时间点到执行时间点的时间间隔。
- 按照延迟时间排序:DelayedWorkQueue按照任务的延迟时间进行排序。队列中的任务按照延迟时间从小到大排列,即延迟时间最小的任务排在队列的前面,最先被取出执行。这样可以确保任务按照预定的延迟时间顺序执行。
- 基于优先级的比较:DelayedWorkQueue使用任务的延迟时间和优先级进行比较。在延迟时间相等的情况下,优先级高的任务会被排在前面,优先执行。这样可以确保在延迟时间相等的情况下,具有高优先级的任务先被执行。
ScheduledFutureTask
ScheduledFutureTask是Java中的一个类,它是ScheduledThreadPoolExecutor类中使用的任务实现。它继承自FutureTask类,并实现了ScheduledFuture接口。
ScheduledFutureTask的特点如下:
- 延迟执行和周期性执行:ScheduledFutureTask用于表示延迟执行和周期性执行的任务。它可以安排任务在指定的延迟时间后执行一次,也可以按照固定的周期执行任务。
- 可取消任务:ScheduledFutureTask允许取消已安排的任务。通过调用
cancel()方法,可以取消任务的执行。已取消的任务将不再执行,已经在执行的任务可以被中断。 - 任务调度信息:ScheduledFutureTask包含任务的调度信息,如延迟时间、周期和任务的执行时间等。它提供了一些方法,如
getDelay()和getPeriod(),用于获取任务的延迟时间和周期。 - 任务执行状态:ScheduledFutureTask提供了任务执行状态的管理。它可以通过
isDone()方法判断任务是否已完成,通过isCancelled()方法判断任务是否已取消。