1.使用socket协议构建server client文件,服务端构建maskrcnn分割模型,客户端发送图片返回分割结果;使用纯socket通信,通信传输效率较低,接收数据需要1024byte连续接收
代码如下
#server.py
import socket
import torchvision
import torch
import numpy as np
import cv2
import time
model = torchvision.models.detection.maskrcnn_resnet50_fpn(pretrained=True)
# model.cuda()
model.eval()
def forward_image_list(input_tensor_list):
pred_list = model(input_tensor_list)
mask_list = []
for pred in pred_list:
pred_score = list(pred['scores'].detach().cpu().numpy())
pred_class = list(pred['labels'].detach().cpu().numpy())
select_ind = [pred_score.index(x) for x, label in zip(pred_score, pred_class) if x > 0.9 and label == 1]
masks = pred['masks']
select_mask = masks[select_ind, :, :, :] > 0.3
total_mask = torch.sum(select_mask, dim=0).float()
total_mask = (total_mask>=1).int()*255
mask_list.append(total_mask)
return mask_list
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.bind(('127.0.0.1', 2222))
s.listen(5)
print("waiting...")
rescale = 1
height = int(500 * rescale)
width = int(1200 * rescale)
lenth = width*height*3
while True:
sock, addr = s.accept()
print("sock ",sock)
print("addr",addr)
while True:
data = sock.recv(1024)
if len(data)>0:
total_data = data
while len(total_data)<lenth and len(data)>0:
data = sock.recv(1024)
total_data += data
# print(len(total_data))
# print("data",total_data)c
# total_data recv finished
np_array = np.frombuffer(total_data, dtype=np.uint8)
# print("np_array.shape",np_array.shape)
# cv2.imwrite("person_resize.jpg",np_array.reshape((500,1200,3)))
input_tensor = torch.from_numpy(np_array).float().view((height, width, 3))
input_tensor = input_tensor.permute((2, 0, 1))
input_tensor = input_tensor/255
t1=time.time()
mask_list = forward_image_list([input_tensor])
t2=time.time()
print("time is(s) :",(t2-t1))
mask0_numpy = mask_list[0].detach().cpu().numpy().astype(np.uint8)
# print("mask0_numpy.shape",mask0_numpy.shape)
# cv2.imwrite("mask.jpg",mask0_numpy[0])
mask0_numpy_bytes = mask0_numpy.tobytes()
sock.sendall(mask0_numpy_bytes)
# print("send mask bytes!" + str(len(mask0_numpy_bytes)))
else:
breakclient.py
import socket
import torchvision
import torch
import numpy as np
import time,sys
import cv2
for i in range(1):
try:
client_send = socket.socket()
ip_port = ("127.0.0.1", 2222)
client_send.connect(ip_port)
t1=time.time()
img_data=cv2.imread("person.jpg")
img_data=cv2.resize(img_data,(1200,500))
cmd_data=img_data.tobytes()
client_send.sendall(cmd_data)
data = client_send.recv(1024)
if len(data)>0:
rec_data=data
while len(rec_data)<600000 and len(data)>0:
data = client_send.recv(1024)
rec_data += data
print(len(rec_data))
np_array = np.frombuffer(rec_data, dtype=np.uint8)
re_np=np_array.reshape((500,1200))
# cv2.imwrite("mask0.jpg",re_np)
t2=time.time()
print("fps",1/(t2-t1))
client_send.close
except:
time.sleep(0.1)
if(i >= 20):
print('退出')
sys.exit()
print('发送命令[{}]时与主程序连接失败,次数:{}'.format("cmd", i+1))
else:
break
# re=str(data, encoding="utf-8").split("\n", 1)[0]
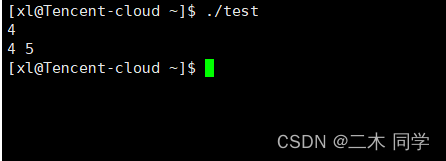
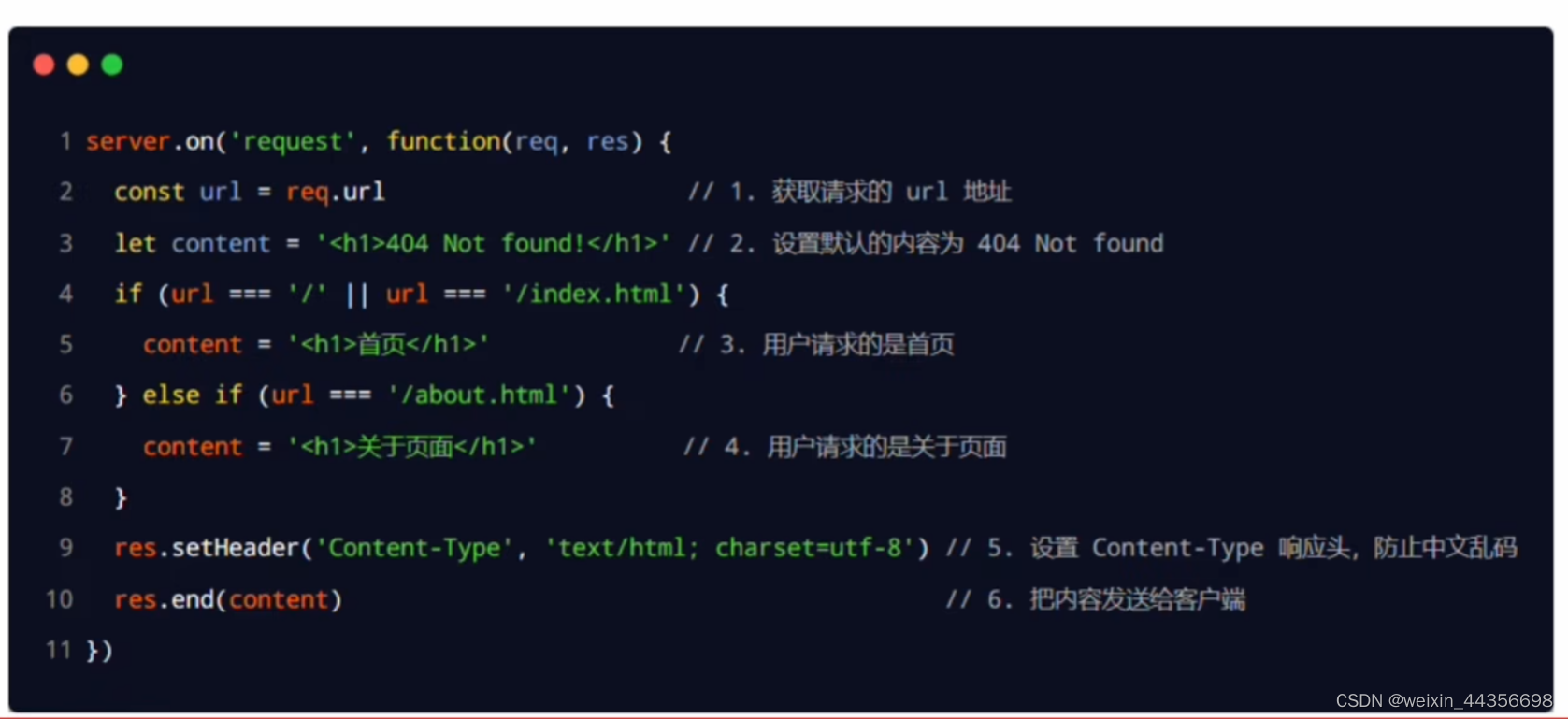
结果如图所示
2.Http服务器实现-基于python的简单服务器
1. 接受静态请求,`html`,`png`等文件
2. 接受动态请求,脚本类型为`python`
3. 提供`Session`服务
4. `root`是根目录,包含资源文件,脚本等
5. 使用线程池来管理请求
python server.py/client.py
实现client send req: (GET / HTTP/1.1 Host: 127.0.0.1:9999)
返回 res.html
实现原理 线程池管理+socket通信
server.py
# -*- coding=utf-8 -*-
import socket
import threading
import queue
from HttpHead import HttpRequest
# 每个任务线程
class WorkThread(threading.Thread):
def __init__(self, work_queue):
super().__init__()
self.work_queue = work_queue
self.daemon = True
def run(self):
while True:
func, args = self.work_queue.get()
func(*args)
self.work_queue.task_done()
# 线程池
class ThreadPoolManger():
def __init__(self, thread_number):
self.thread_number = thread_number
self.work_queue = queue.Queue()
for i in range(self.thread_number): # 生成一些线程来执行任务
thread = WorkThread(self.work_queue)
thread.start()
def add_work(self, func, *args):
self.work_queue.put((func, args))
def tcp_link(sock, addr):
print('Accept new connection from %s:%s...' % addr)
request = sock.recv(1024)
# print("request",request)
http_req = HttpRequest()
http_req.passRequest(request)
sock.send(http_req.getResponse().encode('utf-8'))
sock.close()
def start_server():
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
ip_addr=('127.0.0.1', 9999)
s.bind(ip_addr)
s.listen(10)
thread_pool = ThreadPoolManger(5)
print('listen in %s:%d' % ('127.0.0.1', 9999))
while True:
sock, addr = s.accept()
print("sock ",sock)
print("addr",addr)
thread_pool.add_work(tcp_link, *(sock, addr))
if __name__ == '__main__':
start_server()
pass
client.py
#!E:\python\venv\Scripts
# -*- coding:utf-8 -*-
import socket
# from flask import template_rendered
import numpy as np
from importlib_metadata import re
def post_request():
req = 'POST /?ni=00 HTTP/1.1\r\n'
req = req + 'Host: 127.0.0.1:9999\r\n\r\n'
req = req + 'name=linyi&data=163'
return req
def get_request():
req = 'GET / HTTP/1.1\r\n'
req = req + 'Host: 127.0.0.1:9999\r\n\r\n'
return req
def start_request():
s = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
s.connect(('127.0.0.1', 9999))
req = get_request()
print("req:",req)
# temp_data=np.array([2,3,4])
# req=temp_data.tobytes()
s.sendall(req.encode())
buff = []
while True:
d = s.recv(1024)
if d:
buff.append(d.decode())
else:
break
data = ''.join(buff)
s.close()
header, html = data.split('\r\n\r\n', 1)
f = open('res.html', 'w')
f.write(html)
f.close()
if __name__ == '__main__':
start_request()
input("press any key to exit;")
Httphead.py
# -*- coding:utf-8 -*-
import os
import xml.dom.minidom
# 返回码
class ErrorCode(object):
OK = "HTTP/1.1 200 OK\r\n"
NOT_FOUND = "HTTP/1.1 404 Not Found\r\n"
# 将字典转成字符串
def dict2str(d):
s = ''
for i in d:
s = s + i+': '+d[i]+'\r\n'
return s
class Session(object):
def __init__(self):
self.data = dict()
self.cook_file = None
def getCookie(self, key):
if key in self.data.keys():
return self.data[key]
return None
def setCookie(self, key, value):
self.data[key] = value
def loadFromXML(self):
import xml.dom.minidom as minidom
root = minidom.parse(self.cook_file).documentElement
for node in root.childNodes:
if node.nodeName == '#text':
continue
else:
self.setCookie(node.nodeName, node.childNodes[0].nodeValue)
def write2XML(self):
import xml.dom.minidom as minidom
dom = xml.dom.minidom.getDOMImplementation().createDocument(None, 'Root', None)
root = dom.documentElement
for key in self.data:
node = dom.createElement(key)
node.appendChild(dom.createTextNode(self.data[key]))
root.appendChild(node)
print(self.cook_file)
with open(self.cook_file, 'w') as f:
dom.writexml(f, addindent='\t', newl='\n', encoding='utf-8')
class HttpRequest(object):
RootDir = 'root'
NotFoundHtml = RootDir+'/404.html'
CookieDir = 'root/cookie/'
def __init__(self):
self.method = None
self.url = None
self.protocol = None
self.head = dict()
self.Cookie = None
self.request_data = dict()
self.response_line = ''
self.response_head = dict()
self.response_body = ''
self.session = None
def passRequestLine(self, request_line):
header_list = request_line.split(' ')
self.method = header_list[0].upper()
self.url = header_list[1]
if self.url == '/':
self.url = '/index.html'
self.protocol = header_list[2]
def passRequestHead(self, request_head):
head_options = request_head.split('\r\n')
for option in head_options:
key, val = option.split(': ', 1)
self.head[key] = val
# print key, val
if 'Cookie' in self.head:
self.Cookie = self.head['Cookie']
def passRequest(self, request):
request = request.decode('utf-8')
if len(request.split('\r\n', 1)) != 2:
return
request_line, body = request.split('\r\n', 1)
request_head = body.split('\r\n\r\n', 1)[0] # 头部信息
self.passRequestLine(request_line)
self.passRequestHead(request_head)
# 所有post视为动态请求
# get如果带参数也视为动态请求
# 不带参数的get视为静态请求
if self.method == 'POST':
self.request_data = {}
request_body = body.split('\r\n\r\n', 1)[1]
parameters = request_body.split('&') # 每一行是一个字段
for i in parameters:
if i=='':
continue
key, val = i.split('=', 1)
self.request_data[key] = val
self.dynamicRequest(HttpRequest.RootDir + self.url)
if self.method == 'GET':
if self.url.find('?') != -1: # 含有参数的get
self.request_data = {}
req = self.url.split('?', 1)[1]
s_url = self.url.split('?', 1)[0]
parameters = req.split('&')
for i in parameters:
key, val = i.split('=', 1)
self.request_data[key] = val
self.dynamicRequest(HttpRequest.RootDir + s_url)
else:
self.staticRequest(HttpRequest.RootDir + self.url)
# 只提供制定类型的静态文件
def staticRequest(self, path):
# print path
if not os.path.isfile(path):
f = open(HttpRequest.NotFoundHtml, 'r')
self.response_line = ErrorCode.NOT_FOUND
self.response_head['Content-Type'] = 'text/html'
self.response_body = f.read()
else:
extension_name = os.path.splitext(path)[1] # 扩展名
extension_set = {'.css', '.html', '.js'}
if extension_name == '.png':
f = open(path, 'rb')
self.response_line = ErrorCode.OK
self.response_head['Content-Type'] = 'text/png'
self.response_body = f.read()
elif extension_name in extension_set:
f = open(path, 'r')
self.response_line = ErrorCode.OK
self.response_head['Content-Type'] = 'text/html'
self.response_body = f.read()
elif extension_name == '.py':
self.dynamicRequest(path)
# 其他文件不返回
else:
f = open(HttpRequest.NotFoundHtml, 'r')
self.response_line = ErrorCode.NOT_FOUND
self.response_head['Content-Type'] = 'text/html'
self.response_body = f.read()
def processSession(self):
self.session = Session()
# 没有提交cookie,创建cookie
if self.Cookie is None:
self.Cookie = self.generateCookie()
cookie_file = self.CookieDir + self.Cookie
self.session.cook_file = cookie_file
self.session.write2XML()
else:
cookie_file = self.CookieDir + self.Cookie
self.session.cook_file = cookie_file
if os.path.exists(cookie_file):
self.session.loadFromXML()
# 当前cookie不存在,自动创建
else:
self.Cookie = self.generateCookie()
cookie_file = self.CookieDir+self.Cookie
self.session.cook_file = cookie_file
self.session.write2XML()
return self.session
def generateCookie(self):
import time, hashlib
cookie = str(int(round(time.time() * 1000)))
hl = hashlib.md5()
hl.update(cookie.encode(encoding='utf-8'))
return cookie
def dynamicRequest(self, path):
# 如果找不到或者后缀名不是py则输出404
if not os.path.isfile(path) or os.path.splitext(path)[1] != '.py':
f = open(HttpRequest.NotFoundHtml, 'r')
self.response_line = ErrorCode.NOT_FOUND
self.response_head['Content-Type'] = 'text/html'
self.response_body = f.read()
else:
# 获取文件名,并且将/替换成.
file_path = path.split('.', 1)[0].replace('/', '.')
self.response_line = ErrorCode.OK
m = __import__(file_path)
m.main.SESSION = self.processSession()
if self.method == 'POST':
m.main.POST = self.request_data
m.main.GET = None
else:
m.main.POST = None
m.main.GET = self.request_data
self.response_body = m.main.app()
self.response_head['Content-Type'] = 'text/html'
self.response_head['Set-Cookie'] = self.Cookie
def getResponse(self):
return self.response_line+dict2str(self.response_head)+'\r\n'+self.response_body
返回的html文件
res.html
<!DOCTYPE html>
<html lang="zh-CN">
<head>
<style type="text/css">
div{
width: 100%;
text-align:center;
}
</style>
</head>
<body>
<div>
<h1>this is index html</h1>
</div>
</body>
<html>3 使用flask构建web服务
resent分类任务
export_jit.py 导出模型
# export_jit_model.py
import torch
import torchvision.models as models
model = models.resnet50("/Users/ludongsheng/code/pycode/web_http/flask/resnet50.pth")
model.eval()
example_input = torch.rand(1, 3, 224, 224)
jit_model = torch.jit.trace(model, example_input)
torch.jit.save(jit_model, 'resnet50_jit.pth')
两个html文件
home.html
<html>
<head>
<title>PyTorch Image Classification</title>
</head>
<body>
<h1>PyTorch Image Classification</h1>
<form method="POST" enctype="multipart/form-data" action="/predict">
<input type="file" name="image">
<input type="submit" value="Predict">
</form>
</body>
</html>
predict.html
<html>
<head>
<title>Prediction Results</title>
</head>
<body>
<h1>Prediction Results</h1>
<p>Predicted Class: {{ predicted_class }}</p>
<p>Probability: {{ probability }}</p>
<h2>Other Classes</h2>
<ul>
{% for class_name, prob in class_probs %}
<li>{{ class_name }}: {{ prob }}</li>
{% endfor %}
</ul>
</body>
</html>app.py
from flask import Flask, request, render_template
from PIL import Image
import torch
import torchvision
import torchvision.transforms as transforms
model = torch.jit.load('resnet50_jit.pth')
app = Flask(__name__)
# @app.route('/')
# def home():
# return render_template('home.html')
def process_image(image):
# Preprocess image for model
transformation = transforms.Compose([
transforms.Resize(224),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# print("transformation(image)",transformation(image))
image_tensor = transformation(image).unsqueeze(0)
return image_tensor
class_names = ['apple', 'banana'] #REPLACE THIS WITH YOUR CLASSES
class_names=[str(i) for i in range(1000)]
@app.route('/predict', methods=['POST'])
def predict():
# Get uploaded image file
image = request.files['image']
# Process image and make prediction
image_tensor = process_image(Image.open(image))
output = model(image_tensor)
# Get class probabilities
probabilities = torch.nn.functional.softmax(output, dim=1)
probabilities = probabilities.detach().numpy()[0]
# Get the index of the highest probability
class_index = probabilities.argmax()
# Get the predicted class and probability
predicted_class = class_names[class_index]
probability = probabilities[class_index]
# Sort class probabilities in descending order
class_probs = list(zip(class_names, probabilities))
class_probs.sort(key=lambda x: x[1], reverse=True)
# Render HTML page with prediction results
return render_template('predict.html', class_probs=class_probs,
predicted_class=predicted_class, probability=probability)
if __name__ == '__main__':
app.run()client.py
#can work 2023-1-8
import requests
import time
PyTorch_REST_API_URL = 'http://127.0.0.1:5000/predict'
def predict_result(image_path):
# Initialize image path
image = open(image_path, 'rb').read()
payload = {'image': image}
# Submit the request..json()
# r = requests.post(PyTorch_REST_API_URL, files=payload).json()
r = requests.post(PyTorch_REST_API_URL, files=payload)
# 这里没执行,因为返回的是html文件 需要解析内容
if r['success']:
# Loop over the predictions and display them.
for (i, result) in enumerate(r['predictions']):
print("log is ...")
# print('{}. {}: {:.4f}'.format(i + 1, result['label'],result['probability']))
# Otherwise, the request failed.
else:
print('Request failed')
t1=time.time()
res=predict_result("/Users/ludongsheng/code/pycode/web_http/flask/flower.jpg")
t2=time.time()
print("----------------")
print("time is :",round((t2-t1),5))