-
2023年由Ultralytics 提供了YOLOv8开源项目。YOLOv8 支持全方位的视觉 AI 任务,包括检测、分割、姿态估计、跟踪和分类。这种多功能性使用户能够在各种应用和领域中利用YOLOv8 的功能。安装yolov8开源项目 pip install git+https://github.com/ultralytics/ultralytics.git@main
-
训练模式用于在自定义数据集上训练YOLOv8 模型。在该模式下,模型使用指定的数据集和超参数进行训练。训练过程包括优化模型参数,使其能够准确预测图像中物体的类别和位置。
-
from ultralytics import YOLO model = YOLO('yolov8n.pt') # 加载预训练模型训练 results = model.train(epochs=5) ########### from ultralytics import YOLO model = YOLO('yolov8n.yaml') results = model.train(data='coco128.yaml', epochs=5)
-
-
Val 模式用于在YOLOv8 模型训练完成后对其进行验证。在该模式下,模型在验证集上进行评估,以衡量其准确性和泛化性能。该模式可用于调整模型的超参数,以提高其性能。
-
from ultralytics import YOLO model = YOLO('yolov8n.yaml') model.train(data='coco128.yaml', epochs=5) model.val() # It'll automatically evaluate the data you trained. ########### from ultralytics import YOLO model = YOLO("model.pt") # It'll use the data YAML file in model.pt if you don't set data. model.val() # or you can set the data you want to val model.val(data='coco128.yaml')
-
-
预测模式用于使用训练有素的YOLOv8 模型对新图像或视频进行预测。在该模式下,模型从检查点文件加载,用户可以提供图像或视频来执行推理。模型会预测输入图像或视频中物体的类别和位置。
-
from ultralytics import YOLO from PIL import Image import cv2 model = YOLO("model.pt") # accepts all formats - image/dir/Path/URL/video/PIL/ndarray. 0 for webcam results = model.predict(source="0") results = model.predict(source="folder", show=True) # Display preds. Accepts all YOLO predict arguments # from PIL im1 = Image.open("bus.jpg") results = model.predict(source=im1, save=True) # save plotted images # from ndarray im2 = cv2.imread("bus.jpg") results = model.predict(source=im2, save=True, save_txt=True) # save predictions as labels # from list of PIL/ndarray results = model.predict(source=[im1, im2]) ## 结果文件输出下游任务 # results would be a list of Results object including all the predictions by default # but be careful as it could occupy a lot memory when there're many images, # especially the task is segmentation. # 1. return as a list results = model.predict(source="folder") # results would be a generator which is more friendly to memory by setting stream=True # 2. return as a generator results = model.predict(source=0, stream=True) for result in results: # Detection result.boxes.xyxy # box with xyxy format, (N, 4) result.boxes.xywh # box with xywh format, (N, 4) result.boxes.xyxyn # box with xyxy format but normalized, (N, 4) result.boxes.xywhn # box with xywh format but normalized, (N, 4) result.boxes.conf # confidence score, (N, 1) result.boxes.cls # cls, (N, 1) # Segmentation result.masks.data # masks, (N, H, W) result.masks.xy # x,y segments (pixels), List[segment] * N result.masks.xyn # x,y segments (normalized), List[segment] * N # Classification result.probs # cls prob, (num_class, ) # Each result is composed of torch.Tensor by default, # in which you can easily use following functionality: result = result.cuda() result = result.cpu() result = result.to("cpu") result = result.numpy()
-
-
导出模式用于将YOLOv8 模型导出为可用于部署的格式。在此模式下,模型将转换为其他软件应用程序或硬件设备可以使用的格式。在将模型部署到生产环境时,该模式非常有用。
-
from ultralytics import YOLO model = YOLO('yolov8n.pt') model.export(format='onnx', dynamic=True)
-
-
跟踪模式用于使用YOLOv8 模型实时跟踪物体。在该模式下,模型从检查点文件加载,用户可以提供实时视频流来执行实时物体跟踪。该模式适用于监控系统或自动驾驶汽车等应用。
-
from ultralytics import YOLO model = YOLO('path/to/best.pt') # load a custom model results = model.track(source="https://youtu.be/LNwODJXcvt4", show=True)
-
-
基准模式用于分析YOLOv8 中各种导出格式的速度和准确性。基准模式提供的信息包括导出格式的大小、其
mAP50-95指标(用于物体检测和分割)或accuracy_top5度量(用于分类),以及不同导出格式(如ONNX,OpenVINO,TensorRT 等)下每幅图像的推理时间(以毫秒为单位)。这些信息可以帮助用户根据自己对速度和准确性的要求,为自己的特定使用情况选择最佳的导出格式。-
from ultralytics.utils.benchmarks import benchmark # Benchmark benchmark(model='yolov8n.pt', data='coco8.yaml', imgsz=640, half=False, device=0)
-
-
-
数据集标注是一个非常耗费资源和时间的过程。如果您有一个在合理数据量上训练有素的YOLO 物体检测模型,您就可以使用它来自动标注附加数据(分割格式)。 SAM来自动标注其他数据(分割格式)。
-
from ultralytics.data.annotator import auto_annotate auto_annotate( data='path/to/new/data', det_model='yolov8n.pt', sam_model='mobile_sam.pt', device="cuda", output_dir="path/to/save_labels", )
-
-
将 COCO 转换为YOLO 格式,用于将 COCO JSON 注释转换为适当的YOLO 格式。用于对象检测(边界框)数据集、
use_segments和use_keypoints都应False -
Precision-Recall曲线是根据阈值 从0到1这个区间的变动,每个阈值下模型的precision和recall的值分别作为纵坐标和横坐标来连线绘制而成的。(每个阈值θ对应于一个(Precision,Recall)点,把这些点连起来就是PR曲线)。比如假设我们收集了20个sample的数据,他们的真实标签和置信度如下
-

-
sklearn
-
import numpy as np from sklearn.metrics import precision_recall_curve # 导入数据 y_true = np.array([1,1,0,1,1,1,0,0,1,0,1,0,1,0,0,0,1,0,1,0]) y_scores = np.array([0.9,0.8,0.7,0.6,0.55,0.54, 0.53,0.52,0.51,0.505, 0.4, 0.39,0.38, 0.37, 0.36, 0.35, 0.34, 0.33, 0.30, 0.1]) # 计算出每个阈值下,precision和recall的值 precision, recall, thresholds = precision_recall_curve(y_true, y_scores) # 写上这两行,中间的列就不会被用省略号省略,都显示出来 pd.options.display.max_rows = None pd.options.display.max_columns = None #整理成横向的dataframe,方便大家查看 precision = pd.DataFrame(precision).T recall = pd.DataFrame(recall).T thresholds= pd.DataFrame(thresholds).T #纵向拼接 results = pd.concat([thresholds, recall,precision], axis=0) # 仅仅保留2位小数 results = round(results, 2) #行名改一下 results.index = ["thresholds", "recall", "precision"] print(results) import matplotlib.pyplot as plt def plot_pr_curve(recall, precision): plt.plot(recall, precision, label='Precision-Recall curve') plt.xlabel('Recall') plt.ylabel('Precision') plt.title('PR Curve') plt.legend() plot_pr_curve(recall, precision) -
对于PR图中这种类似锯齿状的图形,我们一般采用平滑锯齿的操作。所谓平滑锯齿操作就是在Recall轴上,对于每个阈值θ计算出的Recall点,看看它的右侧(包含它自己)谁的Precision最大,然后这个区间都使用这个Precision值,Precision和Recall之间的此消彼长的矛盾关系, 既然一个模型的precision和recall是此消彼长的关系,不可能两个同时大,那怎么判断哪个模型更优呢?答案是,P-R曲线越往右上角凸起的曲线对应的模型越优秀。那就引出了平衡点(“Balanced Error Point” (BEP))这个概念。平衡点就是曲线上的Precision值=Recall值的那个点。 除了平衡点,也可以用F1 score来评估。F1 = 2 * P * R /( P + R )。F1-score综合考虑了P值和R值,是精准率和召回率的调和平均值, 同样,F1值越大,我们可以认为该学习器的性能较好。AP值可以理解为PR曲线向下、向左到X轴和Y轴这片面积之和
-
from sklearn.metrics import average_precision_score AP = average_precision_score(y_true, y_scores, average='macro', pos_label=1, sample_weight=None) print(AP) -
把各个类别(比如汽车、行人、巴士、自行车)的AP值取平均就得到了mAP值。mAP里面那个阈值,是指的
分类问题上的阈值(即判断这个目标是人还是汽车还是摩托车 这个分类),如拿着预测某个类别(如:汽车)的置信度和这个置信度阈值比较,如果置信度大于阈值,则predicted label是True;反之如果predicted confidence低于这个IoU阈值,则predicted label是False。mAP50里面这个IoU指的是定位(打bouding box识别框) 里面这个定位问题的阈值。 判断predicted bbox和ground truth bbox之间的IoU大于 这个IoU阈值 才能被算作 定位上的True。反之,如果predicted bbox和ground truth bbox之间的IoU 小于 这个IoU阈值 定位上 这两个框之间的匹配关系 就是False -
在mAP50里面,这个阈值是针对 定位问题的 交并比(IoU) 的。mAP中的阈值是针对分类问题的。所以这里的mAP50, mAP75, mAP95里面这些50、75、95是针对 定位的bouding box而言的,阈值分别为0.50、0.75、0.95。我们在目标检测中常说的mAP实际指的是mAP50-95。这个mAP50-95是mAP阈值为50%到mAP阈值为95,间隔5%,取得10个mAP值,然后对这十个值取平均。后面是这10个IoU阈值[0.5 0.55 0.6 0.65 0.7 0.75 0.8 0.85 0.9 0.95]。mAP50的阈值最低,要求最宽松,因此一般用于人脸识别的性能评估, mAP80到mAP95,要求比较严格,因此多用于一些对准确性和安全性要求比较高的陈景中如自动驾驶目标检测评估指标mAP:从Precision,Recall,到AP50-95【未完待续】_map50和map50-95-CSDN博客
-
-
YOLOv3 引入了三种不同的检测比例,利用三种不同大小的检测内核:13x13、26x26 和 52x52。这大大提高了对不同大小物体的检测精度。此外,YOLOv3 还增加了一些功能,如每个边界框的多标签预测和更好的特征提取网络。
-
YOLOv4 利用多项创新功能共同优化其性能。这些功能包括加权序列连接 (WRC)、跨阶段部分连接 (CSP)、交叉迷你批归一化 (CmBN)、自对抗训练 (SAT)、误激活、马赛克数据增强、DropBlock 正则化和 CIoU 损失。典型的物体检测器由几个部分组成,包括输入、主干、颈部和头部。YOLOv4 的骨干是在 ImageNet 上预先训练好的,用于预测物体的类别和边界框。骨干可以来自多个模型,包括 VGG、ResNet、ResNeXt 或 DenseNet。检测器的颈部用于收集不同阶段的特征图,通常包括几条自下而上的路径和几条自上而下的路径。头部用于进行最终的物体检测和分类。YOLOv4 还使用了被称为 "bag of freebies "的方法,即在不增加推理成本的情况下,在训练过程中提高模型准确性的技术。数据增强是物体检测中常用的一种 "bag of freebies "技术,它可以增加输入图像的可变性,从而提高模型的鲁棒性。数据增强的一些例子包括光度失真(调整图像的亮度、对比度、色调、饱和度和噪点)和几何失真(添加随机缩放、裁剪、翻转和旋转)。
-
YOLOv5u 整合了无锚点、无对象性的分割头,这一调整完善了模型的架构,从而提高了物体检测任务中的精度-速度权衡。鉴于经验结果及其衍生特征,YOLOv5u 为那些在研究和实际应用中寻求稳健解决方案的人提供了一个高效的替代方案。通过采用无锚分Ultralytics 头,它确保了一种更加灵活和自适应的检测机制,从而提高了在不同场景下的性能。
-
YOLOv6 模型在架构和训练方案上引入了几项显著的改进,包括双向串联(BiC)模块、锚点辅助训练(AAT)策略以及改进的骨干和颈部设计,从而在 COCO 数据集上实现了最先进的精度。双向串行 (BiC) 模块:YOLOv6 在探测器的颈部引入了双向并联(BiC)模块,可增强定位信号并提高性能,而速度降低可忽略不计。锚点辅助训练(AAT)策略:该模型提出的 AAT 可同时享受基于锚和无锚范式的优势,而不会降低推理效率。增强型骨干和颈部设计:通过深化 YOLOv6,在骨干和颈部加入另一个阶段,该模型在高分辨率输入的 COCO 数据集上实现了最先进的性能。自蒸馏策略:为了提高 YOLOv6 较小模型的性能,我们采用了一种新的自蒸馏策略,在训练过程中增强辅助回归分支,在推理过程中去除辅助回归分支,以避免速度明显下降。
-
YOLOv7 引入了几项关键功能:模型重新参数化:YOLOv7 提出了一种有计划的重新参数化模型,这是一种适用于不同网络层的策略,具有梯度传播路径的概念。动态标签分配:多输出层模型的训练提出了一个新问题:"如何为不同分支的输出分配动态目标?为了解决这个问题,YOLOv7 引入了一种新的标签分配方法,即从粗到细的引导标签分配法。扩展和复合缩放:YOLOv7 为实时对象检测器提出了 "扩展 "和 "复合缩放 "方法,可有效利用参数和计算。YOLOv7 提出的方法能有效减少最先进的实时物体检测器约 40% 的参数和 50% 的计算量,推理速度更快,检测精度更高。
-
YOLOv8采用了最先进的骨干和颈部架构,从而提高了特征提取和物体检测性能。无锚分裂Ultralytics 头: YOLOv8 采用无锚分裂Ultralytics 头,与基于锚的方法相比,它有助于提高检测过程的准确性和效率。优化精度与速度之间的权衡: YOLOv8 专注于保持精度与速度之间的最佳平衡,适用于各种应用领域的实时目标检测任务。YOLOv8 系列提供多种模型,每种模型都专门用于计算机视觉中的特定任务。这些模型旨在满足从物体检测到实例分割、姿态/关键点检测、定向物体检测和分类等更复杂任务的各种要求。
-
YOLOv9 引入了可编程梯度信息 (PGI) 和广义高效层聚合网络 (GELAN) 等开创性技术,标志着实时目标检测领域的重大进步。该模型在效率、准确性和适应性方面都有显著提高,在 MS COCO 数据集上树立了新的标杆。YOLOv9 项目虽然是由一个独立的开源团队开发的,但
它建立在以下机构提供的强大代码库基础之上 UltralyticsYOLOv5提供的强大代码库,展示了人工智能研究界的协作精神。YOLOv9 以其创新的方法克服了深度神经网络固有的信息丢失难题,脱颖而出。通过整合 PGI 和多功能 GELAN 架构,YOLOv9 不仅增强了模型的学习能力,还确保了在整个检测过程中保留关键信息,从而实现了卓越的准确性和性能。YOLOv9 代表了实时目标检测领域的关键发展,在效率、准确性和适应性方面都有显著提高。通过 PGI 和 GELAN 等创新解决方案解决关键挑战,YOLOv9 为该领域的未来研究和应用开创了新的先例。随着人工智能领域的不断发展,YOLOv9 充分证明了合作与创新在推动技术进步方面的力量。 -
YOLO-NAS 是一种开创性的物体检测基础模型。它是先进的神经架构搜索技术的产物,经过精心设计,解决了以往YOLO 模型的局限性。YOLO-NAS在量化支持和准确性-延迟权衡方面有了重大改进,是物体检测领域的一次重大飞跃。YOLO-NAS采用了量化感知块和选择性量化技术,以获得最佳性能。该模型在转换为 INT8 量化版本时,精度下降极小,比其他模型有显著提高。这些进步最终形成了一个卓越的架构,具有前所未有的目标检测能力和出色的性能。YOLO-NAS 引入了便于量化的新基本模块,解决了以往YOLO 模型的一个重大局限。利用先进的训练方案和训练后量化来提高性能。采用了 AutoNAC 优化技术,并在 COCO、Objects365 和Roboflow 100 等著名数据集上进行了预训练。这种预训练使其非常适合生产环境中的下游对象检测任务。
-
RT-DETR由百度开发,是一种尖端的端到端物体检测器,可在保持高精度的同时提供实时性能。它利用(ViT)的强大功能,通过解耦尺度内交互和跨尺度融合,高效处理多尺度特征。RT-DETR 具有很强的适应性,支持使用不同的解码器层灵活调整推理速度,无需重新训练。该模型在加速后端(如使用TensorRT 的 CUDA)上表现出色,优于许多其他实时物体检测器。作为编码器输入是主干{S3、S4、S5}的最后三个阶段。高效混合编码器通过级内特征交互(AIFI)和跨尺度特征融合模块(CCFM)将多尺度特征转换为图像特征序列。采用 IoU 感知查询选择,选择固定数量的图像特征作为解码器的初始对象查询。最后,带有辅助预测头的解码器会对对象查询进行迭代优化,以生成方框和置信度分数。高效混合编码器:RT-DETR 采用高效混合编码器,通过解耦尺度内交互和跨尺度融合来处理多尺度特征。这种基于视觉转换器的独特设计降低了计算成本,并可实现实时物体检测。IoU 感知查询选择:利用 IoU 感知查询选择功能改进了对象查询初始化。这使得模型能够关注场景中最相关的物体,从而提高检测精度。可调整的推理速度:支持通过使用不同的解码器层灵活调整推理速度,无需重新训练。这种适应性有助于在各种实时物体检测场景中的实际应用。
-
YOLO -World 模型
引入了先进的实时 UltralyticsYOLOv8-基于开放词汇检测任务的先进实时方法。这项创新可根据描述性文本检测图像中的任何物体。YOLO-World 可大幅降低计算要求,同时保持极具竞争力的性能,是众多视觉应用的多功能工具。采用了视觉语言建模和在大量数据集上进行预训练的方法,能够以无与伦比的效率在零样本场景中出色地识别大量物体。利用 CNN 的计算速度,YOLO-World 可提供快速的开放词汇检测解决方案,满足各行业对即时结果的需求。YOLO-World 可在不牺牲性能的前提下降低计算和资源需求,提供了一种可替代SAM 等模型的强大功能,但计算成本仅为它们的一小部分,从而支持实时应用。引入了 "先提示后检测 "的策略,利用离线词汇进一步提高效率。这种方法可以使用预先计算的自定义提示,包括标题或类别,并将其编码和存储为离线词汇嵌入,从而简化检测过程。速度和效率超过了现有的开放词汇检测器,包括 MDETR 和 GLIP 系列,展示了YOLOv8 在单个 NVIDIA V100 GPU 上的卓越性能。YOLO-World 框架允许通过自定义提示动态指定类别,使用户能够根据自己的特定需求定制模型,而无需重新训练。这一功能对于调整模型以适应新领域或特定任务(这些任务最初并不属于训练数据的一部分)尤其有用。通过设置自定义提示,用户基本上可以引导模型关注感兴趣的对象,从而提高检测结果的相关性和准确性。 -
2015 年推出了YOLO ,因其高速度和高精确度而迅速受到欢迎。
-
2016 年发布的YOLOv2 通过纳入批量归一化、锚框和维度集群改进了原始模型。
-
2018 年推出的YOLOv3 使用更高效的骨干网络、多锚和空间金字塔池进一步增强了模型的性能。
-
2020 年发布了YOLOv4 ,引入了 Mosaic 数据增强、新的无锚检测头和新的损失函数等创新技术。
-
YOLOv5进一步提高了模型的性能,并增加了超参数优化、集成跟踪和自动导出为常用导出格式等新功能。
-
2022 年由美团开源了YOLOv6,目前已用于该公司的许多自主配送机器人。
-
2022年YOLOv7增加了额外的任务,如 COCO 关键点数据集的姿势估计。
-
Ultralytics 为各种数据集提供支持,以促进检测、实例分割、姿态估计、分类和多目标跟踪等计算机视觉任务。为数据集创建嵌入、搜索相似图像、运行 SQL 查询、执行语义搜索,甚至使用自然语言进行搜索!您可以使用我们的图形用户界面应用程序或使用应用程序接口创建自己的应用程序。点击此处了解更多。
-
出现安装错误有多种原因,如版本不兼容、缺少依赖项或环境设置不正确。建议您使用Python 3.8 或更高版本。确保安装了正确版本的PyTorch (1.8 或更高版本)。考虑使用虚拟环境来避免冲突。验证 CUDA 兼容性和安装:确保您的 GPU 与 CUDA 兼容,并正确安装了 CUDA。使用 nvidia-smi 命令来检查英伟达™(NVIDIA®)GPU 的状态和 CUDA 版本。检查PyTorch 和 CUDA 集成:确保PyTorch 可以使用 CUDA,方法是运行 import torch; print(torch.cuda.is_available()) 在Python 终端中执行。如果返回 “True”,则表示PyTorch 已设置为使用 CUDA。
-
坐标格式:YOLOv8 以绝对像素值提供边界框坐标。要将其转换为相对坐标(范围从 0 到 1),需要除以图像尺寸。例如,假设图像尺寸为 640x640。那么您需要执行以下操作:
-
# Convert absolute coordinates to relative coordinates x1 = x1 / 640 # Divide x-coordinates by image width x2 = x2 / 640 y1 = y1 / 640 # Divide y-coordinates by image height y2 = y2 / 640
-
-
有些类别的 AP 比其他类别低得多,即使总的 mAP 还不错。这些类别对模型来说可能更具挑战性。在训练过程中为这些类别使用更多数据或调整类别权重可能会有所帮助。
-
在多线程环境中运行YOLO 模型需要仔细考虑,以确保线程安全。Python’s
threading模块允许您同时运行多个线程,但在这些线程中使用YOLO 模型时,需要注意一些重要的安全问题。Python 线程是一种并行方式,允许程序同时运行多个操作。不过,Python 的全局解释器锁(GIL)意味着一次只能有一个线程执行Python 字节码。虽然这听起来像是一种限制,但线程仍然可以提供并发性,尤其是在 I/O 绑定操作或使用释放 GIL 的操作(如由YOLO 的底层 C 库执行的操作)时。-
在Python 中使用线程时,识别可能导致并发问题的模式非常重要。以下是应该避免的情况:在多个线程中共享单个YOLO 模型实例。
-
# Unsafe: Sharing a single model instance across threads from ultralytics import YOLO from threading import Thread # Instantiate the model outside the thread shared_model = YOLO("yolov8n.pt") def predict(image_path): results = shared_model.predict(image_path) # Process results # Starting threads that share the same model instance Thread(target=predict, args=("image1.jpg",)).start() Thread(target=predict, args=("image2.jpg",)).start() -
在上面的例子中
shared_model被多个线程使用,这可能导致不可预测的结果,因为predict可由多个线程同时执行。 -
# Unsafe: Sharing multiple model instances across threads can still lead to issues from ultralytics import YOLO from threading import Thread # Instantiate multiple models outside the thread shared_model_1 = YOLO("yolov8n_1.pt") shared_model_2 = YOLO("yolov8n_2.pt") def predict(model, image_path): results = model.predict(image_path) # Process results # Starting threads with individual model instances Thread(target=predict, args=(shared_model_1, "image1.jpg")).start() Thread(target=predict, args=(shared_model_2, "image2.jpg")).start() -
即使有两个独立的模型实例,并发问题的风险仍然存在。如果
YOLO不是线程安全的,使用单独的实例可能无法防止竞赛条件,特别是如果这些实例共享任何非线程本地的底层资源或状态。要执行线程安全推理,应在每个线程中实例化一个单独的YOLO 模型。这样可以确保每个线程都有自己独立的模型实例,从而消除出现竞赛条件的风险。 -
# Safe: Instantiating a single model inside each thread from ultralytics import YOLO from threading import Thread def thread_safe_predict(image_path): # Instantiate a new model inside the thread local_model = YOLO("yolov8n.pt") results = local_model.predict(image_path) # Process results # Starting threads that each have their own model instance Thread(target=thread_safe_predict, args=("image1.jpg",)).start() Thread(target=thread_safe_predict, args=("image2.jpg",)).start() -
每个线程都创建了自己的
YOLO实例。这可以防止任何线程干扰另一个线程的模型状态,从而确保每个线程都能安全地执行推理,而不会与其他线程发生意外的交互。对于更高级的应用场景,要进一步优化多线程推理性能,可以考虑使用基于进程的并行性与multiprocessing或利用带有专用工作进程的任务队列。
-
-
YOLOv5 目标检测算法中使用的数据增强比较多,包括:
- Mosaic 马赛克,RandomAffine 随机仿射变换,MixUp,图像模糊等采用 Albu 库实现的变换,HSV 颜色空间增强,随机水平翻转
-
Ultralytics YOLO 使用遗传算法优化超参数。遗传算法的灵感来源于自然选择和遗传学机制。突变:突变有助于局部搜索超参数空间,方法是对现有超参数进行微小的随机改变,产生新的候选参数供评估。交叉:虽然交叉是一种流行的遗传算法技术,但目前在Ultralytics YOLO 中并未用于超参数调整。重点主要放在产生新超参数集的突变上。
-
SAHI(切片辅助超推理)是一个创新库,旨在优化大规模高分辨率图像的物体检测算法。其核心功能在于将图像分割成易于管理的切片,在每个切片上运行物体检测,然后将结果拼接在一起。SAHI 与包括YOLO 系列在内的一系列物体检测模型兼容,从而在确保优化使用计算资源的同时提供了灵活性。无缝集成:SAHI 可毫不费力地与YOLO 模型集成,这意味着您无需修改大量代码即可开始切片和检测。资源效率:通过将大图像分解成较小的部分,SAHI 可优化内存使用,让您在资源有限的硬件上运行高质量的检测。高精度:SAHI 采用智能算法,在拼接过程中合并重叠的检测框,从而保持检测精度。减轻计算负担:较小的图像切片处理速度更快,内存消耗更少,可在低端硬件上更流畅地运行。保持检测质量:由于每个切片都是独立处理的,因此只要切片足够大,能够捕捉到感兴趣的物体,物体检测的质量就不会降低。增强的可扩展性:该技术可以更容易地在不同尺寸和分辨率的图像上进行物体检测,因此非常适合从卫星图像到医疗诊断的广泛应用。
-
pip install -U sahi from sahi import AutoDetectionModel from sahi.utils.cv import read_image from sahi.utils.file import download_from_url from sahi.predict import get_prediction, get_sliced_prediction, predict # 实例化YOLOv8 模型,用于对象检测 detection_model = AutoDetectionModel.from_pretrained( model_type='yolov8', model_path=yolov8_model_path, confidence_threshold=0.3, device="cpu", # or 'cuda:0' ) # 通过指定切片尺寸和重叠率来执行切片推理 result = get_sliced_prediction( "demo_data/small-vehicles1.jpeg", detection_model, slice_height=256, slice_width=256, overlap_height_ratio=0.2, overlap_width_ratio=0.2 ) # 从任何 coco 格式的数据集创建切片的 coco 数据集, from sahi.slicing import slice_coco coco_dict, coco_path = slice_coco( coco_annotation_file_path=coco_annotation_file_path, image_dir=image_dir, slice_height=256, slice_width=256, overlap_height_ratio=0.2, overlap_width_ratio=0.2, )
-
-
Docker是一个在容器中开发、运输和运行应用程序的平台。它尤其有利于确保软件无论部署在哪里,都能以相同的方式运行。
-
通过 CSI 电缆将 Pi 摄像头连接到 Raspberry Pi,然后安装 64 位 Raspberry Pi 操作系统。使用以下命令验证摄像头:libcamera-hello
-
使用集成终端查看图像的 VSCode 兼容协议有
sixel和iTerm.本指南将演示如何使用sixel协议。首先,您必须启用设置terminal.integrated.enableImages和terminal.integrated.gpuAcceleration在 VSCode 中。安装python-sixel库。pip install sixel;-
import io import cv2 as cv from ultralytics import YOLO from sixel import SixelWriter # Load a model model = YOLO("yolov8n.pt") # Run inference on an image results = model.predict(source="ultralytics/assets/bus.jpg") # Plot inference results plot = results[0].plot() # Results image as bytes im_bytes = cv.imencode( ".png", plot, )[1].tobytes() # Image bytes as a file-like object mem_file = io.BytesIO(im_bytes) # Create sixel writer object w = SixelWriter() # Draw the sixel image in the terminal w.draw(mem_file)
-
-
对于训练包含负样本的情况,确实可以将正样本(有标注的图像)和负样本(没有任何目标对象的图像)混合在一起进行训练。在准备负样本的标注文件时,请确保这些文件为空,这样模型就能学习到这些图像中不包含任何感兴趣的目标。这种方法
有助于模型更好地理解背景信息,从而减少误检率。 -
coco人体关键点检测数据集标注格式
-
"info"开篇是一些基础信息。 -
"licenses"许可证。 -
"categories"对于每个"person",都有 17个"keypoints",他们的连接方式如"skeleton"。-
{"keypoints":[ "nose", "left_eye", "right_eye", "left_ear", "right_ear", "left_shoulder", "right_shoulder", "left_elbow", "right_elbow", "left_wrist", "right_wrist", "left_hip", "right_hip", "left_knee", "right_knee", "left_ankle", "right_ankle", ],}
-
-
"images"一些关键词信息,比如文件名、尺寸等。 -
"annotations"这里有两个关键字段,"num_keypoints"表示被标注的关键点数目;"keypoints"表示关键点坐标 ( x , y ) (x, y) (x,y) 和可见否标志 v v v 。v=0 ,表示没有标注,此时 x=y=0 ; v=1表示有标注坐标,但是,关节点不可见(被遮挡等);v=2 表示有标注坐标,关节点可见.
-
-
对于人体骨骼关键点算法来说,如何有效的衡量一个算法的好坏非常重要,他不像分类问题那样可以很容易采用一些常用指标,例如precise、error、F-score等进行计算。因为在衡量的过程中,我们无法有效的将预测结果与真实值一一对应,无法知道他们之前的对应关系,更加无法知道当前的某个预测结果是否出现了误检或者漏检的情况。因此,构建一个合适的人体关键点的度量指标很重要。目前最为常用的就是OKS(Object Keypoint Similarity)指标,这个指标启发于目标检测中的IoU指标,目的就是为了计算真值和预测人体关键点的相似度。
-
O K S p = Σ i [ e x p ( − d p i 2 / 2 s p 2 θ i 2 ) δ ( v p i = 1 ) ] / Σ i [ δ ( v p i > 0 ) ] OKS_p = Σ_i[exp(-d_{pi}^2/2s^2_p\theta^2_i)δ(v_{pi}=1)] / Σ_i[δ(v_{pi}>0)] OKSp=Σi[exp(−dpi2/2sp2θi2)δ(vpi=1)]/Σi[δ(vpi>0)]
-
p表示groudtruth中,人的id,i 表示keypoint的id, d p i d_{pi} dpi表示groudtruth中每个人和预测的每个人的关键点的欧氏距离, s p s_p sp表示当前人的尺度因子,这个值等于此人在groundtruth中所占面积的平方根,即 ( x 2 − x 1 ) ( y 2 − y 1 ) \sqrt{(x_2-x_1)(y_2-y_1)} (x2−x1)(y2−y1)。 θ i \theta_i θi 表示第 i 个骨骼点的归一化因子,这个因此是通过对数据集中所有groundtruth计算的标准差而得到的,反映出当前骨骼点标注时候的标准差, θ \theta θ 越大表示这个点越难标注。 v p i v_{pi} vpi代表第p个人的第i个关键点是否可见
-
-
Mosaic 属于混合类数据增强,因为它在运行时候需要 4 张图片拼接,变相的相当于增加了训练的 batch size。其运行过程简要概况为:
- 随机生成拼接后 4 张图的交接中心点坐标,此时就相当于确定了 4 张拼接图片的交接点
- 随机选出另外 3 张图片的索引以及读取对应的标注
- 对每张图片采用保持宽高比的 resize 操作将其缩放到指定大小
- 按照上下左右规则,计算每张图片在待输出图片中应该放置的位置,因为图片可能出界故还需要计算裁剪坐标
- 利用裁剪坐标将缩放后的图片裁剪,然后贴到前面计算出的位置,其余位置全部补 114 像素值
- 对每张图片的标注也进行相应处理
-
由于拼接了 4 张图,所以输出图片面积会扩大 4 倍,从 640x640 变成 1280x1280,因此要想恢复为 640x640, 必须要再接一个 RandomAffine 随机仿射变换,否则图片面积就一直是扩大 4 倍的。随机仿射变换包括平移、旋转、缩放、错切等几何增强操作,同时由于 Mosaic 和 RandomAffine 属于比较强的增强操作,会引入较大噪声,因此需要对增强后的标注进行处理,过滤规则为:
- 增强后的 gt bbox 宽高要大于 wh_thr
- 增强后的 gt bbox 面积和增强前的 gt bbox 面积比要大于 ar_thr,防止增强太严重
- 最大宽高比要小于 area_thr,防止宽高比改变太多
-
YOLOv5 网络结构是标准的
CSPDarknet+PAFPN+非解耦 Head。YOLOv5 网络结构大小由deepen_factor和widen_factor两个参数决定。其中deepen_factor控制网络结构深度,即CSPLayer中DarknetBottleneck模块堆叠的数量;widen_factor控制网络结构宽度,即模块输出特征图的通道数。以 YOLOv5-l 为例,其deepen_factor = widen_factor = 1.0。如果想使用 netron 可视化网络结构图细节,可以直接在 netron 中将 MMDeploy 导出的 ONNX 文件格式文件打开。Stem Layer是 1 个 6x6 kernel 的ConvModule,相较于 v6.1 版本之前的Focus模块更加高效。- 除了最后一个
Stage Layer,其他均由 1 个ConvModule和 1 个CSPLayer组成。 其中ConvModule为 3x3的Conv2d+BatchNorm+SiLU 激活函数。CSPLayer即 YOLOv5 官方仓库中的 C3 模块,由 3 个ConvModule+ n 个DarknetBottleneck(带残差连接) 组成。相对于ReLU函数,SiLU函数在接近零时具有更平滑的曲线,并且由于其使用了sigmoid函数,可以使网络的输出范围在0和1之间。 y = x ⋅ s i g m o i d ( β x ) y=x·sigmoid(\beta x) y=x⋅sigmoid(βx),在使用SiLU时,如果数据存在过大或过小的情况,可能会导致梯度消失或梯度爆炸,因此需要进行一些调整,例如对输入数据进行归一化等。而ReLU在这方面较为稳定,不需要过多的处理。 - 最后一个
Stage Layer在最后增加了SPPF模块。SPPF模块是将输入串行通过多个 5x5 大小的MaxPool2d层,与SPP模块效果相同,但速度更快。 - P5 模型会在
Stage Layer2-4 之后分别输出一个特征图进入Neck结构。以 640x640 输入图片为例,其输出特征为 (B,256,80,80)、(B,512,40,40) 和 (B,1024,20,20),对应的 stride 分别为 8/16/32。 - P6 模型会在
Stage Layer2-5 之后分别输出一个特征图进入Neck结构。以 1280x1280 输入图片为例,其输出特征为 (B,256,160,160)、(B,512,80,80)、(B,768,40,40) 和 (B,1024,20,20),对应的 stride 分别为 8/16/32/64。 - Neck 模块输出的特征图和 Backbone 完全一致。即 P5 模型为 (B,256,80,80)、 (B,512,40,40) 和 (B,1024,20,20);P6 模型为 (B,256,160,160)、(B,512,80,80)、(B,768,40,40) 和 (B,1024,20,20)。
- YOLOv5 Head 结构和 YOLOv3 完全一样,为
非解耦 Head,即分类和 bbox 检测等都是在同一个卷积的不同通道中完成。Head 模块只包括 3 个不共享权重的卷积,用于将输入特征图进行变换而已。以 COCO 80 类为例:- P5 模型在输入为 640x640 分辨率情况下,其 Head 模块输出的 shape 分别为
(B, 3x(4+1+80),80,80),(B, 3x(4+1+80),40,40)和(B, 3x(4+1+80),20,20)。 - P6 模型在输入为 1280x1280 分辨率情况下,其 Head 模块输出的 shape 分别为
(B, 3x(4+1+80),160,160),(B, 3x(4+1+80),80,80),(B, 3x(4+1+80),40,40)和(B, 3x(4+1+80),20,20)。 - 其中 3 表示 3 个 anchor,4 表示 bbox 预测分支,1 表示 obj 预测分支,80 表示 COCO 数据集类别预测分支。
- P5 模型在输入为 640x640 分辨率情况下,其 Head 模块输出的 shape 分别为
-
正负样本匹配策略的核心是确定预测特征图的所有位置中哪些位置应该是正样本,哪些是负样本,甚至有些是忽略样本。 匹配策略是目标检测算法的核心,一个好的匹配策略可以显著提升算法性能。YOLOV5 的匹配策略简单总结为:采用了 anchor 和 gt_bbox 的 shape 匹配度作为划分规则,同时引入跨邻域网格策略来增加正样本。 其主要包括如下两个核心步骤:
- 对于任何一个输出层,抛弃了常用的基于 Max IoU 匹配的规则,而是直接采用 shape 规则匹配,也就是该 GT Bbox 和当前层的 Anchor 计算宽高比,如果宽高比例大于设定阈值,则说明该 GT Bbox 和 Anchor 匹配度不够,将该 GT Bbox 暂时丢掉,在该层预测中该 GT Bbox 对应的网格内的预测位置认为是负样本
- 对于剩下的 GT Bbox(也就是匹配上的 GT Bbox),计算其落在哪个网格内,同时利用四舍五入规则,找出最近的两个网格,将这三个网格都认为是负责预测该 GT Bbox 的,可以粗略估计正样本数相比之前的 YOLO 系列,至少增加了三倍
-
YOLOv5 是 Anchor-based 的目标检测算法,其 Anchor size 的获取方式与 YOLOv3 类似,也是使用聚类获得,其不同之处在于聚类使用的标准不再是基于 IoU 的,而是使用形状上的宽高比作为聚类准则(即 shape-match )。
-
在 Anchor-based 算法中,预测框通常会基于 Anchor 进行变换,然后预测变换量,这对应 GT Bbox 编码过程,而在预测后需要进行 Pred Bbox 解码,还原为真实尺度的 Bbox,这对应 Pred Bbox 解码过程。在 YOLOv3 中,回归公式为:
-
b x = s i g m o i d ( t x ) + c x b y = s i g m o i d ( t y ) + c y b w = a w ⋅ e t w b y = a h ⋅ e t y a w 为 a n c h o r 的宽度, c x 为 G r i d 的坐标 b_x=sigmoid(t_x)+c_x\\ b_y=sigmoid(t_y)+c_y\\ b_w=a_w·e^{t_w}\\ b_y=a_h·e^{t_y}\\ a_w为anchor的宽度,c_x为Grid的坐标 bx=sigmoid(tx)+cxby=sigmoid(ty)+cybw=aw⋅etwby=ah⋅etyaw为anchor的宽度,cx为Grid的坐标
-
在 YOLOv5 中,回归公式为:
-
b x = ( 2 ∗ s i g m o i d ( t x ) − 0.5 ) + c x b y = ( 2 ∗ s i g m o i d ( t y ) − 0.5 ) + c y b w = a w ⋅ ( 2 ⋅ s i g m o i d ( t w ) ) 2 b h = a h ⋅ ( 2 ⋅ s i g m o i d ( t h ) ) 2 b_x=(2*sigmoid(t_x)-0.5)+c_x\\ b_y=(2*sigmoid(t_y)-0.5)+c_y\\ b_w=a_w·(2·sigmoid(t_w))^2\\ b_h=a_h·(2·sigmoid(t_h))^2 bx=(2∗sigmoid(tx)−0.5)+cxby=(2∗sigmoid(ty)−0.5)+cybw=aw⋅(2⋅sigmoid(tw))2bh=ah⋅(2⋅sigmoid(th))2
-
中心点坐标范围从 (0, 1) 调整至 (-0.5, 1.5),以上策略能适度缓解目标检测中常见的正负样本不均衡问题。宽高比从(0,+∞)转变为(0,4*a_{wh})宽高回归公式中 exp(x) 是无界的,这会导致梯度失去控制,造成训练不稳定。YOLOv5 中改进后的宽高回归公式优化了此问题。
-
-
YOLOv5 中总共包含 3 个 Loss,分别为:
-
Classes loss:使用的是 BCE loss
-
Objectness loss:使用的是 BCE loss
-
Location loss:使用的是 CIoU loss
-
L o s s = λ 1 L c l s + λ 2 L o b j + λ 3 L l o c Loss=\lambda_1 L_{cls}+\lambda_2 L_{obj}+\lambda_3 L_{loc} Loss=λ1Lcls+λ2Lobj+λ3Lloc
-
P3、P4、P5 层对应的 Objectness loss 按照不同权重进行相加,默认的设置是,obj_level_weights=[4., 1., 0.4]
-
L o b j = 4.0 ∗ L o b j s m a l l + 1.0 ∗ L o b j m e d i u m + 0.4 ∗ L o b j l a r g e + L_{obj}=4.0*L^{small}_{obj}+1.0*L^{medium}_{obj}+0.4*L^{large}_{obj}+ Lobj=4.0∗Lobjsmall+1.0∗Lobjmedium+0.4∗Lobjlarge+
-
CIoU α = ( i o u s > 0.5 ) . f l o a t ( ) ∗ v / ( 1 − i o u s + v ) \alpha = (ious > 0.5).float() * v / (1 - ious + v) α=(ious>0.5).float()∗v/(1−ious+v)
-
-
将优化参数分成 Conv/Bias/BN 三组,在 WarmUp 阶段,不同组采用不同的 lr 以及 momentum 更新曲线。 同时在 WarmUp 阶段采用的是 iter-based 更新策略,而在非 WarmUp 阶段则变成 epoch-based 更新策略
-
针对不同的 batch size 采用了不同的 weight decay 策略,具体来说为:
- 当训练 batch size <= 64 时,weight decay 不变
- 当训练 batch size > 64 时,weight decay 会根据总 batch size 进行线性缩放
-
为了最大化不同 batch size 情况下的性能,作者设置总 batch size 小于 64 时候会自动开启梯度累加功能。使用了 EMA 策略平滑模型,没有采用多尺度训练策略,同时可以开启 cudnn.benchmark 进一步加速训练,默认采用 AMP 自动混合精度训练
-
yolov5后处理过程
关于yolov8文档的记录,补充一些整理的知识点
news2026/2/15 13:16:47

本文来自互联网用户投稿,该文观点仅代表作者本人,不代表本站立场。本站仅提供信息存储空间服务,不拥有所有权,不承担相关法律责任。如若转载,请注明出处:http://www.coloradmin.cn/o/1510253.html
如若内容造成侵权/违法违规/事实不符,请联系多彩编程网进行投诉反馈,一经查实,立即删除!相关文章

什么是防静电晶圆隔离膜?一分钟让你了解抗静电晶圆隔离纸
防静电晶圆隔离膜,也被称为防静电蓄积纸、硅片纸、半导体晶圆盒内缓冲垫片等多种名称,是半导体制造和运输过程中的一种重要辅助材料。 该隔离膜具备多种特性,如防静电、无尘、不掉屑、强韧耐用等,这些特性使其在半导体制造和运输中…
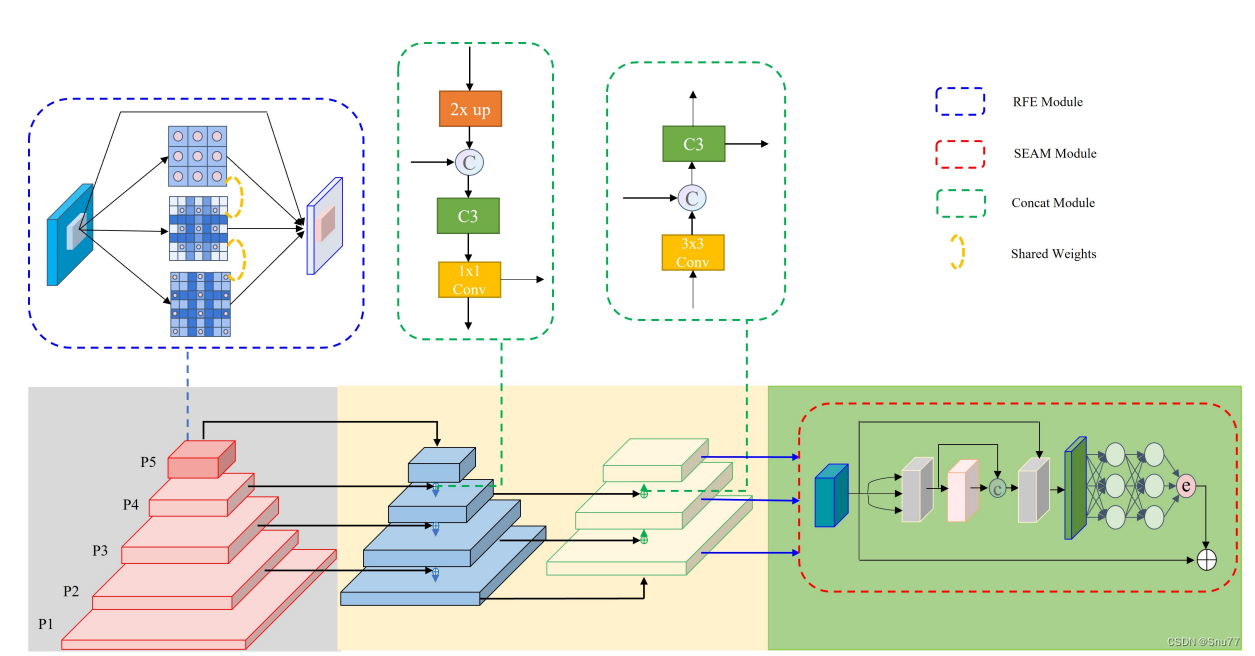
YOLOv8改进 | 注意力机制 | 添加YOLO-Face提出的SEAM注意力机制优化物体遮挡检测(附代码 + 修改教程)
一、本文介绍
本文给大家带来的改进机制是由YOLO-Face提出能够改善物体遮挡检测的注意力机制SEAM,SEAM(Spatially Enhanced Attention Module)注意力网络模块旨在补偿被遮挡面部的响应损失,通过增强未遮挡面部的响应来实现这一目标,其希望通过学习遮挡面和未遮挡面之间的…

腾轩科技传媒讲解百度百科词条品牌怎么创建?
品牌百度百科是为企业或个人创建的一个专门展示品牌信息、活动、产品等内容的百度百科页面。通过品牌百度百科,企业可以向用户展示其核心价值、产品特色,提升品牌知名度,并在互联网上建立一个权威的品牌形象。本文腾轩科技传媒讲解百度百科词…

VMware Workstation Pro17 详细安装步骤
VMware Workstation(中文名“威睿工作站”)是一款功能强大的桌面虚拟计算机软件,提供用户可在单一的桌面上同时运行不同的操作系统,和进行开发、测试 、部署新的应用程序的最佳解决方案。VMware Workstation可在一部实体机器上模拟…

力扣--动态规划/深度优先算法/回溯算法93.复原IP地址
这题主要用了动态规划和回溯算法。 动态规划数组初始化(DP数组): 首先,创建一个二维数组dp,用于记录字符串中哪些部分是合法的IP地址。对字符串进行遍历,同时考虑每个可能的IP地址部分(每部分由1到3个字符组…
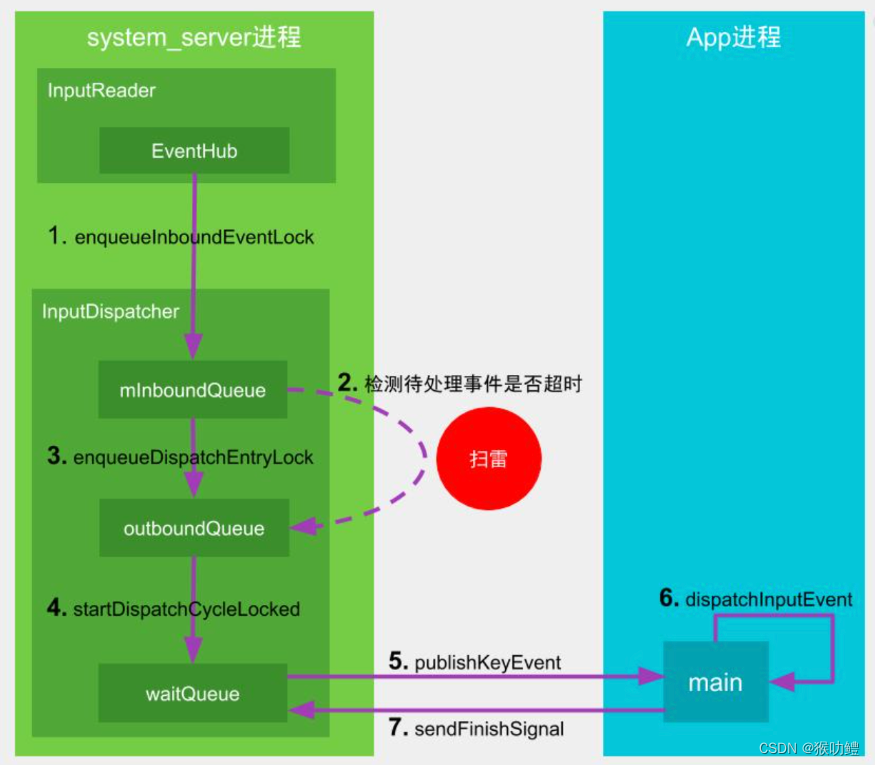
Android中ANR机制
Android中的ANR分为两种,前台ANR和后台ANR。 前台ANR,是指ANR时对用户可感知,比如拥有当前前台可见的activity的进程,或者拥有前台通知的fg-service的进程,这些是用户可感知的场景。前台ANR,会出现一个系统…

岩土工程监测中振弦采集仪的选型指南与市场概况
岩土工程监测中振弦采集仪的选型指南与市场概况
振弦采集仪是岩土工程监测中常用的一种设备,用于测量土体的振动特性。它的选型指南和市场概况如下: 选型指南: 1. 测量参数:振弦采集仪可用于测量土体的振动振幅、频率、相位等参数…
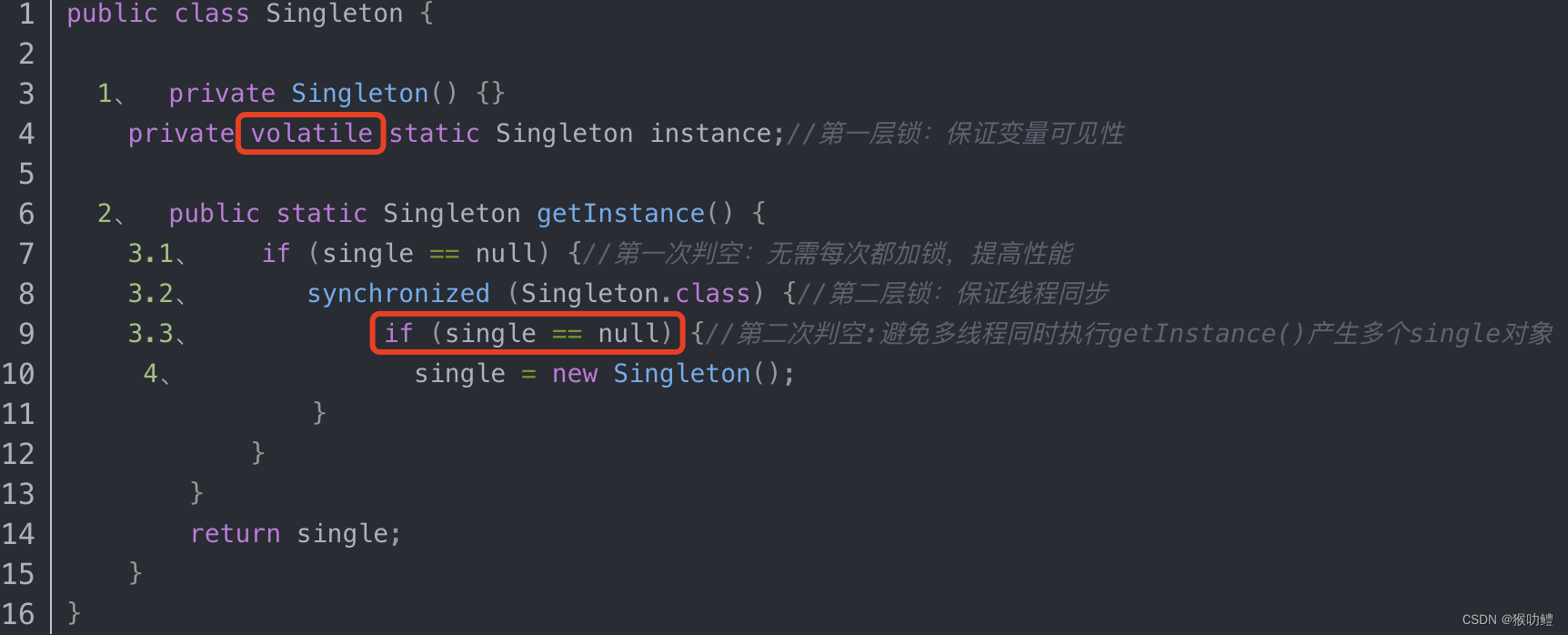
Android中单例模式正确实现方式
1. 饿汉模式 -线程安全 在类加载时进行实例化, 线程安全,但会导致类加载时间变长。饿汉模式如果使用过多,可能会对App启动耗时带来不利影响。 2. 懒汉模式 -线程不安全 没有加锁, 因此线程不安全。 3. 两次判空 加同步锁 -线程不…
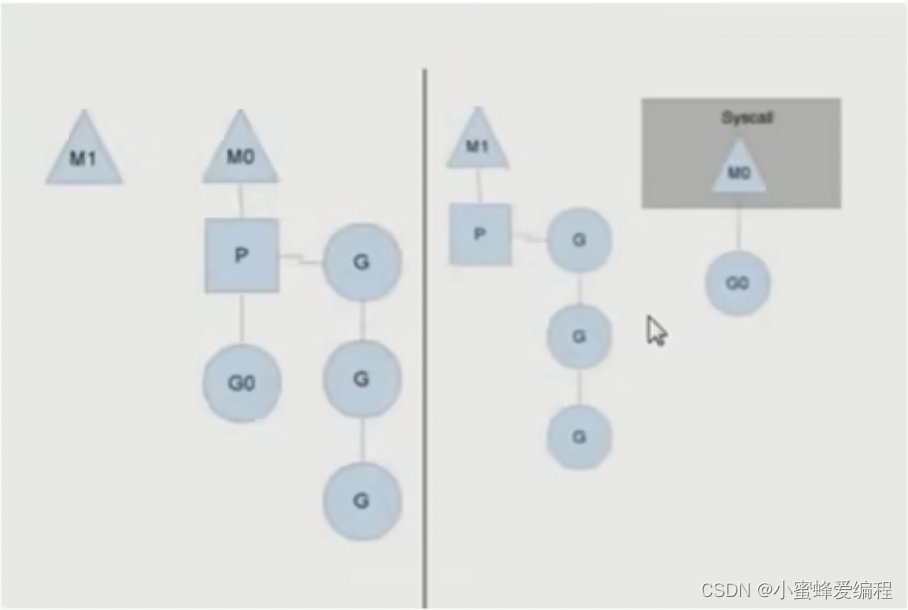
go语言基础 -- goroutine与管道
go协程特点
一个线程上可以起多个goroutine,goroutine有以下特点:
有独立的栈空间共享程序堆空间调度由用户控制
下面是一个简单的协程使用案例:
package main
import("fmt""strconv"
)func test() {for i : 0; i &l…

18-任务管理常用API函数
任务挂起函数
void vTaskSuspend(TaskHandle_t xTaskToSuspend) void vTaskSuspendAll(void)——挂起所有任务 其实就是将调度器锁定,直白点挂起所有的任务,就是挂起任务调度器,调度器被挂起后,就不可以进行上下文的切换…
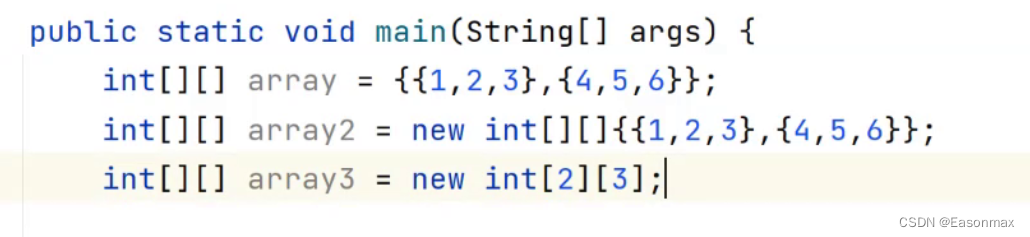
java中数组的定义与使用
Java中的数组跟c语言的数组几乎不一样,我们要区分对待。在之后你就能理解到我为什么说这句话了。
1.java中数组的创建与初始化
数组的创建
如下,皆为数组的创建。
double[] a;
int[] b;
创建时的[]里面绝对不能填数字。 数组的初始化
主要分为动态…

【Python】一文带你了解如何获取 Python模块 安装路径
【Python】一文带你了解如何获取 Python模块 安装路径 🌈 个人主页:高斯小哥 🔥 高质量专栏:Matplotlib之旅:零基础精通数据可视化、Python基础【高质量合集】、PyTorch零基础入门教程👈 希望得到您的订阅…

MyBatis进阶篇
MyBatis MyBtias工具类参数入参参数是单个参数参数是多个参数入参是POJO对象入参是Map类型 自动主键增长#{}和${}两种获取参数方式结果映射动态SQLMyBatis多表查询MyBatis注解开发 MyBtias工具类
SessionUtils.java import org.apache.ibatis.io.Resources;
import org.apache…

当HR问你:“什么事会让你有成就感”你该怎么回答?【文章底部添加进大学生就业交流群】
当HR问你“什么事会让你有成就感”时,你可以通过以下方式回答: 强调目标实现: 表达你在达成挑战性目标时感到的满足感。举例说明你在过去的工作或项目中如何设定并成功实现了目标。 强调对团队成功的贡献: 谈论你与团队合作取得成…

力扣每日一题 将标题首字母大写 模拟 String API
Problem: 2129. 将标题首字母大写 文章目录 思路复杂度Code 思路
👨🏫 灵神题解
复杂度
⏰ 时间复杂度: O ( n ) O(n) O(n) 🌎 空间复杂度: O ( n ) O(n) O(n)
Code
class Solution {public String capitalizeTitle(String title)…

leetcode 25、k个一组翻转链表
给你链表的头节点 head ,每 k 个节点一组进行翻转,请你返回修改后的链表。
k 是一个正整数,它的值小于或等于链表的长度。如果节点总数不是 k 的整数倍,那么请将最后剩余的节点保持原有顺序。
你不能只是单纯的改变节点内部的值…

C++程序设计-练手题集合【期末复习|考研复习】
前言 总结整理不易,希望大家点赞收藏。 给大家整理了一下C程序设计中的练手题,以供大家期末复习和考研复习的时候使用。 C程序设计系列文章传送门: 第一章 面向对象基础 第四/五章 函数和类和对象 第六/七/八章 运算符重载/包含与继承/虚函数…
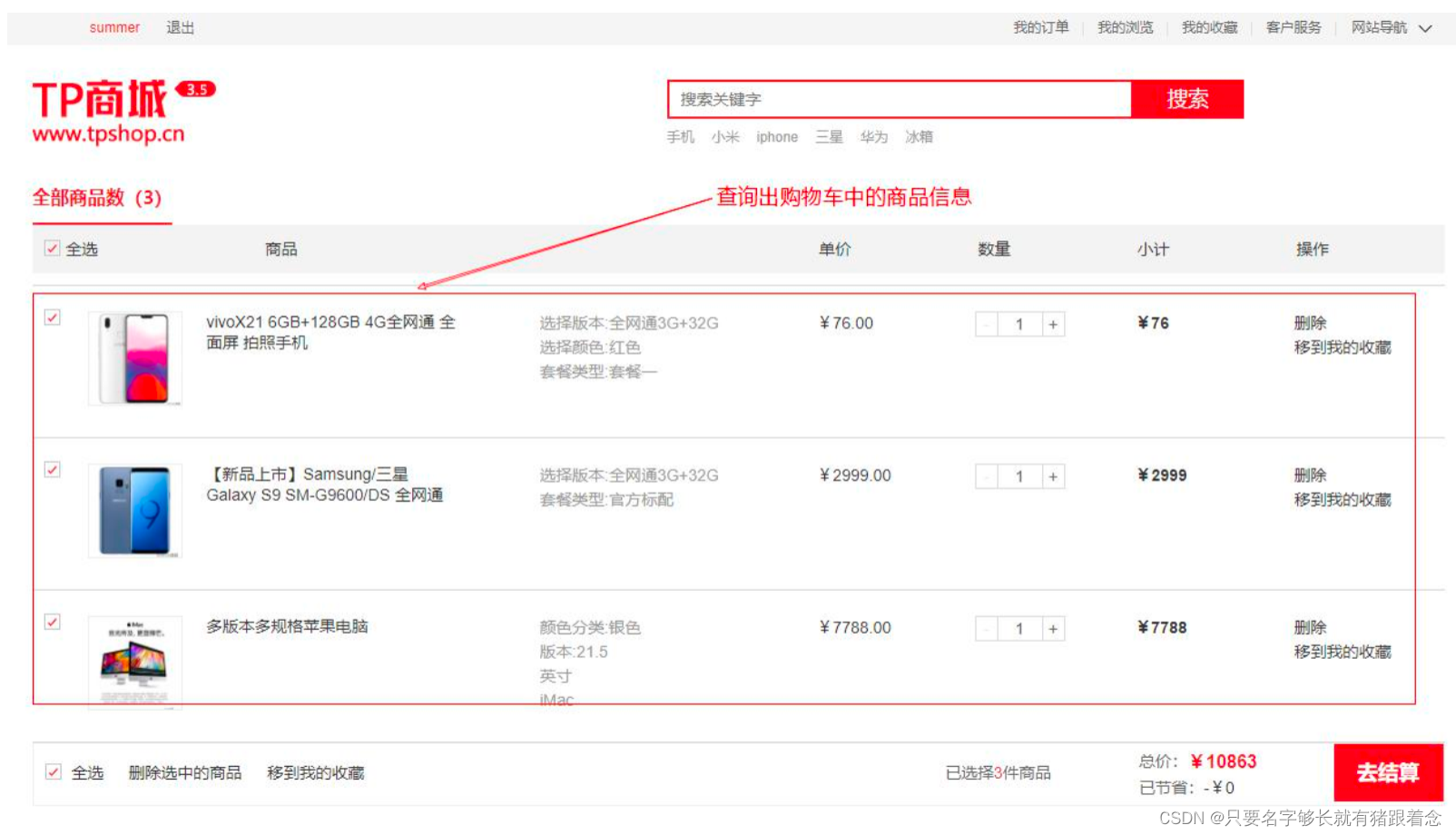
项目实战-tpshop商城项目
项目实战-tpshop商城项目 环境部署准备软件工具准备远程连接测试远程连接测试-查看虚拟机IP地址远程连接测试-检测本机与虚拟机是否连通远程连接测试-通过远程工具连接linux服务器 常见问题处理 环境部署项目技术架构介绍部署tpshop项目-tpshop验证数据库验证用户信息表熟悉商品…
API接口数据集接口pytorch api接口获取数据
API是应用程序的开发接口,在开发程序的时候,我们有些功能可能不需要从到到位去研发,我们可以拿现有的开发出来的功能模块来使用,而这个功能模块,就叫做库(libary)。比如说:要实现数据传输的安全,…

这五款高性能骨传导耳机入手不后悔!附带骨传导耳机选购攻略!
随着健康生活的逐渐流行,越来越多的人开始注重运动和健身,在这一背景下,骨传导耳机作为当下最热门的健身装备,已成为市场上最受欢迎的产品之一,随着骨传导耳机的热度增高,与此同时也引发了一些不良商家和劣…