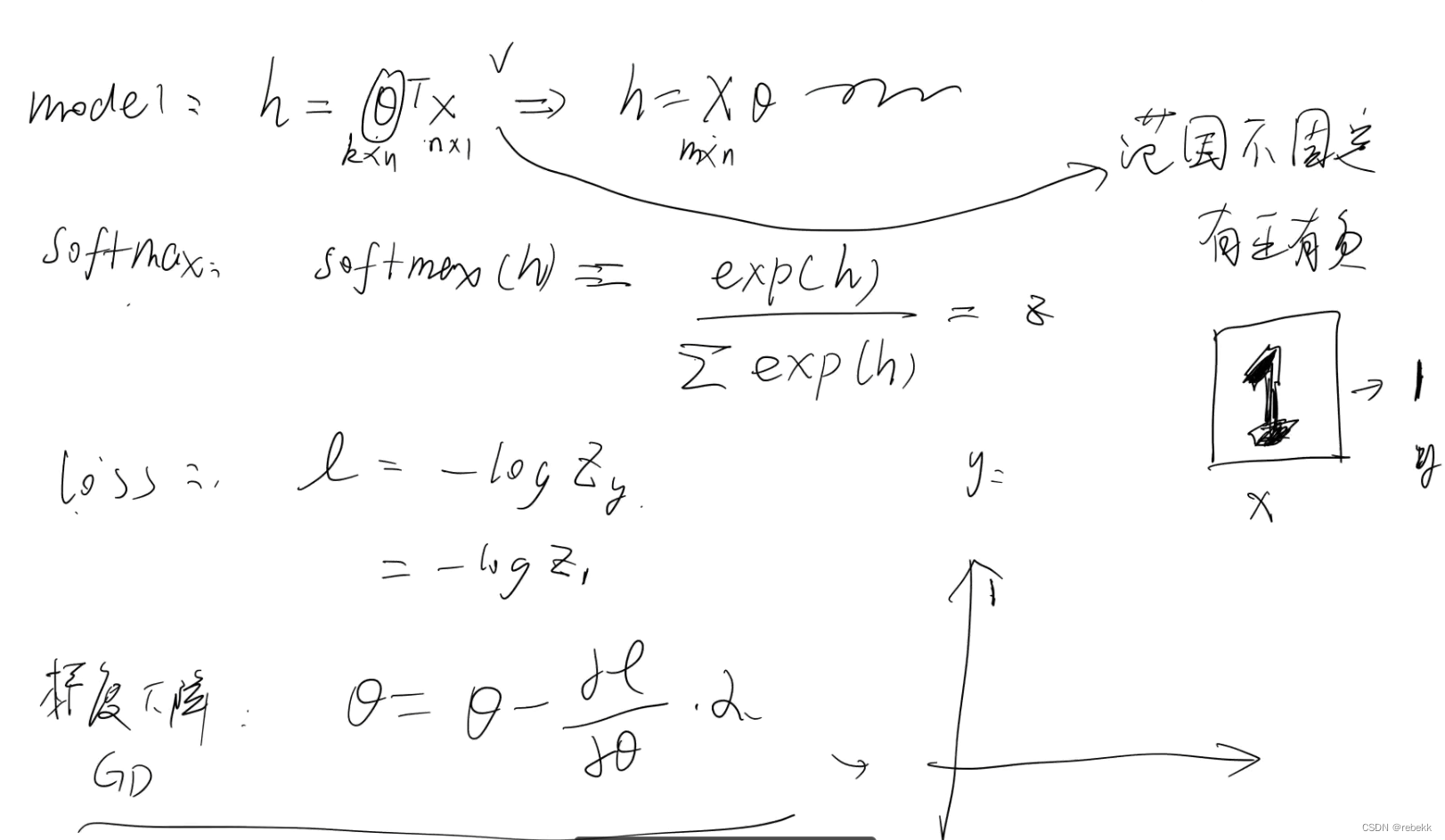/ 表示两个相邻元素节点关系,也可以说父子关系
用法示例:如果要找上述代码中的 a 标签,路径表达式为:div/a注意:如果当前查找出来的标签有多个,比如上面查找到的 a 标签有3个,我们想要第2个,写法就是 div/a[2],同理,我们需要第几个标签,就在标签后面加上[顺序值]
// 表示两个不相邻元素节点关系,也可以说爷孙这种隔代关系
用法示例:还是从上述代码中找 a 标签,路径表达式还可以写为:body//a注意:// 也表示从任意位置开始检索,而不考虑它们的位置。xpath查找标签的顺序正常是从HTML文档头部开始查找,当一个HTML文档中标签非常多,我们查找的标签位于文档的中间某位置。如果直接从头部标签开始一级级往下检索,非常繁琐。用 “// + 标签名” 就相当于从该标签开始检索书写。比如我们还是要找 a 标签,可以写成 //a。
. 指代当前节点,比如xpath路径表达式找到某个元素后,想在此元素基础上往后面查找其他元素,那么前面的路径表达式就可以省略,用 . 替换
@ 选取属性,作用就是更精确定位某个标签
用法示例:比如上面我们正常查找的 a 标签是有3个,我们还是要找第2个 a 标签,已经学了一种方法就是 a 标签后面加上[顺序值]。但是如果 a 标签有几十个呢,我们就要一个个数顺序,很繁琐也容易出错。这时候就可以通过标签自身的属性值来精确定位某个标签。我们仔细可以看出上面的每个 a 标签里面的 href 和 title 两个属性值都是彼此不同的,那我们要找第2个,可以这样写://a[@href=“/ershoufang/xicheng/”] 或者 //a[@title="北京西城在售二手房 "]。格式就是:标签名[@属性名=属性值]text() 提取标签中的文本内容
用法示例:上面的几种方式定位的都是某个标签,如果要拿到标签中的详细内容,比如要拿到第2个 a 标签的文本内容 “西城”这两个字,写法是://a[@title="北京西城在售二手房 "]/text()。格式是:标签/text()
网址信息:
经过点击测试:
“最新发布”的子域名是 co32
下一页的话,子域名是:https://bj.lianjia.com/ershoufang/pg2co32/
https://bj.lianjia.com/ershoufang/pg4co32/
定位需要获取的数据:


代码:
# TODO 爬取链家
import re
import requests
from lxml import etree
import re
basic_url = 'https://bj.lianjia.com/ershoufang/'
domain = 'co32' # 最新发布
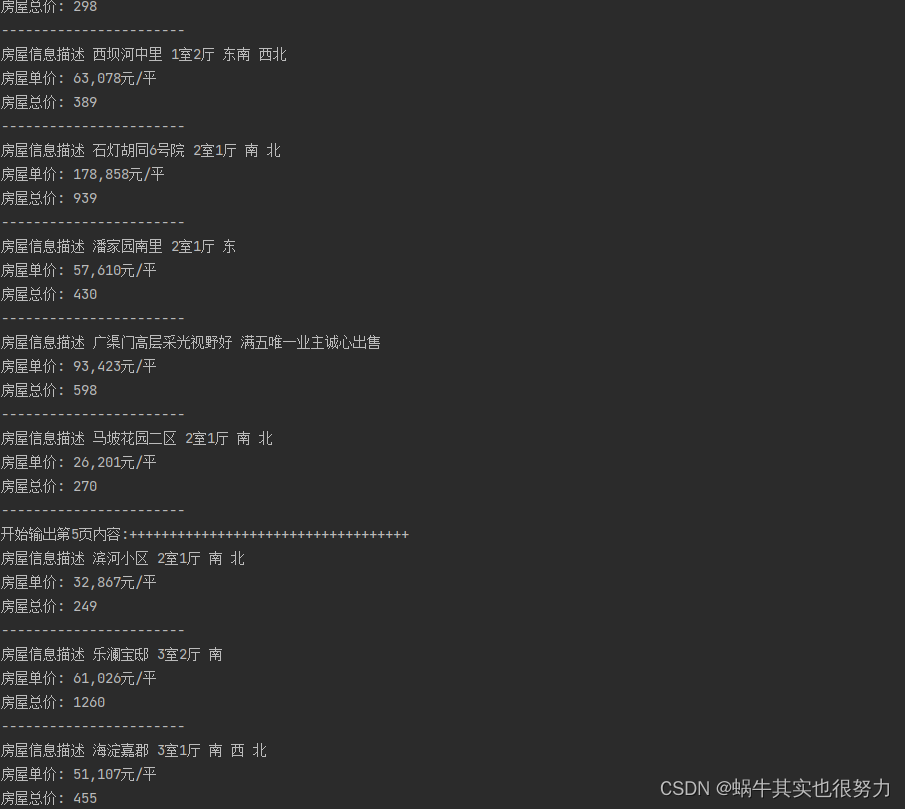
for page in range(1, 6):
print(f"开始输出第{page}页内容:" "+++++++++++++++++++++++++++++++++++")
new_url = basic_url + "pg" + str(page) + domain
headers = {'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'}
response = requests.get(new_url, headers=headers)
html = etree.HTML(response.text)
house_info = html.xpath('//div[@class="title"]/a/text()')
house_price = html.xpath('//div[@class="unitPrice"]//span/text()')
house_sum_prices = html.xpath('//div[@class="totalPrice totalPrice2"]/span/text()')
for house_title, price, sum_price in zip(house_info, house_price, house_sum_prices):
print("房屋信息描述", house_title)
print("房屋单价:", price)
print("房屋总价:", sum_price)
print("-----------------------")大致逻辑:
1.定义一个基本的url
2.定义最新发布的这个子域名
3.for循环定义翻找的页数,这里就弄了5页
4 在for循环里使用拼接字符串法方式 产生新的url,因为是for循环内,所以相当于依次访问
【
https://bj.lianjia.com/ershoufang/pg1co32
https://bj.lianjia.com/ershoufang/pg2co32
https://bj.lianjia.com/ershoufang/pg{N}co32
】
5.etree解析 HTML 内容
6.xpath提取房屋信息
7.使用zip函数迭代多个对象,方便格式化输出相匹配的数据
返回: