一、什么是准确率?
在解答这个问题之前,我们首先得先回顾一下准确率的定义,准确率是机器学习分类问题中一个很直观的指标,它告诉我们模型正确预测的比例,即
还是用我最喜欢的方式,举例子来解释一下:
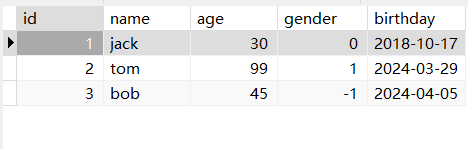
假设我们的任务是将苹果(1)和橘子(0)分开,按照水果的形状、颜色特征来识别并分拣。现在有一个篮子,里面装满了分好的水果。现在,我们要评估一下我们今天工作的准确性。我们就开始一个个地检查篮子里的水果。如果篮子里有100个水果,其中90个是正确分类的(苹果1),那么我们的分拣准确率就是90%。
准确率(Accuracy) = (正确分类的水果数量) / (篮子里水果的总数量)
在这个案例中:准确率 = 90 / 100 = 0.9 或 90%
关于更多其他评估指标,也可以读读我之前的文章作为补充哦。
【机器学习300问】25、常见的模型评估指标有哪些?![]() http://t.csdnimg.cn/pGYSw
http://t.csdnimg.cn/pGYSw
二、准确率局限在哪儿?
准确率虽然是一个直观的模型评估指标,但它有一些局限性,尤其是在处理不平衡数据集(即数据集中某些类别的样本数量远多于其他类别)时。那为什么不平衡的数据集就会导致准确率失去作用呢?
(1)罕见疾病诊断任务为例
目的是预测一组患者是否患有某种疾病。设想这个疾病相对较罕见,所以在1000名患者中,也许只有10人实际上患有这种疾病。患病的人(正类)没有患病的人(负类),一个简单的模型可能会采取最保守的策略,预测所有人都没有患病。
按照准确率的计算方式,这个模型将会有一个很高的准确率:
因为模型预测所有的人都没患病,但实际上有10个人患病,所以模型预测对了990个人,于是分子为990,但是对实际临床应用没有任何价值,因为它没有识别出任何真正的病例。这就是准确率的局限性所在:在不平衡数据集的情况下,它没有考虑到预测的分布是否匹配了现实情况,也没有区分假阳性和假阴性的错误类型。
在医疗领域,漏诊(False Negative, FN, 假阴性)的后果通常比误诊(False Positive, FP, 假阳性)更严重。例如,如果模型未能正确识别出癌症患者,可能导致病情延误、治疗不及时甚至危及生命;而误诊为癌症可能会带来不必要的心理压力和过度治疗,但可以通过进一步检查和专家复核来降低风险。准确率指标无法反映这种重要类别(患病)的识别效果。
- 漏诊(False Negative, FN, 假阴性)模型猜错了[False],猜的是没有得病[Negative],实际上这个人是得病了
- 误诊(False Positive, FP, 假阳性)模型猜错了[False],猜的是得病了[Positive],实际上这个人没得病
(2)电商平台推荐奢侈品任务为例
假设我们正在开发一个系统来为用户推荐高端奢侈品牌商品,通常情况下,消费高端奢侈品的用户群体相比整体用户群体来说要小得多。在所有用户中,可能只有一小部分用户会对奢侈品产生购买行为。因此,数据集在这里是不平衡的,即购买用户(正类)远少于非购买用户(负类)。
假设在一个数据集中,有10000名用户,其中只有100名用户实际购买了奢侈品。如果我们的推荐系统简单地对所有用户都不推荐奢侈品,那么它将在9900个用户身上做出正确的决策(不推荐给不会购买的用户),看上去好像这个推荐系统的准确率很高
这个推荐系统实际上完全失败了,因为它没有成功推荐任何一名用户购买奢侈品,即所有有购买意愿的用户(100名)都被忽略了。
在推荐奢侈品时,误推的成本(False Positive, FP, 假阳性)可能非常高昂。如果推荐给一个对奢侈品兴趣不大或者经济能力不足的用户,不仅浪费了宝贵的推广资源,还可能损害用户体验,降低用户对平台的信任度。漏推的成本(False Negative, FN, 假阴性)同样重要。如果未能识别出潜在的奢侈品买家并向他们推送相关商品,可能导致销售机会的流失和利润减少。
- 误推(False Positive, FP, 假阳性)模型推荐了不买奢侈品的人,推错了[False],模型猜他想买[Positive]
- 漏推(False Negative, FN, 假阴性)模型没有推荐给买奢侈品的人,没推[False],模型猜他不想买[Negtive]
三、有什么办法能对不平衡数据集情况下的模型进行评估呢?
这时候就要考虑用其他的指标来精确率和召回率,关于精确率和召回率的定义,我在另一篇文章中已经介绍过了,链接已经放在上面啦!关于如何不平衡数据集下如何评估模型,我会单独出一篇文章来说精确率和召回率到底怎么理解,还会继续用上面两个任务为大家来深度剖析这两个指标是怎么起作用的。




![BulingBuling - 《金钱心理学》 [ The Psychology of Money ]](https://img-blog.csdnimg.cn/direct/30a3662afd984d6ca0c0b4e1a7a540f8.webp)