有需要互关的小伙伴,关注一下,有关必回关,争取今年认证早日拿到博客专家
解释下什么是面向对象?面向对象和面向过程的区别?
面向对象的三大特性?分别解释下?
-
封装
-
继承
-
多态
JDK、JRE、JVM 三者之间的关系?
JVM:将字节码文件转成具体系统平台的机器指令。
JRE:JVM+Java语言的核心类库。
JDK:JRE+Java的开发工具
重载和重写的区别?
重写注意事项有哪些(一大一同2小2不能 1122)
- 访问修饰符必须大于等于父类
- 方法签名必须相同(方法名+ 参数列表)
- 返回值必须小于等于父类
- 异常必须小于等于父类(可以不抛异常)
- private修饰的方法不能重写
- static修饰的方法不能重写
java.lang.Object#clone
protected native Object clone() throws CloneNotSupportedException;
public class Person {
@Override
public Person clone() {
Person person = null;
try {
person = (Person) super.clone();
} catch (CloneNotSupportedException e) {
e.printStackTrace();
}
return person;
}
}
Java 中是否可以重写一个 private 或者 static 方法?
构造方法有哪些特性?
- 名字与类名相同。
- 没有返回值,但不能用void 声明构造函数。
- 生成类的对象时自动执行,无需调用。
在 Java 中定义一个不做事且没有参数的构造方法有什么作用?
Java 中创建对象的几种方式?
- 使用new关键字
- 使用反射
- clone方法
- 反序列化
抽象类和接口有什么区别?
- 接口自上而下是一种纯粹的规范,抽象类自下而上是一种抽象
- 接口表达是的能干什么,即实现某个接口具有某个接口定义的行为,抽象类表达的是是什么,即子类是 抽象类的特殊类型.
- 接口只有方法的声明,没有具体的实现(java8中接口中的方法可以有默认实现,即用default修饰,即便在java8中也不能有普通方法)抽象类中可以有普通方法.
- 接口中只能有常量不能包含成员变量(默认用 public static final修饰) ;抽象类中可以有成员变量
- 接口中不能含有静态代码块(可以有静态方法,但是只能通过接口调用,不能通过实现类调用,更不能通过实现类的对象调用),抽象类可以有
- 接口不能有构造方法,抽象类可以有
- 一个类只能继承一个抽象类,但是可以实现多个接口.
静态变量和实例变量的区别?
short s1 = 1;s1 = s1 + 1;有什么错?那么 short s1 = 1; s1 += 1;呢?有没有错误?
short s1 = 1;
// 会报错 s1 + 1运算时会自动提升表达式的类型,所以结果是int型, 所以需要将计算结果强转为short类型即s1 = (short) (s1 + 1);
// s1 = s1 + 1;
s1 = (short) (s1 + 1);
// 不会报错 += 是java语言规定的运算符,java编译器会对它进行特殊处理,因此可以正确编译。
s1 +=1;
Integer 和 int 的区别?
装箱和拆箱的区别
switch 语句能否作用在 byte 上,能否作用在 long 上,能否作用在 String 上?
switch可作用于char、byte、short、int及包装类上(4用)
switch不能可作用于long、double、float、boolean及包装类上(4不用)
jdk1.7后switch可作用于String上
// switch可作用于char byte short int
byte season4byte = 3;
char season4char = 3;
short season4short = 3;
int seasonint = 3;
// switch可作用于char byte short int对应的包装类
Byte season4Byte = 3;
Character season4Character = 3;
Short season4Short = 3;
Integer season4Integer = 3;
// switch不可作用于long double float boolean,包括他们的包装类
long season4long = 3;
double season4double = 3;
float season4float = 3f;
boolean season4boolean = false;
// 1.7之后可以作用在String上
String season4String = "";
String strSeason;
switch (season4Byte) {
case 1:
strSeason = "Spring";
break;
case 2:
strSeason = "Summer";
break;
case 3:
strSeason = "Fall";
break;
case 4:
strSeason = "Winter";
break;
default:
strSeason = "四季中没有这个季节";
break;
}
System.out.println("strSeason:" + strSeason);
16、final、finally、finalize 的区别
final 是用来修饰类、方法、变量和参数的关键字;
finally 是 Java 中保证重点代码一定要被执行的一种机制;
finalize 是 Object 类中的一个方法,它的设计目的是保证对象在被垃圾收集前完成特定资源的回收的,但其执行“不稳定”,且有一定的性能问题,已经在 JDK 9 中被设置为弃用的方法了。
== 和 equals 的区别?
- ==一个运算符,equals 是方法
- ==比较变量的值是否相等(基本类型变量的值是值本身,引用类型变量的值是引用),equals 用来比较对象的类容是否相等
两个对象的 hashCode() 相同,则 equals() 也一定为 true 吗?
hashCode()相同,equals不一定相同
equals不同,hashCode一定不相同
为什么重写 equals() 就一定要重写 hashCode() 方法?
因为不同对象的hashCode 可能相同;但hashCode 不同的对象一定不相等,所以使用hashCode 可以起到快速初次判断对象是否相等的作用。
& 和 && 的区别?
&和&&都可以做逻辑运算符号,但&&又叫短路运算符。 因为当第一个表达式的值为false的时候,则不会再计算第二个表达式;而&则不管第一个表达式是否为真都会执行两个表达式。 另外&还可以用作位运算符,当&两边的表达式不是Boolean类型的时候,&表示按位操作。
Java 中的参数传递是传值呢?还是传引用?
java中只有值传递,没有引用传递
形参:方法列表中的参数
实参:调用方法时实际传入到方法列表的参数(实参在传递之前必须初始化)
值传递:传递的是实参的副本(更准确的说是实参引用的副本,因为形参接受的是对象的引用)
引用传递:传递的是内存地址
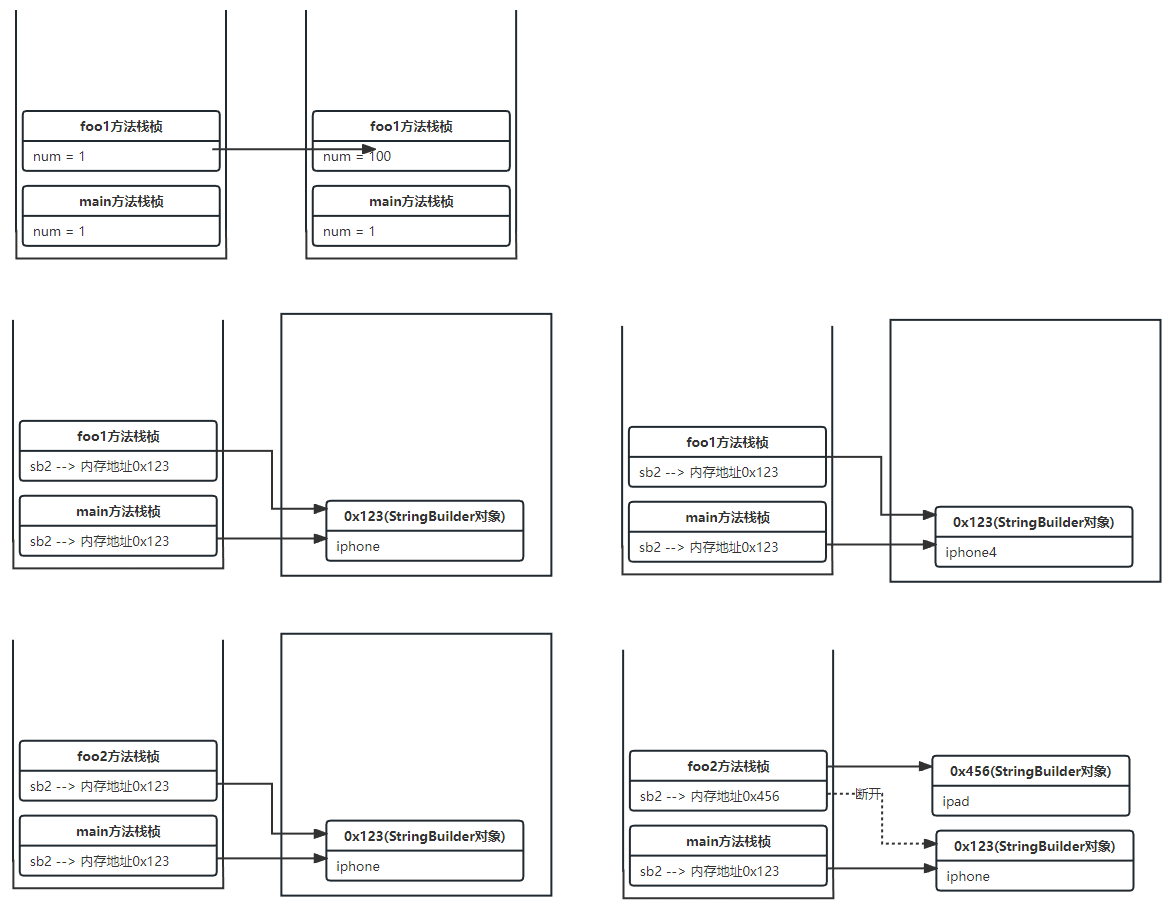
public static void main(String[] args) {
// 实参
int num = 1;
// num 没有被改变 基本类型存储在栈里面,main方法栈里有一个num = 1,foo方法栈里存了一个副本num = 1;后来foo栈里面的改成了100,不会影响main方法中的
foo(num);
String str = "ABC";
foo(str); // str 也没有被改变
StringBuilder sb1 = new StringBuilder("iphone");
foo1(sb1); // sb 被改变了,变成了"iphone4"。
/*
* main方法栈有有个sb2 指向堆中的StringBuilder("iphone")对象
* 将main栈中的sb2的副本传递给foo2中的形参builder,builder指向堆中的StringBuilder("iphone")对象(与main是同一个对象)
* foo2栈中的builder指向StringBuilder("ipad")对象
* main栈中的sb2不会受影响
* 如果是引用传递main中的sb2会收到影响
*/
StringBuilder sb2 = new StringBuilder("iphone");
foo2(sb2); // sb 没有被改变,还是 "iphone"
System.out.println("num:" + num);//num:1
System.out.println("str:" + str);//str:ABC
System.out.println("sb1:" + sb1.toString());//sb1:iphone4
System.out.println("sb2:" + sb2.toString());//sb2:iphone
}
//第一个例子:基本类型 value为形参
static void foo(int value) {
value = 100;
}
//第二个例子:没有提供改变自身方法的引用类型
static void foo(String text) {
text = "windows";
}
/*
* 是否说明java支持引用传递呢? 不支持
* StringBuilder builder传递的仅仅是builder本身的值(即实参引用的副本)
*/
static void foo1(StringBuilder builder) {
builder.append("4");
}
//第四个例子:提供了改变自身方法的引用类型,但是不使用,而是使用赋值运算符。
static void foo2(StringBuilder builder) {
builder = new StringBuilder("ipad");
}
Java 中的 Math.round(-1.5) 等于多少?
-1
如何实现对象的克隆?
有两种方式:
- 实现Cloneable接口并重写Object类中的clone()方法(必须实现Cloneable标记接口,否则会报CloneNotSupportedException异常)
- 实现Serializable接口,通过对象的序列化和反序列化实现克隆,可以实现真正的深度克隆。
深克隆和浅克隆的区别?
-
浅克隆:只复制基本类型的数据,引用类型的数据只复制了引用的地址,引用的对象并没有复制,在新的对象中修改引用类型的数据会影响原对象中的引用(引用类型:新老对象指向同一个对象)。
-
深克隆:是在引用类型的类中也实现了clone,是clone的嵌套,复制后的对象与原对象之间完全不会影响(手动调用引用类型的对象的clone方法)。
-
使用序列化也能完成深复制的功能:对象序列化后写入流中,此时也就不存在引用什么的概念了,再从流中读取,生成新的对象,新对象和原对象之间也是完全互不影响的。
@Data public class Yyy implements Cloneable { int id; @Override protected Yyy clone() throws CloneNotSupportedException { return (Yyy) super.clone(); } public Yyy(int id) { this.id = id; } }浅克隆
public class Xxx implements Cloneable { private int age; private Yyy yyy; @Override public Xxx clone() throws CloneNotSupportedException { // 只克隆了基本类型,引用类型和原对象指向同一个堆中的对象 return (Xxx) super.clone(); } public static void main(String[] args) throws CloneNotSupportedException { Xxx xxx = new Xxx(); xxx.setAge(1); xxx.setYyy(new Yyy(1)); Xxx clone = xxx.clone(); clone.getYyy().setId(2); System.out.println("xxx = " + xxx); System.out.println("clone = " + clone); } }深克隆
public class Xxx implements Cloneable { private int age; private Yyy yyy; @Override public Xxx clone() throws CloneNotSupportedException { Xxx clone = (Xxx) super.clone(); // 给引用类型重新赋值 调用引用类型的 clone方法 clone.setYyy(this.getYyy().clone()); return clone; } public static void main(String[] args) throws CloneNotSupportedException { Xxx xxx = new Xxx(); xxx.setAge(1); xxx.setYyy(new Yyy(1)); Xxx clone = xxx.clone(); clone.getYyy().setId(2); System.out.println("xxx = " + xxx); System.out.println("clone = " + clone); } }xxx = Xxx(age=1, yyy=Yyy(id=1)) clone = Xxx(age=1, yyy=Yyy(id=2))
什么是 Java 的序列化,如何实现 Java 的序列化?
序列化:(方便在磁盘上存储或者在网络上传输)把对象转换为字节序列的过程称为对象的序列化。
反序列化:把字节序列恢复为对象的过程称为对象的反序列化。
利用ObjectOutputStream和ObjectInputStream序列化和反序列化时一定要实现Serializable接口,否则会报NotSerializableException异常
利用fastjson序列化字符串时不实现Serializable不会报异常
@Data
public class Person implements Serializable {
private static final long serialVersionUID = 1L;
// private static final long serialVersionUID = 2L;
public static int id;
private String name;
private int age;
private Pet pet;
private transient Car car;
private int height;
public static void main(String[] args) {
serializePerson();
deserializePerson();
}
private static void serializePerson() {
Person person = new Person();
person.setName("张三三");
person.setAge(18);
person.setPet(new Pet("大黄"));
person.setCar(new Car("奥迪"));
Person.id = 1;
try (ObjectOutputStream out = new ObjectOutputStream(new FileOutputStream("person.txt"))) {
out.writeObject(person);
System.out.println("序列化完成");
} catch (Exception e) {
e.printStackTrace();
}
}
private static void deserializePerson() {
try (ObjectInputStream in = new ObjectInputStream(new FileInputStream("person.txt"))) {
Person readObject = (Person) in.readObject();
System.out.println("readObject = " + readObject);
System.out.println(Person.id);
} catch (Exception e) {
e.printStackTrace();
}
}
}
@Data
class Car {
private String name;
public Car(String name) {
this.name = name;
}
}
@Data
class Pet implements Serializable {
private String name;
public Pet(String name) {
this.name = name;
}
}
序列化完成
readObject = Person(name=张三三, age=18, pet=Pet(name=大黄), car=null, height=0)
1
说明:
- 静态成员变量不能序列化(需要单独跑序列化,再跑反序列化)
- transient修饰的成员变量不参与序列化
- 参与序列化的引用类型也必须实现Serializable接口,否则会报NotSerializableException异常
- 最好提供serialVersionUID解决新老版本数据的兼容性问题(数据版本不一致时会报InvalidClassException异常)
- 可序列化类的所有子类型本身都是可序列化的。因为实现接口也是间接的等同于继承。
- 利用fastjson等工具时,不实现Serializable不会报错
什么情况下需要序列化?
把对象的字节序列永久地保存到硬盘上,通常存放在一个文件中;
在网络上传送对象的字节序列。
Java 的泛型是如何工作的 ? 什么是类型擦除 ?
什么是泛型中的限定通配符和非限定通配符 ?
限定通配符包括两种:
-
表示类型的上界,格式为:<? extends T>,即类型必须为T类型或者T子类
-
表示类型的下界,格式为:<? super T>,即类型必须为T类型或者T的父类
-
List<? extends T> src 只能读,获取到的元素时T类型或者子类型,List<? super T> dest只写,写进去的元素时T类型或者T类型的子类型(上限怎么理解??? List的类型为T或者T的父类,所以你存T或者T的子类是都可以的),读又写List list不限定类型
public static <T> void copy(List<? super T> dest, List<? extends T> src) { for (int i=0; i<srcSize; i++) dest.set(i, src.get(i)); }
非限定通配符:类型为,可以用任意类型来替代。
Java 中的反射是什么意思?
JAVA反射机制是在运行状态中,对于任意一个类,都能够知道这个类的所有属性和方法;对于任意一个对象,都能够调用它的任意一个方法和属性;这种动态获取的信息以及动态调用对象的方法的功能称为java语言的反射机制。
有哪些应用场景?
- 框架和库开发:许多Java框架和库使用反射来实现插件化、扩展性和动态配置。例如,Spring框架使用反射来实现依赖注入和AOP(面向切面编程)等功能。
- 序列化和反序列化:反射可以在对象和字节流之间进行转换,实现对象的序列化和反序列化。常见的序列化框架,如Java的ObjectOutputStream和ObjectInputStream,以及JSON序列化库,通常使用反射来读取和写入对象的属性。
- 单元测试:反射可以在单元测试中模拟和操作私有字段和方法,以便进行更全面的测试。测试框架如JUnit和TestNG使用反射来调用测试方法并获取测试结果。
- 动态代理:反射可以用于创建动态代理对象,通过代理对象来拦截并执行方法调用。这种机制在AOP中经常用到,可以在不修改原始类的情况下添加额外的逻辑。
- 配置文件解析:通过反射可以读取和解析配置文件,将配置文件中的数据映射到Java对象中。例如,常见的XML解析库,如DOM和SAX解析器,可以使用反射来创建并操作对象。
- 注解处理:反射可以用于处理和解析注解。通过反射,可以获取类、字段、方法上的注解,并根据注解的信息执行相应的操作,如生成文档、生成代码等。
反射的优缺点?
- 性能开销:与直接调用静态代码相比,使用反射调用方法和访问字段会导致一定的性能开销。反射涉及到运行时的类型检查和方法调用解析,通常比静态代码执行更慢。
- 安全性限制:反射可以绕过访问控制修饰符(如private),从而访问和修改本来不应该被公开的成员。这可能会破坏封装性和安全性,因此在使用反射时需要特别小心,确保不会引入潜在的安全漏洞。
- 编译时类型检查缺失:由于反射允许在运行时动态地获取类的信息,因此编译器无法进行静态类型检查。这可能导致在编译时无法捕获到某些错误,而是在运行时才会出现异常。
Java 中的动态代理是什么?有哪些应用?
Java中的动态代理是一种在运行时生成代理对象的机制。它允许在不预先编写具体代理类的情况下创建代理对象,并且代理对象可以在运行时拦截并处理对目标对象的方法调用。
动态代理的应用场景
- 日志记录:动态代理可以在方法调用前后记录日志。
- 事务管理:动态代理可以在方法调用前后处理事务的开启、提交或回滚,从而实现对事务的控制。
- 安全检查:动态代理可以在方法调用前进行安全检查,例如检查用户权限或身份验证。
- 缓存管理:动态代理可以在方法调用前检查缓存,如果缓存中存在结果,则直接返回缓存的结果,否则调用目标方法并将结果缓存起来。
- 延迟加载:动态代理可以延迟加载目标对象,当真正需要调用方法时才进行初始化,从而提高性能例如spring的**@Lazy**注解。
- AOP
- @Lookup
- 远程调用:动态代理可以用于远程通信,代理对象将方法调用转发给远程服务,并将结果返回给调用方。
怎么实现动态代理?
- JDK动态代理
PersonServiceImpl target = new PersonServiceImpl();
// UserInterface接口的代理对象
// Object newProxyInstance(ClassLoader loader, Class<?>[] interfaces, InvocationHandler h)
Object proxy = Proxy.newProxyInstance(PersonService.class.getClassLoader(), new Class[]{PersonService.class}, (proxy1, method, args1) -> {
System.out.println("before...");
Object result = method.invoke(target, args1);
System.out.println("after...");
return result;
});
PersonService userService = (PersonService) proxy;
userService.addPerson(new Person("张三三"));
- cglib动态代理
PersonServiceImpl target = new PersonServiceImpl();
// 通过cglib技术 /ɪnˈhɑːnsə(r)/ 增强器
Enhancer enhancer = new Enhancer();
enhancer.setSuperclass(PersonServiceImpl.class);
// 定义额外逻辑,也就是代理逻辑
enhancer.setCallbacks(new Callback[]{(MethodInterceptor) (o, method, objects, methodProxy) -> {
System.out.println("before...");
Object result = methodProxy.invoke(target, objects);
System.out.println("after...");
return result;
}});
// 动态代理所创建出来的UserService对象
PersonServiceImpl personService = (PersonServiceImpl) enhancer.create();
// 执行这个userService的test方法时,就会额外会执行一些其他逻辑
personService.addPerson(new Person("张三三"));
static 关键字的作用?
super 关键字的作用?
一个指向父类对象的引用变量
字节和字符的区别?
String 为什么要设计为不可变类?
因为Sting类型在java中用的最多,所以做了特殊处理,为了提升性能,性能提升了,但是创建了很多对象,怎么破?常量池
Java中的字符串(String)被设计为不可变的主要有以下几个原因:
- 性能优化:字符串池(String Pool)的存在使得多个字符串变量可以共享同一个字符串对象。如果字符串是可变的,那么在修改字符串时就需要创建一个新的字符串对象,导致内存的频繁分配和回收,影响性能。而不可变的字符串可以在字符串池中复用现有对象,避免了额外的内存开销。
- 安全性:字符串在Java中广泛用于作为参数传递给方法、用于作为HashMap的键等。如果字符串是可变的,那么在这些情况下,字符串对象的值可以被修改,从而可能导致意外的行为或安全漏洞。通过将字符串设计为不可变的,可以确保字符串的值不会被修改,提高了代码的安全性。
- 线程安全:不可变性是线程安全的一种保证。在多线程环境下,如果多个线程同时修改同一个可变字符串对象,就会引发竞态条件(race condition)和不一致的结果。通过使用不可变的字符串,可以避免这种问题,无需额外的同步措施。
- 缓存哈希值:由于字符串在Java中经常被用作HashMap的键,字符串的不可变性确保了字符串的哈希值不会变化。这样在使用字符串作为键进行查找时,可以更快地定位到正确的位置,提高了性能。
综上所述,将字符串设计为不可变的是为了性能优化、安全性、线程安全和哈希值缓存等方面的考虑。这是Java语言设计的一项重要决策。
String、StringBuilder、StringBuffer 的区别?
- 可变性:String是不可变的类,一旦创建了String对象,它的值就不能被改变。而StringBuilder和StringBuffer是可变的类,可以修改已有的字符串内容。
- 线程安全性:String是线程安全的,因为它是不可变的,多个线程可以安全地共享String对象。StringBuilder是非线程安全的,而StringBuffer是线程安全的。在多线程环境下,如果需要对字符串进行频繁的修改操作,应使用StringBuffer,它会进行同步控制以保证线程安全性。
- 性能:由于String是不可变的,每次对String进行修改时,实际上都会创建一个新的String对象,这可能导致内存开销增加。而StringBuilder和StringBuffer是可变的,它们在进行字符串修改时不会创建新的对象,而是在原有对象上直接进行操作,因此在性能上比String更高效。StringBuilder相对于StringBuffer稍微快一些,因为StringBuilder不进行同步控制。
综上所述,当字符串需要频繁修改时,应优先使用StringBuilder。如果在多线程环境下需要对字符串进行修改,应使用StringBuffer以保证线程安全性。而当字符串不需要修改时,或者需要在多个线程之间共享时,应使用String,以保证安全性。
String str = “i” 与 String str = new String(“i”) 一样吗?
不一样,String str = “i”;是把值放到了常量中,而String str = new String(“i”);是将值放到了堆内存中。
String 类的常用方法都有那些?
String s = "hello string ";
s.length();
s.trim();
s.contains("");
s.startsWith("");
s.endsWith("");
s.toLowerCase();
s.toUpperCase();
s.replace("","");
s.replaceFirst("","");
s.indexOf("");
s.lastIndexOf("");
s.substring(3);
s.split(" ");
s.matches("");
s.charAt(1);
s.intern();
s.toCharArray();
String.join(",","1","2");
String.format("hello %s","zss");
String.valueOf(1);
字符串比较
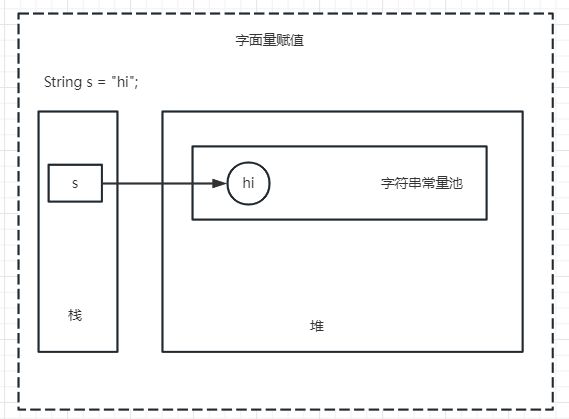
-
通过字面量赋值创建字符串(如:String s=”hi”),会先在常量池中查找是否存在相同的字符串,若存在,则直接指向该字符串;若不存在,则在常量池中生成一个字符串,再将引用指向该字符串。
-
通过new String创建字符串,在堆上创建一个,同时在常量池创建一个值相同的对象,但是这两个对象互不相干,如果常量池里已经有了同样的值的对象,只会在堆里新建对象
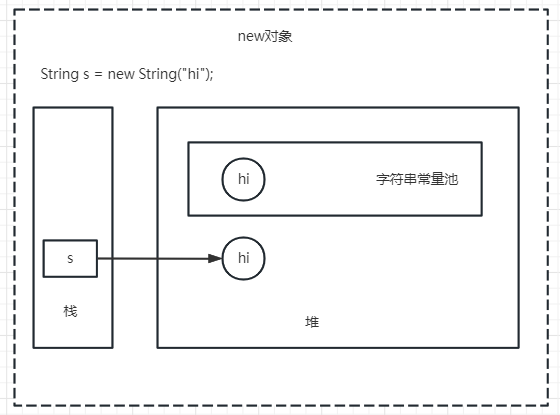
-
常量字符串和变量拼接时或者变量与变量拼接时会调用stringBuilder.append()在堆上创建新的对象,而不会同时在常量池里新建对象
String s = new String("a") + new String("b");约等于
StringBuilder sb = new StringBuilder(); sb.append("a").append("b"); // toString()只会在堆上创建对象("ab"),new String("ab") 会在堆上和常量池都创建 String s = sb.toString();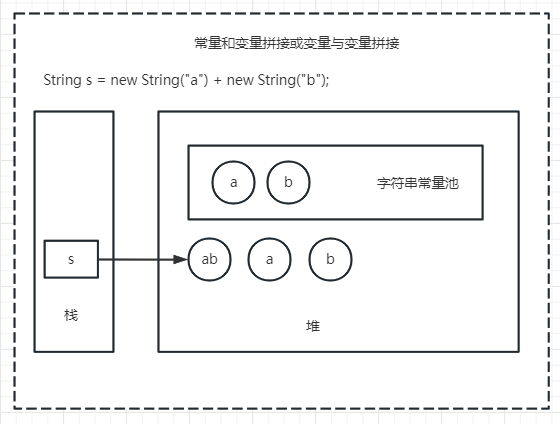
-
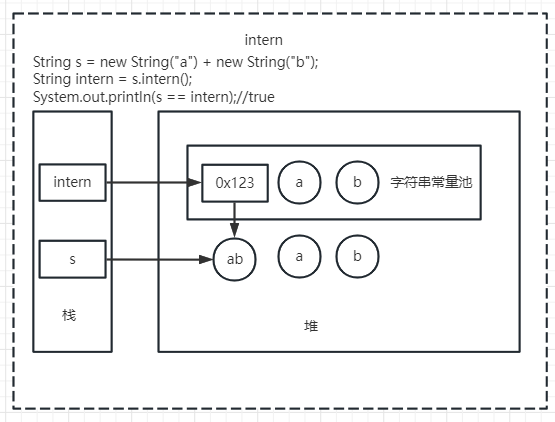
调用字符串对象的 intern() 方法时,intern方法会先去常量池找,如果存在,指向常量池中的,如果不存在,在常量池中生成一个对原字符串的引用
-
字面量+字面量在编译期间就优化成了常量
String s = new String("a") + new String("b"); String intern = s.intern(); System.out.println(s == intern);// trueString str1 = "哈哈"; String str2 = str1 + "呵呵"; String str3 = "哈哈呵呵"; System.out.println(str2 == str3);// falseString s1 = "abc"; String s2 = "a"; String s3 = "bc"; String s4 = s2 + s3; System.out.println(s1 == s4);// false注意这个与上一个对比
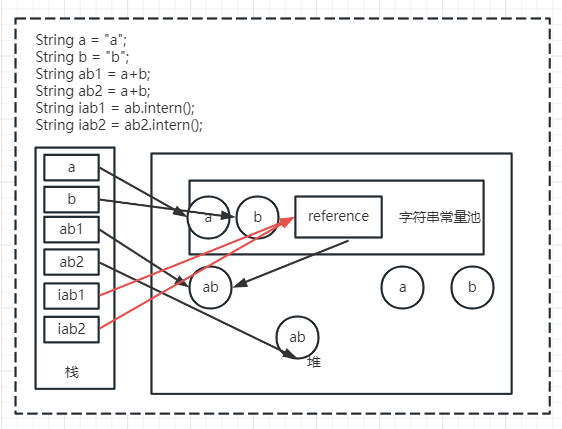
String s1 = "abc"; final String s2 = "a"; final String s3 = "bc"; String s4 = s2 + s3; // 因为final变量在编译后会直接替换成对应的值,所以实际上等于s4=”a”+”bc”,而这种情况下,编译器会直接合并为s4=”abc” System.out.println(s1 == s4);//trueString s = new String("abc"); String s1 = "abc"; String s2 = new String("abc"); System.out.println(s == s1.intern());// false System.out.println(s == s2.intern());// false System.out.println(s1 == s2.intern());// trueString a = "a"; String b = "b"; String ab = a+b; String ab2 = a+b; String Iab = ab.intern(); String Iab2 = ab2.intern(); // ab与ab2都在堆里 System.out.println(ab==ab2);// false // 常量池中没有"ab"即String ab = a+b;也等价于sb.append("a").append("b"); System.out.println(Iab==ab);// true System.out.println(Iab2==ab);// true
你到底懂了吗
public class StringDemo {
public static void main(String[] args) {
m7();
}
private static void m1() {
String a = "a";
String b = "b";
String s = a + b;
String intern = s.intern();
System.out.println(s == intern);
}
private static void m2() {
String s = new String("a") + new String("b");
String intern = s.intern();
System.out.println(s == intern);
}
private static void m3() {
String a = "a";
String ab1 = a + "b";
String ab2 = "ab";
System.out.println(ab1 == ab2);
}
private static void m4() {
String a = "a";
String b = "b";
String ab1 = a + b;
String ab2 = "ab";
System.out.println(ab1 == ab2);
}
private static void m5() {
final String a = "a";
String ab1 = a + "b";
String ab2 = "ab";
System.out.println(ab1 == ab2);
}
private static void m6() {
String ab1 = "ab";
String ab2 = new String("ab");
String ab3 = new String("ab");
System.out.println(ab2 == ab1.intern());
System.out.println(ab2 == ab3.intern());
System.out.println(ab2.intern() == ab3.intern());
System.out.println(ab1 == ab3.intern());
}
private static void m7() {
String a = "a";
String b = "b";
String ab1 = a + b;
String ab2 = a + b;
System.out.println(ab1 == ab2);
System.out.println(ab1 == ab1.intern());
System.out.println(ab2 == ab2.intern());
System.out.println(ab1 == ab2.intern());
System.out.println(ab1.intern() == ab2.intern());
}
}
final 修饰 StringBuffer 后还可以 append 吗?
可以 ,final 修饰的是一个引用变量,那么这个引用始终只能指向这个对象,但是这个对象内部的属性是可以变化的。
Java 中的 IO 流的分类?说出几个你熟悉的实现类?
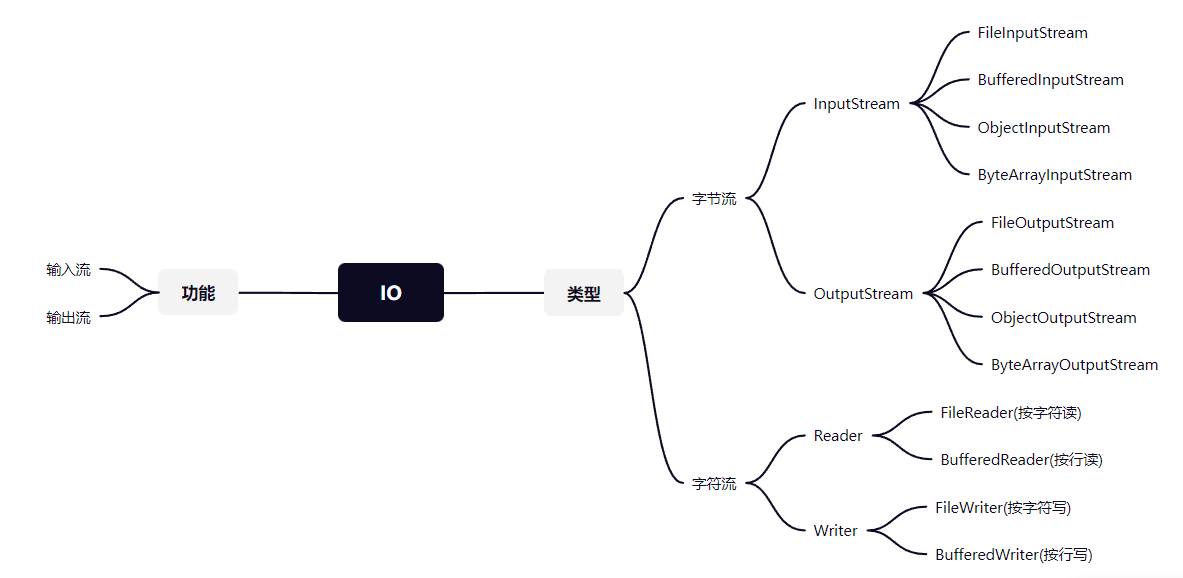
常见的字节流
FileInputStream
try (FileInputStream inputStream = new FileInputStream("input.txt")) {
int data;
while ((data = inputStream.read()) != -1) {
System.out.println((char) data);
}
} catch (IOException e) {
e.printStackTrace();
}
BufferedInputStream
try (BufferedInputStream inputStream = new BufferedInputStream(new FileInputStream("input.txt"))) {
byte[] buffer = new byte[1024];
int bytesRead;
while ((bytesRead = inputStream.read(buffer)) != -1) {
System.out.write(buffer, 0, bytesRead);
}
} catch (IOException e) {
e.printStackTrace();
}
FileOutputStream
try (FileOutputStream outputStream = new FileOutputStream("output.txt")) {
String data = "Hello, World!";
byte[] bytes = data.getBytes();
outputStream.write(bytes);
} catch (IOException e) {
e.printStackTrace();
}
BufferedOutputStream
try (BufferedOutputStream outputStream = new BufferedOutputStream(new FileOutputStream("output.txt"))) {
String data = "Hello, World!";
byte[] bytes = data.getBytes();
outputStream.write(bytes);
} catch (IOException e) {
e.printStackTrace();
}
常见的字符流
FileReader
try (FileReader reader = new FileReader("example.txt")) {
int character;
while ((character = reader.read()) != -1) {
System.out.println((char) character);
}
} catch (IOException e) {
e.printStackTrace();
}
BufferedReader
public static void main(String[] args) {
try (BufferedReader reader = new BufferedReader(new FileReader("example.txt"))) {
String line;
while ((line = reader.readLine()) != null) {
System.out.println(line);
}
} catch (IOException e) {
e.printStackTrace();
}
}
FileWriter
try (FileWriter writer = new FileWriter("output.txt")) {
String data = "Hello, World!";
writer.write(data);
} catch (IOException e) {
e.printStackTrace();
}
BufferedWriter
try (BufferedWriter writer = new BufferedWriter(new FileWriter("output.txt"))) {
String line1 = "Line 1";
String line2 = "Line 2";
writer.write(line1);
writer.newLine(); // 写入换行符
writer.write(line2);
} catch (IOException e) {
e.printStackTrace();
}
字节流和字符流有什么区别?
- 数据处理单位:字节流以字节为单位进行数据传输,而字符流以字符为单位进行数据传输。
- 编码处理:字节流以原始的字节形式传输数据,不对数据进行任何编码或解码。字符流则可以进行字符编码和解码的操作,将字符按照指定的字符集转换为字节流进行传输,或将字节流按照指定的字符集转换为字符进行处理。
- 应用场景:字节流常用于处理图像、音频、视频等二进制文件,或者在处理文本文件时不涉及字符编码的情况。字符流常用于处理文本文件,尤其是需要考虑字符编码和国际化的情况。
- 继承体系:字符流的父接口为Reader/Writer。字节流父接口为InputStream/OutputStream。
需要注意的是,字符流底层仍然是通过字节流来进行数据传输的,字符流会在字节流的基础上进行字符编码和解码的处理。在处理文本数据时,字符流更为方便(推荐),因为它们可以自动处理字符集的转换。
BIO、NIO、AIO 有什么区别?
- 阻塞与非阻塞:BIO是阻塞式的I/O模型,即当线程执行I/O操作时,会被阻塞直到操作完成。NIO和AIO是非阻塞式的I/O模型,允许线程在等待I/O操作完成时继续做其他工作。
- 操作方式:BIO使用同步阻塞方式进行I/O操作,即一个线程对应一个客户端连接或一个I/O操作。NIO使用同步非阻塞方式,通过使用选择器(Selector)和缓冲区(Buffer)实现对多个客户端连接的管理和数据读写。AIO使用异步非阻塞方式,通过回调机制实现对I/O操作的处理。
- 线程模型:BIO采用了一对一的线程模型,即每个客户端连接都需要一个独立的线程进行处理。NIO采用了多路复用器(Selector)和事件驱动模型,通过少量线程管理多个连接。AIO也采用了事件驱动模型,但不需要主动通过多路复用器轮询事件,而是通过回调函数的方式实现异步处理。
- 编程复杂性:BIO的编程模型相对简单,但在面对大量并发连接时,需要创建大量线程,造成资源消耗和线程切换开销。NIO相对于BIO更复杂一些,需要处理事件的选择和缓冲区的管理,但能够处理大量并发连接而不需要过多的线程。AIO在编程模型上更加复杂,需要使用回调函数来处理异步操作,但可以实现高并发和高吞吐量的I/O操作。
根据实际需求和场景的不同,可以选择适合的I/O模型。BIO适用于连接数较小且简单的情况,NIO适用于需要管理大量连接的情况,AIO适用于需要实现高并发和高吞吐量的异步操作的情况。